ChatGPT/智能体/API 调用掉链子排查指南:7 步定位 AI 失灵根因的全流程实战手册
基于 2026-05-29 至 2026-05-30 的 TechCrunch、MarkTechPost 与 OpenAI News 热点,拆解 AI 落地中最常见的需求错位、MCP 上下文膨胀、trace 缺失与人机边界问题
如果你现在的 AI 系统有这些症状:ChatGPT 单聊像学霸,一接业务就像临时转岗;智能体 demo 会飞,一接 MCP 工具就开始乱按按钮;API 明明返回成功,结果却没把事做成------这篇文章就是给你排这种故障的。
读完你应该拿到 3 个产出:5 类问题判断框架、1 份高频原因清单、7 步可执行排查流程。目标不是聊概念,而是帮你尽快定位:到底是模型不行、工具太多、上下文太胖,还是项目目标一开始就写歪了。
说明:本文不是任何厂商的官方手册,而是基于 2026-05-29 至 2026-05-30 几条公开新闻,做的一份工程化排查整理。下面会明确区分"事实描述"和"观点分析"。
工具资源导航
如果你看完这波热点,想顺手把方案跑起来或者把账号环境补齐,这两个入口可以先收藏:
- JKS工具站:工具网站,真实靠谱,可开发票。
- YT SuperStore:工具网站,真实靠谱,可开发票。
文中工具入口属于资源信息整理,请结合平台规则和自身需求判断。
一、问题定义与适用范围
本文解决什么:
- ChatGPT、AI 助手、智能体、API 调用在生产场景中"能回答但不好用"的问题
- 智能体接入工具后准确率下降、调用混乱、结果不可复现的问题
- 代码智能体看起来很强,但落地后返工多、不可控、需要人工兜底的问题
- 团队把 AI 项目做成"玄学调 prompt",却缺少日志、评测与实验闭环的问题
本文不解决什么:
- 账号注册、计费、网络连通性、地区可用性等平台层问题
- 某家模型的私有参数、内部策略或未公开能力
- 法务、合规、采购流程等非技术层问题
一句话概括:本文解决的是"AI 系统为什么做不成事",不是"为什么网页打不开"。
二、热点拆解:先看事实,再谈判断
事实描述
- 2026-05-30,MarkTechPost 报道 :Nous Research 的 Hermes Agent 为 MCP 增加了 Tool Search,用 BM25 和渐进式 schema 披露来缓解上下文膨胀;报道提到,Anthropic 的评测在 Opus 4 上把准确率从 49% 提升到 74%。
- 2026-05-30,MarkTechPost 报道 :AgentTrove 提供了 170 万条开源 agentic traces,采用 ShareGPT 风格布局,可用于构建更干净的 SFT 数据集。
- 2026-05-29,OpenAI News 报道:Braintrust 工程师使用 Codex 与 GPT-5.5,把客户请求转成实验与代码,以更快完成迭代。
- 2026-05-29,TechCrunch 报道:Cognition 的 Scott Wu 明确表示,AI coding agents 不应该替代人类开发者。
- 同样在 2026-05-29,TechCrunch 另外两篇文章讨论了企业"过度 AI 化"与 AI psychosis 现象:决定用 AI 替代工作的人,往往不一定真正理解那份工作本身。
观点分析
把这些新闻放在一起看,会出现一张很清晰的故障地图:
- 很多 AI 落地问题,不是模型突然变笨,而是系统设计出了问题。
- 工具接得越多不一定越强,上下文越塞越满,模型越容易失焦。
- 代码智能体真正能放大的,是实验速度和迭代效率,不是把人类工程师按下线。
- 没有 trace、没有样本集、没有对比实验的 AI 项目,本质上是在靠手感开车。手感偶尔能赢,量产就不稳。
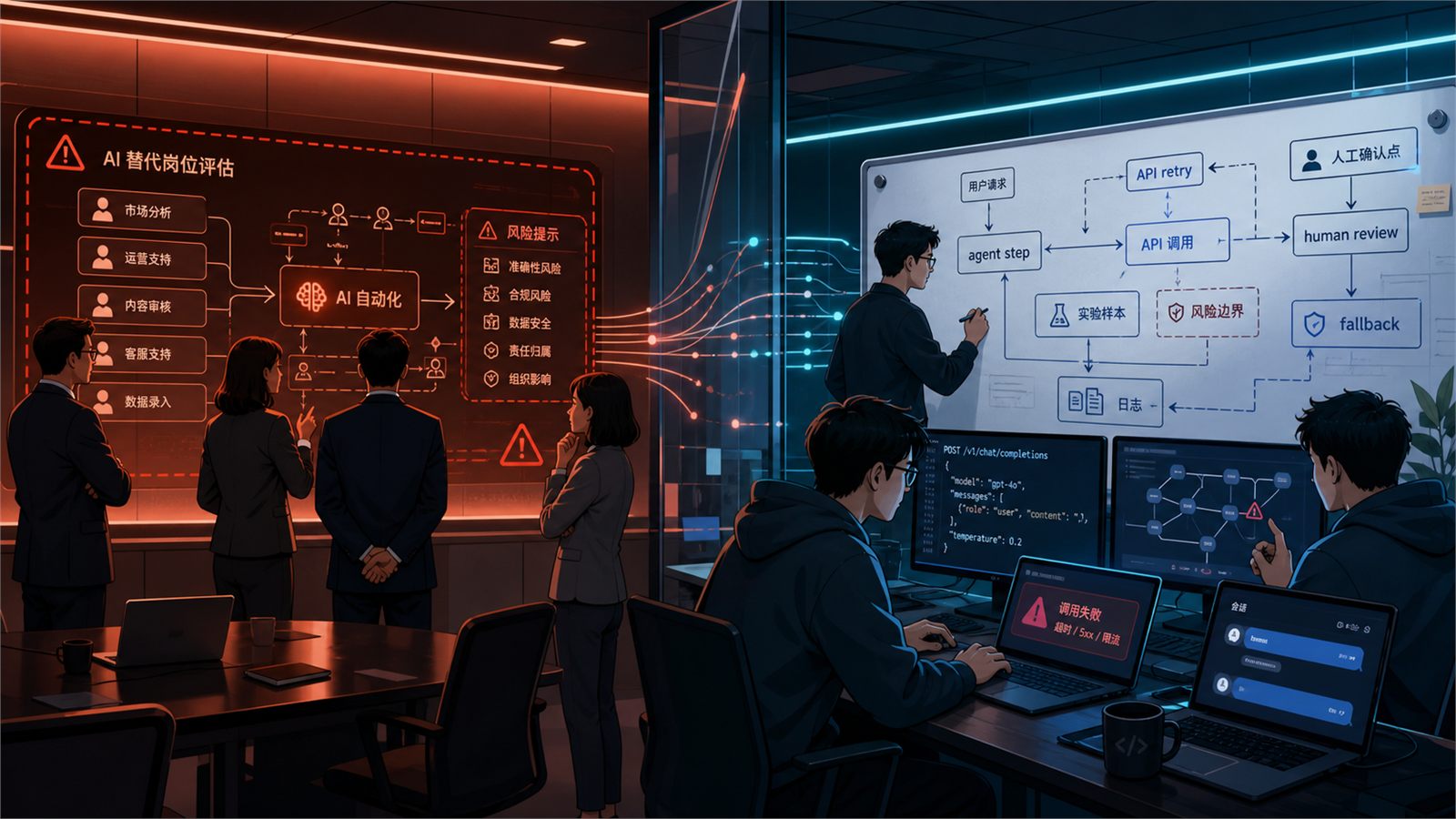
三、先判断问题类型:别急着怪模型,先分型

在排查前,先判断你属于哪一类问题。至少常见有 5 类:
- 需求定义型:AI 输出看起来完整,但根本没解决业务问题。
- 工具路由型:智能体知道要做事,却总选错工具、少调工具,或者干脆不用工具。
- 上下文膨胀型:一接 MCP、多工具、多 schema,准确率明显下降。
- 观测缺失型:你只看到最终答案,看不到中间步骤,失败也无法复现。
- 替代幻觉型:把 AI 当全自动替代者,而不是带护栏的加速器,结果风险一路外溢。
如果你连问题属于哪类都没分清,就开始狂改 prompt,那大概率是在给故障加滤镜,而不是修故障。
四、高频原因清单:按风险和出现概率排序
-
成功标准缺失(高概率 / 高风险)
任务描述只有"帮我搞定",没有验收标准,AI 当然也只能"尽力而为"。
-
工具与 schema 一次性暴露过多(高概率 / 高风险)
这正是 Hermes Agent 试图解决的问题:上下文膨胀会直接拖垮工具选择质量。
-
没有 trace 和代表性样本(高概率 / 中高风险)
没有过程记录,就无法知道问题是出在输入、路由、工具参数,还是最终整合。
-
高风险动作缺少人工确认(中概率 / 高风险)
代码提交、配置修改、数据覆盖这类操作,一旦全自动,事故成本通常比省下的人力高。
-
把 demo 能力当成生产能力(中概率 / 高风险)
Braintrust 的新闻强调的是实验与加速,而不是"一次提示,永远稳定"。
五、可执行排查流程:7 步定位根因

步骤 1:先把任务改写成"输入---动作---验收标准"
如何做:
把模糊需求改成结构化任务卡,至少写清 4 项:输入、允许动作、禁止动作、成功标准。
text
任务:把客户请求转成修复建议
输入:用户反馈、相关代码、最近一次失败 trace
允许动作:查文档、生成 patch、运行测试
禁止动作:自动合并、自动发布
成功标准:定位根因、指出改动文件、给出验证结果
预期结果:
你会先排除一大类"其实不是模型错,而是任务根本没定义清楚"的问题。
步骤 2:建立一个"无工具 baseline"
如何做:
先在 ChatGPT 或直接 API 调用里,让模型只做纯文本分析,不接任何工具。看它是否能正确理解任务、拆步骤、给出合理方案。
预期结果:
- 如果无工具时表现不错,接工具后变差,问题多半在路由、上下文或工具设计。
- 如果无工具时就不行,先别甩锅给 MCP,先回到任务定义和输入质量。
步骤 3:把工具暴露缩到最小集合
如何做:
不要一次把所有工具和完整 schema 都塞给模型。优先只暴露 1 到 3 个最相关工具,按领域分组,再逐步增加。Hermes Agent 的新闻给出的方向很明确:先检索工具,再渐进披露 schema,比"全量说明书灌进去"更稳。
预期结果:
如果工具减少后成功率明显回升,基本可以判定你遇到的是上下文膨胀型故障。
步骤 4:记录最小 trace,至少能回放一次失败
如何做:
为每次任务记录这些信息:用户输入、系统提示、工具选择、工具参数、中间输出、最终结果、人工是否接管。AgentTrove 提供 170 万条 traces 的新闻,最有启发的一点不是"数据多",而是过程可回看。
预期结果:
你会从"感觉它不稳定"升级到"我知道它在哪一步翻车"。这一步非常关键,别让模型当背锅侠。
步骤 5:给高风险动作加人工闸门
如何做:
对代码提交、配置修改、删改数据、触发发布这类动作,强制加人工确认。可以让 agent 先给出 diff、测试结果和理由,再由人决定是否继续。
预期结果:
系统依然能提速,但不会因为一次错误动作把线上环境变成教学案例。Scott Wu 的表态也说明了这点:coding agents 应该是协作者,而不是替代者。
步骤 6:用小样本实验,而不是"老板觉得差不多"
如何做:
挑 10 到 20 条代表性任务,分别测试:原方案、新 prompt、缩减工具集、加人工确认后的版本。记录任务完成率、返工次数、人工接管次数。
预期结果:
你能得到一组可复现的对比结果,而不是靠印象判断哪版更好。Braintrust 用 Codex 与 GPT-5.5 跑实验和写代码的新闻,核心启发正是这个:实验先行,集成后置。
步骤 7:最后回头检查组织假设
如何做:
和业务方、团队负责人确认 3 个问题:
- 这个系统是为了替代整段工作,还是缩短其中几个步骤?
- 哪些动作必须人工审批?
- 失败一次的成本,团队是否真的能承受?
预期结果:
你会发现有些所谓"AI 故障",其实是项目目标得了"AI 万能症"。TechCrunch 在 2026-05-29 的几篇文章提醒的,恰恰就是这种组织层错觉。
六、不建议做法:这些坑真的很常见
- 一上来就接十几个 MCP 工具,希望模型自动变成万能管家
- 只改 prompt,不留 trace,最后谁也说不清哪版更好
- 让代码 agent 直接提交、合并、发布,然后祈祷 CI 像护身符
- 用单次 demo 当生产结论,把偶然成功误判成稳定能力
- 把"降人力"写成唯一目标,却不定义成功边界和人工职责
说直白点:200 返回不等于 200 分,AI 给了输出也不等于它真的把活干好了。
七、趋势判断:对从业者和开发者有什么启发?
下面是观点分析,不是新闻原文。
-
工具搜索与上下文治理会变成智能体基础设施。
Hermes Agent 的案例说明,2026 年的重点可能不是再堆更多工具,而是先解决"工具太多导致模型失焦"。
-
trace 会像日志一样,成为 AI 系统标配。
AgentTrove 这类数据集的意义,不只在训练,更在于提醒开发者:没有过程数据,就没有工程化优化。
-
代码智能体更像实验搭子,不像岗位替代器。
无论是 Scott Wu 的表态,还是 Braintrust 的实践,指向的都是"人机协作 + 快速实验",而不是"一键接管研发"。
-
真正该升级的,不只是模型,还有任务理解能力。
如果管理层并不理解被替代的工作流程,那 AI 项目很容易从技术问题,迅速演化成组织误判。
八、常见问题速查(FAQ)
Q1:ChatGPT 单聊没问题,接入业务后就变笨,先查哪里?
A:先查步骤 2 和步骤 3。先做无工具 baseline,再缩减工具暴露。如果缩工具后表现回升,十有八九是上下文或路由问题。
Q2:MCP 工具是不是越多越好?
A:不是。2026-05-30 的 Hermes Agent 新闻恰恰说明,工具太多、schema 太长会造成上下文膨胀,准确率可能显著下降。
Q3:代码智能体能不能直接替代开发者?
A:从 2026-05-29 TechCrunch 对 Scott Wu 的报道看,连做 coding agent 的人都认为它不该替代人类。更实际的做法是让它加速分析、试验和改代码,再由人审核关键动作。
Q4:没有大规模数据,能不能做排查?
A:可以。先从 10 到 20 条代表性任务开始,重点不是规模,而是能否复现、能否对比。
Q5:怎么向业务方解释"这不是模型智商问题"?
A:拿出证据:无工具 baseline、缩减工具后的结果、失败 trace、前后实验对比。只要证据链完整,讨论就能从情绪切回工程。
九、结语:先做 3 件小事,再谈大规模上线
如果你准备今天就动手,我建议先做这 3 件事:
- 写一张结构化任务卡;
- 把工具集合缩到最小;
- 记录 10 条失败与成功 trace。
做完这三步,你通常就能判断:问题到底在模型、工具、流程,还是组织预期。AI 项目最怕的不是模型不够聪明,而是出了问题却不知道坏在哪一层。
2026 年这几条新闻给开发者最实在的提醒,不是"AI 能不能替代你",而是另一句更工程化的话:先让 AI 稳定地帮你做对一件事,再谈它能不能多做十件事。