目录
[3.1 数据摄取管道实现](#3.1 数据摄取管道实现)
[3.1.1 Loader:加载原始文档](#3.1.1 Loader:加载原始文档)
[3.1.2 对长文本进行分块(Chunking)](#3.1.2 对长文本进行分块(Chunking))
[LangChain 中的文本分块器](#LangChain 中的文本分块器)
[3.1.3 对文本块进行向量化(Embedding)](#3.1.3 对文本块进行向量化(Embedding))
[3.1.4 将向量及其元数据存入向量数据库(Vector Store)](#3.1.4 将向量及其元数据存入向量数据库(Vector Store))
[3.2 检索生成管道(Retrieval Pipeline)](#3.2 检索生成管道(Retrieval Pipeline))
[3.2.2 实现增强生成](#3.2.2 实现增强生成)
一.什么是RAG?(检索增强生成)
检索增强生成(RAG)是一种优化大型语言模型输出的过程,即在生成响应前,
它会参考一个权威的知识库,而这个知识库位于其训练数据来源之外。大型语言
模型(LLMS)通过大量数据进行训练,并使用数十亿个参数来生成原始输出,用
于回答问题、翻译语言和完成句子等任务。
RAG能够将LLMS原本强大的能力扩展到特定领域或组织的内部知识库中,而无需对模型进行重新训练。这是一种提高LLM输出效果的经济有效方法,从而使其在各种情境下保持相关性、准确性和实用性。
二.为什么会有RAG?
没有使用RAG时,我们使用原始模型(纯LLM)的流程如下:
用户给出输入 ,提出具体问题和提示词,直接进入LLM ,大模型靠一开始训练的数据进行回答,形成输出 。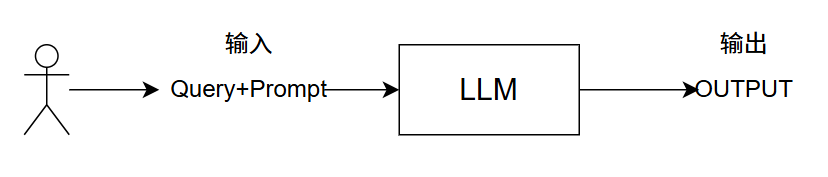
这就导致了一些问题:
- 大模型不知道新知识(知识过时)
大模型只能依靠原有的训练数据进行回答。例如GPT5在2025年8月发布,那么他只能用8月之前的数据,而对8月之后世界发生的事情是未知的。 - 大模型会胡编(幻觉)
当我们对大模型提出问题时,大模型不知道8月之后发生的事情,但LLM会尝试生成自己的答案,这种情况称之为幻觉 - 无法使用私有数据
大模型是用大量数据训练的,当一个公司想要解决自己公司特定的问题时,需要将公司内的特定数据与LLM结合起来。但公司内部的数据不会公开。
当这个公司想要使用自己内部的数据与大模型结合起来做一个聊天机器人,一种方法就是我们可以对模型进行微调,但模型微调是一种复杂的过程,大模型有数十亿个参数,调整这数十亿个参数需要大量的时间和花费。并且随着公司内部数据的不断更新,我们不能每天对它进行微调。而另外一种较好的方法就是使用RAG。
三.RAG流程
传统 RAG 通常由两部分组成:
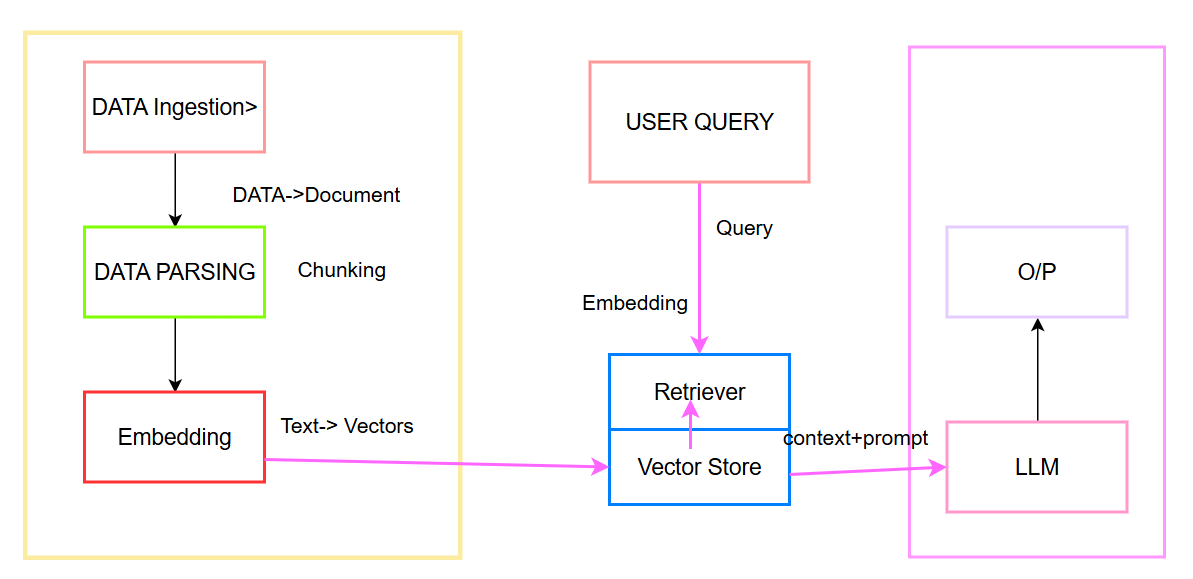
1.数据摄取/索引管道 (Data Ingestion Pipeline)
将外部数据(如 PDF、HTML、Excel、SQL 等)进行加载 到系统中,经过解析、清洗,分块 ,然后通过嵌入 模型将文本块转换为向量,并连同原文和元数据一起存入 向量数据库。
2.检索生成管道(Retrieval Pipeline)
用户提问后,系统先将Query 转换成向量 ,再到向量数据库中做相似度检索 ,召回 与问题最相关的若干文本块,随后将这些文本块作为上下文与用户问题一起输入 给 LLM,最终生成回答。
流程图如下:
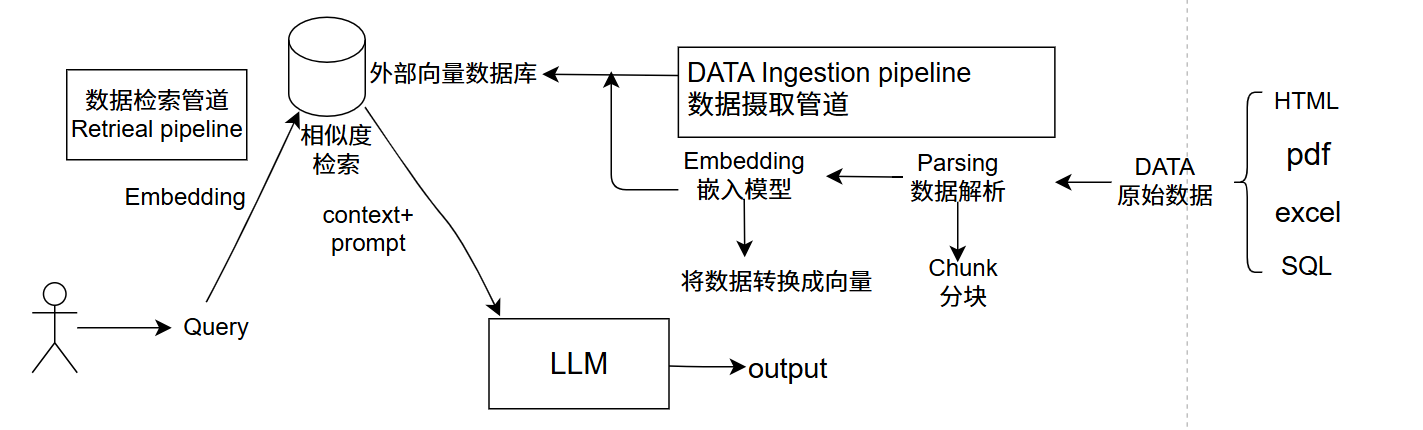
RAG 通过给大模型提供与问题相关的外部知识,提升回答的准确性、时效性和可控性,并在一定程度上能够降低幻觉。
3.1 数据摄取管道实现
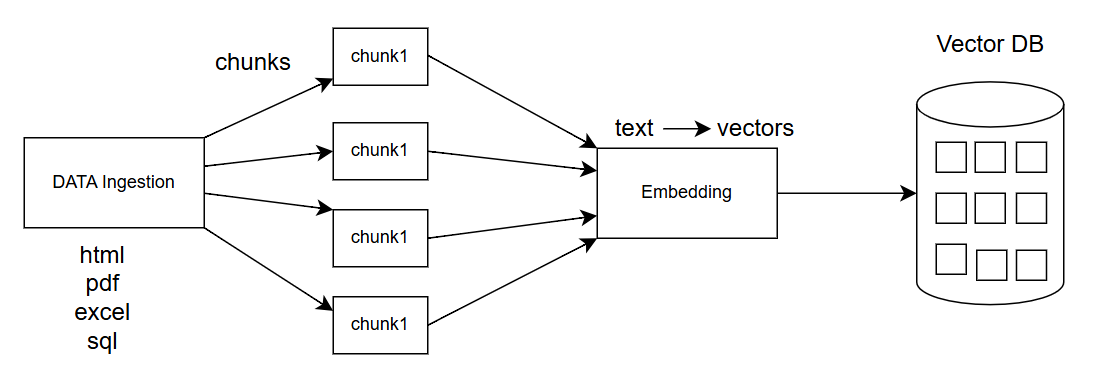
在传统 RAG 系统中,数据摄取管道(Data Ingestion Pipeline)负责将外部知识整理成可检索的形式。
通常来说,数据摄取管道包含以下几个步骤:
- 加载原始数据(Loading)
- 解析文档内容(Parsing)
- 将内容组织为统一的 Document 结构
- 对长文本进行分块(Chunking)
- 对文本块进行向量化(Embedding)
- 将向量及其元数据存入向量数据库(Vector Store)
数据摄取流程示意图:
3.1.1 Loader:加载原始文档
官方文档:https://docs.langchain.com/oss/python/integrations/document_loaders
RAG 的第一步是将外部知识读入系统。
这些知识可能来自多种不同的数据源,例如:txt 文本文件,pdf 文档, csv 表格文件, docx Word 文件,html 网页,数据库或 API 返回的数据。
在 LangChain 中,负责完成这一步的工具叫做 Document Loader。
Loader 的作用可以概括为:将外部原始数据读取出来,并转换成 LangChain 可以统一处理的 Document 对象。
在 LangChain 中,Loader 加载出来的结果通常不是普通字符串,而是 Document 对象。
Document 是 LangChain 中表示文档的统一结构,主要包含两部分:
- page_content: 表示文档的正文内容。是真正需要被检索和理解的文本
- metadata : 表示文档的附加信息,也就是元数据。用来记录这段文本来自哪里、属于哪个文件、在哪一页、作者是谁等信息
不同类型的文件通常对应不同的 Loader。例如:
- TextLoader:读取 .txt
- PyPDFLoader:读取 .pdf
- PyMuPDFLoader:读取 .pdf
- CSVLoader:读取 .csv
- Docx2txtLoader:读取 .docx
- DirectoryLoader:批量读取某个目录下的文件
也就是说,Loader 解决的是"怎么把文件读进来"的问题。
python
##例子:使用 PDF Loader 加载 PDF 文档
from langchain_community.document_loaders import PyPDFLoader, PyMuPDFLoader
dir_loader=DirectoryLoader(
"../data/pdf",
glob="**/*.pdf", ## Pattern to match files
loader_cls= PyMuPDFLoader, ##loader class to use
show_progress=False
)
pdf_documents = dir_loader.load()
pdf_documents
##输出结果(Document文档内容如下)
Document(metadata={'producer': 'Skia/PDF m119', 'creator': 'Chromium', 'creationdate': '2024-08-17T01:25:20+00:00', 'source': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'file_path': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'total_pages': 48, 'format': 'PDF 1.4', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'moddate': '2024-08-17T01:25:20+00:00', 'trapped': '', 'modDate': "D:20240817012520+00'00'", 'creationDate': "D:20240817012520+00'00'", 'page': 0}, page_content='1\nTypeScript 快速上手\n一、TypeScript 简介\n二、为何需要 TypeScript\n三、编译 TypeScript\n1. 命令行编译\n2. 自动化编译\n四、类型声明\n五、类型推断\n六、类型总览\n七、常用类型与语法\n1. any\n2. unknown\n3. never\n4. void\n5. object\n6. tuple\n7. enum\n8. type\n9. 一个特殊情况\n10. 复习类相关知识\n11. 属性修饰符\n12. 抽象类\n13. interface(接口)\n14. 一些相似概念的区别\n14.1. interface 与 type 的区别\n14.2. interface 与 抽象类的区别\n八、泛型\n九、类型声明文件'),
Document(metadata={'producer': 'Skia/PDF m119', 'creator': 'Chromium', 'creationdate': '2024-08-17T01:25:20+00:00', 'source': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'file_path': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'total_pages': 48, 'format': 'PDF 1.4', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'moddate': '2024-08-17T01:25:20+00:00', 'trapped': '', 'modDate': "D:20240817012520+00'00'", 'creationDate': "D:20240817012520+00'00'", 'page': 1}, page_content='2\n1.\nTypeScript\ufeff由微软开发,是基于\ufeffJavaScript\ufeff的一个扩展语言。\n2.\nTypeScript\ufeff包含了\ufeffJavaScript\ufeff的所有内容,即:\ufeffTypeScript\ufeff是\ufeffJavaScrip\nt\ufeff的超集。\n3.\nTypeScript\ufeff增加了:静态类型检查、接口、 泛型等很多现代开发特性,更适合大型项目\n的开发。\n4.\nTypeScript\ufeff需要编译为\ufeffJavaScript\ufeff,然后交给浏览器或其他\ufeffJavaScript\ufeff运行环\n境执行。\n1️⃣今非昔比的 JavaScript(了解)\nJavaScript 当年诞生时的定位是浏览器脚本语言,用于在网页中嵌入简单的逻辑,且代码\n量很少。\n随着时间的推移,JavaScript 变得越来越流行,如今的 JavaScript 已经可以全栈编程\n了。\n现如今的 JavaScript 应用场景比当年丰富的多,代码量也比当年大很多,随便一个 \nJavaScript 项目的代码量,可以轻松的达到几万行,甚至十几万行!\n然而 JavaScript 当年"出生简陋",没考虑到如今的应用场景和代码量,逐渐就出现了很多\n困扰。\n一、TypeScript 简介\n二、为何需要 TypeScript \n●\n●\n●\n●'),
Document(metadata={'producer': 'Skia/PDF m119', 'creator': 'Chromium', 'creationdate': '2024-08-17T01:25:20+00:00', 'source': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'file_path': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'total_pages': 48, 'format': 'PDF 1.4', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'moddate': '2024-08-17T01:25:20+00:00', 'trapped': '', 'modDate': "D:20240817012520+00'00'", 'creationDate': "D:20240817012520+00'00'", 'page': 2}, page_content="3\n2️⃣JavaScript 中的困扰\n3️⃣『静态类型检查』\n在代码运行前进行检查,发现代码的错误或不合理之处,减小运行时出现异常的几率,此种检\n查叫『静态类型检查』,TypeScript 和核心就是『静态类型检查』,简言之就是把运行时的\n错误前置。\n同样的功能,TypeScript 的代码量要大于 JavaScript,但由于 TypeScript 的代码结构更加\n清晰,在后期代码的维护中 TypeScript 却胜于 JavaScript。\n😞1. 不清楚的数据类型\n😞2. 有漏洞的逻辑\n😞3. 访问不存在的属性\n😞4. 低级的拼写错误\n●\n●\n三、编译 TypeScript \nlet welcome = 'hello'\nwelcome() // 此行报错:TypeError: welcome is not a function\nconst str = Date.now() % 2 ? '奇数' : '偶数'\nif (str !== '奇数') {\n alert('hello')\n} else if (str === '偶数') {\n alert('world')\n}\nconst obj = { width: 10, height: 15 };\nconst area = obj.width * obj.heigth;\nconst message = 'hello,world'\nmessage.toUperCase()"),
Document(metadata={'producer': 'Skia/PDF m119', 'creator': 'Chromium', 'creationdate': '2024-08-17T01:25:20+00:00', 'source': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'file_path': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'total_pages': 48, 'format': 'PDF 1.4', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'moddate': '2024-08-17T01:25:20+00:00', 'trapped': '', 'modDate': "D:20240817012520+00'00'", 'creationDate': "D:20240817012520+00'00'", 'page': 3}, page_content="4\n浏览器不能直接运行 TypeScript 代码,需要编译为 JavaScript 再交由浏览器解析器执行。\n要把.ts\ufeff文件编译为\ufeff.js\ufeff文件,需要配置\ufeffTypeScript\ufeff的编译环境,步骤如下:\n第一步:创建一个demo.ts\ufeff文件,例如:\n第二步:全局安装TypeScript\ufeff\n第三步:使用命令编译.ts\ufeff文件\n第一步:创建TypeScript\ufeff编译控制文件\n1. 工程中会生成一个tsconfig.json\ufeff配置文件,其中包含着很多编译时的配置。\n2. 观察发现,默认编译的JS\ufeff版本是\ufeffES7\ufeff,我们可以手动调整为其他版本。\n第二步:监视目录中的.ts\ufeff文件变化\n第三步:小优化,当编译出错时不生成.js\ufeff文件\n1. 命令行编译\n●\n●\n●\n2. 自动化编译\n●\n●\n●\nconst person = {\n name:'李四',\n age:18\n}\nconsole.log(`我叫${person.name},我今年${person.age}岁了`)\nnpm i typescript -g\ntsc demo.ts \ntsc --init\ntsc --watch 或 tsc -w"),
Document(metadata={'producer': 'Skia/PDF m119', 'creator': 'Chromium', 'creationdate': '2024-08-17T01:25:20+00:00', 'source': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'file_path': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'total_pages': 48, 'format': 'PDF 1.4', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'moddate': '2024-08-17T01:25:20+00:00', 'trapped': '', 'modDate': "D:20240817012520+00'00'", 'creationDate': "D:20240817012520+00'00'", 'page': 4}, page_content='5\n备注:当然也可以修改tsconfig.json\ufeff中的\ufeffnoEmitOnError\ufeff配置\n使用:\ufeff来对变量或函数形参,进行类型声明:\n在:\ufeff后也可以写字面量类型,不过实际开发中用的不多。\n四、类型声明\n五、类型推断\ntsc --noEmitOnError --watch\nlet a: string \n//变量a只能存储字符串\nlet b: number \n//变量b只能存储数值\nlet c: boolean //变量c只能存储布尔值\na = \'hello\'\na = 100 //警告:不能将类型"number"分配给类型"string"\nb = 666\nb = \'你好\'//警告:不能将类型"string"分配给类型"number"\nc = true\nc = 666 //警告:不能将类型"number"分配给类型"boolean"\n// 参数x必须是数字,参数y也必须是数字,函数返回值也必须是数字\nfunction demo(x:number,y:number):number{\n return x + y\n}\ndemo(100,200) \ndemo(100,\'200\') \n//警告:类型"string"的参数不能赋给类型"number"的参数\ndemo(100,200,300) //警告:应有 2 个参数,但获得 3 个\ndemo(100) \n//警告:应有 2 个参数,但获得 1 个\nlet a: \'你好\'\n//a的值只能为字符串"你好"\nlet b: 100 \n//b的值只能为数字100\na = \'欢迎\'//警告:不能将类型""欢迎""分配给类型""你好""\nb = 200 //警告:不能将类型"200"分配给类型"100"'),
Document(metadata={'producer': 'Skia/PDF m119', 'creator': 'Chromium', 'creationdate': '2024-08-17T01:25:20+00:00', 'source': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'file_path': '..\\data\\pdf\\TypeScript 快速上手.pdf', 'total_pages': 48, 'format': 'PDF 1.4', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'moddate': '2024-08-17T01:25:20+00:00', 'trapped': '', 'modDate': "D:20240817012520+00'00'", 'creationDate': "D:20240817012520+00'00'", 'page': 5}, page_content='6\nTS\ufeff会根据我们的代码,进行类型推导,例如下面代码中的变量\ufeffd\ufeff,只能存储数字\n①string\ufeff\n②number\ufeff\n③boolean\ufeff\n④null\ufeff\n⑤undefined\ufeff\n⑥bigint\ufeff\n⑦symbol\ufeff\n⑧object\ufeff\n备注:其中object\ufeff包含:\ufeffArray\ufeff、\ufeffFunction\ufeff、\ufeffDate\ufeff、\ufeffError\ufeff等......\n但要注意,类型推断不是万能的,面对复杂类型时推断容易出问题,所以尽量还是明确的编写类\n型声明!\n六、类型总览\nJavaScript 中的数据类型\nlet d = -99 //TypeScript会推断出变量d的类型是数字\nd = false \n//警告:不能将类型"boolean"分配给类型"number"'),3.1.2 对长文本进行分块**(Chunking)**
完成文档加载后,系统通常会得到一个Document 列表 。但是这些文档往往仍然较长,不适合直接用于检索或向量化 。因此,在数据摄取管道中,下一步通常需要对长文本进行分块(Chunking)。
所谓分块,就是将一篇较长的文本切分成多个较小的文本片段(chunk),以便后续分别进行 embedding 和检索。
LangChain 中的文本分块器
LangChain 中常用RecursiveCharacterTextSplitter来完成这一操作。
其中:
- chunk_size 控制文本块大小
- chunk_overlap 控制相邻块之间的重叠部分
分块后的结果仍然是 Document 列表,只不过每个 Document 的内容更短、更适合进行 embedding 和相似度检索。
python
###分块
def split_documents(documents,chunk_size=1000,chunk_overlap=200):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
split_docs = text_splitter.split_documents(documents)
print(f"Split {len(documents)} documents into {len(split_docs)} chunks")
# 打印分块结果
if split_docs:
print(f"\nExample chunk:")
print(f"Content: {split_docs[0].page_content[:200]}...")
print(f"Metadata: {split_docs[0].metadata}")
return split_docs3.1.3 对文本块进行向量化(Embedding)
完成文档分块之后,我们得到了一批长度可控、语义相对完整的文本块(Chunk)。但这些文本无法直接被计算机用于相似度计算,因此我们需要通过向量化(Embedding) ,把文本转换成计算机能理解的数值向量,这个过程就叫做 Embedding(文本向量化)。
我们可以将每个 chunk 的正文提取出来,再交给 embedding 模型处理。
在实际项目中,我们可以使用现有的嵌入模型对文本进行向量化。
Embedding 模型有很多种,常见来源包括:
- OpenAI Embeddings
- HuggingFace / Sentence Transformers
- BGE 系列模型
- E5 系列模型
- 本地部署的中文向量模型
这里我们封装了一个 EmbeddingManager 类,基于开源模型 all-MiniLM-L6-v2 实现本地文本向量化。
python
class EmbeddingManager:
def __init__(self, model_name: str = "all-MiniLM-L6-v2"):
self.model_name = model_name
self.model = None
self._load_model()
"""加载 SentenceTransformer 模型"""
def _load_model(self):
try:
print(f"正在加载嵌入模型: {self.model_name}")
self.model = SentenceTransformer(self.model_name)
print(f"模型加载成功. 向量维度: {self.model.get_sentence_embedding_dimension()}")
except Exception as e:
print(f"加载模型出错 {self.model_name}: {e}")
raise
def generate_embeddings(self, texts: List[str]) -> np.ndarray:
if not self.model:
raise ValueError("Model not loaded")
print(f"正在生成嵌入向量 for {len(texts)} 个文本...")
embeddings = self.model.encode(texts, show_progress_bar=True)
print(f"生成的嵌入向量形状: {embeddings.shape}")
return embeddings
## 初始化嵌入管理类
embedding_manager=EmbeddingManager()
embedding_manager
//输出结果
正在加载嵌入模型: all-MiniLM-L6-v2
Loading weights: 100%|██████████| 103/103 [00:00<00:00, 7669.33it/s]
模型加载成功. 向量维度: 384
C:\Users\Lenovo\AppData\Local\Temp\ipykernel_47612\468568965.py:11: FutureWarning: The `get_sentence_embedding_dimension` method has been renamed to `get_embedding_dimension`.
print(f"模型加载成功. 向量维度: {self.model.get_sentence_embedding_dimension()}")此时,每个文本块都已经被转换成了一个 384 维的向量,后续我们就可以把这些向量和原始文本、元数据一起存入向量数据库了。
3.1.4 将向量及其元数据存入向量数据库(Vector Store)
在完成文本分块和向量化之后,系统已经得到了每个 chunk 的向量表示。之后会将这些向量连同文本块内容和元数据一起存入向量数据库。
也就是说,向量只是中间表示形式。它真正的用途在于支持后续检索。
向量数据库中通常会保存以下几类信息:
- chunk 对应的向量表示
- chunk 的原始文本内容
- chunk 的 metadata(如文件来源、页码等)-元数据
- 唯一标识符(id)
也就是说,向量数据库中的一条记录并不是只有一串数字,而通常是:
python
{
id: "chunk_001",
embedding: [0.12, -0.48, 0.93, ...],
page_content: "Transformer relies entirely on attention mechanisms...",
metadata: {
source: "attention.pdf",
page: 3
}
}这样,在检索到相似向量之后,系统不仅能知道"哪个向量最相近",还能够直接取回:
- 对应的原始文本
- 文本来自哪个文件
- 文本位于第几页
这对 RAG 后续生成回答非常重要。
当用户输入问题时,系统就可以:
- 先将 Query 也转换成向量
- 在向量数据库中进行相似度搜索
- 找到最相关的几个 chunk
- 将这些 chunk 作为上下文提供给 LLM
常见的向量存储工具
在 LangChain 生态中,常见的向量存储包括:FAISS,Chroma,Weaviate,Milvus,Pinecone
在向量存储中,我们创建一个VectorStore的类。用来存储文本块、向量、元数据。
VectorStore 是一个向量数据库管理工具,专门用来把「分块后的文本 + 向量化后的向量」存入 Chroma 向量库,为 RAG 检索做准备。
python
class VectorStore:
"""管理 ChromaDB 向量库中的文档嵌入向量"""
def __init__(self, collection_name: str = "pdf_documents", persist_directory: str = "../data/vector_store"):
"""
Initialize the vector store
Args:
collection_name: 集合名称
persist_directory: 向量库保存路径
"""
self.collection_name = collection_name
self.persist_directory = persist_directory
self.client = None
self.collection = None
self._initialize_store()
def _initialize_store(self):
"""初始化向量库客户端"""
try:
# 创建持久化目录
os.makedirs(self.persist_directory, exist_ok=True)
self.client = chromadb.PersistentClient(path=self.persist_directory)
# 获取或创建集合(相当于数据库里的表)
self.collection = self.client.get_or_create_collection(
name=self.collection_name,
metadata={"description": "PDF document embeddings for RAG"}
)
print(f"Vector store initialized. Collection: {self.collection_name}")
print(f"Existing documents in collection: {self.collection.count()}")
except Exception as e:
print(f"Error initializing vector store: {e}")
raise
def add_documents(self, documents: List[Any], embeddings: np.ndarray):
"""
将文档和它们的向量添加到向量库
Args:
documents:文档块列表
embeddings: 向量数组
"""
if len(documents) != len(embeddings):
raise ValueError("文档数量必须与向量数量一致")
print(f"Adding {len(documents)} documents to vector store...")
# Prepare data for ChromaDB
ids = []
metadatas = []
documents_text = []
embeddings_list = []
for i, (doc, embedding) in enumerate(zip(documents, embeddings)):
# 生成唯一ID
doc_id = f"doc_{uuid.uuid4().hex[:8]}_{i}"
ids.append(doc_id)
# 元数据
metadata = dict(doc.metadata)
metadata['doc_index'] = i
metadata['content_length'] = len(doc.page_content)
metadatas.append(metadata)
#文本内容
documents_text.append(doc.page_content)
# 向量(转成list)
embeddings_list.append(embedding.tolist())
# 把数据写入向量库
try:
self.collection.add(
ids=ids,
embeddings=embeddings_list,
metadatas=metadatas,
documents=documents_text
)
print(f"Successfully added {len(documents)} documents to vector store")
print(f"Total documents in collection: {self.collection.count()}")
except Exception as e:
print(f"向向量库添加文档时出错: {e}")
raise
vectorstore=VectorStore()
vectorstore
向量存储建立后,系统就能根据用户 Query 找到最相关的文本块了。
3.2 检索生成管道(Retrieval Pipeline)
当数据摄取阶段完成后,外部知识已经被处理成多个文本块,并以向量形式存入向量数据库。
此时,RAG 系统已经具备了"知识索引"。
接下来,当用户输入问题时,系统就会进入第二条主流程:检索生成管道(Retrieval Pipeline)。
这一阶段的核心任务是:
根据用户问题,从知识库中找出最相关的上下文,再将这些上下文提供给大语言模型,由模型生成最终回答。
也就是说,RAG 并不是让 LLM 直接凭参数记忆回答问题,而是先"查资料",再"结合资料作答"。
在 检索生成管道 中,通常会经历以下步骤:
- 用户输入 Query
- 将 Query 转换为向量表示
- 在向量数据库中进行相似度检索
- 召回最相关的若干文本块
- 将这些文本块作为上下文,与用户问题一起输入给 LLM
- 由 LLM 生成最终回答
3.2.1创建一个RAG检索器。
我们创建一个RAG Retriever的类,它能够处理基于查询的向量存储检索。
我们创建一个构造函数:其中有两个参数,向量存储(Vector Store)和嵌入管理器(embedding manager)。
我们还需要创建一个检索函数,检索函数的主要工作是根据特定的查询进行检索。这个
python
class RAGRetriever:
"""处理基于查询的向量库检索"""
def __init__(self, vector_store: VectorStore, embedding_manager: EmbeddingManager):
"""
初始化检索器
Args:
vector_store: 包含文档向量的向量库
embedding_manager: 用于生成查询向量的管理器
"""
self.vector_store = vector_store
self.embedding_manager = embedding_manager
def retrieve(self, query: str, top_k: int = 5, score_threshold: float = 0.0) -> List[Dict[str, Any]]:
"""
为用户查询检索相关的文档
Args:
query: 搜索查询(用户的问题)
top_k: 返回最靠前的结果数量
score_threshold: 最低相似度分数阈值
Returns:
包含检索到的文档和元数据的字典列表
"""
print(f"正在为查询检索文档: '{query}'")
print(f"最大返回条数: {top_k}, 最低相似度分数阈值: {score_threshold}")
# 生成查询向量
query_embedding = self.embedding_manager.generate_embeddings([query])[0]
# 在向量库中搜索
try:
results = self.vector_store.collection.query(
query_embeddings=[query_embedding.tolist()],
n_results=top_k
)
# 处理搜索结果
retrieved_docs = []
if results['documents'] and results['documents'][0]:
documents = results['documents'][0]
metadatas = results['metadatas'][0]
distances = results['distances'][0]
ids = results['ids'][0]
for i, (doc_id, document, metadata, distance) in enumerate(zip(ids, documents, metadatas, distances)):
# 将距离转为相似度分数(ChromaDB 使用余弦距离)
similarity_score = 1 - distance
if similarity_score >= score_threshold:
retrieved_docs.append({
'id': doc_id,
'content': document,
'metadata': metadata,
'similarity_score': similarity_score,
'distance': distance,
'rank': i + 1
})
print(f"检索到 {len(retrieved_docs)} 个文档(过滤后)")
else:
print("No documents found")
return retrieved_docs
except Exception as e:
print(f"检索过程中出错: {e}")
return []
rag_retriever=RAGRetriever(vectorstore,embedding_manager)
rag_retriever
rag_retriever.retrieve("什么是TypeScript?")
//输出:
正在为查询检索文档: '什么是TypeScript?'
最大返回条数: 5, 最低相似度分数阈值: 0.0
正在生成嵌入向量 for 1 个文本...
Batches: 100%|██████████| 1/1 [00:00<00:00, 81.83it/s]
生成的嵌入向量形状: (1, 384)
检索到 5 个文档(过滤后)
[{'id': 'doc_5c22cbb6_6',
'content': '7\n1. 上述所有 JavaScript 类型 \n2. 六个新类型:\n① any \n② unknown \n③ never \n④ void \n⑤ tuple \n⑥ enum \n3. 两个⽤于⾃定义类型的⽅式:\n① type \n② interface \nTypeScript 中的数据类型',
'metadata': {'creator': 'Chromium',
'total_pages': 48,
'creationdate': '2024-08-17T01:25:20+00:00',
'producer': 'Skia/PDF m119',
'doc_index': 6,
'page_label': '7',
'source': '..\\data\\pdf\\TypeScript 快速上手.pdf',
'content_length': 144,
'page': 6,
'file_type': 'pdf',
'source_file': 'TypeScript 快速上手.pdf',
'moddate': '2024-08-17T01:25:20+00:00'},
'similarity_score': 0.3673054575920105,
'distance': 0.6326945424079895,
'rank': 1},
{'id': 'doc_b2b9737a_6',
'content': '7\n1. 上述所有 JavaScript 类型 \n2. 六个新类型:\n① any \n② unknown \n③ never \n④ void \n⑤ tuple \n⑥ enum \n3. 两个⽤于⾃定义类型的⽅式:\n① type \n② interface \nTypeScript 中的数据类型',
'metadata': {'creator': 'Chromium',
'source_file': 'TypeScript 快速上手.pdf',
'source': '..\\data\\pdf\\TypeScript 快速上手.pdf',
'moddate': '2024-08-17T01:25:20+00:00',
'page': 6,
'file_type': 'pdf',
...
'moddate': '2024-08-17T01:25:20+00:00',
'content_length': 330},
'similarity_score': 0.3045564293861389,
'distance': 0.6954435706138611,
'rank': 5}]每当我们创建一个检索时,这个检索器实际上是建立在向量存储Vector Store上的,而检索器知识一个基于我们收到的任何查询的简单接口,这个检索器会对你的查询给出回应response,它本质上是一种连接向量存储和短向量(查询向量)的接口。