现在不都是通过流水线去解决这个问题的吗? 不用那么担心了吧。
我自己的AI IDE里配了不少skill,改完让AI跑一套分析和审核,比如说
- impact-analysis(影响面分析)
- codereview
- commit(代码提交)。
这3个skill有一个总的入口skill来串联,配置在SKILL.md里。改完代码后先在「改动点」界面逐个人工审核每处变更,确认没问题剩下全部交给AI了。
另外我会再加上600多行的工程规则文件,告诉AI该怎么写代码,让它按我的风格和标准来。
这套操作下来,对我这种工作多年经验丰富,业务又熟悉的人来说,重构的心理负担基本就没有了。
为什么会有「代码能跑就别动」
大概率都是被坑过。
改代码的风险有三层:
- 改出bug的概率不低。 一个运行了两三年的模块,里面可能有各种隐含的逻辑依赖,有些甚至连原作者自己都忘了。你觉得某段代码写得烂,想优化一下,结果改完之后另一个完全不相关的功能报错了。这种事在大型项目里太常见了。代码之间的耦合关系远比你以为的复杂,改动一个地方引发连锁反应,排查成本极高。
- 验证改动正确性的成本太大。 传统开发环境下,你改完一段代码,怎么确认没改出问题?跑单元测试?很多项目的测试覆盖率不到30%。人肉测试?你只能验证你能想到的场景,想不到的场景就是定时炸弹。找同事帮忙review?大家都忙,能花10分钟看你的代码就不错了,深度审查根本指望不上。
- 出了问题你得背锅。 线上服务挂了,追溯下来是因为你重构了一段「本来跑得好好的」代码,这个责任就是你的。领导不会关心你的重构让代码可读性提升了多少,他只看到:之前没问题,你一改就出问题了。
这几个风险加在一起,正常人都会选择不动。能跑就行。
我的skill工具链
为什么skill粒度要小
我做skill拆分的时候,每个skill只干一件事。比如codereview只管审查,其他的不干,不做大而全的skill。
为什么每个skill只干一件事?粒度小才能复用和组合。
假设你有一个只负责跑单元测试的ut skill,我可以在重构场景里用,也可以在写新功能的场景里用,还可以在修bug之后单独调一下验证。如果把「跑测试+审查+分析影响面」全塞进一个大skill里,那我只想跑个测试的时候,就得忍受一堆不需要的步骤。
这和写代码的道理一样:一个方法只做一件事,才好被不同的地方调用。skill的设计也遵循单一职责原则。
我一直觉得程序员用AI会比其他职业高效很多,原因就在这里。我们天然会用模块化、组合的思维去设计工具链。非程序员可能会想要一个「帮我把所有事情都做了」的大skill,程序员会本能地把它拆成可复用的小模块,然后用一个编排层把它们串起来。
skill清单
这是我实际在用的3个skill:
| Skill | 职责 | 可独立使用 |
|---|---|---|
| impact-analysis | 分析本次变更的影响范围,列出受波及的模块和调用链 | 是 |
| codereview | 审查代码变更的正确性、安全性、性能、可维护性 | 是 |
| commit | 总结变更内容、生成提交信息、确认后执行commit和push | 是 |
每个skill都可以单独用/调用。
总调度skill:一个入口管所有
我不会在写完代码之后,在Agent聊天窗口里依次输入/impact-analysis、/codereview、/commit。那效率不高
我的做法是:在Agent聊天窗口里描述完需求,写完提示词,代码改完之后,只需要输入一个/quality-gate。
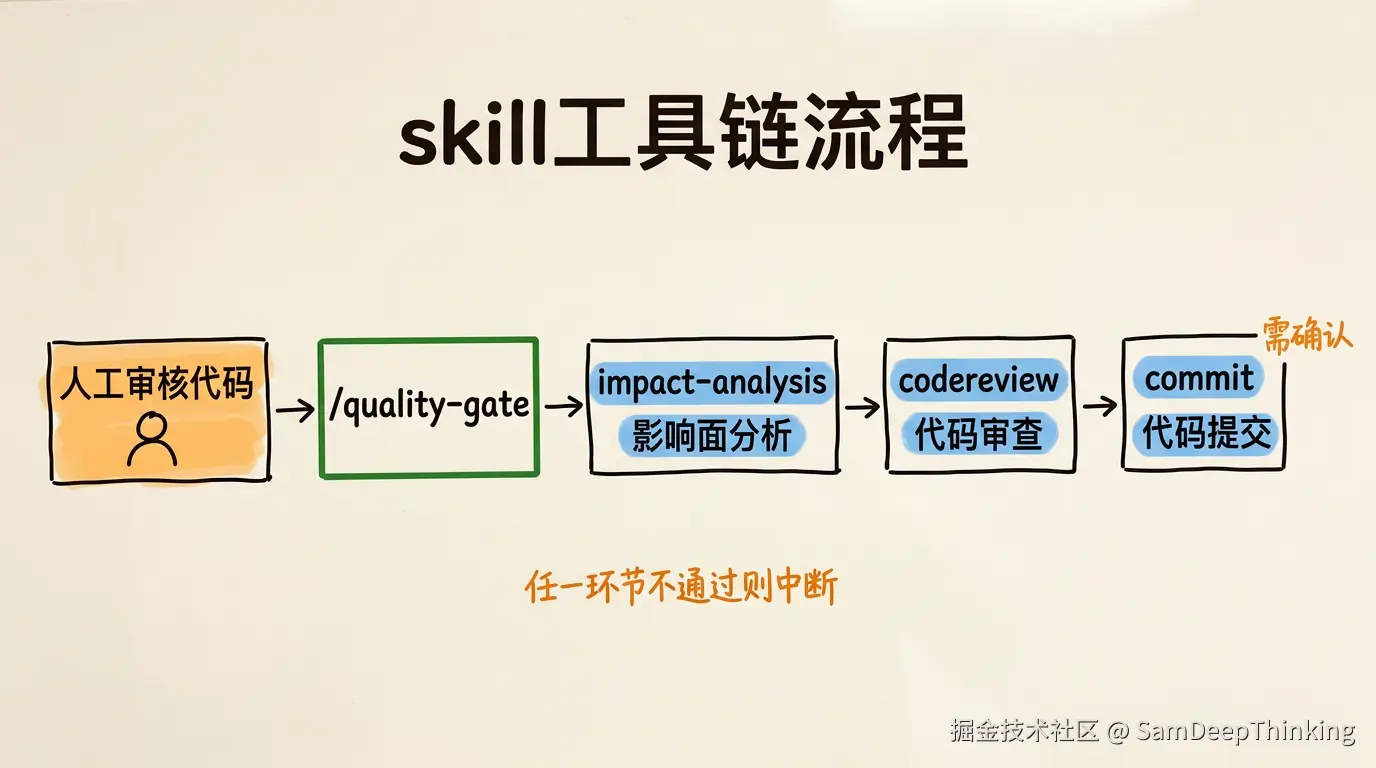
这个quality-gate就是总调度skill,配置在SKILL.md里。它的职责是按顺序调用上面3个子skill,任何一个环节不通过就中断报告问题,全部通过后进入最后的commit环节。
不过在触发quality-gate之前,有一个环节不能省略:人工审核代码。
AI IDE每次帮你改完代码后,都会在界面上展示一个「改动点」面板,你可以逐个文件、逐行diff地查看AI做了哪些修改。这一步必须认真过一遍。AI写的代码大多数时候是对的,但它偶尔会做一些你没要求的多余改动,或者在某个边界条件的处理上不符合你的业务意图。这些问题只有人亲眼看一遍才能发现。
看完所有改动,确认没问题后,在Agent聊天窗口里告诉AI「改动确认,继续」,然后再输入/quality-gate。这样保证进入自动化流水线的代码,已经是你亲眼审核过的。
commit skill不会在所有检查通过后直接帮你提交代码,它会先把本次变更的内容总结出来,生成一条提交信息给你看,等你确认之后才执行。push之前会先pull远程代码,如果有冲突就辅助你解决,解决完再push。整条流程里有三个需要人工介入的点:改完代码后的人工审核、确认commit message、以及确认冲突合并方案。
一个/命令,全套检查跑完,最后确认一下就提交。这就是粒度小带来的好处:每个skill独立可用,同时又能被一个总调度skill编排成流水线。
每个skill具体干什么
impact-analysis是分析影响面的。当然你可以在写代码之前调用也可以在写完代码人工审核后,作为第一个节点去使用。
codereview。codereview关注的是更高层次的东西:这段代码的设计合不合理?有没有安全隐患?性能上有没有坑?可维护性怎么样?这些是机器检查不容易覆盖到的,需要AI从代码审查的角度做一次深度分析。
commit是流水线的终点。它的完整流程是:分析本次变更 → 生成commit message → 弹出确认 → 执行commit → pull远程最新代码 → 如果有冲突则辅助解决 → push。
这里有个细节值得说一下。冲突不是发生在commit的时候,而是push之前pull远程代码的时候。如果你的队友在你改代码的这段时间里也push了新代码,而且改了同一个文件的同一段,pull下来就会产生冲突。commit skill会处理这个情况:检测到冲突后,AI会读取冲突标记,结合你的改动意图和远程的改动内容,给出合并建议。你确认合并方案后,它会提交合并结果,然后再push。
这个skill之所以单独拆出来而不是直接写在quality-gate里,是因为我有时候只想提交代码、不需要跑全套检查(比如改了个README),这时候直接/commit就行。
600行工程规则的作用
Skill只是工具,工具好不好用,取决于你怎么配置它。
我写了600多行的工程规则文件,作用是告诉AI:你在我这个项目里应该怎么干活。没有这些规则,AI会按照它自己的理解来写代码、做审查,结果可能和你的项目风格完全不搭。
规则文件覆盖这几个方面:
代码规范和风格约束。 命名规范、注释风格、方法长度上限、类的职责边界。比如我规定一个方法不超过30行,一个类不超过200行,AI在codereview的时候就会按照这个标准来审查,超了就报出来。
架构约束。 哪些层可以调用哪些层、DTO和Entity之间必须用转换器不能直接赋值、Controller层不允许出现业务逻辑。这些规则让AI在做impact-analysis的时候能够理解你的架构分层,给出更准确的影响范围分析。
测试标准。 单元测试必须覆盖哪些场景(正常路径、边界条件、异常情况)、测试方法的命名规范、mock的使用原则。AI生成单元测试的时候,会严格按照这些标准来,不会生成那种只测happy path的水测试。
质量底线。 哪些问题是必须修复的(比如SQL注入风险、未关闭的资源),哪些是建议修复的(比如可以用更简洁的写法)。codereview的时候,AI会区分severity级别,不会把所有建议都当成必须改的来报。
600多行看起来很多,实际上每条规则都只有一两句话。关键不在于行数多少,而在于覆盖面够不够。你漏掉一条规则,AI在那方面就没有约束。
工程规则和skill是配合使用的。skill决定了能做哪些检查,规则决定了检查的标准是什么。光有skill没有规则,AI不知道按什么标准来审查;光有规则没有skill,规则写得再好也没有执行的载体。
跨多个微服务的需求怎么办
我抛一个问题,如果你的需求是需要一下子修改多个微服务工程的,那你是怎么用AI帮你改,帮你提效的?
最近在知乎出了「应付6000万会员的秒杀系统专栏」和「几亿用户,百万并发的C端商品系统实战」专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。「另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。」
知识星球内后续将推出20+个付费专栏,覆盖电商全链路:
| 选购线 | 用户会员营销线 | 中后台 |
|---|---|---|
| 购物车服务 | 营销系统 | 订单系统 |
| 商品服务 | 用户系统 | 支付系统 |
| 菜单服务 | 结算服务 |
从前台选购到中后台结算,星球成员全部免费,后续新增也不额外收费。
我的知乎账号:
- SamDeepThinking