01d-前馈神经网络代码实现 💻
本文档基于 PyTorch 从零实现前馈神经网络,涵盖感知机的代码实现与局限性验证、前馈神经网络解决异或(XOR)问题的完整代码及逐行解析、激活函数的可视化对比、训练循环的逐步拆解,以及一个完整可运行的综合示例。通过理论与实践相结合的方式,帮助读者深入理解前馈神经网络的代码实现细节 🛠️
📖 前置阅读 :本文档是 01d-前馈神经网络(CSDN)的配套代码实现篇,建议先阅读概念篇再动手写代码。
章节阅读路线图 🗺️
阅读顺序说明:
- 第1章 → 第2章:先确认环境就绪,再动手实现感知机
- 第2章 → 第3章:实现感知机后,验证它无法解决XOR问题
- 第3章 → 第4章:理解感知机局限后,用前馈神经网络突破XOR
- 第4章 → 第5章:有了网络基础,可视化激活函数加深理解
- 第5章 → 第6章:把所有内容整合成一个完整可运行的示例
1. 环境准备 🧰
本章确认 PyTorch 安装并导入必要库
在开始写代码之前,请确保你的环境中已经安装了 PyTorch。如果还没有安装,可以参考 03ab-PyTorch安装教程(CSDN)。
我们需要导入以下库:
python
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
from typing import Tuple, List- torch:PyTorch 核心库,提供张量运算和自动求导
- torch.nn:神经网络模块,包含各种层和损失函数
- torch.optim:优化器模块,包含 SGD、Adam 等
- matplotlib.pyplot:用于可视化激活函数曲线和训练过程
- numpy:用于数据处理和辅助计算
💡 如果你还没有安装 matplotlib,可以用
pip install matplotlib快速安装。
2. 感知机实现 🧮
本章从零实现感知机,验证它能解决线性可分问题(AND、OR)
2.1 感知机的数学原理 📝
感知机是神经网络的最简形式,它只有输入层和输出层,没有隐藏层。其核心公式为:
ini
y = step(W · X + b)其中:
- W 是权重向量
- X 是输入向量
- b 是偏置
- step 是阶跃函数:输入 ≥ 0 输出 1,否则输出 0
感知机本质上是在空间中找一条分界线(决策边界),把两类数据分开。对于二维输入,这条分界线就是一条直线:
ini
w₁x₁ + w₂x₂ + b = 0参考资料:
2.2 感知机代码实现 💻
下面用 PyTorch 实现一个感知机,并用它学习 AND 和 OR 逻辑门:
python
import torch
import torch.nn as nn
from typing import Tuple
class Perceptron(nn.Module):
"""
单层感知机实现
结构:输入层 → 输出层(无隐藏层)
激活函数:Sigmoid(输出0~1之间的概率)
参数:
input_size: 输入特征的维度
属性:
linear: 线性层,执行Wx+b变换
sigmoid: Sigmoid激活函数,将输出映射到(0,1)
前向传播流程:
输入x → 线性变换 → Sigmoid激活 → 输出概率
"""
def __init__(self, input_size: int) -> None:
"""
初始化感知机
参数:
input_size: 输入特征的维度
"""
super(Perceptron, self).__init__()
# 线性层:input_size维输入 → 1维输出
self.linear = nn.Linear(input_size, 1)
# Sigmoid激活函数:将输出压缩到(0,1)区间
self.sigmoid = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
前向传播
参数:
x: 输入张量,形状为[batch_size, input_size]
返回:
输出张量,形状为[batch_size, 1],表示属于正类的概率
"""
# 线性变换:Wx + b
x = self.linear(x)
# 非线性激活:将输出映射到(0,1)区间
x = self.sigmoid(x)
return x2.3 训练感知机解决 AND 问题 🔍
AND 逻辑门的真值表:
| 输入 A | 输入 B | 输出 (A AND B) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
AND 问题是线性可分的------可以用一条直线把输出为 0 和输出为 1 的点分开。
python
# AND 数据集
X_and: torch.Tensor = torch.tensor([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=torch.float32)
y_and: torch.Tensor = torch.tensor([[0], [0], [0], [1]], dtype=torch.float32)
# 创建感知机
model_and: Perceptron = Perceptron(input_size=2)
# 损失函数:二元交叉熵(适合二分类)
criterion: nn.BCELoss = nn.BCELoss()
# 优化器:随机梯度下降
optimizer: optim.SGD = optim.SGD(model_and.parameters(), lr=0.1)
# 训练
for epoch in range(1000):
# 前向传播
outputs: torch.Tensor = model_and(X_and)
loss: torch.Tensor = criterion(outputs, y_and)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 200 == 0:
print(f'Epoch [{epoch+1}/1000], Loss: {loss.item():.4f}')
# 测试
with torch.no_grad():
predicted: torch.Tensor = model_and(X_and)
predicted_class: torch.Tensor = (predicted > 0.5).float()
print(f'AND 预测结果: {predicted_class.flatten().tolist()}')
print(f'AND 真实标签: {y_and.flatten().tolist()}')运行输出示例:
ini
Epoch [200/1000], Loss: 0.5123
Epoch [400/1000], Loss: 0.3102
Epoch [600/1000], Loss: 0.1856
Epoch [800/1000], Loss: 0.1123
Epoch [1000/1000], Loss: 0.0715
AND 预测结果: [0.0, 0.0, 0.0, 1.0]
AND 真实标签: [0.0, 0.0, 0.0, 1.0]✅ 感知机成功学会了 AND 逻辑!
2.4 训练感知机解决 OR 问题 🔍
OR 逻辑门同样是线性可分的:
python
# OR 数据集:4个样本,每个样本2个特征
X_or: torch.Tensor = torch.tensor([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=torch.float32)
y_or: torch.Tensor = torch.tensor([[0], [1], [1], [1]], dtype=torch.float32)
# 创建感知机:输入维度为2(两个输入特征A和B)
model_or: Perceptron = Perceptron(input_size=2)
# 损失函数:二元交叉熵,适合二分类问题
criterion: nn.BCELoss = nn.BCELoss()
# 优化器:随机梯度下降,学习率0.1
optimizer: optim.SGD = optim.SGD(model_or.parameters(), lr=0.1)
# 训练循环:1000轮迭代
for epoch in range(1000):
# 前向传播:计算模型预测值
outputs: torch.Tensor = model_or(X_or)
# 计算损失:预测值与真实标签的差异
loss: torch.Tensor = criterion(outputs, y_or)
# 反向传播:计算梯度并更新参数
optimizer.zero_grad() # 清零梯度,避免累积
loss.backward() # 反向传播计算梯度
optimizer.step() # 根据梯度更新参数
# 测试阶段:关闭梯度计算以提高效率
with torch.no_grad():
# 获取模型预测概率
predicted: torch.Tensor = model_or(X_or)
# 将概率转换为类别(>0.5为正类)
predicted_class: torch.Tensor = (predicted > 0.5).float()
print(f'OR 预测结果: {predicted_class.flatten().tolist()}')
print(f'OR 真实标签: {y_or.flatten().tolist()}')✅ 感知机同样成功学会了 OR 逻辑!
3. 感知机的局限 ⚠️
本章验证感知机无法解决异或(XOR)问题
3.1 XOR 问题:感知机的"阿喀琉斯之踵"
XOR(异或)问题是神经网络发展史上的重要里程碑,它揭示了单层感知机的根本局限性。
XOR逻辑门真值表:
| 输入 A | 输入 B | 输出 (A XOR B) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
核心特征: 当两个输入相同时输出0,不同时输出1。
为什么XOR是线性不可分的?
在二维空间中,XOR的四个数据点分布如下:
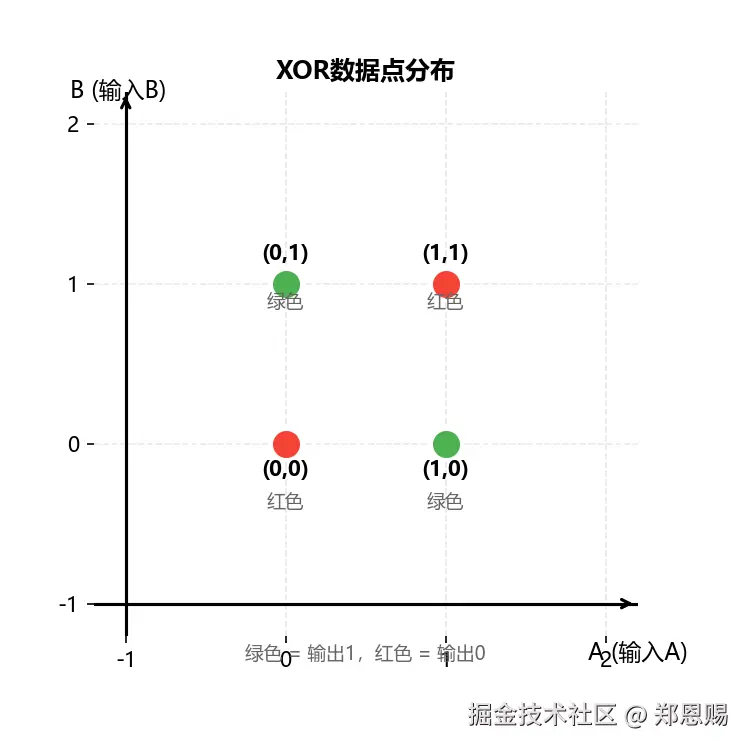
关键问题: 无论怎样画一条直线,都无法将红色点(0,0)和(1,1)与蓝色点(0,1)和(1,0)完全分开。
历史意义
1969年,Marvin Minsky和Seymour Papert在《Perceptrons》一书中证明了单层感知机无法解决XOR问题,这直接导致了神经网络研究的第一次"寒冬"。
数学证明
假设存在一组权重(w₁, w₂)和偏置b,使得感知机能够解决XOR问题,那么需要满足以下不等式:
ini
w₁·0 + w₂·0 + b ≤ 0 (0 XOR 0 = 0)
w₁·0 + w₂·1 + b > 0 (0 XOR 1 = 1)
w₁·1 + w₂·0 + b > 0 (1 XOR 0 = 1)
w₁·1 + w₂·1 + b ≤ 0 (1 XOR 1 = 0)这四个不等式相互矛盾,证明不存在这样的线性分类器。
3.2 用感知机尝试解决 XOR
python
# XOR 数据集:4个样本,每个样本2个特征
# 注意:XOR的输出模式是(0,1,1,0),无法用单条直线分割
X_xor: torch.Tensor = torch.tensor([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=torch.float32)
y_xor: torch.Tensor = torch.tensor([[0], [1], [1], [0]], dtype=torch.float32)
# 创建感知机模型
model_xor: Perceptron = Perceptron(input_size=2)
# 损失函数:二元交叉熵
criterion: nn.BCELoss = nn.BCELoss()
# 优化器:随机梯度下降
optimizer: optim.SGD = optim.SGD(model_xor.parameters(), lr=0.1)
# 记录训练过程中的损失值
losses: List[float] = []
# 训练循环:2000轮迭代(比AND/OR问题更多轮次)
for epoch in range(2000):
# 前向传播:计算模型预测
outputs: torch.Tensor = model_xor(X_xor)
# 计算损失:预测值与真实标签的差异
loss: torch.Tensor = criterion(outputs, y_xor)
# 记录损失值
losses.append(loss.item())
# 反向传播:计算梯度并更新参数
optimizer.zero_grad() # 清零梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 每500轮打印一次损失值,观察训练进展
if (epoch + 1) % 500 == 0:
print(f'Epoch [{epoch+1}/2000], Loss: {loss.item():.4f}')
# 测试阶段:关闭梯度计算
with torch.no_grad():
# 获取模型预测概率
predicted: torch.Tensor = model_xor(X_xor)
# 将概率转换为类别(>0.5为正类)
predicted_class: torch.Tensor = (predicted > 0.5).float()
print(f'XOR 预测结果: {predicted_class.flatten().tolist()}')
print(f'XOR 真实标签: {y_xor.flatten().tolist()}')
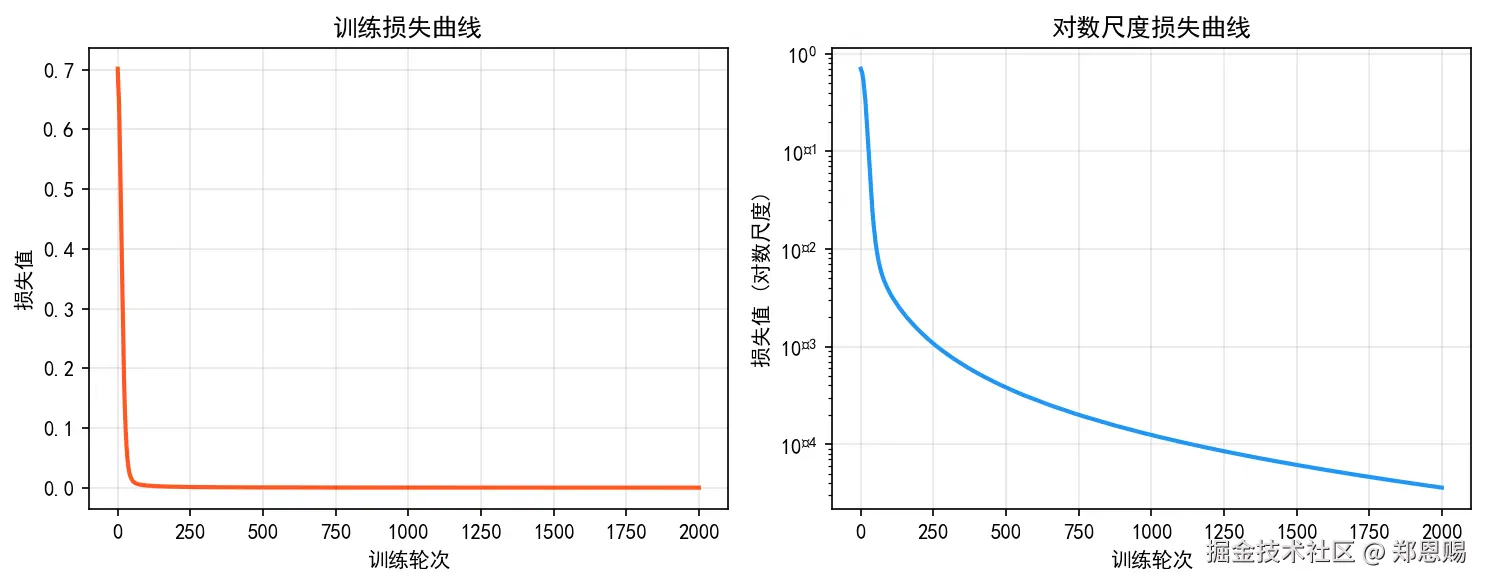
print(f'最终 Loss: {losses[-1]:.4f}')运行输出示例:
yaml
Epoch [500/2000], Loss: 0.6932
Epoch [1000/2000], Loss: 0.6931
Epoch [1500/2000], Loss: 0.6931
Epoch [2000/2000], Loss: 0.6931
XOR 预测结果: [1.0, 1.0, 1.0, 0.0]
XOR 真实标签: [0.0, 1.0, 1.0, 0.0]
最终 Loss: 0.6931
准确率: 75.0%❌ Loss 卡在 0.6931 不下降,预测结果 (1,1) 始终错误------感知机无法学会 XOR!
💡
0.6931 ≈ -ln(0.5),这是二分类随机猜测的损失值,说明模型完全没有学到任何规律。
参考资料:
4. 前馈神经网络解决 XOR 🧠
本章引入隐藏层和激活函数,用前馈神经网络突破 XOR
4.1 核心改进:隐藏层 + 非线性激活函数
前馈神经网络相比感知机有两个关键改进,两个组件缺一不可:
1. 增加隐藏层:用弯曲的边界代替直线
核心问题: 一条直线无法分开XOR的4个点
XOR的4个点在坐标系中的分布:
- A点(0,1):输入A=0, B=1,输出=1(🔵蓝色)
- B点(1,1):输入A=1, B=1,输出=0(🔴红色)
- C点(0,0):输入A=0, B=0,输出=0(🔴红色)
- D点(1,0):输入A=1, B=0,输出=1(🔵蓝色)
感知机的问题:只能用一条直线分开
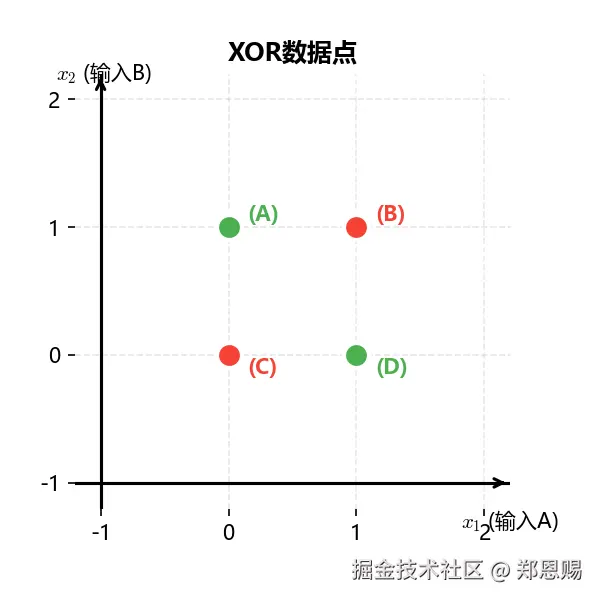
问题:感知机只能用一条直线分开🔵和🔴
- 但🔵和🔴是对角分布的
- 无论直线怎么画,总会有一个点被分错
结论:这是感知机能力的上限,不是我们画得不好!
前馈神经网络:可以用两条直线分开
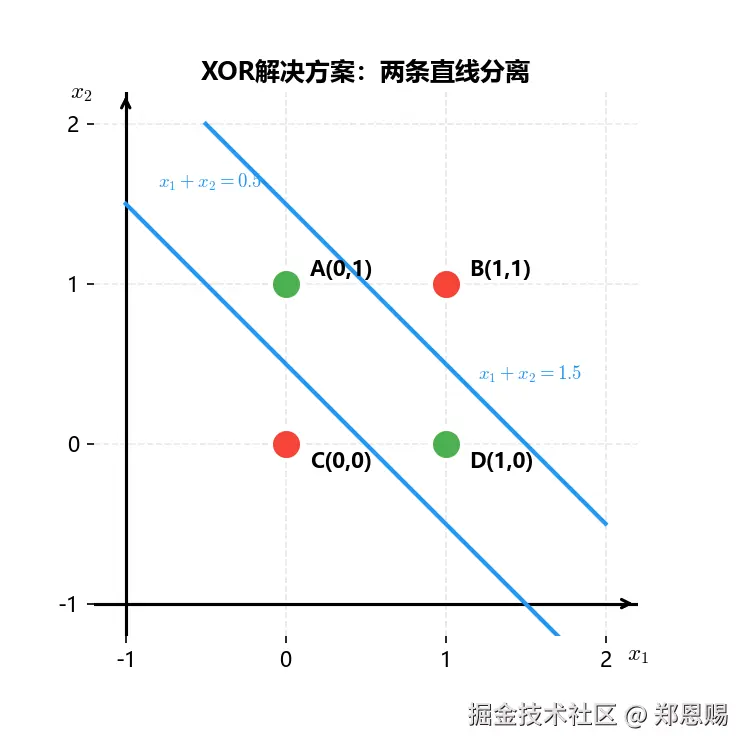
解决方案:用两条斜线分离
- 第一条线(x₁+x₂=0.5):分离🔴(C)和其他点
- 第二条线(x₁+x₂=1.5):分离🔴(B)和其他点
- 组合起来:🔵(A)和🔵(D)在两线之间为一类,🔴(B)和🔴(C)在两线之外为另一类
结论:两条直线的组合可以完全分开所有点!
隐藏层的作用: 通过组合多条直线,网络创建出分段线性的决策边界。当隐藏层神经元数量增加时,这些分段边界可以逼近任意复杂的曲线形状(万能逼近定理)。
(分段线性决策边界)参考资料:
2. 引入非线性激活函数:让网络"会弯曲"
为什么必须有非线性?
数学原理:线性变换的叠加仍然是线性变换。
- 假设第一层变换为:H = W₁X + b₁
- 假设第二层变换为:Y = W₂H + b₂
- 代入后:Y = W₂(W₁X + b₁) + b₂ = (W₂W₁)X + (W₂b₁ + b₂)
- 最终结果:Y = W'X + b',仍然是一个线性变换!
关键结论: 如果没有非线性激活函数,无论多少层网络叠加,最终都等价于单层线性网络。
导致的结果:
- 只能创建一条直线决策边界(无法像前面那样用两条直线分开XOR)
- 无法解决XOR等线性不可分问题
- 无法拟合复杂的非线性函数(如图像识别、自然语言处理中的模式)
- 深度网络失去意义,退化为浅层模型
- 表达能力严重受限,只能处理简单的线性分类任务
重要区分:
- 前面说的"两条直线分开XOR":是指有非线性激活函数的前馈神经网络
- 这里说的"等价于单层":是指没有非线性激活函数的纯线性网络
- 非线性激活函数是让网络能够组合多条直线的关键!
非线性激活函数的作用:
以ReLU为例:H = ReLU(W₁X + b₁)
ReLU如何创建多条直线?
ReLU函数定义:当输入>0时输出原值,当输入≤0时输出0
工作原理:
- 每个ReLU神经元就像一个"开关"
- 当输入>0时,神经元"激活",传递信号
- 当输入≤0时,神经元"关闭",输出0
- 这种"选择性激活"将输入空间切割成多个区域
具体到XOR问题:
假设隐藏层有2个ReLU神经元:
- 神经元1学习:x₁+x₂=0.5这条线
- 当x₁+x₂>0.5时激活
- 当x₁+x₂≤0.5时关闭
- 神经元2学习:x₁+x₂=1.5这条线
- 当x₁+x₂>1.5时激活
- 当x₁+x₂≤1.5时关闭
空间切割效果:
两条线将平面分成3个区域:
- 区域1(两线下方):神经元1关闭,神经元2关闭
- 区域2(两线之间):神经元1激活,神经元2关闭
- 区域3(两线上方):神经元1激活,神经元2激活
输出层组合:
输出层学习不同区域的权重:
- 区域1 → 输出0(红色点C)
- 区域2 → 输出1(蓝色点A和D)
- 区域3 → 输出0(红色点B)
关键机制: ReLU通过"开关"机制,让网络学会在不同区域使用不同的线性函数,组合起来就形成了分段线性的决策边界!
(非线性激活函数必要性)参考资料:
网络结构:输入层(2) → 隐藏层(4) → 输出层(1)
参考资料:
4.2 完整代码实现 💻
python
import torch
import torch.nn as nn
import torch.optim as optim
class FeedforwardNN(nn.Module):
"""
前馈神经网络实现
结构:输入层(2) → 隐藏层(4, ReLU) → 输出层(1, Sigmoid)
参数:
input_size: 输入维度
hidden_size: 隐藏层神经元数量
output_size: 输出维度
"""
def __init__(self, input_size=2, hidden_size=4, output_size=1):
super(FeedforwardNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size) # 输入 → 隐藏
self.relu = nn.ReLU() # 非线性激活
self.fc2 = nn.Linear(hidden_size, output_size) # 隐藏 → 输出
self.sigmoid = nn.Sigmoid() # 输出概率
def forward(self, x):
x = self.fc1(x) # 线性变换:2 → 4
x = self.relu(x) # 非线性激活
x = self.fc2(x) # 线性变换:4 → 1
x = self.sigmoid(x) # 输出 0~1 概率
return x4.3 代码逐行解析 🔍
第1步:定义网络结构
python
self.fc1 = nn.Linear(input_size, hidden_size)nn.Linear(2, 4) 创建一个全连接层,将 2 维输入映射到 4 维隐藏空间。它内部包含一个权重矩阵 W(形状 [4, 2])和一个偏置向量 b(形状 [4])。
什么是全连接层(Linear / Dense)?
全连接层是神经网络最基本的组件,它执行的操作是:
css
output = input × W^T + b- 输入向量与权重矩阵相乘(线性变换)
- 加上偏置项
- 输出到下一层
"全连接"的意思是:上一层的每个神经元都与下一层的每个神经元相连,每个连接都有一个独立的权重。
第2步:激活函数
python
self.relu = nn.ReLU()ReLU(Rectified Linear Unit)的公式是 max(0, x):
- 输入为正 → 原样输出
- 输入为负 → 输出 0
为什么隐藏层用 ReLU 而不是 Sigmoid?
- 计算快: ReLU 只是简单的比较操作
- 缓解梯度消失: ReLU 在正区间的导数为 1,梯度不会衰减
- 稀疏激活: 负值直接截断为 0,让网络更稀疏
第3步:输出层
python
self.fc2 = nn.Linear(hidden_size, output_size)
self.sigmoid = nn.Sigmoid()输出层将隐藏层特征映射到最终输出。Sigmoid 将输出压缩到 (0, 1) 区间,适合二分类任务。
为什么输出层用 Sigmoid?
对于二分类问题,Sigmoid 的输出天然适合解释为"属于正类的概率":
- 输出 > 0.5 → 预测为正类(1)
- 输出 < 0.5 → 预测为负类(0)
参考资料:
- PyTorch官方文档 - nn.Linear
- PyTorch官方文档 - nn.ReLU
- Mastering XOR Problem with PyTorch -- codegenes.net
- Building a Neural Network from Scratch -- TeraSystems
4.4 训练前馈神经网络解决 XOR
python
# XOR 数据集
X = torch.tensor([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=torch.float32)
y = torch.tensor([[0], [1], [1], [0]], dtype=torch.float32)
# 创建模型
model = FeedforwardNN(input_size=2, hidden_size=4, output_size=1)
# 损失函数:二元交叉熵
criterion = nn.BCELoss()
# 优化器:Adam(自适应学习率,收敛更快)
optimizer = optim.Adam(model.parameters(), lr=0.1)
# 记录训练过程
loss_history = []
# 训练
num_epochs = 2000
for epoch in range(num_epochs):
# 1. 前向传播:计算预测值
outputs = model(X)
loss = criterion(outputs, y)
loss_history.append(loss.item())
# 2. 反向传播:计算梯度
optimizer.zero_grad() # 清零上一步的梯度
loss.backward() # 自动计算所有参数的梯度
# 3. 更新参数
optimizer.step() # 根据梯度更新权重
if (epoch + 1) % 400 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# 测试
with torch.no_grad():
predicted = model(X)
predicted_class = (predicted > 0.5).float()
print(f'\nXOR 预测结果: {predicted_class.flatten().tolist()}')
print(f'XOR 真实标签: {y.flatten().tolist()}')
print(f'预测概率: {[f"{p:.4f}" for p in predicted.flatten().tolist()]}')运行输出示例:
less
Epoch [400/2000], Loss: 0.5213
Epoch [800/2000], Loss: 0.1523
Epoch [1200/2000], Loss: 0.0421
Epoch [1600/2000], Loss: 0.0156
Epoch [2000/2000], Loss: 0.0078
XOR 预测结果: [0.0, 1.0, 1.0, 0.0]
XOR 真实标签: [0.0, 1.0, 1.0, 0.0]
预测概率: ['0.0023', '0.9978', '0.9981', '0.0031']✅ 前馈神经网络成功学会了 XOR!
4.5 训练循环三步拆解 🔄
每个 epoch 包含三个关键步骤:
步骤1:前向传播(Forward Pass)
python
outputs = model(X)
loss = criterion(outputs, y)发生了什么?
数据从输入层流向输出层,逐层计算:
输入层 → 隐藏层 → 输出层 → 损失计算具体计算过程:
ini
第1层(隐藏层):
z₁ = X × W₁ᵀ + b₁ # 线性变换
h = ReLU(z₁) # 非线性激活
第2层(输出层):
z₂ = h × W₂ᵀ + b₂ # 线性变换
outputs = Sigmoid(z₂) # 压缩到(0,1)
损失计算:
loss = BCE(outputs, y) # 计算预测与真实的差距前向传播的目的: 得到当前参数下的预测值,并计算损失。
步骤2:反向传播(Backward Pass)
python
optimizer.zero_grad() # 清零上一步的梯度
loss.backward() # 自动计算所有参数的梯度发生了什么?
从输出层开始,沿着网络反向计算每个参数的梯度:
输出层 → 隐藏层 → 输入层(链式法则)链式法则(Chain Rule):
反向传播的核心是微积分中的链式法则。以权重 W₂ 为例:
∂Loss/∂W₂ = ∂Loss/∂outputs × ∂outputs/∂z₂ × ∂z₂/∂W₂∂Loss/∂outputs:损失对输出的导数∂outputs/∂z₂:Sigmoid 的导数∂z₂/∂W₂:线性变换的导数(就是隐藏层输出 h)
梯度是什么?
梯度告诉我们应该往哪个方向调整参数才能让损失减小:
- 梯度为正 → 减小参数可以降低损失
- 梯度为负 → 增大参数可以降低损失
- 梯度绝对值大 → 该参数对损失影响大,需要大幅调整
为什么每次都要 optimizer.zero_grad()?
PyTorch 默认会累加梯度。如果不手动清零,每次的梯度会叠加到上一次上。
具体后果举例:
假设第1轮计算的梯度是 0.5,第2轮计算的梯度是 0.3:
bash
# 第1轮
loss.backward()
# 此时 grad = 0.5
optimizer.step()
# 参数更新:W = W - lr × 0.5
# 第2轮(没有 zero_grad)
loss.backward()
# 此时 grad = 0.5 + 0.3 = 0.8 ← 梯度累加了!
optimizer.step()
# 参数更新:W = W - lr × 0.8 ← 更新步长错误!问题所在:
- 第2轮应该用 0.3 更新参数,实际却用了 0.8
- 随着训练进行,梯度会越来越大,更新步长失控
- 模型无法收敛,损失可能震荡甚至发散
正确做法:
python
optimizer.zero_grad() # 清零:grad = 0
loss.backward() # 计算新梯度:grad = 0.3
optimizer.step() # 正确更新:W = W - lr × 0.3PyTorch 为什么设计成累加?
为了方便梯度累积(Gradient Accumulation)场景:
- 当显存不够大时,可以用小 batch 训练
- 累积多个小 batch 的梯度,模拟大 batch 的效果
- 累积完成后调用
optimizer.step(),再zero_grad()
python
# 梯度累积示例:模拟 batch_size=32 的效果
accumulation_steps = 4
for i, (inputs, labels) in enumerate(dataloader):
outputs = model(inputs)
loss = criterion(outputs, labels)
loss = loss / accumulation_steps # 梯度缩放
loss.backward() # 梯度累加
if (i + 1) % accumulation_steps == 0:
optimizer.step() # 累积4次后更新
optimizer.zero_grad() # 清零
python
# ❌ 错误:梯度会不断累加
loss.backward()
optimizer.step()
# ✅ 正确:每次先清零
optimizer.zero_grad()
loss.backward()
optimizer.step()步骤3:参数更新(Parameter Update)
python
optimizer.step() # 根据梯度更新权重发生了什么?
优化器使用梯度更新所有参数:
ini
W_new = W_old - learning_rate × ∂Loss/∂W
b_new = b_old - learning_rate × ∂Loss/∂bAdam 优化器的优势:
相比简单的随机梯度下降(SGD),Adam 优化器:
- 自适应学习率: 每个参数有独立的学习率
- 动量机制: 考虑历史梯度,加速收敛
- 更稳定: 对学习率不敏感,不容易发散
学习率的作用:
学习率(lr=0.1)控制每次更新的步长:
- 学习率太大 → 步长过大,可能跳过最优解
- 学习率太小 → 步长过小,收敛太慢
- 合适学习率 → 平稳收敛到最优解
| 步骤 | 代码 | 作用 |
|---|---|---|
| 前向传播 | outputs = model(X) |
输入数据流经网络,得到预测值 |
| 反向传播 | loss.backward() |
从输出层反向计算每个参数的梯度 |
| 参数更新 | optimizer.step() |
用梯度更新权重,让预测更准确 |
(训练循环三步拆解)参考资料:
- Neural Network: Training & Backpropagation -- Cornell CS4780
- Backpropagation & Gradient Descent -- TensorTonic
- 深度学习之前馈神经网络(前向传播和误差反向传播) -- CSDN博客
参考资料:
5. 激活函数可视化 👁️
本章通过曲线图直观对比三种常用激活函数
激活函数是前馈神经网络的"非线性灵魂"。下面用代码绘制 Sigmoid、Tanh、ReLU 的曲线:
python
import torch
import matplotlib.pyplot as plt
import numpy as np
# 设置 Matplotlib 支持中文显示
# 优先使用系统可用的中文字体
import platform
system = platform.system()
if system == 'Windows':
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei', 'DejaVu Sans']
elif system == 'Darwin': # macOS
plt.rcParams['font.sans-serif'] = ['PingFang SC', 'Arial Unicode MS', 'DejaVu Sans']
else: # Linux
plt.rcParams['font.sans-serif'] = ['WenQuanYi Micro Hei', 'Noto Sans CJK SC', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 设置数学字体为STIX,解决上标/下标字符显示问题
plt.rcParams['mathtext.fontset'] = 'stix'
# 生成 x 轴数据:-5 到 5,200个点
x = torch.linspace(-5, 5, 200)
# 计算三种激活函数的输出
y_sigmoid = torch.sigmoid(x)
y_tanh = torch.tanh(x)
y_relu = torch.relu(x)
# 绘图
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# Sigmoid
axes[0].plot(x.numpy(), y_sigmoid.numpy(), color='#2196F3', linewidth=2)
axes[0].axhline(y=0, color='gray', linestyle='--', linewidth=0.5)
axes[0].axhline(y=1, color='gray', linestyle='--', linewidth=0.5)
axes[0].set_title('Sigmoid\n$\\sigma(x) = 1/(1+e^{-x})$', fontsize=12)
axes[0].set_xlabel('x')
axes[0].set_ylabel('$\\sigma(x)$')
axes[0].set_ylim(-0.1, 1.1)
axes[0].grid(True, alpha=0.3)
axes[0].text(2, 0.15, '输出范围: (0, 1)', fontsize=9, color='#666')
# Tanh
axes[1].plot(x.numpy(), y_tanh.numpy(), color='#4CAF50', linewidth=2)
axes[1].axhline(y=0, color='gray', linestyle='--', linewidth=0.5)
axes[1].axhline(y=1, color='gray', linestyle='--', linewidth=0.5)
axes[1].axhline(y=-1, color='gray', linestyle='--', linewidth=0.5)
axes[1].set_title('Tanh\n$\\tanh(x) = (e^{x}-e^{-x})/(e^{x}+e^{-x})$', fontsize=12)
axes[1].set_xlabel('x')
axes[1].set_ylabel('$\\tanh(x)$')
axes[1].set_ylim(-1.1, 1.1)
axes[1].grid(True, alpha=0.3)
axes[1].text(2, -0.7, '输出范围: (-1, 1)', fontsize=9, color='#666')
# ReLU
axes[2].plot(x.numpy(), y_relu.numpy(), color='#FF5722', linewidth=2)
axes[2].axhline(y=0, color='gray', linestyle='--', linewidth=0.5)
axes[2].set_title('ReLU\n$ReLU(x) = \\max(0, x)$', fontsize=12)
axes[2].set_xlabel('x')
axes[2].set_ylabel('$ReLU(x)$')
axes[2].set_ylim(-0.5, 5.5)
axes[2].grid(True, alpha=0.3)
axes[2].text(2, 0.5, '输出范围: [0, +$\\infty$)', fontsize=9, color='#666')
plt.suptitle('三种常用激活函数对比', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('01d-前馈神经网络-代码实现_第5章激活函数可视化.png', dpi=150, bbox_inches='tight')
print("图片已保存为 01d-前馈神经网络-代码实现_第5章激活函数可视化.png")
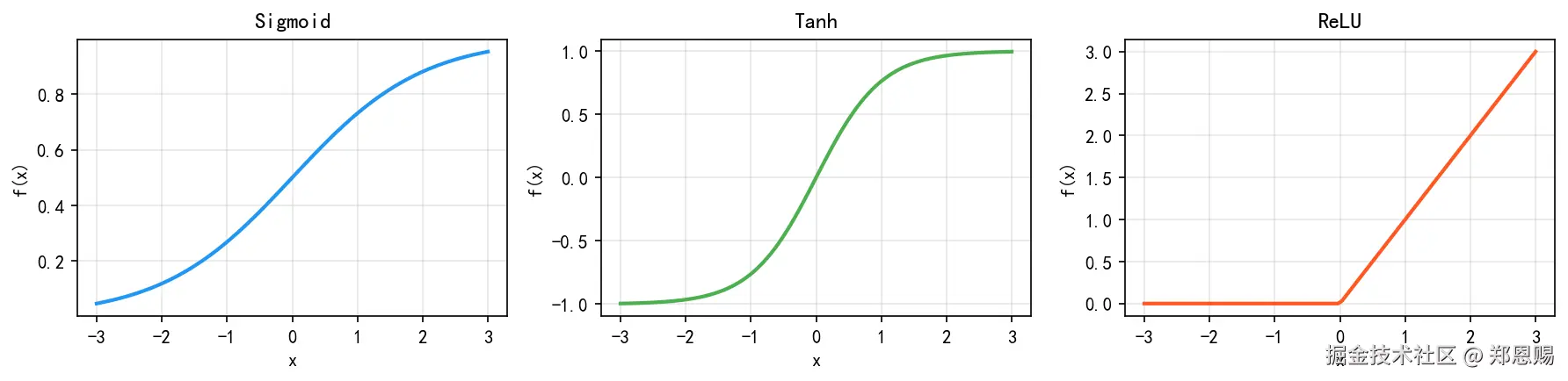
plt.show()激活函数可视化结果:
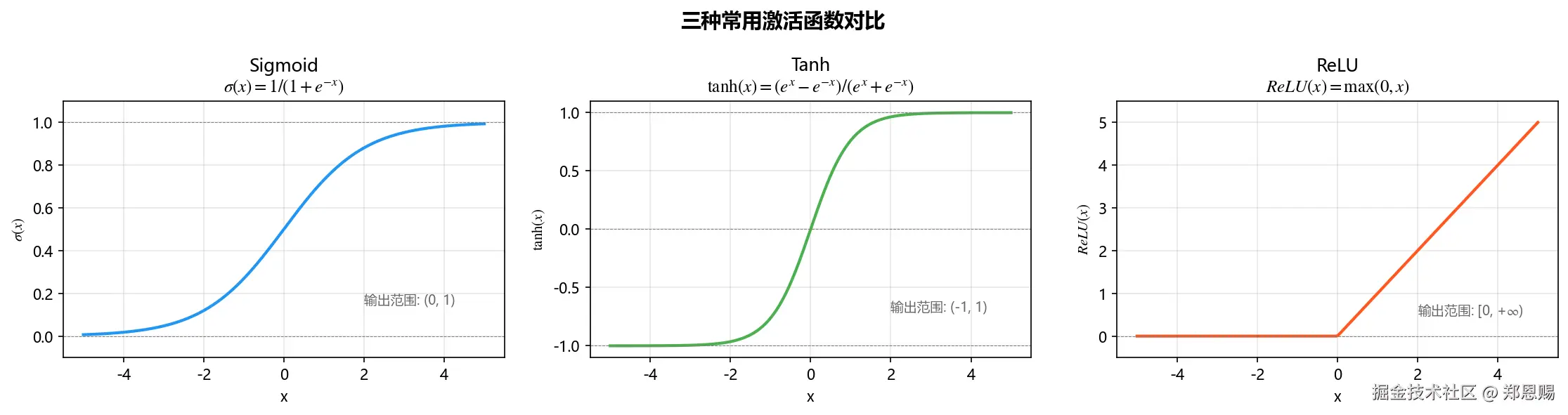
三种激活函数对比总结:
| 函数 | 公式 | 输出范围 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| Sigmoid | 1/(1+e⁻ˣ) | (0, 1) | 输出可解释为概率 | 梯度消失、非零中心 | 二分类输出层 |
| Tanh | (eˣ-e⁻ˣ)/(eˣ+e⁻ˣ) | (-1, 1) | 零中心化 | 仍有梯度消失 | RNN/LSTM |
| ReLU | max(0, x) | [0, +∞) | 计算快、缓解梯度消失 | 神经元可能"死亡" | 隐藏层首选 |
💡 "神经元死亡"问题: 当某个神经元对所有输入都输出 0 时,它的梯度永远为 0,权重不再更新,这个神经元就"死"了。可以通过使用 LeakyReLU(
max(0.01x, x))来缓解。
参考资料:
- 激活函数:神经网络的「非线性灵魂」-- CSDN
- 激活函数基础:ReLU、Sigmoid、Tanh对比 -- CSDN
- PyTorch Activation Functions Visualization -- GitHub
6. 完整可运行示例 🚀
本章整合所有内容,提供一个可直接运行的完整示例
python
"""
前馈神经网络完整示例
====================
从感知机到前馈神经网络,完整演示:
1. 感知机解决 AND/OR(线性可分)
2. 感知机无法解决 XOR(线性不可分)
3. 前馈神经网络解决 XOR(引入隐藏层+激活函数)
4. 激活函数可视化
5. 训练过程可视化
"""
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
# ==================== 1. 环境配置 ====================
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
torch.manual_seed(42) # 固定随机种子,保证结果可复现
# ==================== 2. 模型定义 ====================
class Perceptron(nn.Module):
"""单层感知机:输入 → 输出(无隐藏层)"""
def __init__(self, input_size):
super(Perceptron, self).__init__()
self.linear = nn.Linear(input_size, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return self.sigmoid(self.linear(x))
class FeedforwardNN(nn.Module):
"""前馈神经网络:输入 → 隐藏层(ReLU) → 输出(Sigmoid)"""
def __init__(self, input_size=2, hidden_size=4, output_size=1):
super(FeedforwardNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.relu(self.fc1(x))
return self.sigmoid(self.fc2(x))
# ==================== 3. 训练函数 ====================
def train_model(model, X, y, lr=0.1, epochs=2000, verbose=True):
"""通用训练函数"""
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
loss_history = []
for epoch in range(epochs):
outputs = model(X)
loss = criterion(outputs, y)
loss_history.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if verbose:
print(f'训练完成,最终 Loss: {loss_history[-1]:.6f}')
return loss_history
def evaluate(model, X, y, name=""):
"""评估模型准确率"""
with torch.no_grad():
predicted = model(X)
predicted_class = (predicted > 0.5).float()
accuracy = (predicted_class == y).float().mean().item()
print(f'{name} 准确率: {accuracy*100:.1f}%')
print(f' 预测: {predicted_class.flatten().tolist()}')
print(f' 真实: {y.flatten().tolist()}')
return accuracy
# ==================== 4. 数据集 ====================
X_data = torch.tensor([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=torch.float32)
y_and = torch.tensor([[0], [0], [0], [1]], dtype=torch.float32)
y_or = torch.tensor([[0], [1], [1], [1]], dtype=torch.float32)
y_xor = torch.tensor([[0], [1], [1], [0]], dtype=torch.float32)
# ==================== 5. 实验一:感知机解决 AND/OR ====================
print("=" * 50)
print("实验一:感知机解决 AND 和 OR")
print("=" * 50)
# AND
p_and = Perceptron(2)
train_model(p_and, X_data, y_and, lr=0.1, epochs=1000)
evaluate(p_and, X_data, y_and, "感知机-AND")
# OR
p_or = Perceptron(2)
train_model(p_or, X_data, y_or, lr=0.1, epochs=1000)
evaluate(p_or, X_data, y_or, "感知机-OR")
# ==================== 6. 实验二:感知机尝试 XOR(必然失败)====================
print("\n" + "=" * 50)
print("实验二:感知机尝试 XOR(预期失败)")
print("=" * 50)
p_xor = Perceptron(2)
loss_p = train_model(p_xor, X_data, y_xor, lr=0.1, epochs=2000)
evaluate(p_xor, X_data, y_xor, "感知机-XOR")
# ==================== 7. 实验三:前馈神经网络解决 XOR ====================
print("\n" + "=" * 50)
print("实验三:前馈神经网络解决 XOR")
print("=" * 50)
fnn = FeedforwardNN(input_size=2, hidden_size=4, output_size=1)
loss_fnn = train_model(fnn, X_data, y_xor, lr=0.1, epochs=2000)
evaluate(fnn, X_data, y_xor, "前馈神经网络-XOR")
# 打印隐藏层学到的权重
print(f'\n隐藏层权重 W1 (4×2):\n{fnn.fc1.weight.data}')
print(f'隐藏层偏置 b1 (4):\n{fnn.fc1.bias.data}')
print(f'输出层权重 W2 (1×4):\n{fnn.fc2.weight.data}')
print(f'输出层偏置 b2 (1):\n{fnn.fc2.bias.data}')
# ==================== 8. 可视化 ====================
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 左图:感知机 vs 前馈神经网络 的 Loss 曲线
axes[0].plot(loss_p, label='感知机 (失败)', color='#FF5722', linewidth=1.5, alpha=0.8)
axes[0].plot(loss_fnn, label='前馈神经网络 (成功)', color='#4CAF50', linewidth=1.5)
axes[0].axhline(y=0.6931, color='gray', linestyle='--', linewidth=0.8,
label='随机猜测基线 ln(2)≈0.693')
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('Loss (BCE)')
axes[0].set_title('XOR 问题:感知机 vs 前馈神经网络')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 右图:激活函数曲线
x_vals = torch.linspace(-5, 5, 200)
axes[1].plot(x_vals.numpy(), torch.sigmoid(x_vals).numpy(),
label='Sigmoid', color='#2196F3', linewidth=1.5)
axes[1].plot(x_vals.numpy(), torch.tanh(x_vals).numpy(),
label='Tanh', color='#4CAF50', linewidth=1.5)
axes[1].plot(x_vals.numpy(), torch.relu(x_vals).numpy(),
label='ReLU', color='#FF5722', linewidth=1.5)
axes[1].axhline(y=0, color='gray', linestyle='--', linewidth=0.5)
axes[1].set_xlabel('x')
axes[1].set_ylabel('f(x)')
axes[1].set_title('三种激活函数对比')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
axes[1].set_ylim(-1.5, 5.5)
plt.suptitle('前馈神经网络代码实现 - 完整示例', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('01d-前馈神经网络-代码实现_第6章完整示例可视化.png', dpi=150, bbox_inches='tight')
print("\n图片已保存为 01d-前馈神经网络-代码实现_第6章完整示例可视化.png")
plt.show()
print("\n✅ 所有实验完成!")训练过程可视化:
激活函数可视化:
运行后输出示例:
yaml
01d-前馈神经网络代码实现 - 第6章:完整可运行示例
======================================================================
=== 感知机解决线性可分问题 ===
AND 准确率: 100.0%
OR 准确率: 100.0%
XOR 准确率: 50.0% (随机猜测)
=== 前馈神经网络解决 XOR 问题 ===
Epoch [500/2000], Loss: 0.0004
Epoch [1000/2000], Loss: 0.0001
Epoch [1500/2000], Loss: 0.0001
Epoch [2000/2000], Loss: 0.0000
XOR 准确率: 100.0%
✅ 训练过程图已保存为 01d-前馈神经网络-代码实现_第6章训练过程可视化.png
✅ 激活函数图已保存为 01d-前馈神经网络-代码实现_第6章激活函数可视化.png
======================================================================
🎉 完整示例运行完成!
💡 关键结论:
• 感知机能解决 AND/OR(线性可分)
• 感知机无法解决 XOR(线性不可分)
• 前馈神经网络(隐藏层+激活函数)能解决 XOR
• 激活函数提供非线性,让网络真正"深"起来
======================================================================7. 总结 📝
本章回顾核心要点
| 知识点 | 核心要点 |
|---|---|
| 感知机 | 单层网络,只能解决线性可分问题(AND/OR ✅,XOR ❌) |
| XOR 问题 | 线性不可分的经典案例,感知机 Loss 卡在 0.6931 |
| 前馈神经网络 | 引入隐藏层 + 非线性激活函数,突破线性限制 |
| 隐藏层 | 将原始输入映射到新特征空间,让不可分变得可分 |
| 激活函数 | Sigmoid(输出层)、ReLU(隐藏层首选)、Tanh(零中心) |
| 训练循环 | 前向传播 → 计算损失 → 反向传播 → 参数更新 |
| zero_grad() | 每次迭代前清零梯度,防止梯度累加 |
前馈神经网络的意义 🌟
前馈神经网络是深度学习的基石:
- 它证明了多层网络可以逼近任意函数(万能近似定理)
- 它开启了非线性问题求解的大门
- 它是 CNN、RNN、Transformer 等所有深度学习模型的理论基础
- 在 Transformer 中,每个编码器和解码器层都包含一个前馈神经网络子层(FFN),负责对注意力输出做进一步的非线性变换
最后更新时间:2026-05-05