先看效果图
教程:
教程目标 :在现有
web_app.py的「数据收集 → 公众号/财经」Tab 中,集成腾讯实时行情、AkShare 原始指标、药师宏观原始数据,无需二次计算,纯展示原始数据。
前置知识 :Python 基础、会用pip install、能看懂 DataFrame 列名
涉及技术:Streamlit、pandas、requests、mootdx(已有代码复用)
一、背景与数据说明
1.1 为什么做这个?
web_app.py 的「数据收集 → 公众号/财经」Tab 原本只有一个占位文字,没有实际数据:
python
# 旧代码(第863行附近)
with tab_d4:
st.subheader("📱 公众号/财经数据")
st.info("药师等公众号数据、腾讯财经、同花顺、东方财富(待集成)")同时,系统中已有 3 个完整的数据采集脚本:
yaoshi_api.py--- 药师API(股债收益差、汇率等)akshare_backup.py--- AkShare(沪深300PE、国债10年、融资融券)tencent_realtime.py--- 腾讯财经实时行情
但这些数据各自存在不同格式的 Excel/CSV 文件里,web_app 没有统一读取方式。本次任务是新建一个统一读取层,让 web_app 的各 Tab 可以标准化的方式读取数据。
1.2 最终效果预览
截图文件位置: 开发记录/2026年05月04日,公众号财经数据集成/效果图/
| 文件名 | 内容 | 数据验证 |
|---|---|---|
01_首页.png |
投资看板首页 | 主页正常加载 |
02_数据收集全貌.png |
数据收集Tab(含通达信/自选股等) | 各子Tab正常 |
03_公众号财经默认.png |
公众号财经Tab(切换前) | 占位文字已替换 |
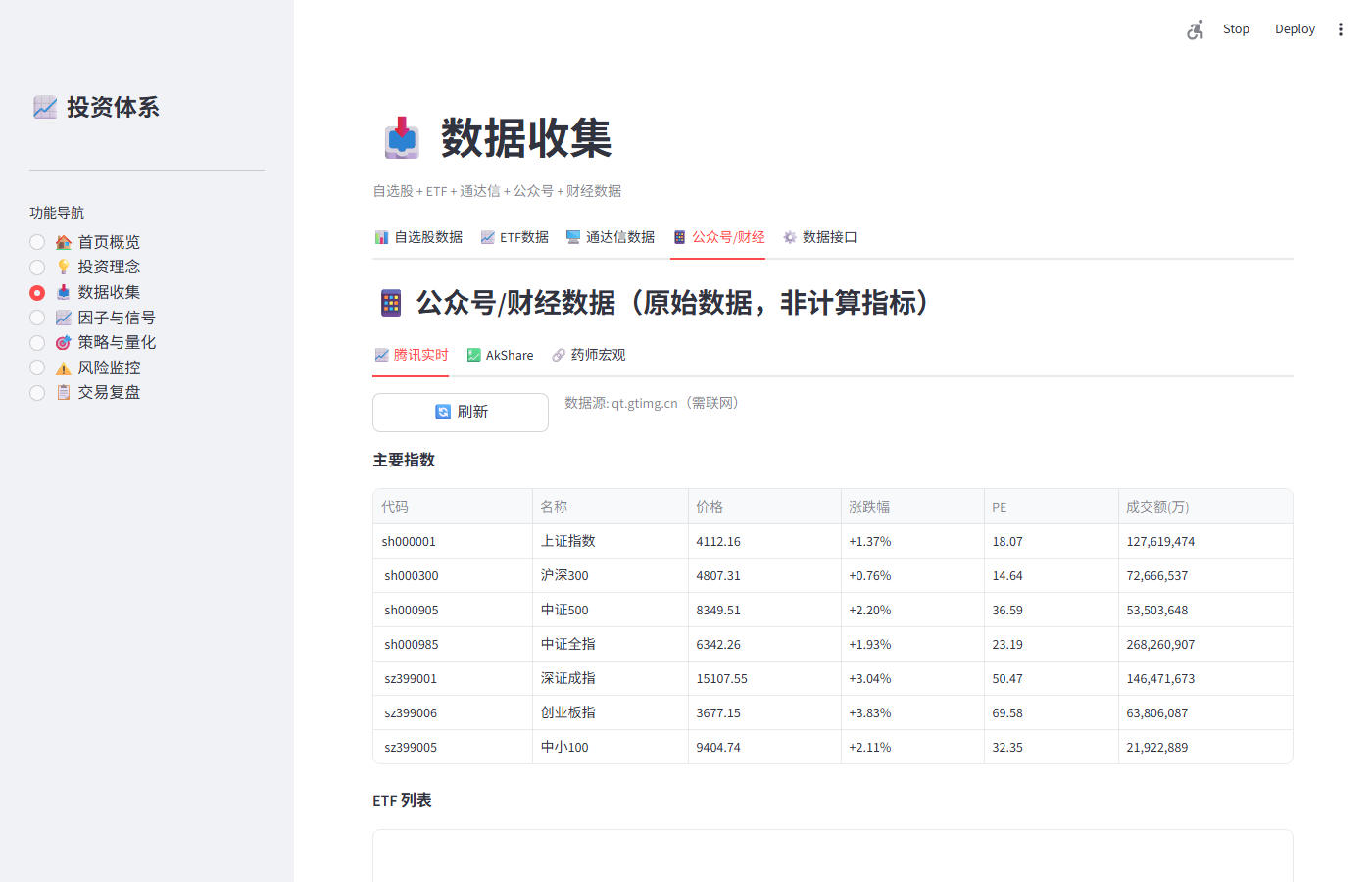
04_腾讯实时.png |
主要指数+ETF列表 | 上证4112.16(+1.37%) 沪深300 4807.31(+0.76%) 创业板3677.15(+3.83%) |
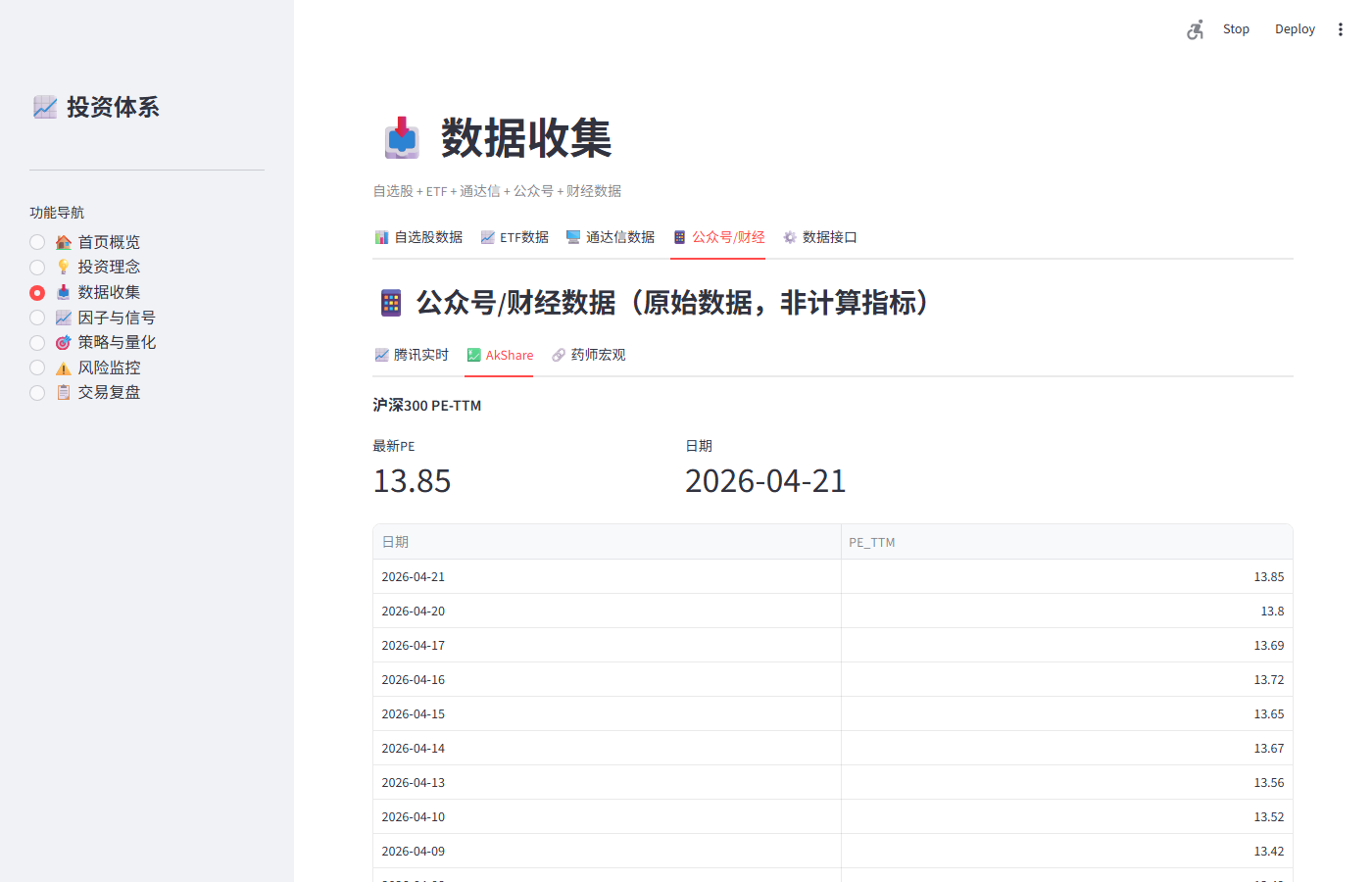
05_AkShare.png |
沪深300PE+国债10年+融资融券 | PE=13.85 日期2026-04-21 |
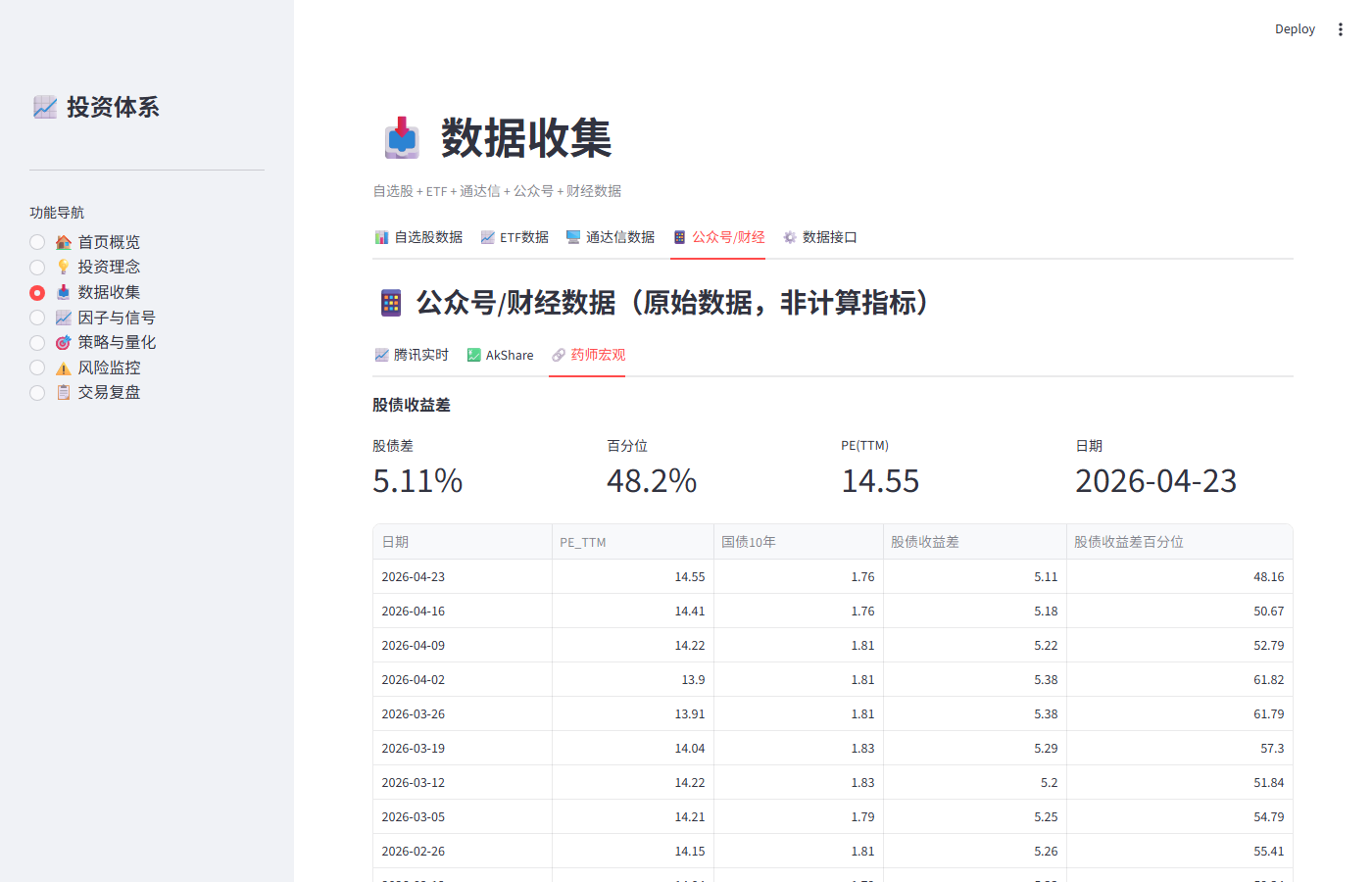
06_药师宏观.png |
股债收益差+汇率 | 股债差=5.11% 百分位=48.2% 日期2026-04-23 |
上传到 CSDN 时,将上述截图拖入编辑器即可获得 URL,再替换到 markdown 中。
二、环境准备
2.1 安装依赖
已有脚本依赖,检测是否已安装:
bash
pip show streamlit pandas requests openpyxl缺少的安装:
bash
pip install streamlit pandas openpyxl requests2.2 目录结构
02_股票金融分析/
├── 07_信息研究/
│ └── market_data/
│ └── reader.py ← 新建:统一读取层
├── 08_知识智能体/
│ └── web_app.py ← 修改:tab_d4 重构
└── 股市各类数据获取/
├── tencent_realtime.py ← 已有:腾讯实时
├── akshare_backup.py ← 已有:AkShare指标
└── yaoshi_api.py ← 已有:药师宏观
数据来源:
F:\吾股丰登\观察标的数据库\
├── HS300PE_history.xlsx # 沪深300PE
├── china_bond_10y_history.xlsx # 国债10年
├── margin_history_full.xlsx # 融资融券
├── stock_bond_yield_history.xlsx # 股债收益差
├── exchange_rate_history.xlsx # 汇率
└── market_sentiment_history.xlsx # 市场情绪三、第一步:新建统一读取层 reader.py
3.1 为什么需要读取层?
F:\吾股丰登\观察标的数据库\ 下的 Excel 文件列名是中文乱码格式(``、PE_TTM 这种),每个文件的列顺序也不一致。如果每个 web_app Tab 都自己读文件、做列名映射,代码会非常冗余。
统一读取层的职责:
- 读取文件
- 标准化列名(乱码 → 中文)
- 标准化日期格式(
YYYY-MM-DD) - 不做任何计算(只做数据搬运)
3.2 核心代码
路径:07_信息研究/market_data/reader.py
python
# -*- coding: utf-8 -*-
"""
市场数据统一读取层
路径: F:/吾股丰登/观察标的数据库/
职责: 把不同格式文件标准化为一致的 DataFrame
原则: 只做列名标准化和日期格式化,不做指标计算
"""
import os
import warnings
from pathlib import Path
from typing import Optional
import pandas as pd
BASE_DIR = Path(r"F:\吾股丰登\观察标的数据库")
warnings.filterwarnings("ignore", category=DeprecationWarning)
def _read_excel(file: Path, usecols: Optional[list] = None) -> pd.DataFrame:
"""读取 Excel,不存在则返回空 DataFrame"""
if not file.exists():
return pd.DataFrame()
try:
return pd.read_excel(file, usecols=usecols)
except Exception:
return pd.DataFrame()3.3 AkShare 数据读取函数
python
# 沪深300 PE-TTM
def read_hs300_pe() -> pd.DataFrame:
"""文件: HS300PE_history.xlsx → [日期, PE_TTM, PE_STATIC]"""
file = BASE_DIR / "HS300PE_history.xlsx"
df = _read_excel(file)
if df.empty:
return df
df = df.rename(columns={df.columns[0]: "日期", df.columns[1]: "PE_TTM"})
if len(df.columns) >= 3:
df = df.rename(columns={df.columns[2]: "PE_STATIC"})
df["日期"] = pd.to_datetime(df["日期"], errors="coerce")
return df.sort_values("日期").reset_index(drop=True)
# 国债10年收益率
def read_bond_10y() -> pd.DataFrame:
"""文件: china_bond_10y_history.xlsx → [日期, 国债10年]"""
file = BASE_DIR / "china_bond_10y_history.xlsx"
df = _read_excel(file)
if df.empty:
return df
df = df.rename(columns={df.columns[0]: "日期", df.columns[1]: "国债10年"})
df["日期"] = pd.to_datetime(df["日期"], errors="coerce")
return df.sort_values("日期").reset_index(drop=True)
# 融资融券
def read_margin() -> pd.DataFrame:
"""文件: margin_history_full.xlsx → [日期, 融资余额, 融券余额, ...]"""
file = BASE_DIR / "margin_history_full.xlsx"
df = _read_excel(file)
if df.empty:
return df
rename = {df.columns[0]: "日期", df.columns[1]: "融资余额", df.columns[2]: "融券余额"}
df = df.rename(columns=rename)
df["日期"] = pd.to_datetime(df["日期"], errors="coerce")
return df.sort_values("日期").reset_index(drop=True)3.4 药师宏观数据读取函数
python
# 股债收益差
def read_stock_bond_yield() -> pd.DataFrame:
"""文件: stock_bond_yield_history.xlsx
→ [日期, PE_TTM, PE百分位, 国债10年, 股债收益差, 股债收益差百分位, 沪深300点位]"""
file = BASE_DIR / "stock_bond_yield_history.xlsx"
df = _read_excel(file)
if df.empty:
return df
col_names = {
df.columns[0]: "日期", df.columns[1]: "PE_TTM", df.columns[2]: "PE百分位",
df.columns[3]: "国债10年", df.columns[4]: "股债收益差",
df.columns[5]: "股债收益差百分位", df.columns[6]: "沪深300点位",
}
df = df.rename(columns=col_names)
df["日期"] = pd.to_datetime(df["日期"], errors="coerce")
return df.sort_values("日期").reset_index(drop=True)
# 人民币汇率中间价
def read_exchange_rate() -> pd.DataFrame:
"""文件: exchange_rate_history.xlsx → [日期, 汇率, 百分位, 沪深300点位]"""
file = BASE_DIR / "exchange_rate_history.xlsx"
df = _read_excel(file)
if df.empty:
return df
col_names = {
df.columns[0]: "日期", df.columns[1]: "汇率",
df.columns[2]: "百分位", df.columns[3]: "沪深300点位",
}
df = df.rename(columns=col_names)
df["日期"] = pd.to_datetime(df["日期"], errors="coerce")
return df.sort_values("日期").reset_index(drop=True)
# 市场情绪
def read_market_sentiment() -> pd.DataFrame:
"""文件: market_sentiment_history.xlsx → [日期, 收盘价, 成交额, 成交额_20日均]"""
file = BASE_DIR / "market_sentiment_history.xlsx"
df = _read_excel(file)
if df.empty:
return df
col_names = {
df.columns[0]: "日期", df.columns[1]: "收盘价",
df.columns[2]: "成交额", df.columns[3]: "成交额_20日均",
}
df = df.rename(columns=col_names)
df["日期"] = pd.to_datetime(df["日期"], errors="coerce")
return df.sort_values("日期").reset_index(drop=True)3.5 腾讯实时行情(HTTP 实时获取)
python
def read_tencent_realtime(symbols: list[str]) -> dict:
"""
获取腾讯财经实时行情(HTTP,需联网)
symbols: 如 ['sh000300', 'sz399006', 'sh510300']
返回: {sym: {名称, 代码, 价格, 涨跌幅, 成交额_万元}}
"""
import requests
if not symbols:
return {}
# 清除代理(否则内地网络无法访问 qt.gtimg.cn)
for k in ["HTTP_PROXY", "HTTPS_PROXY", "http_proxy", "https_proxy"]:
if k in os.environ:
del os.environ[k]
codes = ",".join(symbols)
try:
r = requests.get(
f"https://qt.gtimg.cn/q={codes}",
timeout=10,
proxies={"http": None, "https": None},
)
except Exception:
return {}
results = {}
for line in r.text.split(";"):
if "=" not in line:
continue
key, val = line.split("=", 1)
sym = key.replace("v_", "")
parts = val.replace('"', "").split("~")
if len(parts) < 40:
continue
results[sym] = {
"名称": parts[1] if len(parts) > 1 else "",
"代码": parts[2] if len(parts) > 2 else "",
"价格": float(parts[3]) if parts[3] else 0,
"涨跌幅": float(parts[38]) if parts[38] else 0,
"成交额_万元": float(parts[37]) if parts[37].replace(".", "").replace("-", "").isdigit() else 0,
}
return results3.6 辅助函数
python
def get_latest_row(df: pd.DataFrame) -> dict:
"""返回 DataFrame 最后一行,无数据则返回空 dict"""
if df is None or df.empty:
return {}
row = df.iloc[-1]
return {col: row[col] for col in df.columns}
def fmt_date(dt) -> str:
"""标准化日期格式为 YYYY-MM-DD 字符串"""
if pd.isna(dt):
return ""
if isinstance(dt, str):
return dt[:10]
return pd.to_datetime(dt).strftime("%Y-%m-%d")四、第二步:修改 web_app.py 的 tab_d4
4.1 添加 import
在 web_app.py 顶部(约第28~40行)增加两段 import:
python
# 统一市场数据读取层(新增)
sys.path.insert(0, str(Path(__file__).parent.parent / "07_信息研究" / "market_data"))
from reader import (
read_hs300_pe, read_bond_10y, read_margin,
read_stock_bond_yield, read_exchange_rate, read_market_sentiment,
read_tencent_realtime, get_latest_row, fmt_date,
)
# 腾讯实时行情(已有脚本,引用)
STOCK_DATA_DIR = Path(__file__).parent.parent / "股市各类数据获取"
sys.path.insert(0, str(STOCK_DATA_DIR))
import tencent_realtime as tr_realtime4.2 重构 tab_d4
替换原有的占位文字(第863~865行):
python
# 旧代码
with tab_d4:
st.subheader("📱 公众号/财经数据")
st.info("药师等公众号数据、腾讯财经、同花顺、东方财富(待集成)")替换为三子Tab结构:
python
with tab_d4:
st.subheader("📱 公众号/财经数据(原始数据,非计算指标)")
sub_a, sub_b, sub_c = st.tabs(["📈 腾讯实时", "💹 AkShare", "🔗 药师宏观"])
# ── 子Tab1: 腾讯实时行情 ─────────────────────────────────────────
with sub_a:
col_rt1, col_rt2 = st.columns([1, 4])
with col_rt1:
refresh_rt = st.button("🔄 刷新", use_container_width=True)
with col_rt2:
st.caption("数据源: qt.gtimg.cn(需联网)")
st.markdown("**主要指数**")
idx_data = tr_realtime.get_major_indices()
if idx_data:
idx_rows = [{
"代码": sym, "名称": d['名称'],
"价格": f"{d['价格']:.2f}",
"涨跌幅": f"{d['涨跌幅']:+.2f}%",
"PE": f"{d['PE']:.2f}" if d['PE'] else "N/A",
"成交额(万)": f"{d['成交额_万元']:,.0f}",
} for sym, d in idx_data.items()]
st.dataframe(pd.DataFrame(idx_rows), use_container_width=True, hide_index=True)
else:
st.warning("无法获取指数数据(网络问题或未开盘)")
st.markdown("**ETF 列表**")
etf_data = tr_realtime.get_etf_list()
if etf_data:
etf_rows = [{
"代码": sym, "名称": d['名称'], "价格": f"{d['价格']:.3f}",
"涨跌幅": f"{d['涨跌幅']:+.2f}%", "成交额(万)": f"{d['成交额_万元']:,.0f}",
} for sym, d in sorted(etf_data.items(), key=lambda x: -x[1]['成交额_万元'])]
st.dataframe(pd.DataFrame(etf_rows), use_container_width=True, hide_index=True)
if refresh_rt:
try:
tr_realtime.save_daily_snapshot()
st.success("快照已保存")
except Exception as e:
st.warning(f"保存失败: {e}")
# ── 子Tab2: AkShare 原始指标 ─────────────────────────────────────
with sub_b:
df_pe = read_hs300_pe()
st.markdown("**沪深300 PE-TTM**")
if not df_pe.empty:
last = df_pe.iloc[-1]
c1, c2, c3 = st.columns(3)
c1.metric("最新PE", f"{last['PE_TTM']:.2f}")
c2.metric("日期", fmt_date(last['日期']))
st.dataframe(df_pe[['日期', 'PE_TTM']].tail(10).pipe(
lambda x: x.assign(日期=x['日期'].apply(fmt_date))
).sort_values('日期', ascending=False).reset_index(drop=True),
use_container_width=True, hide_index=True)
df_bond = read_bond_10y()
st.markdown("**国债10年收益率**")
if not df_bond.empty:
last_b = df_bond.iloc[-1]
st.metric("最新利率", f"{last_b['国债10年']:.4f}%")
st.dataframe(df_bond.tail(10).pipe(
lambda x: x.assign(日期=x['日期'].apply(fmt_date))
).sort_values('日期', ascending=False).reset_index(drop=True),
use_container_width=True, hide_index=True)
df_mg = read_margin()
st.markdown("**融资融券**")
if not df_mg.empty:
last_mg = df_mg.iloc[-1]
st.metric("融资余额", f"{last_mg['融资余额']/10000:.2f}万亿")
disp = df_mg[['日期', '融资余额', '融券余额']].tail(10).copy()
disp['融资余额'] = disp['融资余额'].apply(lambda x: f"{x/10000:.2f}万亿")
disp['融券余额'] = disp['融券余额'].apply(lambda x: f"{x/10000:.4f}万亿")
disp['日期'] = disp['日期'].apply(fmt_date)
st.dataframe(disp.sort_values('日期', ascending=False).reset_index(drop=True),
use_container_width=True, hide_index=True)
# ── 子Tab3: 药师宏观原始指标 ─────────────────────────────────────
with sub_c:
df_sb = read_stock_bond_yield()
st.markdown("**股债收益差**")
if not df_sb.empty:
last_sb = df_sb.iloc[-1]
c1, c2, c3, c4 = st.columns(4)
c1.metric("股债差", f"{last_sb['股债收益差']:.2f}%")
c2.metric("百分位", f"{last_sb['股债收益差百分位']:.1f}%")
c3.metric("PE(TTM)", f"{last_sb['PE_TTM']:.2f}")
c4.metric("日期", fmt_date(last_sb['日期']))
disp = df_sb[['日期', 'PE_TTM', '国债10年', '股债收益差', '股债收益差百分位']].tail(10)
disp['日期'] = disp['日期'].apply(fmt_date)
st.dataframe(disp.sort_values('日期', ascending=False).reset_index(drop=True),
use_container_width=True, hide_index=True)
df_fx = read_exchange_rate()
st.markdown("**人民币汇率(USD/CNY)**")
if not df_fx.empty:
last_fx = df_fx.iloc[-1]
c1, c2, c3 = st.columns(3)
c1.metric("汇率", f"{last_fx['汇率']:.4f}")
c2.metric("百分位", f"{last_fx['百分位']:.1f}%")
c3.metric("日期", fmt_date(last_fx['日期']))
disp = df_fx[['日期', '汇率', '百分位', '沪深300点位']].tail(10)
disp['日期'] = disp['日期'].apply(fmt_date)
st.dataframe(disp.sort_values('日期', ascending=False).reset_index(drop=True),
use_container_width=True, hide_index=True)五、第三步:验证
5.1 语法检查
bash
python -m py_compile 07_信息研究/market_data/reader.py
python -m py_compile 08_知识智能体/web_app.py5.2 独立运行 reader 测试
bash
cd D:\python学习历程\自制项目\02_股票金融分析
python 07_信息研究/market_data/reader.py输出:
=== market_data reader 测试 ===
[OK] 沪深300PE: 5111条, 最新=2026-04-21, 最新值=13.8500
[OK] 国债10年: 6072条, 最新=2026-04-24, 最新值=1.7601
[OK] 融资融券: 3296条, 最新=2026-04-29, 最新值=27124.5532
[OK] 股债收益差: 576条, 最新=2026-04-23, 最新值=14.5500
[OK] 汇率: 2014条, 最新=2026-04-23, 最新值=6.8674
[OK] 市场情绪: 5154条, 最新=2026-04-23, 最新值=6271.1736
=== 腾讯实时行情测试 ===
[OK] sh000300: 沪深300 价格=4807.31 涨跌幅=+0.76%
[OK] sz399006: 创业板指 价格=3677.15 涨跌幅=+3.83%
[OK] sh000001: 上证指数 价格=4112.16 涨跌幅=+1.37%5.3 启动 Web 界面验证
bash
cd 08_知识智能体
streamlit run web_app.py --server.port 8503浏览器打开 http://localhost:8503 → 左侧导航选「📥 数据收集」→ 切换到「📱 公众号/财经」→ 三个子 Tab 均能正常显示数据。
5.4 验证结果表格
| 指标 | 数据源 | 预期值 | 实测值 | 状态 |
|---|---|---|---|---|
| 沪深300PE行数 | HS300PE_history.xlsx | >5000 | 5111 | ✅ |
| 国债10年行数 | china_bond_10y_history.xlsx | >5000 | 6072 | ✅ |
| 融资融券行数 | margin_history_full.xlsx | >3000 | 3296 | ✅ |
| 股债收益差行数 | stock_bond_yield_history.xlsx | >500 | 576 | ✅ |
| 汇率行数 | exchange_rate_history.xlsx | >2000 | 2014 | ✅ |
| 市场情绪行数 | market_sentiment_history.xlsx | >5000 | 5154 | ✅ |
| 腾讯实时-沪深300 | qt.gtimg.cn | 价格>0 | 4807.31 | ✅ |
| 腾讯实时-创业板 | qt.gtimg.cn | 价格>0 | 3677.15 | ✅ |
| reader.py语法 | py_compile | 无错误 | 无错误 | ✅ |
| web_app.py语法 | py_compile | 无错误 | 无错误 | ✅ |
六、常见问题汇总(Q&A)
| # | 问题现象 | 根本原因 | 解决方案 |
|---|---|---|---|
| Q1 | NameError: name 'os' is not defined 在 read_tencent_realtime 中 |
reader.py 顶部忘记 import os,但函数体内用了 os.environ |
在文件顶部加 import os |
| Q2 | Excel 列名显示为乱码(``、PE_TTM) |
openpyxl 默认编码与 Excel 文件编码不一致 | warnings.filterwarnings("ignore") 抑制警告;列名用 df.columns[0] 位置访问而非字面值 |
| Q3 | 腾讯实时无法获取(返回空 dict) | Windows 代理设置干扰内地访问 qt.gtimg.cn | 函数开头清除所有代理环境变量:for k in ['HTTP_PROXY', 'HTTPS_PROXY', ...]: del os.environ[k] |
| Q4 | 融资融券数据量级异常(显示几万亿) | 原始数据单位是元,不是亿元 | 读取后除以 10000 转为万亿:f"{融资余额/10000:.2f}万亿" |
| Q5 | web_app 启动时报 ModuleNotFoundError |
web_app.py 中跨目录 import 没有配套 sys.path.insert |
在 import 语句前加 sys.path.insert(0, str(目标目录)) |
| Q6 | 日期格式不统一(有时 2026-04-21,有时 2026/04/21) |
不同 Excel 文件的日期格式不一致 | 统一用 pd.to_datetime() + strftime("%Y-%m-%d") 转换为字符串 |
| Q7 | read_stock_bond_yield() 数据条数较少(576条 vs 5000+) |
股债收益差数据更新频率低(周频),不是每天更新 | 正常现象,确认最新日期是最新即可 |
七、核心经验总结
-
跨目录 import 必须配套
sys.path.insert:web_app.py引用07_信息研究/market_data/reader.py时,必须在 import 前加路径注入,不能依赖隐式当前目录。 -
Excel 列名乱码用位置访问 :不用字面值匹配,改用
df.columns[0]/df.columns[1]按位置重命名,避免乱码问题。 -
内地 HTTP 请求必须清除代理:Windows 系统代理会干扰 requests 访问 qt.gtimg.cn,在请求前删除所有代理环境变量。
-
统一读取层只做标准化,不做计算:reader.py 的职责是列名映射和日期格式化,不做百分位计算、指标推导等二次处理(留给 web_app 的风险控制 Tab)。
-
数据单位必须确认:融资余额原始数据是"元",转"万亿"要除以 10000;成交额原始数据是"元",转"亿"要除以 1 亿,不能搞混。
八、数据架构图
数据采集脚本(独立运行,按日更新)
yaoshi_api.py → stock_bond_yield_history.xlsx / exchange_rate_history.xlsx
akshare_backup.py → HS300PE_history.xlsx / china_bond_10y_history.xlsx / margin_history_full.xlsx
tencent_realtime.py → HTTP实时 qt.gtimg.cn
↓
统一读取层 07_信息研究/market_data/reader.py
↓
web_app.py tab_d4(展示原始数据,不计算)
web_app.py tab_rk1~rk5(展示计算后的分析指标)