PyTorch强化学习实战------构建生成对抗网络生成Atari游戏画面
-
- [0. 前言](#0. 前言)
- [1. 生成对抗网络简介](#1. 生成对抗网络简介)
- [2. 实现生成对抗网络](#2. 实现生成对抗网络)
- 相关链接
0. 前言
我们已经学习了PyTorch 训练神经网络的核心功能。在本节中,将通过一个实战示例综合演示所有概念,通过构建生成对抗网络 (Generative Adversarial Network, GAN) 模型来展示 PyTorch 的应用,训练一个能生成各种 Atari 游戏画面的 GAN 模型。
1. 生成对抗网络简介
最简单的生成对抗网络 (Generative Adversarial Network, GAN)架构包含两个神经网络:一个生成器,一个判别器。两个网络相互博弈,生成器试图生成伪造数据,而判别器则试图检测生成数据与真实数据的差异。随着训练的推进,两个网络的能力同步提高------生成器生成越来越逼真的数据样本,而判别器则学会更复杂的方式来区分伪造数据。
GAN 能够应用于提升图像质量、生成逼真图像以及特征学习等,虽然在本节中的实用价值有限,但它能全面应用所介绍的 PyTorch 技能。
2. 实现生成对抗网络
(1) 定义封装 Gym 游戏的包装类:
python
class InputWrapper(gym.ObservationWrapper):
def __init__(self, *args):
super(InputWrapper, self).__init__(*args)
old_space = self.observation_space
assert isinstance(old_space, spaces.Box)
self.observation_space = spaces.Box(
self.observation(old_space.low), self.observation(old_space.high),
dtype=np.float32
)
def observation(self, observation: gym.core.ObsType) -> gym.core.ObsType:
# resize image
new_obs = cv2.resize(
observation, (IMAGE_SIZE, IMAGE_SIZE))
# transform (w, h, c) -> (c, w, h)
new_obs = np.moveaxis(new_obs, 2, 0)
return new_obs.astype(np.float32)以上封装类主要实现了以下图像预处理流程:
- 尺寸转换:将
210×160的标准Atari分辨率调整为64×64方形尺寸 - 通道重排:按照
PyTorch卷积层输入规范,将图像色彩通道维度从末位移至首位(形成通道×高度×宽度的张量结构) - 类型转换:将字节型图像数据转为浮点型
然后,定义两个 nn.Module 类:判别器 (Discriminator) 和生成器 (Generator)。判别器以经过缩放的彩色图像作为输入,通过五层卷积,最后通过 Sigmoid 非线性函数输出单个数值。Sigmoid 的输出被解释为判别器认为输入图像来自真实数据集的概率。
生成器则以随机数向量(潜向量)为输入,使用"转置卷积"操作(也称为反卷积),将该向量转换为原始分辨率的彩色图像。
我们将使用多个随机智能体同时进行 Atari 游戏时产生的屏幕截图作为输入数据。下图展示了输入数据的示例。
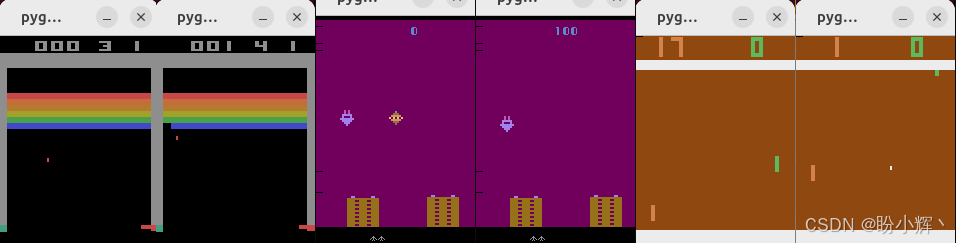
(2) 图像按批次合并:
python
def iterate_batches(envs: tt.List[gym.Env],
batch_size: int = BATCH_SIZE) -> tt.Generator[torch.Tensor, None, None]:
batch = [e.reset()[0] for e in envs]
env_gen = iter(lambda: random.choice(envs), None)
while True:
e = next(env_gen)
action = e.action_space.sample()
obs, reward, is_done, is_trunc, _ = e.step(action)
if np.mean(obs) > 0.01:
batch.append(obs)
if len(batch) == batch_size:
batch_np = np.array(batch, dtype=np.float32)
# Normalising input to [-1..1] and convert to tensor
yield torch.tensor(batch_np * 2.0 / 255.0 - 1.0)
batch.clear()
if is_done or is_trunc:
e.reset()该函数会持续从给定的游戏列表中采样环境状态,执行随机动作,并将观测到的图像存入批次列表。当批次数据达到指定大小时,我们对图像进行归一化处理,转换为张量格式,然后通过生成器返回结果。其中对观测数据非零均值的检查,是为了修复游戏中存在的图像闪烁。
(3) 定义主函数,准备模型并运行训练循环:
python
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--dev", default="cpu", help="Device name, default=cpu")
args = parser.parse_args()
device = torch.device(args.dev)
envs = [
InputWrapper(gym.make(name))
for name in ('Breakout-v4', 'AirRaid-v4', 'Pong-v4')
]
shape = envs[0].observation_space.shape处理命令行参数(可能只有一个可选参数 --dev,用于指定计算设备),并创建带有包装器的环境池。该环境数组后续将传递给 iterate_batches 函数以生成训练数据。
(4) 接下来,创建记录器、两个神经网络、损失函数以及两个优化器:
python
net_discr = Discriminator(input_shape=shape).to(device)
net_gener = Generator(output_shape=shape).to(device)
objective = nn.BCELoss()
gen_optimizer = optim.Adam(params=net_gener.parameters(), lr=LEARNING_RATE,
betas=(0.5, 0.999))
dis_optimizer = optim.Adam(params=net_discr.parameters(), lr=LEARNING_RATE,
betas=(0.5, 0.999))
writer = SummaryWriter()我们需要两个优化器,这是因为 GAN 的训练机制:为了训练判别器,我们需要向它展示真实和伪造的数据样本,并使用合适的标签(真实为 1,伪造为 0)。在这一步中,只更新判别器的参数。
然后,我们再次将真实和伪造样本传递给判别器,但此时所有样本标签均为 1,且仅更新生成器权重。这一过程教会生成器如何"欺骗"判别器,使其难以区分真实与生成样本。
(5) 接着,我们定义了用于累计损失值、迭代计数器的数组,以及存储真假标签的变量。同时记录当前时间戳,用于每完成 100 次训练迭代后记录耗时:
python
gen_losses = []
dis_losses = []
iter_no = 0
true_labels_v = torch.ones(BATCH_SIZE, device=device)
fake_labels_v = torch.zeros(BATCH_SIZE, device=device)
ts_start = time.time()(6) 在训练循环开始时,生成一个随机向量并将其输入生成器网络:
python
for batch_v in iterate_batches(envs):
# fake samples, input is 4D: batch, filters, x, y
gen_input_v = torch.FloatTensor(BATCH_SIZE, LATENT_VECTOR_SIZE, 1, 1)
gen_input_v.normal_(0, 1)
gen_input_v = gen_input_v.to(device)
batch_v = batch_v.to(device)
gen_output_v = net_gener(gen_input_v)(7) 然后,我们分两次训练判别器,一次使用批次中的真实数据样本,另一次使用生成器生成的样本:
python
dis_optimizer.zero_grad()
dis_output_true_v = net_discr(batch_v)
dis_output_fake_v = net_discr(gen_output_v.detach())
dis_loss = objective(dis_output_true_v, true_labels_v) + \
objective(dis_output_fake_v, fake_labels_v)
dis_loss.backward()
dis_optimizer.step()
dis_losses.append(dis_loss.item())在以上代码中,我们需要对生成器的输出调用 detach() 方法,以防止本次训练的梯度流向生成器( detach() 是张量的一个方法,它会创建该张量的副本,并且与父操作没有连接,也就是将张量从父图中分离出来)。
(8) 接下来,训练生成器:
python
gen_optimizer.zero_grad()
dis_output_v = net_discr(gen_output_v)
gen_loss_v = objective(dis_output_v, true_labels_v)
gen_loss_v.backward()
gen_optimizer.step()
gen_losses.append(gen_loss_v.item())将生成器的输出再次输入判别器,但这次不再阻断梯度传播。相反,我们使用真实标签应用目标函数,这将推动生成器朝生成能够误导判别器的样本方向优化------让判别器误以为生成样本是真实数据。
(9) 模型训练代码完成后,记录损失值并向 TensorBoard 输送图像样本:
python
iter_no += 1
if iter_no % REPORT_EVERY_ITER == 0:
dt = time.time() - ts_start
print("Iter {} in {:.2f}s: gen_loss={:.3}e, dis_loss={:.3e}".format(
iter_no, dt, np.mean(gen_losses), np.mean(dis_losses)))
ts_start = time.time()
writer.add_scalar("gen_loss", np.mean(gen_losses), iter_no)
writer.add_scalar("dis_loss", np.mean(dis_losses), iter_no)
gen_losses = []
dis_losses = []
if iter_no % SAVE_IMAGE_EVERY_ITER == 0:
img = vutils.make_grid(gen_output_v.data[:64], normalize=True)
writer.add_image("fake", img, iter_no)
img = vutils.make_grid(batch_v.data[:64], normalize=True)
writer.add_image("real", img, iter_no)刚开始时,生成的图像完全是随机噪声,但经过 1 万至 2 万次迭代后,生成器逐渐改进,生成的图像也越来越像真实的游戏截图。训练完成后,生成样本图像如下所示:

如图所示,生成器已经能够相当出色的生成 Atari 游戏截图。
相关链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础