一、为什么需要注意力机制?
在深度学习飞速发展的当下,**注意力机制(Attention Mechanism)**已经成为各大模型的核心基石,无论是NLP领域的Transformer、大语言模型,还是CV领域的图像分类、目标检测模型,都离不开注意力机制的加持。
在注意力机制诞生之前,传统序列模型(RNN、LSTM、GRU)存在致命短板:
-
长序列依赖失效:序列过长时,会出现梯度消失、梯度爆炸问题,无法捕捉远距离特征关联;
-
信息权重均等:模型会平等对待输入的每一个信息,无法区分关键信息与冗余信息,特征提取效率极低;
-
串行计算效率低:RNN系列模型只能逐序列计算,无法并行运算,训练速度慢。
注意力机制灵感源自人类的视觉与认知习惯 ,其核心本质 :动态自适应地为输入信息分配权重,强化关键特征、抑制冗余特征,同时实现全局特征关联与并行计算。
二、注意力机制核心原理
2.1 核心逻辑:三步通用流程
所有注意力机制的底层逻辑都遵循 相似度计算→权重归一化→加权求和 三步流程,形成「需求-匹配-聚合」的完整链路:
-
相似度打分:计算当前查询信息与所有输入信息的关联程度,得到原始权重;
-
权重归一化:通过Softmax函数将原始权重转换为0-1之间的概率分布,所有权重之和为1;
-
特征加权聚合:用归一化后的权重对原始输入特征加权求和,得到聚焦关键信息的最终输出特征。
2.2 核心三要素:Q、K、V 彻底详解
现代注意力机制均基于QKV模型构建,三个矩阵是理解注意力的核心,通俗释义如下:
-
Q(Query,查询向量) :代表当前需要寻找的信息,是模型的查询目标,相当于"我想知道什么";
-
K(Key,键向量) :代表输入信息的特征标签,是所有待匹配的信息,相当于"这里有什么";
-
V(Value,值向量) :代表输入信息的真实内容,是最终需要提取的特征本身。
简单类比:查字典
Q=你要查询的汉字(查询目标),K=字典里所有汉字的索引(匹配标签),V=汉字对应的释义(真实内容)。通过Q匹配最相似的K,最终提取对应的V作为输出。
2.3 数学公式完整推导
第一步:通过线性变换生成Q、K、V矩阵(输入特征为X)
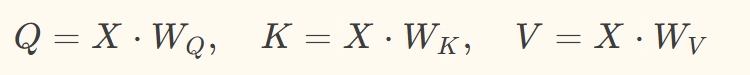
其中 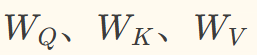 为可学习的权重参数,通过神经网络训练更新。
为可学习的权重参数,通过神经网络训练更新。
第二步:计算Q与K的点积相似度,得到原始注意力分数
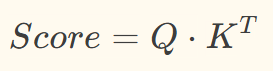
第三步:缩放操作(解决维度越高、点积结果方差越大问题)
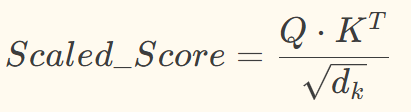
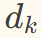 为Key向量的维度,缩放后可保证梯度稳定,利于模型训练。
为Key向量的维度,缩放后可保证梯度稳定,利于模型训练。
第四步:Softmax归一化得到最终注意力权重
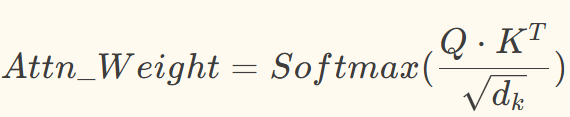
第五步:权重与V加权求和,得到注意力输出特征
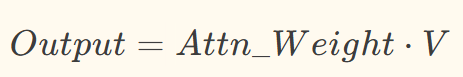
三、注意力机制主流分类详解
3.1 按计算方式分类:软性注意力 vs 硬性注意力
1)软性注意力(Soft Attention)
目前最常用的注意力方式,也是Transformer默认采用的机制。
-
特点:对所有输入特征计算权重,权重为连续概率值(0~1),所有特征都会参与输出计算;
-
优势:模型可微、梯度连续,支持反向传播训练,收敛稳定;
-
劣势:需要计算全局所有特征的相似度,计算量相对较大。
2)硬性注意力(Hard Attention)
属于稀疏注意力机制,只选取权重最大的单个/少数几个特征参与计算。
-
特点:权重为0或1的离散值,仅聚焦局部关键特征,忽略其余信息;
-
优势:计算量极小、推理速度快;
-
劣势:不可微,无法直接反向传播,训练难度大,目前极少单独使用。
3.2 经典核心:自注意力机制(Self-Attention)
自注意力机制是Transformer的核心创新,区别于传统的交叉注意力,Q、K、V均来自同一组输入,无需额外编码信息,可直接捕捉序列内部任意位置的特征关联。
核心优势:
-
打破序列距离限制,可直接捕捉长距离依赖,解决RNN长序列失效问题;
-
全局建模,每个特征都能与全局所有特征建立关联;
-
完全并行计算,大幅提升训练与推理效率。
3.3 进阶核心:多头注意力机制(Multi-Head Attention, MHA)
单头注意力只能学习单一维度的特征关联,表达能力有限。多头注意力将Q、K、V拆分为多个子空间,并行执行多组注意力计算,最后拼接融合结果。
执行流程:
-
将Q、K、V均匀拆分为h个子头(常用h=8、16);
-
每个子头独立执行缩放点积注意力计算;
-
拼接所有子头的输出特征;
-
通过全连接层融合特征,得到最终输出。
核心作用:多维度捕捉特征关联(语义、位置、语法等),大幅提升模型特征表达能力。
3.4 计算机视觉专用:通道注意力 & 空间注意力
1)通道注意力(Channel Attention)
针对图像特征图的通道维度分配权重。不同卷积通道对应不同特征(边缘、纹理、色彩等),通道注意力会强化有效特征通道,抑制无效通道。
经典代表:SE-Net,是CV领域轻量化注意力的标杆。
2)空间注意力(Spatial Attention)
针对图像特征图的空间位置维度分配权重,聚焦图像核心目标区域,抑制背景、噪声等无效区域。常与通道注意力结合使用(CBAM模块)。
四、PyTorch代码实战:缩放点积注意力实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class ScaledDotProductAttention(nn.Module):
"""
标准缩放点积注意力机制(Transformer核心)
"""
def __init__(self):
super().__init__()
def forward(self, q, k, v, mask=None):
# 获取key的维度,用于缩放
d_k = q.size(-1)
# 1.计算QK点积相似度
attn_score = torch.matmul(q, k.transpose(-2, -1))
# 2.缩放操作,稳定梯度
attn_score = attn_score / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
# 3.掩码处理(用于屏蔽padding位置、未来位置信息)
if mask is not None:
attn_score = attn_score.masked_fill(mask == 0, -1e9)
# 4.Softmax归一化得到注意力权重
attn_weight = F.softmax(attn_score, dim=-1)
# 5.加权Value得到输出特征
output = torch.matmul(attn_weight, v)
return output, attn_weight
# 测试代码
if __name__ == "__main__":
# 模拟输入:batch_size=2,序列长度=5,特征维度=64
batch_size, seq_len, dim = 2, 5, 64
q = torch.randn(batch_size, seq_len, dim)
k = torch.randn(batch_size, seq_len, dim)
v = torch.randn(batch_size, seq_len, dim)
# 初始化注意力模块
attention = ScaledDotProductAttention()
out, weight = attention(q, k, v)
print(f"输出特征维度: {out.shape}") # torch.Size([2, 5, 64])
print(f"注意力权重维度: {weight.shape}") # torch.Size([2, 5, 5])五、注意力机制优缺点总结
5.1 核心优势
-
解决长序列依赖问题:彻底摆脱RNN梯度消失缺陷,支持超长序列特征建模;
-
特征筛选能力强:自适应权重分配,聚焦核心信息,提升模型精度;
-
全局建模能力:可捕捉任意位置的特征关联,不局限于局部相邻特征;
-
支持并行计算:打破串行计算限制,大幅提升训练速度;
-
通用性极强:适配NLP、CV、语音、推荐系统等所有AI任务。
5.2 现存缺陷
-
计算复杂度高 :标准自注意力复杂度为
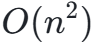 ,序列越长,计算量爆炸式增长;
,序列越长,计算量爆炸式增长; -
内存占用大:长序列场景下,注意力权重矩阵占用大量显存;
-
缺乏位置感知能力:纯注意力机制无法识别序列顺序,需额外搭配位置编码使用。
六、主流应用场景
6.1 自然语言处理(NLP)
机器翻译、文本分类、情感分析、大语言模型、文本摘要、问答系统、命名实体识别(Transformer、BERT、GPT系列核心)。
6.2 计算机视觉(CV)
图像分类、目标检测、语义分割、图像生成、超分辨率重建(SE-Net、CBAM、ViT、Swin Transformer)。
6.3 其他领域
语音识别、语音合成、推荐系统、时序预测、自动驾驶特征融合、多模态大模型。
七、注意力机制优化方向(进阶)
针对标准注意力 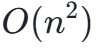 复杂度的缺陷,行业主流优化方案:
复杂度的缺陷,行业主流优化方案:
-
稀疏注意力:只计算局部关联Token,代表模型:Longformer、Sparse Transformer;
-
线性注意力 :将复杂度降为
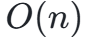 ,代表模型:Performer;
,代表模型:Performer; -
分层注意力:通过窗口划分、层级聚合降低计算量,代表模型:Swin Transformer;
-
量化注意力:通过低精度计算、权重压缩降低显存占用。