今天没有大功能上线,但有几件事同时在推进:知识库服务打包合并进主镜像,腾讯会议的体验优化刚提上来等着合版测试,多 Agent 的并发问题还在调,前端拆分引发的一连串连锁反应也在收尾。
说是"最后一天",但代码仓库的提交记录显示,没有人真的停下来。
一、腾讯会议:从"能用"到"好用"
昨天有人提了用户体验不够好,今天腾讯会议这块专门做了一轮优化,已经提交上来,等着合进今天的版本一起测。
改动集中在三个地方:
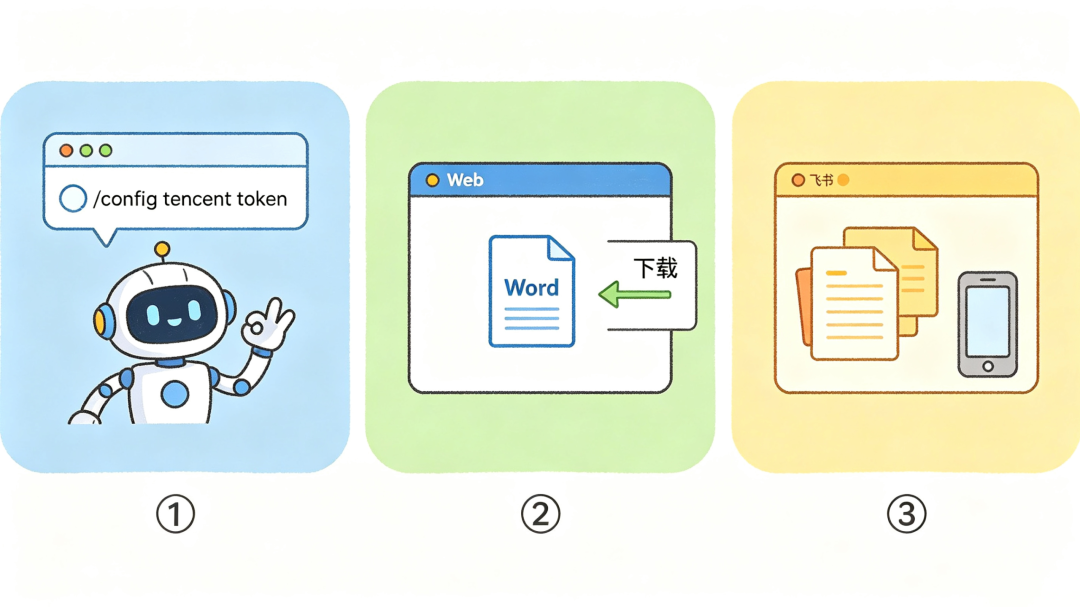
第一,配置门槛降低了。 以前要去后台手动配 token,现在可以直接在聊天窗口里用指令完成配置------对话里说一句,系统帮你把腾讯会议的 token 设置好,不需要跳出去找后台。
第二,转写文件可以直接下载了。 会议结束后,转写内容会被整理成 Word 文件,在 web 端聊天界面右侧直接弹出下载入口,不需要去别的地方找。现在是最小实现路径,文件落在本地服务器,通过下载链接拉取。
第三,飞书端推文件的方式改了。 之前是用文本消息推内容,现在改成用飞书机器人直接推文件类型的消息------飞书内部有一套文件中转机制,机器人拿到 file key 之后,把消息类型改成 file,对方收到的就是一个可以直接点击下载或预览的文件,手机上也能直接操作,体验比纯文本好很多。
这三个改动加在一起,腾讯会议从"功能上有"变成了"用起来顺"。今天的主要测试任务就是把这条链路跑通。
二、知识库的双轨检索,今天要合进主镜像
知识库这边今天在做一件事:把知识库服务打包合进整体部署架构,变成一个镜像包统一管理。打完包之后,要测整体串起来会不会有问题------知识库的接入点、RAG 节点的触发、检索结果的返回,这条链路要完整跑一遍。
顺带说一下知识库现在的检索逻辑,今天会议里说清楚了:它是双轨的。
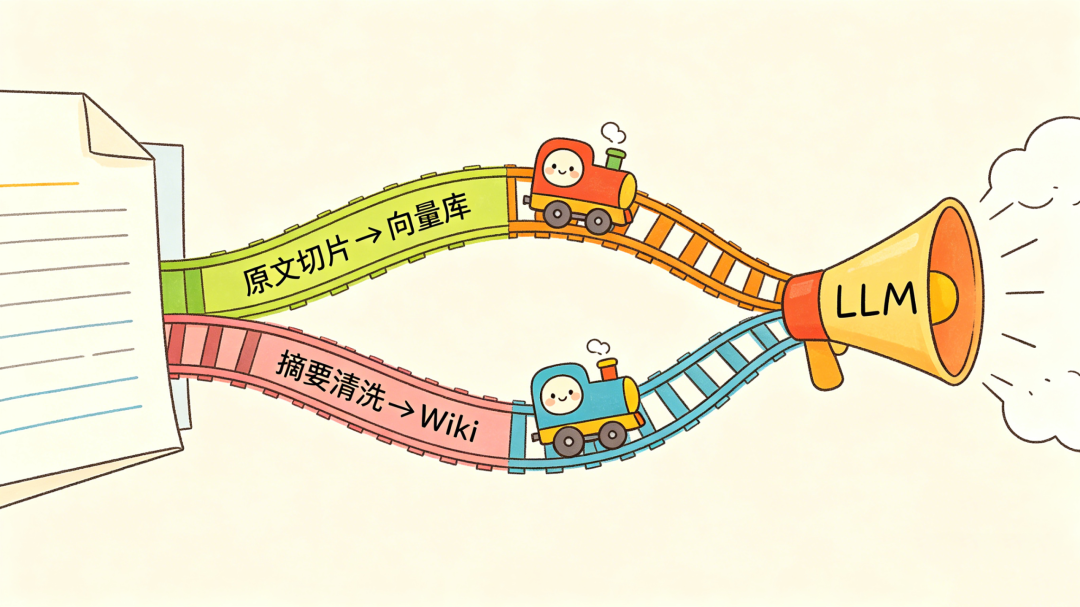
上传一个文件之后,系统会做两件事:一是把原文切片,存进向量数据库,用于语义检索;二是对内容做摘要和清洗,生成结构化的 wiki,用于知识图谱检索。
检索的时候,两条路同时走------原文切片和 wiki 摘要都会被召回,最后由 LLM 决定引用哪部分来回答问题。
这个设计的好处是:原文的细节和摘要的结构各有用处,不互相替代。用户问细节,能从原文切片里找到;问概念,能从 wiki 里找到。
三、多 Agent:合并之后又打回原形
多 Agent 这边,今天的状态是:之前测通的东西,合并完之后又不行了。
并发执行的任务状态不对,有超时,工具超时的时候会把整个任务链路打断------这些问题在合并前都没有,合并后全出来了。

昨晚用 CodeBuddy 修了一整晚,没找到根本原因。
这类问题的特点是:单独跑没问题,合进去就出问题,说明问题出在集成层,不在功能本身。可能是某个状态没有正确传递,可能是某个超时配置在合并后被覆盖了,也可能是并发时的资源竞争。
今天的目标是不管怎样先把并发执行的场景测完提交上去。现在是以编码场景为基准在调,调好之后再扩展到其他场景。
有一点值得说:多 Agent 的图不配置,就路由不到那边去,不影响主流程。 所以即使今天提上来还有问题,也不会影响其他人的使用。
四、前端拆分的连锁反应
前端这边,web 的主文件拆分基本完成了------main.py 和 index.py 按功能模块拆开,测试用例也跟着更新了一遍。
但拆分完之后出了一个典型的连锁问题:
入口文件变成了一个很小的转发文件,原来的测试用例还在引用旧的路径,跑起来全部报错。
AI 发现测试跑不过,第一反应不是去修测试用例,而是想往入口文件里塞转发引用,让旧路径继续能找到方法------这样测试就能过了,但源代码的拆分就被回退了。
这个问题今天被及时叫停:不能为了让测试通过去改源代码,要基于新的源代码结构去更新测试用例。
类似的问题还有一个:在做工具模块迁移的时候,AI 有时候会把方法搬到新位置,然后在原文件里留一个软引用------表面上其他地方还能找到这个方法,但原文件实际上已经是空壳了。这种做法短期内不报错,但会留下隐患,后来发现了就全部改掉了。
这两件事说的是同一个问题:让 AI 做代码重构,要盯着它的策略,不只是看结果。 它有时候会用"让测试通过"或者"让引用不报错"来替代"真正解决问题",这两件事看起来一样,实际上完全不同。
五、热加载有个坑,改完代码一定要重启容器
今天还有一个很实用的提醒被说出来了:
挂载模式下,改完代码不重启容器,运行的还是旧版本。
现在的部署方式是把原文件挂载进容器,不需要每次重新编译镜像。但这不意味着改完代码就能立刻生效------容器必须重启,新代码才会被加载进来。

更隐蔽的问题是:不重启的情况下,代码文件看起来是最新的,但实际运行的是旧版本。如果新代码有语法错误,容器不重启就不会报错,一旦重启才会在启动阶段暴露出来。
这类问题很容易让人误判------明明改了代码,行为却没变,以为是逻辑问题,其实是没重启。
结论很简单:改完代码,不用重新编译镜像,但对应的容器必须重启一次。
六、文件上传限制:从 1MB 调到了 20MB,但还不够
测试过程中发现知识库的文件上传有大小限制,原来是 1MB,已经调到了 20MB。
但 20MB 还是太小------一个长会议的录音转写文件、一份几百页的 PDF,随便一个都可能超过这个限制。
后续要改成全局配置项,统一管理上传限制,不同场景可以单独调整。目标至少支持到 GB 级别,因为企业场景里的文件动辄几百 MB。

七、五一期间,系统自己在跑
今天会议最后说了一句话:大家留着余额,五一期间多发点。
这句话有两层意思。
一层是字面的:五一假期,大家可以多用用系统,发现问题记录下来。
另一层是工程上的:那套 24 小时自动跑的 CI/CD 系统和 Agent Runner,五一期间不需要人盯,它们会自己继续跑。代码仓库有提交就触发测试,测试通过就发版,TODO 列表里的任务也在被逐条消化。
五一 5 天,系统不放假。

五一前没有大功能,但每一件事都在往前推一步。
腾讯会议的体验补上了,知识库在合包,多 Agent 还在调,前端拆分的尾巴在收,热加载的坑被记下来了。
这些事情单独看都不大,但加在一起,是一个系统在慢慢变得更可用、更可靠、更好维护的过程。
五一之后,Base 层的架构讨论要正式开始了。
这,是第十六天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。