目录


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》《笔试算法》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、从前序与中序遍历序列构造二叉树
之前在这篇文章的题目当中只通过一种序列就可以构建树,这是因为题目中对空树是有特殊符号"null"作标记的二叉树核心算法分类精讲:选择、遍历与结构关系
现在由于没有对空位置特殊标记,所以就无法直接通过前序构造树了,必须结合两种序列来构建才行,如图所示,没有特殊标记的时候,两颗前序相同的树是无法区分的
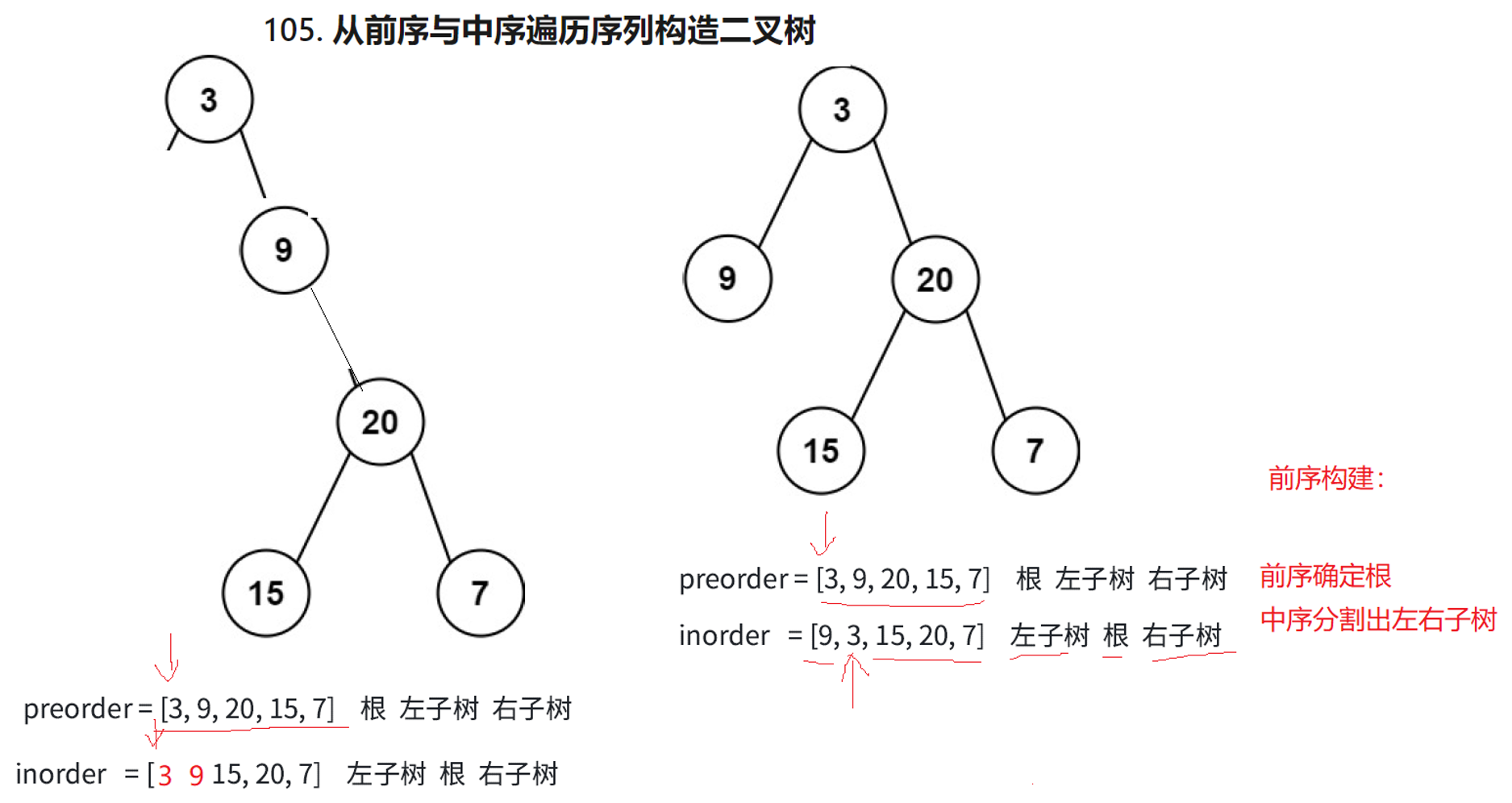
接下来详细讲分析下两个树前序构建的过程,所谓前序构建顾名思义就是先构建根,再构建左子树,最后构建右子树,循环往复。
首先前序根左右确定根为(3),中序左根右就可以分割出左(9),右(15,20,7)子树两段区间,根构建完成之后就要构建左子树,左子树的根也根据前序确定,如图preorder的箭头所指最初指向3,确定了最初的根之后移动到9(因为根左右,9就是左子树的根)
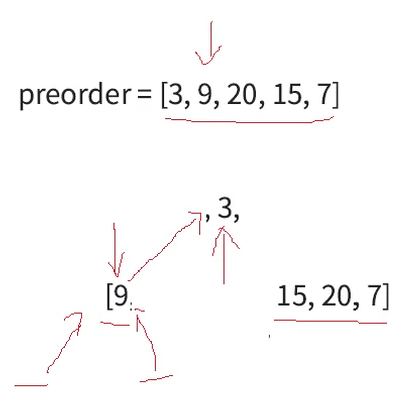
接下来根据中序分割9的左右子树区间,由于9的左右子树区间都没有值,所以为空。
此时前序左根构建完了,接下来构建3的右子树,中序3的右区间有多个值无法确定谁是3的右子树的根,继续按照前序构建规则,用前序确定根,此时由于以9为根的左子树构建完了,箭头继续右移,指向20,根据根左右,20就是右子树的根,再根据中序左根右分割出以20为根的左右区间(15为左,7为右)
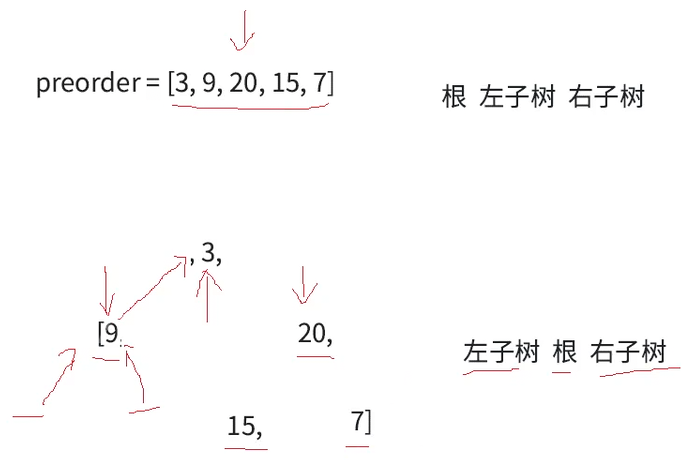
由于20为根已经确定,前序的箭头继续向右挪动一位,判断以20为根的树的左子树的根,根据前序根左右,15就为20的左子树的根,继续根据中序左根右分割以15为根的左右区间(中序15左右区间没有值,为空)
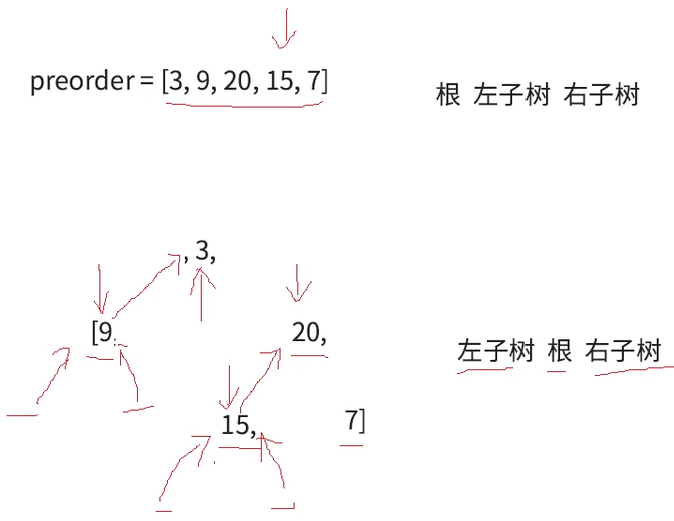
此时以20为根的左树就构建完成,继续递归构建右子树,前序指向15的箭头继续右移指向7,根据前序根左右,7就是右子树的根。再根据中序分割以7为根的左右区间(左右区间没有值,都为空树)
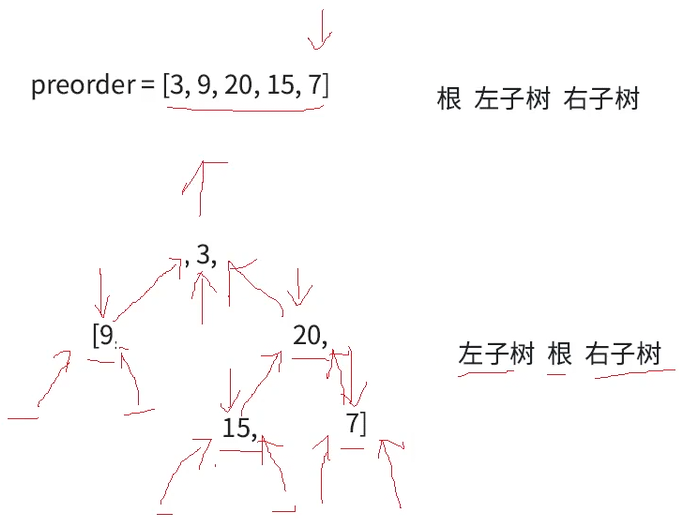
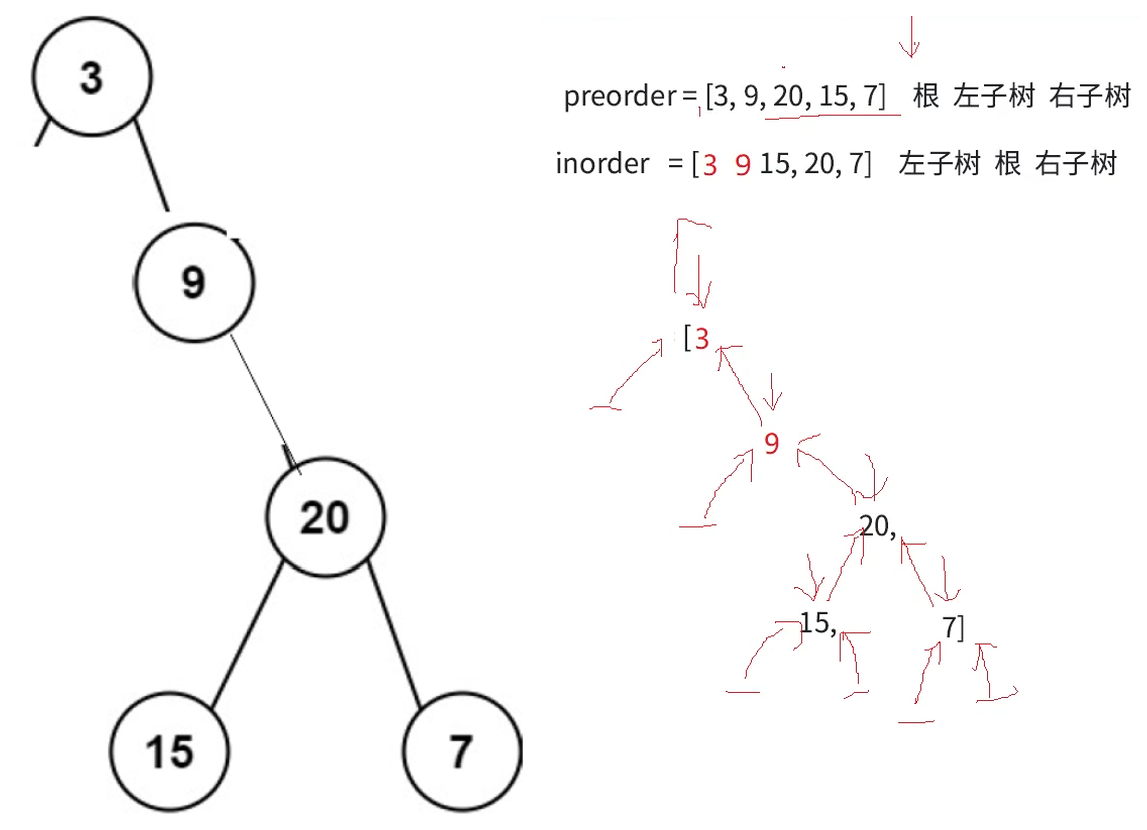
此时整棵树就构建完成了
另一个树的构建方法也是一样
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
//后三个参数依次是前序的下标和中序的区间
TreeNode* build(vector<int>& preorder, vector<int>& inorder, int& prei, int inbegin, int inend)
{
//当遇到不存在的子区间不再构建
if(inbegin > inend)
return nullptr;
//前序确定根
TreeNode* root = new TreeNode(preorder[prei]);
//中序分割左右子树区间
int rooti = inbegin;
while(rooti <= inend)
{
if(preorder[prei] == inorder[rooti])
break;
else
rooti++;
}
prei++;
//[inbegin, rooti - 1] rooti [rooti + 1, inend];
//递归构建左右子树
root->left = build(preorder, inorder, prei, inbegin, rooti - 1);
root->right = build(preorder, inorder, prei, rooti + 1, inend);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int i = 0;
return build(preorder, inorder, i, 0, inorder.size() - 1);
}
};除此之外,还有一个要点就是当遇到不存在的子区间不再构建
如图,中序区间是0 ~ 4,此时的rooti = 0,中序的第一个元素和前序确定的根相等,break。此时rooti - 1 = -1,rooti + 1 = 1,此时的inbegin, rooti - 1就是一个不存在的区间

二、从中序与后序遍历序列构造二叉树
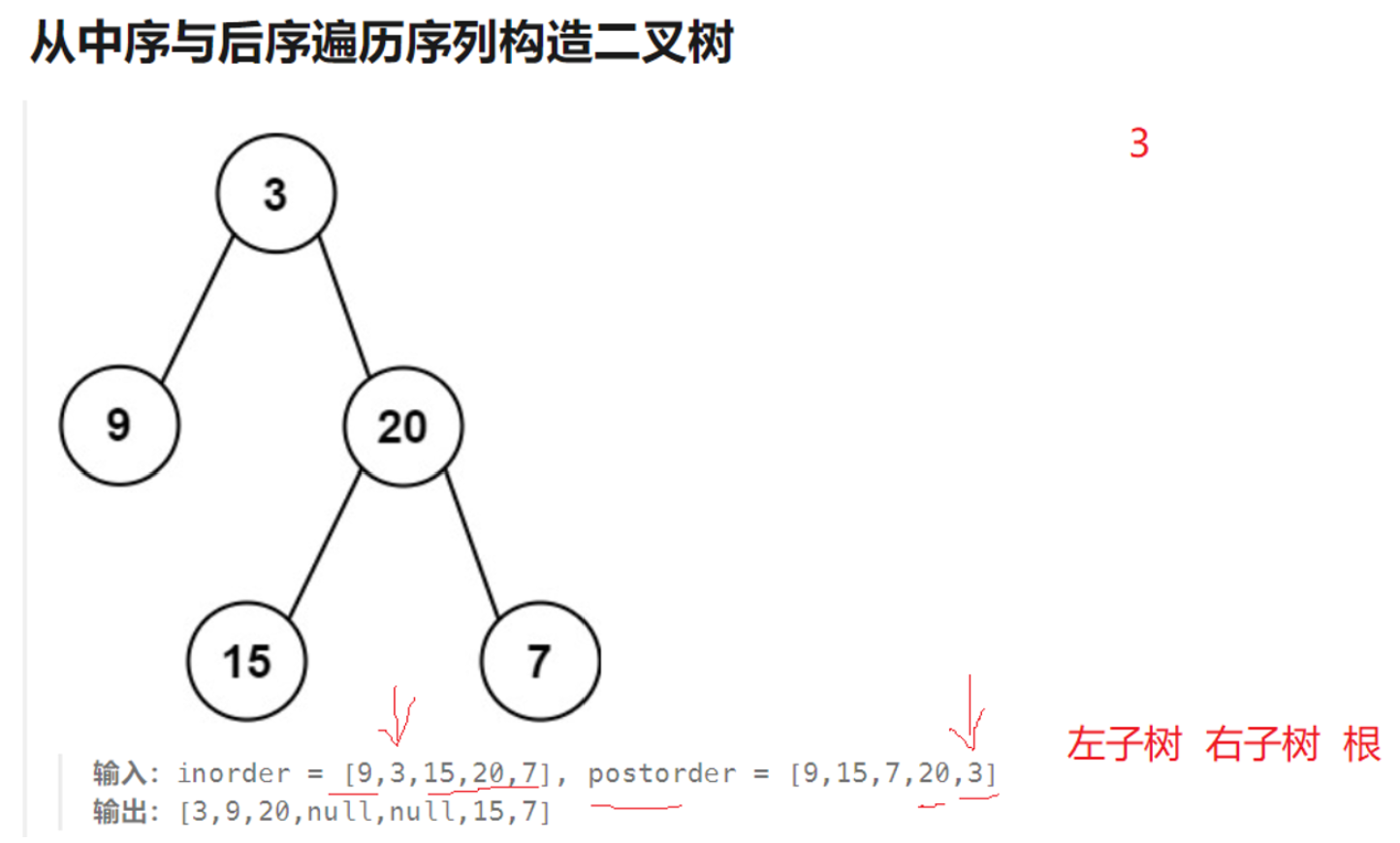
换汤不换药,依旧和前面的题目一样,中序左根右负责分割左右子树区间,后序遍历由于是左右根,所以后序的区间要倒着构建,最后一个数字(3)即是根。然后中序根据3分割出左右子树区间(3 和 15, 20, 7),由于后序的顺序是左右根,所以初始的根构建好之后下一个要构建的就是右子树的根(根据后序来看这个根就是20)。然后以此类推,循环往复,后序倒着确定根,中序分割左右子树区间
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
//指向后序的下标
int i = postorder.size() - 1;
return build(inorder, postorder, i, 0, inorder.size() - 1);
}
private:
TreeNode* build(vector<int>& inorder, vector<int>& postorder, int& posi, int inbegin, int inend)
{
//当遇到不存在的子区间不再构建
if(inbegin > inend)
return nullptr;
//后序确定根
TreeNode* root = new TreeNode(postorder[posi]);
//中序分割左右子树区间
int rooti = inbegin;
while(rooti <= inend)
{
if(postorder[posi] == inorder[rooti])
break;
else
rooti++;
}
posi--;
//中序递归构建右左子树
//[inbegin, rooti - 1] rooti [rooti + 1, inend]
root->right = build(inorder, postorder, posi, rooti + 1, inend);
root->left = build(inorder, postorder, posi, inbegin, rooti - 1);
return root;
}
};三、二叉树的前序遍历(非递归)
首先这道题目的递归写法是非常简单的,如果你按照我的刷题顺序来写的话
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> ret;
dfs(root, ret);
return ret;
}
private:
void dfs(TreeNode* cur, vector<int>& nodes)
{
if(cur == nullptr) return;
nodes.push_back(cur->val);
dfs(cur->left, nodes);
dfs(cur->right, nodes);
}
};但是这道题目要求用非递归来实现,为什么明明可以用递归写,还要学非递归呢?
递归是有一定的缺陷的,原因是如果一个树特别深,这种不断开辟函数栈帧的写法是有可能导致栈溢出的,因为栈这个空间不大,对于Linux/macOS下32位就8MB,Windows下就更小了,默认栈大小1MB,所以非递归也需要懂
递归改非递归主要有两个思路,对于简单的例如斐波那契数列包括归并排序那种都是直接改为循环,复杂一点的非递归核心思路就是需要借助数据结构栈来类似模拟递归过程中栈帧开辟的过程
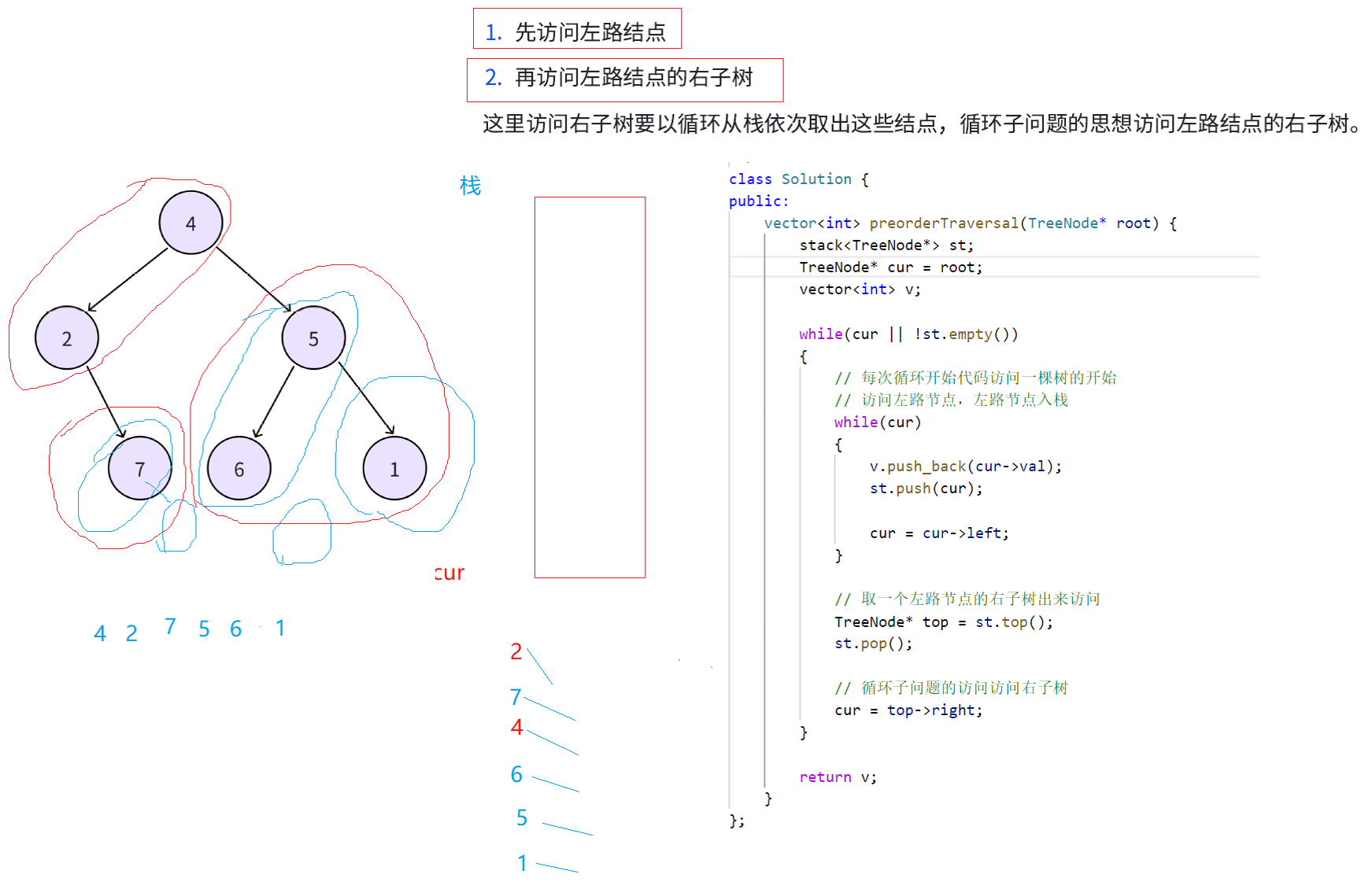
演示一下过程,首先对于一棵树可以先将其分为左路节点(4,2)和左路节点的右子树(7和5,6,1)。现在有一个栈。首先访问左路结点(4,2),同时把(4,2)入栈,这样访问是因为前序一棵树就可以分为先访问左路结点,再访问左路结点的右子树,入栈是因为后续需要取其右树来访问
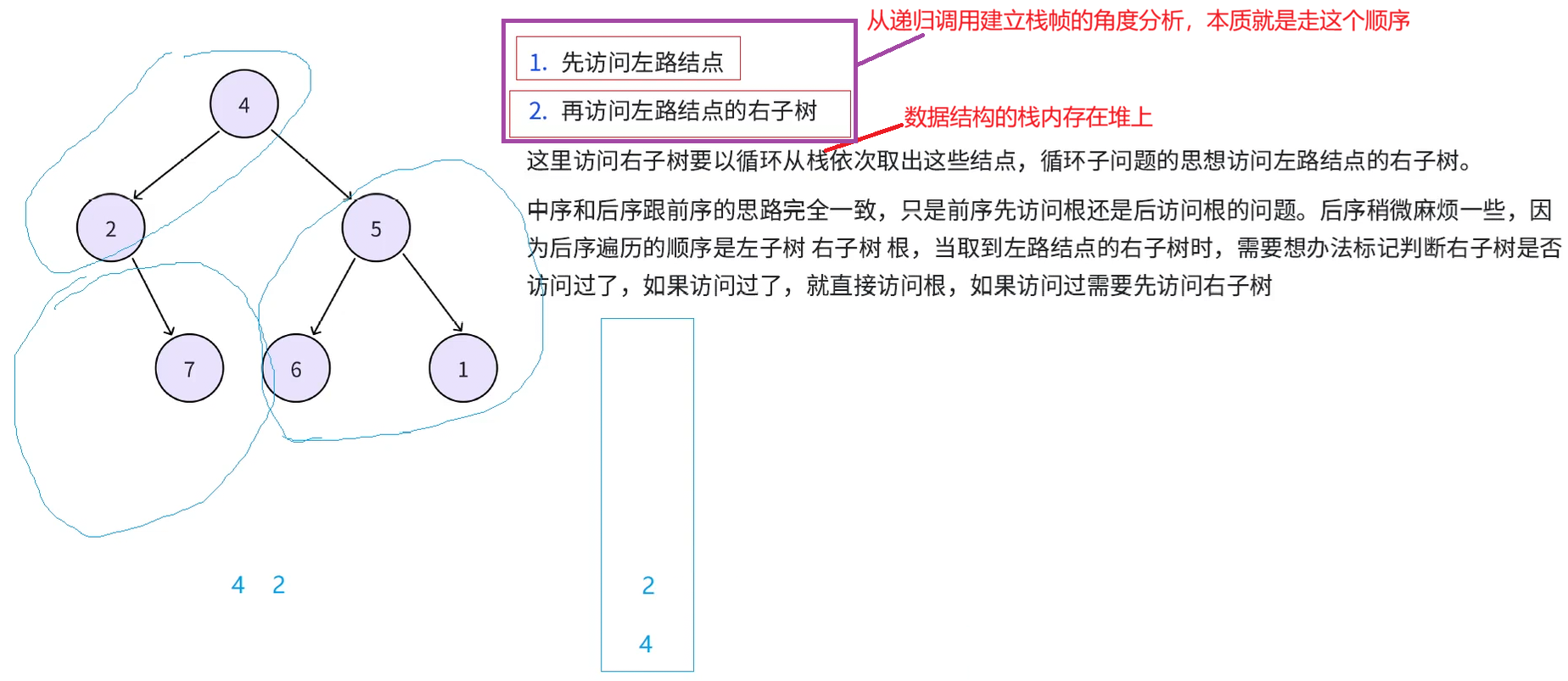
接下来从栈中取出2,然后要访问2的右树,这个过程还是看作一个子问题,2的右树(7)也可以分为左路结点(7)和左路节点的右子树(7的右为空),访问规则还是先访问左路结点(7),左路结点入栈
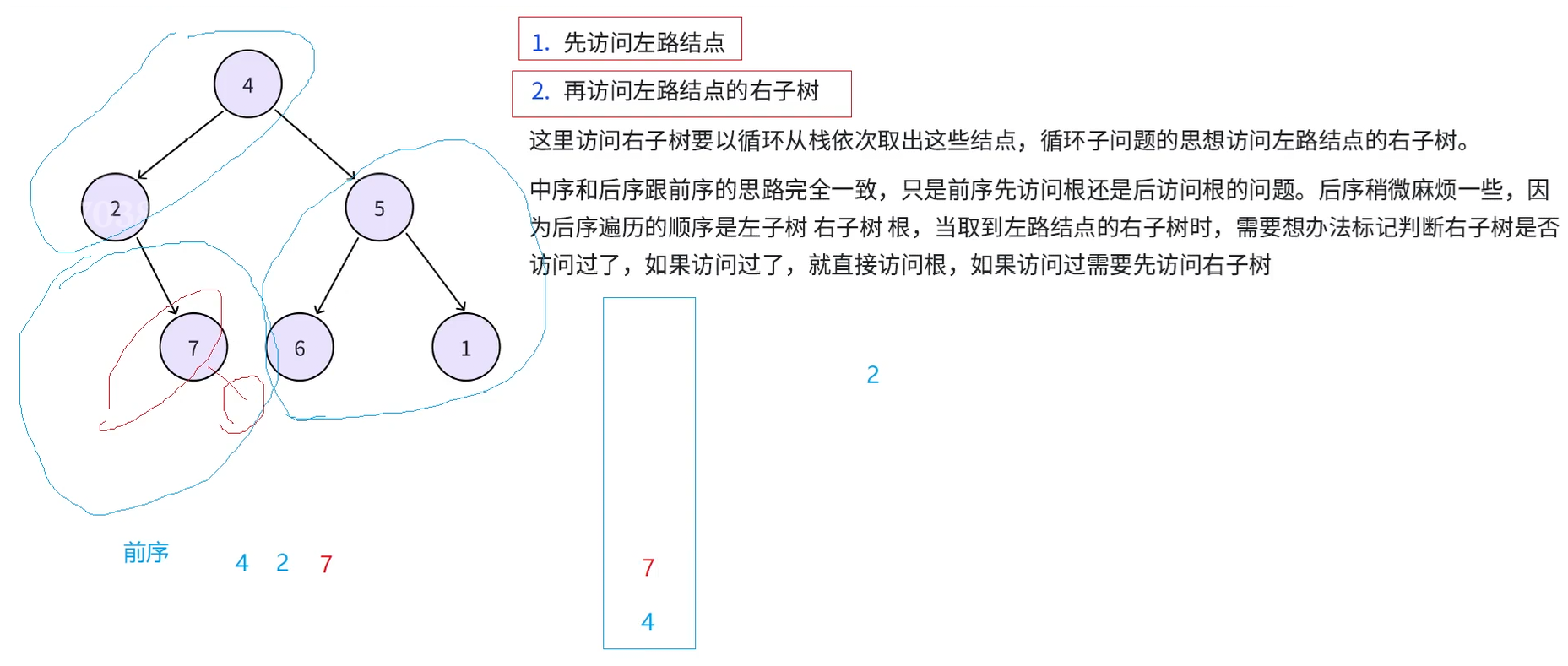
再从栈中取出7,取其右子树来访问,7的右子树是一颗空树,就不需要访问了,接下来由于左路结点7访问了,左路结点7的右子树也访问完了,就认为这棵树访问完了。
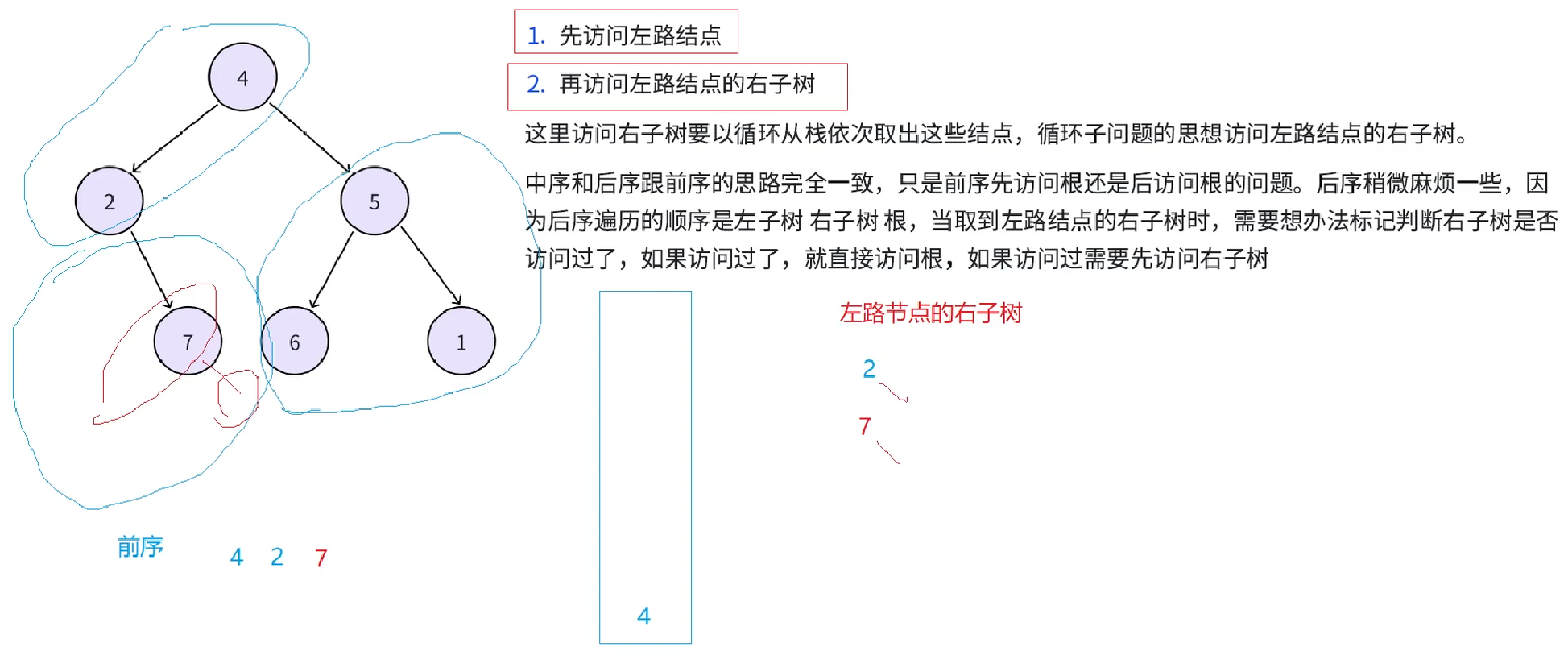
接下来再从栈中取4,就要访问4的右子树,4的右子树也分为两个部分,左路结点(5,6),左路节点的右子树(6的右:空和5的右:1)。接下来先访问左路结点(5,6),(5,6)入栈
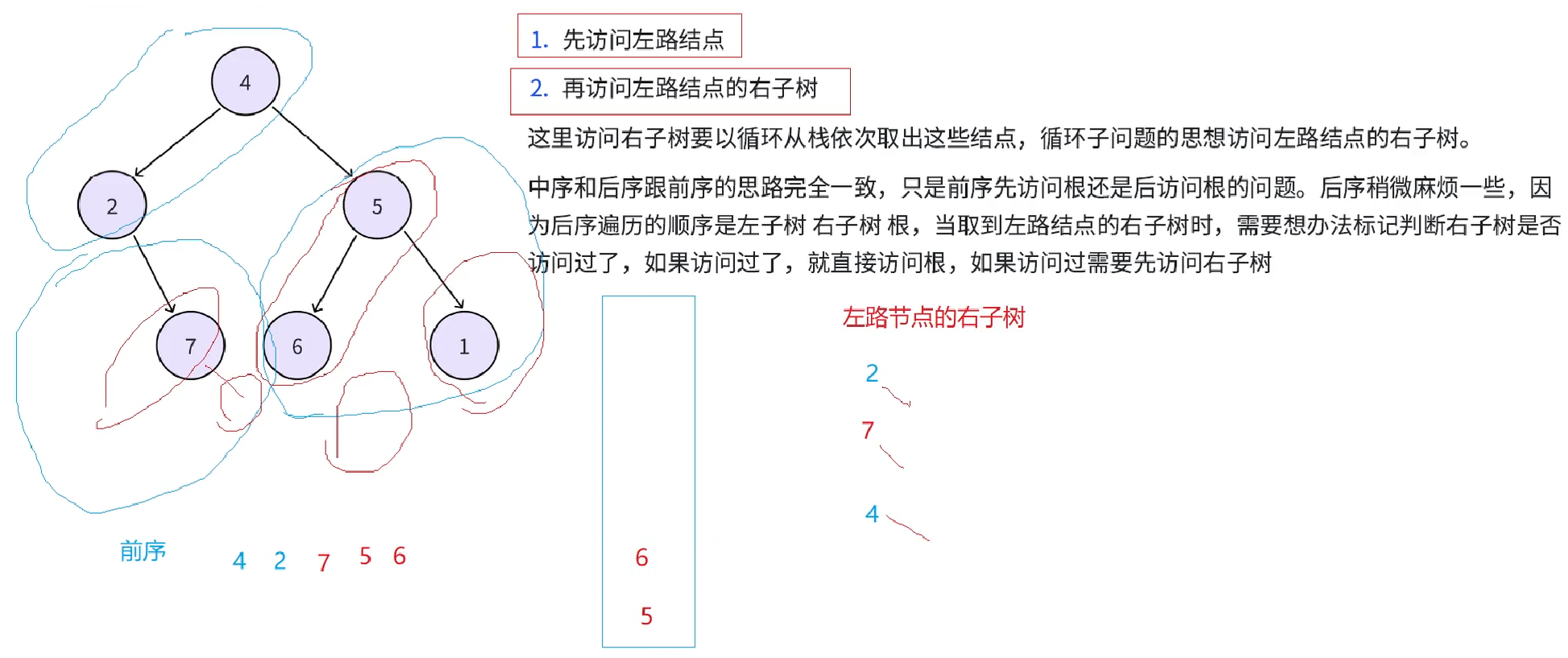
接下来再取栈中结点6,访问6的右子树,由于6的右子树是空树就不需要访问了
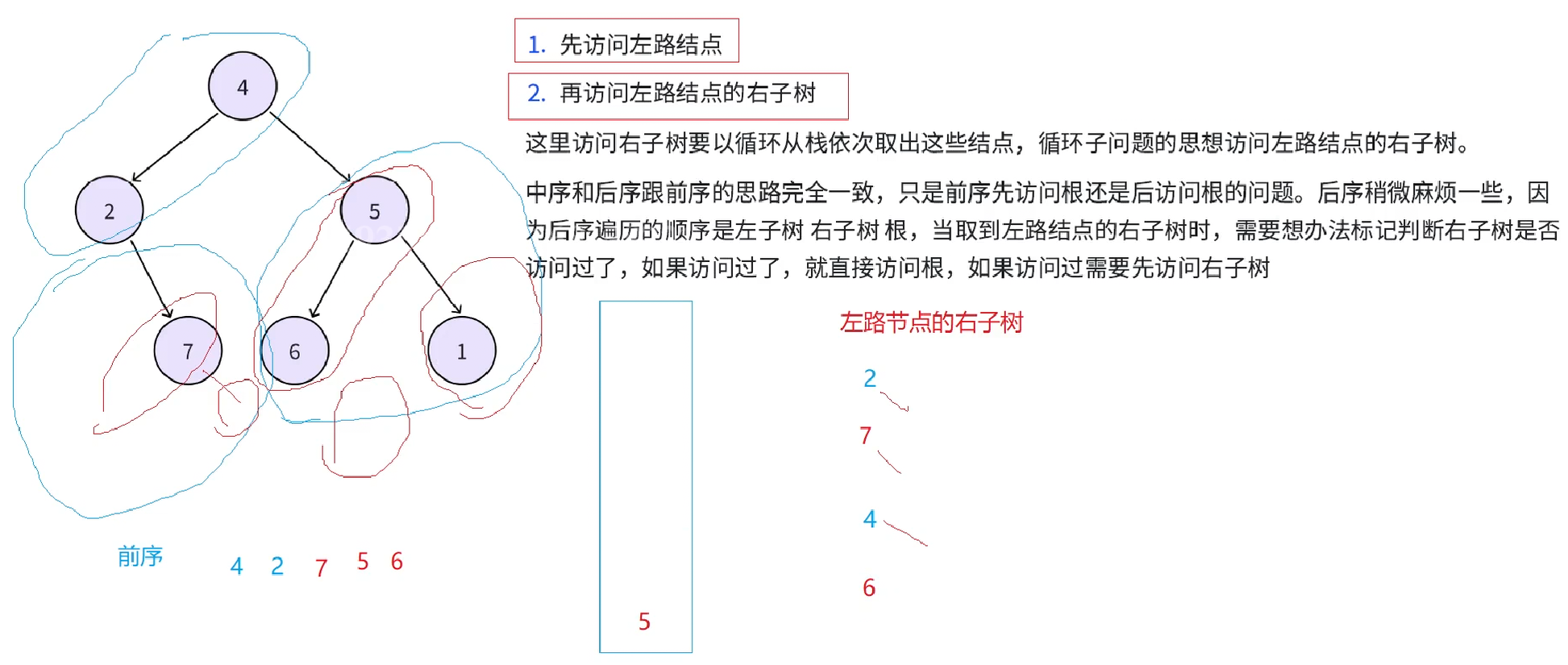
再从栈中取出结点5,接下来要访问5的右子树,依旧把5的右子树分为两个部分,左路节点(1),左路节点的右子树(1的右为空)。
接下里先访问左路结点(1),同时左路结点入栈
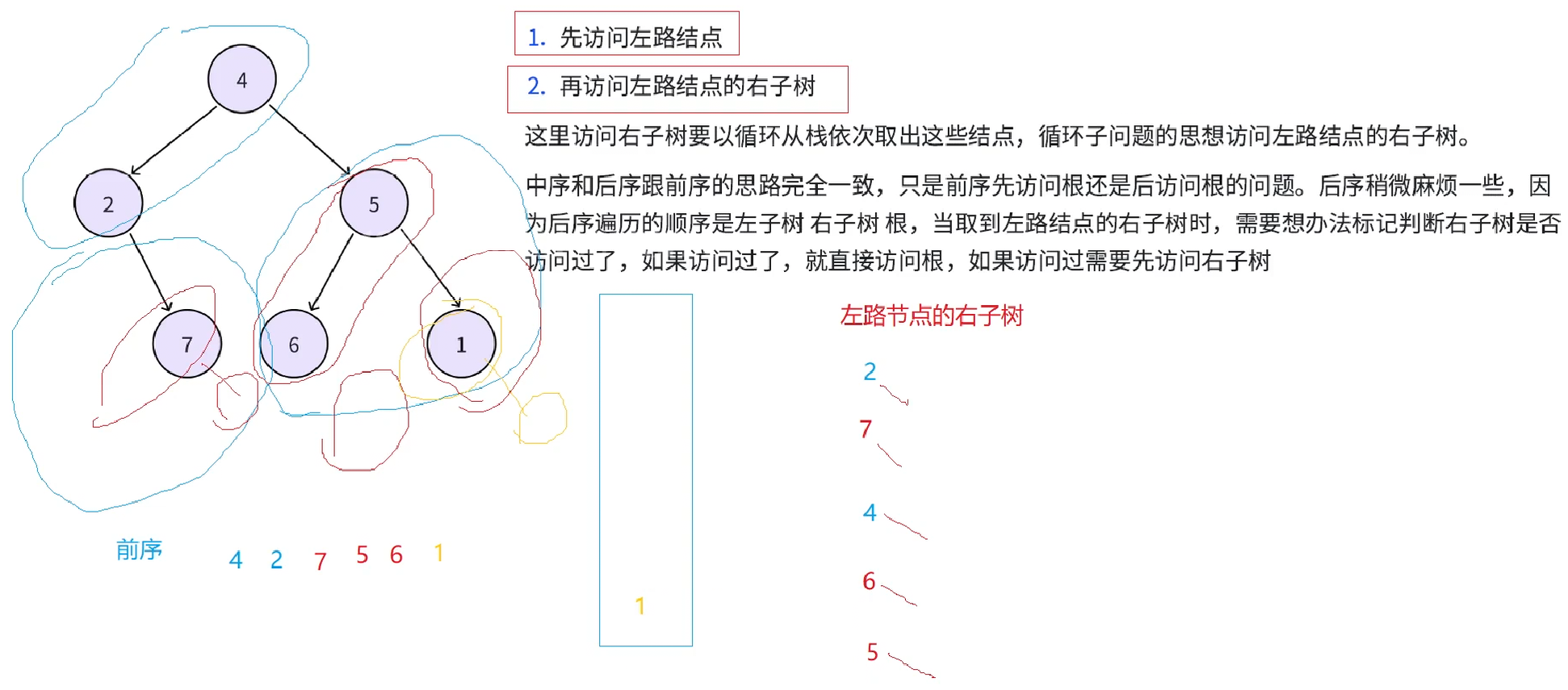
再从栈中取出结点1,下轮就访问左路节点(1)的右子树(空),1的右子树为空,就不用访问了,这样整个递归改非递归的过程就结束了
这道题目的整体思路都是比较抽象的,接下来结合对应代码和图看一下
cur最初指向根节点4,代表访问这棵树的开始,然后进入第二层while循环开始访问左路结点,前序数组和栈中就有了(4,2),cur指向空的时候跳出第二层while循环
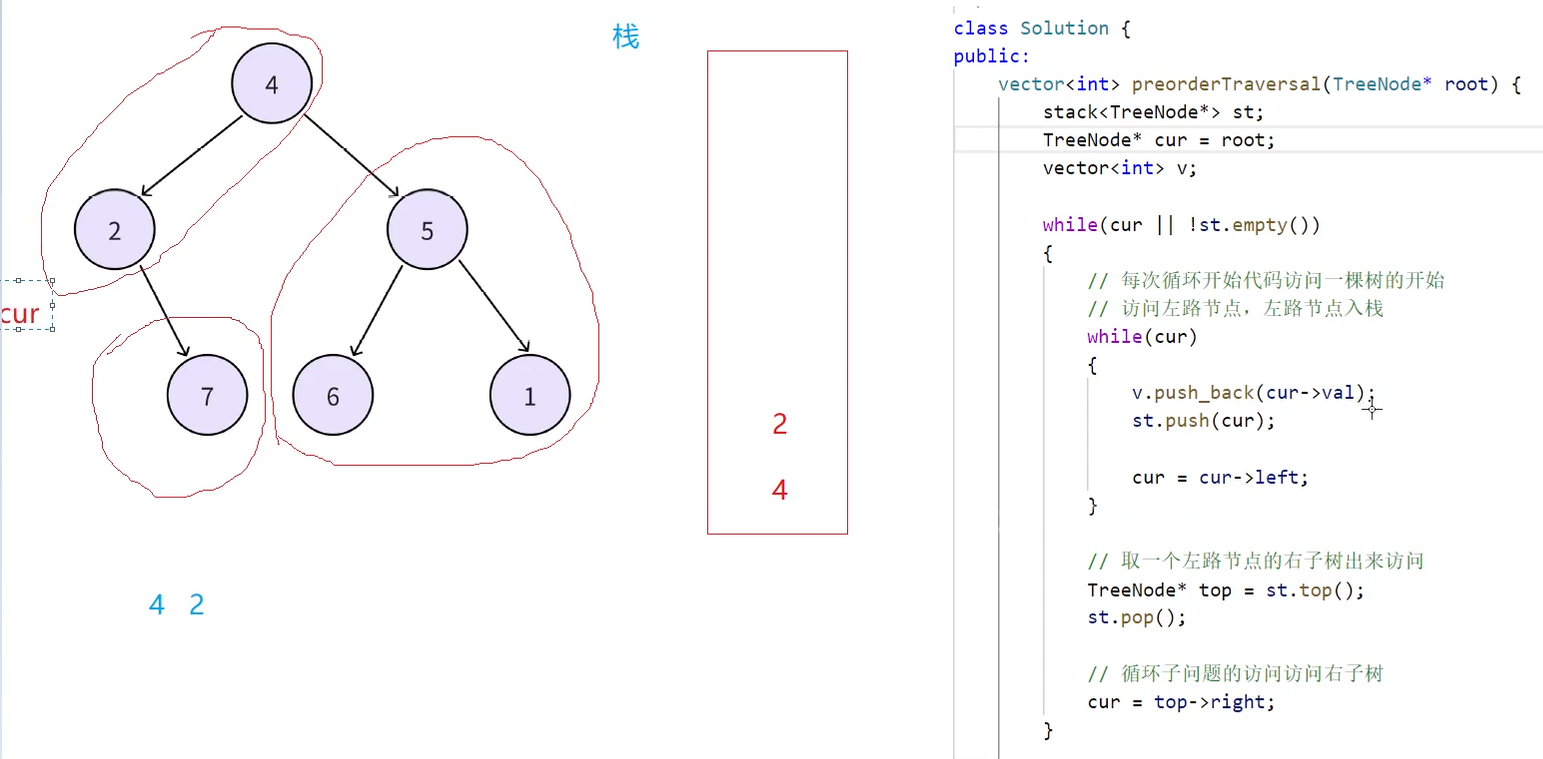
下一步取到栈顶结点2,出栈顶后访问2的右子树7,然后第一层while循环条件满足,再次进入第二层while循环,此时7就是新的一棵树的左路节点,再将其划分为左路节点(7)和左路节点的右子树(7的右为空),左路结点7入栈
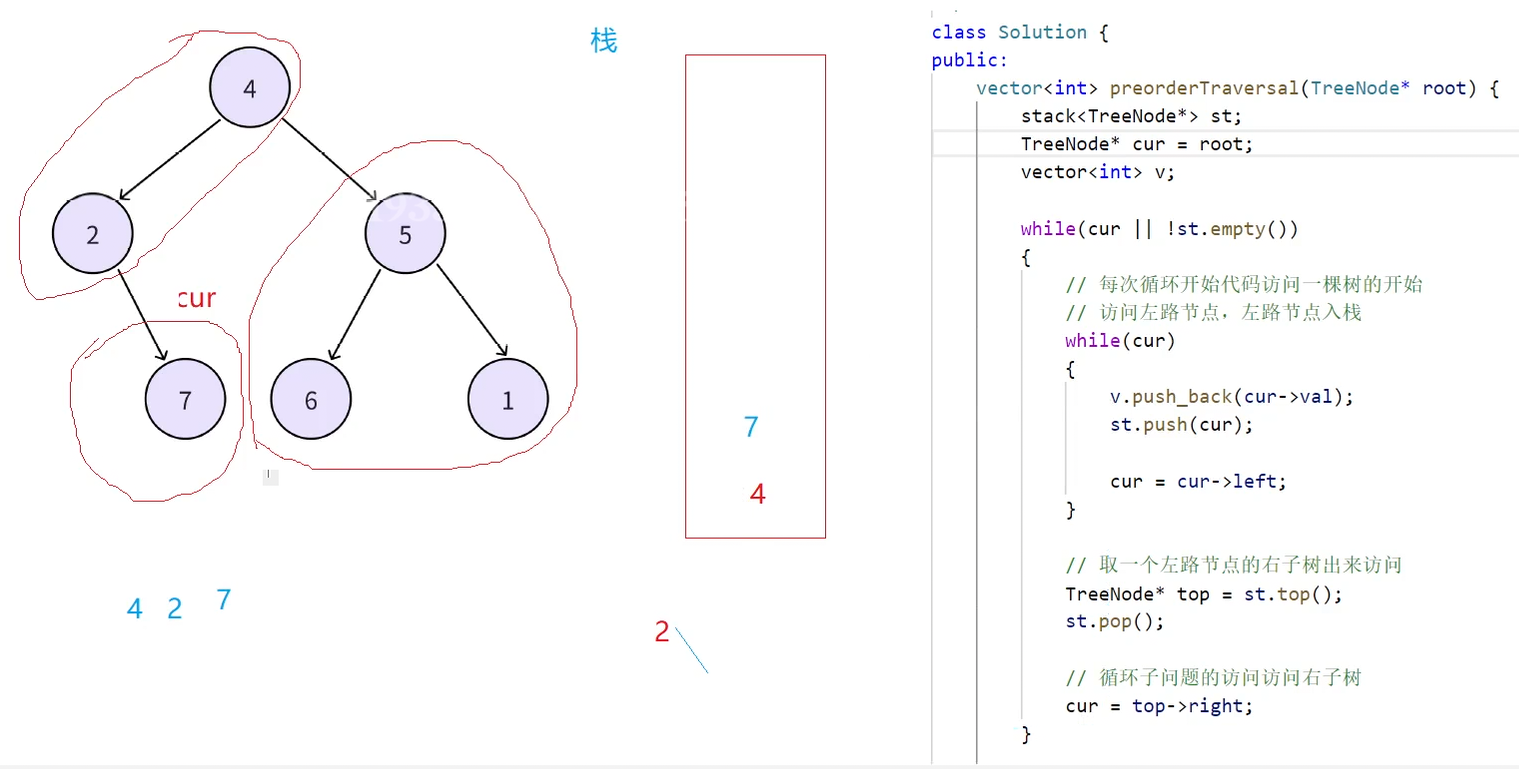
cur指向左路节点的左子树为空跳出第二层while循环
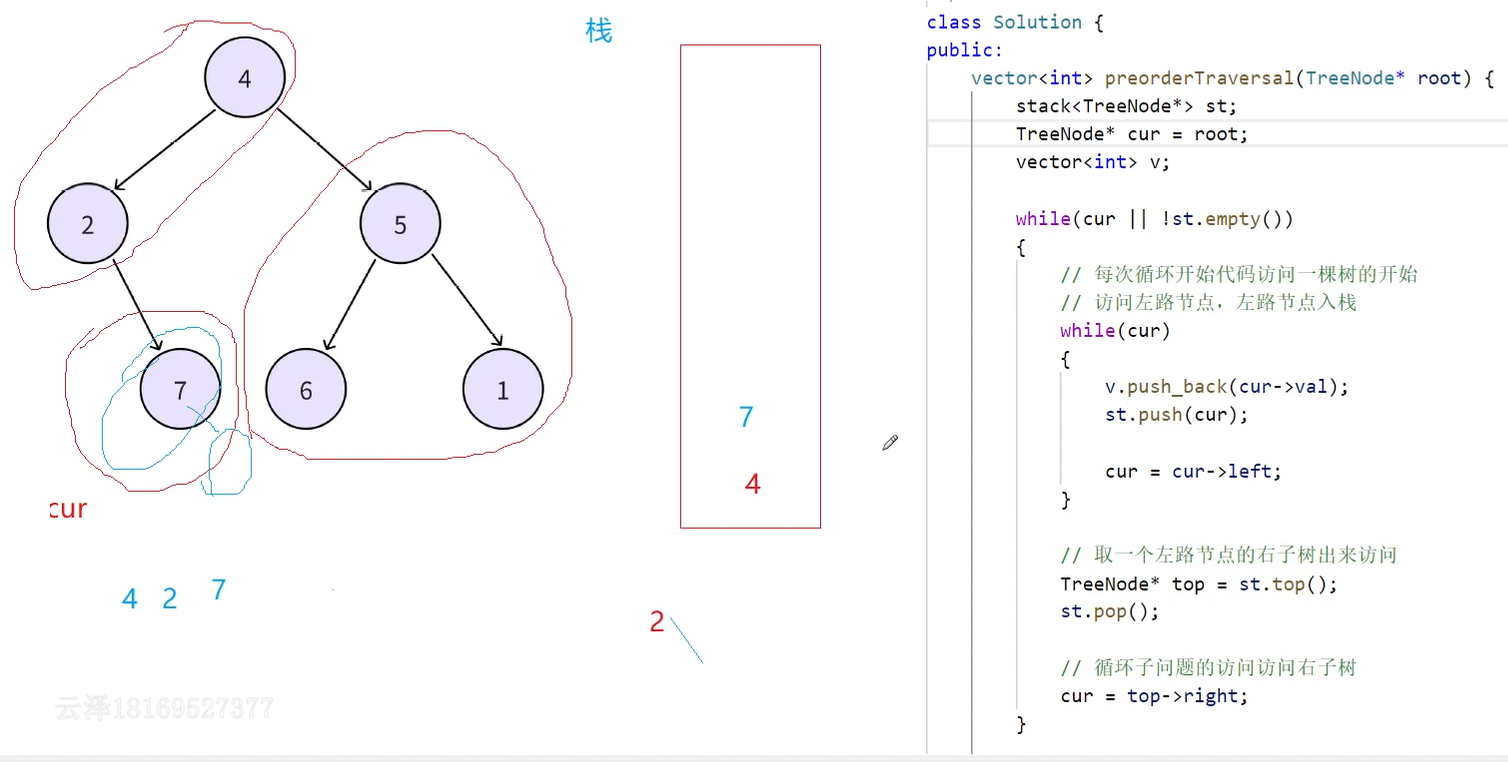
此时7出栈,再取7的右子树来访问(cur指向7的右子树)
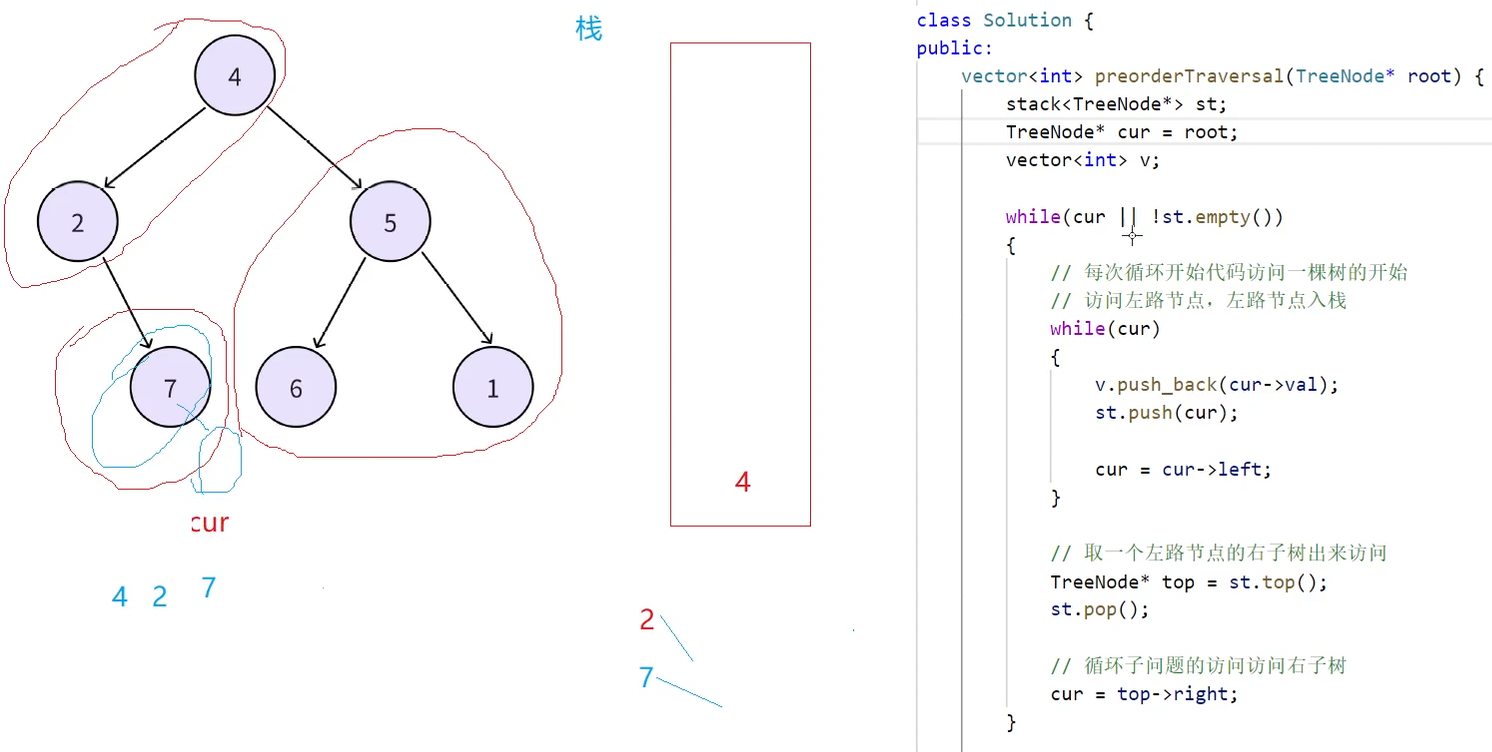
此时第一层while循环由于栈不为空依然可以进去,第二层while循环cur为空进不去了,继续取栈顶,此时取到的栈顶结点就是4,然后访问4的右子树(5)
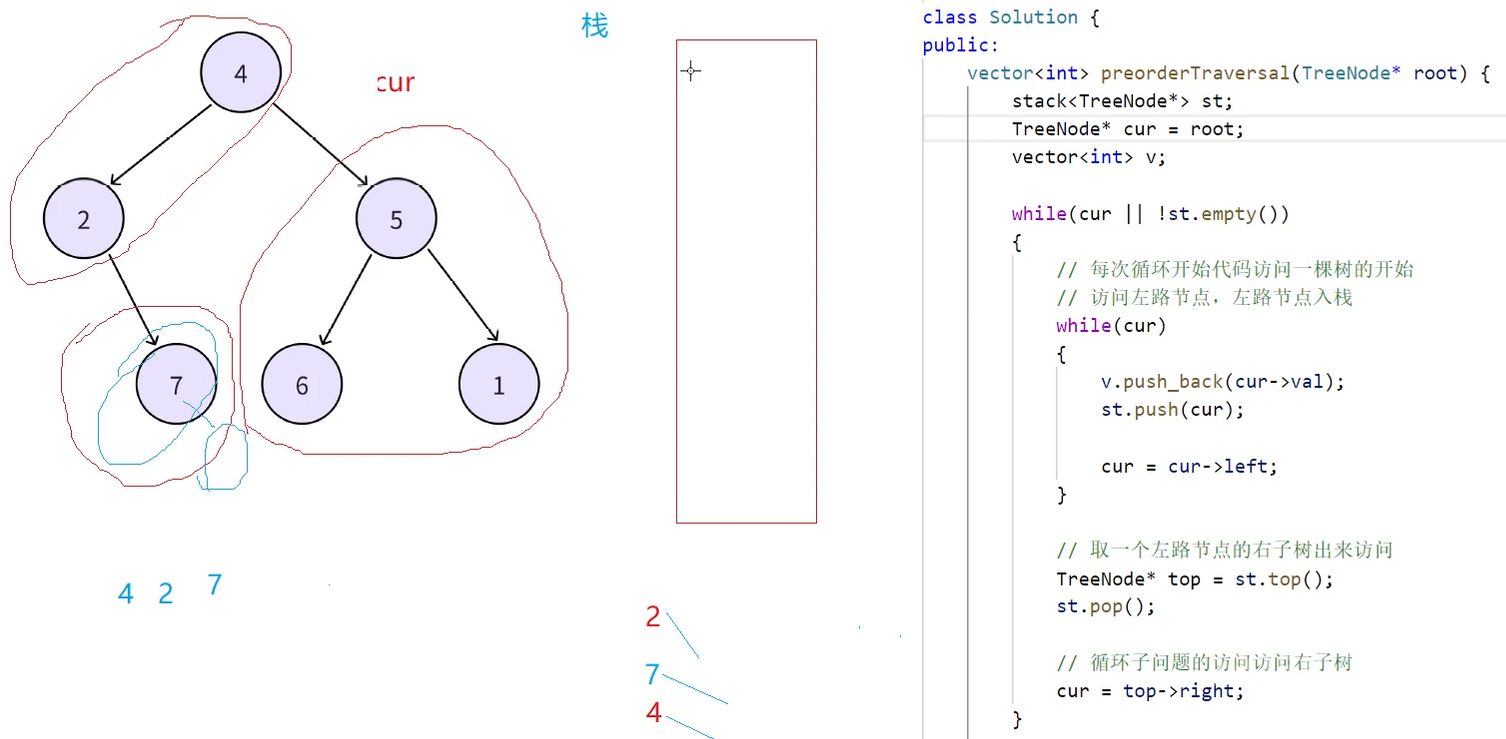
此时栈为空,但是cur不为空,然后顺势推下去就行了,这个代码的精髓cur = top->right
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
//借助cur来访问左路结点
TreeNode* cur = root;
vector<int> v;
//cur不为空表示还有树要访问
//栈不为空表示还有节点的右子树要访问
while(cur || !st.empty())
{
//每次循环开始代表访问一棵树的开始
//访问左路结点,左路结点入栈
while(cur)
{
v.push_back(cur->val);
st.push(cur);
cur = cur->left;
}
//取一个左路节点的右子树出来访问
TreeNode* top = st.top();
st.pop();
//循环子问题的方式访问右子树
cur = top->right;
}
return v;
}
};而且使用堆内存是完全不用担心会存在栈溢出这样的现象的
四、二叉树的中序遍历(非递归)
中序和前序大体思路一致,只不过前序是先访问左路结点再入栈,中序是左路结点只入栈不访问,因为要先访问完最左的左子树再访问根再访问右子树,当一个数从栈顶拿出的时候再访问其和其的右子树
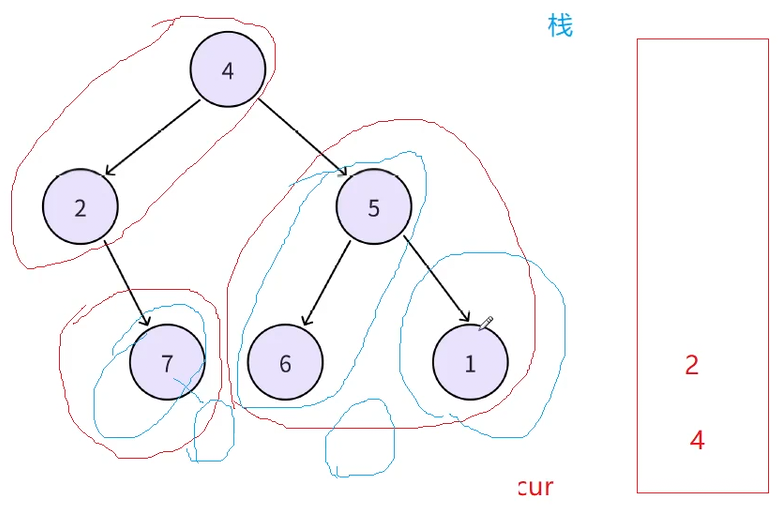
如图左路结点4,2先入栈,此时左路节点已经全部入栈,开始出栈顶数据,出栈顶数据2的时候就顺便访问2这个结点,接下来再访问左路节点(2)的右子树7,然后将7当作新的左路结点入栈,接下来为了访问7的右子树,7出栈顶顺便访问,然后再访问7的右子树,7的右子树若是空就不用访问了,若以7为根的这个结点还有子树也是一样,先入栈其左路节点,出栈的时候访问且接下来访问其右子树,循环往复
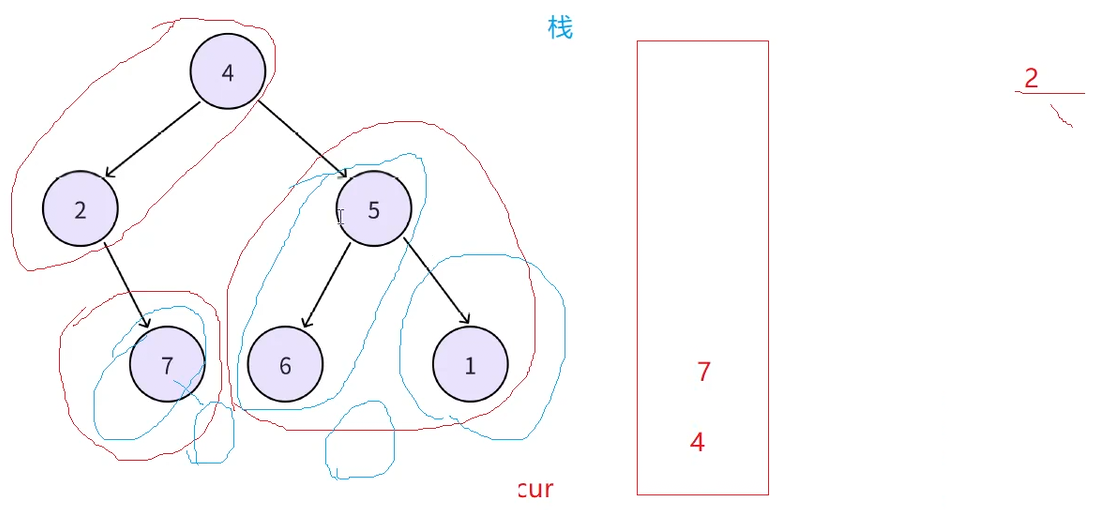
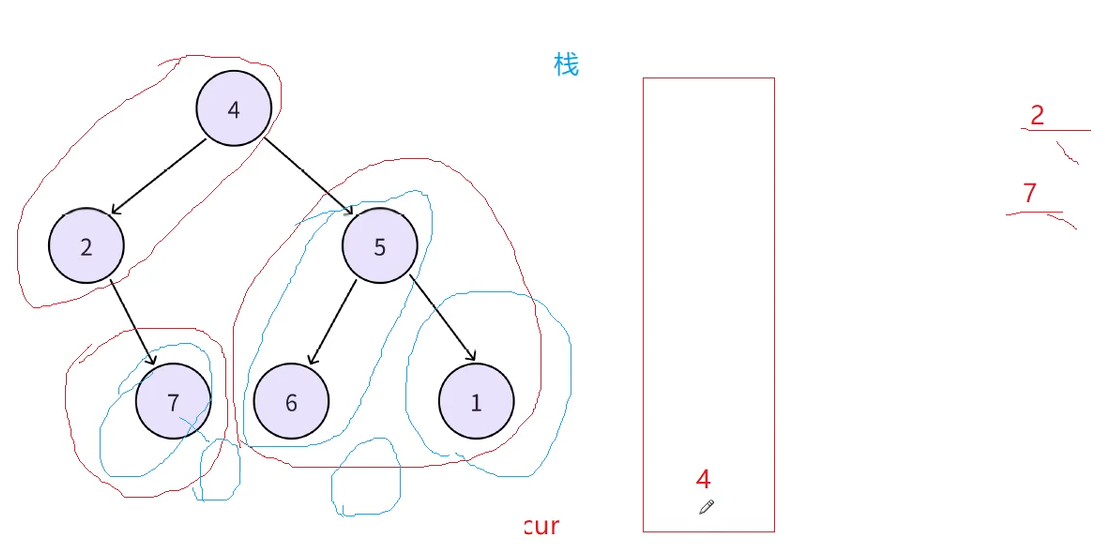
此时再取栈顶结点4,此时可以发现此时4的左子树已经访问完了,根据中序左根右,这个逻辑也符合中序遍历的规矩,出栈顶4的时候顺便访问该结点,然后访问4的右子树,5和6又是新的左路结点入栈,循环这个过程
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
vector<int> v;
while(cur || !st.empty())
{
// 一路向左,把左路节点全部压栈(不访问)
while(cur)
{
st.push(cur);
cur = cur->left;
}
// 出栈时访问节点(这一步就是中序遍历的"根节点访问时机")
TreeNode* top = st.top();
st.pop();
v.push_back(top->val);
// 3. 处理右子树
cur = top->right;
}
return v;
}
};可以看出非递归的中序代码和前序代码的逻辑是完全类似的,就是访问根的时机不一样,仔细分析一下可以发现非递归的代码都是模拟递归栈帧建立的过程实现的,
五、二叉树的后序遍历(非递归)
后序非递归的遍历也是大思路和前面一样,先访问左路结点,然后访问左路节点的右子树,也是根访问的时机不一样
还是结合图演示一下过程,和中序一样一棵树先入栈其左路结点(4,2),不能访问,因为后序是左右根,要先访问完左右结点再访问根
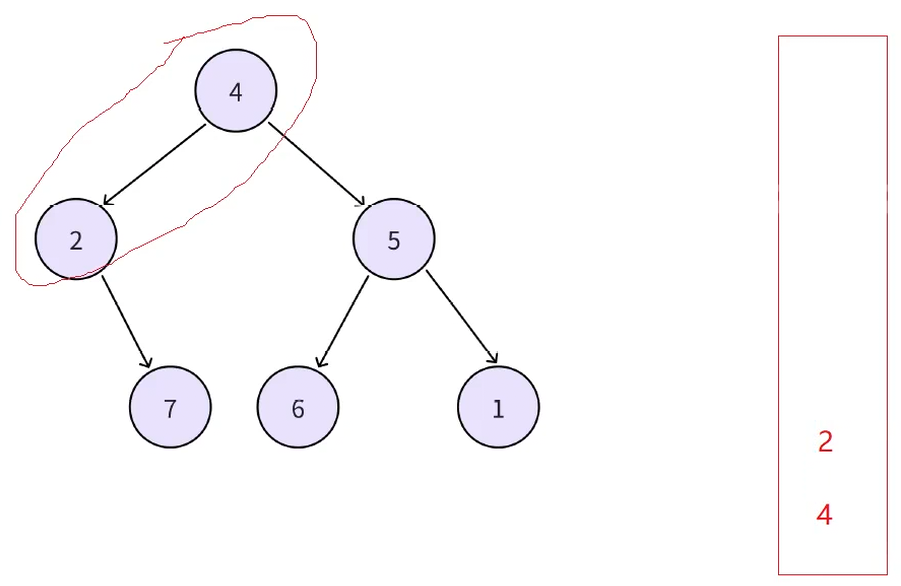
接下来取栈顶取到2意味着其左树已经访问完了,但是此时不能出栈,因为还要用这个结点来访问2的右树,此时再把7当作新的左路结点入栈
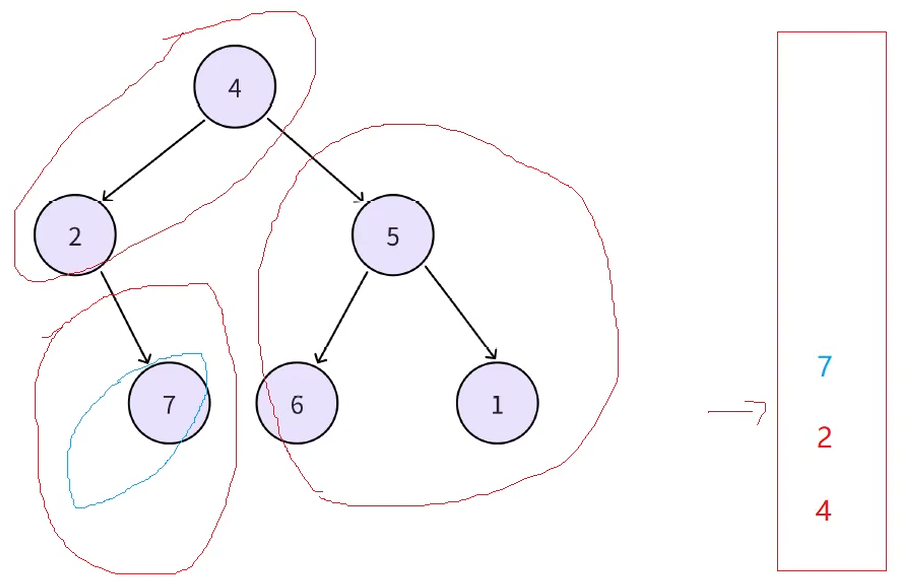
此时取到栈顶结点7,再访问7的右子树,7的右子树为空就不访问了。因为7的右子树为空,而此时7的左已经访问完了,所以此时就可以访问7了,把7出栈顶访问7
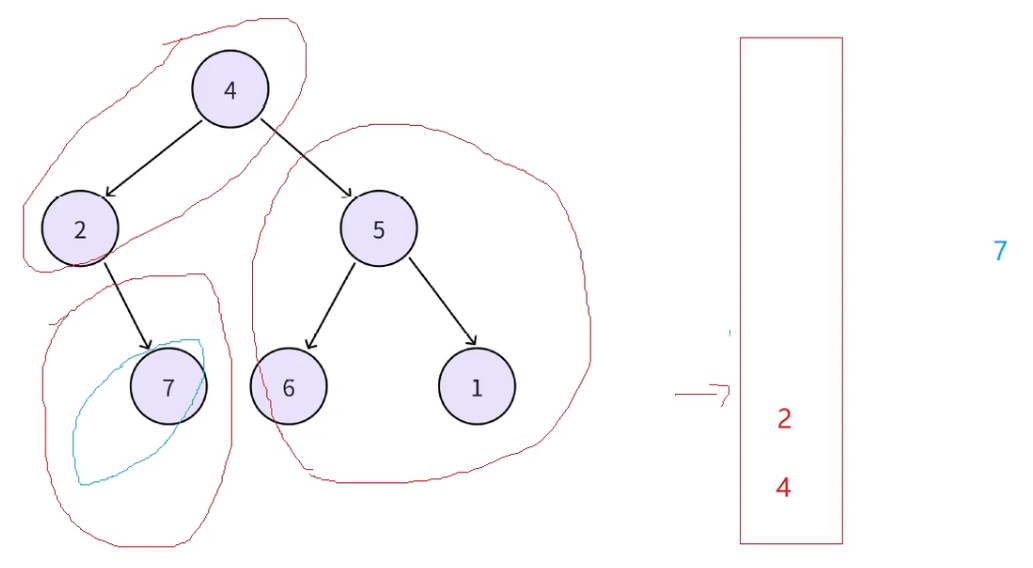
接下来再取栈顶结点为2,这是第二次取到2,此时就会陷入一个问题,若是2的右为空可以重复前面对7的操作,根据后序左右根,根据2的右为空就可以访问2了,但是此时2的右并不为空,所以二叉树后序最麻烦的一个点就是右不为空的时候如何确定这个右是否访问过,访问过了就可以直接出栈访问为根的结点,没访问过还要再入栈访问

这种写法虽然解决了后序先左后右最后根的访问顺序,但是就会陷入刚才无法区分右树是否访问的困境,代码陷入死循环
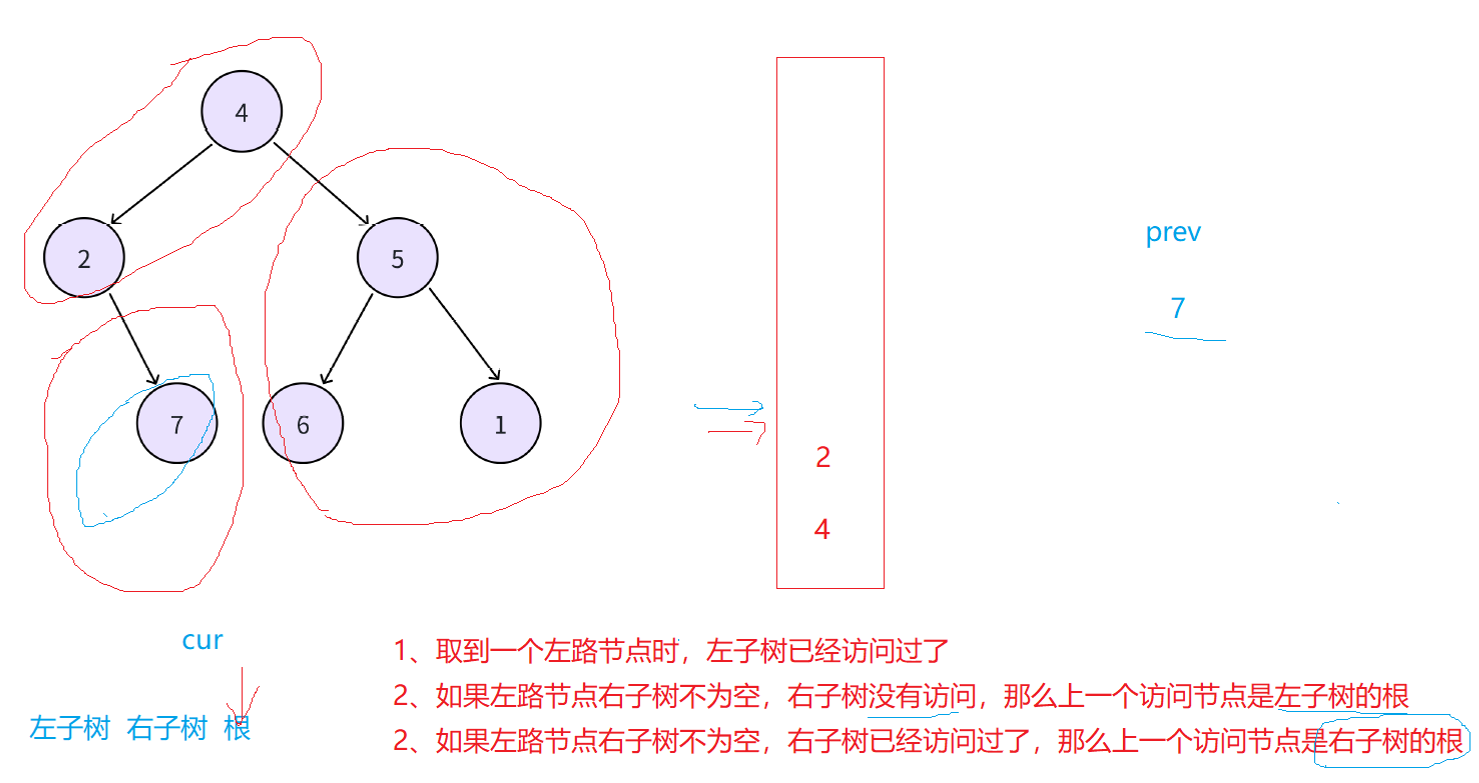
如图三句话就是解决这道题目的关键点,需要用一个变量去记录上一个访问的结点
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
// 记录上一个被访问的节点,用于判断当前节点的右子树是否已处理完成
TreeNode* prev = nullptr;
TreeNode* cur = root;
vector<int> v;
// 循环条件:cur不为空(还有未入栈的节点) 或 栈不为空(还有节点待处理)
while(cur || !st.empty())
{--
// 步骤1:一路向左,把所有左路节点压入栈
// 目的:先处理所有左子树,符合后序"先左"的顺序
while(cur)
{
st.push(cur); // 节点入栈暂存,后续再处理
cur = cur->left; // 继续向左遍历,直到左孩子为空
}
// 取出栈顶节点(此时它的左子树已经全部处理完毕)
TreeNode* top = st.top();
// 步骤2:判断当前节点是否可以被访问
// 满足以下两种情况之一,说明左右子树都已处理完,可以访问根节点:
// 1. top的右孩子为空 → 没有右子树,左右都已处理
// 2. top的右孩子 == prev → 上一个访问的节点就是top的右孩子,说明右子树已经处理完
if(top->right == nullptr || top->right == prev)
{
// 左右子树都已处理完毕,现在可以访问根节点
v.push_back(top->val);
st.pop(); // 节点出栈,标记为已处理
// 更新prev为当前节点,供后续节点判断右子树是否已处理
prev = top;
}
else
{
// 不满足条件:右子树还没处理,需要先处理右子树
// 将cur指向top的右孩子,下一轮循环会先处理它的左子树
cur = top->right;
}
}
return v;
}
};结语
