第二章 贝尔曼方程
引言
本讲介绍强化学习中两个核心概念:
-
状态值 (State Value):评估状态的价值
-
贝尔曼方程 (Bellman Equation):描述状态值之间关系的基本工具
1 动机示例 (Motivating Examples)
1.1 为什么回报很重要?
回报 (Return) 是沿轨迹获得的所有奖励的(折扣)总和。
核心问题: 从起点 s 1 s_1 s1 出发,哪个策略是"最好的"?哪个是"最坏的"?
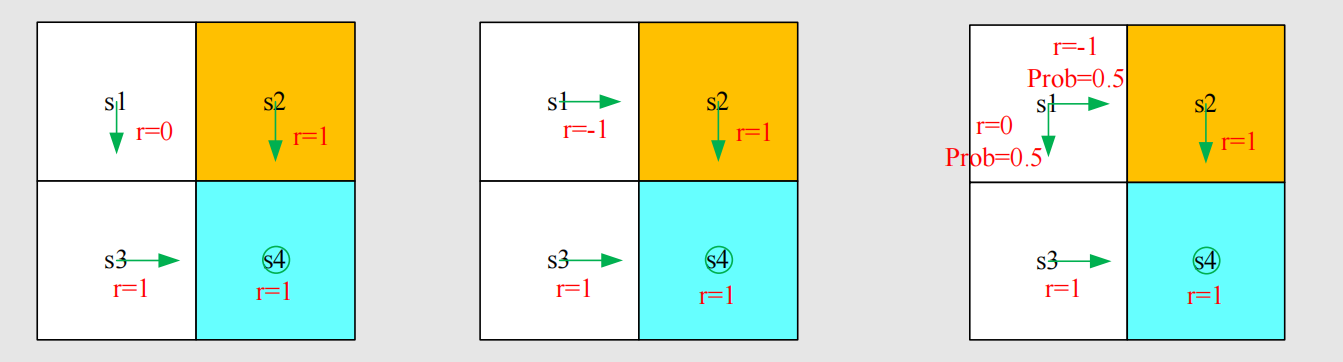
对于三个策略的折扣回报计算:
-
策略1的回报 (左图):
return 1 = 0 + γ ⋅ 1 + γ 2 ⋅ 1 + ... = γ ( 1 + γ + γ 2 + ... ) = γ 1 − γ \text{return}_1 = 0 + \gamma \cdot 1 + \gamma^2 \cdot 1 + \ldots = \gamma(1 + \gamma + \gamma^2 + \ldots) = \frac{\gamma}{1 - \gamma} return1=0+γ⋅1+γ2⋅1+...=γ(1+γ+γ2+...)=1−γγ -
策略2的回报 (中图):
return 2 = − 1 + γ ⋅ 1 + γ 2 ⋅ 1 + ... = − 1 + γ 1 − γ \text{return}_2 = -1 + \gamma \cdot 1 + \gamma^2 \cdot 1 + \ldots = -1 + \frac{\gamma}{1 - \gamma} return2=−1+γ⋅1+γ2⋅1+...=−1+1−γγ -
策略3的回报 (右图,随机策略):
return 3 = 0.5 ( − 1 + γ 1 − γ ) + 0.5 ( γ 1 − γ ) = − 0.5 + γ 1 − γ \text{return}_3 = 0.5\left(-1 + \frac{\gamma}{1 - \gamma}\right) + 0.5\left(\frac{\gamma}{1 - \gamma}\right) = -0.5 + \frac{\gamma}{1 - \gamma} return3=0.5(−1+1−γγ)+0.5(1−γγ)=−0.5+1−γγ
总结 :从 s 1 s_1 s1 出发,有:
return 1 > return 3 > return 2 \text{return}_1 > \text{return}_3 > \text{return}_2 return1>return3>return2
该不等式表明第一个策略最好,第二个策略最差,与直觉完全一致。因此,计算回报对评估策略至关重要。
1.2 如何计算回报?
考虑如下四个状态的循环问题:
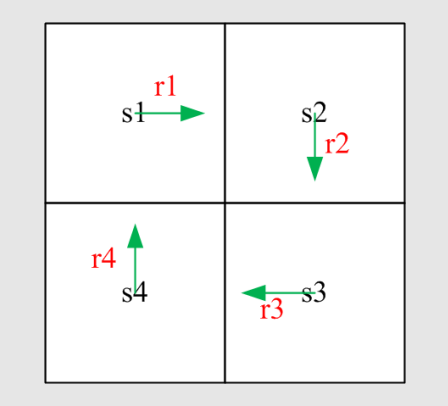
有两种方法计算回报:
方法一:按定义
令 v i v_i vi 表示从 s i s_i si 出发的回报( i = 1 , 2 , 3 , 4 i=1,2,3,4 i=1,2,3,4):
v 1 = r 1 + γ r 2 + γ 2 r 3 + ... v_1 = r_1 + \gamma r_2 + \gamma^2 r_3 + \ldots v1=r1+γr2+γ2r3+...
v 2 = r 2 + γ r 3 + γ 2 r 4 + ... v_2 = r_2 + \gamma r_3 + \gamma^2 r_4 + \ldots v2=r2+γr3+γ2r4+...
v 3 = r 3 + γ r 4 + γ 2 r 1 + ... v_3 = r_3 + \gamma r_4 + \gamma^2 r_1 + \ldots v3=r3+γr4+γ2r1+...
v 4 = r 4 + γ r 1 + γ 2 r 2 + ... v_4 = r_4 + \gamma r_1 + \gamma^2 r_2 + \ldots v4=r4+γr1+γ2r2+...
方法二:使用递推关系(Bootstrapping)
v 1 = r 1 + γ v 2 v_1 = r_1 + \gamma v_2 v1=r1+γv2
v 2 = r 2 + γ v 3 v_2 = r_2 + \gamma v_3 v2=r2+γv3
v 3 = r 3 + γ v 4 v_3 = r_3 + \gamma v_4 v3=r3+γv4
v 4 = r 4 + γ v 1 v_4 = r_4 + \gamma v_1 v4=r4+γv1
核心思想:返回值相互依赖------一个状态的值依赖于其他状态的值。
可以将上述方程写成矩阵-向量形式 :
v = r + γ P v \mathbf{v} = \mathbf{r} + \gamma \mathbf{P}\mathbf{v} v=r+γPv
这就是贝尔曼方程 (针对此特定确定性问题的形式),其中 P P P 表示状态转移矩阵。虽然简单,但它展示了核心思想:一个状态的值依赖于其他状态的值。
2 状态值 (State Value)
2.1 单步过程
考虑如下单步过程:
S t → A t R t + 1 , S t + 1 S_t \xrightarrow{A_t} R_{t+1}, S_{t+1} StAt Rt+1,St+1
其中:
-
t , t + 1 t, t+1 t,t+1:离散时间点
-
S t S_t St:时刻 t t t 的状态
-
A t A_t At:在状态 S t S_t St 采取的动作
-
R t + 1 R_{t+1} Rt+1:采取动作 A t A_t At 后获得的奖励
-
S t + 1 S_{t+1} St+1:采取动作 A t A_t At 后转移到的状态
注意 : S t , A t , R t + 1 S_t, A_t, R_{t+1} St,At,Rt+1 都是随机变量。
该步骤由以下概率分布支配:
-
S t → A t S_t \to A_t St→At:由 π ( A t = a ∣ S t = s ) \pi(A_t = a | S_t = s) π(At=a∣St=s) 支配
-
S t , A t → R t + 1 S_t, A_t \to R_{t+1} St,At→Rt+1:由 p ( R t + 1 = r ∣ S t = s , A t = a ) p(R_{t+1} = r | S_t = s, A_t = a) p(Rt+1=r∣St=s,At=a) 支配
-
S t , A t → S t + 1 S_t, A_t \to S_{t+1} St,At→St+1:由 p ( S t + 1 = s ′ ∣ S t = s , A t = a ) p(S_{t+1} = s' | S_t = s, A_t = a) p(St+1=s′∣St=s,At=a) 支配
注意:此时假设我们已知模型(即概率分布)。
2.2 多步轨迹与回报
考虑如下多步轨迹:
S t → A t R t + 1 , S t + 1 → A t + 1 R t + 2 , S t + 2 → A t + 2 R t + 3 , ... S_t \xrightarrow{A_t} R_{t+1}, S_{t+1} \xrightarrow{A_{t+1}} R_{t+2}, S_{t+2} \xrightarrow{A_{t+2}} R_{t+3}, \ldots StAt Rt+1,St+1At+1 Rt+2,St+2At+2 Rt+3,...
折扣回报为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ... G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \ldots Gt=Rt+1+γRt+2+γ2Rt+3+...
其中 γ ∈ [ 0 , 1 ) \gamma \in [0,1) γ∈[0,1) 是折扣率。 G t G_t Gt 也是随机变量,因为 R t + 1 , R t + 2 , ... R_{t+1}, R_{t+2}, \ldots Rt+1,Rt+2,... 是随机变量。
2.3 状态值函数
G t G_t Gt 的期望定义为状态值函数 或简称状态值:
v π ( s ) = E G t ∣ S t = s v_\pi(s) = \mathbb{E}G_t \| S_t = s vπ(s)=EGt∣St=s
备注:
-
它是 s s s 的函数。这是一个条件期望,条件是状态从 s s s 开始。
-
它基于策略 π \pi π。对于不同的策略,状态值可能不同。
-
它代表一个状态的"价值"。如果状态值越大,说明策略越好,因为可以获得更大的累积奖励。
问题:回报 G G G 和状态值 v v v 之间有什么关系?
回答:状态值是从一个状态出发所能获得的所有可能回报的均值。如果一切------ π ( a ∣ s ) , p ( r ∣ s , a ) , p ( s ′ ∣ s , a ) \pi(a|s), p(r|s,a), p(s'|s,a) π(a∣s),p(r∣s,a),p(s′∣s,a)------都是确定性的,那么状态值就等于回报。
示例:
回忆三个策略从 s 1 s_1 s1 获得的回报(即状态值):
v π 1 ( s 1 ) = γ 1 − γ v_{\pi_1}(s_1) = \frac{\gamma}{1 - \gamma} vπ1(s1)=1−γγ
v π 2 ( s 1 ) = − 1 + γ 1 − γ v_{\pi_2}(s_1) = -1 + \frac{\gamma}{1 - \gamma} vπ2(s1)=−1+1−γγ
v π 3 ( s 1 ) = − 0.5 + γ 1 − γ v_{\pi_3}(s_1) = -0.5 + \frac{\gamma}{1 - \gamma} vπ3(s1)=−0.5+1−γγ
3 贝尔曼方程的推导 (Bellman Equation: Derivation)
核心思想:贝尔曼方程描述了所有状态值之间的关系。
推导过程:
考虑一条随机轨迹,回报 G t G_t Gt 可以写为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ... = R t + 1 + γ G t + 1 G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \ldots = R_{t+1} + \gamma G_{t+1} Gt=Rt+1+γRt+2+γ2Rt+3+...=Rt+1+γGt+1
根据状态值的定义:
v π ( s ) = E G t ∣ S t = s = E R t + 1 + γ G t + 1 ∣ S t = s = E R t + 1 ∣ S t = s + γ E G t + 1 ∣ S t = s v_\pi(s) = \mathbb{E}G_t \| S_t = s = \mathbb{E}R_{t+1} + \\gamma G_{t+1} \| S_t = s = {\color{red}\mathbb{E}R_{t+1} \| S_t = s} + \gamma {\color{red}\mathbb{E}G_{t+1} \| S_t = s} vπ(s)=EGt∣St=s=ERt+1+γGt+1∣St=s=ERt+1∣St=s+γEGt+1∣St=s
接下来分别计算两项。
第一项 : E R t + 1 ∣ S t = s \mathbb{E}R_{t+1} \| S_t = s ERt+1∣St=s------即时奖励的均值
E R t + 1 ∣ S t = s = ∑ a π ( a ∣ s ) E R t + 1 ∣ S t = s , A t = a = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r \begin{array}{ll} \mathbb{E}R_{t+1} \| S_t = s & = \sum_a \pi(a|s) \mathbb{E}R_{t+1} \| S_t = s, A_t = a \\ & = \sum_a \pi(a|s) \sum_r p(r|s,a) r \end{array} ERt+1∣St=s=∑aπ(a∣s)ERt+1∣St=s,At=a=∑aπ(a∣s)∑rp(r∣s,a)r
第二项 : E G t + 1 ∣ S t = s \mathbb{E}G_{t+1} \| S_t = s EGt+1∣St=s------未来奖励的均值
E G t + 1 ∣ S t = s = ∑ s ′ E G t + 1 ∣ S t = s , S t + 1 = s ′ p ( s ′ ∣ s ) = ∑ s ′ E G t + 1 ∣ S t + 1 = s ′ p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) ∑ a p ( s ′ ∣ s , a ) π ( a ∣ s ) \begin{array}{ll} \mathbb{E}G_{t+1} \| S_t = s & = \sum_{s'} \mathbb{E}G_{t+1} \| S_t = s, S_{t+1} = s' p(s'|s) \\ & = \sum_{s'} \mathbb{E}G_{t+1} \| S_{t+1} = s' p(s'|s) \\ & = \sum_{s'} v_\pi(s') p(s'|s) \\ & = \sum_{s'} v_\pi(s') \sum_a p(s'|s,a) \pi(a|s) \end{array} EGt+1∣St=s=∑s′EGt+1∣St=s,St+1=s′p(s′∣s)=∑s′EGt+1∣St+1=s′p(s′∣s)=∑s′vπ(s′)p(s′∣s)=∑s′vπ(s′)∑ap(s′∣s,a)π(a∣s)
其中 E G t + 1 ∣ S t = s , S t + 1 = s ′ = E G t + 1 ∣ S t + 1 = s ′ \mathbb{E}G_{t+1} \| S_t = s, S_{t+1} = s' = \mathbb{E}G_{t+1} \| S_{t+1} = s' EGt+1∣St=s,St+1=s′=EGt+1∣St+1=s′ 是根据马尔可夫的无记忆性。
完整的贝尔曼方程:
v π ( s ) = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r + γ ∑ a π ( a ∣ s ) ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) , ∀ s ∈ S \begin{array}{ll} v_\pi(s) &= \sum_a \pi(a|s) \sum_r p(r|s,a) r + \gamma \sum_a \pi(a|s) \sum_{s'} p(s'|s,a) v_\pi(s') \\ & = \sum_a \pi(a|s) \left \\sum_r p(r\|s,a)r + \\gamma \\sum_s\^{\\prime}p(s\^\\prime\|s,a) v_{\\pi}(s\^\\prime) \\right, \forall s \in S \end{array} vπ(s)=∑aπ(a∣s)∑rp(r∣s,a)r+γ∑aπ(a∣s)∑s′p(s′∣s,a)vπ(s′)=∑aπ(a∣s)∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)vπ(s′),∀s∈S
要点:
-
该方程描述了不同状态的状态值函数之间的关系。
-
它由两项组成:即时奖励项 和未来奖励项。
-
这是一组方程:每个状态都有一个这样的方程!
-
v π ( s ) v_\pi(s) vπ(s) 和 v π ( s ′ ) v_\pi(s') vπ(s′) 是待计算的状态值(Bootstrapping!)
4 贝尔曼方程的矩阵-向量形式 (Matrix-Vector Form)
为什么要考虑矩阵-向量形式?
-
逐元素形式的贝尔曼方程对每个状态 s ∈ S s \in \mathcal{S} s∈S 都成立,意味着共有 ∣ S ∣ |\mathcal{S}| ∣S∣ 个这样的方程。
-
如果将所有方程放在一起,就得到一组线性方程,可以简洁地写成矩阵-向量形式。
-
矩阵-向量形式优雅且重要。
推导:
将贝尔曼方程重写为:
v π ( s ) = r π ( s ) + γ ∑ s ′ p π ( s ′ ∣ s ) v π ( s ′ ) ( 1 ) v_\pi(s) = r_\pi(s) + \gamma \sum_{s'} p_\pi(s'|s) v_\pi(s') \quad (1) vπ(s)=rπ(s)+γs′∑pπ(s′∣s)vπ(s′)(1)
其中:
r π ( s ) ≜ ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r , p π ( s ′ ∣ s ) ≜ ∑ a π ( a ∣ s ) p ( s ′ ∣ s , a ) r_\pi(s) \triangleq \sum_a \pi(a|s) \sum_r p(r|s,a) r, \qquad p_\pi(s'|s) \triangleq \sum_a \pi(a|s) p(s'|s,a) rπ(s)≜∑aπ(a∣s)∑rp(r∣s,a)r,pπ(s′∣s)≜∑aπ(a∣s)p(s′∣s,a)
如果有四个状态, v π = r π + γ P π v π v_\pi = r_\pi + \gamma P_\pi v_\pi vπ=rπ+γPπvπ 可以写为:
v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) = r π ( s 1 ) r π ( s 2 ) r π ( s 3 ) r π ( s 4 ) + γ p π ( s 1 ∣ s 1 ) p π ( s 2 ∣ s 1 ) p π ( s 3 ∣ s 1 ) p π ( s 4 ∣ s 1 ) p π ( s 1 ∣ s 2 ) p π ( s 2 ∣ s 2 ) p π ( s 3 ∣ s 2 ) p π ( s 4 ∣ s 2 ) p π ( s 1 ∣ s 3 ) p π ( s 2 ∣ s 3 ) p π ( s 3 ∣ s 3 ) p π ( s 4 ∣ s 3 ) p π ( s 1 ∣ s 4 ) p π ( s 2 ∣ s 4 ) p π ( s 3 ∣ s 4 ) p π ( s 4 ∣ s 4 ) v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) \begin{bmatrix} v_\pi(s_1) \\ v_\pi(s_2) \\ v_\pi(s_3) \\ v_\pi(s_4) \end{bmatrix} = \begin{bmatrix} r_\pi(s_1) \\ r_\pi(s_2) \\ r_\pi(s_3) \\ r_\pi(s_4) \end{bmatrix} + \gamma \begin{bmatrix} p_\pi(s_1|s_1) & p_\pi(s_2|s_1) & p_\pi(s_3|s_1) & p_\pi(s_4|s_1) \\ p_\pi(s_1|s_2) & p_\pi(s_2|s_2) & p_\pi(s_3|s_2) & p_\pi(s_4|s_2) \\ p_\pi(s_1|s_3) & p_\pi(s_2|s_3) & p_\pi(s_3|s_3) & p_\pi(s_4|s_3) \\ p_\pi(s_1|s_4) & p_\pi(s_2|s_4) & p_\pi(s_3|s_4) & p_\pi(s_4|s_4) \end{bmatrix} \begin{bmatrix} v_\pi(s_1) \\ v_\pi(s_2) \\ v_\pi(s_3) \\ v_\pi(s_4) \end{bmatrix} vπ(s1)vπ(s2)vπ(s3)vπ(s4) = rπ(s1)rπ(s2)rπ(s3)rπ(s4) +γ pπ(s1∣s1)pπ(s1∣s2)pπ(s1∣s3)pπ(s1∣s4)pπ(s2∣s1)pπ(s2∣s2)pπ(s2∣s3)pπ(s2∣s4)pπ(s3∣s1)pπ(s3∣s2)pπ(s3∣s3)pπ(s3∣s4)pπ(s4∣s1)pπ(s4∣s2)pπ(s4∣s3)pπ(s4∣s4) vπ(s1)vπ(s2)vπ(s3)vπ(s4)
对特定示例:
v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) = 0.5 ( 0 ) + 0.5 ( − 1 ) 1 1 1 + γ 0 0.5 0.5 0 0 0 0 1 0 0 0 1 0 0 0 1 v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) \begin{bmatrix} v_\pi(s_1) \\ v_\pi(s_2) \\ v_\pi(s_3) \\ v_\pi(s_4) \end{bmatrix} = \begin{bmatrix} 0.5(0) + 0.5(-1) \\ 1 \\ 1 \\ 1 \end{bmatrix} + \gamma \begin{bmatrix} 0 & 0.5 & 0.5 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} v_\pi(s_1) \\ v_\pi(s_2) \\ v_\pi(s_3) \\ v_\pi(s_4) \end{bmatrix} vπ(s1)vπ(s2)vπ(s3)vπ(s4) = 0.5(0)+0.5(−1)111 +γ 00000.50000.50000111 vπ(s1)vπ(s2)vπ(s3)vπ(s4)
5 贝尔曼方程的求解 (Solve the State Values)
为什么要解状态值?
- 给定一个策略,求出相应的状态值的过程称为策略评估 (Policy Evaluation)。这是强化学习中的一个基本问题,是寻找更好策略的基础。
求解方法:
贝尔曼方程的矩阵-向量形式:
v π = r π + γ P π v π v_\pi = r_\pi + \gamma P_\pi v_\pi vπ=rπ+γPπvπ
闭式解 (Closed-form Solution):
v π = ( I − γ P π ) − 1 r π v_\pi = (I - \gamma P_\pi)^{-1} r_\pi vπ=(I−γPπ)−1rπ
实际中仍需使用数值工具计算矩阵求逆。能否避免矩阵求逆?可以,通过迭代算法。
迭代解 (Iterative Solution):
v k + 1 = r π + γ P π v k v_{k+1} = r_\pi + \gamma P_\pi v_k vk+1=rπ+γPπvk
该算法产生一个序列 { v 0 , v 1 , v 2 , ... } \{v_0, v_1, v_2, \ldots\} {v0,v1,v2,...},可以证明:
v k → v π = ( I − γ P π ) − 1 r π , k → ∞ v_k \to v_\pi = (I - \gamma P_\pi)^{-1} r_\pi, \quad k \to \infty vk→vπ=(I−γPπ)−1rπ,k→∞
6 动作值 (Action Value)
从状态值到动作值:
-
状态值:智能体从某一状态出发所能获得的平均回报。
-
动作值:智能体从某一状态出发并采取某一动作后所能获得的平均回报。
为什么关心动作值? 因为我们想知道哪个动作更好。
定义:
q π ( s , a ) = E G t ∣ S t = s , A t = a q_\pi(s,a) = \mathbb{E}G_t \| S_t = s, A_t = a qπ(s,a)=EGt∣St=s,At=a
-
q π ( s , a ) q_\pi(s,a) qπ(s,a) 是状态-动作对 ( s , a ) (s,a) (s,a) 的函数。
-
q π ( s , a ) q_\pi(s,a) qπ(s,a) 依赖于策略 π \pi π。
根据条件期望的性质:
E G t ∣ S t = s ⏟ v π ( s ) = ∑ a E G t ∣ S t = s , A t = a ⏟ q π ( s , a ) π ( a ∣ s ) \underbrace{\mathbb{E}G_t \| S_t = s}{v\pi(s)} = \sum_a \underbrace{\mathbb{E}G_t \| S_t = s, A_t = a}{q\pi(s,a)} \pi(a|s) vπ(s) EGt∣St=s=∑aqπ(s,a) EGt∣St=s,At=aπ(a∣s)
因此:
v π ( s ) = ∑ a π ( a ∣ s ) q π ( s , a ) ( 2 ) v_\pi(s) = \sum_a \pi(a|s) q_\pi(s,a) \quad (2) vπ(s)=a∑π(a∣s)qπ(s,a)(2)
回忆状态值的贝尔曼方程:
v π ( s ) = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ( 3 ) v_\pi(s) = \sum_a \pi(a|s) \left \\sum_r p(r\|s,a) r + \\gamma \\sum_{s'} p(s'\|s,a) v_\\pi(s') \\right \quad (3) vπ(s)=a∑π(a∣s)r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)(3)
对比 (2) 和 (3),得到动作值函数:
q π ( s , a ) = ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ( 4 ) q_\pi(s,a) = \sum_r p(r|s,a) r + \gamma \sum_{s'} p(s'|s,a) v_\pi(s') \quad (4) qπ(s,a)=r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)(4)
(2) 和 (4) 是同一枚硬币的两面:
-
(2) 展示了如何从动作值获取状态值。
-
(4) 展示了如何从状态值获取动作值。
要点:
-
动作值很重要,因为我们关心采取哪个动作。
-
我们可以先计算所有状态值,然后计算动作值。
-
我们也可以在有模型或无模型的情况下直接计算动作值。
7 总结
关键概念与结果:
-
状态值 : v π ( s ) = E G t ∣ S t = s v_\pi(s) = \mathbb{E}G_t \| S_t = s vπ(s)=EGt∣St=s
-
动作值 : q π ( s , a ) = E G t ∣ S t = s , A t = a q_\pi(s,a) = \mathbb{E}G_t \| S_t = s, A_t = a qπ(s,a)=EGt∣St=s,At=a
贝尔曼方程(元素形式):
v π ( s ) = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ⏟ q π ( s , a ) = ∑ a π ( a ∣ s ) q π ( s , a ) \begin{array}{ll} v_\pi(s) &= \sum_a \pi(a|s) \underbrace{\left \\sum_r p(r\|s,a) r + \\gamma \\sum_{s'} p(s'\|s,a) v_\\pi(s') \\right}{q\pi(s,a)} \\ &= \sum_a \pi(a|s) q_\pi(s,a) \end{array} vπ(s)=∑aπ(a∣s)qπ(s,a) r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)=∑aπ(a∣s)qπ(s,a)
贝尔曼方程(矩阵-向量形式):
v π = r π + γ P π v π v_\pi = r_\pi + \gamma P_\pi v_\pi vπ=rπ+γPπvπ
贝尔曼方程的求解方法:
-
闭式解: v π = ( I − γ P π ) − 1 r π v_\pi = (I - \gamma P_\pi)^{-1} r_\pi vπ=(I−γPπ)−1rπ
-
迭代解: v k + 1 = r π + γ P π v k v_{k+1} = r_\pi + \gamma P_\pi v_k vk+1=rπ+γPπvk
参考
《Mathematical Foundations of Reinforcement Learning》,作者:赵世钰,2025年出版,清华大学出版社