RAG是什么?为什么需要RAG
LLM的三大缺陷
先发提问:为什么不让LLM直接回答,非要用RAG?或者换句话说,针对LLM的知识截止日期你怎么看?
知识截止:大模型的训练数据有截止日期,昨天发生的事情他可能不知道,你问他"2026年4月发布的 XX 框架有什么特性",他要么瞎编要么不知道。私有数据无法企及:公司内部文档、业务规则、客户数据等等,这些LLM根本没见过,直接问就是胡说八道。容易幻觉:当LLM不确定但是又想回答时,它会编造看似合理但完全错误的信息。这个问题尤其在没有外部知识验证的时候尤其严重。
举个例子
js
question: 辰俞(假设是笔者)是谁?
没有外部知识库 = 胡言乱语,我是小小高呀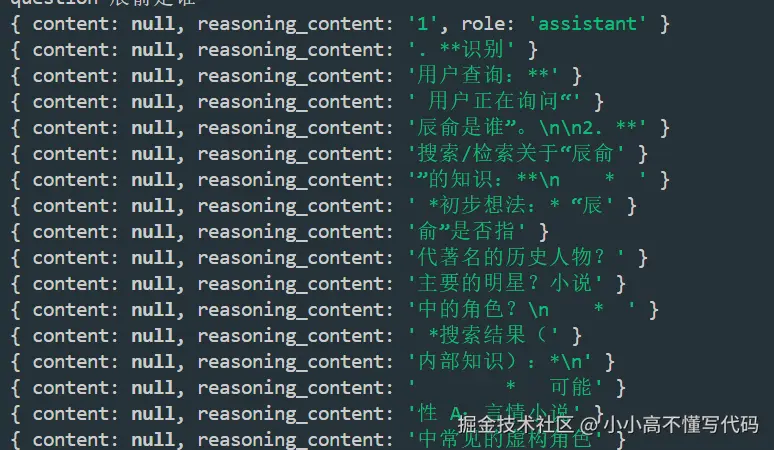
RAG的核心思路
RAG:Retrieval Argumented Generation (检索增强生成)
本质就一句话:在LLM生成回答问题之前*,先从外部知识库检索相关信息,把检索结果塞进Prompt,让LLM基于事实回答
- 没有RAG:用户提问 -> LLM -> 回答(可能幻觉)
- 有RAG:用户提问 -> 检索相关知识 -> 【问题 + 检索结果】 -> LLM -> 回答(基于事实)
核心点:RAG不是代替LLM,而是给LLM补充外部知识。LLM负责理解和生成,RAG负责提供事实依据。
RAG的完整链路是怎样的
先发提问,你了解过RAG,那你说说从用户提问到最终回答的链路吗?
RAG的七步链路
Query → 文档处理 → Chunking → Embedding → 检索 → Rerank → 生成
向量检索的原理
依旧问题先行:向量检索和关键字检索有什么区别?Embedding的原理是什么?为什么语义相似的文本距离那么近?
向量检索的本质
把文本转换成高维空间 中的点,语义相似的文本在这个空间里距离近。检索就是找离问题最近的几个文档向量。
举个例子
markdown
"如何优化首屏加载" -> [0.12, -0.34, 0.56, ...]
"首屏性能优化" -> [0.11, -0.32, 0.55, ...] ← 和上面距离近
"今天天气不错" -> [-0.45, 0.78, -0.23, ...] ← 和上面距离远相似度计算
最常用的就是余弦相似度,及计算两个向量之间的夹角
cos(A,B)=(A⋅B)/(∣A∣×∣B∣)
值域 -1, 1,越大越相似。1 表示方向完全相同,0 表示无关,-1 表示方向相反。
抛个问题出来:为什么不用欧氏距离
一句话概括:Embedding模型编码的是语义方向,而非绝对位置。余弦相似度恰好是衡量方向一致性。但欧氏距离会被向量模长所干扰。
ANN检索(近似最近邻)
当文档量大了(百万级以上),逐个计算相似度太慢,甚至直接卡死。于是就有了ANN检索:
回答ANN之前,因为我是一名前端,我平常经常会使用 牺牲空间换时间 的操作,及缓存Storage换接口请求。
ANN的思路:不要求找到最近的,找到足够近的即可。即 牺牲精度换速度。
举个例子
找到一本【类似机器学习】的书
-
精确NN检索
- 把图书馆的每一本书 全部翻一遍,对比内容,找到最像的
- 结果:太慢
-
ANN
- 先按照 【科技 -> 计算机 -> AI】 分区,只在对应书架找
- 不用完全翻图书馆,快速挑选基本最像的
- 快、够用、误差极小
主流ANN算法
| 算法 | 原理 | 特点 |
|---|---|---|
| HNSW | 多层跳表图,从上层粗搜到下层经搜 | 查询快、内存占用大、Milvus默认 |
| IVF(倒排) | 先聚类,只搜最近的几个蔟 | 可控精度,适合超大规模 |
| PQ(乘积量化) | 压缩向量维度,降低内存 | 内存省,精度有损 |
目前市面上的向量数据库(Milvus、FAISS、Qdarnt)都配备了HNSW做ANN检索
【扩展知识】:HNSW的2个核心参数
- ef_construction:建图时搜索宽度,越高图质量越高但建图越慢
- M:每个节点的邻居数,越大图越密但内存占用大
向量数据库怎么选择?
聊到上面的检索需要将文本块变成向量,那么就必须有一个库将这些向量存下来。目前市面上有三个比较热门的向量数据库:Milvus、FAISS、Qdrant。这三者该怎么选择呢
| FAISS | Milvus | Qdrant | |
|---|---|---|---|
| 类型 | 库 | 数据库 | 数据库 |
| 部署方式 | 嵌入应用进程 | 独立服务,支持分布式 | 独立服务,轻量级 |
| 持久化 | 需自己实现(pickle + s3) | 原生支持 | 原生支持 |
| 适合规模 | 百万级以下 | 亿级 | 千万级 |
| 运维成本 | 低(无额外服务) | 中(需部署集群) | 低(单节点起步) |
| 生产环境 | 适合原型验证 | 适合大规模生产 | 适合中小规模生产 |
纯向量检索有什么问题?为什么需要混合检索?
纯向量检索的三个致命问题
缺乏精确匹配:向量仅靠语义相似度匹配,无法精准命中专属内容。- 像状态码、接口字段、全局变量、组件名、框架 API、配置项等内容,极易匹配偏差。例如查询
407代理错误,纯向量容易误召回 401、403 相关无关内容。
- 像状态码、接口字段、全局变量、组件名、框架 API、配置项等内容,极易匹配偏差。例如查询
专业术语召回差:面对专属缩写、技术名词表现薄弱。- 如查询
React Hooks、Vue 组合式API、TS泛型,向量会优先匹配泛化释义,反而丢失带实操代码、配置细节的核心文档。
- 如查询
专属名词易遗漏:前端框架名、工具别名、自定义指令、工程化术语等短专有词汇,向量辨识度极低,频繁出现漏搜、错搜问题。
混合检索 = 向量检索 + 关键字检索
混合检索同时跑2路
向量检索:抓语义相关的文档("axios"和"错误拦截器"能匹配上)关键字检索:抓精确匹配的文档("http code 407"能精确命中)
两路结果合并,取长补短
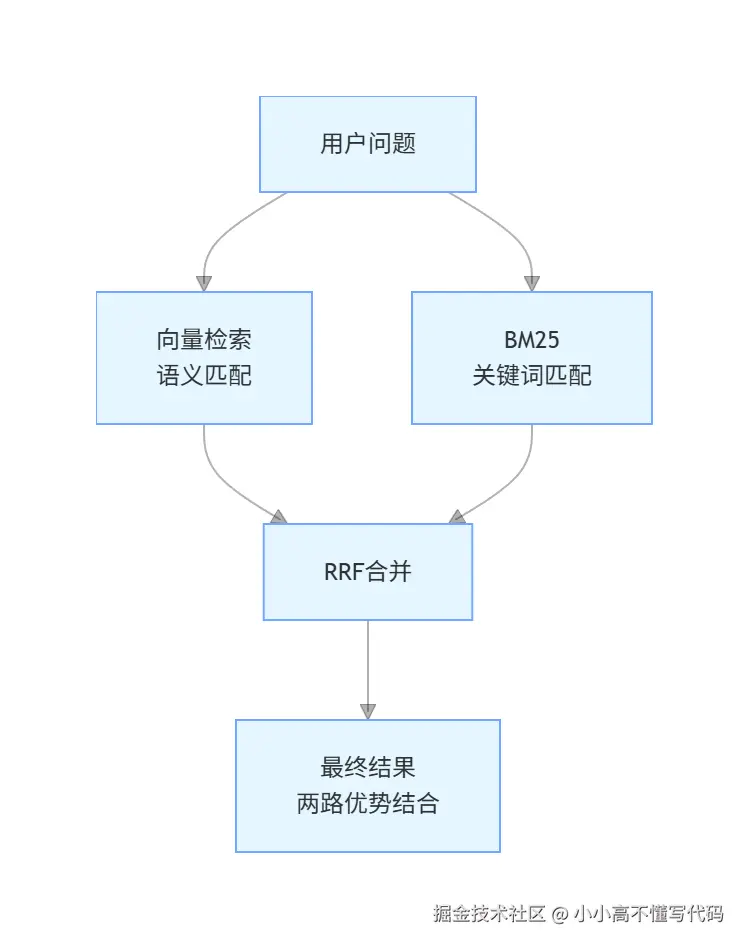
合并策略 RRF
最常用的合并方法,公式很简单:
RRFscore(d)=Σ1/(k+ranki(d))
k 通常设 60,rank_i(d) 是文档 d 在第 i 路检索中的排名。排名越靠前,贡献分数越高。
js
class VectorStore {
/**
* 混合检索:向量检索 + 关键字检索(TF-IDF)
*/
hybridSearch = async (query: string, k: number = 5, vectorWeight: number = 0.7) => {
// 1. 向量检索:获取所有文档的相似度分数
// 2. 关键字检索:计算 TF-IDF 分数
// 3. 融合排序:加权合并
};
}常用混合检索
关键字搜索主要靠BM25进行,那为什么不用 TF-IDF 呢?
TF-IDF的劣势
- 词频 (TF) 无限累加:一段话反复堆同一个词,分数会无限暴涨,造成关键词堆砌作弊。
- 不考虑文档长度:长文档天然词多、TF 高,更容易排前面,不公平。
- 词权重生硬:死板、无上限、不看场景
BM25的优点
- 限制词频上限:同一个词出现再多,分数不再无限增加。
- 惩罚长文档:自动根据文档长度做归一。
- 引入可调节超参,适配中文 / 短文本 / 长文档。
js
import jieba from "nodejieba";
// 简单分词
const tokenize = (text: string) => {
return jieba.cut(text).filter(w => w.trim().length > 1);
}
class BM25 {
/** 分词后的文档集合:docs[docId] = ["词1", "词2", ...] */
private docs: string[][];
/** 原始文档内容(用于返回结果) */
private rawDocs: string[];
/** 词频饱和度:越大词频影响越线性(默认 1.5) */
private k1: number;
/** 长度惩罚因子:0-1,越大长文档惩罚越重(默认 0.75) */
private b: number;
/** 文档总数 */
private N: number;
/** 每篇文档的长度(词数):docLen[docId] */
private docLen: number[];
/** 平均文档长度 */
private avgdl: number;
/**
* 词频表:tf[docId] = Map<词, 出现次数>
* 例如:tf[0].get("FAISS") = 2 表示第 0 篇文档中 "FAISS" 出现 2 次
*/
private tf: Map<string, number>[];
/**
* 文档频率:df.get(词) = 包含该词的文档数
* 例如:df.get("FAISS") = 3 表示有 3 篇文档包含 "FAISS"
*/
private df: Map<string, number>;
constructor(docs: string[], k1: number = 1.5, b: number = 0.75) {
this.rawDocs = docs;
this.k1 = k1;
this.b = b;
// 对所有文档进行分词
this.docs = docs.map((d) => tokenize(d));
this.N = this.docs.length;
// 计算文档长度和平均长度(用于长度归一化)
this.docLen = this.docs.map((tokens) => tokens.length);
this.avgdl = this.docLen.reduce((a, b) => a + b, 0) / this.N;
// 初始化词频和文档频率
this.tf = [];
this.df = new Map();
this.buildIndex();
}
private buildIndex = () => {
for (let i = 0; i < this.N; i++) {
const tokens = this.docs[i];
const wordCount = new Map<string, number>();
// 统计该文档中每个词的出现次数(词频 TF)
for (const w of tokens) {
wordCount.set(w, (wordCount.get(w) || 0) + 1);
}
this.tf.push(wordCount);
// 统计文档频率(DF):该词在多少篇文档中出现
// 用 Set 去重,同一篇文档中多次出现只算一次
for (const w of new Set(tokens)) {
this.df.set(w, (this.df.get(w) || 0) + 1);
}
}
};
getIDF = (word: string) => {
const df = this.df.get(word) || 0;
return Math.log((this.N - df + 0.5) / (df + 0.5) + 1);
};
/**
* 计算单篇文档的 BM25 分数
*/
score = (queryTokens: string[], docIndex: number) => {
let total = 0;
const docLen = this.docLen[docIndex];
const wordMap = this.tf[docIndex];
for (const w of queryTokens) {
// 1. IDF:词的稀缺程度权重
const idf = this.getIDF(w);
// 2. 原始词频
const tf = wordMap.get(w) || 0;
// 如果文档中不包含该词,直接跳过(贡献为 0)
if (tf === 0) continue;
// 3. 长度归一化因子
const lenNorm = 1 - this.b + this.b * (docLen / this.avgdl);
// 4. 饱和后词频
const tfScore = (tf * (this.k1 + 1)) / (tf + this.k1 * lenNorm);
// 5. 累加该词的贡献
total += idf * tfScore;
}
return total;
};
search = (query: string, topK: number = 5) => {
const qTokens = tokenize(query);
// 如果查询没有有效词,返回空
if (qTokens.length === 0) return [];
const res = [];
for (let i = 0; i < this.N; i++) {
const s = this.score(qTokens, i);
res.push({ docId: i, score: s });
}
// 按分数降序排序,取 topK
return res.sort((a, b) => b.score - a.score).slice(0, topK);
}
/**
* 检索并返回带文档内容的结果
*/
searchWithDocs = (query: string, topK: number = 5) => {
const results = this.search(query, topK);
return results.map((r) => ({
...r,
content: this.rawDocs[r.docId],
}));
};
}Rerank是什么?为什么检索之后还要重排?
检索是初筛,从百万甚至千万文档里快速捞出top-20,速度快但精度有限。用向量相似度或BM25打分,这种打分是近似的,不一定反映真实相关性。
Rerank是精排,对top-20重新计算相关性,用更精确的模型(Cross-Encoder)逐个打分,把真正相关的排到最前面
为什么检索的打分不够准
向量检索用的是BI-Encoder:将问题和文档分别编码成向量,再计算相似度。问题和文档再编码时互不知道,所以只能算"大概相关"。
Rerank用的是Cross-Encoder:把问题和文档拼在一起送进模型,模型可以同时看到双方内容,做更精准的判断。代价是慢。因为不能进行预计算,每个问题和文档都要过一遍模型,所以只能对少量候选做精排。
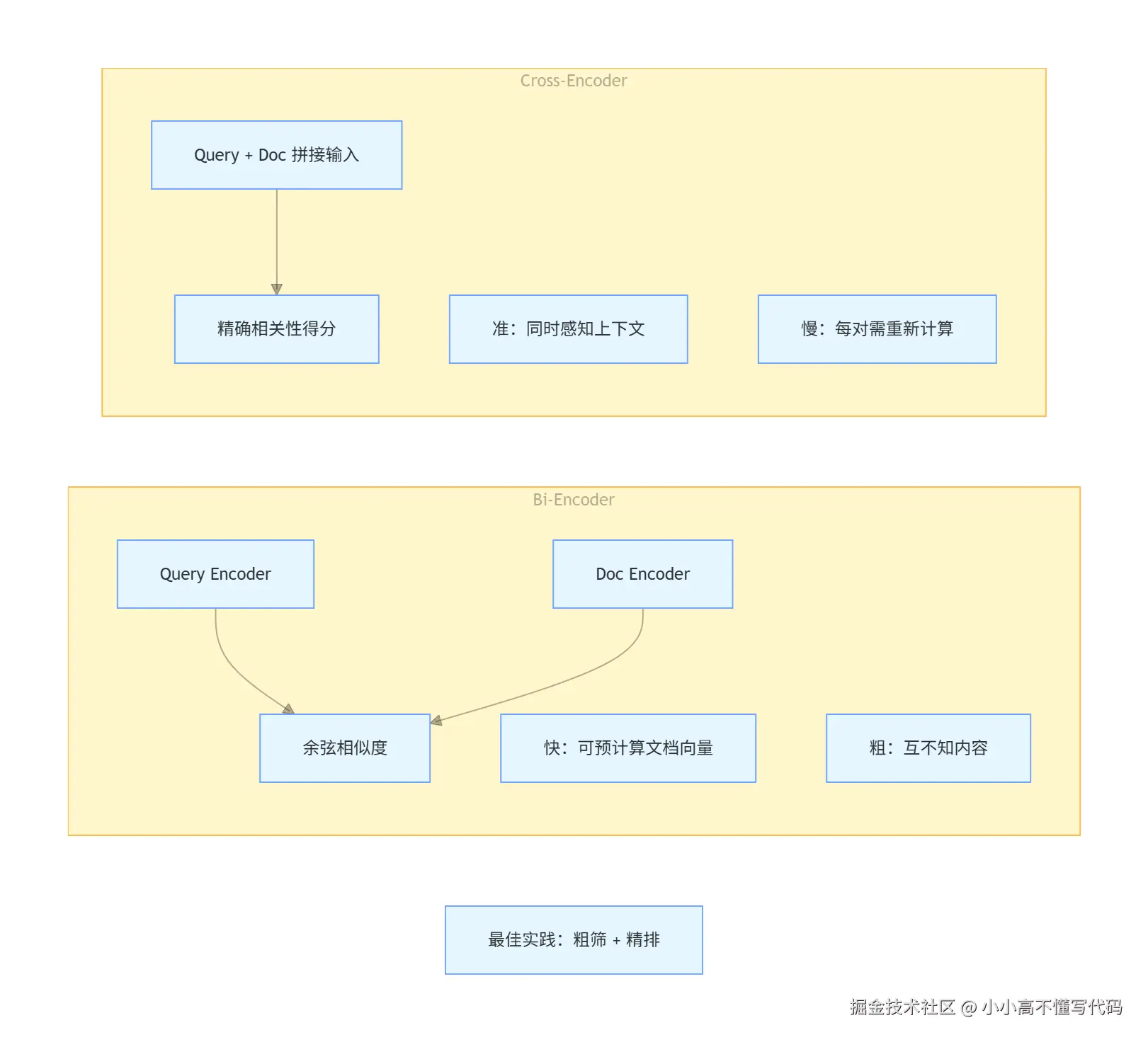
Rerank的效果
在实际项目中,Rerank带来的提升很明显。
| 指标 | 检索无Rerank | 检索有Rerank |
|---|---|---|
| Top-5召回率 | 71% | 89% |
| Top-3准确率 | 65% | 84% |
常用的Rerank模型
| 模型 | 特点 |
|---|---|
| BGE-Reranker (bge-reranker-v2-m3) | 中文效果好,开源免费 |
| Cohere Rerank | API 调用,效果好,英文为主 |
| bce-reranker-base_v1 | 中文场景,轻量级 |
流程大致如下
chunk怎么切?切多大?overlap怎么调?
问题先行:chunk策略怎么设计?chunk size 设置多少?
chunk切大了什么问题
信息稀释:一个chunk里塞了太多内容,检索时真正相关的部分被其他无关内容所淹没,导致相似度降低,排名靠后。
chunk切小了什么问题
上下文丢失:一个完整的论述被切成碎片,检索出来是断章取义的片段,LLM拿到后无法理解完整含义,生成质量下降。
三种主流chunk策略
按照固定长度切:最简单,每512token切一个片段。优点是简单,缺点是不管语义边界,可能把一句话切两半。*递归切分:按照 段落 -> 句子 -> 字符 的优先级进行切分,尽量在自然边界处切段。这是生产环境最常见的方案
js
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 300, // 每块最大长度
chunkOverlap: 60, // 重叠量(防止上下文断裂)
separators: ["\n\n", "\n", "。", "!", "?", " ", ""], // 递归切分符号
});语义切分:用Embedding计算相邻句子的语义相似度,在语义断点处切分。理论上最好,但计算量大,生产环境用的少。
overlap的作用
相邻chunk直接重叠的一部分文字,避免关键信息正好在切割点处被截断。overlap通常设置 chunk_size 的 10% ~20%。
不同文档类型分别怎么处理
| 文档类型 | 处理策略 |
|---|---|
| Markdown | 按标题层级切分,保留标题层级信息 |
| 先解析表格和图片,再按段落切分 | |
| 代码 | 按函数/类切分,保留完整代码块 |
| FAQ | 每个问答作为一个chunk,不要拆开 |
如何切片
加载所需文档(暂定只支持md文件和txt文件)
js
import fs from "fs";
import path from "path";
const loadDocFromDir = (dirPath: string) => {
const supportExt = ['.md', '.txt'];
const documents = [];
const files = fs.readdirSync(dirPath);
for (const file of files) {
const extension = path.extname(file).toLowerCase();
if (!supportExt.includes(extension)) continue;
const filePath = path.join(dirPath, file);
const content = fs.readFileSync(filePath, 'utf-8');
documents.push({
content,
source: file
});
}
return documents;
};切片文档
js
const splitTextWithChunk = (text: string, maxChunkSize: number = 500, overlap: number = 50) => {
// 这里笔者按照段落切
const paragraphs = text.split(/\n\s+\n/);
const chunks: string[] = [];
let currentChunk = '';
for (const paragraph of paragraphs) {
const trimmed = paragraph.trim();
if (!trimmed) continue;
if (currentChunk.length + trimmed.length + 1 > maxChunkSize && currentChunk) {
chunks.push(currentChunk.trim());
// 保留overlap用于上下文完整
const overlapText = currentChunk.slice(-overlap);
currentChunk += overlapText + '\n' + trimmed;
continue;
}
currentChunk += currentChunk ? '\n' : '' + trimmed;
}
if (currentChunk.trim()) {
chunks.push(currentChunk.trim());
}
return chunks;
};加载文档并切片
js
const loadAndSplitDocuments = (docsDir: string) => {
const rawDocuments = loadDocFromDir(docsDir);
const allChunks = [];
for (const document of rawDocuments) {
const textChunk = splitTextWithChunk(document.content);
for (let chunkIndex = 0; chunkIndex < textChunk.length; chunkIndex++) {
allChunks.push({
content: textChunk[chunkIndex],
metadata: {
source: document.source,
chunkIndex
}
});
}
}
return allChunks;
};langchain 原生支持 TextLoader,DirectoryLoader,RecursiveCharacterTextSplitter 可以直接替代上面的函数,有兴趣的可以直接试试。
Embedding模型怎么选?
中文场景主流模型
| 模型 | 维度 | 特点 |
|---|---|---|
| bge-large-zh-v1.5 | 1024 | 中文效果最好,开源,本地部署 |
| bge-m3 | 1024 | 多语言,支持稠密+稀疏+多向量三种检索 |
| text-embedding-3-large (OpenAI) | 3072 | 效果好,但 API 调用有成本,中文不如 bge |
| text-embedding-3-small (OpenAI) | 1536 | 便宜,效果够用,英文场景首选 |
维度越高越好吗
不是。维度高→表达能力强但存储和检索成本也高。1024 维是当前性价比最好的选择,3072 维的检索效果提升有限但存储翻 3 倍。
生成本地向量数据库
FAISS
js
class VevtorStore {
buildFromDocs = async () => {
const chunks = loadAndSplitDocuments(docsDirectory);
const texts = chunks.map((chunk) => chunk.content);
const embeddings = await getEmbeddings(texts);
// 逐条添加到 FAISS 索引
for (const embedding of embeddings) {
this.index.add(embedding);
}
};
}langchain
langchain主要是使用了 MemoryVectorStore 类,在初始化一个实例的过程中进行写入和读取。
js
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
// 这里笔者偷懒了,使用了 ollma
const embeddings = new OllamaEmbeddings({
model: "bge-m3",
baseUrl: "http://localhost:11434",
});
class VectorStore {
// 前文chunk所说的切片文档函数
loadDocuments = async () => {};
init = async () => {
const splitDocs = await this.loadDocuments();
const store = await MemoryVectorStore.fromDocuments(splitDocs, embeddings);
// 写入向量数据
fs.writeFileSync(VECTOR_FILE, JSON.stringify(store.memoryVectors, null, 2));
console.log(`✅ 向量库构建完成,已保存到: ${VECTOR_FILE}`);
};
}RAG的幻觉怎么处理
提问:RAG检索到了正确信息,LLM还是编造了不存在的内容,怎么办?
幻觉的两种类型
内在幻觉:检索到了正确信息,但LLM生成的内容和检索结果矛盾。比如"检索结果说正确率90%",LLM说正确率"80%"外在幻觉:LLM生成了检索结果里完全没有的内容。例如检索结果只提到了A,LLM自己瞎编了B
六种幻觉的处理策略
Prompt约束:在Prompt里明确要求"只能基于检索结果回答,检索结果里没有的不要编造"。输出自校验:LLM生成回答后,再用一次LLM检查,回答的每一条是否都能在检索结果里找到依据?找不到的标注为"未验证"。
js
VERIFICATION_PROMPT = """
请检查以下回答是否每一条都能在参考资料中找到依据。
对于每条声明,标注:✅ 有依据 / ❌ 无依据 / ⚠️ 部分依据
回答:{answer}
参考资料:{context}
"""引用标注: 要求LLM在回答时标注每条信息的来源chunk,便于自查。温度调低:temperature 设置 0.1 - 0.3,降低LLM的随机性,减少"编造的"倾向。检索结果与生成结果的对齐:生成回答后,把回答和检索结果做相似度对比,如果回答中有大段内容和所有检索结果都不相关,大概率是幻觉。兜底回答:当所有检索结果都低于阈值时,直接回答"未找到相关信息",而不是让LLM硬编。
RAG检索效果不好怎么优化
优化思路---从链路的每一步找问题
文档处理阶段:PDF表格提取准确率够不够?图片里的文字有没有OCR?不太格式分别做了哪些适配?Chunk阶段:chunk_size 合不合理?有没有针对不同文档类型进行调参?overlap设置的多少?检索阶段:纯向量检索还是混合检索?top-K设置多少?有没有加 Rerank?生成阶段:Prompt怎么写?幻觉怎么处理?
四种高级优化策略
Query 改写:用户的提问可能表述不清或太短,先用LLM改写成更适合检索的query。
js
原始问题:怎么调优?
改写后:RAG 系统中向量检索准确率低,有哪些优化方法?多路召回:同一个问题用多种方式检索:原问题检索、改写问题检索、提取关键字检索、拆分子问题检索,最后合并结果。Parent-Child检索:检索时用小chunk进行精确匹配,返回时用大chunk保证上下文。小 chunk 存向量索引用于检索,每个小 chunk 关联一个父 chunk,检索命中后返回父 chunk 的完整内容。上下文窗口扩展:检索到一个 chunk 后,把它前后的chunk也带上,保证上下文完整。
Agentic RAG 是什么?和普通RAG有社么区别
普通RAG的局限
普通RAG是固定流程:用户提问 -> 检索一次 -> 生成回答。如果第一次的检索结果不好,它不会自己纠正,直接硬生成。就像一个不会反思的人,说错就错到底。
Agentic RAG: 让RAG自己决定怎么检索
Agentic RAG 把 Agent 的规划能力引入 RAG------LLM 自己判断:需要检索哪些数据源?检索结果够不够?不够就换个角度再检索。
| 普通RAG | Agentic RAG | |
|---|---|---|
| 检索次数 | 固定 1 次 | 动态,LLM 决定 |
| 检索策略 | 固定 pipeline | LLM 自主选择 |
| 结果不满意 | 直接生成 | 换策略重新检索 |
| 复杂问题 | 容易答偏 | 可以拆解子问题分步检索 |
| Token 消耗 | 低 | 高(多次推理) |
Agentic RAG 的工作流程
js
用户问题 → Agent 规划:这个问题需要检索什么?
→ 第一次检索 → 结果不够?
→ Agent 判断:换个 query 再检索
→ 第二次检索 → 结果够了?
→ Agent 判断:够了,生成回答小结
这一篇文章中我们了解了LLM需要RAG进行辅助的原因以及如何去优化RAG。后续我会慢慢的在其他方面进行入手,并深入的了解agent开发。