我用 Rust 写了个数据文件预览工具,167MB Parquet 35ms 出结果
背景
做数据工程时经常遇到这个场景:
收到一个陌生的 .parquet 或 .csv 文件,想快速了解它有多少行、哪些列、什么类型。
常规操作是打开 Python:
python
import polars as pl
df = pl.read_parquet("file.parquet")
print(df.shape)
print(df.schema)
print(df.head())等个几秒,看完,关掉。
每天重复十几次,很烦。
于是我写了 dpeek,一个基于 Polars 的命令行数据预览工具。
一行命令看清楚
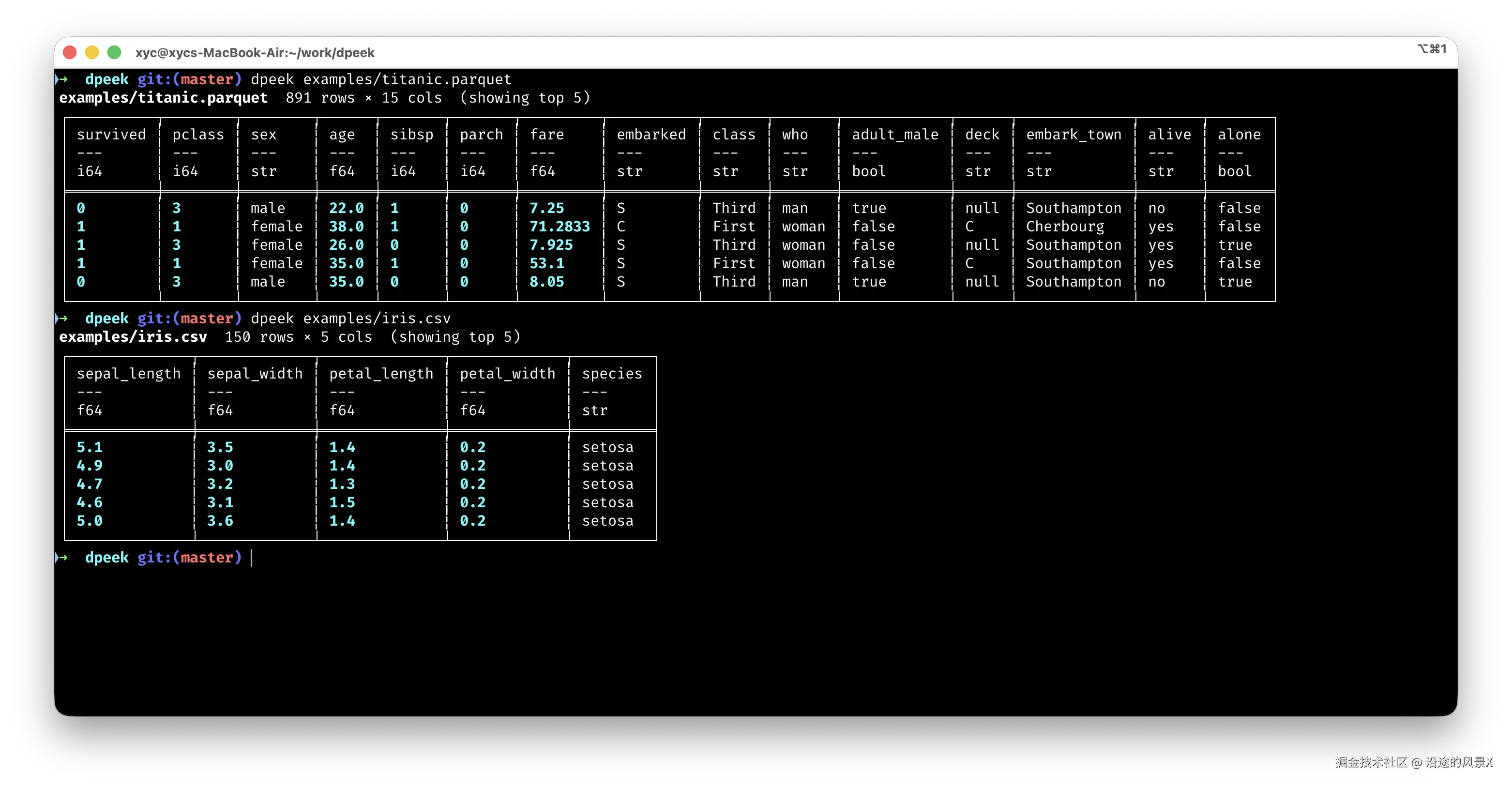
行数、列数、类型、数据,一次看全。
还支持:
bash
dpeek tail file.parquet # 看最后几行
dpeek schema file.parquet # 只看列名和类型
dpeek -c col1,col2 file.csv # 只看部分列
dpeek -n 20 file.csv # 看前20行
dpeek --fast file.csv # 大文件跳过全量扫描为什么快?
Parquet 的秘密: Parquet 文件把 schema、行数、统计信息都存在文件末尾的 footer 里。dpeek 直接读 footer,不用扫描数据------167MB 的文件,实际 I/O 不到 1MB。
CSV 的权衡: CSV 没有元数据,行数和类型只能扫全文。默认模式会扫完整个文件保证准确;加 --fast 只读前 100 行,1.8GB 的 CSV 也能 90ms 出结果。
性能数据(Apple M4,含进程启动):
| 文件 | 大小 | 模式 | 耗时 |
|---|---|---|---|
| titanic.parquet | 11KB | 默认 | ~23ms |
| 167MB Parquet | 167MB | 默认 | ~35ms |
| 1.8GB CSV | 1.8GB | --fast |
~24ms |
对比:pandas/pyarrow 作为 CLI 工具调用,光 Python 解释器启动就要 ~500ms。
安装
最省事的方式(有 uv 就行,自动安装不污染环境):
bash
uvx dpeek file.parquet或者永久安装:
bash
uv tool install dpeek # 之后直接 dpeek
brew install Xyc2016/tap/dpeek
cargo binstall dpeek
pip install dpeek技术栈
- Rust --- 核心逻辑
- Polars 0.53 --- DataFrame 引擎,Parquet/CSV 读取
- clap 4 --- CLI 解析
- maturin --- 打包成 Python wheel 发布到 PyPI
- GitHub Actions --- 三平台构建 + 自动发布 PyPI / Homebrew tap
二进制 39MB(LTO + strip),PyPI wheel 直接包含预编译二进制,无需本地编译。
GitHub: github.com/Xyc2016/dpe...
欢迎 Star ⭐ 和提 Issue!