当然不建议将业务逻辑全部写在存储过程里,太难维护了。但是《代码大全》里的表驱动法的话,有些场景还是可以用的。
这两件事看起来有点像,都是把逻辑「外置」到数据库层面,但本质区别很大。存储过程是把程序的执行流程搬到数据库里,而表驱动法是把数据和规则的映射关系存到表里,执行流程还是留在应用代码中。
前者带来的问题远大于收益,后者在特定场景下确实能减少大量的条件判断代码。
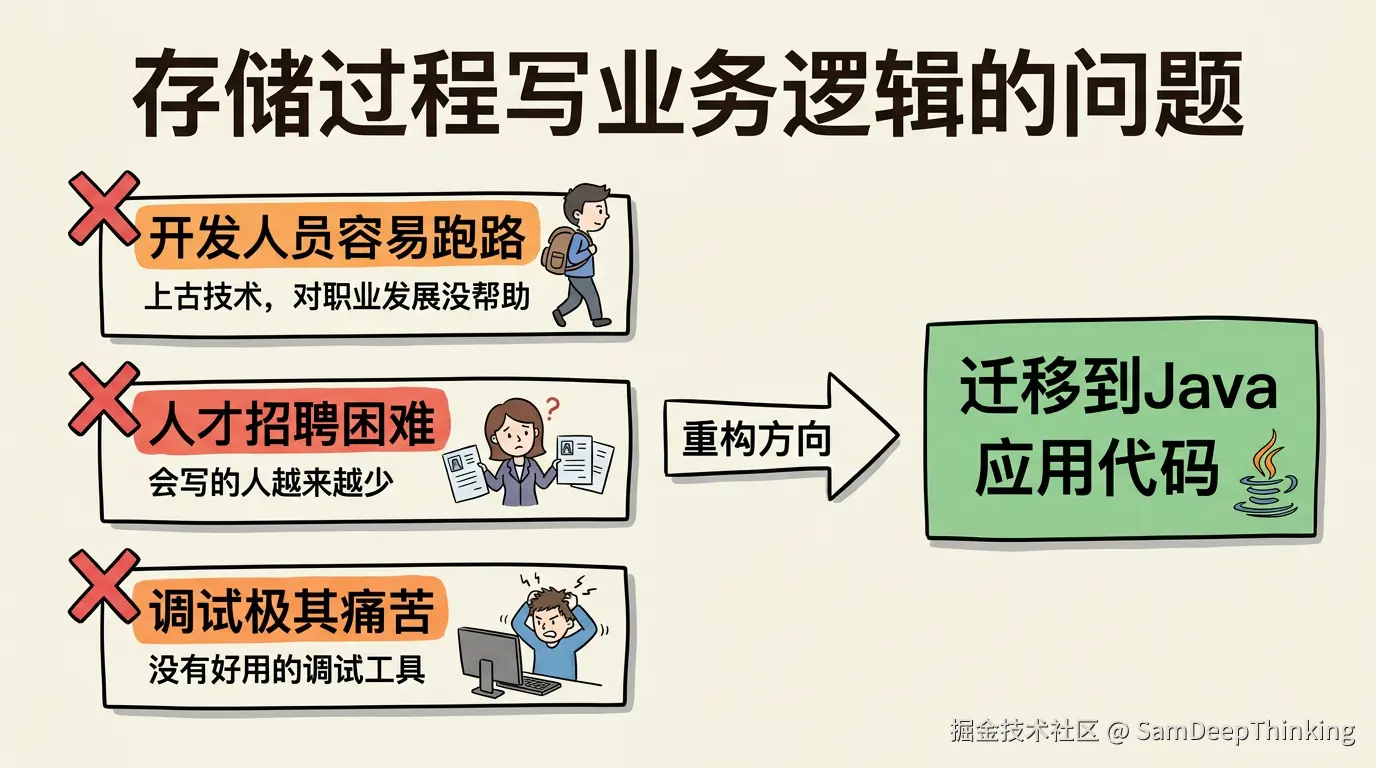
存储过程放业务逻辑的问题
最近帮知识星球里的一个星友出了一套方案,他们公司正在做一件事:把存储过程全部迁移到Java实现。整个项目做了灰度、质检、回滚的全流程设计。
为什么要迁移?他们遇到的问题集中在以下几个方面。
开发人员容易跑路。 存储过程在今天的技术栈里属于上古时代的产物了。开发人员对这类技术普遍比较抵触,一方面是维护难度大,几千行的存储过程改起来提心吊胆;另一方面,这段工作经历对个人职业发展没有任何加分。出去面试的时候,简历上写「维护了三年存储过程」,面试官不会觉得这是亮点。开发人员心里清楚这一点,干一阵子就会想办法跳走。
人才招聘的现实问题。 熟练写存储过程的开发者越来越少了。新招进来的同事面对几千行的存储过程,上手时间远比看Java代码长。知识传承和团队协作的效率都会受影响。
调试极其痛苦。 Java代码在IDE里打断点、看变量、单步执行,整个调试体验很顺畅。存储过程的调试工具不成熟,大多数时候只能靠print日志或者临时插入中间表来观察中间结果。逻辑一复杂,排查问题的效率直线下降。
有人可能会说:CTO的出发点是接口通用化、减少代码发布,这个需求本身没问题,但解决方案选错了。接口通用化可以通过设计良好的API抽象层来实现,减少发布可以通过配置中心和热加载来做。把逻辑下沉到存储过程,表面上少发了几次版,实际上是把复杂度转移到了更难维护的地方。
《代码大全》里的表驱动法
Steve McConnell在《代码大全》第18章专门讲了表驱动法。核心观点是:如果你发现代码里有大段的if-else或switch-case,而这些条件分支的目的只是根据输入查找对应的输出值,那就应该用查表代替逻辑判断。
这跟把逻辑写进存储过程是两回事。表驱动法不是把程序流程搬到数据库执行,而是把「条件→结果」的映射关系存成数据,程序只负责查表。执行流程、异常处理、事务控制这些还是写在应用代码里。
书中给出了三种表的访问方式。

直接访问:每月天数
最经典的例子。如果不用表驱动,计算某个月有多少天,代码是这样的:
Java
public int getDaysInMonth(int month) {
if (month == 1) return 31;
if (month == 2) return 28;
if (month == 3) return 31;
if (month == 4) return 30;
if (month == 5) return 31;
if (month == 6) return 30;
if (month == 7) return 31;
if (month == 8) return 31;
if (month == 9) return 30;
if (month == 10) return 31;
if (month == 11) return 30;
if (month == 12) return 31;
return -1;
}用表驱动法改写之后:
Java
// 月份天数表,索引0对应1月
int[] daysPerMonth = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
public int getDaysInMonth(int month) {
return daysPerMonth[month - 1];
}12个if变成了一次数组取值。这里月份本身就是连续的整数,可以直接当索引用,这就是「直接访问」。
直接访问:保险费率
书中还有一个更复杂的例子。计算医疗保险费率,影响因素有四个:年龄、性别、婚姻状况、是否吸烟。
如果用if-else来写,四个维度的组合会产生大量嵌套条件分支,代码膨胀得厉害,且每次费率调整都要改代码、重新发布。
表驱动的做法是建一个多维数组:
Java
// 费率表:[性别][婚姻状况][吸烟状态][年龄段]
double[][][][] rateTable = new double[2][2][2][48];查询时,把各个维度的值转成数组索引,直接取值:
Java
public double getRate(int gender, int maritalStatus, int smokingStatus, int ageFactor) {
return rateTable[gender][maritalStatus][smokingStatus][ageFactor];
}这里年龄不能直接当索引(17岁以下算一档、18-25算一档这种),需要先做一次区间到索引的转换。转换逻辑本身也可以用表来处理,后面会讲到。
关键的好处是:费率调整时,只需要更新数组里的数值,不用改任何逻辑代码。如果把这个数组的数据源改成数据库表,那连代码都不用重新发布,改数据库记录就生效了。
阶梯访问:成绩等级
有些场景的输入不是离散值,而是一个连续的范围。比如根据考试分数判定等级:
- 90分及以上:A
- 80-89:B
- 70-79:C
- 60-69:D
- 60分以下:F
直接访问在这里不好用,因为分数是0-100的连续值,不可能为每个分数都建一条记录。阶梯访问的做法是,只存每个等级的上限边界:
Java
// 每个等级的分数上限
double[] rangeLimit = {60.0, 70.0, 80.0, 90.0, 100.0};
// 对应的等级
String[] grade = {"F", "D", "C", "B", "A"};
public String getGrade(double score) {
for (int i = 0; i < rangeLimit.length; i++) {
if (score < rangeLimit[i]) {
return grade[i];
}
}
// 满分
return grade[grade.length - 1];
}输入值落在哪个区间,就返回那个区间对应的结果。新增一个等级或者调整分数线,只需要改表数据,不用动逻辑代码。
一个实际项目中的例子:电商平台抽佣
《代码大全》里的例子偏学术化。来看一个真实项目里的场景:电商平台的商家抽佣计算。
业务规则是这样的:不同商家等级、不同商品类目、不同活动期间,平台的佣金费率不一样。如果用if-else来硬编码:
Java
public BigDecimal getCommissionRate(String sellerLevel, String category, boolean isPromotion) {
if ("S".equals(sellerLevel)) {
if ("electronics".equals(category)) {
if (isPromotion) return new BigDecimal("0.02");
return new BigDecimal("0.03");
}
if ("clothing".equals(category)) {
if (isPromotion) return new BigDecimal("0.03");
return new BigDecimal("0.05");
}
// 还有十几个类目...
}
if ("A".equals(sellerLevel)) {
// 又是一大段...
}
// B级、C级...
}四个商家等级、十几个类目、是否促销期,组合起来几十个分支。每次运营调整费率,开发就要改代码、走发布流程。
用表驱动法改造,在数据库里建一张佣金规则表:
SQL
CREATE TABLE commission_rule (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
seller_level VARCHAR(10) NOT NULL,
category VARCHAR(50) NOT NULL,
is_promotion TINYINT NOT NULL DEFAULT 0,
rate DECIMAL(5,4) NOT NULL,
effective_from DATE NOT NULL,
effective_to DATE,
UNIQUE KEY uk_rule (seller_level, category, is_promotion, effective_from)
);写几条数据进去:
SQL
INSERT INTO commission_rule (seller_level, category, is_promotion, rate, effective_from) VALUES
('S', 'electronics', 0, 0.0300, '2026-01-01'),
('S', 'electronics', 1, 0.0200, '2026-01-01'),
('S', 'clothing', 0, 0.0500, '2026-01-01'),
('S', 'clothing', 1, 0.0300, '2026-01-01'),
('A', 'electronics', 0, 0.0500, '2026-01-01'),
('A', 'electronics', 1, 0.0300, '2026-01-01');Java代码变成:
Java
public BigDecimal getCommissionRate(String sellerLevel, String category, boolean isPromotion) {
CommissionRule rule = commissionRuleMapper.selectOne(
new LambdaQueryWrapper<CommissionRule>()
.eq(CommissionRule::getSellerLevel, sellerLevel)
.eq(CommissionRule::getCategory, category)
.eq(CommissionRule::getIsPromotion, isPromotion ? 1 : 0)
.le(CommissionRule::getEffectiveFrom, LocalDate.now())
.and(w -> w.isNull(CommissionRule::getEffectiveTo)
.or()
.ge(CommissionRule::getEffectiveTo, LocalDate.now()))
);
if (rule == null) {
// 没命中规则,走默认费率
return DEFAULT_RATE;
}
return rule.getRate();
}逻辑代码只有一段查询,不管未来加多少种组合规则,代码都不用改。运营要调费率,直接改数据库记录,实时生效。
这就是表驱动法在实际项目中的正确用法:程序负责查表和执行,规则数据存在表里。 程序的执行流程、异常处理、事务边界、参数校验,这些仍然写在Java代码里。数据库只存「什么条件对应什么结果」的映射关系。
跟存储过程完全不一样。存储过程是把整个执行流程、循环、条件判断、异常处理都写到SQL里去了。
判断标准:什么放表里,什么写代码
这个判断其实有一个清晰的边界。
| 特征 | 适合表驱动 | 应该写在代码里 |
|---|---|---|
| 本质 | 数据映射(输入→输出) | 执行流程(步骤、顺序、分支) |
| 变化频率 | 经常变(费率调整、规则变更) | 不常变(核心业务流程) |
| 变更发起人 | 运营、产品(非技术人员) | 开发团队 |
| 复杂度 | 组合条件多但每条规则简单 | 涉及循环、递归、状态机 |
| 例子 | 费率表、权限矩阵、配置项 | 订单状态流转、支付流程、库存扣减 |
一个简单的判断方法:如果你能把这段逻辑画成一张Excel表格,每行是一组条件,最后一列是结果,那它就适合表驱动。如果画不出来,说明这段逻辑包含了流程控制,应该留在代码里。
再给几个典型的适合表驱动的场景:
- 不同地区的税率配置
- 会员等级与对应权益的映射
- 错误码与错误提示信息的对应关系
- 不同渠道来源的分润比例
- 审批流程中的角色权限矩阵
不适合表驱动的:
- 订单从创建到完成的状态流转逻辑
- 库存扣减时的并发控制
- 支付回调的签名验证和幂等处理
- 涉及多个服务调用的编排逻辑
小结
CTO想解决的问题是对的,减少频繁发版、让接口通用化,这些都是合理诉求。问题出在方案上:存储过程不是解决这些问题的正确工具。
从我接触的项目来看,凡是把大量业务逻辑写进存储过程的系统,一两年后几乎都会走向重构。原因也不复杂:软件工程这些年积累的最佳实践,版本控制、单元测试、持续集成、代码审查,在存储过程体系下全部失效或大打折扣。等到系统复杂度上来之后,维护成本的差距会指数级放大。
表驱动法是一个在特定场景下非常有效的替代方案。它解决了「规则频繁变化导致频繁发版」的问题,同时没有引入存储过程那些维护性上的负担。把变化的数据和稳定的流程分开,各自用最适合的方式管理,这是架构设计里值得反复运用的原则。
最近在知乎出了「应付6000万会员的秒杀系统专栏」和「几亿用户,百万并发的C端商品系统实战」专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。「另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。」
知识星球内后续将推出20+个付费专栏,覆盖电商全链路:
| 选购线 | 用户会员营销线 | 中后台 |
|---|---|---|
| 购物车服务 | 营销系统 | 订单系统 |
| 商品服务 | 用户系统 | 支付系统 |
| 菜单服务 | 结算服务 |
从前台选购到中后台结算,星球成员全部免费,后续新增也不额外收费。
我的知乎账号:
- SamDeepThinking