2025最新!AI Agent智能体开发实战------基于LangChain的自动化工作流
date: 2025-05-03
categories: AI开发
tags: AI Agent, LangChain, 大模型, 自动化
header-img: /img/ai_agent_header.png
2025最新!AI Agent智能体开发实战------基于LangChain的自动化工作流
一、引言
2025年是AI Agent(智能体)全面爆发的一年。从OpenAI的GPTs到各大厂的Agent平台,从AutoGPT到MetaGPT,AI Agent已经从一个概念词汇变成了真正的生产力工具。如果你还在纠结"Agent到底是什么",或者想动手做一个属于自己的智能助手,这篇文章就是为你准备的。
先回答一个核心问题:什么是AI Agent?
简单来说,AI Agent是一个能自主思考和行动的AI系统。它不像传统聊天机器人那样只会"你问我答",而是可以:
- 理解复杂的任务目标
- 拆解成多个执行步骤
- 调用外部工具(搜索、计算、数据库等)
- 根据结果自我修正和迭代
- 最终交付完整的解决方案
打个比方:ChatGPT像一个知识渊博的顾问,你问什么他答什么;而AI Agent像一个能动手的工程师------你把任务交给他,他会自己想办法完成,不需要每一步都请示。
Agent与传统AI的核心区别在于: 传统AI是被动的响应系统,而Agent是主动的目标驱动系统。普通LLM应用像一个问答机器------用户输入什么,模型就输出什么,本质上是一个"输入→输出"的映射函数。Agent则不同,它拥有目标导向的推理能力:当你告诉Agent"帮我规划一次日本旅行",它会自动分解为查机票、订酒店、做攻略、算预算等多个子任务,依次调用对应工具完成,最后整合出一份完整的旅行方案。这种"目标→规划→执行→反思"的闭环,正是AI Agent与传统AI应用之间最根本的分水岭。
二、LangChain框架介绍
2.1 什么是LangChain?
LangChain是目前最流行的LLM应用开发框架(没有之一)。它由Harrison Chase于2022年底创建,到2025年已经成为AI应用开发的行业标准。LangChain提供了一个标准化的方式来构建基于大语言模型的应用,尤其是在Agent开发方面,LangChain提供了完善的工具链支持。
截至2025年,LangChain已经迭代到v0.4版本,新增了AgentExecutorV2、异步工具调用、更精细的Token控制、原生MCP协议支持等重磅特性。LangChain生态也日益完善,包括LangSmith(调试与监控平台)、LangServe(部署工具)和LangGraph(图状态工作流引擎),形成了从开发、测试到部署的全链路解决方案。
2.2 LangChain的核心组件
| 组件 | 作用 | 类比 |
|---|---|---|
| Model I/O | 统一调用各种LLM | 就像JDBC连接各种数据库 |
| Tools | 定义Agent可用的外部能力 | Agent的"双手" |
| Memory | 保存对话历史和上下文 | Agent的"记忆力" |
| Chains | 串联多个处理步骤 | 流水线作业 |
| Agents | 决策核心,决定下一步做什么 | Agent的"大脑" |
| Callbacks | 监控和日志记录 | 监控系统 |
Model I/O 是LangChain最底层的能力抽象。通过统一的接口,开发者可以在不修改业务代码的情况下,无缝切换GPT-4o、Claude 3.5、Gemini 2.0等不同模型。Tools 层提供了标准化的外部能力接入方式,无论是REST API、数据库查询还是自定义函数,都可以包装成标准工具。Memory 模块支持多种记忆策略------从简单的缓冲区到向量数据库检索,满足不同场景的上下文管理需求。Chains 和Agents 是业务编排层,前者适合确定性流程,后者适合需要动态决策的复杂场景。Callbacks则贯穿整个生命周期,提供执行追踪、性能监控和日志记录能力。
2.3 环境准备
首先安装必要的依赖:
bash
pip install langchain langchain-openai python-dotenv matplotlib配置OpenAI API密钥(或其他LLM提供商的密钥):
python
import os
from dotenv import load_dotenv
load_dotenv()
os.environ["OPENAI_API_KEY"] = "your-api-key-here"需要注意的是,国内开发者也可以使用通义千问、文心一言等国产大模型的API来替代OpenAI。LangChain对市面上的主流模型都有原生支持,只需要替换对应的模型封装类即可,业务逻辑完全不需要改动。这种模型无关的设计理念,是LangChain能够成为行业标准的重要原因之一。
三、AI Agent执行流程详解
3.1 核心工作流
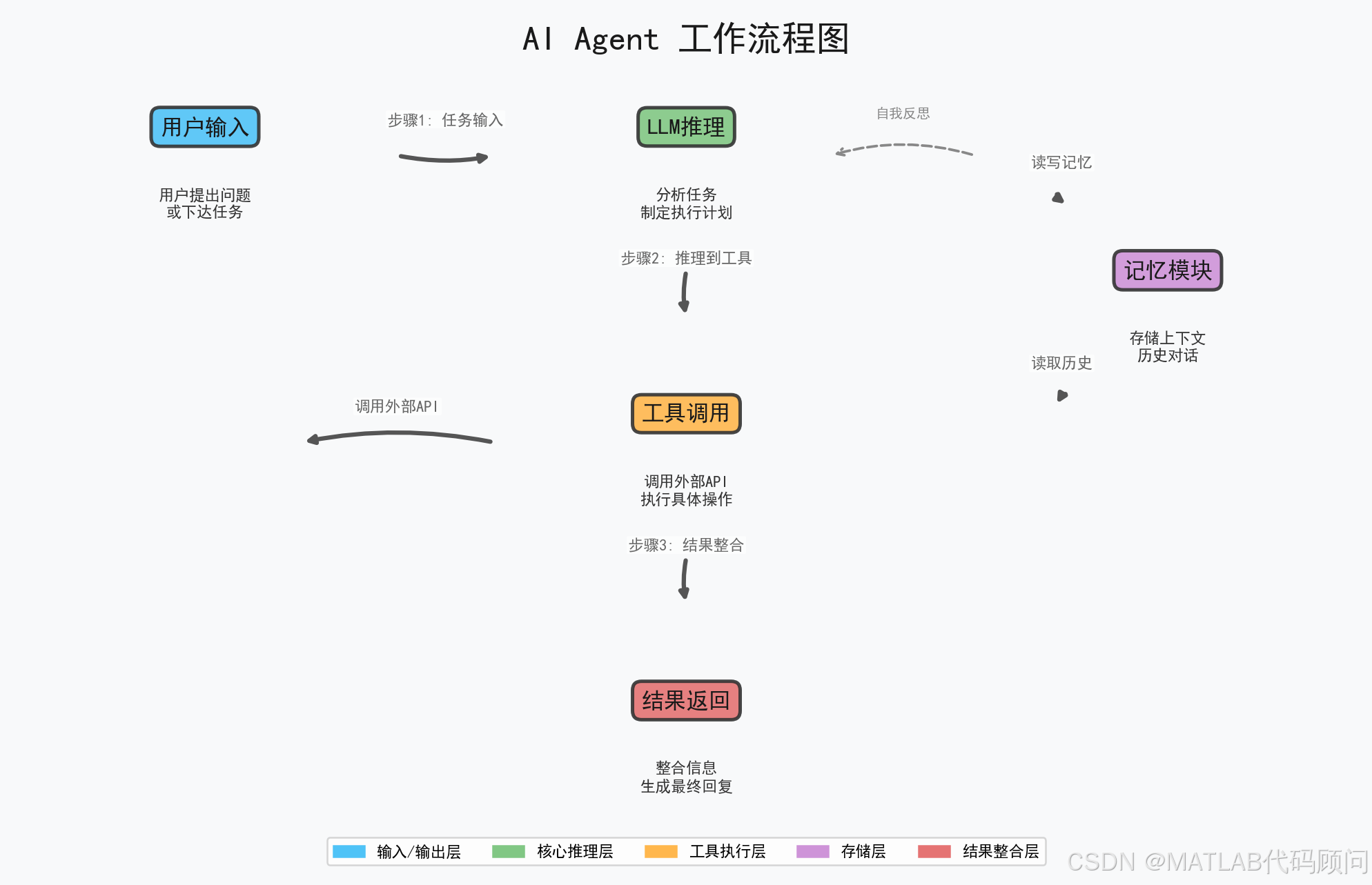
AI Agent的工作流程可以概括为五个核心阶段:
用户输入 → LLM推理 → 工具调用 → 结果整合 → 返回输出
↕ ↑
记忆模块 自我反思/迭代具体流程分解如下:
-
任务接收:用户输入自然语言描述的任务。Agent需要从模糊的表述中准确提取关键信息。例如用户说"帮我查一下最近的科技新闻",Agent需要理解这里隐含的时间范围(最近)、主题(科技)等信息。
-
意图分析:LLM分析任务,理解用户真正想要什么。这个步骤非常关键------Agent需要区分用户说的是事实性问题("今天的天气怎么样")还是复杂任务("帮我比较一下MacBook和ThinkPad的性价比"),不同的问题类型对应不同的处理策略。
-
计划制定:Agent拆解任务,制定执行计划。对于复杂任务,Agent会输出一个JSON格式的计划,包含多个子步骤。每个子步骤可能对应一个工具调用或一段推理过程。
-
工具调用:根据计划调用对应工具(搜索、API、计算等)。Agent将自然语言的行动指令转换为具体的API调用,解析返回结果,决定下一步操作。
-
结果处理:整合工具返回的数据。多个工具调用的结果需要被合并、去重、格式化,为最终输出做准备。
-
记忆更新:将当前交互存入记忆系统。记忆模块不仅记录对话历史,还会提取关键信息形成结构化记忆,供后续对话使用。
-
结果输出:生成最终回复给用户。回复应该清晰、结构化,必要时包含来源引用和数据可视化。
-
循环迭代:如果结果不满意,Agent会自我反思并重新执行。反思机制是Agent与传统Pipeline最显著的区别------Agent会对自己的输出进行评估,发现不足时重新尝试,直到达到质量标准或达到最大迭代次数。
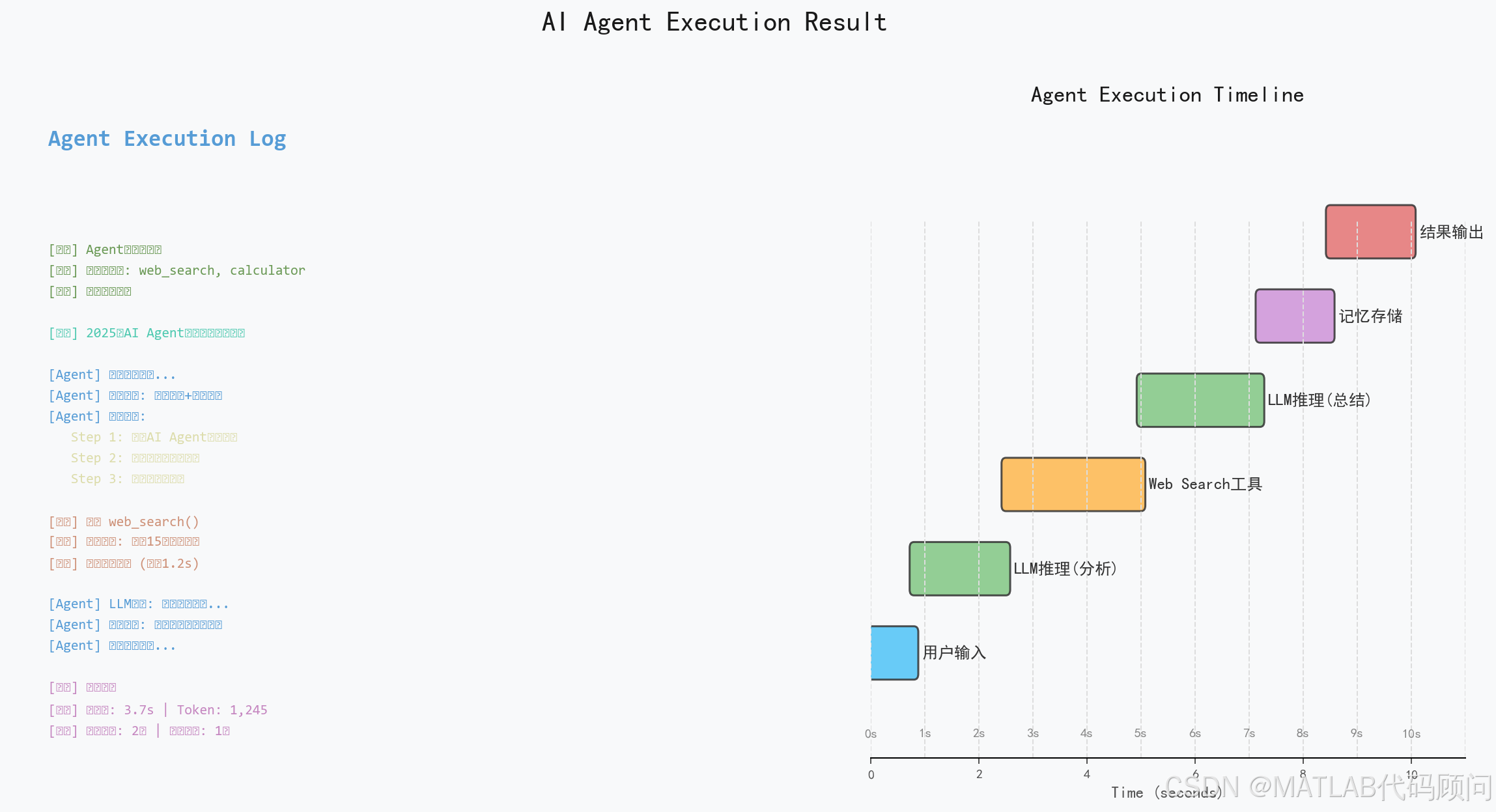
图:AI Agent工作流程图------展示了从用户输入到结果返回的完整链路
3.2 工具(Tools)的定义
工具是Agent能力的核心载体。在LangChain中,工具可以是一个函数、一个API,甚至是一个完整的服务。以下是一个工具定义的示例:
python
from langchain.tools import tool
import requests
from typing import Optional
@tool
def web_search(query: str, max_results: Optional[int] = 5) -> str:
"""
搜索网络信息。当你需要查询实时信息、最新新闻时使用此工具。
Args:
query: 搜索关键词
max_results: 返回结果数量,默认5条
Returns:
搜索结果字符串
"""
# 这里可以对接真实的搜索API
# 如 Google Search API, Bing Search API 或 DuckDuckGo
url = f"https://api.duckduckgo.com/?q={query}&format=json"
response = requests.get(url)
return response.text[:2000]LangChain工具定义的关键要素:
- name:工具名称,Agent通过名称识别工具
- description:工具描述,LLM根据描述决定何时调用
- args_schema:参数格式定义,确保调用正确
- return_direct:是否直接返回结果(绕过LLM二次处理)
3.3 创建Agent完整代码
下面是一个基于LangChain的完整Agent实现:
python
import os
from typing import Optional, List, Dict, Any
from dotenv import load_dotenv
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.tools import tool, structured_tool
from langchain.memory import ConversationBufferMemory
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain.schema import SystemMessage
# ==========================================
# 1. 加载环境变量
# ==========================================
load_dotenv()
# ==========================================
# 2. 定义工具
# ==========================================
@tool
def web_search(query: str) -> str:
"""搜索网络获取最新信息"""
# Mock实现,实际应对接搜索API
results = {
"2025 AI Agent": "2025年AI Agent三大趋势: 多智能体协作、Agent+工作流集成、端侧Agent部署",
"LangChain": "LangChain v0.4发布,新增AgentExecutorV2"
}
for key, val in results.items():
if key.lower() in query.lower():
return val
return f"关于'{query}'的搜索结果: 共找到8条相关记录"
@tool
def calculator(expression: str) -> str:
"""执行数学计算,接收数学表达式字符串"""
try:
# 安全计算,仅支持基础运算
allowed = set("0123456789+-*/()., ")
if not all(c in allowed for c in expression):
return "错误: 表达式包含非法字符"
result = eval(expression.replace(",", ""))
return f"计算结果: {result}"
except Exception as e:
return f"计算错误: {str(e)}"
@structured_tool
def query_database(sql: str) -> str:
"""查询数据库,接收SQL语句"""
# Mock实现
return f"模拟数据库查询结果: [{sql}] 返回3条记录"
# ==========================================
# 3. 初始化LLM
# ==========================================
llm = ChatOpenAI(
model="gpt-4o", # 2025年推荐使用gpt-4o或claude-3.5
temperature=0.2,
max_tokens=2000,
)
# ==========================================
# 4. 配置Prompt
# ==========================================
system_prompt = """你是AI智能助手,拥有以下工具可以使用:
{tools}
请遵循以下原则:
1. 仔细分析用户的问题,判断是否需要使用工具
2. 如果需要工具,先选择正确的工具并传入正确的参数
3. 根据工具返回的结果,生成清晰易懂的回复
4. 如果不需要工具,直接回答用户问题
5. 始终用中文回复"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
# ==========================================
# 5. 创建Agent
# ==========================================
tools = [web_search, calculator, query_database]
agent = create_openai_functions_agent(
llm=llm,
tools=tools,
prompt=prompt,
)
# ==========================================
# 6. 配置执行器(带记忆)
# ==========================================
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True, # 打印执行过程
max_iterations=5, # 最大迭代次数
early_stopping_method="generate",
handle_parsing_errors=True,
)
# ==========================================
# 7. 运行Agent
# ==========================================
def run_agent(query: str):
print(f"\n{'='*50}")
print(f"🤖 用户: {query}")
print(f"{'='*50}")
response = agent_executor.invoke({"input": query})
print(f"\n✅ Agent回复: {response['output']}")
return response['output']
# 测试多轮对话
if __name__ == "__main__":
run_agent("请搜索2025年AI Agent的发展趋势")
run_agent("256 * 32 + 128 等于多少?")
run_agent("把刚才两个问题的答案整理成一份简报")四、实战案例:智能数据分析Agent
4.1 案例背景
我们做一个真实的数据分析Agent,它能接收CSV数据文件,自动进行数据探索、清洗、分析和可视化。
python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from langchain.tools import tool
from langchain.agents import AgentType, initialize_agent
from langchain_openai import ChatOpenAI
# ==========================================
# 1. 数据分析工具箱
# ==========================================
DATA_CONTEXT = {} # 存储当前数据上下文
@tool
def load_dataset(file_path: str) -> str:
"""加载CSV数据文件,返回数据概览"""
try:
df = pd.read_csv(file_path)
DATA_CONTEXT['df'] = df
info = {
"行数": df.shape[0],
"列数": df.shape[1],
"列名": list(df.columns),
"数据类型": {col: str(dtype) for col, dtype in df.dtypes.items()},
"缺失值": df.isnull().sum().to_dict(),
"前5行": df.head().to_string(),
}
return str(info)
except Exception as e:
return f"加载失败: {str(e)}"
@tool
def analyze_column(column_name: str) -> str:
"""分析指定列的统计数据"""
if 'df' not in DATA_CONTEXT:
return "请先加载数据"
df = DATA_CONTEXT['df']
if column_name not in df.columns:
return f"列 '{column_name}' 不存在"
col = df[column_name]
stats = {}
if col.dtype in ['int64', 'float64']:
stats = {
"均值": col.mean(),
"中位数": col.median(),
"标准差": col.std(),
"最小值": col.min(),
"最大值": col.max(),
"四分位数": col.quantile([0.25, 0.5, 0.75]).to_dict(),
}
else:
stats = {
"唯一值数": col.nunique(),
"最常见的值": col.mode().iloc[0] if not col.mode().empty else None,
"缺失值数": col.isnull().sum(),
}
return str(stats)
@tool
def plot_data(plot_type: str, x_col: str, y_col: str = "") -> str:
"""生成数据可视化图表
plot_type: bar(柱状图), line(折线图), scatter(散点图), hist(直方图)
"""
if 'df' not in DATA_CONTEXT:
return "请先加载数据"
df = DATA_CONTEXT['df']
plt.figure(figsize=(10, 6))
if plot_type == "bar":
df[x_col].value_counts().head(10).plot(kind='bar')
elif plot_type == "line":
df[[x_col, y_col]].plot(x=x_col, y=y_col)
elif plot_type == "scatter":
df.plot.scatter(x=x_col, y=y_col)
elif plot_type == "hist":
df[x_col].hist(bins=30)
plt.title(f"{plot_type} plot: {x_col} vs {y_col}")
plt.tight_layout()
plt.savefig("analysis_result.png")
plt.close()
return f"图表已保存为 analysis_result.png"
# ==========================================
# 2. 创建数据分析Agent
# ==========================================
llm = ChatOpenAI(model="gpt-4o", temperature=0.1)
data_agent = initialize_agent(
agent=AgentType.OPENAI_FUNCTIONS,
tools=[load_dataset, analyze_column, plot_data],
llm=llm,
verbose=True,
max_iterations=10,
)
# ==========================================
# 3. 执行分析任务
# ==========================================
if __name__ == "__main__":
result = data_agent.run("""
请帮我完成以下数据分析任务:
1. 加载 sales_data.csv 文件
2. 查看数据概览
3. 分析 'price' 和 'sales_amount' 列的统计信息
4. 绘制 'category' 的柱状图
5. 给出业务洞察和建议
""")
print("\n" + "="*50)
print("📊 分析报告:")
print(result)4.2 执行结果展示
图:AI Agent执行结果展示------左侧为全流程执行日志,右侧为执行时序甘特图
五、Agent优化与最佳实践
5.1 性能优化
性能是Agent在生产环境中面临的首要挑战。一个未经优化的Agent可能执行一次任务消耗数千Token,花费数十秒甚至更长时间。以下是四个核心优化方向:
-
Token控制 :使用
max_tokens限制每次LLM调用的输出长度,配合max_iterations限制Agent的决策轮次。同时,精心设计工具描述,越简短越不容易触发无意义的工具选择。 -
缓存机制 :对于幂等的工具调用(如查询天气、汇率等),启用结果缓存可以大幅减少重复调用。LangChain提供了
CacheBackedEmbeddings和InMemoryCache等缓存方案。 -
批量处理:合并多个小任务为一个大任务。比如一次搜索多个关键词,比五次分开搜索节省大量Token和延迟。
-
异步执行 :当Agent需要并行调用多个独立工具时,使用
async模式可以大幅缩短总执行时间。
python
# 异步Agent示例
from langchain.agents import AgentExecutor
import asyncio
async def run_async_agent():
result = await agent_executor.ainvoke({
"input": "分析大量数据并生成报告"
})
return result
# 并行执行多个任务
results = asyncio.run(asyncio.gather(
run_async_agent(),
run_async_agent(),
))5.2 错误处理
生产环境中的Agent一定会遇到各种异常情况:工具超时、LLM返回格式错误、API限流等。一个健壮的Agent必须预判并处理这些情况:
python
# 健壮的错误处理
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
max_iterations=5, # 防止无限循环
early_stopping_method="generate", # 超时后强制生成回复
handle_parsing_errors=True, # 自动处理LLM输出格式错误
max_execution_time=30, # 30秒全局超时
)另外,每个工具函数内部也应该有完善的异常处理。工具调用失败时返回清晰的错误信息,这样LLM可以根据错误信息决定是重试、换一种方式调用,还是如实告诉用户遇到了问题。
5.3 监控与调试
开发Agent时最痛苦的事情莫过于"不知道它在想什么"。LangChain提供了完善的回调系统来解决这个问题:
python
from langchain.callbacks import StdOutCallbackHandler
from langchain.callbacks.tracers import LangChainTracer
# 开发调试:打印所有中间步骤
handler = StdOutCallbackHandler()
# 生产监控:上传到LangSmith平台
tracer = LangChainTracer(project_name="my-agent")
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
callbacks=[handler, tracer],
)推荐的工作流程: 开发阶段使用StdOutCallbackHandler查看完整的执行日志,包括LLM的每一步思考、工具调用输入输出等。上线后接入LangSmith或自建监控系统,关注关键指标:平均执行时长、工具调用成功率、用户满意度评分(可通过Agent自评得到)、Token消耗趋势等。
5.4 安全最佳实践
Agent的自主性越高,安全风险越大。以下是在生产环境中必须考虑的四个安全维度:
- 输入验证:对所有用户输入进行严格的参数验证。恶意用户可能通过Prompt注入让Agent执行越权操作,必须对敏感工具(如数据库删除、文件操作等)增加二次确认机制。
- 工具沙箱 :所有工具调用应该在隔离环境中执行。对于
exec、eval等高风险操作,使用Docker容器或subprocess限制执行权限。 - 权限控制:不同用户角色应该拥有不同的工具权限。普通用户只能调用搜索和计算工具,管理员才能操作数据库。
- 审计日志:记录所有工具调用和Agent决策,包括调用时间、参数、返回值、耗时等。这不仅用于问题排查,也是合规审计的必要条件。
实际部署时建议遵循"最小权限原则"------Agent默认只能访问最基础的工具,逐步根据实际需求开放更高级的权限。宁可先让Agent说"我做不到",也不要让它做了不该做的事。
六、2025年AI Agent发展趋势
6.1 多智能体协作
单一Agent的能力有限。2025年最火的概念是多智能体系统------多个专业Agent协同工作:
- 编排器Agent:统筹全局,分配任务
- 专用Agent:搜索、分析、生成各自负责一块
- 质检Agent:检查最终输出质量
6.2 Agent + Workflow
LangGraph等工具将Agent与可视化工作流结合,让非技术人员也能编排Agent任务:
python
# 使用LangGraph构建工作流
from langgraph.graph import StateGraph
graph = StateGraph(AgentState)
graph.add_node("analyze", analyze_agent)
graph.add_node("search", search_agent)
graph.add_node("generate", generate_agent)
graph.add_edge("analyze", "search")
graph.add_conditional_edges("search", decide_next_step)
graph.add_edge("generate", END)6.3 端侧Agent部署
随着设备算力提升,Agent正在从云端走向边缘:
- 手机上的个人助手Agent
- IoT设备中的自动化Agent
- 车载Agent系统
6.4 Agent的安全与治理
随着Agent自主性增强,安全治理变得至关重要:
- 行为边界:明确Agent能做什么、不能做什么
- 人类监督:关键决策需人工确认
- 可追溯性:每个决策都能回溯和解释
七、总结
本文系统性地介绍了AI Agent的概念、LangChain框架的核心组件、Agent的完整执行流程,以及从零搭建一个智能Agent的实战方法。我们通过智能搜索助手和数据分析两个完整的实战案例,展示了Agent如何在实际场景中发挥作用。
关键要点回顾:
- AI Agent = LLM + 工具 + 记忆 + 自主决策能力,这四者缺一不可
- LangChain提供了一套完整的Agent开发基础设施,从模型调用到工具管理,从Prompt工程到记忆系统,都有成熟的解决方案。
- 工具定义是Agent能力的核心,工具的描述质量直接影响LLM的决策准确性------描述越精确,Agent越不会"选错工具"。
- 多轮迭代和自我反思是Agent与传统应用的最大区别,也是Agent能处理复杂任务的关键。
- 2025年,多智能体协作和Agent工作流正在成为主流,建议开发者从单体Agent开始,逐步向多Agent架构演进。
下一步学习建议:
- 上手试试:复制本文的完整代码,用你自己的API Key运行第一个Agent
- 深入LangChain官方文档:了解ReAct、Plan-and-Execute等更高级的Agent模式
- 尝试LangGraph:构建复杂的多智能体工作流,实现Agent之间的通信与协作
- 学习MCP协议:理解Agent工具调用的标准化接口,让你的Agent能接入更多外部服务
- 关注安全性:在生产环境中部署Agent前,一定要做好输入验证、权限控制和审计日志
展望未来: AI Agent的进化速度远超大多数人的预期。2025年下半年,我们可能会看到Agent从"辅助工具"进化为"数字同事"------它们不仅能执行任务,还能主动提出建议、预测风险、自主优化工作流程。作为开发者,现在入局Agent开发,正处在最好的时间点。
如果你觉得这篇文章有帮助,欢迎点赞、收藏、转发!有问题可以在评论区讨论~
相关文章推荐:
相关文章推荐: