一、定义
协同训练(Co-Training)是自训练的一种改进方法,通过两个基于不同视角(view)的分类器来相互促进。很多数据都有相对独立的不同视角。比如互联网上的每个网页都由两种视角组成:文字内容(text)和指向其它网页的链接(hyperlink)。如果要确定一个网页的类别,可以根据文字内容来判断,也可根据网页之间的链接关系来判断。
二、算法解析及伪代码
假设一个样本x = **x** 1, **x** 2,其中x1 和x2 分别表示两种不同视角V1 和V2的 特征,并满足下面两个假设:(1)条件独立性:给定样本标签y时,两种特征条 件独立p(x 1, x 2|y) = p(x 1|y)p(x 2|y);(2)充足和冗余性:当数据充分时,每种视角的特征都可以足以单独训练出一个正确的分类器。令y = g(x)为需要学习的真实映射函数,f1和f2分别为两个视角的分类器,有
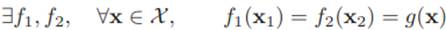
其中X 为样本x的取值空间。
由于不同视角的条件独立性,在不同视角上训练出来的模型就相当于从不同视角来理解问题,具有一定的互补性。协同训练就是利用这种互补性来来进行自训练的一种方法。首先在训练集上根据不同视角分别训练两个模型f1和f2,然后用f1和f2在无标记数据集上进行预测,各选取预测置信度比较高的样本加入训练集,重新训练两个不同视角的模型,并不断重复这个过程。算法10.3给出了协同训练的训练过程。

三、总结
协同算法要求两种视图是条件独立的。如果两种视图完全一样,则协同训练退化成自训练算法。