一 问题定义
视觉故障检测领域的识别问题整体可以分为两大类:
1)结构化故障识别:故障形态单一、明显、可语义穷尽,如部件脱落、丢失等,可以用自然语言描述完故障发生的所有情况
2)开放形态故障识别:故障形态多变,无明显故障特征、无法语义穷尽,最典型的就是异物、破损类问题,异物的种类不固定,破损的位置、大小、形状都不固定,三者的故障形态组合理论上可以接近无穷
下面是一些开放形态故障的例子:
①部件表面出现不规则凹痕

②铁轨之间出现不规则异物

现有的视觉故障识别方法依赖故障特征提取的准确性,从早期的SIFT、HOG等人工设计的特征,到基于卷积神经网络的自动特征提取,再到现在基于大规模预训练数据自监督的Transformer架构(ViT、DINO等系列),目标都是让提取到的特征更准确,不同特征之间的区分性更强,从而可以利用这些特征进行接下来的故障识别任务,这种故障识别模式对于结构性故障有效,能够达到较高的识别准确率,但是对于开放形态故障识别效果不明显,原因有以下几点:
1)开放形态故障数据采集困难:这是这种特征提取方法效果较差的主要原因,这类方法一般需要借助大量的监督信息,才能逐步学习到准确的特征表示,但是某些种类的故障数据很难在真实场景中收集(森林大面积火灾)或者只能收集到较少量的数据,用这些少量的数据进行模型训练,模型容易过拟合,不仅特征提取不准,而且泛化性也较差,体现在线上的使用效果就是漏报误报都很高
2)特征形态不固定:即使能收集或者生成大量开放形态的故障数据,因为这类故障的特征形态不固定,往往线下模型训练时,各类评测指标的效果极好,但是上线后对于分布外(训练集外)的故障数据还是无法产生准确的预测,这种"特征形态的不固定"体现在故障形态开放、故障类别开放上,线上总有一些故障形态或者故障类别是线下训练集无法覆盖到的
针对开放形态故障识别问题,业界已提出大量的方法,本文按照:
1)有监督方法:需要监督信号进行自身方法、模型结构的迭代改进
2)无监督方法:不需要监督信号进行迭代改进,直接可运用于线上识别环境中
进行介绍。
二 有监督方法
2.1 充足异常数据
当异常数据充足时,可以直接使用已被工业界反复验证,比较成熟的故障检测方法,这些方法主要分为:
1)目标检测类:目标检测会同时给出待检测故障在图像中的位置坐标和故障类别,是故障检测领域最常使用的检测方法类。目标检测是基于特征语义层级的判定,具有快速、抗干扰等特性,对于常规、特征固定的目标,已经能达到人眼识别的水准,现在主要的性能瓶颈集中在对密集目标、遮挡目标、小目标、不规则目标的检测上,较成熟的开发框架是MMDetection、Ultralytics
2)图像分割:图像分割会给出图像中故障具体的亚像素级别的像素集合信息,一般称为Mask矩阵,适用于哪些追求高精度量化层级的故障检测、比如测距。因为图像分割需要逐像素进行分类,所以一般相比于目标检测方法运行更慢,大约相差在10倍的量级,比如目标检测可能0.03秒就出检测结果,但是图像分割需要0.3秒才能出结果。图像分割对于不规则形状、柔性物体的故障检测,比如布料破洞、裂纹等,相比于目标检测效果更好,较成熟的开发框架是MMSegmentation
3)关键点检测:关键点检测同样也是亚像素级别的故障检测,相比于图像分割,关键点检测只给出故障几个预定义部位的坐标点,比如4个角点,而不是像图像分割一样给出故障的所有位置信息像素集合,适用于哪些不规则形状、柔性物体的故障量化指标计算,比如计算一个锁链断裂后下摆的角度,可以通过求解关键点,然后通过几何的手段进行计算,较成熟的开发框架是MMPose
2.1.1 目标检测
目标检测主要分为三大类方法,适用于不同的业务场景:
1)两阶段目标检测:代表性方法是Faster R-CNN、Cascade R-CNN,是工业落地的标准,能够兼顾精度和速度的平衡。两阶段目标检测先根据图像的特征,输出故障大致可能存在的位置,然后再对这些位置进行进一步精细调整,给出最终的故障坐标和对应故障类别
2)单阶段目标检测:单阶段目标检测将图像分为不同的格子,直接对每个格子进行是否有目标、目标具体位置的预测,相比于两阶段目标检测速度更快,适用于实时目标检测要求的场景。最初单阶段目标检测的精度远远落后于两阶段目标检测方法,但是随着近几年的不断优化,效果已经远超两阶段模型,尤其是以YOLO系列为代表的模型,已经成为了实际的单阶段目标检测方法标准,最新的YOLO26模型相比于其它目标检测模型在CoCo目标检测公共数据集上达到了最优的结果
3)端到端目标检测:无论是两阶段目标检测还是单阶段目标检测,都会包含'NMS'的过程,NMS会剔除模型对同一目标的重复性预测结果,是一个无法纳入模型端到端学习的过程,并且对NMS超参数设置较敏感,容易导致正确检测结果的'误杀',对密集目标、遮挡目标不友好,也是目标检测后处理比较耗时的一个环节。端到端目标检测完全舍弃'NMS'过程,直接输出无冗余的检测结果,代表性方法是以DETR系列为代表的Transformer架构目标检测模型,如Deformable DETR、RT-DETR,最新推出的RF-DETR达到了CoCo数据集上的最优
Faster R-CNN/Cascade R-CNN
方法出处
2016-《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
2017-《Cascade R-CNN: Delving into High Quality Object Detection》
方法原理和过程
对于输入的待检测故障图片
1)利用特征提取网络,一般使用的是ResNet,这种在大规模数据集上进行过预训练的模型,对输入的图片进行特征提取,得到图片不同尺度层级对应的Feature Map(特征图),网络浅层输出的特征图感受野较小,适合检测图片中的小目标故障,更深层网络的特征图融合了更多的全局语义特征,适合中、大型故障目标的检测,根据这个特点可以有选择的使用这些特征图,如果要检测的故障大多为小型目标,那么需要重点融合、处理浅层的特征信息,让浅层提取到的特征更准确,比如可以添加辅助分支专门对浅层的特征提取网络层进行训练等
2)一般我们要处理的目标检测问题,目标的尺度大多数是不固定的,也就是大、中、小目标会同时糅合在一张图片中,不可能所有的目标都是小目标,除非人为刻意的构建这种小目标数据集进行训练,所以需要同时根据不同特征提取网络层输出的特征图,进行故障判定,这就需要利用特征融合网络对这些不同层级的特征图进行特征融合,利用融合之后的特征图再进行接下来的目标检测,结果会更加准确
3)根据融合后的特征,预测出原图中可能存在故障的区域
4)对于这些可能存在故障的区域进行进一步精细微调,包括故障的准确坐标、故障的类别
Cascade R-CNN相比于Faster R-CNN会重复多次4)过程,所以检测结果相比于Faster R-CNN更加准确,但是推理时间也会相应变长
方法适用性
时效性方面,对于一张1024*1024的图片,常用的推理、消费级显卡上,Faster R-CNN/Cascade R-CNN大约需要0.02~0.05秒给出检测结果。准确性方面,当故障训练数据充足时,Faster R-CNN/Cascade R-CNN能够达到超越YOLO单阶段的检测准确性,是服务端部署的首选
YOLO系列
YOLO是单阶段目标检测方法的代表,在通用推理、消费级显卡上能轻松达到1秒200张左右图片的推理速度(200FPS),适合对于实时性要求较高的目标检测场景,比如视频的目标跟踪、监控,以及端侧的推理部署环境,比如嵌入式设备。YOLO(You Only Look Once)自2016年诞生以来,始终围绕速度与精度的平衡、工业场景落地适配为核心进行迭代演进,它放弃了传统两阶段目标检测方法的"锚框->锚框预测->预测结果精调"的复杂流水线,开创了"单次前向传播完成检测"的实时检测范式。
方法出处
2016-YOLO V1-《You Only Look Once: Unfied, Real-Time Object Detection》
2016-YOLO V2-《YOLO9000:Better, Faster, Stronger》
2018-YOLO V3-《YOLOv3: An Incremental Improvement》
2020-YOLO V4-《YOLOv4: Optimal Speed and Accuracy of Object Detection》
YOLO V5-ultralytics推出,框架集成
2022-YOLO V6-《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》
2022-YOLO V7-《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》
2023-YOLO V8-ultralytics推出,框架集成
2024-YOLO V9-《YOLOv9: Learning What You Want to Learn
Using Programmable Gradient Information》
2024-YOLO V10-《YOLOv10: Real-Time End-to-End Object Detection》
2024-YOLO V11-ultralytics推出,框架集成
2025-YOLO V12-《YOLOv12: Attention-Centric Real-Time Object Detectors》
2026-YOLO26-ultralytics推出,框架集成,《YOLO26: KEY ARCHITECTURAL ENHANCEMENTS AND PERFORMANCE BENCHMARKING FOR REAL-TIME OBJECT DETECTION》
方法原理和过程
YOLO V1将图像分为S*S个网格,每个网格直接预测可能包含故障的坐标位置、故障类别、检测置信度
YOLO V2/V3结合了当时的批量归一化、残差连接、多尺度特征融合、多尺度训练、锚框思想等对YOLO V1进行了迭代改进,在保证检测速率的前提上,大幅提升了检测准确性
YOLO V4采用CSPDarknet+SPP空间金字塔池化+PANet路径聚合网络结构,融合CutMix、Mosaic数据增强策略,并结合CIoU损失、标签平滑、Mish激活函数等当时最新提出的技术,大幅提升了模型的检测精度
YOLO V5由ultralistic框架集成,无学术论文,凭借极致的工程化设计,成为了当时工业落地的标准,YOLO V5提供n/s/m/l/x全系列尺寸,适配不同的部署环境,同一网络结构通过更改检测头可解决目标检测、图像分割、关键点检测、分类、旋转框检测多个视觉任务,这些设计思想被ultralistc后续的模型结构所延续
YOLO V6引入重参数化方法轻量化检测模型,然后结合知识蒸馏,利用知识蒸馏对大参数量模型进行蒸馏,提升小模型的精度
YOLO V7重点探讨了不增加模型推理开销、保证梯度传导路径不受影响的情况下,如何进行模型backbone特征提取网络的结构变体设计,提出了ELEN方法
YOLO V8同样由ultralytics框架集成,无锚框设计,利用YOLO V7的设计思想,利用C2f模块融合以往的CSP网络,让整体模型结构梯度流更加丰富,同时加入DFL+CIoU损失,让坐标框的定位更加准确,类似YOLO V5,也具备不同参数量的版本,原生支持多个视觉任务,是目前工业算法落地的主流版本
YOLO V9设计辅助可逆分支,训练时为主分支提供完整、可靠的梯度信息,缓解梯度信息瓶颈问题,推理时辅助分支可完全丢弃,无任何额外推理开销,让轻量级模型也能从深度监督中充分受益
YOLO V10训练时同时使用一对多分支(提供丰富监督信号)和一对一分支(端到端推理),推理时仅保留一对一头,实现无 NMS 的端到端检测,大幅降低端到端推理延迟
YOLO V11同样由ultralytics框架推出和集成
YOLO26是ultralytics最新推出的模型,具有以下特点:
1)网络结构层面,YOLO26的backbone加入了类似YOLO V10的局部通道注意力机制(PCA),增强模型对于局部细节、长距离语义依赖的特征提取
2)采取无锚框设计,特征图每个特征点直接预测对应的目标类别和位置,不依赖锚框参数
3)一对一标签分配:每个真实框只分配给唯一一个最优匹配的预测框,让模型不输出冗余目标框,取消后处理的NMS过程
4)YOLO26完全移除了DFL损失模块,简化边界框的回归计算流程,提升模型对于不同计算设备的部署适配性。
5)利用Progloss在模型训练过程中动态调整不同损失的权重,在训练前期增加分类损失的权重,让模型快速学习对目标的精准分类识别,然后在模型能够较为准确分类目标的前提下,增大目标坐标定位的损失权重,提升模型的目标定位能力,"看的清,之后才能看的准"
6)利用STAL显示考虑小目标的标签分配,以往YOLO模型在标签分配过程中,小目标因为IoU本身数值很低,容易被忽略,得不到充分训练,导致模型对于小目标的检测效果较差,YOLO26在标签分配过程中,对于小目标会动态调整IoU匹配阈值,保证小目标能够得到充分训练,提升了YOLO26对于小目标的检测性能。
7)YOLO26在训练过程中借鉴了Kimi大模型的Moun梯度正交分解的思想,实现模型训练的快速收敛和稳定优化。
8)类似YOLO V5/8/11,YOLO26也具有多个不同参数的版本,适配不同的部署资源环境,统一结构支持多个视觉任务
方法适用性
实时检测、端侧部署资源受限制时的首选目标检测方法
Deformable DETR/RT-DETR/RF-DETR
DETR系列目标检测方法采取编码器-解码器的思想,不再将目标检测看作是预测问题,而是从集合匹配的角度,给出目标框和类别的唯一解码匹配,省去了以往两阶段/单阶段目标检测方法中常用的NMS处理过程。DETR系列方法检测速度慢、小目标识别效果较差。
针对检测速度慢的问题,Deformable DETR借鉴卷积神经网络中的空洞卷积思想,提出了可分离式注意力,可分离式注意力不像传统注意力计算会关注所有token之间的相似性,而是有选择的关注部分token,加速整体计算速度。
对于小目标识别效果较差问题,RT-DETR融合不同尺度的特征图,类似以往目标检测模型中的特征融合网络,保证检测速度的同时,大幅提升了检测精度。
RF-DETR是DETR系列最新的方法,采取DINO V2作为backbone,借助NAS神经网络架构搜索,自动确定在当前计算资源和任务的条件下,最优的模型结构,替代人工设计网络结构的方式,在CoCo数据集多项评测任务中达到了最优,而且借助Transformer的全局语义关系提取,处理遮挡目标识别问题更优。
方法出处
2020-DETR-《End-to-End Object Detection with Transformers》
2021-Deformable DETR-《DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION》
2024-RT-DETR-《DETRs Beat YOLOs on Real-time Object Detection》
2026-RF-DETR-《RF-DETR: NEURAL ARCHITECTURE SEARCH FOR REAL-TIME DETECTION TRANSFORMERS》
方法原理和过程
DETR系列方法首先会利用Transformer架构的特征提取模型,比如ViT、DINO等,这类模型会将图片切分为一个个的patch,每个patch生成对应的语义token,然后利用注意力机制捕获不同torken之间的关系,生成具有元素语义关系的特征表示,相比于以往的卷积神经网络,这种特征提取方式对于细粒度、长距离关系依赖的故障识别更加准确。对于提取到的特征表示,利用Decoder模型,从特征表示中解码出具体的故障目标类别和位置信息,解码过程根据是否需要外部输入Object query,也分为两阶段和单阶段。单阶段解码需要预先训练Object query,在推理过程中输入这些预训练完毕的Object query,Object query是一种目标查询信号,不同的Object query负责在特征表示中搜索不同维度的目标信息,然后Decoder根据这些搜集到的目标信息进行目标检测结果解码输出。两阶段解码不需要输入Object query,而是先通过一个selecter组件,从特征表示中筛选出最重要的特征表示,然后只根据这些筛选出来的特征表示进行目标检测结果解码。
为保证模型的预测和真实标签之间可以进行一对一匹配,采用匈牙利匹配算法,去寻找最优的匹配关系,然后根据这些匹配关系,采取以往目标检测模型训练常使用的交叉熵损失、L1损失等,对整体网络进行训练。
方法适用性
检出率要求大于误报率要求的业务场景,也就是宁可误报,但是不允许漏报的场景,DETR系列方法凭借Transformer架构的全局语义关系建模,目标识别非常灵敏,举例来说,可能以往的模型需要根据完整的A特征才能给出判定,但是DETR系列模型可能只需要1/3的A特征就会给出判定。
2.1.2 图像分割
图像分割整体可以分为自底向上和自顶向下方法,自底向上方法先对图像进行特征提取,然后进行逐像素的类别分类,代表方法是FCN、U-Net。自顶向上方法首先判断图像中哪里存在物体,然后再对这个物体区域进行逐像素的分类,代表方法是Mask R-CNN。如果分类的类别只是"有"或者"没有"物体,这种分割称为语义分割,如果分类的类别是具体的目标类别,那么这种分割称为实例分割,近几年随着自动驾驶技术的发展,还出现了全景分割,全景分割会给出图像中所有物体所在的区域,即使天空、土地这种背景也会参与分割过程。以往的图像分割方法注重结构的优化调整、损失函数的设计等方面,随着2023年SAM模型的出现,证明了大规模数据预训练+prompt对齐的分割训练方法,可以让模型获得通用的分割能力,即使这些物体没在训练数据集中出现过,SAM系列也成为了近几年分割模型的代表。
方法出处
2015-FCN-《Fully Convolutional Networks for Semantic Segmentation》
2015-U-Net-《U-Net: Convolutional Networks for BiomedicalImage Segmentation》
2017-Mask R-CNN-《Mask R-CNN》
2018-DeepLab V1-《SEMANTICIMAGESEGMENTATION WITHDEEPCON-VOLUTIONALNETS ANDFULLYCONNECTEDCRFS》
2018-DeepLab V2-《DeepLab: Semantic Image Segmentation withDeep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs》
2019-DeepLab V3-《Rethinking Atrous Convolution for Semantic Image Segmentation》
2019-DeepLab V4-《Encoder-Decoder with Atrous SeparableConvolution for Semantic Image Segmentation》
2023-《Segment Anything》
方法原理和过程
不同分割方法首先都会利用特征提取网络对输入图像进行特征提取,然后自底向上方法会通过上采样方法,将特征图恢复到原图尺寸大小,生成不同类别的分割热力图,自顶向下方法根据特征提取网络输出的特征图先进行目标的预测,然后再对目标区域进行逐像素的分类。
SAM整体结构如下:
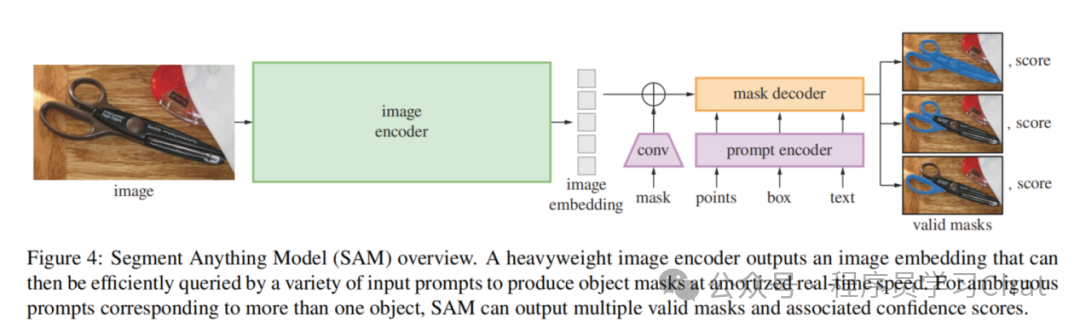
输入是<待分割的图片,人工Prompt>,人工Prompt用于辅助分割任务,具体分为两种类型:
1.稀疏提示:用户输入点、框、文本,比如用户在图片上点击一个点、框起一个矩形区域、或者输入一段文本,如"天空"、"图片中穿红色衣服的人"
2.密集提示:用户输入一个分割掩码mask矩阵
SAM最终会将这些人工Prompt统一转换为256维的向量,作为一种分割任务先验信息提示,辅助分割任务的处理。
SAM整体流程如下:
1.利用图像编码器(image encoder)获取输入图像的特征编码表示
2.利用提示编码器(prompt encoder)对输入的稀疏提示进行特征编码
3.如果用户输入了密集提示,利用卷积层对用户输入的分割掩码mask矩阵进行特征编码
4.将图像特征编码表示(image embedding)、稀疏提示特征编码和密集提示特征编码(prompt embedding)、一个用于最终分割解码输出的output token输入到分割掩码解码器(mask decoder)中,获取输入图像的分割掩码mask
方法适用性
对推理速度要求不严格,或者设计精密测量的故障检测场景,对于柔性或者不规则性物体检测效果较好。
2.1.3 关键点检测
关键点检测同样分为自底向上与自顶向下两类方法,自底向上方法根据特征提取结果,输出关键点的所在热力图,自顶向下方法先确定图像中的目标区域,然后直接输出目标区域的关键点坐标。关键点检测适合不规则/柔性物体的量化指标计算,比如锁链下摆的角度等。
方法出处
2014-DeepPose:Human Pose Estimation via Deep Neural Networks
2017-OpenPose-Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
2019-FCOS:Fully Convolutional One-Stage Object Detection
2023-RTMPose:Real-Time Multi-Person Pose Estimation based on MMPose
方法原理和过程
当前主流的关键点检测技术可分为三大技术路线,各方案在定位精度、推理速度、部署难度与场景适配性上形成互补,覆盖了不同工业与科研场景的需求。
- 基于热图(Heatmap)的关键点检测方法
该方法是高精度关键点检测的经典主流范式,核心原理是通过模型预测每个关键点对应的二维高斯热图,热图中每个像素的响应值代表该位置为目标关键点的概率,最终通过热图峰值检索完成关键点坐标定位。其核心实现逻辑为:训练阶段,为每个标注的关键点生成以标注坐标为中心的二维高斯分布热图作为监督标签,模型通过卷积神经网络提取目标的多尺度视觉特征,回归得到与标签维度一致的预测热图;通过均方误差(MSE)、Dice 损失等函数约束预测热图与真实高斯热图的分布差异,让模型学习关键点的视觉特征与空间分布规律。推理阶段,对模型输出的热图进行峰值检索,取热图中响应值最高的坐标作为关键点的粗定位结果,再通过热图偏移修正、二次曲线拟合、亚像素插值等方式进一步提升定位精度。该方法的核心特点是定位精度高、对目标遮挡与局部形变的鲁棒性强,是工业高精度视觉测量、人体姿态估计等场景的主流方案;其局限性在于存在固有量化误差,推理阶段需要额外的后处理步骤,高分辨率热图会带来一定的计算开销。
- 基于直接回归的关键点检测方法
该方法摒弃了热图的中间表示,将关键点检测转化为坐标回归任务,通过神经网络直接预测关键点在图像中的归一化坐标或像素级绝对坐标,实现端到端的点位预测。其核心实现逻辑为:以目标检测框或图像全局特征为基准,通过骨干网络提取目标的深度视觉特征,再通过全连接层或卷积检测头直接回归每个关键点的横纵坐标偏移量与绝对坐标;训练阶段采用 Smooth L1 损失、Wing Loss、KIoU 损失等对小误差更敏感的损失函数,约束预测坐标与标注坐标的偏差,让模型学习关键点与目标视觉特征、结构约束的映射关系。推理阶段无需复杂后处理,模型单次前向传播后直接输出关键点的最终坐标,可通过偏移量解码实现亚像素级定位。该方法的核心特点是推理速度快、部署流程简洁、端到端训练难度低,适合实时性要求高的工业在线检测场景;传统回归方法对小目标、遮挡目标的定位精度略低于热图法,近年来通过引入目标结构先验、多尺度特征融合技术,二者的精度差距已大幅缩小。
方法适用性
关键点检测核心目标是自动定位图像中具有明确语义信息、结构约束或任务价值的空间坐标点,广泛应用于工业视觉质检(工件基准孔位定位、缺陷特征点提取、装配精度检测)、目标姿态估计、视觉精密测量等场景。该任务通过建模目标的结构先验与视觉特征,实现对关键点位的亚像素级精准定位,为后续的尺寸测量、缺陷判定提供核心空间基准。
2.2 少量异常数据
2.2.1 生成方法
当异常数据量较少,且异常形态固定时,可使用生成方法生成异常数据辅助模型训练。生成模型从早期的GAN网络结构,到常用的扩散模型,再到目前以Transformer结构为主的生成模型,目前具有代表性的模型是国内字节Seeddance和阿里最新推出的Happyhorse。值得一提的是,异常检测领域中除了使用生成方法生成异常数据进行辅助训练之外,也有利用生成模型进行样本重构,如果重构误差较大,也就是没有办法从输入的待检测图片中重构出正常样本,则认为待检测图片是异常样本,这种方法推理较耗时,线上资源受限的工业场景中部署较困难。
2.2.2 Few-shot训练
Few-shot指的是有少量异常数据可供模型学习、训练,因为数据量比较小,要训练的网络结构大多只是简单的MLP(前馈神经网络),如果要训练的网络结构过于复杂,因为少量数据无法给出充足的监督信号,训练结果反倒会变差。MLP在这类方法中其实起到"适配器"的角色,基础特征提取网络一般采用大规模预训练模型,如ViT、CLIP、DINO等,利用基础特征提取网络在大规模预训练数据上获取到的通用识别能力,对待检测图片进行特征提取,这些特征是面向通用领域的,需要借助MLP对这些特征进行变换,转换到当前的异常检测任务空间中。综上,Few-shot训练方法一般采取的是:"通用大规模预训练模型特征提取+轻量MLP可训练特征变换网络"的技术路线。
异常检测任务中常使用的通用大规模预训练模型是CLIP,传统判别式模型是从特征映射的角度处理识别问题,也就是"特征->识别结果",而CLIP是从语义相似性的角度来处理识别问题,也就是"(特征,识别结果)->最相似的是正确结果"。举例来说,输入一张"猫"的图片,传统判别式模型会对图片进行特征提取,根据提取到的特征进行判断,说"我认为这张图片90%是猫",而CLIP会分别对图片、所有类别"猫"、"狗"......,都进行特征提取,然后判断每个<图片特征,类别特征>相似度是多少,选相似度最大的作为当前图片的类别。CLIP的Zero-Shot能力就体现在如果'所有类别'哪天突然变了,传统判别式模型需要重新构建数据集->进行训练......,但是CLIP只需要对新类别进行一次特征提取就可以,然后还是通过相似度比对就可以进行判断识别,CLIP整体结构如下:
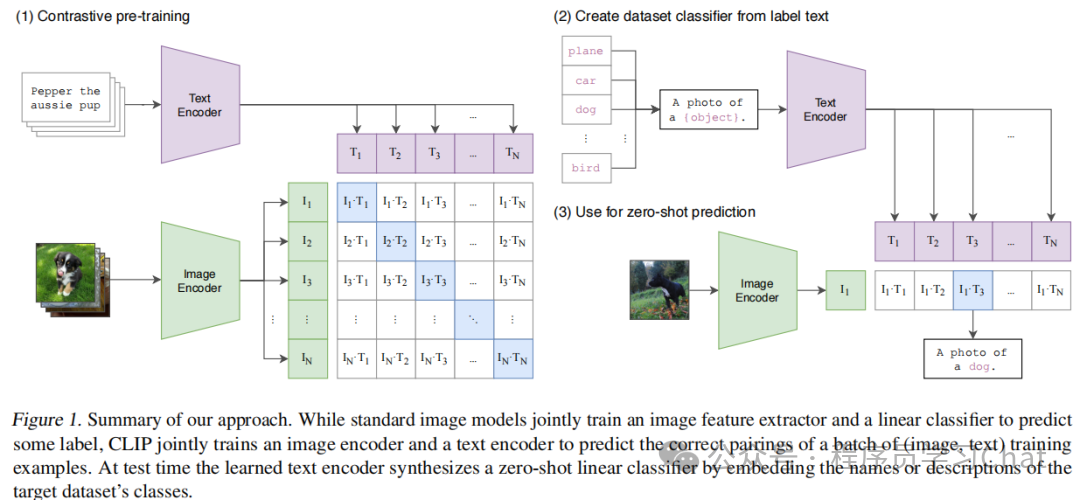
左侧是CLIP的训练过程,CLIP包含两个关键组件Image Encoder(图像编码器)、Text Encoder(文本编码器),最后就是通过数据集训练这两个编码器,让它们提取到的特征具有语义相似性,也就是图像编码器对'猫图片'的特征编码输出和文本编码器对文本"猫"的特征编码输出具有最大的相似性。右侧是CLIP的推理过程,输入一张待进行识别的图片,利用训练完毕的图像编码器对其进行特征提取,利用文本编码器对所有类别标签文本进行特征提取,然后判断图像特征和类别标签文本特征的相似性,具有最大相似性的就是图像对应的类别。
CLIP训练时的输入是多个<图像,图像文本描述>对,比如<猫的图片,"A photo of a cat">,利用图像编码器对输入图像进行特征提取,论文中尝试了ResNet和ViT作为图像编码器,利用文本编码器对于图像文本描述进行特征提取,论文中尝试了类似BERT结构的文本编码器,对于图像编码器和文本编码器提取到的特征,利用对比学习最大化正确匹配<图像,图像文本描述>相关特征的余弦相似度,最小化错误匹配<图像,图像文本描述>相关特征的余弦相似度,强迫模型学习出图像特征和文本特征之间的语义相关性。
MRAD-TF/MRAD-FT/MRAD-CLIP
方法出处:
2026-《MRAD:ZERO-SHOTANOMALYDETECTIONWITHMEMORY-DRIVENRETRIEVAL》
整体架构如下:





AnomalyCLIP
方法出处:2026-《ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARN-ING FOR ZERO-SHOT ANOMALY DETECTION》
AnomalyCLIP的核心思路是学习对象无关的文本提示,让模型聚焦通用正常/异常故障模式而非具体的物体语义,同时优化CLIP的局部视觉特征建模能力,实现跨域零样本异常检测。模型基于预训练CLIP(ViT-L/14@336px)构建,冻结CLIP全部原始参数,仅训练新增的少量可学习提示参数,整体结构如下:


AdaptCLIP
方法出处:2026-《AdaptCLIP: Adapting CLIP for Universal Visual Anomaly Detection》
AdaptCLIP的核心设计理念是"更少、更简单的模块更好",基于预训练CLIP模型,仅在其输入/输出端添加三个轻量级适配器,完全冻结CLIP原生参数,保留其原有跨模态能力。




VisualAD
方法出处:2026-《VisualAD: Language-Free Zero-Shot Anomaly Detection via Vision Transformer》
VisualAD是纯视觉CLIP零样本异常检测框架,完全移除CLIP文本分支,核心思路是在冻结的预训练ViT中插入可学习的正常/异常Token,通过多层交互学习异常语义,配合空间增强和特征校准模块实现精准定位,模型结构如下:



三 无监督方法
3.1 特征库查询
特征库查询方法是异常检测领域从早期一直延续至今的思想,因为异常检测领域正常样本远大于异常样本,所以可以使用特征提取网络基于大量的正常样本预先建立一个正常特征特征库,对于待检测的样本,用同样的特征提取网络进行特征提取,将提取到的特征送入特征库中进行特征对比,如果对比结果大于预先设定的阈值,则认为图像具有异常,这类方法的代表是PaDiM、SPADE、和PatchCore。
方法出处:
2020-《PaDiM: a Patch Distribution Modeling Frameworkfor Anomaly Detection and Localization》
2021-《Sub-Image Anomaly Detection with DeepPyramid Correspondences》
2022-《Towards Total Recall in Industrial Anomaly Detection》
PaDiM、SPADE直接使用逐像素特征构建记忆库,缺乏邻域上下文信息,对微小的空间偏差极其敏感,归纳偏置能力弱。PatchCore旨在构建一个最具代表性的正常样本块特征记忆库,在保留最大正常上下文的同时,通过核心集下采样实现极低的推理延迟。



3.2 Zero-shot
异常检测中的Zero-shot方法,一般是借助CLIP在大规模预训练数据集上获取到的通用识别能力直接进行异常检测,不重新训练CLIP,而是研究如何充分利用CLIP输出的特征提取信息,实现即使无法获取到异常数据,也能进行异常检测。
WinCLIP
方法出处:2023-《WinCLIP:Zero-/Few-Shot Anomaly Classification and Segmentation》
WinCLIP发现直接使用预训练的CLIP模型进行零样本分类效果较差,• 对于基于ViT的CLIP,其patch级别的特征图并未直接受语言信号的监督,导致与语言空间不对齐,直接用于密集预测(分割)效果很差;此外,这些patch特征因自注意力机制已聚合了全局上下文,阻碍了对局部细节的捕捉。为了改善CLIP的零样本分类,WinCLIP设计了多层次的多维提示词组合(包含状态级、裁剪方式、光照条件、任务描述等,如"a cropped photo of a state c"),通过集成这些提示的特征,丰富了文本端的语义表达,克服了单一提示的局限性。

FADE
方法出处:2024-《FADE:Few-shot/zero-shot AnomalyDetection Engine using LargeVision-Language Model》
CLIP模型在预训练时使用的是图像级别的对比损失(CLS token与文本对齐),导致其局部Patch嵌入与文本嵌入对齐较差,直接用于像素级异常分割(AS)效果极差,甚至出现前景/背景可视化反转的现象。现有Zero-shot方法多采用人工构建的提示词,难以全面覆盖工业场景中复杂多样的异常描述。FADE的核心思想是免训练地利用预训练CLIP模型,通过语言引导和视觉引导两条路径,分别解决0-shot和k-shot下的AC与AS任务。模型由四个互补的流水线组成:



UniVAD
方法出处:2025-《UniVAD: A Training-free Unified Model for Few-shot Visual Anomaly Detection》
现有的异常检测方法通常针对特定领域设计专门的检测算法和架构。例如,工业领域的SOTA方法PatchCore在MVTec-AD数据集上1-shot AUC达到84.1%,但应用到逻辑异常检测数据集MVTec LOCO时,性能暴跌至62.0%。传统异常检测方法即使在同一领域内,也往往需要为每个物体类别单独训练一个模型,一旦训练完成,模型仅限于该特定类别,极大地限制了研究的标准化和可扩展性。UniVAD的核心在于免训练与多语义层级检测,其整体架构由三大模块组成:上下文组件聚类、组件感知块匹配和图增强组件建模:




3.3 多模态信息引导
随着近几年多模态模型的发展,其本身的基模能力已经能够识别出一些常见的异常类别,比如裂纹、破损等。对于多模态基模进行微调不是多模态信息引导方法首选的思路,因为数据量不充足时很容易出现灾难性遗忘的问题,多模态模型对于新的故障数据没学好,以往学习到的知识也忘记了。多模态信息引导方法使用的重点应该是利用它具备语义对齐能力的特征输出,以及文本信息提示引导的异常检测。
Anomaly-OV
传统Zero-shot异常检测方法仅能输出异常概率分数,无法提供异常位置、类型、成因、改进建议等可解释信息,无法满足工业、医疗等场景对可信度的要求。GPT-4o等通用MLLM虽具备强大推理能力,但对图像中细粒度异常特征不敏感,漏检率高,且缺乏针对异常检测的专业指令数据集与评测基准,无法适配专科场景需求。Anomaly-OneVision(Anomaly-OV),是首个面向零样本异常检测与推理的专科视觉助手,基于LLaVA-OneVision构建,采用「异常专家+通用MLLM」的双阶段训练框架。


通用多模态大模型
BLIP
BLIP原论文:《BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation》
基于多任务学习构建了一个兼顾图像理解与生成的多模态模型BLIP,具体结构如下:
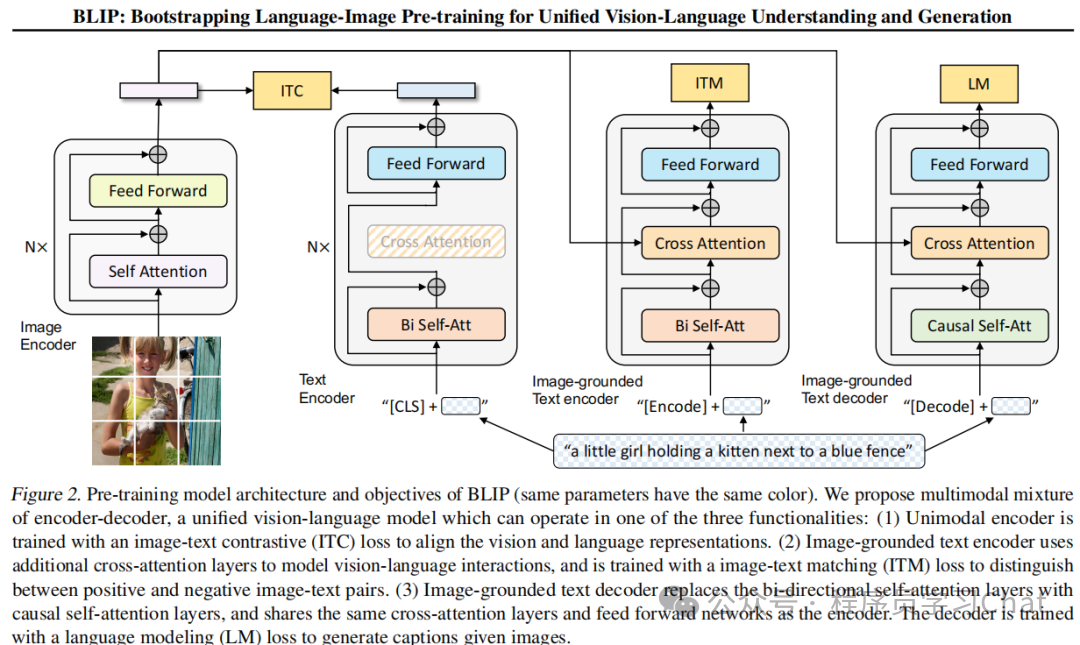
整体包含四部分:
1)图像编码器:上图中最左侧部分,论文中使用的是ViT模型,负责对输入的图像进行特征编码
2)ITC(Image-Text Contrastive)任务:,图像编码表示、文本编码表示对比学习组件,利用类似CLIP的对比学习方法,构建全局粒度的图像特征、文本特征语义对齐
3)ITM(Image-Text Matching)任务:,判断图像编码表示、文本编码表示是否匹配,二分类任务,构建局部细粒度的图像特征、文本特征语义对齐
4)LM(Language Modeling)任务:,文本生成组件,负责根据输入的图像编码表示、文本编码表示,生成输入图像对应的文本描述
LLaVA
LLaVA原论文:
1.《Visual Instruction Tuning》
2.《Improved Baselines with Visual Instruction Tuning》
LLaVA采用了类似BLIP2的适配器思想,不从头训练图像编码器和文本编码器,只训练适配器,但是LLaVA的适配器组件不像BLIP2的Q-Former那样复杂,只是一个简单的线性投影层。

图像编码器使用的是CLIP,对于输入的<图像,文本描述>,利用CLIP对图像进行特征编码表示,然后利用一个线性投影层将图像特征编码表示的维度转换为文本描述编码表示的维度大小,图像特征编码表示+文本描述编码表示输入到一个语言大模型(LLM)中得到具体生成文本解码,LLaVA使用的语言大模型是Vicuna,因为当时Vicuna是公开数据集、开源模型上指令遵循能力最好的模型,最后根据语言大模型的文本内容解码损失,反向梯度传播进行训练。
Grounding DINO
传统目标检测输入待检测的图片,模型输出图片中物体所在位置的矩形框和置信度,这种模型依赖训练数据集,对于训练数据集中不包含的物体,要么检测不出来,要么给出低置信度的其它物体类别标签。多模态领域中的"Grounding"指的是模型能够检测任意用户输入文本中包含的物体,也就是输入是待检测图片+用户的检测要求,比如输入一张图片+用户的问题"图片中穿红色衣服的人在哪里",多模态模型应该给出穿红色衣服人的坐标回答,将传统的目标检测流程变为了一个问答流程,多模态模型的Grounding能力是一项重要的评测指标,体现了模型的语义+空间理解能力,可以理解为是"开放集合目标检测(Open-Set Object Detection)",不像传统目标检测模型一样只认识训练数据集中已标记过的类别,借助多模态能力,可以检测查询文本中要求检测的任意物体类别。
Grounding DINO整体结构如下:
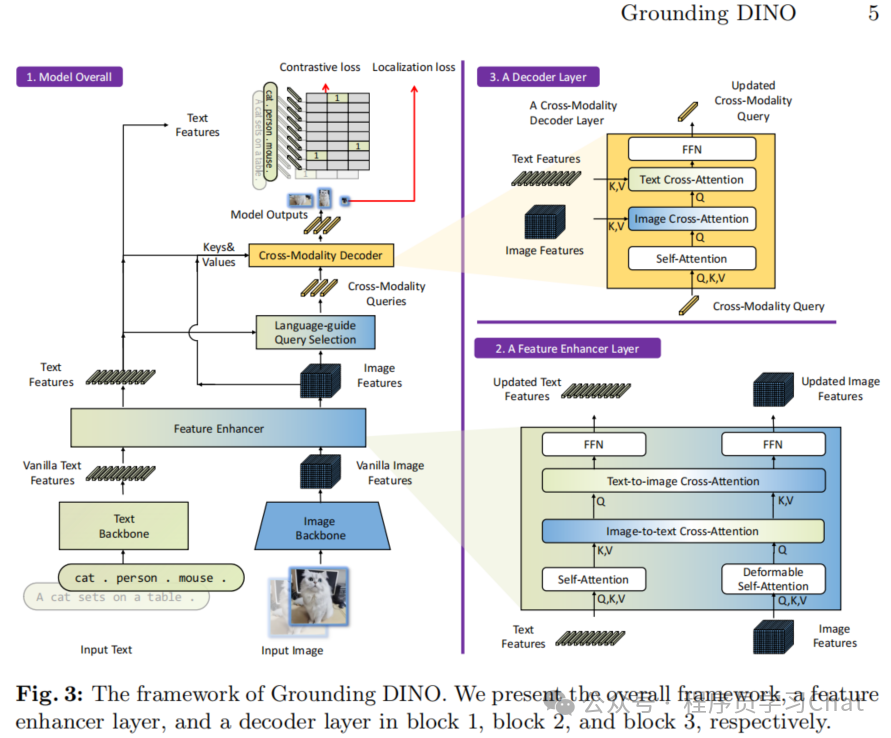
分为4个部分
1.特征提取:分别利用图像编码器、文本编码器,提取输入<图像,文本>的特征
2.特征增强:基于交叉注意力(Cross-Attention)对齐图像编码表示和文本编码表示的语义信息
3.特征查询:根据文本编码表示从图像编码表示中筛选出和当前输入文本最相关的特征信息
4.多模态解码生成:在图像编码表示和文本编码表示的引导下,解码出当前输入对应的输出(物体所在位置坐标、类别)
YOLO World
YOLO World类似Grounding DINO,也是解决开放集合目标检测的问题,但是使用的图像编码器是YOLO(具体是YOLO V8),相比于以往的开放集合目标检测模型更轻量,推理部署阶段可进一步配合重参数化的技巧提升推理速度,使YOLO World接近于原始YOLO的速度,消费级显卡上可达70+ FPS。
YOLO World整体结构如下:
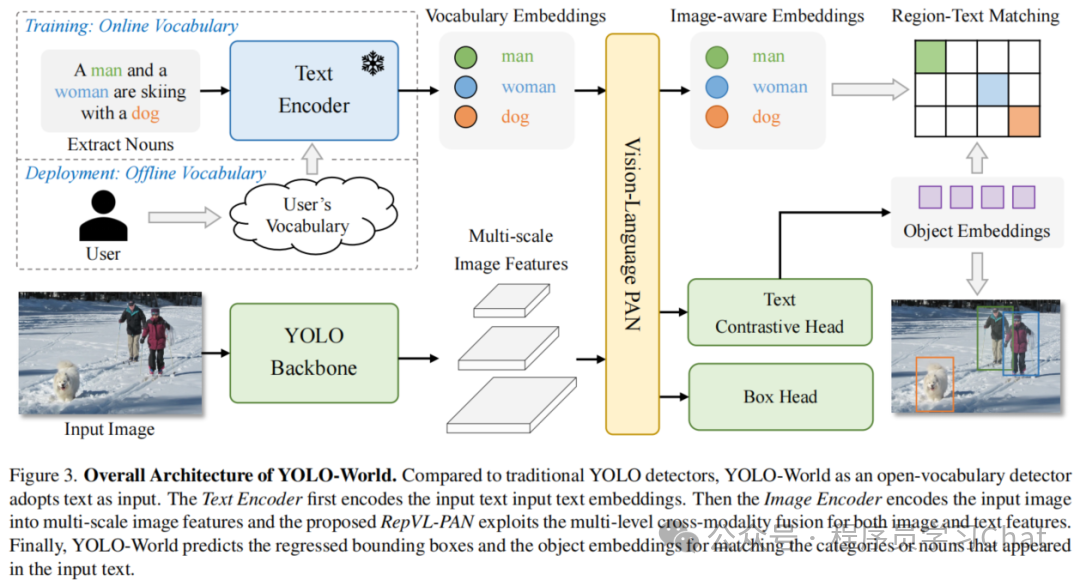
输入依旧是<图像,文本>,但是相比于Grounding DINO,YOLO World输入的文本是类别名称列表,而Grounding DINO是任意格式的文本。
YOLO-World 更适合"我知道要检测什么,只是模型没学过"的场景,而Grounding DINO 更适合"我用语言描述我想找的东西"的场景。
将图片输入到YOLO的Backbone中进行图像特征提取,将类别文本输入到Text Encoder中进行文本编码特征提取(论文中使用的Text Encoder是CLIP),利用Vision-Language PAN进行图像特征、文本编码特征的语义对齐,将语义对齐后的特征输入到Text Contrastive Head、Box Head中得到预测类别和矩形框坐标输出,和真实标签计算损失反向梯度传播训练整个YOLO World。
Qwen-VL
Qwen-VL原论文:《Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond》
Qwen-VL采取的也是类似BLIP2的适配器方法,在图像编码器和语言大模型(LLM)之间插入一个适配器,对齐图像特征、文本特征的语义,但是Qwen-VL在自己的训练数据集上分阶段的重新训练了图像编码器和语言大模型,而BLIP2只训练适配器Q-Former。以往的VL模型一般都是面向英文的,Qwen-VL支持中英双语,中文友好,而且除了支持图像理解、问答任务外,还支持Grounding任务(多模态模型的Grounding任务介绍可以看:)、OCR文本提取,在多个公开评测数据集上,达到了当时最优的开源模型效果。
模型结构如下:

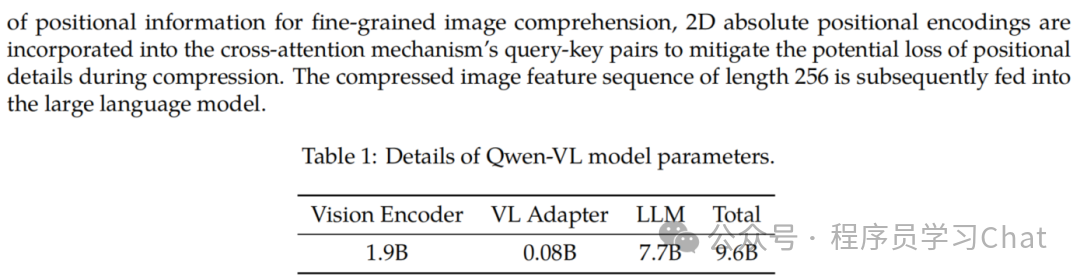
整体由以下三个组件构成:
1)图像编码器:Vision Encoder,论文中使用的是ViT结构,ViT的详细介绍可以看:
2)视觉-语言特征适配器:VL Adapter,cross attention层,负责从图像编码器输出结果中提取和文本最相关的视觉特征,将视觉特征转换为语言大模型可以理解的特征(语义对齐)
3)语言大模型:LLM,论文中使用的是Qwen 7B
Qwen2-VL
Qwen2-VL原论文:《Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution》
Qwen2-VL是Qwen-VL的拓展延续,进行了以下改进:
1)动态分辨率:Qwen-VL只支持固定大小的图像输入,Qwen2-VL支持任意大小的图像输入
2)更全面的模态:Qwen-VL主要输入是图文,Qwen2-VL支持处理视频
3)更丰富的数据集:增加视频、Agent调用等多种类型的数据,形成1.4T token的高质量训练集
4)多语言支持:Qwen-VL主要支持中英文,Qwen2-VL拓宽了语言范围,支持日语、韩语、法语、德语、意大利语、俄语、越南语、阿拉伯语等
5)多视觉任务支持:除了支持Qwen-VL的图像理解、问答、Grounding、OCR,还支持视觉Agent、视频理解等任务

Qwen2-VL全面探索了视觉语言大模型的Scaling law,针对不同使用场景发布了不同参数规模的Qwen2-VL版本,包括具有最优效率适合边缘部署的Qwen2-VL-2B、平衡性能和效率的Qwen2-VL-8B、最全面综合能力的Qwen2-VL-72B
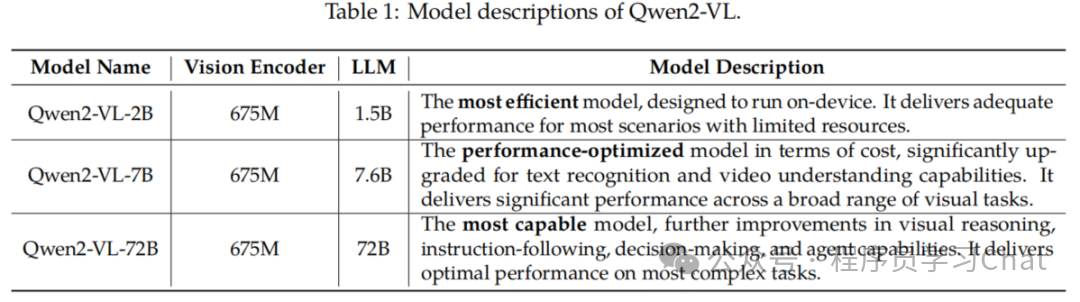
Qwen2-VL要解决的关键问题是突破Qwen-VL的固定图像输入尺度限制,实现对任意尺寸图像和视频的理解,整体类似Qwen-VL的思路,视觉编码器提取视觉特征,视觉特征融合到语言大模型的token序列中,由语言大模型根据这些序列进行视觉理解与信息生成,但是Qwen2-VL移除了Qwen-VL的adapter组件,只由视觉编码器(Vision Encoder)+语言大模型(LLM,Qwen2-VL使用的语言大模型是Qwen2)组成。
Qwen2.5-VL
Qwen2.5-VL原论文:《Qwen2.5-VL Technical Report》
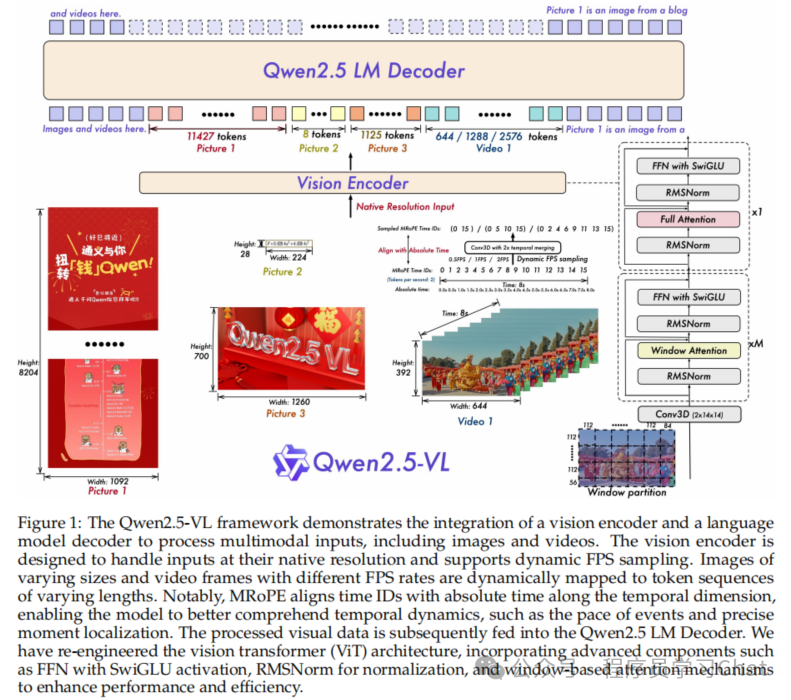
Qwen2.5-VL整体由以下三部分组成:
1)Large Language Model:语言大模型(LLM),使用的是Qwen2.5语言大模型,最大支持32K上下文长度
2)Vision Encoder:图像编码器,负责提取输入图像、视频的特征编码表示,利用2D-RoPE支持任意尺度的输入大小,利用Window Attention加速注意力计算
3)MLP-based Vision-Language Merger:一个两层的MLP,负责将视觉编码器输出的长序列视觉特征编码表示压缩,投影到 LLM 的嵌入空间中,进行多模态语义对齐。Vision-Language Merger会对相邻的2x2 patch 视觉特征编码表示进行聚合和投影,减少模型整体的计算成本,使Qwen2.5-VL能够灵活处理不同长度的视觉序列特征
Qwen3-VL
Qwen3-VL原论文:《Qwen3-VL Technical Report》
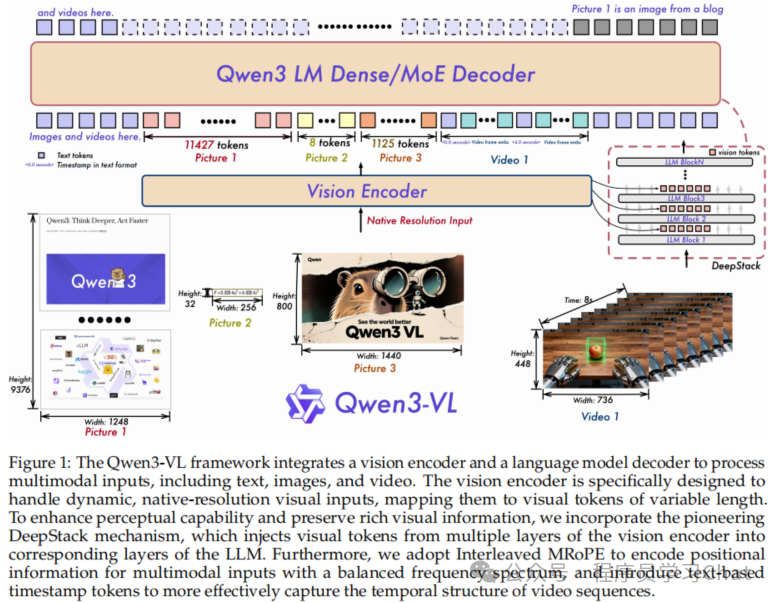
整体还是类似Qwen2.5-VL,有三个部件组成:
1)Large Language Model:语言大模型(LLM),使用的是Qwen3系列的语言大模型,包括稠密版本和MoE稀疏激活版本
2)Vision Encoder:不再使用ViT作为基础图像编码器,而是使用SigLIP-2,同样使用2D-RoPE编码处理多尺度图像尺寸大小的输入,M-RoPE编码同样进行了改进
3)MLP-based Vision-Language Merger:还是类似Qwen2.5-VL中的MLP压缩序列结构