目录
[2.1 预备知识:虚拟内存与物理内存](#2.1 预备知识:虚拟内存与物理内存)
[2.2 共享内存的核心概念](#2.2 共享内存的核心概念)
[2.3 与其他IPC方式对比](#2.3 与其他IPC方式对比)
[三、第二阶段:System V 共享内存](#三、第二阶段:System V 共享内存)
[3.1 核心API详解](#3.1 核心API详解)
[3.2 完整代码示例:生产者-消费者](#3.2 完整代码示例:生产者-消费者)
[3.3 调试命令](#3.3 调试命令)
[四、第三阶段:POSIX 共享内存](#四、第三阶段:POSIX 共享内存)
[4.1 核心API详解](#4.1 核心API详解)
[4.2 System V vs POSIX 对比](#4.2 System V vs POSIX 对比)
[4.3 代码示例:共享计数器](#4.3 代码示例:共享计数器)
[5.1 问题揭示](#5.1 问题揭示)
[5.2 互斥锁(Mutex)](#5.2 互斥锁(Mutex))
[5.3 信号量(Semaphore)](#5.3 信号量(Semaphore))
[5.4 旋转锁(Spinlock)](#5.4 旋转锁(Spinlock))
[5.5 实战:多生产者/多消费者环形队列](#5.5 实战:多生产者/多消费者环形队列)
[5.6 进阶:读写锁](#5.6 进阶:读写锁)
[6.1 memfd_create:匿名共享内存](#6.1 memfd_create:匿名共享内存)
[6.2 零拷贝技术:splice/vmsplice](#6.2 零拷贝技术:splice/vmsplice)
[6.3 大页内存(Huge Pages)](#6.3 大页内存(Huge Pages))
[6.4 持久内存 (PMEM)](#6.4 持久内存 (PMEM))
[7.1 调试工具](#7.1 调试工具)
[7.2 常见问题速查表](#7.2 常见问题速查表)
[8.1 入门:多进程日志系统](#8.1 入门:多进程日志系统)
[8.2 进阶:内存KV数据库](#8.2 进阶:内存KV数据库)
一、引言:为什么我们需要共享内存?
想象一下,如果进程A想把一段数据发送给进程B,使用管道(Pipe)或消息队列(Message Queue)会发生什么?数据需要从用户态缓冲区复制到内核态缓冲区,再从内核态复制到接收进程的用户态缓冲区------这中间发生了两次昂贵的拷贝。
而共享内存的机制完全不同:内核负责开辟一块物理内存区域,然后让多个进程的页表同时映射到这块内存。从此,数据不再"流动",进程们像是在同一张巨大的公共白板 上书写,无需经过内核中转。这就是为什么共享内存是所有IPC机制中速度最快的一种。
学习路线
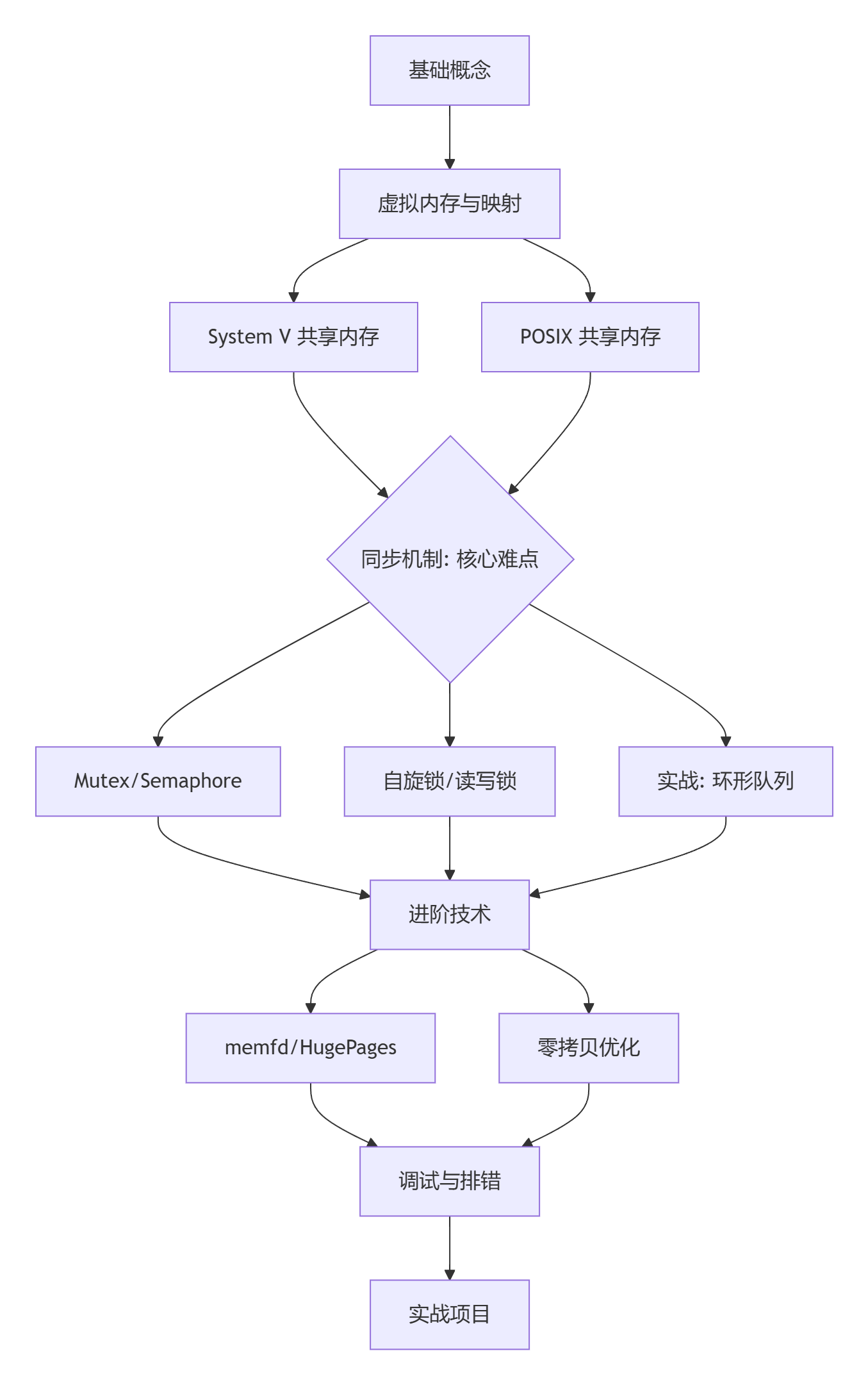
二、第一阶段:基础概念理解
2.1 预备知识:虚拟内存与物理内存
为了理解共享内存,我们必须先搞懂现代操作系统最核心的机制之一:虚拟内存。
城市地图比喻
物理内存(RAM) :就像城市的实际土地。这是有限的,并且每一寸土地都有唯一的物理地址。
虚拟内存 :就像给每个进程发放的一张私人城市地图。在这张地图上,地址从0开始一直到很大(比如2^64)。
页表(Page Table) :这就是城市规划局。它负责把"私人地图"(虚拟地址)翻译成"实际土地坐标"(物理地址)。
关键点 :两个不同进程的虚拟地址可能数值相同(比如都是0x123456),但通过各自的页表翻译后,指向的是完全不同的物理地址。这就实现了进程地址空间的隔离,保证了安全。
2.2 共享内存的核心概念
那么,共享内存是如何打破这种隔离的?
它的本质非常简单:内核强制让两个或多个进程的页表项,指向同一个物理内存页框(Page Frame)。
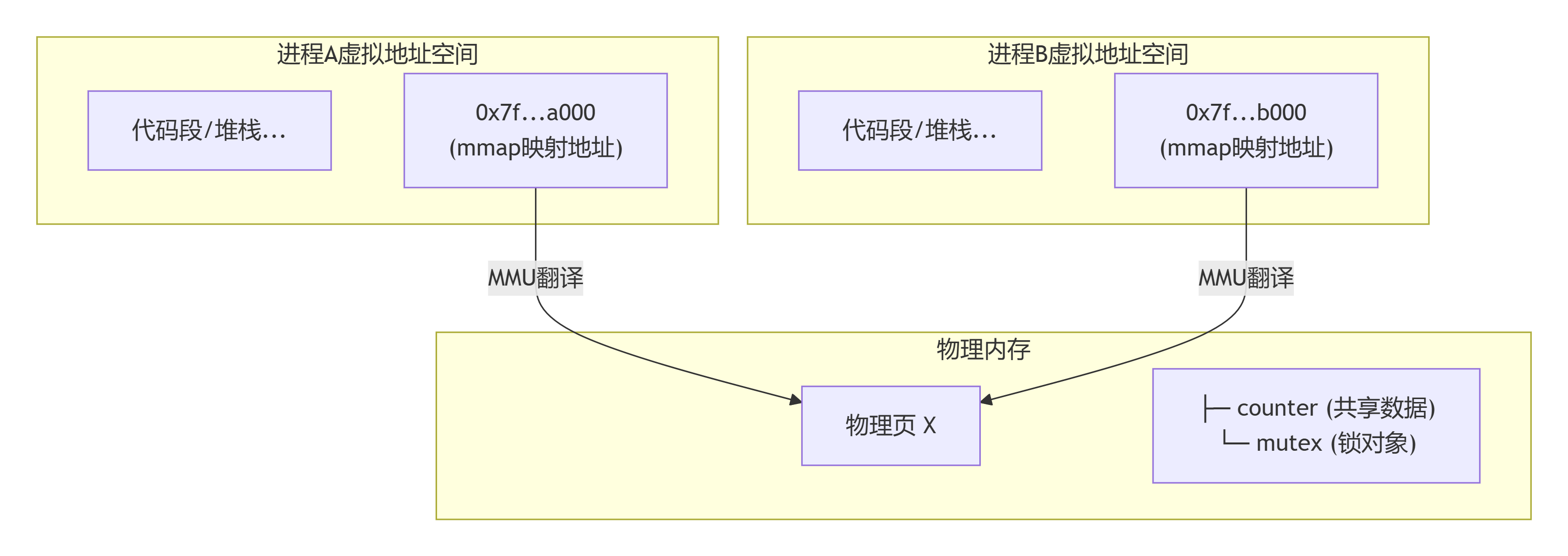
零拷贝原理:
当你使用
memcpy在共享内存中写入数据时,CPU直接操作物理RAM,不涉及任何内核缓冲区的数据移动。相比之下,Socket发送数据至少需要一次DMA拷贝和一次CPU拷贝。
生命周期:
创建:内核分配物理页,生成标识符(ID或文件描述符)。
映射 :进程调用
mmap或shmat,建立虚拟地址到物理地址的关联。使用:进程像访问普通指针一样读写数据。
解除映射 :
shmdt或munmap。销毁:内核释放物理页(这一步容易被遗忘!)。
内核介入时机 :仅在创建、映射和销毁时介入。一旦映射完成,读写操作不经过内核,这也是其速度快的根本原因。
2.3 与其他IPC方式对比
让我们看看共享内存在IPC家族中的地位:
IPC机制 数据拷贝次数 速度评级 适用场景 管道/FIFO ≥2次 ⭐⭐ 简单字节流、父子进程 消息队列 ≥2次 ⭐⭐⭐ 结构化消息、低吞吐 Socket ≥2次 ⭐⭐ 跨主机、通用性强 共享内存 0次 ⭐⭐⭐⭐⭐ 高频、大数据、低延迟 小结 :如果你对性能不敏感,选Socket;如果追求极致性能,共享内存是唯一选择。
三、第二阶段:System V 共享内存
System V是Unix历史上最古老的IPC标准之一,虽然接口略显陈旧,但在很多遗留系统中依然广泛存在。
3.1 核心API详解
System V 共享内存通过四个函数来管理:
shmget()(获取共享内存)
cppint shmget(key_t key, size_t size, int shmflg);key: 类似于文件名。可以使用 IPC_PRIVATE(创建私有、仅亲缘进程可用的内存)或通过 ftok()生成。
size: 内存段大小(通常是页大小的整数倍)。
shmflg: 权限标志(如 0666)及创建标志(IPC_CREAT)。
shmat()(附加到进程地址空间)
cppvoid *shmat(int shmid, const void *shmaddr, int shmflg);shmid: shmget返回的ID。
shmaddr: 建议的挂载地址,通常设为 NULL让内核自动分配。
shmflg: 常用 SHM_RDONLY只读,否则为读写。
shmdt()(分离)
cppint shmdt(const void *shmaddr);注意:这只是解除映射,并不会删除共享内存!
shmctl()(控制)
cppint shmctl(int shmid, int cmd, struct shmid_ds *buf);真正删除内存的命令是
IPC_RMID。即使所有进程都shmdt了,内存依然存在,直到最后一个进程调用IPC_RMID。
3.2 完整代码示例:生产者-消费者
下面是一个使用 System V 共享内存的简单示例。
System V 接口是C风格的,容易出错。这里我们用RAII思想进行封装。
cpp#include <iostream> #include <sys/ipc.h> #include <sys/shm.h> #include <sys/types.h> #include <cstring> #include <cerrno> #include <unistd.h> #define SHM_SIZE 1024 #define SHM_KEY 12345 class SysVShm { public: SysVShm(key_t key, size_t size, bool create = false) : size_(size) { int flags = 0666; if (create) flags |= IPC_CREAT; shmid_ = shmget(key, size_, flags); if (shmid_ == -1) { throw std::runtime_error("shmget failed: " + std::string(strerror(errno))); } addr_ = shmat(shmid_, nullptr, 0); if (addr_ == (void*)-1) { throw std::runtime_error("shmat failed: " + std::string(strerror(errno))); } } ~SysVShm() { if (addr_) shmdt(addr_); } int get_shmid() { return shmid_;} void* get() { return addr_; } private: int shmid_; void* addr_; size_t size_; }; int main(int argc, char* argv[]) { try { // 生产者 if (argc > 1 && strcmp(argv[1], "producer") == 0) { SysVShm shm(SHM_KEY, SHM_SIZE, true); const char* msg = "Hello from Producer! This is a test."; memcpy(shm.get(), msg, strlen(msg) + 1); std::cout << "Producer wrote: " << static_cast<char*>(shm.get()) << std::endl; } // 消费者 else { sleep(1); // 等待生产者写入(简陋同步) SysVShm shm(SHM_KEY, SHM_SIZE); std::cout << "Consumer read: " << static_cast<char*>(shm.get()) << std::endl; // 清理 int ret = shmctl(shm.get_shmid(), IPC_RMID, nullptr); if (ret == -1) perror("shmctl IPC_RMID"); } } catch (const std::exception& e) { std::cerr << e.what() << std::endl; return 1; } return 0; }


3.3 调试命令
System V 的一大优点是提供了现成的调试命令:
cpp# 查看当前系统的共享内存段 ipcs -m # 输出示例: # key shmid owner perms bytes # 0x00003039 32768 user 666 1024 # 手动删除一个共享内存段 ipcrm -m 32768小结:System V 接口简单直接,但缺乏文件系统的灵活性,且大小固定。
四、第三阶段:POSIX 共享内存
POSIX 共享内存是现代Linux推荐的方案,它利用文件系统(/dev/shm)作为命名空间,接口更符合直觉。
4.1 核心API详解
POSIX 共享内存本质上是基于
mmap的:
shm_open()
cppint shm_open(const char *name, int oflag, mode_t mode);name: 共享内存对象的名字(如 /myshm)。注意,在Linux上它实际上是一个文件。
返回值是一个文件描述符(fd)。
ftruncate()
cppint ftruncate(int fd, off_t length);非常重要!刚创建的共享内存大小为0,必须调用此函数设置大小。
mmap()
cppvoid *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);flags: 必须包含 MAP_SHARED。
fd: shm_open返回的描述符。
shm_unlink()
cppint shm_unlink(const char *name);类似文件的
unlink。删除名字,当所有进程munmap后,内存被回收。
4.2 System V vs POSIX 对比
| 特性 | System V | POSIX |
|---|---|---|
| 接口风格 | 专用API (shmget) |
文件式API (shm_open) |
| 大小调整 | 固定,需重建 | ftruncate动态 |
| 调试 | ipcs, ipcrm |
ls /dev/shm, rm |
| 标准 | SUSv2 (较老) | SUSv3/POSIX.1 (现代) |
| 推荐度 | ⭐⭐ | ⭐⭐⭐⭐ |
4.3 代码示例:共享计数器
cpp#include <iostream> #include <fcntl.h> #include <sys/mman.h> #include <sys/stat.h> #include <unistd.h> #include <cstring> #include <atomic> #define SHM_NAME "/my_posix_shm" #define SHM_SIZE sizeof(std::atomic<int>) int main() { int fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666); if (fd == -1) { perror("shm_open"); return 1; } // 设置大小 if (ftruncate(fd, SHM_SIZE) == -1) { perror("ftruncate"); close(fd); return 1; } // 映射 void* addr = mmap(nullptr, SHM_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); if (addr == MAP_FAILED) { perror("mmap"); close(fd); return 1; } // 初始化原子计数器 auto* counter = new (addr) std::atomic<int>(0); // 模拟多个进程增加计数 for (int i = 0; i < 5; ++i) { counter->fetch_add(1, std::memory_order_relaxed); std::cout << "PID " << getpid() << " incremented counter to " << *counter << std::endl; } // 清理 munmap(addr, SHM_SIZE); close(fd); // 只有主进程删除 if (getpid() % 2 == 0) { // 假设父进程清理 shm_unlink(SHM_NAME); } return 0; }小结 :POSIX 接口更优雅,且与文件系统集成,便于管理和调试,是首选方案。
五、第四阶段:同步机制【核心难点】
重中之重 :共享内存本身不提供任何同步机制 !如果你不自己处理同步,就会发生竞态条件(Race Condition)。
5.1 问题揭示
假设两个进程同时执行
counter++:
进程A读取 counter = 10
进程B读取 counter = 10
进程A计算 10+1=11,写回
进程B计算 10+1=11,写回
结果:counter = 11(错误!应该是12)
5.2 互斥锁(Mutex)
在共享内存中使用 pthread mutex,必须设置
PTHREAD_PROCESS_SHARED属性。
cpp// 在共享内存中放置一个Mutex struct SharedData { pthread_mutex_t mutex; int value; }; // 初始化 pthread_mutexattr_t attr; pthread_mutexattr_init(&attr); pthread_mutexattr_setpshared(&attr, PTHREAD_PROCESS_SHARED); pthread_mutexattr_setrobust(&attr, PTHREAD_MUTEX_ROBUST); // 防止进程崩溃导致死锁 pthread_mutex_init(&data->mutex, &attr);死锁预防 :始终按固定顺序加锁,或使用
trylock并设置超时。
5.3 信号量(Semaphore)
信号量比Mutex更灵活,适合控制资源数量。
cpp
sem_open("/my_sem", O_CREAT, 0666, 1); // 初始值为1的二进制信号量,等价于Mutex
sem_wait(sem); // P操作 (加锁)
// 临界区
sem_post(sem); // V操作 (解锁)5.4 旋转锁(Spinlock)
适用场景:临界区极短(几条指令),且不想发生上下文切换。
缺点:忙等(Busy Waiting),消耗CPU。
建议:除非你能证明Mutex是瓶颈,否则优先使用Mutex。
5.5 实战:多生产者/多消费者环形队列
这是一个经典的工业级设计模式。(简单演示)
cpp
#include <semaphore.h>
#include <atomic>
template<typename T, size_t N>
struct RingBuffer {
sem_t sem_empty; // 空位数量
sem_t sem_full; // 数据数量
std::atomic<size_t> head{0};
std::atomic<size_t> tail{0};
T buffer[N];
void init() {
sem_init(&sem_empty, 1, N); // 1表示进程共享
sem_init(&sem_full, 1, 0);
}
void push(const T& item) {
sem_wait(&sem_empty); // 等待有空位
size_t pos = head.fetch_add(1) % N;
buffer[pos] = item;
sem_post(&sem_full); // 通知有新数据
}
void pop(T& item) {
sem_wait(&sem_full); // 等待有数据
size_t pos = tail.fetch_add(1) % N;
item = buffer[pos];
sem_post(&sem_empty); // 通知有空位
}
};5.6 进阶:读写锁
允许多个读者并发,但写者独占。
cpp
pthread_rwlockattr_t attr;
pthread_rwlockattr_init(&attr);
pthread_rwlockattr_setpshared(&attr, PTHREAD_PROCESS_SHARED);
pthread_rwlock_init(&rwlock, &attr);小结:同步是共享内存编程中最难的部分,没有银弹,必须根据业务场景仔细设计。
六、第五阶段:进阶技术专题
6.1 memfd_create:匿名共享内存
memfd_create()创建一个匿名的 文件描述符,可用于mmap。
优势 :没有文件系统残留(不像
/dev/shm下的文件)。用途:进程内部或亲缘进程间通信,传递文件描述符(FD Passing)。
6.2 零拷贝技术:splice/vmsplice
如果你想把共享内存中的数据发送到Socket,通常流程是:
memcpy到缓冲区 ->send()。使用
vmsplice()可以直接将用户空间的内存页"嫁接"到内核管道,再splice()到socket,实现真正的零拷贝。6.3 大页内存(Huge Pages)
问题:TLB(快表)缓存命中率低会导致频繁页表查询。
解决方案:使用 2MB 或 1GB 的大页代替 4KB 小页。
用法 :
mmap(MAP_HUGETLB)。效果:显著降低TLB Miss,提升数据库、虚拟化等场景性能。
6.4 持久内存 (PMEM)
结合
MAP_SYNC标志,可以将数据直接持久化到NVDIMM等设备,实现崩溃一致性。小结:这些技术将共享内存的性能推向了极致,但也伴随着极高的复杂性。
七、调试与排错
7.1 调试工具
gdb :
x/10x addr查看共享内存内容。strace :
strace -e trace=ipc,mmap ./app跟踪IPC调用。perf :
perf stat -e cache-misses ./app分析缓存命中率。
7.2 常见问题速查表
| 问题类型 | 症状 | 解决方案 |
|---|---|---|
| 内存泄漏 | ipcs -m看到大量残留 |
确保调用 IPC_RMID或 shm_unlink |
| 并发冲突 | 数据随机损坏 | 检查同步原语是否正确初始化和加锁 |
| 权限错误 | Permission denied |
检查 shmflg/mode权限位 |
| 跨平台问题 | MacOS 行为不同 | 避免在共享内存中使用复杂C++对象(如std::string) |
| 大小限制 | EINVAL |
检查 ulimit -a中的 shmmax |
八、实战项目建议
8.1 入门:多进程日志系统
构建一个无锁(或低锁)的日志收集器。工作进程将日志写入环形缓冲区,后台进程批量刷盘。
8.2 进阶:内存KV数据库
实现一个基于哈希表的Key-Value存储。挑战在于:如何设计一个支持并发扩容的哈希表?