1. 为什么需要内存模型?------从一个"诡异"的 Bug 说起
我们先看一段看起来"完全没问题"的代码:
cpp
// 线程间通信:一个线程准备数据,另一个线程读取
// ❌ 这段代码存在严重的并发问题!
#include <thread>
#include <iostream>
int data = 0; // 共享数据------普通变量,没有任何同步保护
bool ready = false; // 标志位:数据是否准备好------同样是普通变量
void producer() {
data = 42; // Step 1: 写入数据
ready = true; // Step 2: 设置标志位
}
void consumer() {
while (!ready) { // Step 3: 等待标志位
// 忙等------注意:编译器可能将 ready 缓存到寄存器中,
// 导致这个循环永远不会退出!(见下面的编译器优化分析)
}
std::cout << data << std::endl; // Step 4: 读取数据
// 你期望输出 42,但可能输出 0!
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); // 等待 t1 执行完毕
t2.join(); // 等待 t2 执行完毕
return 0;
}这段代码的意图 非常清晰:生产者先写 data = 42,再设 ready = true;消费者等到 ready == true 后读取 data。逻辑上,输出应该永远是 42。
但实际上,这段代码有三个致命问题:
问题一:编译器重排序(Compiler Reordering)
编译器为了优化性能,可能会调换 data = 42 和 ready = true 的执行顺序。因为从单线程的视角看,这两条语句之间没有依赖关系,交换顺序不影响单线程的正确性。但对于多线程,顺序至关重要。
cpp
// 编译器可能将 producer() 优化为:
void producer() {
ready = true; // ← 被提前了!
data = 42; // ← 被延后了!
}
// 这样 consumer 可能在 data 还没写入时就看到 ready == true** 编译器为什么要重排序?**
指令流水线 :最朴素的 CPU 执行方式是:一条指令彻底完成,再开始下一条。但一条指令内部其实由多个步骤组成,每个步骤使用的硬件部件不同。经典的五级流水线把每条指令拆成:
| 阶段 | 缩写 | 做什么 | 用到的硬件 |
|---|---|---|---|
| 取指 | IF | 从内存取出指令 | 程序计数器、指令缓存 |
| 译码 | ID | 解析指令含义,读寄存器 | 译码器、寄存器文件 |
| 执行 | EX | 算术/逻辑运算 | ALU |
| 访存 | MEM | 读写内存(load/store) | 数据缓存 |
| 写回 | WB | 结果写回寄存器 | 寄存器文件 |
当指令 1 在做"译码"时,"取指"部件是空闲的,完全可以让指令 2 去用。这就像工厂流水线------工人 A 在给产品上螺丝时,工人 B 可以同时给下一个产品喷漆,各干各的。所以 CPU 让多条指令像这样重叠执行:
时钟周期: 1 2 3 4 5 6 7
指令1: IF ID EX MEM WB
指令2: IF ID EX MEM WB
指令3: IF ID EX MEM WB理想情况下,虽然每条指令仍需 5 个周期完成,但每个周期都能"吐出"一条指令的结果,吞吐量提升到了 5 倍。
为什么编译器敢重排?
编译器做优化时遵循的是 as-if 规则 :只要单线程的可观察行为 不变,怎么改都行。
编译器重排序的目的是优化指令流水线的利用率 。
如上面所说,现代 CPU 的指令流水线有多个阶段(取指、译码、执行、访存、写回),如果连续两条指令访问同一个内存地址 ,可能产生流水线停顿(pipeline stall) 。编译器通过重排指令来避免这种停顿,提高指令级并行度(ILP, Instruction-Level Parallelism,在一段代码中,有多少指令可以同时执行)。在单线程环境下这是完全安全的(因为编译器保证重排不改变单线程的可观察行为),但在多线程环境下就可能破坏程序员的预期。
为什么连续两条指令访问同一内存地址会导致流水线停顿?
数据冒险(Data Hazard)
cpp
// 考虑这两条连续指令:
str x1, [addr] // 指令A:把 x1 的值写入内存地址 addr
ldr x2, [addr] // 指令B:从同一个地址 addr 读值到 x2
// 在流水线里它们是重叠的:
时钟周期: 1 2 3 4 5 6
指令A(store): IF ID EX MEM WB
指令B(load): IF ID EX MEM WB
// 问题在于:指令 B 在第 5 周期的 MEM 阶段去读 addr,但指令 A 要到第 4 周期的 MEM 阶段才把数据写进去。 如果 B 的 MEM 阶段和 A 的 MEM 阶段时序卡得太紧,B 可能读到的是旧值,或者必须等 A 写完。
// 更直观的例子是寄存器级别的:
add x1, x2, x3 // 指令A:x1 = x2 + x3,结果在 EX 阶段才算出来
sub x4, x1, x5 // 指令B:需要用 x1,但在 ID 阶段就要读 x1
// 在流水线中:
时钟周期: 1 2 3 4 5
指令A: IF ID EX MEM WB ← 第5周期才写回 x1
指令B: IF ID ... ← 第3周期就要读 x1!
↑
x1 还没准备好!
// 指令 B 在第 3 周期需要 x1 的值,但指令 A 到第 5 周期才写回。这就是 Read-After-Write (RAW) 冒险。停顿(Stall / Bubble)
CPU 的解决办法之一就是插入气泡------让 B 原地等几个周期:
cpp
时钟周期: 1 2 3 4 5 6 7
指令A: IF ID EX MEM WB
[bubble] [bubble]
指令B: IF ---- ---- ID EX MEM WB
// 这些空等的周期就是流水线停顿(pipeline stall),流水线里出现了"气泡",吞吐量下降了。
// 虽然现代 CPU 用数据转发/旁路(forwarding/bypassing)技术能缓解很多情况(比如把 A 的 EX 结果直接转发给 B,不等写回),但涉及到内存访问(load/store)时,延迟更大、转发更困难,停顿更容易发生。编译器优化
编译器知道这些硬件特性,所以它会分析指令间的依赖图,尽量让没有依赖关系的指令同时进入不同的执行单元,在两条有依赖的指令之间插入不相关的指令来填充气泡,这就是编译器重排指令,进而提高进而提高指令级并行度:
cpp
// 原始顺序(会停顿):
str x1, [addr] // A:写 addr
ldr x2, [addr] // B:读 addr(依赖A,要等)
// 编译器重排后:
str x1, [addr] // A:写 addr
add x5, x6, x7 // C:完全无关的运算,填在中间
ldr x2, [addr] // B:读 addr(A已经完成了,不用等)
// 指令 C 本来在代码的其他位置,编译器把它"搬"过来填坑。这就是为什么编译器要重排指令------不是闲着没事干,而是在帮 CPU 避免停顿,进而提高指令级并行度。问题二:CPU 指令重排序(CPU Reordering)
即使编译器没有重排序,现代 CPU 的乱序执行(Out-of-Order Execution)也可能让 ready = true 的效果在 data = 42 之前对其他 CPU 核心可见。
CPU 为什么要乱序执行?
乱序执行是 CPU 微架构层面的优化。CPU 内部有一个保留站(Reservation Station)/ 重排序缓冲区(ROB, Reorder Buffer) ,它将指令按数据依赖关系而非程序顺序来调度执行 。例如,如果指令 A 需要等待内存读取(可能耗时 100+ 个周期),CPU 不会空等,而是先执行后面不依赖 A 结果的指令 B 和 C。这在单核 看来结果是一致的(CPU 保证单核的退休顺序与程序顺序一致 ),但对其他核心观察到的写入顺序可能不同 。
举个例子:
cpp
// 假设 CPU 按顺序执行这三条指令:
ldr x1, [addr1] // A:从内存读数据到 x1(cache miss,要等 100+ 周期)
add x2, x1, x3 // B:x2 = x1 + x3(依赖 A 的结果)
add x5, x6, x7 // C:x5 = x6 + x7(和 A、B 完全无关)
// 如果严格按顺序执行,CPU的状态是:
周期 1: A 发出内存请求
周期 2~100: 等......等......等......(x1 还没回来)
B 不能执行(依赖 x1)
C 也不能执行(被 B 挡住了)
周期 101: A 完成,x1 就绪
周期 102: B 执行
周期 103: C 执行
// CPU 白白空转了将近 100 个周期。C 明明和 A、B 没有任何关系,却被堵在后面,这太浪费了。
// 乱序执行的思路就是:既然 C 不依赖 A 和 B,为什么不先执行 C?
周期 1: A 发出内存请求
周期 2: C 执行!(不用等 A)
周期 3~100: 还可以继续执行后面其他不依赖 A 的指令
周期 101: A 完成,x1 就绪
周期 102: B 执行
// 白白浪费的 100 个周期被利用起来了。这就是乱序执行的核心价值。如何实现CPU乱序执行?
1. 保留站(Reservation Station):保留站是指令的"候车室"。每条指令被译码后,不是直接执行,而是先进入保留站等待。保留站会记录:
- 这条指令要做什么运算
- 它需要哪些操作数
- 这些操作数是否已经就绪
一旦某条指令的所有操作数都就绪了,它就可以被**发射(issue)**到执行单元去执行------不管它前面的指令有没有完成。
cpp
// 例如上面的例子:
保留站状态(周期 2):
┌─────────┬──────────┬────────────┐
│ 指令 │ 操作数 │ 状态 │
├─────────┼──────────┼────────────┤
│ A (ldr) │ addr1 │ 等待内存 │
│ B (add) │ x1, x3 │ x1 未就绪 │ ← 等 A
│ C (add) │ x6, x7 │ 全部就绪! │ ← 可以发射!
└─────────┴──────────┴────────────┘
// C 的操作数 x6 和 x7 都已经在寄存器里了,所以 C 直接被发射执行,跳过了还在等待的 A 和 B。2. 重排序缓冲区(ROB, Reorder Buffer) :乱序执行带来一个问题,指令的完成顺序和程序顺序不一致了 。如果中间发生异常(比如指令 A 触发了缺页中断),已经执行完的 C 的结果应该算数吗?按照程序语义,A 都没完成,C 不该被执行。
ROB 就是用来解决这个问题的。它是一个按程序顺序排列的队列,每条指令进入流水线时按顺序分配一个 ROB 条目:
cpp
ROB(周期 2):
┌────────┬────────┬──────────┐
│ 槽位 │ 指令 │ 状态 │
├────────┼────────┼──────────┤
│ #1 │ A │ 执行中 │
│ #2 │ B │ 等待 │
│ #3 │ C │ 已完成 ✓ │ ← 虽然先算完了,但不能先提交
└────────┴────────┴──────────┘
// C 虽然先算完了,但它的结果暂时存在 ROB 里,不会立即写入寄存器文件/内存。只有当队列头部的指令完成了,才按顺序提交(commit/retire):
周期 101: A 完成 → 提交 A(ROB #1 退出)
周期 102: B 完成 → 提交 B(ROB #2 退出)
周期 102: C 早就完成了 → 提交 C(ROB #3 退出)
// 这就是上面说的"CPU 保证单核的退休顺序与程序顺序一致",从本核心的视角看,结果和顺序执行完全一样。问题三:内存可见性(Memory Visibility)
CPU 核心各有自己的缓存 (L1/L2 Cache)。一个核心对变量的修改不一定会立刻对其他核心可见。没有适当的同步手段,消费者可能看到 ready == true 但 data 仍然是旧值 0。
举个例子:
// 现代多核 CPU 的内存层次大致是这样的:
核心0 核心1
┌──────────┐ ┌──────────┐
│ 寄存器 │ │ 寄存器 │
│ L1 Cache │ │ L1 Cache │ ← 每个核心私有
│ L2 Cache │ │ L2 Cache │ ← 通常也私有
└────┬─────┘ └────┬─────┘
└──────────┬────────────┘
L3 Cache ← 所有核心共享
│
主内存L1/L2 是每个核心私有 的。当核心 0 写一个变量时,新值首先写入核心 0 自己的 L1 Cache,并不会立刻出现在核心 1 的 L1 Cache 里。
问题四:编译器优化导致的无限循环
还有一个容易被忽视的问题:编译器在优化 consumer() 时,可能发现 ready 在循环体内没有被修改 ,于是将 ready 的值缓存到寄存器中 ,导致循环永远不会退出。这并不是重排序问题 ,而是编译器不知道其他线程可能修改这个变量 的问题。C++ 标准规定,对非原子、非 volatile(volatile用于声明禁止编译器优化) 变量的并发读写是未定义行为(Undefined Behavior, UB),编译器可以做出任意假设。
cpp
// 编译器可能将 consumer() 优化为:
void consumer() {
bool cached_ready = ready; // 将 ready 读入寄存器(只读一次!)
while (!cached_ready) { // 永远循环下去...
// 因为 cached_ready 永远不会改变
}
std::cout << data << std::endl;
}问题汇总:
所以会有一个矛盾:现代硬件和编译器都是为单线程优化的,但程序员写的是多线程代码。这就导致对于多线程代码有三层因为优化而产生的问题,每层都独立地可能破坏多线程程序的正确性:
- 第一层:编译器重排序。 编译器为了提高指令级并行度、避免流水线停顿,会调换没有数据依赖的语句顺序。
data = 42和ready = true在单线程视角下互不依赖,编译器可能把ready = true提前,导致 consumer 看到信号时数据还没写入。 - 第二层:CPU 乱序执行 + Store Buffer。 即使编译器没重排,CPU 的乱序执行引擎会按数据依赖关系而非程序顺序来调度指令。而且执行结果会先进入 Store Buffer,不同变量的写入从 Store Buffer 刷出到缓存的时序不确定,其他核心可能先看到后写的变量。
- 第三层:缓存可见性延迟。 每个核心有私有的 L1/L2 Cache,一个核心的写入需要通过缓存一致性协议(MESI)传播到其他核心,这个传播有时间窗口,不同变量的传播速度可能不同。
- 额外还有一个编译器层面的问题: 编译器发现
ready在循环体内没被修改,就把它缓存到寄存器里只读一次,导致循环永远看不到其他线程的更新,变成死循环。这不是重排,而是编译器利用 UB 做的激进优化。
这四个问题的共同根源 是:C++ 标准规定对非原子变量的并发读写是未定义行为,编译器和 CPU 都有权假设不存在多线程竞争,从而自由优化。
这就是为什么我们需要内存模型 ------它是一套规则,定义了在多线程环境下,一个线程对内存的修改何时、以何种顺序对其他线程可见。
2. 硬件层:CPU 缓存、缓存一致性与内存屏障
在理解 C++ 内存模型之前,必须先理解硬件层面发生了什么。
2.1 现代 CPU 的存储层次
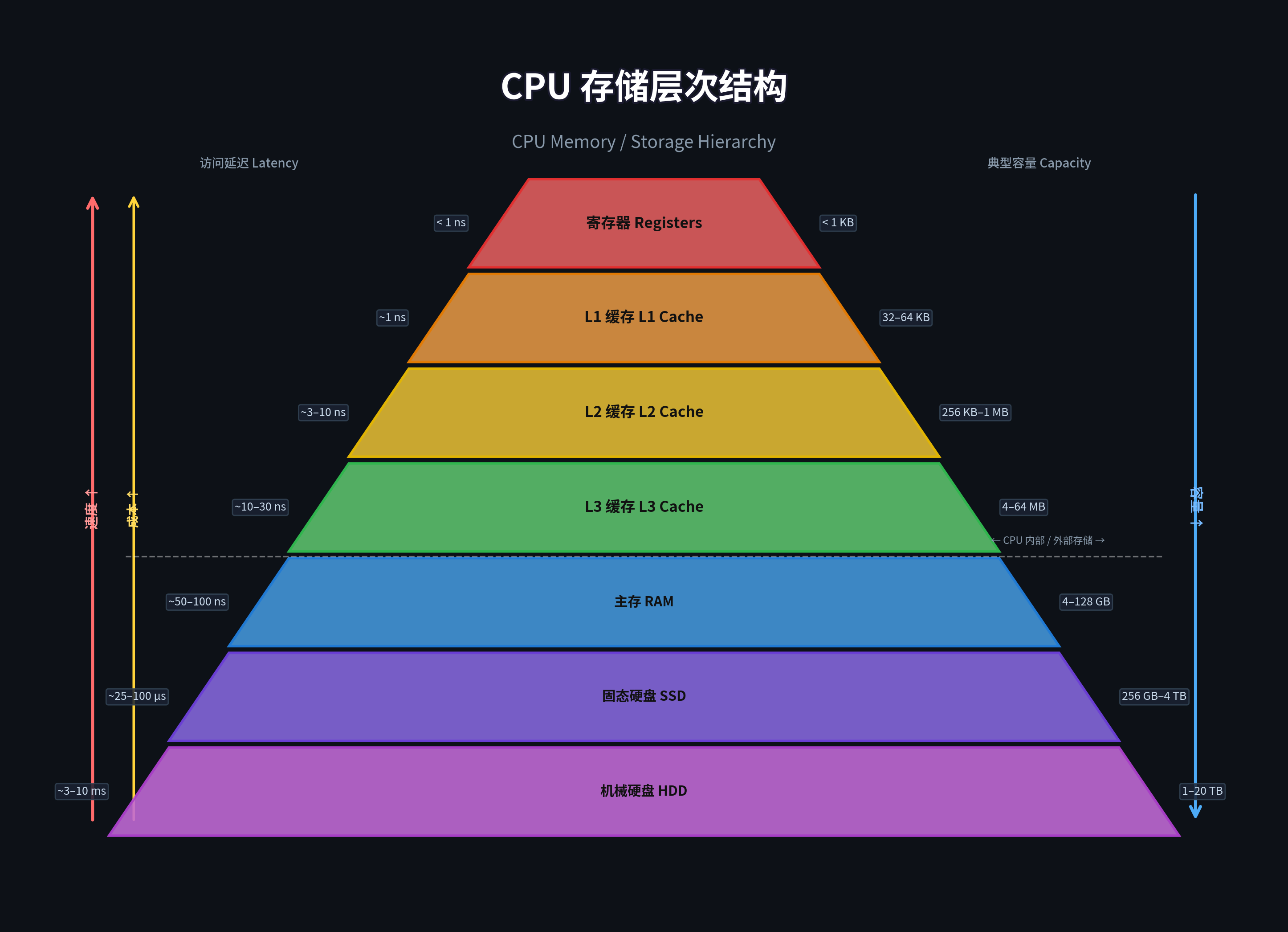

关键事实:
-
L1/L2 Cache 是每个 CPU 核心私有的。Core 0 写入一个变量,修改首先只存在于 Core 0 的 L1 Cache 中。
-
从 L1 到主内存,延迟差距可达 50-100 倍。
-
L1 分为 I-Cache(指令缓存)和 D-Cache(数据缓存),现代 CPU 通常各 32KB 或 48KB。
-
Cache Line(缓存行)是缓存操作的最小单位(CPU 缓存与内存之间交换数据的最小单位 ),通常为 64 字节 。 L1 Cache、L2 Cache、L3 Cache这三层------它们内部都是以缓存行为单位 来存储和管理数据的。即使你只修改了一个
int(4 字节),CPU 并不会只搬运这 4 字节,而是会把这个变量所在的整整 64 字节(一个缓存行)一起从内存加载到 L1 Cache 中。写回时也是整行操作。举个多核数组访问场景的例子:
第①步 Cache Miss :Core 0 只想读arr[0](4 字节),但 CPU 按缓存行为单位搬运,直接把arr[0]~arr[15]整整 64 字节从内存拉进 L1 Cache。
第②步 Cache Hit :接下来遍历arr[1]~arr[15]时,数据全在 L1 里了,每次访问 1ns,比去内存(100ns)快约 100 倍。这就是连续数组比链表快的根本原因。
第③步 伪共享 :两个核心各改各的变量,但因为它们挤在同一条缓存行里,每次修改都会让对方的整行副本失效、重新加载,反复拉扯导致严重性能下降。解决办法是用填充(Padding)把它们隔开到不同的缓存行。

-
补充一个查找过程和策略:

** 缓存的关联性(Associativity)**
缓存内部是怎么决定"一条数据该放在哪个位置"的?有一下几种策略:
缓存不是简单的"大数组",它通常采用 N 路组相联(N-way Set Associative)结构 。例如 8 路组相联意味着,对于某个特定的内存地址,它只能存储在缓存中 8 个特定位置之一 (也就是说即便有其他空位,但也只能存在这8个特定位置之一,其他空位无法使用)。这意味着即使缓存没有完全用满,也可能因为"冲突未命中"(Conflict Miss)而淘汰有用的数据。这在性能调优中很重要------如果你的数据结构中经常访问的字段恰好映射到缓存的同一个组(set),就会产生严重的性能问题。补充说明8路组相关联:
8路组相联缓存是指每个缓存组中包含8条缓存行,通过组索引 和标签 匹配实现高效缓存访问。
基本概念:在8路组相联缓存中,Cache被划分为若干组(Set),每组包含8条缓存行(line)。每条缓存行存储主存中的一块连续数据(通常称为Cache Line),并配有一个标签(Tag)用于标识该缓存行对应的主存地址。
地址映射与访问流程:
- 组索引(Set Index):CPU访问某个内存地址时,先取地址的中间几位作为组索引,确定该地址映射到哪一组。例如,对于32KB、每行64字节、8路组相联的Cache,总共有64组,地址的第6到11位用于选择组。
- 标签匹配(Tag Match):确定组后,需要在组内的8条缓存行中查找标签是否匹配。如果某条缓存行的标签与地址匹配且有效,则发生缓存命中(Cache Hit);否则为缓存未命中(Cache Miss)。
- 并行比较:组内的8条缓存行的标签通常同时进行比较,以加快查找速度。

2.2 缓存一致性协议(MESI)
既然每个核心都有自己的缓存 ,那如何保证数据一致 ?答案是缓存一致性协议 ,最经典的是 MESI 协议。
MESI 定义了每条缓存行的四种状态:
| 状态 | 全称 | 含义 |
|---|---|---|
| M (Modified) | 已修改 | 本核心修改了这行数据,与主内存不一致,其他核心没有这行的有效拷贝 |
| E (Exclusive) | 独占 | 本核心独占这行数据,与主内存一致,其他核心没有这行的有效拷贝 |
| S (Shared) | 共享 | 多个核心都有这行数据的拷贝,与主内存一致 |
| I (Invalid) | 无效 | 本核心的这行数据已失效(被其他核心修改了) |
** MESI 的扩展协议**
实际硬件中使用的协议通常是 MESI 的扩展版本:
- MOESI (AMD 使用):增加了 O (Owned) 状态,允许一个核心在持有 Modified 数据时与其他核心共享,而不必先写回主内存。这减少了内存总线的流量。
- MESIF (Intel 使用):增加了 F (Forward) 状态,在多个核心持有 Shared 状态的缓存行时,只有 F 状态的核心负责响应其他核心的读请求,避免所有 S 状态核心同时响应。
MESI 的核心流程举例:
初始状态:变量 x = 0 在主内存中
1. Core 0 读取 x:
- Cache Miss! 从主内存加载到 Core 0 的 L1 Cache
- 状态标记为 E (Exclusive)
- (因为没有其他核心缓存了这行数据)
2. Core 1 也读取 x:
- Cache Miss! 通过总线嗅探(Bus Snooping)发现 Core 0 有这行数据
- Core 0 的状态从 E 变为 S (Shared)
- Core 1 也得到一份拷贝,状态为 S (Shared)
- (现在两个核心都有一致的拷贝)
3. Core 0 写入 x = 42:
- Core 0 需要独占这行数据才能修改
- Core 0 发出 "Invalidate" 消息到总线
- Core 1 收到消息,将本地缓存行状态变为 I (Invalid)
- Core 1 回复 Invalidate ACK
- Core 0 收到 ACK 后,状态变为 M (Modified)
- Core 0 在自己的 Cache 中修改 x = 42
4. Core 1 再次读取 x:
- 发现自己的缓存行是 I (Invalid)
- 发出读请求到总线
- Core 0 通过总线嗅探发现读请求命中自己的 M 状态缓存行
- Core 0 将修改后的数据(x=42)发给 Core 1
- Core 0 同时将数据写回主内存(Write-Back)
- Core 0 和 Core 1 的状态都变为 S (Shared)关键点 :MESI 保证了最终所有核心能看到一致的数据 ,但是时机是不确定的。原因在于下面的 Store Buffer 和 Invalidate Queue。
2.3 Store Buffer 与 Invalidate Queue
为了提高性能,现代 CPU 在缓存一致性协议之上又加了两个缓冲结构:
Store Buffer(写缓冲区):
Core 0 写入 x = 42 时,如果要严格遵循 MESI:
1. 发送 Invalidate 消息
2. 等待所有其他核心回复 ACK(可能要等几十个时钟周期!)
3. 收到所有 ACK 后,才修改缓存行
4. 继续执行下一条指令
这太慢了!所以现代 CPU 引入了 Store Buffer:
1. 将 "x = 42" 暂存到 Store Buffer(几乎瞬间完成)
2. 同时发送 Invalidate 消息(异步)
3. CPU 立即继续执行后续指令(不等待 ACK)
4. 等 ACK 全部收到后,Store Buffer 中的值再异步刷入 L1 Cache
结果:Core 0 自己能立即看到 x = 42(CPU 会先检查 Store Buffer 再查 Cache,叫做 "Store Forwarding" / "Store Buffer Forwarding")但 Core 1 可能暂时还看不到这个修改!Invalidate Queue(失效队列):
Core 1 收到 "x 已失效" 的 Invalidate 消息时,如果严格处理:
1. 立即将对应缓存行标记为 Invalid
2. 回复 ACK
但标记 Invalid 需要查找缓存(有时还需要等待 Cache 可用),所以:
1. 将 Invalidate 消息放入 Invalidate Queue(瞬间完成)
2. 立即回复 ACK(让 Core 0 不用等)
3. 稍后再真正处理队列中的 Invalidate 消息,将缓存行标记为 Invalid
结果:Core 1 可能在一小段时间内还能读到 x 的旧值!因为 Invalidate 还在队列里排队,还没真正执行。这就是为什么仅有缓存一致性协议是不够的 ------Store Buffer 和 Invalidate Queue 让修改的可见性变得不确定。它们让 CPU 快了很多,但也让多线程编程变得困难。
2.4 内存屏障(Memory Barrier / Memory Fence)
在提出解决办法之前,我们先捋一下问题(即屏障到底在"挡"谁):
存在两道关卡会改变程序的指令执行顺序:
- 关卡 1:编译器。 它在编译阶段就可能把你的指令换位置。原因是 as-if 规则------只要单线程行为不变,编译器怎么排都行。你写的是
data=42; ready=true;,它可能生成的 机器码顺序是ready=true; data=42;。这一步发生在你的代码变成二进制的时候,CPU 还没上场。 - 关卡 2:CPU 硬件。 即使编译器没重排,CPU 的乱序执行引擎 、Store Buffer、Invalidate Queue 也会让其他核心观察到的写入顺序 跟你程序中的顺序不一样。这一步发生在指令实际运行的时候。
所以"内存屏障"其实是一个统称,对应这两道关卡,有两种不同层次的屏障:
| 编译器屏障 | 硬件内存屏障 | |
|---|---|---|
| 挡谁 | 只挡编译器 | 挡编译器 + 挡 CPU |
| 生成 CPU 指令吗 | 不生成,零开销 | 生成(如 MFENCE、DMB) |
| C++ 写法 | asm volatile("" ::: "memory") 或 atomic_signal_fence |
atomic_thread_fence 或 atomic 操作本身自带 |
硬件屏障是编译器屏障的超集。 你用了硬件屏障,编译器重排也同时被禁止了。所以日常写代码时,你真正要打交道的是硬件屏障这一层(通过 std::atomic 来间接使用)。
硬件层面到底发送了什么?-- 屏障的物理根源
要理解屏障为什么"长这样",必须先理解 Store Buffer 和 Invalidate Queue。它们才是制造麻烦的元凶。
- Store Buffer 制造了"写-写"和"写-读"乱序:当 Core 0 执行
data = 42时,如果严格走 MESI 协议,它要先发 Invalidate 消息给所有核心、等所有 ACK 回来、才能写入缓存。这个等待可能 几十到上百个时钟周期 。
CPU 设计者说:太慢了。于是引入 Store Buffer------把写操作先"暂存"起来,CPU 立即执行下一条指令,不等 ACK。 等 ACK 慢慢收齐后,Store Buffer 里的值再异步刷入 L1 Cache。
这带来一个问题:Core 0 先写data、后写ready,但这两个写可能按不同的速度从 Store Buffer 刷出到缓存。Core 1 完全有可能先看到ready=true,后看到data=42。 - Invalidate Queue 制造了"读"的乱序:类似地,当 Core 1 收到"某个缓存行失效了"的消息时,如果立刻去缓存里做 Invalid 标记,需要查找缓存、等缓存可用,也有延迟。所以 CPU 把这个消息先放进 Invalidate Queue,立刻回复 ACK,稍后再真正把缓存行标记为 Invalid 。
这就意味着:Core 1 在一小段时间窗口内,可能还在用旧的缓存数据,因为 Invalidate 消息还在队列里排队没处理。
屏障就是强迫 CPU "停下来清理":理解了上面两个队列,三种屏障的含义就自然了:
- Store Fence(写屏障) :在执行后续的 store 之前,先把 Store Buffer 里所有挂起的写操作全部刷出去写入缓存 。效果是------"我之前的所有写,必须先对外可见,然后才能做新的写。" 这挡住了写-写重排。
- Load Fence(读屏障) :在执行后续的 load 之前,先把 Invalidate Queue 里所有挂起的失效消息全部处理掉 。效果是------"我要确保自己的缓存是最新的,然后才做新的读。" 这挡住了读-读重排。
- Full Fence(全屏障):两件事都做。Store Buffer 清干净,Invalidate Queue 也清干净。这是最重的屏障。
用一个比喻来说:Store Buffer 和 Invalidate Queue 就像两个待办箱。正常情况下 CPU 会攒着慢慢处理。内存屏障就是领导突然来说"你现在把待办箱清空了再做下一件事"。
为了让程序员能控制内存操作的可见顺序 ,CPU 提供了内存屏障指令:
| 屏障类型 | 作用 | x86 指令 | ARM 指令 |
|---|---|---|---|
| Store Fence | 刷出 Store Buffer:确保屏障之前的所有写操作都写入缓存后,屏障之后的写操作才能执行 | SFENCE |
DSB ST |
| Load Fence | 清空 Invalidate Queue:确保屏障之前的所有读操作完成后,屏障之后的读操作才能执行 | LFENCE |
DSB LD |
| Full Fence | 同时刷出 Store Buffer 并清空 Invalidate Queue,约束读和写 | MFENCE |
DSB SY |
屏障的精确语义
更精确地说,内存屏障并不是"让缓存写入主内存",而是:
- Store Fence:确保在该指令之前的所有 store 操作的效果,在该指令之后的所有 store 操作的效果之前,对所有其他核心可见。
- Load Fence:确保在该指令之前的所有 load 操作都完成了(即读到了最新值),再执行该指令之后的 load 操作。
- Full Fence:以上两者的组合。
内存屏障的作用范围是屏障前后操作之间的排序关系,而非某个具体的"刷新"动作。
x86 的特殊性:x86 架构提供了较强的内存模型(TSO, Total Store Order),天然保证:
- Store-Store 不重排:写操作之间保持程序顺序
- Load-Load 不重排:读操作之间保持程序顺序
- Load-Store 不重排:读操作不会被重排到后续的写操作之后
x86 唯一允许的重排 是:Store-Load 重排(写操作可能被重排到后续读操作之后)。
x86 TSO 允许的重排示例:
CPU 的程序顺序: 其他核心可能观察到的顺序:
STORE x = 1 ──┐ LOAD y ← 被提前了
LOAD y ─┘ STORE x = 1
原因:STORE 在 Store Buffer 中排队,
而 LOAD 直接从 Cache 读取,LOAD 可能先完成。但 ARM 和 RISC-V 等架构的内存模型要弱得多,几乎所有类型的重排都可能发生:
各架构允许的重排类型对比:
| 重排类型 | x86-64 | ARM | RISC-V (RVWMO) | Power |
|----------------|--------|--------|----------------|--------|
| Load-Load | ✗ 禁止 | ✓ 允许 | ✓ 允许 | ✓ 允许 |
| Load-Store | ✗ 禁止 | ✓ 允许 | ✓ 允许 | ✓ 允许 |
| Store-Load | ✓ 允许 | ✓ 允许 | ✓ 允许 | ✓ 允许 |
| Store-Store | ✗ 禁止 | ✓ 允许 | ✓ 允许 | ✓ 允许 |
| 数据依赖保序 | ✓ 保证 | ✓ 保证 | ✓ 保证 | ✓ 保证 |这就是为什么不能依赖平台特性,而要使用 C++ 标准提供的内存模型来编写可移植的并发代码。在 x86 上看起来正确的代码,移植到 ARM(如 Apple M 系列芯片、Android 手机)上可能就会出 Bug。
3. 编译器屏障 vs 硬件屏障:容易混淆的两个层次
很多人混淆编译器屏障和硬件内存屏障,这是两个完全不同层面的东西。
3.1 编译器屏障(Compiler Barrier)
编译器屏障阻止编译器对指令进行重排序,但不会生成任何 CPU 指令,对 CPU 的行为没有影响。
cpp
#include <atomic>
// GCC/Clang 的编译器屏障
void compiler_barrier_demo() {
int a = 1;
// asm volatile 是 GCC/Clang 的内联汇编语法
// "" 表示空指令(不生成任何 CPU 指令)
// "memory" 告诉编译器:这条伪指令可能读写了任意内存
// 效果:编译器不会将这条语句前后的内存操作互相重排
asm volatile("" ::: "memory");
int b = 2;
// 编译器保证 a = 1 在 b = 2 之前执行
// 但 CPU 仍然可能重排它们的执行顺序!
}
// MSVC 的编译器屏障
// _ReadWriteBarrier(); // (已弃用,不推荐)
// C++11 标准的编译器屏障(推荐方式)
void standard_compiler_barrier() {
int a = 1;
// std::atomic_signal_fence 只阻止编译器重排,不生成硬件屏障
// 它主要用于同一线程中信号处理函数(signal handler)与主代码之间的同步
std::atomic_signal_fence(std::memory_order_acq_rel);
int b = 2;
}但只有编译器屏障是远远不够的,编译器屏障只是阻止编译器重排,但CPU仍然会发生重排。
举个例子:按照下列代码的逻辑,存在v1、v2、r1、r2
如果没有发生指令重排的话,会有如下三种情况:
- r1 = 1,r2 = 1:即线程1和线程2都先完成了对v1 = 1和 v2 = 1的操作,然后再分别对r1 = v2,r2 = v1。
- r1 = 0,r2 = 1:即线程1进行r1 = v2操作之前,线程2还没有进行v2 = 1的操作,导致了 r1 = v2 = 0。(发生这种情况的原因有两种,第一就是线程的执行顺序导致的(线程1比线程2快执行),第二就是可能发生了指令重排(线程1比线程2快执行的同时,线程1的v1 = 1和r1 = v2顺序交换了,但是暂时无法观测到这个重排现象,所以是理论上存在,所以这里就认定为没有发生指令重排))
- r1 = 1,r2 = 0:即线程2进行r2 = v1操作之前,线程1还没有进行v1 = 1的操作,导致了 r2 = v2 = 0。(发生这种情况的原因有两种,第一就是线程的执行顺序导致的(线程2比线程1快执行),第二就是可能发生了指令重排(线程2比线程1快执行的同时,线程2的v2 = 1和r2 = v1顺序交换了,但是暂时无法观测到这个重排现象,所以是理论上存在,所以这里就认定为没有发生指令重排))
如果发生了指令重排,会有这个情况:
- r1 = 0,r2 = 0:即为线程1 和 线程2对 r1 = v2、r2 = v1的操作都重排到v1 = 1、v2 = 1之前了,这就导致了 r1 = v2 = 0、r2 = v1 = 0;所以可以把这个r1 = 0 && r2 = 0 作为条件来观测是否指令发生了重排。
cpp
#include <iostream>
#include <semaphore.h>
#include <thread>
int v1, v2, r1, r2;
sem_t start1, start2, complete;
void thread1()
{
while(true)
{
// 每次在这里等待,直到主线程发出信号
sem_wait(&start1);
v1 = 1;
r1 = v2;
sem_post(&complete);
}
}
void thread2()
{
while(true)
{
// 每次在这里等待,直到主线程发出信号
sem_wait(&start2);
v2 = 1;
r2 = v1;
sem_post(&complete);
}
}
int main()
{
// 初始化信号量
sem_init(&start1, 0, 0);
sem_init(&start2, 0, 0);
sem_init(&complete, 0, 0);
// 启动两个线程
std::thread t1(thread1);
std::thread t2(thread2);
// 1000000 次测试
for(int i = 0; i < 1000000; i++)
{
v1 = v2 = 0;
// 通知两个线程一次测试开始
sem_post(&start1);
sem_post(&start2);
// 等待两个线程一次测试完成
sem_wait(&complete);
sem_wait(&complete);
// 如果发生重排,这里就会打印
if((r1 == 0) && (r2 == 0))
{
std::cout << "reorder detected @ " << i << std::endl;
}
}
t1.detach();
t2.detach();
return 0;
}多次运行结果:
bash
$ ./test
reorder detected @ 103274
reorder detected @ 165413
reorder detected @ 260100
reorder detected @ 419154
reorder detected @ 508480
reorder detected @ 509414
reorder detected @ 535796
reorder detected @ 554339
reorder detected @ 602725
reorder detected @ 626495
reorder detected @ 756016
reorder detected @ 848165
reorder detected @ 864235
$ ./test
reorder detected @ 145744
reorder detected @ 292547
reorder detected @ 319411
reorder detected @ 325013
reorder detected @ 360162
reorder detected @ 368819
reorder detected @ 373382
reorder detected @ 397535
reorder detected @ 401965
reorder detected @ 449255
reorder detected @ 472074
reorder detected @ 570637
reorder detected @ 570802
reorder detected @ 574712
reorder detected @ 587480
reorder detected @ 616706
reorder detected @ 617032
reorder detected @ 643429
reorder detected @ 679384
reorder detected @ 691302
reorder detected @ 741847
reorder detected @ 765935
reorder detected @ 802661
reorder detected @ 831310
reorder detected @ 879595
reorder detected @ 886543
reorder detected @ 886786
reorder detected @ 893694
reorder detected @ 898316
reorder detected @ 919692
reorder detected @ 924013
reorder detected @ 966790
$ ./test
reorder detected @ 300
reorder detected @ 122448
reorder detected @ 176583
reorder detected @ 190003
reorder detected @ 230573
reorder detected @ 245686
reorder detected @ 281640
reorder detected @ 390802
reorder detected @ 416831
reorder detected @ 451071
reorder detected @ 470245
reorder detected @ 531855
reorder detected @ 560102
reorder detected @ 562926
reorder detected @ 655202
reorder detected @ 657929
reorder detected @ 668500
reorder detected @ 695968
reorder detected @ 710164
reorder detected @ 726194
reorder detected @ 777659
reorder detected @ 780944
reorder detected @ 781010
reorder detected @ 795391
reorder detected @ 876963
reorder detected @ 880055
reorder detected @ 890770
$ ./test
reorder detected @ 62922
reorder detected @ 176667
reorder detected @ 203593
reorder detected @ 224320
reorder detected @ 345974
reorder detected @ 392123
reorder detected @ 393105
reorder detected @ 459240
reorder detected @ 486975
reorder detected @ 508644
reorder detected @ 656035
reorder detected @ 669090
reorder detected @ 703426
reorder detected @ 706660
reorder detected @ 920639从结果得到,是存在指令重排导致乱序执行的,即便采用了编译器屏障,也只是阻止了编译器重排并没有生成任何 CPU 指令,对 CPU 的行为没有影响,CPU仍然可能重排它们的执行顺序,所以需要硬件内存屏障。
3.2 硬件内存屏障
生成CPU 指令 ,强制 CPU 按照程序顺序执行内存读写,解决多核 CPU 缓存不一致、乱序执行问题。硬件屏障既阻止编译器重排,也阻止 CPU 重排。
cpp
#include <atomic>
void hardware_barrier_demo() {
int a = 1;
// 多种使用硬件内存屏障的方式:
// 1、GCC/Clang 硬件屏障(直接嵌入汇编)
// 1.1 全能屏障:asm volatile("mfence" ::: "memory"); 读写都屏障(x86)
// 1.2 读屏障:asm volatile("lfence" ::: "memory"); 仅读屏障
// 1.3 写屏障:asm volatile("sfence" ::: "memory"); 仅写屏障
// 2、Linux内核封装
// mb(); // 全屏障
// rmb(); // 读屏障
// wmb(); // 写屏障
//
// smp_mb(); // 多核 SMP 全屏障
// smp_rmb(); // 多核读屏障
// smp_wmb(); // 多核写屏障
// 3、C/C++ 标准跨平台硬件屏障(C++11):std::atomic_thread_fence 同时生成编译器屏障 + 硬件屏障
// 在 x86 上,seq_cst fence 会生成 MFENCE 指令
// 在 ARM 上,会生成 DMB 或 DSB 指令
std::atomic_thread_fence(std::memory_order_seq_cst);
// 硬件屏障(带CPU指令,多核线程间同步)
// atomic_thread_fence(memory_order_acquire); // 读屏障
// atomic_thread_fence(memory_order_release); // 写屏障
// atomic_thread_fence(memory_order_acq_rel); // 读写屏障
// atomic_thread_fence(memory_order_seq_cst); // 最强全屏障
int b = 2;
// 编译器和 CPU 都保证 a = 1 在 b = 2 之前完成
}在3.1 举的例子加入硬件内存屏障就不会乱序执行了:
cpp
#include <iostream>
#include <semaphore.h>
#include <thread>
int v1, v2, r1, r2;
sem_t start1, start2, complete;
void thread1()
{
while(true)
{
// 每次在这里等待,直到主线程发出信号
sem_wait(&start1);
v1 = 1;
// std::atomic_signal_fence(std::memory_order_acq_rel);// 编译器屏障
std::atomic_thread_fence(std::memory_order_seq_cst);// 硬件屏障
r1 = v2;
sem_post(&complete);
}
}
void thread2()
{
while(true)
{
// 每次在这里等待,直到主线程发出信号
sem_wait(&start2);
v2 = 1;
// std::atomic_signal_fence(std::memory_order_acq_rel);// 编译器屏障
std::atomic_thread_fence(std::memory_order_seq_cst);// 硬件屏障
r2 = v1;
sem_post(&complete);
}
}
int main()
{
// 初始化信号量
sem_init(&start1, 0, 0);
sem_init(&start2, 0, 0);
sem_init(&complete, 0, 0);
// 启动两个线程
std::thread t1(thread1);
std::thread t2(thread2);
// 1000000 次测试
for(int i = 0; i < 1000000; i++)
{
v1 = v2 = 0;
// 通知两个线程一次测试开始
sem_post(&start1);
sem_post(&start2);
// 等待两个线程一次测试完成
sem_wait(&complete);
sem_wait(&complete);
// 如果发生重排,这里就会打印
if((r1 == 0) && (r2 == 0))
{
std::cout << "reorder detected @ " << i << std::endl;
}
}
t1.detach();
t2.detach();
return 0;
}3.3 两者的关系
┌─────────────────────────────────────────────────────┐
│ 编译器屏障 │
│ 阻止编译器重排,不生成 CPU 指令 │
│ 示例:asm volatile("" ::: "memory") │
│ std::atomic_signal_fence(...) │
│ │
│ ┌───────────────────────────────────────────────┐ │
│ │ 硬件内存屏障 │ │
│ │ 阻止编译器重排 + 阻止 CPU 重排 │ │
│ │ 示例:MFENCE / DMB / DSB │ │
│ │ std::atomic_thread_fence(...) │ │
│ │ std::atomic 操作(非 relaxed) │ │
│ └───────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────┘
注意:硬件屏障是编译器屏障的超集。
使用 std::atomic_thread_fence 时,编译器会自动插入编译器屏障。实践建议 :绝大多数情况下,你不需要直接使用编译器屏障或硬件屏障。使用
std::atomic配合合适的memory_order是最佳实践------编译器会自动帮你生成正确的屏障指令。只有在极端性能优化或与硬件 I/O 交互时,才需要使用更底层的屏障。
3.4 从硬件屏障到 C++ 的 Memory Order------抽象层的映射
直接写 MFENCE/DMB 这样的汇编指令既不可移植、也容易出错。C++11 做的事情是:把"屏障"的概念抽象成了 memory_order,绑定在每一个原子操作上。
你不需要自己插入屏障指令,你只需要在 atomic.store() 或 atomic.load() 时告诉编译器 :"这个操作要有什么级别的排序保证",编译器就会自动帮你在对应平台上生成正确的屏障指令。
这是一个从"具体"到"抽象"的映射关系:
你想要的效果 C++ 的写法 x86 实际生成的 ARM 实际生成的
───────────── ────────── ────────── ──────────
什么保证都不要 memory_order_relaxed 普通 MOV 普通 LDR/STR
写之前的东西不许往后跑 memory_order_release (store) 普通 MOV (x86天然保证) STLR
读之后的东西不许往前跑 memory_order_acquire (load) 普通 MOV (x86天然保证) LDAR
以上两者都要 memory_order_acq_rel (RMW) LOCK 前缀 LDAXR + STLXR
全局一致的全序 memory_order_seq_cst LOCK XCHG 或 MFENCE DMB + LDAR/STLR注意看 x86 那一列:acquire 和 release 在 x86 上竟然都是普通 MOV,不生成任何额外指令。这是因为 x86 的 TSO(Total Store Order)内存模型天然就禁止了除 Store-Load 以外的所有重排。这也是为什么很多 bug 在 x86 上跑不出来,一移植到 ARM 手机或 Apple M 芯片就崩了。
3.5 Acquire-Release 配对------理解屏障最核心的心智模型
三种屏障(读屏障、写屏障、全屏障)在 C++ 中最常用的形态就是 acquire + release 配对。把这个配对吃透,内存屏障就算真正理解了。
1、release = "单向下推屏障"
store(value, memory_order_release) 的语义是:在这个 store 之前的所有读写操作,不允许被重排到这个 store 之后。
你可以把它想象成一道只阻止向下穿越的单向闸门:
data = 42; ← 这些操作被"关"在上面
extra = 100; ← 不允许掉到 release store 下面
─── release store(ready = true) ─── ← 闸门
... 后续操作 ... ← 上面的操作不能跑到这里来
但后续操作可以往上跑(是单向的)从硬件角度看,release store 做的事情就是:确保在这个 store 被写入 Store Buffer 之前,前面所有挂起的写操作都已经从 Store Buffer 刷出到缓存了。 这样当其他核心看到 ready=true 时,data=42 和 extra=100 一定已经在缓存中可见了。
2、 acquire = "单向上推屏障"
load(memory_order_acquire) 的语义是:在这个 load 之后的所有读写操作,不允许被重排到这个 load 之前。
... 前面的操作 ... ← 后面的操作不能跑到这里来
但前面的操作可以往下跑(是单向的)
─── acquire load(ready) ─── ← 闸门
use(data); ← 这些操作被"关"在下面
use(extra); ← 不允许浮到 acquire load 上面从硬件角度看,acquire load 做的事情是:在执行后续的 load/store 之前,先把 Invalidate Queue 中的所有消息处理掉,确保自己看到的是最新的缓存状态。
3、 配对的效果 = "同步点"
单独的 release 或单独的 acquire 都没什么用。它们必须配对使用,并且配对的条件是:acquire-load 读到了 release-store 写入的那个值。
一旦配对成功,效果就像在两个线程之间建立了一条因果链:
cpp
Thread A Thread B
──────── ────────
(1) data = 42;
(2) extra = 100;
(3) ready.store(true, RELEASE); ──── "synchronizes-with" ────
(4) while(!ready.load(ACQUIRE));
(5) assert(data == 42); // ✅ 保证成立
(6) assert(extra == 100); // ✅ 保证成立为什么 (5)(6) 一定能看到正确的值?因为:
- release 保证了 (1)(2) 在 (3) 之前完成(硬件上:Store Buffer 已刷出)
- acquire 保证了 (5)(6) 在 (4) 之后执行(硬件上:Invalidate Queue 已清空)
- (4) 读到了 (3) 写入的
true→ 建立了 synchronizes-with 关系 - 所以 (1)(2) happens-before (5)(6)
这就是整个 C++ 内存模型中最核心的推理链条。
3.6、atomic_thread_fence ------独立屏障 vs 附着在操作上的屏障
上面我们说的都是"把 memory order 写在 atomic 操作上",比如 flag.store(true, release)。但 C++ 还提供了另一种写法:独立的屏障函数 std::atomic_thread_fence。
两者的区别在于作用范围:
- 附着式 (memory order 写在 atomic 操作上):只约束这一个原子操作与其前/后操作之间的顺序。
- 独立式 (atomic_thread_fence):约束 fence 前后所有内存操作之间的顺序。它是一道"批量屏障"。
什么时候独立式更好?当你有多个原子变量都需要同样的排序保证时:
cpp
// 方式一:每个操作都标 release(三条 release store)
x = 1; y = 2; z = 3; // 非原子写
a.store(1, memory_order_release);// 保证 x,y,z 在 a 之前完成
b.store(1, memory_order_release);// 保证 x,y,z 在 b 之前完成
c.store(1, memory_order_release);// 保证 x,y,z 在 c 之前完成
// 这能工作,但每个 store 都单独带了一个 release。在 ARM 上,每条 release store 都会生成一条 STLR 指令(带屏障效果的 store),你写了三条,就生成了三条 STLR。
// 方式二:一个 release fence + 三条 relaxed store(只用一个屏障)
x = 1; y = 2; z = 3; // 非原子写
std::atomic_thread_fence(memory_order_release); // 一道屏障管住上面所有写
a.store(1, memory_order_relaxed);
b.store(1, memory_order_relaxed);
c.store(1, memory_order_relaxed);
// fence 的语义是:fence 之前的所有操作,不许重排到 fence 之后的任何 store 之后。
// 注意这里说的是"所有"和"任何"------它不绑定某一个特定的 atomic 操作,而是一刀切,把前后所有操作的顺序关系都管了。
// 所以 x=1, y=2, z=3 这三个写操作,全部被这一道 fence 挡住了,不可能跑到 a.store、b.store、c.store 的后面。效果和方式一完全一样,但在 ARM 上只生成一条 DMB 屏障指令 + 三条普通 STR。方式二的好处是:一道屏障保护了上面所有的写操作,而不需要在每个 store 上都加 release。在某些架构上,这可以减少生成的屏障指令数量。
3.7、seq_cst------最强的全屏障,以及你什么时候真正需要它
memory_order_seq_cst 是最严格的选项。它在 acquire-release 的基础上,额外保证了一件事:所有线程观察到的所有 seq_cst 操作,存在一个全局一致的全序。
这个"全序"有什么用?看一个经典的例子:
cpp
// 两个线程分别写两个不同的变量,另外两个线程分别观察
Thread 1: x.store(1, seq_cst); // 写x
Thread 2: y.store(1, seq_cst); // 写y
Thread 3: if (x.load(seq_cst)==1 && y.load(seq_cst)==0) { saw_x_first = true; } // 观察者A
Thread 4: if (y.load(seq_cst)==1 && x.load(seq_cst)==0) { saw_y_first = true; } // 观察者B
// Thread 1 和 Thread 2 分别写不同的变量,Thread 3 和 Thread 4 是两个"旁观者",各自按不同顺序观察这两个写入。
// 核心问题是:Thread 3 和 Thread 4 对"x 和 y 谁先被写入"的看法,能不能不一致?
// 用 acquire/release 时:两个观察者可能"各说各话"
Thread 1 (Core 0): x.store(1, release);
Thread 2 (Core 1): y.store(1, release);
// 从硬件角度想。Core 0 写 x=1,这个值先进 Core 0 的 Store Buffer,然后通过 Invalidate 传播到各个核心。Core 1 写 y=1,同理。
// 关键在于:x 的 Invalidate 和 y 的 Invalidate 到达不同核心的时间可能不同。
Core 0 写了 x=1 Core 1 写了 y=1
发出 x 的 Invalidate 发出 y 的 Invalidate
│ │
▼ ▼
Core 2 (Thread 3): 先收到 x 的 Invalidate,后收到 y 的 Invalidate
→ 先看到 x=1,此时 y 还是 0
→ saw_x_first = true ✓
Core 3 (Thread 4): 先收到 y 的 Invalidate,后收到 x 的 Invalidate
→ 先看到 y=1,此时 x 还是 0
→ saw_y_first = true ✓
// 两个观察者同时为 true! 因为 Invalidate 消息在总线上传播到不同核心的时间是不确定的。Core 2 可能离 Core 0 更近(或者 Core 2 的 Invalidate Queue 先处理了 x 的消息),Core 3 可能离 Core 1 更近。每个核心看到的"写入顺序"可以是不同的。
// acquire/release 不管这个问题。它只保证配对的两个线程之间的同步------"我写的东西你能看到"。但它不保证第三方观察者看到的顺序跟另一个第三方观察者一致。用 seq_cst 时:所有人必须达成共识:seq_cst 额外加了一条规则:所有 seq_cst 操作,在所有线程眼中,必须存在同一个全局顺序。
这意味着 x.store(1) 和 y.store(1) 这两个操作,全世界所有核心必须就"谁先谁后"达成一致。要么全局顺序是"先 x 后 y",要么是"先 y 后 x",不允许有分歧。
cpp
假设全局顺序是 "先 x=1,后 y=1":
Thread 3: 读 x==1 && 读 y==0 → saw_x_first = true ✓(符合全局顺序)
Thread 4: 读 y==1 && 读 x==0 → 不可能!
因为全局顺序是先 x 后 y,
当 y==1 已经成立时,x==1 一定更早就成立了,
所以 Thread 4 读到 y==1 时,x 不可能还是 0
假设全局顺序是 "先 y=1,后 x=1":
Thread 3: 读 x==1 && 读 y==0 → 不可能!(同理)
Thread 4: 读 y==1 && 读 x==0 → saw_y_first = true ✓
// 无论全局顺序是哪种,最多只有一个观察者为 true。 这就是"全序"的威力。硬件上 seq_cst 是怎么做到的?
在 x86 上,seq_cst store 会生成 MFENCE 或 LOCK XCHG。这条指令做的事情是:
Core 0 执行 x.store(1, seq_cst):
(1) 把 x=1 写入 Store Buffer
(2) MFENCE:强制等待 Store Buffer 完全刷空
(3) 直到 x=1 已经进入 L1 Cache 并且所有核心都处理了 Invalidate
(4) 才继续执行下一条指令MFENCE 禁止了 Store-Load 重排。 没有 MFENCE 时,CPU 可以在 Store Buffer 还没刷完的情况下就去做下一个 load(这就是 Store-Load 重排,也是 x86 唯一允许的重排)。MFENCE 堵住了这个口子。
而 acquire/release 在 x86 上就是普通 MOV,不生成 MFENCE,所以 Store-Load 重排仍然可能发生。
在 ARM 上更明显:seq_cst 会生成 DMB(Data Memory Barrier)全屏障,相当于同时刷 Store Buffer 和清 Invalidate Queue,并且确保所有核心对操作顺序达成一致。
为什么 90% 场景不需要 seq_cst?
因为绝大多数并发模式都是两方通信 :一个生产者写数据,一个消费者读数据。这种场景只需要"我写的东西你能看到",acquire/release 就够了。
只有当你有多个写者写不同变量 + 多个观察者需要对这些写入的顺序达成一致时,才需要 seq_cst。这种场景在实际代码中很少见。而 seq_cst 的代价是每次 store 都要强制刷 Store Buffer(等几十个时钟周期),在高频操作中这个开销很显著。
4. C++ 内存模型基础:std::atomic 与原子操作
4.1 什么是原子操作?
原子操作 是不可分割的操作:它要么完全执行,要么完全不执行,不存在"执行到一半"被其他线程看到中间状态的情况。
先看一个非原子操作的问题:
cpp
// ❌ 非原子操作:两个线程同时执行 counter++ 会出问题
int counter = 0; // 普通 int,没有原子性保证
// 线程 A 和线程 B 同时执行:
counter++;
// counter++ 在 CPU 层面实际上是三步操作(Read-Modify-Write, RMW),有三条指令(单条指令执行是原子的):
// 1. 从内存读取 counter 到寄存器(LOAD)
// 2. 寄存器中的值 +1 (ADD)
// 3. 将结果写回内存 (STORE)
//
// 可能的执行序列(两个线程各执行一次 counter++,期望结果是 2):
//
// 时间线 Thread A Thread B
// ───── ──────── ────────
// t0 LOAD counter (=0)
// t1 LOAD counter (=0) ← B 也读到 0!
// t2 ADD (0+1=1)
// t3 STORE (counter=1)
// t4 ADD (0+1=1)
// t5 STORE (counter=1) ← 覆盖了 A 的结果!
//
// 最终结果:counter = 1(而不是期望的 2)
// 这就是典型的 "数据竞争"(Data Race)** C++ 标准中数据竞争的定义**
C++11 标准(§1.10)对数据竞争的定义非常精确:如果两个表达式求值分别来自不同线程,访问同一个内存位置,其中至少有一个是修改(写入),且两者之间没有 happens-before 关系,则构成数据竞争(Data Race)。
数据竞争是未定义行为(Undefined Behavior)。这意味着编译器可以假设程序不存在数据竞争,并基于此假设进行激进优化。一旦程序存在数据竞争,所有行为都是未定义的------不仅仅是那个特定的变量,整个程序的行为都不可预测。
4.2 std::atomic 基础用法
std::atomic<T> 是 C++11 引入的类模板,定义在 <atomic> 头文件中,用于提供原子类型------可以在多线程环境下安全访问的数据类型,无需使用互斥锁就能避免数据竞争。
普通变量在多线程下并发读写会触发未定义行为 (数据竞争)。而 std::atomic<T> 保证:
- 原子性:一个线程对原子对象的读/写操作不会被其他线程"看到一半"。
- 线程间同步 :通过
std::memory_order参数,原子操作还能为周围的非原子内存访问建立 happens-before 关系,这是无锁编程的基础。
类型限制:std::atomic 既不可复制也不可移动。原因很简单:复制一个原子对象需要同时读源和写目标,这两步本身就不是原子的。
cpp
#include <atomic> // 原子操作头文件
#include <thread> // 线程支持
#include <iostream>
#include <vector>
// ✅ 使用 std::atomic 保证原子性
// atomic<int> 保证对 counter 的所有操作都是原子的,不会被其他线程"撕裂"
std::atomic<int> counter{0}; // 花括号初始化(推荐)
void increment(int times) {
for (int i = 0; i < times; ++i) {
// fetch_add 是原子的 Read-Modify-Write 操作:
// 将 counter 加 1,并返回加之前的旧值
// memory_order_relaxed 表示只保证原子性,不保证与其他变量的顺序关系
// 对于独立的计数器,relaxed 就足够了(性能最好)
counter.fetch_add(1, std::memory_order_relaxed);
// 或者使用 operator++ 重载(默认使用 seq_cst 语序,更安全但性能稍差):
// counter++;
}
}
int main() {
const int num_threads = 8; // 使用 8 个线程
const int per_thread = 100000; // 每个线程递增 10 万次
std::vector<std::thread> threads; // 线程容器
for (int i = 0; i < num_threads; ++i) {
// emplace_back 原地构造线程对象,比 push_back 更高效
threads.emplace_back(increment, per_thread);
}
for (auto& t : threads) {
t.join(); // 等待所有线程完成
}
// 结果一定是 800000,不会有数据竞争
// load() 原子地读取 counter 的当前值
std::cout << "Counter = " << counter.load() << std::endl;
return 0;
}4.3 std::atomic 支持的类型(atomic模板与特化)
1、主模板 std::atomic<T>
可用于任何满足以下条件的用户自定义类型T:
- TriviallyCopyable(可平凡复制)
- 可拷贝/移动构造,可拷贝/移动赋值
- 不能是 cv 限定的(LWG 4069 修复)
cpp
struct Counters { int a; int b; }; // 平凡可复制
std::atomic<Counters> cnt; // OK注意: 用户自定义类型的原子操作通常不是无锁的 ------实现一般会内部加一把锁,只为你提供原子性的语义假象。可以用 is_lock_free() 或 is_always_lock_free 查询。
std::atomic<bool> 也走主模板,但保证是标准布局并具有平凡析构函数。
2、指针特化 std::atomic<U*>
除了基本操作外,额外支持指针算术:fetch_add、fetch_sub、++、-- 等(按元素步长偏移,类似裸指针运算)。
**3、std::shared_ptr / std::weak_ptr **特化(C++20)
定义在 <memory> 中,让原子地替换共享指针成为可能,取代了 C++20 之前的自由函数 std::atomic_load(shared_ptr*) 等(已弃用)。
4、整数类型特化
对所有标准整数类型(char、short、int、long、long long、对应无符号版本、char8_t/char16_t/char32_t/wchar_t,以及 <cstdint> 中的定宽类型),除基本操作外还提供:
fetch_add/fetch_sub------ 原子加减fetch_and/fetch_or/fetch_xor------ 原子位运算fetch_max/fetch_min(C++26) ------ 原子取大/取小- 复合赋值
+=、-=、&=、|=、^=、++、--
特别注意:有符号整数算术明确定义为二进制补码,没有未定义行为 ------不像普通有符号 int 溢出是 UB。
5、浮点类型特化(C++20)
对 float、double、long double 提供 fetch_add/fetch_sub。即使结果不可表示也不会 UB,但浮点环境可能与调用线程不同。
cpp
// ==================== 基本整数类型 ====================
std::atomic<bool> flag; // 原子布尔
std::atomic<int> counter; // 原子 int (32 位)
std::atomic<long> big_counter; // 原子 long
std::atomic<unsigned int> unsigned_counter; // 原子无符号 int
std::atomic<int64_t> precise_counter; // 原子 64 位整数
// ==================== 指针类型 ====================
// 原子指针支持 fetch_add/fetch_sub(指针算术),但不支持 fetch_and 等位操作
std::atomic<int*> ptr;
std::atomic<Node*> head;
// ==================== C++20 引入浮点数支持 ====================
std::atomic<float> value; // C++20 支持 fetch_add, fetch_sub
std::atomic<double> result; // C++20 支持 fetch_add, fetch_sub
// 注意:浮点原子操作不支持 fetch_and / fetch_or 等位操作
// 注意:浮点原子操作的 RMW 使用 CAS 循环实现(因为硬件不直接支持原子浮点加法)
// ==================== 自定义类型 ====================
// 必须满足 TriviallyCopyable 条件:
// 1. 没有虚函数(no virtual functions)
// 2. 没有虚基类(no virtual base classes)
// 3. 可以用 memcpy 安全复制(trivial copy/move constructor/assignment)
// 4. 有 trivial 析构函数
struct Point {
int x, y;
};
std::atomic<Point> pos; // OK,Point 是 trivially copyable 的
// 判断某个类型是否满足 TriviallyCopyable
static_assert(std::is_trivially_copyable_v<Point>,
"Point must be trivially copyable for std::atomic");
// ❌ 以下类型不能用 std::atomic
// std::atomic<std::string> s; // 错误!string 有动态内存,不是 trivially copyable
// std::atomic<std::vector<int>> v; // 错误!vector 有动态内存
// std::atomic<std::shared_ptr<int>> sp; // 错误!(但 C++20 提供了 std::atomic<std::shared_ptr<T>>)
// ==================== C++20 特殊支持 ====================
// C++20 为 std::shared_ptr 和 std::weak_ptr 提供了原子特化:
// std::atomic<std::shared_ptr<int>> atomic_sp; // C++20 OK
// 这在无锁数据结构中非常有用,但内部实现通常使用锁(不是 lock-free 的)4.4 std::atomic 的核心操作
成员函数速览:
| 函数 | 作用 |
|---|---|
store(v, order) |
原子写入 |
load(order) |
原子读取 |
operator T / operator= |
load/store 的语法糖 |
exchange(v) |
原子地写入新值并返回旧值 |
compare_exchange_weak/strong |
CAS: 若当前值等于期望值则写入新值,否则把当前值读到期望值中 |
is_lock_free() |
运行时查询是否无锁 |
is_always_lock_free |
编译期常量(C++17),所有平台都无锁时为 true |
wait(old) / notify_one() / notify_all() |
C++20 引入的原子等待/通知,类似条件变量 |
cpp
#include <atomic>
std::atomic<int> x{0}; // 初始化为 0
// ==================== 基本读写操作 ====================
// store: 原子写入(仅写操作)
// 将值原子地写入 x,保证其他线程不会看到"写了一半"的值
x.store(42); // 默认 memory_order_seq_cst
x.store(42, std::memory_order_release); // 指定 release 语序(更高效)
x = 42; // store的语法糖,等价于x.store(42);
// load: 原子读取(仅读操作)
// 原子地读取 x 的值,保证读到的是一个完整的值
int val = x.load(); // 默认 memory_order_seq_cst
int val2 = x.load(std::memory_order_acquire); // 指定 acquire 语序
int val3 = x; // load的语法糖,等价于int val3 = x.load();
// exchange: 原子"交换"操作(Read-Modify-Write 操作)
// 将 x 设为 100,并返回 x 交换前的旧值
// 整个"读旧值+写新值"是一个不可分割的原子操作
int old = x.exchange(100); // x 变为 100,old 是交换前的值
// ==================== 算术操作(仅整数和指针类型)====================
// 这些都是 Read-Modify-Write (RMW) 操作,天然支持 acq_rel 语义
x.fetch_add(5); // 原子加:x += 5,返回旧值(即加之前的值)
x.fetch_sub(3); // 原子减:x -= 3,返回旧值
x.fetch_and(0xFF); // 原子按位与:x &= 0xFF,返回旧值
x.fetch_or(0x01); // 原子按位或:x |= 0x01,返回旧值
x.fetch_xor(0x10); // 原子按位异或:x ^= 0x10,返回旧值
// 操作符重载(默认使用 seq_cst,方便但性能稍差)
x++; // 等效于 x.fetch_add(1, memory_order_seq_cst),返回旧值
++x; // 等效于 x.fetch_add(1, memory_order_seq_cst) + 1,返回新值
x--; // 等效于 x.fetch_sub(1, memory_order_seq_cst),返回旧值
x += 5; // 等效于 x.fetch_add(5, memory_order_seq_cst) + 5,返回新值
// 注意:x++ 和 ++x 的语义差异!x++ 返回旧值,++x 返回新值
// ==================== CAS 操作(最重要!)====================
int expected = 42; // 期望值(会被 CAS 修改!)
// compare_exchange_strong: 强 CAS
// 语义:if (x == expected) { x = 100; return true; }
// else { expected = x; return false; }
// 整个操作是原子的
// "strong" 表示只在 x != expected 时才返回 false
bool success = x.compare_exchange_strong(expected, 100);
// compare_exchange_weak: 弱 CAS
// 和 strong 的区别:即使 x == expected,也可能返回 false("伪失败")
// 但在循环中使用时,weak 的性能通常更好(在 ARM 上尤其明显)
bool success2 = x.compare_exchange_weak(expected, 100);
// CAS 可以为成功和失败指定不同的 memory order
int exp = 0;
bool ok = x.compare_exchange_weak(
exp, // 期望值(引用,失败时被更新)
42, // 期望成功时写入的值
std::memory_order_release, // 成功时的内存序
std::memory_order_relaxed // 失败时的内存序(不能强于成功时的语序)
);
// ==================== 查询 ====================
// 检查是否是真正的原子操作(而非用锁模拟的)
bool lock_free = x.is_lock_free();
// 编译期常量版本(C++17),用于编译时断言
constexpr bool always_lock_free = std::atomic<int>::is_always_lock_free;
// 用法:static_assert(std::atomic<int>::is_always_lock_free,
// "需要硬件级原子支持");4.5 is_lock_free 的含义
并非所有 std::atomic<T> 都是真正的无锁操作 。如果类型 T 的大小超过了平台原子指令能处理的范围 ,编译器会退化为用内部锁 (通常是一个全局的自旋锁数组,叫做 "lock table")来实现:
cpp
#include <atomic>
#include <iostream>
struct Small { int a; }; // 4 bytes
struct Medium { long a, b; }; // 16 bytes
struct Large { long a, b, c, d, e; }; // 40 bytes
int main() {
std::atomic<Small> s;
std::atomic<Medium> m;
std::atomic<Large> l;
// 在 x86_64 上的典型输出:
std::cout << "Small is_lock_free: " << s.is_lock_free() << std::endl;
// 输出 1 (true):4 字节,CMPXCHG 指令直接支持
std::cout << "Medium is_lock_free: " << m.is_lock_free() << std::endl;
// 输出 1 (true):16 字节,通过 CMPXCHG16B 指令支持(需要 -mcx16 编译选项)
std::cout << "Large is_lock_free: " << l.is_lock_free() << std::endl;
// 输出 0 (false):40 字节,超过了硬件原子指令的能力
// 编译器内部会使用一个自旋锁来保护对这个 atomic 的访问
// 性能会大幅下降!
return 0;
}lock table 的实现细节
当
is_lock_free()返回 false 时,编译器使用一个全局的锁哈希表来保护原子操作。GCC/libstdc++ 的实现大致如下:
cpp// 简化的内部实现(概念性代码,非真实代码) static std::mutex lock_table[16]; // 全局锁数组 template<typename T> void atomic_store_fallback(T* addr, T value) { // 根据地址哈希选择锁,减少不同原子变量之间的争用 size_t index = (reinterpret_cast<uintptr_t>(addr) >> 4) % 16; std::lock_guard<std::mutex> guard(lock_table[index]); *addr = value; }问题:不同的
atomic<Large>变量可能映射到同一把锁,产生"虚假争用"。
经验法则 :在 x86_64 上,8 字节及以下的类型通常是 lock-free 的;16 字节在支持cmpxchg16b的平台上也是 lock-free 的。超过 16 字节的自定义类型不建议使用std::atomic。
5. volatile vs std::atomic:一个经典的误区
很多从 C 或 Java 转过来的程序员会用 volatile 来做线程间同步,这在 C++ 中是完全错误的。
5.1 volatile 的真实含义
**volatile 是 C++ 中的类型限定符(与 const 同级),核心作用是告诉编译器:该变量的值可能在程序控制之外被意外修改,**因此禁止对其进行任何优化,确保每次读写都直接访问内存(告诉编译器不要优化对该变量的访问 ------每次读必须从内存读取,每次写必须写入内存)。
volatile 只影响编译阶段,不改变运行时的 CPU 指令或内存模型:
- 正常情况:编译器会将高频变量存入寄存器(速度远快于内存),减少内存访问。
volatile:强制每次读取都从内存重新加载,每次写入都立即同步到内存。
cpp
// volatile 的正确用途 1:硬件 I/O 映射寄存器
volatile uint32_t* const GPIO_PORT = (volatile uint32_t*)0x40000000;
// 每次读写 *GPIO_PORT 都会真正访问硬件寄存器
// 如果不加 volatile,编译器可能缓存上次读取的值,导致读不到硬件变化
// volatile 的正确用途 2:信号处理
volatile sig_atomic_t signal_received = 0;
void signal_handler(int sig) {
signal_received = 1; // 信号处理函数中设置标志
}
void main_loop() {
while (!signal_received) { // 主循环中检查标志
// volatile 防止编译器将 signal_received 缓存到寄存器
}
}5.2 volatile 不能做什么
cpp
volatile int counter = 0; // ❌ 用 volatile 做线程间同步是错误的!
// 问题一:volatile 不保证原子性
// volatile int 的 counter++ 仍然是 LOAD-ADD-STORE 三步
// 两个线程同时 counter++ 仍然会丢失计数
// 问题二:volatile 不阻止 CPU 重排序
// volatile 只阻止编译器对该变量的优化,但 CPU 仍然可以乱序执行
// 在 ARM 上,volatile 写入后跟的 volatile 读取可能被重排
// 问题三:volatile 没有 happens-before 语义
// C++ 标准不保证 volatile 操作在不同线程间建立任何排序关系
// 对 volatile 变量的并发读写仍然是未定义行为5.3 对比总结
cpp
// ┌─────────────────────────────┬─────────────┬──────────────┐
// │ 特性 │ volatile │ std::atomic │
// ├─────────────────────────────┼─────────────┼──────────────┤
// │ 阻止编译器优化访问 │ ✓ │ ✓ │
// │ 保证操作的原子性 │ ✗ │ ✓ │
// │ 阻止编译器重排序 │ 部分(*) │ ✓ │
// │ 阻止 CPU 重排序 │ ✗ │ ✓ │
// │ 建立 happens-before 关系 │ ✗ │ ✓ │
// │ 适用于线程间同步 │ ✗ │ ✓ │
// │ 适用于硬件 I/O │ ✓ │ ✗ │
// │ 适用于信号处理 │ ✓ │ ✓(C++11后) │
// └─────────────────────────────┴─────────────┴──────────────┘
// (*) volatile 只阻止编译器对该特定变量的重排,不阻止与其他变量之间的重排
// ✅ 正确做法:线程间同步用 std::atomic
std::atomic<bool> ready{false};
// ❌ 错误做法:不要用 volatile 做线程间同步
// volatile bool ready = false;
// ⚠️ Java 的 volatile 不等于 C++ 的 volatile!
// Java 的 volatile 具有 acquire/release 语义,可以用于线程同步
// C++ 的 volatile 没有任何多线程语义6. std::atomic_flag:唯一保证 lock-free 的原子类型 与 自旋锁实现
6.1 为什么需要 atomic_flag?
std::atomic_flag 是 C++11 引入的一个布尔型原子标志 ,定义在 <atomic> 中。它的特殊地位在于:
它是 C++ 标准中唯一保证在所有平台上都是 lock-free 的原子类型。
这句话很关键。你可能会问:std::atomic<bool> 难道不是无锁的吗?答案是------通常是,但标准不保证(不保证在所有平台上都是 lock-free 的(取决于类型大小和平台支持)) 。标准只保证 atomic_flag。之所以能做这种保证,是因为 atomic_flag 的接口被刻意设计得极其贫瘠,贫瘠到任何一个有点现代味道的 CPU 都能用一条指令实现它。
atomic_flag 只有两种状态:set(已设置) 和 clear(已清除)。C++20 之前,它只提供两个操作:
| 操作 | 语义 |
|---|---|
test_and_set() |
原子地把 flag 设为 set,返回之前的值 |
clear() |
原子地把 flag 设为 clear |
它没有 load(),也没有 store(true)------你不能单纯地"读取"它的当前状态而不修改它(C++20 之前)。这是为了让它能直接映射到硬件的 test-and-set 指令,比如:
- x86:
xchg或lock bts - ARM:
ldxr/stxr对 - RISC-V:
amoswap
C++20 之后补充了几个方法:
| 新操作(C++20) | 语义 |
|---|---|
test() |
只读地查询当前状态,不修改 |
wait(old) |
若当前值等于 old 则阻塞,直到被通知 |
notify_one() / notify_all() |
唤醒因 wait 阻塞的线程 |
6.2 std::atomic_flag 的使用
C++20 之前,atomic_flag 必须 用宏 ATOMIC_FLAG_INIT 初始化:
cpp
std::atomic_flag f = ATOMIC_FLAG_INIT; // 初始为 clearC++20 之后,默认构造函数就保证初始状态为 clear,也可以用 {}:
cpp
std::atomic_flag f; // C++20:保证 clear
std::atomic_flag f{}; // 同上这是因为 C++20 之前,标准并不要求 atomic_flag 的默认构造函数把它初始化为 clear------这看起来很怪,但同样是为了迁就某些硬件。C++20 修正了这一点。
6.3 使用std::atomic_flag 实现自旋锁
自旋锁:自旋锁(spinlock)是一种忙等待 的锁,当锁不可用时,线程不睡眠 ,而是在一个紧凑的循环里反复检查锁状态,直到拿到为止。
与互斥锁(std::mutex)对比:
| 互斥锁 | 自旋锁 | |
|---|---|---|
| 获取失败时的行为 | 线程被挂起,让出 CPU | 线程占着 CPU 反复尝试 |
| 上下文切换开销 | 有(进入内核态) | 无 |
| 等待时的 CPU 占用 | 0 | 100% |
| 适合的临界区 | 较长 | 极短(几十条指令以内) |
| 适合的场景 | 通用 | 多核 + 短临界区 + 低竞争 |
std::mutex(互斥锁)在锁争用时会产生高额的上下文切换开销(微秒级、千~万 CPU 周期);自旋锁(Spinlock)完全无上下文切换,但会持续消耗 CPU 资源进行忙等。 两者的本质差异在于等待策略 :互斥锁是 "让出 CPU、休眠等待 ",自旋锁是"占用 CPU、循环检查"。
核心权衡 :自旋锁避免了上下文切换的开销 ,但代价是等待期间把 CPU 烧掉 。如果临界区很短(比如就是几条赋值),自旋几次就能拿到锁 ,这比让操作系统调度划算得多;但如果临界区很长或者竞争激烈,自旋锁会疯狂浪费 CPU,还不如乖乖用 std::mutex。
cpp
// 朴素版实现自旋锁
#include <atomic>
#include <thread>
#include <iostream>
// atomic_flag 只有两个操作:test_and_set() 和 clear()
// 它是最底层的原子类型,适合实现自旋锁等同步原语
// ==================== 用 atomic_flag 实现自旋锁 ====================
class SpinlockFlag {
// ATOMIC_FLAG_INIT 将 flag 初始化为 "清除" 状态
// C++20 中可以直接用 {} 初始化
std::atomic_flag flag_ = ATOMIC_FLAG_INIT;
public:
void lock() {
// test_and_set:原子地将 flag 设为 "已设置",返回旧值
// 如果旧值是 false(未锁定),说明我们成功获取了锁
// 如果旧值是 true(已锁定),说明锁被其他线程持有,继续自旋
// memory_order_acquire: 保证锁内的操作不被提前到 lock 之前
while (flag_.test_and_set(std::memory_order_acquire)) {
// 自旋等待
// 优化一:
// C++20 提供了 test() 方法(只读,不修改 flag)
// 先用 test() 检查可以减少对缓存行的写入争用
// while (flag_.test(std::memory_order_relaxed)) {
// // 纯读操作,不修改缓存行,减少总线流量
// }
// 优化二:
#if defined(__x86_64__)
__builtin_ia32_pause(); // PAUSE 指令:降低自旋时的功耗和总线争用
#elif defined(__aarch64__)
asm volatile("yield"); // ARM 的等效指令
#endif
}
}
void unlock() {
// clear:原子地将 flag 设为 "清除" 状态
// memory_order_release: 保证锁内的操作不被延迟到 unlock 之后
flag_.clear(std::memory_order_release);
}
// 尝试获取锁:如果锁空闲则获取并返回 true,否则立即返回 false(不阻塞)
bool try_lock() {
return !flag_.test_and_set(std::memory_order_acquire);
}
};
// ==================== 使用示例 ====================
SpinlockFlag spin;
int shared_counter = 0;
void worker(int id, int iterations) {
for (int i = 0; i < iterations; ++i) {
spin.lock();
// ------ 临界区开始 ------
shared_counter++; // 安全的:同一时间只有一个线程在这里
// ------ 临界区结束 ------
spin.unlock();
}
}
// 或者搭配 std::lock_guard 使用
// void worker(int id, int iterations)
// {
// for (int i = 0; i < iterations; ++i)
// {
// // 上面自旋锁的实现满足 C++ 的 Lockable 具名要求,可以直接配合 std::lock_guard 使用
// std::lock_guard<SpinlockFlag> lock(spin); // RAII 锁
// shared_counter++;
// }
// }
// 优化一:降低总线争用(test-and-test-and-set)
// 朴素版本有个性能问题:在 x86 上,test_and_set 对应的 xchg 指令是一个带锁的读改写------它会获取缓存行的独占权,广播到所有核。如果 10 个线程同时在 test_and_set 自旋,就有 10 个核在不停地抢同一个缓存行,总线/互连被刷屏,连真正持有锁的线程做 unlock 都会变慢。
// TTAS(test and test-and-set):先用纯读操作检查 flag 是否空闲,只有看起来空闲了才尝试真正的 test_and_set。
// test() 是 C++20 新增的只读操作,在 x86 上就是普通的 mov 指令。纯读不会让缓存行进入"独占"状态,各个核可以共享这个缓存行的副本,不会互相争抢。只有当持有者 unlock 时,缓存一致性协议才会把其他核的副本标记为无效,等待者这时才会看到 flag 变 clear,然后跳出内层循环,再去试一次真正的 test_and_set。
// 这个优化一在竞争激烈的场景下能带来数倍的性能提升。
// 优化二:pause / yield 指令
#if defined(__x86_64__)
__builtin_ia32_pause(); // 对应 x86 的 PAUSE 指令
#elif defined(__aarch64__)
asm volatile("yield"); // 对应 ARM 的 YIELD 指令
#endif
// 这些指令的作用是告诉 CPU:"我现在在忙等待,别太积极"。具体做了几件事:
// 1、降低功耗:CPU 进入一种轻度节能状态,不全速执行循环。
// 2、让出流水线资源给超线程兄弟:在 Intel 超线程(SMT)架构上,两个逻辑核心共享物理执行单元。如果一个核心在自旋,pause 会把执行资源让给同核的另一个线程------而那个线程可能恰好就是锁的持有者!没有 pause 的话,自旋线程可能"饿死"持有者,反而延长了等待。
// 3、避免内存序推测惩罚:x86 会猜测后续的 load 操作不会看到乱序写入,一旦猜错要回滚。紧凑的自旋循环经常触发这种误判,pause 能缓解。
// 4、防止过快重试:减少对缓存行的轮询频率,缓解总线压力。
// 没有 pause 的自旋锁在高竞争下可能比有 pause 的慢几倍------这不是微优化,这是正确性级别的必要。让我们逐行剖析:
lock() 的逻辑 :test_and_set 原子地做两件事------把 flag 设为 set,并返回旧值。
- 如果旧值是
false(clear,表示之前没人持有),说明我们刚刚 成功把它从 clear 翻成了 set,即我们获得了锁,while条件为假,跳出循环。 - 如果旧值是
true(set,表示别人持有),说明我们这次"设置"是多余的(它本来就是 set),我们没拿到锁,继续自旋。
即使我们自旋期间反复把一个已经是 set 的 flag 设为 set,也不会破坏锁的持有者 ------因为持有者不关心 flag 具体被谁重复设置,只关心自己 unlock() 时把它清掉。
unlock() 的逻辑 :直接 clear(),让下一个自旋的线程看到 false,从而能够拿到锁。
try_lock() 的逻辑 :只尝试一次。test_and_set 返回 false 说明之前没人持有,我们成功拿到锁,返回 true。否则立即返回 false,不阻塞。
内存序:为什么必须是 acquire / release :
这是整段代码最精妙、也最容易被忽略的地方。考虑临界区的典型用法:
cpp
spin.lock();
// 临界区开始
shared_data = 42; // (A)
another_var = 100; // (B)
// 临界区结束
spin.unlock();我们期望的语义是:当另一个线程之后拿到锁时,它能看到 (A) 和 (B) 的写入。但是:
- 编译器 可能把 (A) 重排到
lock()之前,或把 (B) 重排到unlock()之后。 - CPU 也会乱序执行------特别是 ARM、POWER 这类弱内存模型架构。
如果不加约束,(A) 和 (B) 可能"溢出"临界区,破坏互斥语义。内存序参数就是用来设置这道围栏的:
memory_order_acquire(用于lock) :保证临界区内的任何读写都不能被重排到lock之前 。它像一扇只能进不能出的门------后面的操作不能跑到前面。memory_order_release(用于unlock) :保证临界区内的任何读写都不能被重排到unlock之后 。它像一扇只能出不能进的门------前面的操作不能跑到后面。
两者配对后,形成一个"盒子":临界区内的所有操作被严格限制在 lock 和 unlock 之间。而且,当线程 B 的 lock(acquire) 看到线程 A 的 unlock(release) 写入的值时,A 在临界区内的所有写入都对 B 可见 ------这就是 release-acquire 同步,也是无锁编程的基石。
如果用默认的 memory_order_seq_cst,代码也能正确工作,但会略慢(特别是 ARM 上),因为顺序一致序要求更强的硬件栅栏。acquire/release 是自旋锁刚刚好够用的最低限度。
✅ 适合用自旋锁
- 临界区极短:比如几条指令的原子累加、更新少量成员变量。
- 多核系统:单核用自旋锁基本没意义------持有者没有 CPU 就不能释放锁,等待者一直占着 CPU 等,死锁式地浪费时间,不如直接睡。
- 竞争不激烈:大部分时候锁能瞬间拿到。
- 不能睡眠的上下文:比如中断处理程序、某些内核路径。
- 对延迟极度敏感:上下文切换通常需要微秒级别,而自旋拿到锁可能只要几十纳秒。
❌ 不适合用自旋锁
- 临界区较长或可能阻塞(比如涉及 I/O、系统调用、内存分配)。
- 持有者可能被抢占 :用户态自旋锁有个致命问题------持有者的线程随时可能被 OS 调度走,这段时间里所有等待者全都在白烧 CPU。这叫"lock holder preemption",Linux 上极端情况可以烧几十毫秒。内核态没这问题(持锁时禁止抢占)。
- 高竞争:等待者越多,总线争用越严重,甚至可能整体吞吐量倒退。
- 公平性要求高 :朴素自旋锁不保证 FIFO,可能出现某个线程饥饿。如果需要公平,可以换成票锁(ticket lock) 或 MCS 锁。
实践建议:
-
对于绝大多数应用代码,优先用
std::mutex。它在低竞争时也很快(Linux 的 futex 实现让无竞争路径完全在用户态完成),在高竞争时还能自动退化到睡眠,不会烧 CPU。自旋锁是一把锋利但容易割到自己的刀------只有当你测量过、确认自旋锁能带来实实在在的性能提升时才用它。 -
补充:现代
std::mutex并不是一拿不到锁就立刻切换,Linux 上的std::mutex底层是 futex (Fast Userspace Mutex)。它的聪明之处在于:1、无竞争时完全在用户态完成 :
lock()就是一个原子 CAS,成功就返回,不进内核,代价跟一次原子操作差不多(~10 ns)。2、有竞争时才调用
futex_wait系统调用 进入内核睡眠。3、更进一步,glibc 的
pthread_mutex(C++std::mutex在 Linux 上的底层)默认会在进入内核前先自旋一小段时间 ------这种"混合策略"叫 adaptive mutex 。思路是:如果锁的持有者很快就会释放,自旋几次拿到就够了;如果自旋几次仍然拿不到,再睡。这样在两种情况下都接近最优。4、
std::mutex已经免费得到了自旋锁的快速路径,又有睡眠机制兜底。自己手写自旋锁要跑赢它,必须对工作负载有非常精准的把握。 -
另外,C++ 标准库没有 提供自旋锁类型。这不是疏忽------标准委员会讨论过但决定不加,部分原因就是:用户写的自旋锁几乎总是比不过平台优化过的
std::mutex,除非你真的知道自己在做什么。 -
不要在自旋锁保护下调用可能阻塞的代码,例如:
cppSpinlock spin; void bad() { std::lock_guard<Spinlock> g(spin); std::cout << "hello\n"; // ❌ iostream 内部可能有互斥锁、系统调用 some_syscall(); // ❌ 可能阻塞数毫秒 } // 这会把所有等待者变成长时间的 CPU 烧烤机。自旋锁的临界区要短、短、再短------理想情况下不超过几十条指令,且不包含任何可能触发调度的操作。
6.2 atomic_flag vs atomic<bool>
| 特性 | std::atomic_flag |
std::atomic<bool> |
|---|---|---|
| 保证 lock-free | ✅ 标准保证 | ⚠️ 通常是,但不保证 |
load() |
❌(C++20 前) / ✅(C++20 test()) |
✅ |
store() |
只有 clear(),即 store(false) |
✅ |
test_and_set() |
✅ 原生支持 | ❌,但可用 exchange(true) 替代 |
compare_exchange |
❌ | ✅ |
wait/notify |
✅(C++20) | ✅(C++20) |
| 适合实现自旋锁 | ✅ 最佳选择 | ✅(也可以) |
| 可复制/移动 | ❌ | ❌ |
什么时候选 atomic_flag? 当你需要一个纯粹的二元标志 ,且希望在任何平台上都保证无锁------典型场景就是自旋锁 、一次性初始化标志、以及内核/嵌入式中的低层同步原语。
什么时候选 atomic<bool>? 当你需要读取当前值、或者需要 CAS 语义、或者只是写普通应用代码 ------atomic<bool> 接口更全,在主流平台上也都是无锁的。
7. 六种 Memory Order 深度剖析
这是整个内存模型中最核心、也最难理解的部分。C++11 定义了六种内存序(Memory Order),它们控制原子操作前后的非原子操作的可见顺序。
7.1 总览
严格程度(性能开销)
▲
│
seq_cst │ ████████████████████████ ← 最严格,最安全,性能最差
│ x86: MFENCE / LOCK XCHG
│ ARM: DMB + LDAR/STLR
│
acq_rel │ ██████████████████ ← acquire + release 的组合
│ 用于 RMW 操作
│
release │ ████████████████ ← "发布"语义,保证之前的写对其他线程可见
│ x86: 普通 MOV(天然保证!)
│ ARM: STLR(Store-Release)
│
acquire │ ████████████████ ← "获取"语义,保证能看到其他线程 release 的写
│ x86: 普通 MOV(天然保证!)
│ ARM: LDAR(Load-Acquire)
│
consume │ ██████████████ ← 弱化版 acquire(不要使用!)
│ 所有编译器都当 acquire 实现
│
relaxed │ ████████ ← 最宽松,只保证原子性,不保证顺序
│ 所有平台: 普通 MOV
└──────────────────────────────►7.2 memory_order_relaxed ------ 只保证原子性
memory_order_relaxed 是最宽松的内存序。它只保证当前原子操作本身是原子的 ,但不保证任何同步和内存顺序 ------前后的操作可以被任意重排。不同线程看到的操作顺序可能不一致,但对同一变量的修改顺序(modification order)仍是全局一致的。
cpp
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<int> x{0};
std::atomic<int> y{0};
void thread_a() {
// relaxed 语序:这两条原子操作之间没有顺序保证
x.store(1, std::memory_order_relaxed); // (1) 原子写 x = 1
y.store(1, std::memory_order_relaxed); // (2) 原子写 y = 1
// 注意:(1) 和 (2) 可能被重排!
// 其他线程可能先看到 y==1 但还没看到 x==1
// 在 ARM 上这种重排非常容易发生
}
void thread_b() {
// 即使看到 y==1,也不能保证 x==1
while (y.load(std::memory_order_relaxed) != 1) {} // 等待 y 变为 1
// 以下断言在 ARM 上可能失败!在 x86 上可能"碰巧"通过(因为 TSO)
// assert(x.load(std::memory_order_relaxed) == 1); // ❌ 不安全
}适用场景 :只关心操作本身的原子性,不需要跨线程的顺序保证。最经典的场景是独立的计数器:
cpp
// ✅ relaxed 的典型正确用法:全局统计计数器
class Statistics {
// 这三个计数器互相独立,不存在"先写 A 才能写 B"的依赖关系
std::atomic<uint64_t> packets_received_{0};
std::atomic<uint64_t> packets_dropped_{0};
std::atomic<uint64_t> bytes_transferred_{0};
public:
// 多个线程同时递增不同的计数器
// 我们只关心每个计数器自身的准确性,不关心它们之间的时序
void on_packet_received(size_t bytes) {
// relaxed:只需要原子性,不需要排序保证
// 在 x86 上,这编译为一条 LOCK XADD 指令(无额外屏障)
packets_received_.fetch_add(1, std::memory_order_relaxed);
bytes_transferred_.fetch_add(bytes, std::memory_order_relaxed);
}
void on_packet_dropped() {
packets_dropped_.fetch_add(1, std::memory_order_relaxed);
}
// 读取时也用 relaxed ------ 统计数据不需要严格一致性
// 可能出现的情况:packets_received 已经更新了但 bytes_transferred 还是旧值
// 这在统计场景下是完全可以接受的
void print_stats() {
std::cout << "Received: " << packets_received_.load(std::memory_order_relaxed)
<< " Dropped: " << packets_dropped_.load(std::memory_order_relaxed)
<< " Bytes: " << bytes_transferred_.load(std::memory_order_relaxed)
<< std::endl;
}
};relaxed 的一个常见误区
relaxed 虽然不保证跨线程的顺序,但它仍然保证了单变量的一致性(也叫 coherence)。具体来说:
- 对同一个原子变量的所有修改,在所有线程中以相同的顺序出现(modification order)
- 一旦某个线程读到了某个值,后续读取只会看到相同或更新的值(不会看到更旧的值)
所以 relaxed 不是"完全无序"的------它只是不保证不同变量之间的顺序。
7.3 memory_order_acquire 和 memory_order_release ------ 最核心的配对
这是实际编程中最常用、最重要的内存序组合。理解它们就理解了 C++ 内存模型的核心。
memory_order_acquire --- 获取序:用于读操作 (load)。保证在此 load 之后的所有读写操作,不会被重排到此 load 之前。它与某个 release 操作配对,用于"接收"另一线程发布的数据。
memory_order_release --- 释放序:用于写操作 (store)。保证在此 store 之前的所有读写操作,不会被重排到此 store 之后。它把此前完成的所有修改"发布"给后续 acquire 同一变量的线程。
配对使用时的效果 :当线程 B 的 acquire-load 读到了线程 A 的 release-store 写入的值时,线程 A 在 release-store 之前 的所有写操作,对线程 B 在 acquire-load 之后都可见。
线程 A (producer) 线程 B (consumer)
───────────────── ──────────────────
data = 42; ─┐
extra = 100; │ 这些写入
msg = "hello"; │ 都在 release 之前 ───────────────┐
│ │
ready.store(true, ─┘ │
memory_order_release); ─── "release 发布" ───► │
│
while (!ready.load( │
memory_order_acquire)) │
; ← "acquire 获取" │
│
┌──── 到这里,能保证看到 ─────┘
│ data == 42 ✓
│ extra == 100 ✓
│ msg == "hello" ✓
└──现在我们来修复开头那个 Bug:
cpp
// ✅ 正确的线程间通信:使用 acquire-release 语义
#include <atomic>
#include <thread>
#include <iostream>
int data = 0; // 普通变量(非原子)------但在同步保护下可以安全使用
std::atomic<bool> ready{false}; // 原子标志变量------用于同步
void producer() {
data = 42; // (1) 普通写入
ready.store(true, std::memory_order_release); // (2) release 发布
// release 保证:(1) 一定在 (2) 之前完成
// 即:data=42 的写入效果一定在 ready=true 之前对其他核心可见
// 注意:即使 data 不是原子变量,只要在 release 之前写入,也能被 acquire 端安全读取
}
void consumer() {
while (!ready.load(std::memory_order_acquire)) { // (3) acquire 获取
// 忙等------但因为使用了 atomic,编译器不会将循环优化掉
}
// 当 (3) 读到 true 时(意味着它"看到了" producer 的 release store),
// acquire 保证:producer 在 release 之前的所有写入(包括 data=42)对这里可见
std::cout << data << std::endl; // (4) 一定输出 42 ✓
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}更实际的例子:自旋锁(Spinlock)
cpp
#include <atomic>
class Spinlock {
std::atomic<bool> locked_{false}; // false = 未锁定,true = 已锁定
public:
void lock() {
// 不断尝试将 locked_ 从 false 设为 true
// exchange 是原子的 RMW 操作:读旧值 + 写新值
// acquire 语义:如果成功获取锁(exchange 返回 false),
// 保证锁内的操作不会被重排到 lock() 之前
while (locked_.exchange(true, std::memory_order_acquire)) {
// exchange 返回旧值:
// 如果旧值是 false → 锁原来是空闲的,我们成功获取了锁,退出循环
// 如果旧值是 true → 锁被其他线程持有,继续自旋
// ===== 性能优化:Test-And-Test-And-Set (TTAS) =====
// 直接用 exchange 自旋会不断执行写操作(即使锁被持有),
// 导致缓存行在 Modified 和 Invalid 之间频繁切换(cache bouncing)
// 改为先用 relaxed load 检查,只在锁可能空闲时才执行 exchange
while (locked_.load(std::memory_order_relaxed)) {
// 纯读操作:缓存行保持 Shared 状态,不产生总线流量
// 直到其他线程 unlock(写入 false),才会收到 Invalidate
#if defined(__x86_64__)
__builtin_ia32_pause();
// PAUSE 指令的三个作用:
// 1. 告诉 CPU 这是自旋等待,降低功耗
// 2. 避免因投机执行导致的流水线清空(memory order violation)
// 3. 在超线程环境下,让出资源给另一个硬件线程
#elif defined(__aarch64__)
asm volatile("yield"); // ARM 等效指令
#endif
}
// locked_ 变为 false 了(可能),回到外层循环的 exchange 再试一次
}
}
void unlock() {
locked_.store(false, std::memory_order_release);
// release 语义:保证锁内的所有操作在 unlock 之前完成
// 即:下一个获取锁的线程能看到我们在临界区内做的所有修改
}
};
// 使用示例
Spinlock spin;
int shared_data = 0;
void worker() {
spin.lock();
// ---- 临界区开始 ----
// 所有在 acquire 之后、release 之前的读写
// 都不会被重排到临界区外部
shared_data++; // 安全的
// ---- 临界区结束 ----
spin.unlock();
}7.4 memory_order_acq_rel --- 获取-释放
用于读-改-写 (read-modify-write)操作,如 fetch_add、compare_exchange、exchange。同时具有 acquire 和 release 语义:读取部分是 acquire,写入部分是 release。
cpp
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<int> sync_point{0};
int payload_a = 0;
int payload_b = 0;
void thread_a() {
payload_a = 42; // 准备数据 A(普通写入)
// fetch_add 是 RMW 操作,同时具有 acquire 和 release 语义:
// release 效果:payload_a = 42 不会被重排到 fetch_add 之后
// → 保证其他线程通过此操作能看到 payload_a
// acquire 效果:如果 thread_b 的 fetch_add 先执行,
// 此操作之后能看到 thread_b release 之前的所有写入
int prev = sync_point.fetch_add(1, std::memory_order_acq_rel);
if (prev == 1) {
// prev == 1 说明 thread_b 已经执行了 fetch_add
// 由于我们的 acquire 语义,此处能安全读取 payload_b
std::cout << "A sees B's data: " << payload_b << std::endl; // 一定是 100
}
}
void thread_b() {
payload_b = 100; // 准备数据 B(普通写入)
int prev = sync_point.fetch_add(1, std::memory_order_acq_rel);
if (prev == 1) {
// prev == 1 说明 thread_a 已经执行了 fetch_add
std::cout << "B sees A's data: " << payload_a << std::endl; // 一定是 42
}
}
// 注意:prev == 0 的那个线程不能安全读取另一个线程的 payload
// 因为另一个线程可能还没执行到 fetch_add
// 只有 prev == 1 的线程才建立了与另一个线程的 happens-before 关系7.5 memory_order_seq_cst ------ 全局一致顺序
seq_cst(Sequential Consistency,顺序一致性)是最严格的 内存序,也是所有 std::atomic 操作的默认内存序 。
它在 acquire/release 的基础上,额外保证了:所有线程看到的所有 seq_cst 操作的顺序是一致的(存在一个全局一致的全序关系 "S")。
例如下面代码这个例子:
四个线程并发运行:
- 线程1:写
x = true - 线程2:写
y = true - 线程3:先等
x变 true,再看y是不是 true,是就z++ - 线程4:先等
y变 true,再看x是不是 true,是就z++
问题:最终 z 会不会是 0?也就是说,是否可能线程3 看到 x=true, y=false,同时 线程4 看到 y=true, x=false?
直觉上这不可能------既然线程3 已经看到 x 是 true,线程4 又看到 y 是 true,那两个写都已经发生了,怎么可能后续的读又都看不到对方?但在 acquire/release 下,这居然是可能的。
为什么acquire/release 下会有这个问题?
write_x 和 write_y 是两个独立的 store,它们之间没有任何 happens-before 关系 (分别在两个不相关的线程里,happens-before具体是什么后面有详细说)。acquire/release 建立的同步是"点对点"的:
- 线程3 的
x.load(acquire)读到 true,与线程1 的x.store(release)同步 → 线程3 能看到线程1 此前的所有写入 - 线程4 的
y.load(acquire)读到 true,与线程2 的y.store(release)同步 → 线程4 能看到线程2 此前的所有写入
但线程1 的写和线程2 的写之间没有任何约束。于是允许这样一种"观察不一致":
- 从线程3 的视角:
x先变 true,y后变 true(当它读 y 时 y 还没传播过来) - 从线程4 的视角:
y先变 true,x后变 true(当它读 x 时 x 还没传播过来) - 这两种视角各自都自洽 ,但合在一起矛盾 ------没有一个全局顺序能同时满足"x 先于 y"和"y 先于 x"。acquire/release 允许这种矛盾存在,因此
z == 0是可能的。 - 这种现象在真实硬件上(尤其是 POWER、ARM)是会实际发生的,不是纯理论。原因是每个 CPU 核心有自己的 store buffer,一个核心的写何时对其他核心可见是独立的,不同观察者看到的传播顺序可能不同。
seq_cst 额外要求:所有 seq_cst 操作存在一个全局单一顺序 S,所有线程看到的都是这同一个 S 。
在这个全局顺序里,write_x 和 write_y 必有一个先一个后。假设 S 中 write_x 在 write_y 之前:
- 线程4 看到
y == true,说明write_y已在 S 中发生,那么write_x(在它之前)也必然已发生,所以线程4 读x一定得到 true →z++ - 线程3 可能看到
y是 true 或 false,不确定,但至少线程4 必然z++
反过来假设 write_y 在 write_x 之前,则线程3 必然 z++。
无论哪种情况,至少有一个线程会递增 z,所以 z 不可能为 0。
cpp
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<bool> x{false};
std::atomic<bool> y{false};
std::atomic<int> z{0};
void thread_a()
{
x.store(true, std::memory_order_seq_cst); // (1) seq_cst 写 x
}
void thread_b()
{
y.store(true, std::memory_order_seq_cst); // (2) seq_cst 写 y
}
void thread_c()
{
while (!x.load(std::memory_order_seq_cst)); // (3) 等 x 变为 true
if (y.load(std::memory_order_seq_cst)) { // (4) 检查 y
z.fetch_add(1, std::memory_order_relaxed); // y 也为 true,z++
std::cout << "thread_c" << std::endl;
}
}
void thread_d()
{
while (!y.load(std::memory_order_seq_cst)); // (5) 等 y 变为 true
if (x.load(std::memory_order_seq_cst)) { // (6) 检查 x
z.fetch_add(1, std::memory_order_relaxed); // x 也为 true,z++
std::cout << "thread_d" << std::endl;
}
}
int main()
{
std::thread a(thread_a), b(thread_b), c(thread_c), d(thread_d);
a.join(); b.join(); c.join(); d.join();
// 如果使用 seq_cst,z 不可能为 0
// 因为所有线程对 x, y 的 seq_cst 操作观察顺序是一致的:
// 要么全局顺序是 x=true 先于 y=true:
// → thread_d 看到 y=true 后一定也看到 x=true → z 至少为 1(是否为2这个无法确定,因为x先于y发生,此时thread_c读取y时,y可能为false)
// 要么全局顺序是 y=true 先于 x=true:
// → thread_c 看到 x=true 后一定也看到 y=true → z 至少为 1(是否为2这个无法确定,因为y先于x发生,此时thread_d读取x时,x可能为false)
assert(z.load() != 0); // ✅ 在 seq_cst 下一定成立
std::cout << z.load() << std::endl;
// 但如果改成 acquire/release,z == 0 是可能发生的!
// 因为 acquire/release 没有全局一致顺序的保证
// thread_c 可能看到 x=true, y=false(x先变)
// thread_d 可能看到 y=true, x=false(y先变)
// 两个线程对 x 和 y 的修改顺序的"观察"可以不一致!
}seq_cst 的代价 :在 x86 上,seq_cst store 需要插入 MFENCE 指令或使用 LOCK XCHG 指令(比普通 MOV 慢得多)。在 ARM 上,需要额外的 DMB 指令。
不同 memory order 在 x86 上的指令生成:
release store: MOV [addr], val ← 普通指令,零额外开销!
seq_cst store: MOV [addr], val; MFENCE ← 多了一条 MFENCE(或用 XCHG)
或 LOCK XCHG [addr], val
acquire load: MOV val, [addr] ← 普通指令,零额外开销!
seq_cst load: MOV val, [addr] ← x86 上和 acquire load 一样!
结论:x86 上 acquire/release 几乎免费,seq_cst store 有显著开销
ARM 上所有非 relaxed 操作都有开销7.6 memory_order_consume ------ 几乎不要用
consume 是 acquire 的弱化版本,它只保证有数据依赖关系 的后续操作不被重排。理论上比 acquire 开销更小,但:
- 几乎所有编译器都把
consume当作acquire来实现(因为正确追踪数据依赖关系太困难了) - C++17 标准明确建议不要使用
consume - C++ 标准委员会正在考虑重新设计
consume(可能在未来标准中修改语义) - 实际编程中,请始终使用
acquire代替consume
** consume 的理论价值**
consume 的设计初衷是利用 CPU 的"数据依赖序"(data dependency ordering)。几乎所有 CPU 都天然保证:如果指令 B 的输入依赖于指令 A 的输出,则 B 不会在 A 之前执行。consume 希望利用这个特性来避免生成不必要的屏障指令(尤其在弱序架构如 ARM 上)。
例如:
T* p = atomic_ptr.load(consume); use(p->data);这里p->data依赖于p,CPU 天然会先加载p再加载p->data,不需要屏障。但问题是编译器在优化时可能打破数据依赖(例如通过常量传播),导致 consume 语义被破坏。所以编译器选择保守地将 consume 升级为 acquire。
7.7 六种内存序的总结对比
cpp
// ┌─────────────────────┬───────────────────────────────────────────────┐
// │ 场景 │ 推荐 Memory Order │
// ├─────────────────────┼───────────────────────────────────────────────┤
// │ 独立的计数器 │ relaxed │
// │ (不与其他数据联动) │ │
// ├─────────────────────┼───────────────────────────────────────────────┤
// │ 生产者-消费者模式 │ 生产者用 release store │
// │ (发送/接收数据) │ 消费者用 acquire load │
// ├─────────────────────┼───────────────────────────────────────────────┤
// │ 自旋锁 │ lock: acquire (exchange/CAS) │
// │ │ unlock: release (store) │
// ├─────────────────────┼───────────────────────────────────────────────┤
// │ 读-改-写操作需要 │ acq_rel (fetch_add, CAS 等) │
// │ 同时读写 │ │
// ├─────────────────────┼───────────────────────────────────────────────┤
// │ 需要全局一致顺序 │ seq_cst │
// │ 或者不确定该用什么 │ (最安全,但性能最差) │
// ├─────────────────────┼───────────────────────────────────────────────┤
// │ 不知道该用什么 │ 先用 seq_cst,性能分析后再降级 │
// └─────────────────────┴───────────────────────────────────────────────┘8. Happens-Before 关系的形式化定义
C++ 内存模型的核心是 happens-before 关系。理解它需要先理解几个更基本的概念。
8.1 基本概念链
Sequenced-Before (同一线程内的程序顺序)
↓
Synchronizes-With (一个 release 操作与读到其值的 acquire 操作之间建立的跨线程同步关系,由原子操作建立)
↓
Happens-Before = sequenced-before 与 synchronizes-with 的传递闭包
↓
Visible Side Effect (可见的副作用)
// 如果操作 A happens-before 操作 B,那么 A 的效果对 B 可见。这是无锁编程推理正确性的核心工具。补充:什么是闭包?sequenced-before 和 synchronizes-with具体是什么?为什么Happens-before 是 sequenced-before 与 synchronizes-with 的传递闭包?
1、sequenced-before 与 synchronizes-with :
- Sequenced-before(顺序前) :同一个线程内,代码按书写顺序执行的先后关系。比如线程里
a = 1; b = 2;,a=1sequenced-beforeb=2。 - Synchronizes-with(同步于) :跨线程的同步关系,比如一个线程对原子变量的
release操作,和另一个线程对同一个变量的acquire操作,就建立了 synchronizes-with 关系。
2、传递性(是一种属性):
如果关系 R 是传递的,就意味着:
若
A R B且B R C,则一定有A R C。
比如「大于」是传递关系:A > B 且 B > C → A > C;
而「朋友」不是传递关系 :A是B的朋友、B是C的朋友,不代表A是C的朋友。
3、传递闭包:
对于一个关系
R,它的传递闭包是「包含R的、最小的传递关系」。
通俗来说:
- 原关系
R可能本身不满足传递性; - 我们给它补全所有能通过传递性推出来的新关系,得到的完整关系集合,就是它的传递闭包。
举个简单例子:
假设我们有 3 个操作 A, B, C,原关系只有:A R B,B R C
原关系 R 不满足传递性(没有 A R C),我们补全 A R C 后,得到的完整关系 {A R B, B R C, A R C},就是 R 的传递闭包。
4、Happens-Before:
Happens-before 是 sequenced-before 与 synchronizes-with 的传递闭包 ,意思是:
a、基础规则(原关系):
- 规则 1(线程内顺序):如果操作
Xsequenced-beforeY,那么X happens-before Y; - 规则 2(跨线程同步):如果操作
Xsynchronizes-withY,那么X happens-before Y。
b、传递性补全(闭包的核心)
- 规则 3(传递性):如果
X happens-before Y,且Y happens-before Z,那么X happens-before Z。
c、完整的 Happens-Before 关系:
就是把所有满足规则 1、规则 2 的基础关系,再通过规则 3 补全所有能传递推导出来的关系,最终得到的完整关系集合,就是「sequenced-before 与 synchronizes-with 的传递闭包」。
5、例子:
cpp
// 线程A
int a = 1; // 操作A
flag.store(true, std::memory_order_release); // 操作B (release)
// 线程B
while (!flag.load(std::memory_order_acquire)); // 操作C (acquire,读到B的true)
int b = a; // 操作D推导 Happens-Before 关系:
- 线程内顺序 :
A sequenced-before B→A happens-before B;C sequenced-before D→C happens-before D; - 跨线程同步 :
B synchronizes-with C→B happens-before C; - 传递闭包补全 :
A happens-before B+B happens-before C+C happens-before D→A happens-before D。
最终结论:A(a=1)的效果对 D(b=a)可见,所以 b 一定等于 1,不会出现读到旧值的问题。
这就是 Happens-Before 作为**「传递闭包」**的实际作用:把线程内顺序和跨线程同步串起来,保证跨线程的内存可见性。
8.2 详细定义与示例
cpp
#include <atomic>
#include <thread>
std::atomic<int> flag{0};
int data = 0; // 非原子变量
int result = 0; // 非原子变量
void writer() {
data = 42; // (A)
flag.store(1, std::memory_order_release); // (B)
}
void reader() {
while (flag.load(std::memory_order_acquire) != 1) {} // (C)
result = data; // (D)
}
// ==================== Happens-Before 分析 ====================
//
// 1. Sequenced-Before(线程内的程序顺序):
// (A) sequenced-before (B) ------ 因为 (A) 在同一线程中先于 (B) 执行
// (C) sequenced-before (D) ------ 因为 (C) 在同一线程中先于 (D) 执行
//
// 2. Synchronizes-With(跨线程同步):
// 当 (C) 的 acquire load 读到了 (B) 的 release store 写入的值 1 时:
// (B) synchronizes-with (C) ------ release store 与 acquire load 构成同步
//
// 3. Happens-Before(传递闭包):
// (A) happens-before (B) ------ 来自 sequenced-before
// (B) happens-before (C) ------ 来自 synchronizes-with
// (C) happens-before (D) ------ 来自 sequenced-before
//
// 通过传递性:
// (A) happens-before (D) ------ A → B → C → D
//
// 4. 结论:
// 因为 (A) happens-before (D),
// 所以 (D) 读取 data 时一定能看到 (A) 写入的 42。
// result 一定等于 42。✅8.3 Modification Order(修改序)
每个原子变量 都有一个修改序 ------所有线程对该变量的修改构成一个全序关系(total order)。所有线程都同意这个顺序。
cpp
#include <atomic>
#include <thread>
#include <cassert>
std::atomic<int> x{0};
// 假设 3 个线程分别写入 x:
// Thread 1: x.store(1, relaxed);
// Thread 2: x.store(2, relaxed);
// Thread 3: x.store(3, relaxed);
// 修改序可能是以下任意一种(但一旦确定,所有线程都看到相同的顺序):
// 0 → 1 → 2 → 3
// 0 → 1 → 3 → 2
// 0 → 2 → 1 → 3
// 0 → 2 → 3 → 1
// 0 → 3 → 1 → 2
// 0 → 3 → 2 → 1
// 关键保证:如果 Thread A 先看到 x=1 再看到 x=2,
// 那么 Thread B 不可能先看到 x=2 再看到 x=1
// (对同一个原子变量,所有线程的观察顺序一致)
// 这就是 "coherence" 保证,即使使用 relaxed 也有此保证8.4 Release Sequence(释放序列)
release sequence 是一个重要但常被忽略的概念。它允许 acquire load 与 release store 之间存在其他 RMW 操作,仍然能建立 synchronizes-with 关系。
回到标准的acquire/release配对:
cpp
shared_data = 42;
count.store(1, release); // (A)
// ...
while (count.load(acquire) < 1) {} // (C)
assert(shared_data == 42); // OK
// 这里 (C) 直接读到了 (A) 写入的值 1,所以 (A) synchronizes-with (C),happens-before 关系建立,shared_data 可见。
// 但如果中间有人改了 count 呢?(C) 可能读到的根本就不是 (A) 写的那个 1,而是别人后来写的 2。按字面定义,(C) 没有"读到 (A) 的值",同步关系似乎就断了。
// 这就是 release sequence 要解决的问题。Release Sequence 的定义:
一个 release 操作 (A) 后面,在同一个原子变量上,后续满足以下条件的写操作组成一个序列,叫做 (A) 的 release sequence:
- 同一线程 的任意写操作,或
- 任意线程 的读-改-写 (RMW)操作(如
fetch_add、exchange、compare_exchange)
关键规则 :只要 acquire load © 读到的值是这个 release sequence 中任何一个 操作写入的,(A) 就 synchronizes-with ©。
注意这条线很"脆":一旦中间夹了一个别的线程的普通 store (非 RMW),release sequence 就断了,后面再读到的值就不再与 (A) 同步。
回到例子:
cpp
// 线程1 (producer)
shared_data = 42;
count.store(1, release); // (A)
// 线程2 (relay)
count.fetch_add(1, relaxed); // (B) RMW,即使是 relaxed!
// 线程3 (consumer)
while (count.load(acquire) < 2) {} // (C) 最终读到 2
assert(shared_data == 42); // 成立执行顺序大致是:
- (A) 把
count写成 1,并把shared_data = 42"发布"出去 - (B) 是 RMW,把 1 改成 2。因为它是 RMW,它加入了 (A) 的 release sequence
- © 读到 2,这个 2 是 release sequence 中的成员((B))写入的
- 因此 (A) synchronizes-with ©,(A) 之前的
shared_data = 42对 © 可见
有意思的点 :(B) 自己用的是 relaxed,看起来什么同步都不提供。但因为它是 RMW,它"接力"延续了 (A) 建立的发布关系。consumer 即使没读到 (A) 直接写的 1,而是读到 (B) 写的 2,依然能看到 shared_data = 42。
如果(B)不是RMW会怎么样?
cpp
// 线程2 改成普通 store
count.store(2, relaxed); // (B') 不是 RMW这时 (B') 是另一个线程的普通 store,会切断 release sequence。consumer 读到 2 时,这个 2 来自 (B'),而 (B') 不在 (A) 的 release sequence 里,所以 (A) 不 synchronizes-with ©,shared_data == 42 就不再保证 。
consumer 可能读到 count == 2,却看到 shared_data 还是 0。
为什么这条规则存在?
最常见的实战场景是引用计数 和多消费者通知。比如:
cpp
#include <atomic>
#include <iostream>
struct Resource {
int data = 0;
};
Resource* ptr = new Resource();
std::atomic<int> ref_count{3}; // 假设3个线程共享
// ============ 线程A ============
void thread_a() {
ptr->data = 42; // 修改资源
// release 封印:ptr->data = 42 不会跑到 fetch_sub 后面
ref_count.fetch_sub(1, std::memory_order_acq_rel);
}
// ============ 线程B ============
void thread_b() {
ptr->data = 100; // 修改资源
// release 封印:ptr->data = 100 不会跑到 fetch_sub 后面
ref_count.fetch_sub(1, std::memory_order_acq_rel);
}
// ============ 线程C(最后一个)============
void thread_c() {
if (ref_count.fetch_sub(1, std::memory_order_acq_rel) == 1) {
// acquire 封印:通过 release sequence
// 线程A 和 线程B 的 ptr->data 写入,此处均可见
std::cout << ptr->data; // ✅ 安全
delete ptr;
}
}
// 为什么这里用 acq_rel 而不是 relaxed?
// fetch_sub----relaxedrelease sequence ✅ 但最后一次 fetch_sub 看不到之前所有线程的写入(也就是说delete ptr可能会重排到refcount.fetch_sub(1, acq_rel) == 1前面)
// fetch_sub acq_relrelease sequence ✅ 且 最后一次操作 acquire 到所有之前的修改
// 如果改成relaxed会发生什么?
// ============ 线程A ============
void thread_a() {
ptr->data = 42;
ref_count.fetch_sub(1, std::memory_order_relaxed); // ← 无 release
// ptr->data = 42 这个写入,没有被"封印"在 fetch_sub 之前
// 对其他线程而言,这个写入何时可见,没有任何保证
}
// ============ 线程C(最后一个)============
void thread_c() {
if (ref_count.fetch_sub(1, std::memory_order_relaxed) == 1) {
// ← 无 acquire,没有桥接到线程A/B 的 release
// ref_count 减到0了,但线程A/B 对 ptr->data 的修改
// 有没有同步过来?完全不知道
std::cout << ptr->data; // ❌ 可能读到旧值甚至撕裂的值
delete ptr;
}
}每个 fetch_sub 都是 RMW,它们形成一条 release sequence 链。最后那个把计数减到 0 的线程,通过 release sequence 能看到此前所有线程对对象的修改------即使中间的 fetch_sub 用了较弱的内存序。这正是 std::shared_ptr 析构能正确工作的理论基础之一。
另一个场景:信号量 / 计数型门闩 。多个生产者各自 fetch_add 一个计数,消费者等待计数达到某个阈值。生产者们的修改通过 release sequence 串起来,消费者一次 acquire 就能看到所有生产者的工作。
总结:Release sequence 让 RMW 操作变成"接力棒",可以在不破坏同步关系的前提下,让多个线程依次修改同一个原子变量;但普通的非-RMW store 会"打断接力",同步关系就此终止。
记住RMW 续链,普通 store 断链 。以后看 shared_ptr、无锁队列、计数门闩这类代码里为什么大量用 fetch_add/fetch_sub 而不是 store,就会更有体感了。
cpp
#include <atomic>
#include <thread>
#include <vector>
std::atomic<int> count{0};
int shared_data = 0;
void producer() {
shared_data = 42;
count.store(1, std::memory_order_release); // (A) release store
}
void relay() {
// fetch_add 是 RMW 操作,它读取了 count 的值
// 即使使用 relaxed,它仍然是 (A) 的 release sequence 的一部分
int c = count.fetch_add(1, std::memory_order_relaxed); // (B)
// 因为 (B) 原子地读取-修改了 count,
// 它延续了 (A) 建立的 release sequence
}
void consumer() {
while (count.load(std::memory_order_acquire) < 2) {} // (C)
// (C) 读到的值(>= 2)是 release sequence {(A), (B)} 产生的
// 所以 (A) synchronizes-with (C)
// 因此 shared_data = 42 对这里可见!
assert(shared_data == 42); // ✅ 即使 (B) 用了 relaxed
}
// 如果 (B) 不是 RMW 而是单独的 store,就打破了 release sequence,
// consumer 就不能保证看到 shared_data = 429.std::atomic_thread_fence:独立内存屏障
除了在 std::atomic 的 load/store 操作上指定 memory order 之外,C++ 还提供了独立的内存屏障 函数 std::atomic_thread_fence。它不绑定在任何具体的原子变量的 load/store 上 ,而是在代码中单独设立一道"栅栏" 。用来约束其前后内存操作的重排序和可见性。
在 std::atomic 的 load/store 上直接指定 memory_order(例如 store(x, memory_order_release)),屏障是绑在那一个原子操作上的。但有时你希望:
- 用 relaxed 的原子操作(性能更好),同时只在某个关键点插一道屏障
- 让一道屏障同时保护多个原子变量的写入或读取
- 与非原子变量的读写配合使用
这时就需要 atomic_thread_fence。
9.1 基本用法
cpp
#include <atomic>
#include <thread>
int data = 0;
std::atomic<bool> flag{false};
void producer() {
data = 42;
// 方式一:在 store 操作上指定 release
// flag.store(true, std::memory_order_release);
// 方式二:使用独立的 release fence + relaxed store
// 效果与方式一等价,但更灵活
std::atomic_thread_fence(std::memory_order_release); // release 屏障
flag.store(true, std::memory_order_relaxed); // relaxed store
// release fence 保证:fence 之前的所有读写操作
// 都在 fence 之后的任何原子 store 之前完成
}
void consumer() {
// 方式一:在 load 操作上指定 acquire
// while (!flag.load(std::memory_order_acquire)) {}
// 方式二:使用 relaxed load + 独立的 acquire fence
while (!flag.load(std::memory_order_relaxed)) {}
std::atomic_thread_fence(std::memory_order_acquire); // acquire 屏障
// acquire fence 保证:fence 之前的任何原子 load(读到了非初始值)
// 之后的所有读写操作都能看到对方 release 之前的写入
assert(data == 42); // ✅ 安全
}1、release fence 的语义是------fence 之前的所有读写操作 ,不能被重排到 fence 之后的任何 store (无论那些 store 是 relaxed 还是什么)之后。
所以:
data = 42和其他的写入 都被"按住"在 fence 之前- 之后的
flag.store还有其他的store即便是 relaxed,但它们一旦被其它线程观察到 true/1,那么 fence 之前的所有写入对那个线程就都可见了
2、acquire fence 的语义是------fence 之后的所有读写 ,不能被重排到 fence 之前的任何 load 之前。
配对规则:只要当前线程在 acquire fence 之前用 relaxed 读到了另一个线程在 release fence 之后写入的某个值,那么另一个线程在 release fence 之前的所有写入,都对当前线程在 acquire fence 之后的代码可见。
9.2 fence 的独特优势
fence 与 atomic 操作上的 memory order 有一个关键区别:fence 是"批量"屏障,它影响 fence 前后的所有内存操作;而 atomic 操作上的 memory order 只约束该特定操作。
cpp
#include <atomic>
std::atomic<int> a{0}, b{0}, c{0};
int x = 0, y = 0, z = 0;
void writer() {
x = 1;
y = 2;
z = 3;
// 一个 release fence 可以保护上面所有三个写入
// 比在每个原子操作上单独指定 release 更简洁
std::atomic_thread_fence(std::memory_order_release);
a.store(1, std::memory_order_relaxed);
b.store(1, std::memory_order_relaxed);
c.store(1, std::memory_order_relaxed);
// fence 保证 x, y, z 的写入在 a, b, c 的 store 之前完成
// 读者只要 acquire-读到 a/b/c 中任意一个为 1,就能安全读取 x, y, z
}
void reader() {
// 只要读到 a, b, c 中任意一个为 1
if (a.load(std::memory_order_relaxed) == 1 ||
b.load(std::memory_order_relaxed) == 1 ||
c.load(std::memory_order_relaxed) == 1) {
// 一个 acquire fence 就够了
std::atomic_thread_fence(std::memory_order_acquire);
// 安全读取所有非原子变量
assert(x == 1 && y == 2 && z == 3); // ✅
}
}fence 和atomic操作上 memory_order 的区别:
两者不完全等价,这是容易踩坑的地方:
| 绑在 store 上的 release | 独立 release fence | |
|---|---|---|
| 影响范围 | 只和这一次 store 形成同步关系 | 和 fence 之后任意一个 store 都能形成同步 |
| 灵活性 | 一对一 | 一对多 |
| 开销 | 通常更轻 | 通常更重(编译器更保守) |
一般来说,能用atomic操作上的 memory_order 就优先用atomic操作上的,fence 更重、也更难推理。只有当你确实需要"一道屏障管多个原子变量"时才用 fence。
9.3 seq_cst fence 的特殊语义
seq_cst fence 是最强的屏障,atomic_thread_fence(memory_order_seq_cst)做了三件事:
- 刷出 Store Buffer(等同 release fence 的效果)------本线程之前的写都推出去
- 清空 Invalidate Queue(等同 acquire fence 的效果)------让本线程能看到其它核心的新写入
- 参与 seq_cst 全局全序------所有 seq_cst fence 和 seq_cst 操作之间存在一个全局一致的顺序
第 3 条是关键:普通的 acquire/release fence 只提供"成对同步",而 seq_cst fence 参与全局全序,可以用来修复一些经典的 StoreLoad 重排问题(例如 Dekker 算法)。
硬件层面:
- x86 上:编译为
MFENCE指令(x86 本身内存模型较强,只有 StoreLoad 需要屏障) - ARM 上:编译为
DMB SY(Data Memory Barrier, Full System,最强的屏障)
例子:两个线程各自先"声明自己要进入",然后检查"对方有没有要进入":
cpp
std::atomic<bool> x{false}, y{false};
int r1, r2;
void thread1() {
x.store(true, std::memory_order_release); // (1) 我要进入
r1 = y.load(std::memory_order_acquire); // (2) 对方要进入吗?
}
void thread2() {
y.store(true, std::memory_order_release); // (3) 我要进入
r2 = x.load(std::memory_order_acquire); // (4) 对方要进入吗?
}期望 :至少有一个线程能看到对方的 true,即 r1 == true || r2 == true,不可能两个都是 false。
现实 :用 release/acquire 这个断言会失败! 可能出现 r1 == false && r2 == false。
为什么release/acquire不够?
因为release/acquire 只约束以下三种重排:
- LoadLoad、LoadStore(acquire 负责)
- StoreStore、LoadStore(release 负责)
但它们都不约束 StoreLoad 重排 !也就是说,x.store(true) 和 r1 = y.load() 在 CPU 看来完全可以交换顺序执行 ------因为现代 CPU 有 Store Buffer,store 先丢进 buffer 就算"完成",紧接着的 load 可以先走。
于是可能的执行顺序变成:
thread1: r1 = y.load() → 读到 false(此时 thread2 还没 store)
thread2: r2 = x.load() → 读到 false(此时 thread1 的 store 还在 Store Buffer 里)
thread1: x.store(true) → 现在才刷出去
thread2: y.store(true) → 现在才刷出去结果:r1 == false && r2 == false,两个线程都以为对方没来,同时进入临界区
修复:使用 seq_cst fence:
cpp
std::atomic<bool> x{false}, y{false};
int r1, r2;
void thread1() {
x.store(true, std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_seq_cst); // 🔑
r1 = y.load(std::memory_order_relaxed);
}
void thread2() {
y.store(true, std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_seq_cst); // 🔑
r2 = x.load(std::memory_order_relaxed);
}
// 保证:r1 和 r2 不会同时为 false为什么这样就对了?
seq_cst fence 会刷出 Store Buffer ,确保 fence 之前的 store 真正写到内存;同时所有 seq_cst fence 之间存在全局全序。
于是两个 fence 必有一个"先发生":
- 假设 thread1 的 fence 在 thread2 的 fence 之前 → thread1 的
x.store(true)一定已经对所有线程可见 → thread2 之后的r2 = x.load()必然读到 true - 反之亦然
所以 r1 == false && r2 == false 变得不可能。
其实也可以直接用 memory_order_seq_cst 标注原子操作:
cpp
void thread1() {
x.store(true, std::memory_order_seq_cst);
r1 = y.load(std::memory_order_seq_cst);
}
// memory_order_seq_cst 标注的原子操作本身就自带"full fence"效果,它不仅参与全局全序,还会强制刷空 Store Buffer。换句话说,seq_cst 的 store 和 seq_cst 的 load,天生就把 StoreLoad 重排禁掉了。
// 一个 seq_cst 的原子操作同时提供两件事:
// 第一层:包含 acquire + release 的效果
// seq_cst store 至少是 release store
// seq_cst load 至少是 acquire load
// 所以前三种重排(LoadLoad、LoadStore、StoreStore)都被禁
// 第二层:参与一个全局单一全序(Single Total Order, S)
// 所有线程里的所有 seq_cst 操作,存在一个所有线程都同意的统一顺序
// 这个全序和每个线程自己的 program order 是一致的(不矛盾)
// 为了实现"全局全序",硬件必须保证------一个 seq_cst store 完成之后,它对所有核心都已经可见,后续的 seq_cst load 才能执行。这就等于强制禁了 StoreLoad 重排。效果等价。那什么时候选 fence 版本?
- 当你有多个 relaxed 原子操作要共享一道全序屏障时,fence 更划算------只插一次,管一片
- 当你想在 非原子代码 和原子代码之间划一道全序线时
- 当算法里"需要全序"的点和"原子操作"的点不在同一行时
10. CAS 操作:无锁编程的基石
10.1 什么是 CAS?
CAS(Compare-And-Swap,比较并交换)是所有无锁(Lock-Free)数据结构和算法的核心原语 ,是一条硬件级别的原子指令 ,是并发编程中最核心的原子操作之一。
CAS是无锁编程的核心机制,它如同无锁编程的 "大脑",指挥着各个线程有序地访问共享资源 。CAS 算法包含三个参数:V(要更新的变量)、E(预期值)、N(新值) 。其工作原理是:当且仅当变量 V 的值等于预期值 E 时,才会将变量 V 的值更新为新值 N;如果 V 的值和 E 的值不同,那就说明已经有其他线程对 V 进行了更新,当前线程则什么都不做,最后 CAS 返回当前 V 的真实值 。
在一个多线程的计数器场景中,假设有多个线程都要对计数器count进行加 1 操作 。每个线程在执行加 1 操作时,会先读取count的当前值作为预期值 E,然后计算新值 N(即 E + 1),接着使用 CAS 算法尝试将count的值更新为 N 。如果此时count的值仍然等于预期值 E,说明在读取和尝试更新的过程中没有其他线程修改过count,那么更新操作就会成功;反之,如果count的值已经被其他线程修改,不等于预期值 E,更新操作就会失败,线程会重新读取count的当前值,再次尝试 。通过这种不断比较和交换的方式,CAS 算法实现了无锁同步,避免了传统锁机制带来的线程阻塞和性能开销 。
cpp
// CAS操作就是原子地执行以下操作(整个过程不可被中断):
// *addr--当前值;expected--期望值;desired--新值
bool CAS(addr, expected, desired) {
// 以下整体是原子的,不可被中断
if (*addr == expected) { // if(当前值==期望值)
*addr = desired; // 成功:将变量更新为新值
return true;
} else { // else if(当前值 != 期望值)
expected = *addr; // 失败:顺便把当前值带回来
return false; // (这样下次重试时可以用最新值)
}
}
// 关键要点:上面整个 if-else 是一个不可分割的原子操作,不会被其他线程打断。这是无锁编程的根基。
// 含义是:"我认为这个位置当前的值是 expected,如果确实如此,就把它改成 desired;否则什么都不做,并告诉我实际值是多少。"
// 例如:使用atomic类型的compare_exchange_weak接口来实现cas原子操作
#include <iostream>
#include <thread>
#include <atomic>
#include <mutex>
#include <vector>
#include <chrono>
std::atomic<int> count = 0;
void thread1()
{
int cnt = 10000;
while(cnt--)
{
int old_value = count.load(std::memory_order_relaxed);
int new_value;
do
{
new_value = old_value + 1;
} while (!count.compare_exchange_weak(old_value, new_value));
}
}
int main()
{
// 计时
auto start_time = std::chrono::system_clock::now();
std::vector<std::thread> theads(1000);
for(int i = 0; i < 1000; i++)
{
theads[i] = std::thread(thread1);
}
for(int i = 0; i < 1000; i++)
{
theads[i].join();
}
std::cout << "count = " << count << std::endl;
auto end_time = std::chrono::system_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end_time - start_time).count();
std::cout << "duration = " << duration << " microseconds" << std::endl;
return 0;
}原理:CAS 依赖 CPU 提供的原子指令实现,例如 x86 上的 CMPXCHG,ARM 上的 LDREX/STREX(LL/SC)。这些指令通过锁定缓存行(cache line locking) 或总线锁来保证操作的原子性,整个"比较 + 交换"在硬件层面不可分割。
CAS 在不同硬件上的实现
x86 :使用
CMPXCHG指令(带LOCK前缀),直接在硬件层面实现原子的比较-交换。ARM/RISC-V:使用 LL/SC(Load-Linked / Store-Conditional)指令对:
LDXR(Load-Exclusive):读取值并在 CPU 内部设置一个"独占监视器"STXR(Store-Exclusive):尝试写入值,只有在独占监视器没有被清除时才成功- 如果在 LDXR 和 STXR 之间,任何核心访问了同一缓存行(甚至是中断),STXR 会失败
LL/SC 的一个副作用是 "spurious failure"(伪失败)------这就是
compare_exchange_weak存在的原因。
10.2 C/C++中实现CAS操作的接口
1、C11标准:<stdatomic.h>:
cpp
// C11 提供了标准的原子操作接口:
#include <stdatomic.h>
atomic_int val = 0;
int expected = 0;
// 强版本:失败时一定是值不相等
atomic_compare_exchange_strong(&val, &expected, 10);
// 弱版本:可能伪失败,但在循环中性能更好
atomic_compare_exchange_weak(&val, &expected, 10);
// 函数原型
_Bool atomic_compare_exchange_weak(volatile A *object,
C *expected, C desired);
_Bool atomic_compare_exchange_strong(volatile A *object,
C *expected, C desired);
_Bool atomic_compare_exchange_weak_explicit(volatile A *object,
C *expected, C desired,
memory_order succ,
memory_order fail);
_Bool atomic_compare_exchange_strong_explicit(volatile A *object,
C *expected, C desired,
memory_order succ,
memory_order fail);2、C++11标准:
cpp
// 1、std::atomic<T> 成员函数
// compare_exchange_weak - 成员函数(非 volatile)
bool compare_exchange_weak(T& expected, T desired,
std::memory_order success,
std::memory_order failure) noexcept;
bool compare_exchange_weak(T& expected, T desired,
std::memory_order order = std::memory_order_seq_cst) noexcept;
// compare_exchange_strong - 成员函数(非 volatile)
bool compare_exchange_strong(T& expected, T desired,
std::memory_order success,
std::memory_order failure) noexcept;
bool compare_exchange_strong(T& expected, T desired,
std::memory_order order = std::memory_order_seq_cst) noexcept;3、GCC/Clang内建函数
c
// 1、老式接口(__sync_* 系列),全序屏障(Full Memory Barrier):
__sync_bool_compare_and_swap(&val, oldval, newval); // 返回 bool
__sync_val_compare_and_swap(&val, oldval, newval); // 返回旧值
// 2、新式接口(__atomic_* 系列),可指定内存序:
__atomic_compare_exchange_n(&val, &expected, newval,
0, // weak: 0=strong, 1=weak
__ATOMIC_SEQ_CST,
__ATOMIC_SEQ_CST);
// 接口内存序可选值:
__ATOMIC_RELAXED // 无屏障,最轻量
__ATOMIC_ACQUIRE // 加锁级别
__ATOMIC_RELEASE // 解锁级别
__ATOMIC_ACQ_REL // acquire + release
__ATOMIC_SEQ_CST // 最强,和 __sync 一样10.3 compare_exchange_weak vs compare_exchange_strong
cpp
#include <atomic>
std::atomic<int> value{0};
void demo_cas() {
int expected = 0;
int desired = 42;
// ========== strong 版本 ==========
// 只有在 value 确实不等于 expected 时才返回 false
// 在 x86 上:编译为 LOCK CMPXCHG(一条指令,不会伪失败)
// 在 ARM 上:编译为 LDXR + CMP + STXR + 失败时重试的循环
// (编译器自动加了重试循环来消除伪失败)
bool success = value.compare_exchange_strong(expected, desired);
// ========== weak 版本 ==========
// 即使 value == expected,也可能返回 false("伪失败")
// 在 x86 上:和 strong 完全相同(x86 的 CMPXCHG 不会伪失败)
// 在 ARM 上:编译为 LDXR + STXR(不加重试循环)
// STXR 可能因为缓存行被其他核心触碰而失败
expected = 0;
success = value.compare_exchange_weak(expected, desired);
}为什么存在 weak 版本?
cpp
#include <atomic>
std::atomic<int> value{0};
// ✅ 典型的 CAS 循环模式(推荐 weak)
// 因为循环本身就是重试机制,weak 的伪失败只是多循环一次
// 而 weak 在 ARM 上省去了 strong 内部的重试循环,性能更好
void atomic_multiply_by_2() {
int expected = value.load(std::memory_order_relaxed);
// 持续尝试直到成功
while (!value.compare_exchange_weak(
expected, // 期望值(失败时自动更新为最新值)
expected * 2, // 新值(基于最新的 expected 计算)
std::memory_order_release, // 成功时的内存序
std::memory_order_relaxed // 失败时的内存序(只需要更新 expected)
)) {
// CAS 失败(两种可能):
// 1. 真失败:其他线程修改了 value,expected 被更新为最新值
// 2. 伪失败(仅 ARM):expected 被更新为最新值(可能没变)
// 无论哪种情况,下次循环都用新的 expected 重新计算 desired
// 注意:desired (expected * 2) 会在循环条件中用新的 expected 重新计算
}
}
// ❌ 不需要循环的场景,应该用 strong
// 因为 weak 可能伪失败,而我们只想试一次
void try_claim_once() {
int expected = 0;
// 只尝试一次:如果 value 当前是 0 就设为 1,否则放弃
if (value.compare_exchange_strong(expected, 1)) {
// 成功:value 原来是 0,现在变成 1
} else {
// 失败:value 不是 0,expected 已更新为 value 的当前值
// 不重试,直接放弃
}
}10.4 用 CAS 实现各种无锁操作
无锁的 fetch_max (标准库没有提供 fetch_max,需要自己实现):
cpp
#include <atomic>
#include <algorithm>
// 原子地将 target 更新为 max(target, value),返回旧值
// 这是一个经典的 CAS 循环模式
template<typename T>
T atomic_fetch_max(std::atomic<T>& target, T value,
std::memory_order order = std::memory_order_seq_cst) {
// 第一步:读取当前值
T current = target.load(std::memory_order_relaxed);
// 如果 current >= value,无需更新,直接返回
// 否则,用 CAS 循环尝试更新
while (current < value) {
// 尝试:如果 target 仍然等于 current,则将其更新为 value
if (target.compare_exchange_weak(
current, // expected(失败时被更新为最新值)
value, // desired
order, // 成功时的内存序
std::memory_order_relaxed // 失败时的内存序
)) {
return current; // CAS 成功,返回旧值
}
// CAS 失败:current 已被自动更新为 target 的最新值
// 检查条件:如果新的 current >= value,循环自然退出
}
return current; // current >= value,无需更新,返回当前值
}
// 类似地,可以实现 atomic_fetch_min
template<typename T>
T atomic_fetch_min(std::atomic<T>& target, T value,
std::memory_order order = std::memory_order_seq_cst) {
T current = target.load(std::memory_order_relaxed);
while (current > value) {
if (target.compare_exchange_weak(current, value, order,
std::memory_order_relaxed)) {
return current;
}
}
return current;
}无锁的"仅设置一次"标志:
cpp
#include <atomic>
class OnceFlag {
std::atomic<bool> flag_{false};
public:
// 尝试设置标志位。如果是第一个调用的线程,返回 true
// 所有后续调用都返回 false
// 线程安全,无锁
bool try_set() {
bool expected = false;
// CAS:如果 flag_ 是 false,将其设为 true
// 使用 strong 因为不需要循环重试
return flag_.compare_exchange_strong(
expected, true,
std::memory_order_acq_rel, // 成功时:需要 acquire(读到之前的状态)
// 和 release(发布设置完成的事实)
std::memory_order_acquire // 失败时:只需要 acquire(知道已经被设置了)
);
}
bool is_set() const {
return flag_.load(std::memory_order_acquire);
}
};11. 退避策略(Backoff):减少 CAS 争用
在高竞争场景下,多个线程同时执行 CAS 循环会导致大量失败重试 。退避策略通过让失败的线程等待一小段时间来减少争用。
为什么要有退避策略?这就涉及到纯CAS循环的问题 -- 争抢同一缓存行
假设有多个线程拼命对同一个 shared_int 做 CAS。在硬件层面发生的事情是:
- 线程 A 把
shared_int所在的缓存行以独占(Modified)状态拉到自己的 L1 cache,让其他线程所在的核心的缓存行副本失效 - 线程 B 也要 CAS,必须把这个缓存行从 A 那里"抢"过来------通过 MESI 协议发送 Invalidate 消息,让 A 的副本失效
- A 的下一次 CAS 又得把缓存行抢回来
- ......循环往复
这就是所谓的 cache line ping-pong(缓存行乒乓) 。多个核心在缓存一致性总线上疯狂拉扯同一个缓存行,绝大部分时间不是在做有用功,而是在等缓存行迁移。
11.1 指数退避(Exponential Backoff)
为什么要"指数"退避?
先想一个朴素的问题:CAS 失败后等多久再重试?
- 等太短:缓存行还没"冷却",立刻又冲上去抢,等于没退避。
- 等太长:万一竞争已经消失,自己却还在傻等,白白浪费延迟。
- 固定时长:在低竞争时太慢,在高竞争时又不够。
指数退避的核心思想是自适应 :我不知道当前竞争有多激烈,那就先试探性地等一小会儿 ,如果还失败说明竞争确实激烈,那就等更久;每次失败都把等待时间翻倍,直到达到上限。这样:
- 低竞争场景下,第一次重试就成功,几乎没有额外延迟
- 高竞争场景下,等待时间快速增长到一个能让局面"散开"的级别
- 自动适应不同的负载强度,无需手动调参
这个思想最早来自 1970 年代的 以太网 CSMA/CD 协议(多台机器共享一根线缆,冲突后用指数退避避免反复碰撞),后来被广泛用在 TCP 重传、HTTP 重试、分布式锁、无锁数据结构等所有"多方争抢一个资源"的场景。
为什么还需要加上随机干扰?
下面代码有个非常重要的细节 :等待时间不是直接用 current_delay_,而是从 [0, current_delay_) 里随机取一个值 。这叫 随机化退避(randomized backoff) 或者 jitter(抖动) 。
为什么要随机?想象 10 个线程同时 CAS 失败,如果它们都精确地等 16 次 pause,那 16 次 pause 之后它们又会同时冲上来 ------惊群问题原封不动地在退避之后复现了。加入随机后,10 个线程的等待时间散布在 0~15 之间,重新进入战场的时刻被打散了 ,自然就不会再撞在一起。
这是指数退避能真正生效的关键。没有 jitter 的指数退避等于没退避 ------这条规则在分布式系统里也成立,AWS 官方甚至专门写过一篇文章叫 "Exponential Backoff and Jitter" 强调这一点。
cpp
// 指数退避策略
// 思想:每次 CAS 失败后,等待时间翻倍(加上随机扰动)
// 避免多个线程同时重试导致的 "雷鸣群" 问题
class ExponentialBackoff
{
// 最小退避时间(以 PAUSE 指令循环次数为单位)
static constexpr int MIN_DELAY = 1;
// 最大退避时间上限(防止等太久)
static constexpr int MAX_DELAY = 1024;
int current_delay_ = MIN_DELAY;
public:
// 执行一次退避等待
void backoff()
{
// 在 [0, current_delay_) 范围内随机等待
// 使用线程局部的随机数生成器,避免全局争用
// 这为什么要用线程局部存储?使用static会线程竞争,使用普通变量会进入backoff函数反复创建;使用thread_local在线程内只会创建一次,且只有单个线程可见。
thread_local std::mt19937 rng(std::hash<std::thread::id>{}(std::this_thread::get_id()));
std::uniform_int_distribution<int> dist(0, current_delay_ - 1);
int delay = dist(rng);
// 执行 delay 次 PAUSE 指令
for (int i = 0; i < delay; ++i)
{
#if defined(__x86_64__)
__builtin_ia32_pause();
#elif defined(__aarch64__)
asm volatile("yield");
#else
// 其他平台的退避:短暂让出 CPU
std::this_thread::yield();
#endif
}
// 指数增长退避时间,但不超过上限
current_delay_ = std::min(current_delay_ * 2, MAX_DELAY);
}
// 重置退避时间(CAS 成功后调用)
void reset()
{
current_delay_ = MIN_DELAY;
}
};
// ==================== 使用退避的 CAS 循环 ====================
std::atomic<int> shared_value{0};
void cas_with_backoff(int cnt)
{
ExponentialBackoff backoff;
while (cnt--)
{
int expected = shared_value.load(std::memory_order_relaxed);
while (!shared_value.compare_exchange_weak(expected, expected + 1, std::memory_order_release, std::memory_order_relaxed))
{
backoff.backoff(); // CAS 失败,执行退避等待
}
backoff.reset(); // CAS 成功,重置退避时间
}
}
int main()
{
auto start_time = std::chrono::system_clock::now();
std::vector<std::thread> threads;
for (int i = 0; i < 10; i++)
{
threads.emplace_back(cas_with_backoff,10000);
}
for (auto &e : threads)
{
e.join();
}
std::cout << "shared_value = " << shared_value << std::endl;
auto end_time = std::chrono::system_clock::now();
std::cout << "duration = " << std::chrono::duration_cast<std::chrono::nanoseconds>(end_time - start_time).count() << " nanoseconds" << std::endl;
return 0;
}PAUSE 指令:CPU 友好的"原地等待":
cpp
#if defined(__x86_64__)
__builtin_ia32_pause();
#elif defined(__aarch64__)
asm volatile("yield");
#endif这部分的精髓是:等待方式很关键。对比几种等法:
| 等法 | 代价 | 副作用 |
|---|---|---|
空循环 for(...) |
CPU 烧满 | 流水线推测执行可能导致内存订单冲突;超线程的另一个逻辑核被饿死 |
pause 指令 |
几乎为零 | 提示 CPU "我在自旋等待",CPU 会减缓推测执行 、让出共享资源给同核的另一个超线程 、避免内存订单违规导致的流水线清空 |
std::this_thread::yield() |
一次系统调用 | 主动让出时间片,开销大但适合较长等待 |
sleep |
上下文切换 | 开销最大,至少几十微秒 |
pause 是为自旋等待专门设计 的指令。它告诉 CPU:"接下来这点时间我在原地打转,你不用拼命预测分支、不用预取数据、不用为我准备资源,把流水线和共享缓存让给同核的另一个 SMT 线程吧。" 在 Intel 较新的微架构上,一条 pause 大约消耗 10~100 个时钟周期,但功耗极低,且对系统几乎无害。
ARM64 的 yield 指令语义类似,是给 CPU 的提示而非操作系统层面的 yield。注意它和 std::this_thread::yield() 完全不是一回事------前者是硬件指令、纳秒级;后者是系统调用、微秒级。
ExponentialBackoff 的本质是:用尽可能小的代价告诉 CPU "这场争抢我先退一步",并且退的时间根据失败次数自适应、加上随机扰动避免线程同步、再用 pause 指令让等待本身几乎免费。它把惊群问题里"散开撤退"的思想,浓缩进了一个十几行的小工具类,是无锁编程里的标准件。
11.2 适应性退避(AdaptiveBackoff )
指数退避解决的是"等多久"的问题,而适应性退避解决的是一个更本质的问题:等待方式本身也应该随着竞争持续时间而变化。
它的哲学是:
短期竞争用便宜的等法,长期竞争用贵但更让位的等法。
因为不同的等待手段有完全不同的开销和效果,用错就会适得其反。这个类把等待分成三个阶段,每个阶段对应一种等待机制:
| 阶段 | 触发条件 | 等待方式 | 单次开销 | 适合场景 |
|---|---|---|---|---|
| 1. 自旋 | spin_count < 16 | pause 指令 |
~10 ns | 资源马上就会释放 |
| 2. yield | 16 ≤ spin_count < 32 | this_thread::yield() |
~1 μs | 资源可能被同优先级线程持有 |
| 3. sleep | spin_count ≥ 32 | sleep_for(1μs) |
几~几十 μs | 资源被长时间持有 |
三个阶段的开销差三个数量级,所以从便宜到贵依次尝试才是合理的。
为什么需要分阶段?每种等法的本质区别:
阶段 1:pause ------ 硬件级自旋 :
__builtin_ia32_pause() 对应 x86 的 PAUSE 指令。我们之前讲过,它告诉 CPU"我在自旋等待",让 CPU:
- 放慢推测执行,避免流水线冲刷
- 让出资源给同核的另一个超线程
- 几乎不消耗功耗
关键特性 :线程完全不离开 CPU ,没有任何调度开销。一次 pause 只有纳秒级代价。
适用场景:资源马上就能拿到。比如另一个线程正在做一个很短的 CAS,你等几十纳秒它就完成了。这时候让出 CPU 反而得不偿失------光是一次上下文切换的开销(几微秒)就比整个等待时间都长。
阶段 2:yield ------ 用户态让步 :
std::this_thread::yield() 是向操作系统请求:"我当前没什么紧急的事,如果有同优先级 的其他线程在等 CPU,让它先跑"。
关键特性:
- 会触发一次系统调用和可能的上下文切换(约 1 μs 量级)
- 如果没有其他线程在等,操作系统可能立刻让当前线程继续运行
- 只让步给同优先级或更高优先级的线程,低优先级的仍然抢不到
适用场景:资源可能被同优先级的另一个线程持有,而我所在的核心可能就是它想跑的核心。自旋一阵没结果,说明光靠 CPU 级的礼让不够了,可能是某个就绪的线程根本没拿到 CPU。这时候主动 yield 一下,操作系统可能把 CPU 切给持有资源的那个线程,让它尽快完成、释放资源。
阶段 3:sleep ------ 深度让出:
sleep_for(1μs) 把线程真正挂起 一段时间(虽然是 1 微秒这种极短时间,但语义上进入了睡眠队列)。
关键特性:
- 必然触发上下文切换
- 让出 CPU 给任何线程,包括低优先级线程
- 实际睡眠时间通常会比参数更长(受调度器时间片精度影响,可能是几十微秒)
适用场景:资源被长时间持有 ,比如持有锁的线程正在做磁盘 IO、被换出、或者干脆被内核调度走了。自旋和 yield 都试过了还不行,说明问题不是"CPU 资源分配"而是"持有者短期内根本不会释放"。这种情况继续占着 CPU 毫无意义,主动睡一小会儿让整个系统的调度更健康------甚至可以让低优先级线程(可能正好是那个持锁线程)拿到时间片往前推进。
阶段二和阶段三的区别:线程进入了哪个队列
操作系统调度器管理着几个线程队列(简化模型):
- 运行队列(runqueue):就绪的、等着被调度上 CPU 的线程
- 等待队列(wait queue)/ 睡眠队列:因为某种原因暂时不需要 CPU 的线程
两者的根本区别:
| yield | sleep | |
|---|---|---|
| 线程进入哪里 | 仍在运行队列 | 离开运行队列,进入等待队列 |
| 线程状态 | 仍是 RUNNABLE | 变成 SLEEPING / INTERRUPTIBLE |
| 何时能再跑 | 立刻就有资格被调度 | 定时器到期前不会被考虑 |
yield 的语义是"我不介意让别人先跑,但我随时准备继续" ------线程仍然是"就绪"状态,调度器会立刻进行一次重新调度决策。如果运行队列里没有其他就绪线程,或者只有优先级更低的线程,调度器会立即把 CPU 还给你 ,yield 几乎等于没调用。
sleep 的语义是"我接下来这段时间不需要 CPU,别来找我" ------线程被主动从运行队列摘除 ,挂到定时器等待队列上。即使 CPU 完全空闲、一个竞争者都没有,线程也不会被调度,必须等定时器超时把它重新放回运行队列。
cpp
// 更智能的退避:根据连续失败次数动态调整策略
class AdaptiveBackoff {
int spin_count_ = 0;
static constexpr int SPIN_THRESHOLD = 16; // 自旋阈值
static constexpr int YIELD_THRESHOLD = 32; // yield 阈值
// 为什么阈值是16和32?
// SPIN_THRESHOLD = 16:意味着自旋最多 16 次。每次自旋的 pause 数量是 spin_count_ 次(递增),所以累计 pause 次数是 1+2+...+16 = 136 次。在 x86 上一次 pause 约几十到 100 纳秒,总共大约 5~15 微秒的纯自旋时间。如果这段时间内问题还没解决,说明不是"马上能拿到"的短期竞争。
// YIELD_THRESHOLD = 32:再给 16 次 yield 的机会(16~31),大约对应 16 微秒级别的让步尝试。如果 yield 也救不了,说明问题不是调度层面的"同优先级抢 CPU",而是更严重的阻塞。
public:
void backoff() {
++spin_count_;
if (spin_count_ < SPIN_THRESHOLD) {
// 阶段 1:纯自旋(适合锁很快释放的场景)
for (int i = 0; i < spin_count_; ++i) {
#if defined(__x86_64__)
__builtin_ia32_pause();
#endif
}
} else if (spin_count_ < YIELD_THRESHOLD) {
// 阶段 2:yield(让出 CPU 时间片给同优先级线程)
std::this_thread::yield();
} else {
// 阶段 3:sleep(让出 CPU 给任何线程,包括低优先级线程)
// 适合锁被长时间持有的场景
std::this_thread::sleep_for(std::chrono::microseconds(1));
}
}
void reset() { spin_count_ = 0; }
};这个设计的一个经典应用:Linux 内核的 mutex :
Linux 内核的 mutex 就是这个思路的著名实例------它被称为 "混合锁" (hybrid lock)或 "乐观自旋锁"(optimistic spinning):
- 先自旋一段时间,如果持有者正在别的 CPU 上运行,就等它几十纳秒可能就释放了
- 如果持有者已经被调度走了(不在 CPU 上),自旋就毫无意义,直接进入睡眠队列
Java 的 synchronized、.NET 的 Monitor、folly 的 MicroLock 都采用类似的分阶段策略。甚至 Intel 在 Haswell 引入的硬件事务内存(TSX)也有类似的"回退阶梯"。所以这不是一个学术玩具,而是工业界公认的最佳实践。
这种设计的一个副作用:延迟的双峰分布:
适应性退避有一个不完美之处 :它的延迟分布往往是双峰的。大部分请求在阶段 1 就完成(微秒级),少数请求进入阶段 3(几十微秒到毫秒级),中间部分反而很少。这在延迟敏感的系统里可能导致 P99 尾延迟显著高于 P50。
解决方法通常是:
- 调低 YIELD_THRESHOLD,尽早睡眠避免浪费
- 或者反过来调高 SPIN_THRESHOLD,让绝大多数请求都在自旋阶段完成
- 或者结合 futex 这样的内核机制,让睡眠后能被精确唤醒,避免盲目睡眠
这也是为什么真正的工业级实现往往比这个教学版本复杂得多------它们要在各种工作负载下都能保持稳定的尾延迟。
总结:AdaptiveBackoff 的本质是"用开销判断竞争性质、用竞争性质决定等待方式" 。它把"等"这个动作从单一的 pause 拓展成一个三级阶梯 :从纳秒级硬件提示,到微秒级调度让步,再到主动睡眠。每一级都比上一级更愿意"放弃 CPU",代价是更高的唤醒延迟。适应性退避通过观察自己的失败次数,在这三级之间自动切换,让同一套代码既能应对短暂争抢也能应对长期阻塞,避免了固定策略在不同场景下的水土不服。
结合之前讲的 ExponentialBackoff,退避策略的设计空间有两个维度------等多久 (指数 vs 线性 vs 固定)和怎么等(pause vs yield vs sleep)。不同场景下的最优解是这两个维度的不同组合,没有银弹,只有根据实际负载测量和调优。这也是为什么无锁编程被认为是"理论优雅、实践困难"的领域------正确性靠 CAS 就能保证,但性能要靠无数这样的微观决策堆出来。
11.3 指数退避和适应性退避的区别
| 维度 | ExponentialBackoff | AdaptiveBackoff |
|---|---|---|
| 增长方式 | 指数(×2) | 线性(+1) |
| 等待手段 | 单一:只用 pause | 多层:pause → yield → sleep |
| 随机抖动 | 有 | 无 |
| 假设的竞争模式 | 短期争抢,CPU 一直在跑 | 可能是短期自旋,也可能是长期阻塞 |
| 适合场景 | 轻量无锁数据结构(CAS 循环) | 通用自旋锁,或可能退化为长期等待的场景 |
一个核心区别 :ExponentialBackoff 假设竞争总会很快结束,所以始终让线程保持"运行中但等待"。AdaptiveBackoff 不做这个假设,而是通过失败次数判断竞争的性质:
- 竞争短 → 停留在阶段 1,开销极低
- 竞争中 → 进入阶段 2,开始参与调度
- 竞争长 → 进入阶段 3,彻底让出 CPU 节省能源
这种"自我诊断"让它在负载不可预测的环境中更稳健。
12. 非阻塞同步的实现级别:Wait-Free / Lock-Free / Obstruction-Free
多线程访问共享数据,会出现竞争。最直接的解决办法是加锁 :谁要改数据,先抢一把锁,改完再放。这就是 std::mutex、spinlock 这类东西。
锁简单好用,但有个根本性的毛病:它的正确性依赖于"持锁线程会及时释放锁"这个假设。一旦这个假设破了,整个系统就完蛋。什么时候会破?
- 持锁线程被操作系统调度走了,迟迟不被换回来------其他等锁的线程全部干等
- 持锁线程优先级低,被高优先级线程抢占------经典的"优先级反转"
- 持锁线程崩溃了------锁永远不会释放,系统死锁
- 持锁线程在持锁期间触发缺页中断、被换页到磁盘------其他线程跟着一起卡几十毫秒
注意一个关键点:这些故障都不是当前线程自己的错 ,而是被别的线程拖累的。这种"我能不能前进取决于别人"的性质,就叫阻塞(blocking)。
非阻塞同步(non-blocking synchronization)就是要摆脱这种依赖,让算法的进度不依赖于任何单个线程的行为 。但"不依赖"也分程度,于是就有了从强到弱的三个层级:Wait-Free → Lock-Free → Obstruction-Free,再加上垫底的 Blocking,一共四级。
12.1 四个层级,从弱到强
第 1 级:Blocking(阻塞)------锁:
代表:mutex、spinlock、semaphore。
进度保证:无 。任何一个持锁线程出问题,所有等锁的线程跟着出问题。整个系统的活性(liveness)被绑在了那一个线程的命运上。
这里要破除一个误区:spinlock 也是 blocking 的,虽然它不调用 OS 的 mutex,只是在用户态自旋。判断标准不是"有没有用 OS 的锁原语",而是"持有者挂掉后,其他线程会不会被卡住"。spinlock 的持有者被挂起后,其他线程会无限自旋下去,所以它依然是阻塞式的。
第 2 级:Obstruction-Free(无障碍)------最弱的非阻塞:
核心承诺 :如果让某个线程单独执行 (其他线程全部暂停),它一定能在有限步骤内完成。
注意这个承诺有多弱:它只在单线程独占的情况下 才保证进度。多个线程同时跑的时候,Obstruction-free 对这个完全不保证 ,它们可能互相干扰,谁都完不成,出现活锁(livelock)------A 和 B 同时开始一个事务,跑到一半发现冲突,都回滚;两人同时重试,又同时冲突,又同时回滚......CPU 烧得很热,但谁都没完成任何事。所有人都在动,所有人都在做无用功,系统整体没有进展。
但是现实中你不会真的去暂停别的线程。多个线程本来就是同时在跑的。
那这个承诺有什么用?它的真正含义是反过来读的:
如果一个算法连"单线程独占跑都跑不完"都做不到,那它一定是用了锁(或类似的阻塞机制)。
举个例子:如果 A 拿了一把 mutex 然后被挂起,B 来了想拿这把锁,即使 B 是"独占执行"(A 已经被挂起不动了),B 还是会卡死在等锁上,因为锁的所有者是 A,而 A 不会再醒来释放。这种情况下,B 单独跑也跑不完 ------所以 mutex 不是 obstruction-free。
反过来,obstruction-free 算法保证:不管之前发生过什么乱七八糟的事(其他线程跑到一半被挂起、状态看起来很混乱),只要现在让任何一个线程单独跑,它都能从当前状态出发,把自己的操作干完。没有任何"必须等别人"的依赖。
活锁 vs 死锁:死锁是大家都不动了(在等彼此),活锁是大家都在拼命动但都在白费力气。从外面看 CPU 跑满,从里面看一事无成。
为什么这也算"非阻塞"?因为单个线程被挂起不会影响其他线程 ------挂起一个线程,剩下的线程仍然可以正常推进(只是它们之间还可能互相干扰)。它满足"不依赖任何单个线程"的最低要求。
典型代表是某些软件事务内存(STM) :每个事务乐观地执行,提交时检测冲突,有冲突就回滚重来。如果两个事务总是同时启动、同时冲突、同时回滚、同时再启动......就活锁了。
实践中需要外挂一个**争用管理器(contention manager)**来打破对称------比如随机退避、或者强行暂停某些线程,让另一些先跑完。加上这个管理器后,它通常就能升级成 lock-free 的实际行为。
第 3 级:Lock-Free(无锁)------工业主流:
核心承诺 :在任何时刻,至少有一个 线程能在有限步骤 内取得进展。
把它和 obstruction-free 对比:obstruction-free 说"单独跑就能进展",lock-free 说"哪怕大家一起抢,也总有一个人能成功"。这就排除了活锁------系统作为一个整体,永远在前进。
但要注意措辞:"至少有一个 "线程在前进,意味着具体到某个倒霉蛋,它可能一直失败、一直重试 。这种现象叫饥饿(starvation)。系统在前进,但前进的可能永远不是你。
典型实现:CAS 循环 (Compare-And-Swap),也就是图里那段 lock_free_update:
cpp
void lock_free_update() {
int expected = lock_free_value.load(std::memory_order_relaxed);
while (!lock_free_value.compare_exchange_weak(
expected, expected * 2 + 1,
std::memory_order_release,
std::memory_order_relaxed
)) {
// CAS 失败,expected 已被自动更新为当前最新值,继续重试
}
}CAS 的语义是:"如果当前值还等于 expected,就把它换成新值,返回成功;否则把 expected 更新为当前值,返回失败"------这一切是一条原子指令。
为什么这个循环是 lock-free 的? 关键在于:每次 CAS 失败,一定意味着别的某个线程 CAS 成功了。因为你的 expected 之所以对不上,只能是别人改了它。所以"有人失败"等价于"有人成功"------系统总在前进。把这个推到极端:即使一个线程在 load 和 CAS 之间被永久挂起,其他线程毫不受影响,该读读、该 CAS CAS、该成功成功。
饥饿是怎么发生的? 想象 100 个线程都在跑这个循环。每次只有一个赢家,其他 99 个全部失败重来。理论上某个倒霉的线程可能每次都是失败的那一个 ,永远赢不了。系统整体进展飞快,但它一直在原地打转。
这就是 lock-free 的本质权衡:系统级保证 vs 线程级保证。它放弃了对单个线程的承诺,换来实现上的可行性和优秀的平均性能。
第 3 级:Wait-Free(无等待)------最强保证:
核心承诺 :每一个 线程都能在有限步骤内 完成操作,这个步数有一个预先可计算的上界 ,完全不依赖其他线程的行为。
和 lock-free 的差别就一个词:从"至少有一个"变成"每一个"。但这一个词的差距是巨大的------饥饿被彻底消除了。无论争用多激烈、有多少线程在抢、其他线程是不是被挂起,你的线程完成操作所需的步数都有一个固定的上界。
关键:"有限步骤"的严格含义 :这里的"有限"不是模糊的"早晚会完成",而是"我能写出一个具体的数字 N,保证不超过 N 步"。
对比 CAS 循环:while (!CAS) { 重试 } 这个循环可能转 1 次,可能转 100 次,可能转 10000 次------你写不出上界,因为它取决于运行时有多少争用。所以它不是 wait-free。
而 fetch_add 不一样:
cpp
std::atomic<int> wait_free_counter{0};
void wait_free_increment() {
wait_free_counter.fetch_add(1, std::memory_order_relaxed);
}在 x86 上,fetch_add 编译成一条 LOCK XADD 指令。就一条指令 。无论有 2 个还是 200 个线程同时在 fetch_add,每个线程自己执行的指令数永远是 1。线程之间会在硬件缓存一致性协议(MESI)层面排队,但每个线程自己看到的步数永远是常数。
这就是 wait-free 的精髓:最坏情况延迟可以被一个具体的数字封顶。
适用场景:硬实时系统 :
想象飞机的飞控:"读传感器 + 计算 + 输出舵面角度"必须在 1 毫秒内完成,每一次都不能超时 ,超一次就可能机毁人亡。
如果用 lock-free,你只能说"平均很快,通常 0.1 毫秒"。但万一某次特别倒霉,这个线程被挤了 50 次重试,花了 5 毫秒呢?平均值再好也救不了你 。硬实时需要的不是平均,是最坏情况上界------这正是 wait-free 提供的东西。
医疗设备(心脏起搏器)、航空电子、汽车防抱死系统,都是类似的场景。
代价:为什么 wait-free 不是处处适用?
直觉上"最强保证"听着应该最好,但现实是 wait-free 在工业界很罕见,原因有两条:
- 难以实现 。
fetch_add这种简单操作能由硬件直接做成 wait-free,是特例。对复杂数据结构(队列、链表、哈希表),要做到 wait-free 极其困难,通常需要引入帮助机制(helping mechanism)------每个线程在做自己的事之前,先扫描一下"公告板",看有没有其他线程的操作还没完成,有的话先帮人家做完,再做自己的。这样即使某个线程被无限延迟,别人也会替它完成,从而保证它的操作步数有上界。 - 平均性能往往不如 lock-free 。帮助机制意味着每个线程都要做额外的协调工作,即使没人需要被帮助也要做。结果就是:无争用时它有冗余开销,有争用时 lock-free 也很快(因为大部分线程一两次就成功了)。wait-free 多付出的开销,只在"必须封顶最坏情况"的场景才划得来。
12.2 判断一个算法是不是 lock-free 的实用方法
"如果某个线程在操作中途被永远挂起(操作系统再也不调度它了),其他线程是否仍然能完成自己的操作?"
- 答案 YES → 至少是 lock-free(可能是 wait-free)
- 答案 NO → 是 blocking
这个测试的精妙之处在于,它直接对应了"非阻塞"的定义------非阻塞就是"不依赖任何单个线程的进度"。
用 mutex 试: 一个线程拿到 mutex 后被挂起,其他等这把 mutex 的线程会被永久阻塞。答案 NO → blocking。✓
用 spinlock 试: 持有者被挂起,其他线程无限自旋,永远等不到锁。答案 NO → blocking。✓(尽管它没用 OS 锁原语)
用 CAS 循环试: 线程 A 在 load 和 CAS 之间被挂起。线程 B、C、D...... 继续读、CAS、成功,毫不受影响。答案 YES → lock-free。✓
用 fetch_add 试: 线程 A 在 fetch_add 之前被挂起。其他线程的 fetch_add 完全不受影响。答案 YES → 至少 lock-free(实际上是 wait-free)。✓
12.3 强弱关系与最常见的误区
层级是包含关系:
Wait-Free ⊂ Lock-Free ⊂ Obstruction-Free ⊂ Non-Blocking
一个 wait-free 算法自动也是 lock-free 的(每个线程都进展 → 至少有一个线程进展),lock-free 自动也是 obstruction-free 的。
最常见的误区 :把"没用 mutex"等同于"lock-free"。
不是的。判断标准是上面的挂起测试,不是看代码里有没有 lock() 这个词。一段代码可以完全没用 mutex,但仍然是 blocking 的(spinlock);也可以看起来很复杂,但其实是 lock-free 的(精心设计的 CAS 数据结构)。
12.4 怎么选?
不是"层级越高越好"。每升一级,实现复杂度和潜在陷阱都急剧增加(ABA 问题、内存回收、memory ordering、helping 机制......),日常性能可能反而下降。务实的选择是:
| 场景 | 推荐 | 理由 |
|---|---|---|
| 普通业务代码 | Mutex | 简单、正确、维护成本低。没有硬实时需求时,锁就是最好的工具。 |
| 高并发数据结构(队列、哈希表) | Lock-Free | 实现可控,平均性能好,工业界主流。 |
| 硬实时系统(飞控、起搏器) | Wait-Free | 唯一能给最坏情况延迟提供上界的方案。 |
| STM 等研究/特殊场景 | Obstruction-Free + 争用管理器 | 实现最简单,靠外部机制兜底活锁。 |
核心原则:选对层级,不要无脑追求最强。无锁编程的复杂度是真实的,大多数业务场景下,一把写得正确的 mutex 比一个写得有 bug 的 lock-free 队列要好得多。
12.5 代码示例
cpp
#include <atomic>
#include <thread>
// ==================== Wait-Free 示例 ====================
// fetch_add 在硬件支持的类型上是 wait-free 的:
// 每个线程的操作都在恒定时间内完成(一条 LOCK XADD 指令)
std::atomic<int> wait_free_counter{0};
void wait_free_increment() {
// 这条操作一定在常数时间内完成,不受其他线程影响
wait_free_counter.fetch_add(1, std::memory_order_relaxed);
}
// ==================== Lock-Free 示例 ====================
// CAS 循环是 lock-free 的:
// 虽然单个线程可能失败重试,但每次至少有一个线程成功
std::atomic<int> lock_free_value{0};
void lock_free_update() {
int expected = lock_free_value.load(std::memory_order_relaxed);
while (!lock_free_value.compare_exchange_weak(
expected, expected * 2 + 1,
std::memory_order_release,
std::memory_order_relaxed
)) {
// 我失败了,但这意味着某个其他线程成功了
// → 整体系统一定在进展
// 极端情况:某个"倒霉"的线程可能一直失败(饥饿)
}
}13. ABA 问题:CAS 的经典陷阱与解决方案
13.1 什么是 ABA 问题?
CAS 的语义是"如果当前值等于 expected,就更新"。但这里有个隐含的假设被悄悄偷换了:CAS 判断的是"值相等",而我们真正想判断的是"这个位置从我读完到现在没有被动过" 。
大多数时候这两者等价,但有一种情况它们会错开:值从 A 变成 B,又变回 A。从 CAS 的角度看,值还是 A,它高高兴兴地认为"没人动过",交换成功。但实际上中间发生了什么,CAS 完全不知道 。
这就是 ABA 问题。名字就是这么来的:A → B → A。
对简单的计数器,这不是问题------值是多少就是多少,中间经历了什么无所谓。但对指针来说,灾难就来了。
例子:无锁栈;用 CAS 实现一个无锁栈,pop 操作大致是这样:
cpp
struct Node { int value; Node* next; };
std::atomic<Node*> top;
void pop() {
Node* old_top;
Node* new_top;
do {
old_top = top.load(); // (1) 读出栈顶
if (!old_top) return;
new_top = old_top->next; // (2) 看栈顶的 next
} while (!top.compare_exchange_weak(old_top, new_top)); // (3) CAS
// 到这里 old_top 已经被弹出,可以释放
}逻辑看起来很清晰:读栈顶 → 看它的 next 是谁 → CAS 把栈顶换成 next。
灾难剧本 。初始栈是 A → B → C(top 指向 A)。
- 线程 T1 执行 pop,读到
old_top = A,读到new_top = B。然后------被操作系统调度走了,卡在这里。 - 线程 T2 连续操作:pop A(栈变成
B → C),pop B(栈变成C),然后 push A (把 A 节点重新放回栈顶)。现在栈是A → C------注意,这个 A 是同一个内存地址的节点,因为内存分配器很可能把刚释放的 A 复用了。 - T1 被唤醒 ,继续执行那条 CAS:期望
top == A,新值B。top 确实等于 A(地址一样),CAS 成功! - 结果:top 现在指向 B。但 B 早就被 T2 弹出并释放了。栈的链接指向一个已释放的内存,后续任何访问都是未定义行为。
问题的根源:T1 的 CAS 以为"值没变"等于"栈顶没动过",但其实栈顶经历了一整段复杂的变化,只是恰好又绕回了 A。old_top->next 这个 B,是 T1 当年看到的 B,跟现在这个 A 后面接的 C 完全没关系了。
为什么容易发生?因为内存复用 :
有人会想:"A 被释放了,再 malloc 怎么可能还是同一个地址?概率很低吧?"
恰恰相反,概率非常高 。
现代内存分配器(tcmalloc、jemalloc、glibc 的 ptmalloc)为了性能,都有线程本地缓存:释放的小对象先放进一个 freelist,下次同样大小的分配请求优先从这个 freelist 里拿。结果就是刚 free 掉的地址,往往是下一次 malloc 同样大小对象时最先拿到的 。在一个紧密循环里 push/pop 同一种节点,地址复用基本是必然的,不是概率事件。
所以 ABA 在无锁数据结构里不是理论上的边界问题,是实打实会触发的 bug。
13.2 解决方案一:Tagged Pointer(版本号标记)
最经典的办法:把指针和一个单调递增的版本号绑在一起,每次修改都让版本号 +1。CAS 比较的是"指针 + 版本号"这整个对,哪怕指针值绕回来了,版本号也回不去。
cpp
#include <atomic>
#include <cstdint>
// 方案一:利用指针高位存储版本号
// 在 x86_64 上,虚拟地址只用了 48 位(实际是 57 位,启用 5-level paging 时)
// 高 16 位可以存版本号(65536 个版本,足以避免 ABA)
template<typename T>
class TaggedPointer {
// 将指针和标签打包成一个 64 位整数
// 好处:可以用普通的 64 位 CAS(所有 x86_64 都支持)
std::atomic<uint64_t> data_{0};
// 位布局:[63:48] = tag (16 bits), [47:0] = pointer (48 bits)
static constexpr int TAG_BITS = 16;
static constexpr uint64_t PTR_MASK = (1ULL << 48) - 1; // 低 48 位
static constexpr uint64_t TAG_MASK = ~PTR_MASK; // 高 16 位
// 将指针和标签打包为一个 64 位值
static uint64_t pack(T* ptr, uint16_t tag) {
uint64_t p = reinterpret_cast<uint64_t>(ptr) & PTR_MASK; // 取低 48 位
uint64_t t = static_cast<uint64_t>(tag) << 48; // 标签左移到高 16 位
return p | t; // 合并
}
// 从打包值中提取指针
static T* get_ptr(uint64_t packed) {
uint64_t p = packed & PTR_MASK; // 取低 48 位
// 符号扩展:如果第 47 位是 1(内核地址空间),高位全填 1
// 在用户空间中通常不需要,但为了正确性保留
if (p & (1ULL << 47)) {
p |= TAG_MASK; // 符号扩展
}
return reinterpret_cast<T*>(p);
}
// 从打包值中提取标签
static uint16_t get_tag(uint64_t packed) {
return static_cast<uint16_t>(packed >> 48); // 右移 48 位
}
public:
TaggedPointer() = default;
TaggedPointer(T* ptr, uint16_t tag) : data_(pack(ptr, tag)) {}
// 获取当前的指针和标签
std::pair<T*, uint16_t> load(
std::memory_order order = std::memory_order_seq_cst) {
uint64_t d = data_.load(order);
return {get_ptr(d), get_tag(d)};
}
// CAS 操作:同时比较指针和标签
// 只有指针和标签都匹配时才更新
// 每次更新都递增标签,从而避免 ABA 问题
bool compare_exchange(T*& expected_ptr, uint16_t& expected_tag,
T* desired_ptr, uint16_t desired_tag,
std::memory_order success = std::memory_order_seq_cst,
std::memory_order failure = std::memory_order_seq_cst) {
uint64_t expected = pack(expected_ptr, expected_tag);
uint64_t desired = pack(desired_ptr, desired_tag);
bool ok = data_.compare_exchange_strong(expected, desired, success, failure);
if (!ok) {
// CAS 失败:将最新值解包后写回引用参数
expected_ptr = get_ptr(expected);
expected_tag = get_tag(expected);
}
return ok;
}
};
// ==================== 使用 TaggedPointer 的无锁栈 ====================
// 通过版本号避免 ABA 问题
template<typename T>
class ABAFreeStack {
struct Node {
T data;
Node* next;
};
TaggedPointer<Node> head_; // 带版本号的栈顶指针
public:
void push(const T& value) {
Node* new_node = new Node{value, nullptr};
auto [head, tag] = head_.load(std::memory_order_relaxed);
do {
new_node->next = head;
} while (!head_.compare_exchange(
head, tag, // 期望值(引用,失败时更新)
new_node, tag + 1, // 新值:新节点 + 版本号 +1
std::memory_order_release,
std::memory_order_relaxed
));
}
bool pop(T& result) {
auto [head, tag] = head_.load(std::memory_order_acquire);
while (head != nullptr) {
Node* next = head->next;
if (head_.compare_exchange(
head, tag, // 期望值
next, tag + 1, // 新值:版本号 +1
std::memory_order_acquire,
std::memory_order_relaxed
)) {
result = head->data;
delete head; // 注意:实际项目中需要延迟删除(hazard pointer / epoch)
return true;
}
// CAS 失败:head 和 tag 已被更新为最新值
}
return false; // 栈为空
}
};13.3 解决方案二:使用 128 位 CAS(Double-Width CAS)
实践上 x86-64 提供 CMPXCHG16B 指令支持 128 位原子比较交换,C++ 里用 std::atomic<TaggedPtr> 搭配对齐就能用
cpp
#include <atomic>
#include <cstdint>
// 方案二:使用 128 位的原子结构
// 编译时需要 -mcx16 标志(GCC/Clang)
// 好处:64 位版本号几乎不可能溢出(比 16 位安全得多)
struct StampedReference {
void* ptr; // 64 位指针
uint64_t stamp; // 64 位版本号(不会溢出)
};
static_assert(sizeof(StampedReference) == 16,
"StampedReference must be 16 bytes");
// 使用示例(概念性代码)
class LockFreeStackABA {
struct Node {
int data;
Node* next;
};
// 128 位原子变量
// 注意:需要用 is_lock_free() 检查是否支持
std::atomic<StampedReference> head_{StampedReference{nullptr, 0}};
public:
void push(int value) {
Node* new_node = new Node{value, nullptr};
auto current = head_.load(std::memory_order_relaxed);
do {
new_node->next = static_cast<Node*>(current.ptr);
} while (!head_.compare_exchange_weak(
current,
StampedReference{new_node, current.stamp + 1}, // 版本号 +1
std::memory_order_release,
std::memory_order_relaxed
));
}
};13.4 解决方案三:Hazard Pointers(风险指针)
换个思路:ABA 之所以致命,是因为节点被释放并复用了 。如果我们能保证"只要还有线程可能在引用这个节点,就不释放它",ABA 就威胁不到我们------因为 T2 根本没法 free 掉 A,更谈不上 A 被重新 push 回来。
Hazard Pointer 的做法:每个线程维护一个"我现在正在看的指针"列表(hazard pointers)。T1 读到 old_top = A 后,立刻把 A 登记到自己的 hazard 列表里。T2 想释放 A 之前,会扫描所有线程的 hazard 列表,如果发现还有人在看 A,就不真正 free,而是把 A 放进一个"待回收"队列,等所有 hazard 都不再指向它了再回收。
这就把"内存回收"和"CAS 正确性"解耦开了。代价是每个操作都有登记 hazard 的开销,释放路径也要扫描全局状态。
cpp
#include <atomic>
#include <array>
#include <vector>
#include <functional>
#include <algorithm>
#include <atomic>
#include <vector>
#include <thread>
#include <iostream>
// 简化版 Hazard Pointer 实现
// 核心思想:
// 1. 线程在使用某个指针前,先将其注册为 "hazard pointer"(风险指针)
// 2. 其他线程在回收内存前,检查是否有人在使用
// 3. 如果有人在使用,延迟回收
class HazardPointerManager
{
public:
static constexpr int MAX_THREADS = 64; // 最大支持线程数
static constexpr int MAX_HAZARDS_PER_THREAD = 2; // 每线程最多保护 2 个指针
// 每个线程的 hazard pointer 记录
struct ThreadRecord
{
std::atomic<void *> hazards[MAX_HAZARDS_PER_THREAD]{}; // 正在保护的指针
std::atomic<bool> active{false}; // 此记录是否被某个线程占用
};
// 获取一个线程记录(每个线程启动时调用一次)
ThreadRecord *acquire_record()
{
for (auto &record : records_)
{
bool expected = false;
// CAS:尝试占用一个空闲的记录
if (record.active.compare_exchange_strong(expected, true))
{
return &record;
}
}
return nullptr; // 超过最大线程数
}
// 释放线程记录(线程退出时调用)
void release_record(ThreadRecord *record)
{
// 清除所有 hazard pointers
for (int i = 0; i < MAX_HAZARDS_PER_THREAD; ++i)
{
record->hazards[i].store(nullptr, std::memory_order_release);
}
// 释放记录
record->active.store(false, std::memory_order_release);
}
// 设置 hazard pointer:宣告"我正在使用这个指针,别释放它"
void set_hazard(ThreadRecord *record, int index, void *ptr)
{
record->hazards[index].store(ptr, std::memory_order_release);
}
// 清除 hazard pointer:宣告"我不再使用这个指针了"
void clear_hazard(ThreadRecord *record, int index)
{
record->hazards[index].store(nullptr, std::memory_order_release);
}
// 检查某个指针是否正在被任何线程使用
bool is_hazardous(void *ptr)
{
for (auto &record : records_)
{
if (!record.active.load(std::memory_order_acquire))
continue;
for (int i = 0; i < MAX_HAZARDS_PER_THREAD; ++i)
{
if (record.hazards[i].load(std::memory_order_acquire) == ptr)
{
return true; // 有线程正在使用这个指针,不能释放
}
}
}
return false; // 没有线程在使用,可以安全释放
}
// 安全回收:批量检查和释放
template <typename T>
void safe_reclaim(std::vector<T *> &retire_list)
{
auto it = retire_list.begin();
while (it != retire_list.end())
{
if (!is_hazardous(*it))
{
delete *it; // 安全释放
it = retire_list.erase(it);
}
else
{
++it; // 还有人在用,下次再试
}
}
}
private:
std::array<ThreadRecord, MAX_THREADS> records_;
};
// 全局单例(简化起见)
HazardPointerManager g_hp_manager;
// 线程局部状态:每个线程持有自己的 record 和"待回收"列表
thread_local HazardPointerManager::ThreadRecord *tl_record = nullptr;
thread_local std::vector<void *> tl_retire_list;
// 线程初始化:获取一个 record
void thread_init()
{
tl_record = g_hp_manager.acquire_record();
}
// 线程退出:尝试回收所有本地待释放节点,然后归还 record
void thread_exit()
{
// 注意:这里类型信息丢了,真实代码里 retire_list 应该存函数指针或 std::function
// 为了演示简化,我们假设调用者知道类型
g_hp_manager.release_record(tl_record);
}
// ============== 无锁栈 ==============
template <typename T>
class LockFreeStack
{
struct Node
{
T value;
Node *next;
Node(const T &v) : value(v), next(nullptr) {}
};
std::atomic<Node *> top_{nullptr};
public:
void push(const T &value)
{
Node *new_node = new Node(value);
Node *old_top;
do
{
old_top = top_.load(std::memory_order_relaxed);
new_node->next = old_top;
} while (!top_.compare_exchange_weak(
old_top, new_node,
std::memory_order_release,
std::memory_order_relaxed));
}
bool pop(T &out)
{
Node *old_top;
while (true)
{
// ---------- 关键步骤 ----------
// 第 1 步:读当前栈顶
old_top = top_.load(std::memory_order_acquire);
if (!old_top)
return false;
// 第 2 步:把 old_top 登记为 hazard
// 宣告:"我现在正在看这个指针,谁都别释放它"
g_hp_manager.set_hazard(tl_record, 0, old_top);
// 第 3 步:重新验证栈顶是否还是 old_top
// 必须重读!因为在第 1 步和第 2 步之间,别的线程可能已经 pop 并释放了它
// 只有"登记之后仍然看到它"才能保证接下来访问 old_top->next 是安全的
if (top_.load(std::memory_order_acquire) != old_top)
{
continue; // 栈顶变了,重来
}
// 第 4 步:现在可以安全访问 old_top->next
// 因为已经登记了 hazard,即使别人 pop 了 old_top,
// 他也不会真正 delete 它,只会把它放进 retire_list
Node *next = old_top->next;
// 第 5 步:CAS 尝试弹出
if (top_.compare_exchange_strong(
old_top, next,
std::memory_order_release,
std::memory_order_relaxed))
{
break; // 成功
}
// CAS 失败,清掉 hazard 重来
}
// 第 6 步:CAS 成功后清除 hazard
g_hp_manager.clear_hazard(tl_record, 0);
out = old_top->value;
// 第 7 步:不能立即 delete old_top!
// 其他线程可能还在它们自己的第 1~3 步之间看到过这个指针
// 放进待回收列表,攒够一批再集中回收
tl_retire_list.push_back(old_top);
// 第 8 步:当待回收列表攒到一定数量,尝试批量回收
if (tl_retire_list.size() >= 16)
{
std::vector<Node *> typed_list;
for (void *p : tl_retire_list)
{
typed_list.push_back(static_cast<Node *>(p));
}
tl_retire_list.clear();
g_hp_manager.safe_reclaim(typed_list);
// 没能回收的放回去,下次再试
for (Node *p : typed_list)
{
tl_retire_list.push_back(p);
}
}
return true;
}
};
// ============== 使用示例 ==============
LockFreeStack<int> stack;
void worker(int id)
{
thread_init();
// 每个线程 push 一批,再 pop 一批
for (int i = 0; i < 100; ++i)
{
stack.push(id * 1000 + i);
}
for (int i = 0; i < 100; ++i)
{
int value;
if (stack.pop(value))
{
// 处理 value
}
}
thread_exit();
}
int main()
{
std::vector<std::thread> threads;
for (int i = 0; i < 8; ++i)
{
threads.emplace_back(worker, i);
}
for (auto &t : threads)
t.join();
}14. Epoch-Based Reclamation(EBR):更实用的内存回收方案
Hazard Pointers 虽然安全,但开销较大(每次读取前都要设置 hazard pointer)。Epoch-Based Reclamation(基于纪元的回收)提供了一种更高效的方案。
回想 hazard pointer 的代价:每次访问一个共享节点,都要 set_hazard 一次,读完再清掉。这是细粒度 的------精确到"我现在正在看哪个指针"。好处是内存回收可以很及时,坏处是读路径的开销不小(每次访问都有原子写)。
RCU(下面介绍) 走另一个极端:读者完全不做任何同步 ,读路径零开销。写者要释放节点时,等一个"宽限期"------保证所有老读者都走完了------再 free。代价是宽限期可能很长,释放延迟大。
EBR 想要介于两者之间:读路径开销远小于 hazard pointer,回收延迟远小于 RCU。它的核心洞察是:
与其追踪"每个线程正在看哪些具体指针",不如追踪"每个线程是不是正在看某些东西"。
粒度更粗,但换来极低的读开销。
读路径(read path / read-side) 指的是读者线程从开始读共享数据到读完为止,所执行的那一串代码 。对应地还有写路径(write path / update-side),指写者更新数据所走的代码。
14.1 核心思想
全局 epoch 和线程本地 epoch:
系统维护一个全局的 epoch 计数器 global_epoch,它就是一个普通的整数,会在某些条件满足时 +1(满足什么条件下面会说)。
每个线程有一个**"本地 epoch"**变量(local_epoch),记录两件事:
- 当前是否处于临界区(是不是正在读/写共享数据)
- 如果在临界区,进入时看到的 global_epoch 是多少
一个典型的线程状态结构:
cpp
struct ThreadEpoch {
std::atomic<uint64_t> local_epoch; // 0 表示不在临界区,非 0 表示该 epoch 下的临界区
};进入临界区(线程要开始访问共享数据时):
cpp
void enter() {
uint64_t e = global_epoch.load(std::memory_order_acquire);
tl_state.local_epoch.store(e, std::memory_order_release);
// 现在这个线程"被钉在"了 epoch e
}离开临界区:
cpp
void leave() {
tl_state.local_epoch.store(0, std::memory_order_release);
// 把 local_epoch 清零,表示"我不在临界区了"
}对比一下 hazard pointer 的读路径:那里每访问一个节点都要登记,可能登记很多次。EBR 的读路径只在进入和离开临界区各写一次,和节点数量无关。这就是它快的原因。
回收:retire
当写者想删除一个节点时:
cpp
void retire(Node* p) {
uint64_t e = global_epoch.load(std::memory_order_acquire);
tl_retire_list[e].push_back(p);
// 把节点挂到"当前 epoch 的 retire 桶"里
}节点没被 free,只是被打上了"我是 epoch e 时 retire 的"这个标签,放进一个按 epoch 分桶的待回收列表。
什么时候可以真正free?
这是整个机制的核心。考虑一个 epoch e 时被 retire 的节点 p,它能被 free 的充要条件是:
所有可能还持有对 p 引用的线程,都已经离开了它们的临界区。
怎么判断?如果某个线程 T 的 local_epoch 等于 e(或者更小,但 EBR 一般限制在相邻几个 epoch 内),说明 T 正处于 epoch e 的临界区,它可能 在 e 时刻读到过 p------因为 p 是在 e 被移除的,而 T 在 p 被移除之前就进入了临界区,所以 T 可能还看着 p。这时候不能 free。
反过来,如果所有活跃线程的 local_epoch 都已经大于 e(或者等于 0,即不在临界区),那就说明:这些线程要么根本不在临界区、要么是在 p 被移除之后才进入的------它们不可能持有对 p 的引用。于是 p 可以安全 free。
推进 global_epoch:
光有上面还不够,还缺一块:global_epoch 什么时候 +1?
答案是:当全局扫描发现"所有活跃线程的 local_epoch 要么是 0,要么等于当前global_epoch"时 ,global_epoch 可以推进到下一个值。
具体做法:某个线程(通常是正在 retire 的写者)周期性地扫描所有线程的local_epoch:
cpp
bool try_advance_epoch() {
uint64_t current = global_epoch.load();
for (auto& t : all_threads) {
uint64_t le = t.local_epoch.load(std::memory_order_acquire);
if (le != 0 && le != current) {
return false; // 有线程还停留在更早的 epoch,不能推进
}
}
global_epoch.compare_exchange_strong(current, current + 1);
return true;
}一旦 global_epoch 从 e 推进到 e+1,意味着所有线程要么不在临界区、要么已经进入了 e+1 的临界区------再也没有任何线程能看到 epoch e 或更早被移除的节点。于是,epoch e 及更早的 retire 桶里的所有节点,现在都可以 free 了。
14.2 三个epoch的经典设计
注意到一个问题:如果 global_epoch 从 e 推进到 e+1,我能回收 epoch e 的节点吗?不一定能。
考虑这种情况:线程 A 刚要把 global_epoch 推进到 e+1,但线程 B 在这之前已经进入了 epoch e 的临界区,B 的 local_epoch = e。B 可能还在看 epoch e 时被 retire 的节点。
所以最安全的做法是:只回收两个 epoch 之前的节点 。即 global_epoch = e+1 时,可以 free epoch e-1 的桶。这样就有一个保护性的时间差,确保没有任何线程还停留在那么老的 epoch 上。
实际实现中通常用三个 retire 桶 循环使用:bucket[global_epoch % 3]。具体分析可以参考 Crossbeam 的文档,基本逻辑是"正在用 e,回收 e-2,e-1 是缓冲"。
全局纪元(epoch):0 → 1 → 2 → 0 → 1 → 2 → ...(循环递增)
规则:
1. 每个线程在访问共享数据前,声明自己进入了当前纪元
2. 线程退出临界区时,声明自己离开了当前纪元
3. 要释放的节点被放入当前纪元的"退休列表"
4. 当所有线程都离开了某个纪元后,该纪元的退休列表可以安全释放
核心保证:
如果一个节点在纪元 E 被退休,
那么在纪元 E+2 时,所有可能持有该节点引用的线程都已经完成了对它的访问(因为它们要么退出了,要么进入了更新的纪元)14.3 为什么比 hazard pointer 快、比 RCU 回收更及时?
比 hazard pointer 快的原因 :读路径只有"进入临界区时写一次 local_epoch,离开时写一次"。这两次写是线程本地的原子变量(没人跟它 cache bouncing,因为只有这个线程自己写),几乎零开销。而 hazard pointer 的每次访问都要写一次,对节点数量敏感。
比 RCU 回收更及时的原因:RCU 的宽限期等的是"所有读者都走完一整轮",这一轮可能很长(在内核里经常是几十毫秒级)。EBR 的宽限期是"global_epoch 推进两次",只要线程活跃,推进就很快------实际回收延迟通常在毫秒甚至微秒级。
14.4 EBR的代价和坑
坑 1:stall 问题 。如果某个线程进入了临界区,然后被操作系统调度走了(或者干脆崩了、死循环了),它的 local_epoch 永远停在进入时的那个值,global_epoch 再也推不动 。所有后续的 retire 节点都累积在内存里,无法回收------泄漏。
这是 EBR 最严重的实践问题。Hazard pointer 没有这个问题,因为它追踪的是具体指针,一个挂起的线程只会保护它真正登记过的那些节点,其他节点照常回收。而 EBR 是"一个线程 stall,全系统 retire 卡住"。
应对方式:限制临界区的长度(不能在里面做 I/O、不能持久等待)、加入超时检测强制清理、或者混合使用多种方案。
坑 2:内存序要求很细 。enter 之后读共享数据,需要保证"读"发生在"enter"之后,否则线程可能在还没宣告自己进入 epoch 的时候就偷跑读数据。对应地,retire 之前的"移除"操作,需要保证对其他线程的 enter 可见。细节不展开,原则是:enter 用 seq_cst 或带完整屏障,retire 路径要有 release,扫描方用 acquire。
坑 3:实现依然不简单 。虽然比 hazard pointer 简单一些,但"简单"是相对的------并发推进 epoch、避免重复 free、处理线程加入退出的注册表、retire 桶的并发安全,每一项都有细节。Crossbeam 的 crossbeam-epoch crate 有数千行代码,不是凭空写出来的。
14.5 完整实现
cpp
#include <iostream>
#include <type_traits>
#include <gtest/gtest.h>
#include <atomic>
#include <array>
#include <vector>
#include <functional>
#include <cassert>
#include <iostream>
#include <thread>
#include <chrono>
#include <memory>
#include <string>
class EpochBasedReclamation
{
public:
// 全局纪元:在 0, 1, 2 之间循环
std::atomic<uint64_t> global_epoch_{0};
static constexpr int MAX_THREADS = 64; // 最大线程数
static constexpr int NUM_EPOCHS = 3; // 需要 3 个纪元来保证安全性
/*
详细讲讲alignas关键字
alignas 是 C++11 引入的内存对齐指定符,用来强制指定类型 / 变量在内存中的对齐方式,让编译器按照你要求的字节数来分配内存地址。
1、什么是内存对齐?
现代 CPU 访问内存时,不是按单个字节读取,而是按字长(如 4/8/64 字节)批量读取。如果数据的内存地址不是 CPU 读取粒度的整数倍,就会触发未对齐访问:
性能下降:CPU 需要做两次内存读取 + 数据拼接,耗时翻倍
硬件异常:部分架构(如 ARM)直接崩溃,程序无法运行
缓存失效:未对齐数据会跨缓存行,导致缓存命中率暴跌
2、alignas(N) 的作用
强制编译器将类型 / 变量的起始地址,对齐到 N 字节的整数倍。
N 必须是 2 的幂(如 1, 2, 4, 8, 16, 32, 64...)
可以作用于结构体 / 类、变量、联合体、位域
3、alignas(64)
让 ThreadState 结构体的每个实例,在内存中的起始地址,都对齐到 64 字节的整数倍。
4、为什么用 64 字节?
64 字节是现代 CPU L1/L2 缓存行(Cache Line)的标准大小(x86-64、ARM 等主流架构都是 64B)。
对齐到缓存行大小,可以避免伪共享(False Sharing):多线程场景下,如果两个线程的变量落在同一个缓存行,CPU 缓存一致性协议(MESI)会频繁失效,导致性能暴跌。
把每个线程的 ThreadState 单独占一个缓存行,就能彻底隔离,互不干扰,这是无锁队列、Epoch-Based Reclamation(EBR,你代码里的 local_epoch 就是 EBR 实现)等高性能并发结构的经典优化。
*/
// 每个线程的状态
struct alignas(64) ThreadState
{
std::atomic<uint64_t> local_epoch{0}; // 线程当前所在的纪元
std::atomic<bool> active{false}; // 线程是否在临界区内
std::atomic<bool> in_use{false}; // 此槽位是否被分配
std::atomic<size_t> retired_count{0}; // 尚未真正回收的退休节点个数
// 每个纪元的退休列表
// 使用 function<void()> 来实现类型擦除,支持任意类型的删除
std::vector<std::function<void()>> retire_list[NUM_EPOCHS];
};
private:
std::array<ThreadState, MAX_THREADS> thread_states_;
public:
// RAII 临界区守卫
class Guard
{
EpochBasedReclamation &ebr_;
ThreadState &state_;
public:
Guard(EpochBasedReclamation &ebr, ThreadState &state)
: ebr_(ebr), state_(state)
{
// 进入临界区:将本地纪元同步到全局纪元
uint64_t epoch = ebr_.global_epoch_.load(std::memory_order_relaxed);
state_.local_epoch.store(epoch, std::memory_order_relaxed);
state_.active.store(true, std::memory_order_release);
// 需要重新读取全局纪元(可能在 store active 之前被推进了)
// 为什么需要重新读取?
// 1、因为第一次读global_epoch_,只是"我打算进入哪个纪元"
// 2、state_.active.store(true) 之后,才算"我真的进入临界区了,别的线程扫描时必须把我算进去"。
// 3、但这两步之间有一个时间窗,别的线程可能正好调用 try_advance_epoch() ,看到你还没 active=true ,于是 忽略你并推进纪元 。
// 如果 不重新读 ,会出现这种情况:
// 1. 线程 A 进入 Guard
// 2. A 先读到 global_epoch_ = 0
// 3. 这时 A 还没 active=true
// 4. 线程 B 扫描所有线程,发现 A 还不活跃,于是把全局纪元推进到 1
// 5. A 接着执行 active=true ,并带着 local_epoch = 0 进入临界区
// 这就有问题了:
// - A 已经进入了临界区,但它"挂"的还是旧纪元 0
// - 而系统已经把它当成"推进到 1 时不存在的线程"处理过一次了
// - 这会破坏 EBR 的安全前提: 凡是活跃线程,都必须准确地宣布自己当前所在的纪元
// 用 seq_cst load 替代 "fence + relaxed load" 的组合,效果等价:
// - seq_cst load 在全局全序 S 中排在 active=true 之后,
// 保证读到的 epoch 不早于 active 可见时刻的最新值;
// - 同时避免使用 atomic_thread_fence,因为 TSAN 声明不支持对
// atomic_thread_fence 建模,使用 fence 会造成大量误报。
// seq_cst store 保证扫描线程的 acquire load 能看到最新 local_epoch。
epoch = ebr_.global_epoch_.load(std::memory_order_seq_cst);
state_.local_epoch.store(epoch, std::memory_order_seq_cst);
// 这里重新读取全局纪元和try_advance_epoch中的推进关系
// 如果有这个时刻,线程一处于:uint64_t epoch = ebr_.global_epoch_.load(std::memory_order_relaxed),读到纪元e和state_.local_epoch.store(epoch, std::memory_order_relaxed);已经发生,但state_.active.store(true, std::memory_order_release);还没执行:
// 1、如果此时另一个线程还没推进全局纪元到e+1/或者正在遍历但未遍历到线程一的,同时线程一的active=true,全局推进e+1失败,后续线程一重读也还是e
// 2、如果此时另一个线程已经推进全局纪元到e+1,线程一后续重新读取,重新更新纪元为e+1
// 3、如果此时另一个线程正在进行全局纪元推进工作,但此时还在遍历且已经遍历过了线程一,但还没推进到e+1,这会有两种情况:
// 3.1、如果线程一重新读取时全局纪元已经是e+1,那么线程一重新读取后更新为e+1
// 3.2、如果线程一重新读取时,全局推进纪元还在进行中且还没有推进到e+1,那么线程一重新读取还是e,这就是特殊情况,这也说明了为什么全局纪元推进到e+1之后,还不能删除掉e纪元的节点,只能删除e-1的节点,因为这个特殊情况:全局纪元为e+1,但此时还有线程处于e纪元,所以e纪元的节点还不能真正删除
}
~Guard()
{
// 离开临界区 -- 重置 active 为 false表示线程已离开临界区
state_.active.store(false, std::memory_order_release);
}
// 禁止拷贝
Guard(const Guard &) = delete;
Guard &operator=(const Guard &) = delete;
};
// 注册线程 -- 线程初始化时调用,返回线程状态指针
ThreadState *register_thread()
{
for (auto &state : thread_states_)
{
bool expected = false;
// 线程状态能用的条件:
// 1、in_use == false,当前没有线程占用这个槽位
// 2、retired_count == 0,旧线程遗留的退休节点已经全部清空
if (state.in_use.compare_exchange_strong(expected, true)) // in_use=false
{
// 先占住槽位,再检查是否仍有待回收节点,避免并发直接读 vector。
if (state.retired_count.load(std::memory_order_acquire) != 0)
{
state.in_use.store(false, std::memory_order_release);
continue;
}
state.active.store(false, std::memory_order_relaxed);
state.local_epoch.store(global_epoch_.load(std::memory_order_relaxed), std::memory_order_relaxed);
return &state;
}
}
return nullptr;
}
// 注销线程 -- 线程退出时调用,不直接释放退休节点
// 节点仍按 epoch 规则延迟回收,避免在线程退出时过早 delete
void unregister_thread(ThreadState *state)
{
// 线程退出后立刻离开参与者集合。
// 如果仍有退休节点残留,槽位会因为 retired_count != 0 而暂时不可复用,
// 直到后续 try_advance_epoch() 真正把这些节点回收掉。
state->active.store(false, std::memory_order_release);
state->local_epoch.store(0, std::memory_order_relaxed);
state->in_use.store(false, std::memory_order_release);
}
// 进入临界区(获取 guard)
Guard enter(ThreadState *state)
{
return Guard(*this, *state);
}
// ---- 仅供测试使用:无并发保护,所有线程必须已退出后才能调用 ----
void force_reclaim_all()
{
for (auto &state : thread_states_)
{
for (int e = 0; e < NUM_EPOCHS; ++e)
{
auto &bucket = state.retire_list[e];
size_t n = bucket.size();
for (auto &deleter : bucket) deleter();
bucket.clear();
if (n > 0)
state.retired_count.fetch_sub(n, std::memory_order_relaxed);
}
}
}
int64_t total_pending_retirements() const
{
int64_t total = 0;
for (const auto &state : thread_states_)
total += state.retired_count.load(std::memory_order_relaxed);
return total;
}
// ---- 测试接口结束 ----
// 退休一个指针(延迟删除)
template <typename T>
void retire(ThreadState *state, T *ptr)
{
// 使用线程自己的 local_epoch,而非重新读 global_epoch_。
// retire() 必须在 Guard 生命周期内调用,local_epoch 由 Guard 构造时的 seq_cst
// fence 保证了足够新的可见性,且同线程 relaxed load 一定能看到本线程最新写入,
// 不存在 global_epoch_.load(relaxed) 在弱序架构上读到过时值(E-1)而把节点
// 放入过早被回收的 bucket、导致 use-after-free 的问题。
uint64_t epoch = state->local_epoch.load(std::memory_order_relaxed);
state->retire_list[epoch % NUM_EPOCHS].emplace_back(
[ptr]()
{ delete ptr; }
);
state->retired_count.fetch_add(1, std::memory_order_acq_rel);
// 尝试推进全局纪元
try_advance_epoch();
}
private:
// 尝试推进全局纪元
void try_advance_epoch()
{
uint64_t current = global_epoch_.load(std::memory_order_relaxed);
// 检查是否所有活跃线程都已经进入了当前纪元
for (auto &state : thread_states_)
{
if (!state.in_use.load(std::memory_order_acquire)) // 未被线程使用,跳过
continue;
if (!state.active.load(std::memory_order_acquire)) // 线程未进入临界区,跳过
continue;
// 如果某个活跃线程还在旧纪元中,不能推进
if (state.local_epoch.load(std::memory_order_acquire) != current)
{
return;
}
}
// 所有活跃线程都在当前纪元中(或已退出临界区),可以推进
uint64_t new_epoch = current + 1;
// 走到这里,还没进行推进到 e + 1 之前,仍可能有线程以旧视角在 e 纪元进入临界区,
// 所以此时最多只能回收 e - 1 那一桶,而不能回收 e。
if (global_epoch_.compare_exchange_strong(current, new_epoch, std::memory_order_acq_rel))
{
// 推进成功后,new_epoch = e + 1,可安全回收的是 e - 1 那一桶。
uint64_t reclaim_epoch = (new_epoch + 1) % NUM_EPOCHS;
// 扫描所有槽位,把该桶中已经安全的退休节点真正释放掉;扫描所有的线程,即便是线程状态为in_use=false退出了也需要扫描清空,便于后续使用
for (auto &state : thread_states_)
{
auto &bucket = state.retire_list[reclaim_epoch];
size_t reclaimed = bucket.size();
for (auto &deleter : bucket)
{
deleter();
}
bucket.clear();
if (reclaimed != 0)
{
state.retired_count.fetch_sub(reclaimed, std::memory_order_acq_rel);
}
}
}
}
};
// 全局单例
EpochBasedReclamation g_ebr;
// 每个线程的 EBR 状态槽位,thread_local 自动管理
thread_local EpochBasedReclamation::ThreadState *tl_ebr_state = nullptr;
// 线程初始化:注册到 EBR
void ebr_thread_init()
{
tl_ebr_state = g_ebr.register_thread();
if (!tl_ebr_state)
{
throw std::runtime_error("EBR: too many threads");
}
}
// 线程退出:注销
void ebr_thread_exit()
{
if (tl_ebr_state)
{
g_ebr.unregister_thread(tl_ebr_state);
tl_ebr_state = nullptr;
}
}
// ========== 无锁栈 ==========
template <typename T>
class LockFreeStack
{
struct Node
{
T value;
Node *next;
Node(const T &v) : value(v), next(nullptr) {}
};
std::atomic<Node *> top_{nullptr};
public:
~LockFreeStack()
{
// 析构时清理剩余节点(假设此时没有并发访问)
Node *p = top_.load();
while (p)
{
Node *next = p->next;
delete p;
p = next;
}
}
void push(const T &value)
{
Node *new_node = new Node(value);
Node *old_top = top_.load(std::memory_order_relaxed);
do
{
new_node->next = old_top;
} while (!top_.compare_exchange_weak(
old_top, new_node,
std::memory_order_release,
std::memory_order_relaxed));
}
bool pop(T &out)
{
// ========== 整个读临界区被 Guard 包起来 ==========
auto guard = g_ebr.enter(tl_ebr_state);
// 从这一刻起,本线程"钉"在当前 epoch 上
// 在 guard 生命周期内读到的任何节点,都不会被真正 free
Node *old_top;
Node *new_top;
do
{
old_top = top_.load(std::memory_order_acquire);
if (!old_top)
{
return false;
}
// 关键:这一步访问 old_top->next 是安全的
// 因为哪怕另一个线程已经 pop 并 retire 了 old_top,
// 它也不会真的 delete------因为我的 local_epoch 还钉在这里,
// 全局 epoch 没法推进到能回收 old_top 的程度
new_top = old_top->next;
} while (!top_.compare_exchange_weak(
old_top, new_top,
std::memory_order_acquire,
std::memory_order_relaxed));
out = old_top->value;
// 弹出成功,把节点交给 EBR 延迟回收
// 注意:这里并不立即 delete,而是放进 retire_list
g_ebr.retire(tl_ebr_state, old_top);
return true;
// guard 在这里析构,离开临界区
// 对比 hazard pointer 需要 set_hazard/clear_hazard 精确配对,
// EBR 的 RAII 风格在使用上简洁得多
}
};
// ============================================================
// 测试辅助
// ============================================================
// RAII: 为调用线程完成 EBR 注册/注销
struct EbrScope {
EbrScope() { ebr_thread_init(); }
~EbrScope() { ebr_thread_exit(); g_ebr.force_reclaim_all(); }
};
// ============================================================
// LifetimeTracker:追踪对象生命周期,用于内存泄漏检测
// 每个实例(含拷贝构造)alive+1,析构 alive-1
// ============================================================
struct Tracked {
static std::atomic<int64_t> alive;
int val;
Tracked() : val(0) { alive.fetch_add(1, std::memory_order_relaxed); }
explicit Tracked(int v) : val(v) { alive.fetch_add(1, std::memory_order_relaxed); }
Tracked(const Tracked &o) : val(o.val) { alive.fetch_add(1, std::memory_order_relaxed); }
Tracked &operator=(const Tracked &o) { val = o.val; return *this; }
~Tracked() { alive.fetch_sub(1, std::memory_order_relaxed); }
};
std::atomic<int64_t> Tracked::alive{0};
// ============================================================
// 并发测试辅助:生产者/消费者(Bug 2 已修复的消费者退出逻辑)
// ============================================================
struct RoundCtx {
LockFreeStack<int> *stack;
const int total;
const int num_producers;
std::atomic<int> push_cnt{0};
std::atomic<int> pop_cnt{0};
std::atomic<int> done_producers{0};
std::atomic<int> invalid_cnt{0};
std::atomic<int> dup_cnt{0};
std::vector<std::atomic<int>> seen; // seen[v]: 值 v 被 pop 的次数
const bool perturb;
RoundCtx(int np, int items, bool p)
: total(np * items), num_producers(np), seen(np * items), perturb(p)
{
for (auto &s : seen) s.store(0, std::memory_order_relaxed);
}
};
static void perturb_maybe(int marker)
{
if ((marker & 0x3F) == 0) std::this_thread::yield();
if ((marker & 0x1FF) == 0)
std::this_thread::sleep_for(std::chrono::microseconds(1));
}
static void record_pop(RoundCtx &ctx, int v)
{
if (v < 0 || v >= ctx.total) {
ctx.invalid_cnt.fetch_add(1, std::memory_order_relaxed);
return;
}
if (ctx.seen[v].fetch_add(1, std::memory_order_relaxed) != 0)
ctx.dup_cnt.fetch_add(1, std::memory_order_relaxed);
}
static void producer_worker(RoundCtx &ctx, int id, int items)
{
ebr_thread_init();
for (int i = 0; i < items; ++i) {
ctx.stack->push(id * items + i);
ctx.push_cnt.fetch_add(1, std::memory_order_relaxed);
if (ctx.perturb) perturb_maybe(i + id * 17);
}
ctx.done_producers.fetch_add(1, std::memory_order_release);
ebr_thread_exit();
}
static void consumer_worker(RoundCtx &ctx)
{
ebr_thread_init();
int v, local = 0;
while (true) {
if (ctx.stack->pop(v)) {
++local;
record_pop(ctx, v);
if (ctx.perturb) perturb_maybe(v + local);
} else {
if (ctx.done_producers.load(std::memory_order_acquire) == ctx.num_producers) {
// Bug 2 修复:确认所有生产者完成后,彻底排空剩余元素再退出,
// 避免生产者在消费者 pop 失败和检查 done_producers 之间推入的元素丢失
while (ctx.stack->pop(v)) { ++local; record_pop(ctx, v); }
break;
}
std::this_thread::yield();
}
}
ctx.pop_cnt.fetch_add(local, std::memory_order_relaxed);
ebr_thread_exit();
}
struct RoundResult { bool ok; int missing, extra, invalid, dup; };
static RoundResult run_round(int np, int nc, int items, bool perturb = false)
{
LockFreeStack<int> stack;
RoundCtx ctx(np, items, perturb);
ctx.stack = &stack;
std::vector<std::thread> threads;
for (int i = 0; i < np; ++i)
threads.emplace_back(producer_worker, std::ref(ctx), i, items);
for (int i = 0; i < nc; ++i)
threads.emplace_back(consumer_worker, std::ref(ctx));
for (auto &t : threads) t.join();
RoundResult r{true, 0, 0, ctx.invalid_cnt.load(), ctx.dup_cnt.load()};
for (int i = 0; i < ctx.total; ++i) {
int c = ctx.seen[i].load();
if (c == 0) ++r.missing;
else if (c > 1) r.extra += c - 1;
}
bool cnt_ok = (ctx.push_cnt.load() == ctx.total) && (ctx.pop_cnt.load() == ctx.total);
r.ok = cnt_ok && r.invalid == 0 && r.dup == 0 && r.missing == 0 && r.extra == 0;
return r;
}
// ============================================================
// TEST 1:单线程 LIFO 正确性
// ============================================================
TEST(LockFreeStack, SingleThreadLIFO)
{
EbrScope ebr;
LockFreeStack<int> s;
int v = -1;
// 空栈 pop 返回 false
EXPECT_FALSE(s.pop(v));
// 单个元素
s.push(42);
EXPECT_TRUE(s.pop(v));
EXPECT_EQ(v, 42);
EXPECT_FALSE(s.pop(v));
// LIFO 顺序
s.push(1); s.push(2); s.push(3);
ASSERT_TRUE(s.pop(v)); EXPECT_EQ(v, 3);
ASSERT_TRUE(s.pop(v)); EXPECT_EQ(v, 2);
ASSERT_TRUE(s.pop(v)); EXPECT_EQ(v, 1);
EXPECT_FALSE(s.pop(v));
// 大量串行 push/pop
const int N = 100000;
for (int i = 0; i < N; ++i) s.push(i);
for (int i = N - 1; i >= 0; --i) {
ASSERT_TRUE(s.pop(v));
EXPECT_EQ(v, i) << "LIFO violation at position " << i;
}
EXPECT_FALSE(s.pop(v));
}
// ============================================================
// TEST 2:多线程并发正确性(多种生产者/消费者比例)
// ============================================================
TEST(LockFreeStack, Concurrent_1P_1C)
{
auto r = run_round(1, 1, 20000);
EXPECT_TRUE(r.ok) << "missing=" << r.missing << " extra=" << r.extra
<< " invalid=" << r.invalid << " dup=" << r.dup;
g_ebr.force_reclaim_all();
}
TEST(LockFreeStack, Concurrent_4P_4C)
{
auto r = run_round(4, 4, 10000);
EXPECT_TRUE(r.ok) << "missing=" << r.missing << " extra=" << r.extra
<< " invalid=" << r.invalid << " dup=" << r.dup;
g_ebr.force_reclaim_all();
}
TEST(LockFreeStack, Concurrent_8P_1C)
{
auto r = run_round(8, 1, 5000);
EXPECT_TRUE(r.ok) << "missing=" << r.missing << " extra=" << r.extra;
g_ebr.force_reclaim_all();
}
TEST(LockFreeStack, Concurrent_1P_8C)
{
auto r = run_round(1, 8, 40000);
EXPECT_TRUE(r.ok) << "missing=" << r.missing << " extra=" << r.extra;
g_ebr.force_reclaim_all();
}
TEST(LockFreeStack, Concurrent_4P_8C_ProducerHeavy)
{
auto r = run_round(4, 8, 8000);
EXPECT_TRUE(r.ok) << "missing=" << r.missing << " extra=" << r.extra;
g_ebr.force_reclaim_all();
}
// ============================================================
// TEST 3:内存泄漏检测
// 使用 Tracked 类型,每个节点创建时 alive+1,delete 时 alive-1。
// 全部 pop + EBR 强制回收后 alive 必须为 0。
// ============================================================
static void producer_tracked(LockFreeStack<Tracked> *s,
std::atomic<int> *done, int id, int n)
{
ebr_thread_init();
for (int i = 0; i < n; ++i) s->push(Tracked(id * n + i));
done->fetch_add(1, std::memory_order_release);
ebr_thread_exit();
}
static void consumer_tracked(LockFreeStack<Tracked> *s,
std::atomic<int> *done, int np)
{
ebr_thread_init();
Tracked out;
while (true) {
if (s->pop(out)) { /* consumed */ }
else {
if (done->load(std::memory_order_acquire) == np) {
while (s->pop(out)) {} // 排空
break;
}
std::this_thread::yield();
}
}
ebr_thread_exit();
}
TEST(EBR, NoMemoryLeak)
{
Tracked::alive.store(0, std::memory_order_relaxed);
{
constexpr int NP = 4, NC = 4, ITEMS = 5000;
auto *s = new LockFreeStack<Tracked>();
std::atomic<int> done{0};
std::vector<std::thread> threads;
for (int i = 0; i < NP; ++i)
threads.emplace_back(producer_tracked, s, &done, i, ITEMS);
for (int i = 0; i < NC; ++i)
threads.emplace_back(consumer_tracked, s, &done, NP);
for (auto &t : threads) t.join();
// 所有线程结束后,alive 不得为负(说明无 double-free)
EXPECT_GE(Tracked::alive.load(), 0) << "double-free detected";
delete s; // 析构栈(正常情况下栈已空)
g_ebr.force_reclaim_all(); // 强制回收 retire list 中全部待删节点
}
EXPECT_EQ(Tracked::alive.load(), 0LL) << "memory leak: nodes were not freed";
}
// ============================================================
// TEST 4:EBR 延迟回收正确性
// 验证:Guard 持有期间节点不会被提前删除。
// 线程 A 持有 Guard → main pop 节点并 retire → 检查节点仍存活
// → 释放 Guard → 触发 epoch 推进 → 节点被删除
// ============================================================
TEST(EBR, DeferredReclaimWhileGuardHeld)
{
Tracked::alive.store(0, std::memory_order_relaxed);
auto *s = new LockFreeStack<Tracked>();
s->push(Tracked(1));
ASSERT_EQ(Tracked::alive.load(), 1LL) << "precondition: 1 node alive";
std::atomic<bool> guard_held{false};
std::atomic<bool> can_release{false};
std::thread thread_a([&] {
ebr_thread_init();
{
auto guard = g_ebr.enter(tl_ebr_state); // 进入临界区,钉住当前 epoch
guard_held.store(true, std::memory_order_release);
// 持有 Guard,等待 main 完成 pop
while (!can_release.load(std::memory_order_acquire))
std::this_thread::yield();
} // guard 析构,离开临界区
ebr_thread_exit();
});
// 等待 thread_a 真正进入 Guard
while (!guard_held.load(std::memory_order_acquire))
std::this_thread::yield();
// main 注册 EBR 并 pop 节点(retire 进 retire_list,try_advance_epoch 尝试推进)
// 因 thread_a 钉住了旧 epoch,epoch 至多推进一步,无法到达回收该节点的程度
ebr_thread_init();
{
Tracked out;
ASSERT_TRUE(s->pop(out));
}
// 给 try_advance_epoch 足够时间运行,确认节点确实没有被提前删除
std::this_thread::sleep_for(std::chrono::milliseconds(10));
EXPECT_GE(Tracked::alive.load(), 1LL)
<< "node was prematurely deleted while Guard still held by thread_a";
// 释放 thread_a 的 Guard
can_release.store(true, std::memory_order_release);
thread_a.join();
// 触发 epoch 继续推进(推进后才能回收上述 retire 的节点)
{
LockFreeStack<int> dummy;
for (int i = 0; i < 6; ++i) { dummy.push(i); int v; dummy.pop(v); }
}
g_ebr.force_reclaim_all();
delete s;
ebr_thread_exit();
EXPECT_EQ(Tracked::alive.load(), 0LL)
<< "node was not freed after Guard released and EBR drained";
}
// ============================================================
// TEST 5:EBR retired_count 最终归零
// 大量 push/pop 后所有线程退出,force_reclaim_all 强制回收,
// pending_retirements 必须为 0,否则说明 retire_count 记账有误。
// ============================================================
TEST(EBR, RetiredCountEventuallyZero)
{
Tracked::alive.store(0, std::memory_order_relaxed);
{
constexpr int NP = 4, NC = 4, ITEMS = 2000;
auto *s = new LockFreeStack<Tracked>();
std::atomic<int> done{0};
std::vector<std::thread> threads;
for (int i = 0; i < NP; ++i)
threads.emplace_back(producer_tracked, s, &done, i, ITEMS);
for (int i = 0; i < NC; ++i)
threads.emplace_back(consumer_tracked, s, &done, NP);
for (auto &t : threads) t.join();
delete s;
g_ebr.force_reclaim_all();
}
int64_t pending = g_ebr.total_pending_retirements();
EXPECT_EQ(pending, 0LL)
<< "EBR has " << pending << " unflushed retirements after full drain";
EXPECT_EQ(Tracked::alive.load(), 0LL)
<< "memory leak: " << Tracked::alive.load() << " nodes still alive";
}
// ============================================================
// TEST 6:压力测试(多轮并发 + 随机扰动)
// ============================================================
TEST(Stress, MultiRoundWithPerturbation)
{
constexpr int ROUNDS = 50;
int failed = 0;
for (int r = 0; r < ROUNDS; ++r) {
auto res = run_round(4, 4, 5000, /*perturb=*/true);
if (!res.ok) {
++failed;
ADD_FAILURE() << "Round " << r << " failed:"
<< " missing=" << res.missing
<< " extra=" << res.extra
<< " dup=" << res.dup
<< " invalid=" << res.invalid;
}
g_ebr.force_reclaim_all();
}
EXPECT_EQ(failed, 0) << failed << "/" << ROUNDS << " rounds failed";
}
// ============================================================
// main
// ============================================================
int main(int argc, char **argv)
{
::testing::InitGoogleTest(&argc, argv);
return RUN_ALL_TESTS();
}15. RCU(Read-Copy-Update):读多写少的终极方案
RCU 是 Linux 内核里最重要的同步机制之一,几乎所有热路径数据结构(进程列表、路由表、文件描述符表、网络协议栈)都用了它。它的设计目标极其极端:读路径完全零开销------不加锁、不写原子变量、不发内存屏障,什么都不做,直接读。
**RCU(Read-Copy Update),**顾名思义就是读-拷贝修改,它是基于其原理命名的。对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针替换为新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的访问。
15.1 核心思想
字面拆开:
- Read:读者直接读,不做任何同步
- Copy :写者要修改时,拷贝一份新数据,在副本上修改
- Update:用一次原子的指针赋值,把"当前版本"切换到新副本
关键的不变量是:老版本一旦被切换下来,就再也不会被修改 。它像一座纪念碑------可能还有读者站在它脚下,但它本身的内容是冻结的。读者读到老版本,看到的是一个完整的、自洽的旧快照 ;读者读到新版本,看到的是一个完整的、自洽的新快照 。永远不会有读者看到"修改到一半"的中间状态。
这就解释了为什么读者不需要同步:读者读到什么版本不重要,重要的是它读到的任何版本都是一致的。
举个最小的例子。假设有一个全局指针指向一个配置对象:
c
struct config *global_config; // 当前生效的配置读者:
c
struct config *c = rcu_dereference(global_config); // 读指针
use(c->some_field); // 直接用写者:
c
struct config *new_c = kmalloc(sizeof(struct config));
*new_c = *old_c; // 拷贝
new_c->some_field = 42; // 在副本上修改
rcu_assign_pointer(global_config, new_c); // 原子切换
synchronize_rcu(); // 等待所有老读者退场
kfree(old_c); // 现在可以安全释放老版本rcu_dereference 和 rcu_assign_pointer 在大多数架构上(尤其是 x86)什么都不做,就是普通的指针读写------只有在 Alpha 这种极弱内存模型上才需要插入屏障。所以读路径真的就是一次普通的内存读 ,和"用裸指针访问全局变量"开销完全一样。
写路径稍微复杂一点,但精髓只有一句:新老版本并存,等老读者全部走完,再释放老版本。
RCU 的三个核心操作:
1. Read(读取):直接读,无需加锁,零开销
2. Copy-Update(拷贝更新):要修改数据时,先复制一份,在副本上修改,
然后原子地替换指针
3. Reclaim(回收):等到所有正在读取旧数据的线程都完成后,释放旧数据
关键洞察:读者看到的要么是完整的旧数据,要么是完整的新数据,
不会看到"修改到一半"的状态15.2 核心函数:synchronize_rcu
整个 RCU 的核心机密都藏在 synchronize_rcu() 这个函数里。它的语义是:
阻塞调用者,直到所有"在调用 synchronize_rcu 之前就已经开始"的读临界区都已经结束。
注意它不等"所有未来的读者",只等"已经存在的老读者"。新读者来了无所谓------它们要么已经能看到新指针(看到的是新版本,完全没引用老版本),要么虽然看到老指针但还没开始读(synchronize_rcu 不需要等它们,因为它们读的也是合法的老版本,只要在 kfree 之前结束就行)。
实际上 synchronize_rcu 给的保证更强一点:它等的是一个宽限期(grace period)------这段时间内,系统中所有 CPU 都至少经历过一次"静止状态(quiescent state)"。静止状态的定义是"这个 CPU 现在肯定不在任何 RCU 读临界区里"。
那怎么知道一个 CPU 肯定不在临界区里?这就要看 RCU 的精妙之处:它利用了内核里本来就发生的事件作为静止点的信号,而不是让读者主动汇报。
15.3 识别静止状态的关键技巧
经典 RCU(classic RCU,以及现在 Linux 内核中的 tree RCU)的核心约定是:
RCU 读临界区内禁止睡眠、禁止抢占、禁止主动让出 CPU。
这条约定带来的逻辑后果非常强:如果一个 CPU 发生了上下文切换,那它一定不在 RCU 读临界区里。因为如果它在读临界区里,按约定它就不会让出 CPU,所以一旦它切走了,就证明它在切之前已经走出临界区了。
于是 rcu_read_lock() 和 rcu_read_unlock() 在内核里的实现是禁用/启用抢占:
c
#define rcu_read_lock() preempt_disable()
#define rcu_read_unlock() preempt_enable()注意它们没有写任何全局变量、没有原子操作、没有内存屏障------只是把当前 CPU 的"抢占允许"标志改一下,这是个 per-CPU 的局部操作,几乎零开销。在非抢占式内核上,这两个宏甚至直接是空操作,读临界区的标记成本是字面意义上的零。
那 synchronize_rcu 怎么实现?它需要确认每个 CPU 都至少经历过一次上下文切换(或进入了 idle、用户态等明显不在内核临界区的状态)。常见做法:
- 写者调用
synchronize_rcu,被加入一个等待队列 - 系统记录下当前每个 CPU 的某个状态计数
- 每个 CPU 在下次发生上下文切换、时钟中断、进入 idle、或返回用户态时,更新自己的状态
- 当所有 CPU 都"动过"之后,意味着没有任何 CPU 还停留在 synchronize_rcu 调用之前的临界区里------宽限期结束
- 写者被唤醒,可以继续 kfree
这个过程不涉及读者的任何参与。读者完全不知道宽限期的存在,也不需要知道。同步代价全部由写者承担,而且是均摊的------一次 synchronize_rcu 可能等几毫秒,但同期可以有几百几千个写者一起等同一个宽限期,均摊下来非常划算。
15.4 为什么RCU适合内核
理解 RCU 必须理解它的原产地------Linux 内核------才能明白为什么这套设计的取舍是合理的。内核环境有几个特点:
- 读远多于写。比如路由表,每个网络包都要查一次,但路由表本身可能几秒甚至几分钟才改一次。读写比可以是 100 万比一。
- 读路径是热路径。每条读路径都在系统调用、网络中断、调度器里被反复执行,任何同步开销都会乘以亿万次。
- 写路径可以慢。配置变更、模块加载、路由更新这些事件本来就不频繁,慢一点不影响整体性能。
- 抢占可以被禁用。内核有完全的控制权,可以禁用抢占而不会给应用带来任何感知。
在这样的环境下,把所有同步成本压到写者身上、让读者享受零开销,是非常划算的交易。写者慢几毫秒甚至几百毫秒都没事,只要读者每秒能跑亿万次。
反过来,如果是用户态的应用,情况可能完全相反:写者不那么稀疏、读者也不需要极致性能、还要面对线程被随意抢占------这时 RCU 的优势就没那么明显了,用 hazard pointer 或 EBR 可能更合适。这也是为什么 RCU 在内核统治一切,在用户态应用却相对小众。
15.5 用户态 RCU(URCU)和它的妥协
用户态没有"禁用抢占"这个工具------用户线程随时可能被 OS 调度走,而且应用没办法控制。所以用户态 RCU(liburcu)必须换一套机制识别静止状态,主要有几种实现:
QSBR(Quiescent-State-Based RCU) :最快,这个算法的核心思想就是识别出线程的不活动(quiescent)状态,但要求应用程序显式调用 rcu_quiescent_state() 来声明"我现在不在任何读临界区里",也就是声明"线程离开临界区,变成不活动状态了,并把状态通知出去,让其他线程知道"。读路径依然零开销(连 rcu_read_lock 都是空操作),但需要侵入式地改造应用代码。适合事件循环类的应用------每次事件处理完调用一次 quiescent_state 即可。
Memory-barrier-based RCU :rcu_read_lock 和 rcu_read_unlock 各做一次内存屏障,代价比 QSBR 高,但应用不需要改造。
Signal-based RCU:通过给所有线程发信号来强制它们到达静止点,读路径开销几乎为零,但 synchronize 的延迟很高。
这些方案都比内核版"贵"一些,因为用户态拿不到那些"免费的静止点"(上下文切换、中断、系统调用)。但它们仍然能保持读路径远比 hazard pointer 便宜的优势。
15.6 RCU的局限和典型陷阱
陷阱 1:读临界区里禁止睡眠 。这条约定是核心 RCU 正确性的基石,违反它会让 synchronize_rcu 产生错觉(以为某个 CPU 已经退出了,实际上读者还在),导致 use-after-free。Linux 内核里有一个变体叫 SRCU(Sleepable RCU)允许睡眠,代价是要显式管理一个"读者持有计数",失去了一部分零开销特性。
陷阱 2:写者必须真的"拷贝"。RCU 的不变量是"老版本永远不变"。如果写者偷懒,直接在原地修改某个字段,读者就会看到中间状态------RCU 完全不能防止这种破坏。任何修改都必须走"拷贝-改副本-切指针"的流程。
陷阱 3:适合"原子可替换"的数据结构,不适合复杂修改。给一个链表插入一个节点很容易(改一两个 next 指针就行),但要原子地"反转整个链表"就麻烦------需要拷贝整个链表。所以 RCU 用得好的数据结构通常是:链表(单向插入/删除)、树(更新单条路径)、哈希表(按桶 RCU);用得不好的是:需要全局一致性快照的复杂结构。
陷阱 4:写者吞吐受 synchronize 延迟限制 。一个宽限期通常是毫秒级的,如果写者必须等 synchronize 才能继续(比如要立刻释放内存),写吞吐就受限。Linux 提供了 call_rcu(ptr, free_func) 异步版本------把释放操作注册成一个回调,等下一个宽限期到来时由内核线程批量执行,写者立即返回。这样写者无需阻塞,代价是被释放的内存会有一段延迟。
陷阱 5:内存使用峰值。因为老版本要等宽限期才能释放,如果写很频繁、宽限期又较长,系统中可能同时存在大量"待回收"的旧版本,内存使用会飙高。Linux 内核有专门的机制限制 call_rcu 的积压量,超过阈值会强制等待。
15.7 简化实现
cpp
#include <atomic>
#include <memory>
#include <thread>
#include <functional>
// 简化的用户空间 RCU 实现
// 使用引用计数来跟踪读者
template<typename T>
class RCU {
// 受 RCU 保护的数据指针
// 使用 shared_ptr 来管理生命周期
std::atomic<std::shared_ptr<const T>*> data_;
public:
// 构造函数:初始化数据
explicit RCU(T initial_value) {
data_.store(
new std::shared_ptr<const T>(
std::make_shared<const T>(std::move(initial_value))
),
std::memory_order_release
);
}
~RCU() {
delete data_.load(std::memory_order_relaxed);
}
// 读取操作:零开销获取当前数据的快照
// 返回 shared_ptr,保证在持有期间数据不被释放
std::shared_ptr<const T> read() const {
// acquire load:确保能看到 writer 发布的最新数据
auto* ptr = data_.load(std::memory_order_acquire);
return *ptr; // 返回 shared_ptr 的拷贝(原子递增引用计数)
}
// 更新操作:拷贝-修改-替换
// updater 是一个函数,接受当前值的 const 引用,返回新值
void update(std::function<T(const T&)> updater) {
auto* old_ptr = data_.load(std::memory_order_acquire);
// 1. 拷贝当前数据
T new_value = updater(**old_ptr);
// 2. 创建新的 shared_ptr
auto* new_ptr = new std::shared_ptr<const T>(
std::make_shared<const T>(std::move(new_value))
);
// 3. 原子替换指针
auto* prev = data_.exchange(new_ptr, std::memory_order_acq_rel);
// 4. 延迟释放旧数据
// 当所有持有旧 shared_ptr 的读者释放后,旧数据自动被销毁
delete prev; // 删除旧的 shared_ptr 容器(但不是 T 本身)
// T 的生命周期由 shared_ptr 引用计数管理
}
};
// ==================== 使用示例:游戏配置热更新 ====================
struct GameConfig {
int max_players;
float tick_rate;
std::string server_name;
// ... 更多配置项
};
RCU<GameConfig> global_config(GameConfig{100, 30.0f, "GameServer-1"});
// 游戏逻辑线程(读取配置,高频,零开销)
void game_tick() {
// 读取当前配置快照------极低开销
auto config = global_config.read();
// 使用配置(config 在使用期间不会被释放)
if (config->max_players > 50) {
// ...
}
}
// 管理线程(更新配置,低频)
void update_config() {
global_config.update([](const GameConfig& old) {
GameConfig new_config = old; // 拷贝旧配置
new_config.max_players = 200; // 修改
new_config.server_name = "GameServer-2"; // 修改
return new_config; // 返回新配置
});
// 旧配置在所有读者释放后自动回收
}15.8 多种方案对比
| 维度 | Mutex | Hazard Pointer | EBR | RCU |
|---|---|---|---|---|
| 读路径开销 | 高(锁竞争) | 中(每节点原子写) | 低(只在临界区边界) | 几乎零 |
| 回收延迟 | 即时 | 短 | 短 | 长(宽限期) |
| 写路径开销 | 中 | 中 | 中 | 高(synchronize) |
| 内存峰值 | 低 | 低 | 中 | 高 |
| Stall 容忍 | 差 | 好 | 差 | 差 |
| 实现复杂度 | 低 | 高 | 中 | 极高 |
| 读临界区限制 | 无 | 无 | 临界区要短 | 不能睡眠 |
| 适合场景 | 通用 | 用户态无锁结构 | Rust 无锁结构 | 内核热路径、读远多于写 |
RCU 的位置很特殊:它在"读路径开销"这个维度上是无可争议的冠军,代价是把所有压力推给写路径、并接受较长的回收延迟和较高的内存峰值。这种取舍只在"读极端频繁、写很稀疏、且能接受回收延迟"的场景下才划算。
幸运的是,Linux 内核里到处都是这种场景,所以 RCU 在内核里几乎是默认选择。Paul McKenney(RCU 的作者)在内核里维护这套机制几十年,围绕 RCU 写过一本厚厚的专著,可以说 RCU 是"用大量的工程复杂度,换读路径上的极致简洁"。
15.9 一个让 RCU 真正神奇的细节
最后说一个我觉得最能体现 RCU 之美的点。考虑这段读者代码:
c
rcu_read_lock();
struct foo *p = rcu_dereference(global_ptr);
int x = p->field;
rcu_read_unlock();在 x86 上,这段代码编译后实际执行的指令大致就是:
asm
mov global_ptr, %rax ; 读指针
mov (%rax), %ebx ; 读 fieldrcu_read_lock、rcu_dereference、rcu_read_unlock 全部是空操作(在非抢占式内核里)或者只是 preempt_disable/enable 的本地操作。整个"安全的并发读"被压缩到了两条普通的 mov 指令,和"完全不考虑并发的代码"在指令层面没有区别。
这就是为什么 RCU 能在 Linux 内核的最热路径上取得统治地位:它不仅在并发正确性上做对了,而且没有为这份正确性付出任何运行时代价------所有代价都被精心地转嫁到了写者那一边、转嫁到了"宽限期机制"这个后台流程里。这种"读者完全感觉不到同步存在"的特性,是其他任何方案都做不到的。
16. False Sharing:隐蔽的多线程性能杀手
16.1 什么是 False Sharing?
还记得前面说的 Cache Line 是 64 字节吗?False Sharing 就是:两个不相关的变量恰好位于同一条 Cache Line 上,当多个线程分别修改这两个变量时,会导致 Cache Line 在核心之间来回弹跳(cache line bouncing),严重降低性能。
Cache Line (64 bytes)
┌──────────────────────────────────────────────────────┐
│ counter_a (8 bytes) │ counter_b (8 bytes) │ ... │
│ Thread A 频繁修改 │ Thread B 频繁修改 │ │
└──────────────────────────────────────────────────────┘
Thread A 修改 counter_a:
→ Core A 的缓存行变为 Modified
→ Core B 的缓存行变为 Invalid(即使 B 没有修改 counter_a!)
Thread B 接下来修改 counter_b:
→ 需要先从 Core A 获取最新的缓存行(因为自己的是 Invalid)
→ Core B 的缓存行变为 Modified
→ Core A 的缓存行变为 Invalid
→ 缓存行在两个核心之间不断 "乒乓",性能可能下降 10-100 倍!16.2 False Sharing 的性能对比实验
cpp
#include <atomic>
#include <thread>
#include <chrono>
#include <iostream>
#include <vector>
// ❌ 存在 False Sharing 的版本
struct BadCounters {
std::atomic<long> counter_a{0}; // 偏移 0,占 8 字节
std::atomic<long> counter_b{0}; // 偏移 8,占 8 字节
// 两个 counter 在同一条 64 字节的 Cache Line 中!
// sizeof(BadCounters) = 16
};
// ✅ 修复 False Sharing 的版本
struct GoodCounters {
alignas(64) std::atomic<long> counter_a{0}; // 独占一条 Cache Line
alignas(64) std::atomic<long> counter_b{0}; // 独占另一条 Cache Line
// sizeof(GoodCounters) = 128(两条 Cache Line)
};
// C++17 标准提供了平台无关的缓存行大小常量
// #include <new>
// constexpr size_t CACHE_LINE = std::hardware_destructive_interference_size;
// 注意:某些编译器可能不支持此常量(如 GCC 某些版本)
// 实践中直接用 64 更稳妥
template<typename Counters>
void benchmark(const char* name) {
Counters counters;
constexpr int ITERATIONS = 100'000'000; // 一亿次
auto start = std::chrono::high_resolution_clock::now();
// 线程 A 狂写 counter_a
std::thread ta([&]() {
for (int i = 0; i < ITERATIONS; ++i) {
counters.counter_a.fetch_add(1, std::memory_order_relaxed);
}
});
// 线程 B 狂写 counter_b
std::thread tb([&]() {
for (int i = 0; i < ITERATIONS; ++i) {
counters.counter_b.fetch_add(1, std::memory_order_relaxed);
}
});
ta.join();
tb.join();
auto end = std::chrono::high_resolution_clock::now();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << name << ": " << ms << " ms" << std::endl;
std::cout << " counter_a = " << counters.counter_a.load() << std::endl;
std::cout << " counter_b = " << counters.counter_b.load() << std::endl;
std::cout << " sizeof(Counters) = " << sizeof(Counters) << std::endl;
}
int main() {
benchmark<BadCounters>("False Sharing (BAD) ");
benchmark<GoodCounters>("No False Sharing (GOOD)");
return 0;
}以下是虚拟机Ubuntu系统8核8G的几次运行结果,差不多4~5倍的差距:
bash
ayanami@eva:~/myfile/learn$ g++ -o test test.cpp
ayanami@eva:~/myfile/learn$ ./test
False Sharing (BAD) : 2361 ms
counter_a = 100000000
counter_b = 100000000
sizeof(Counters) = 16
No False Sharing (GOOD): 542 ms
counter_a = 100000000
counter_b = 100000000
sizeof(Counters) = 128
ayanami@eva:~/myfile/learn$ ./test
False Sharing (BAD) : 2340 ms
counter_a = 100000000
counter_b = 100000000
sizeof(Counters) = 16
No False Sharing (GOOD): 545 ms
counter_a = 100000000
counter_b = 100000000
sizeof(Counters) = 128
ayanami@eva:~/myfile/learn$ ./test
False Sharing (BAD) : 2432 ms
counter_a = 100000000
counter_b = 100000000
sizeof(Counters) = 16
No False Sharing (GOOD): 540 ms
counter_a = 100000000
counter_b = 100000000
sizeof(Counters) = 12816.3 实际工程中防止 False Sharing 的技巧
cpp
#include <atomic>
#include <new>
#include <vector>
constexpr size_t CACHE_LINE_SIZE = 64;
// 技巧一:使用 alignas 对齐到缓存行
struct PerThreadData {
alignas(CACHE_LINE_SIZE) std::atomic<uint64_t> counter{0};
alignas(CACHE_LINE_SIZE) std::atomic<uint64_t> timestamp{0};
// 每个成员独占一条缓存行
};
// 技巧二:使用 padding 填充
struct PaddedCounter {
std::atomic<uint64_t> value{0};
// 填充到 64 字节,确保下一个 PaddedCounter 在新的缓存行上
char padding[CACHE_LINE_SIZE - sizeof(std::atomic<uint64_t>)];
};
// 技巧三:Per-Thread 计数器(在高频统计场景中非常实用)
// 每个线程只写自己的计数器,完全没有缓存争用
class DistributedCounter {
struct alignas(CACHE_LINE_SIZE) LocalCounter {
std::atomic<long> value{0};
// alignas 保证每个 LocalCounter 独占一条缓存行
};
std::vector<LocalCounter> local_counters_;
public:
explicit DistributedCounter(int num_threads)
: local_counters_(num_threads) {}
// 每个线程只操作自己的计数器------完全没有缓存争用!
void increment(int thread_id) {
local_counters_[thread_id].value.fetch_add(1, std::memory_order_relaxed);
}
// 需要读取总数时,汇总所有线程的值
// 这个操作不是精确的快照(但在统计场景下够用)
long total() const {
long sum = 0;
for (const auto& lc : local_counters_) {
sum += lc.value.load(std::memory_order_relaxed);
}
return sum;
}
};17. 实战一:无锁 SPSC 队列(单生产者单消费者)
18. 实战二:无锁 MPSC 队列(多生产者单消费者)
19. 实战三:无锁 MPMC 队列(多生产者多消费者)
20. 实战四:无锁栈
21. C++20 原子新特性
21.1 std::atomic::wait() 和 notify()
C++20 为 std::atomic 添加了类似条件变量的等待/通知机制,避免了忙等(busy-waiting)。
cpp
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<int> value{0};
void waiter() {
// wait(old_value):如果 value == old_value,则阻塞当前线程
// 当其他线程调用 notify_one/notify_all 且 value != old_value 时被唤醒
// 好处:不消耗 CPU(不像自旋等待),比 condition_variable 更轻量
value.wait(0); // 等待 value 变为非 0
std::cout << "Got value: " << value.load() << std::endl;
}
void setter() {
std::this_thread::sleep_for(std::chrono::seconds(1));
value.store(42);
value.notify_one(); // 唤醒一个等待的线程
// value.notify_all(); // 或唤醒所有等待的线程
}
// wait/notify 的实现通常基于 Linux 的 futex(Fast Userspace muTEX)系统调用
// 快速路径(无竞争)不涉及系统调用,只在需要阻塞时才陷入内核21.2 std::atomic_ref
cpp
#include <atomic>
// std::atomic_ref 允许对非原子变量执行原子操作
// 场景:你有一个已存在的普通变量(如结构体成员),需要临时对它做原子操作
void demo_atomic_ref() {
int value = 0; // 普通变量
// 创建 atomic_ref,对 value 提供原子操作接口
// 注意:value 必须正确对齐(int 需要 4 字节对齐,通常自动满足)
std::atomic_ref<int> ref(value);
ref.store(42, std::memory_order_release);
int v = ref.load(std::memory_order_acquire);
ref.fetch_add(1, std::memory_order_relaxed);
// 重要限制:
// 1. 在 atomic_ref 存在期间,不能直接通过 value 访问(否则数据竞争)
// 2. 所有对 value 的原子操作必须通过 atomic_ref 进行
// 3. value 的对齐必须满足 std::atomic_ref<T>::required_alignment
}
// 实用场景:对数组元素做原子操作
void parallel_array_update(int* array, size_t size) {
// 每个线程负责一部分数组,但可能有重叠
// 使用 atomic_ref 对可能被多个线程访问的元素做原子操作
std::atomic_ref<int> ref(array[42]);
ref.fetch_add(1, std::memory_order_relaxed);
}21.3 std::atomic<float> / std::atomic<double>
cpp
#include <atomic>
// C++20 之前,浮点数的 atomic 只支持 load/store/exchange/CAS
// C++20 新增了 fetch_add 和 fetch_sub
void demo_atomic_float() {
std::atomic<float> score{0.0f};
// C++20 新增的浮点原子加减
score.fetch_add(1.5f, std::memory_order_relaxed);
score.fetch_sub(0.3f, std::memory_order_relaxed);
// 注意:浮点原子 RMW 内部使用 CAS 循环实现(因为硬件不直接支持原子浮点加法)
// 性能不如整数的 fetch_add(整数版本通常是一条 LOCK XADD 指令)
}22. 调试与验证:如何证明你的无锁代码是正确的
22.1 ThreadSanitizer (TSan)
bash
# 编译时开启 ThreadSanitizer
g++ -fsanitize=thread -g -O1 -o my_program my_program.cpp -lpthread
# TSan 会在运行时检测数据竞争并报告详细信息:
# WARNING: ThreadSanitizer: data race (pid=12345)
# Write of size 4 at 0x7ffd12345678 by thread T1:
# #0 producer() my_program.cpp:10
# Previous read of size 4 at 0x7ffd12345678 by thread T2:
# #0 consumer() my_program.cpp:20TSan 的局限性:
TSan 通过动态分析检测数据竞争,但它有几个局限:
- 只能检测到实际执行路径上的竞争,不能覆盖所有可能的交错
- 会显著降低程序性能(通常 5-15 倍减速)
- 内存消耗增加(通常 5-10 倍)
- 可能有少量误报(false positive)
22.2 压力测试框架
cpp
#include <thread>
#include <vector>
#include <atomic>
#include <cassert>
#include <iostream>
#include <chrono>
// 通用无锁数据结构压力测试
template<typename Queue>
class StressTest {
Queue& queue_;
int num_producers_, num_consumers_, items_per_producer_;
std::atomic<uint64_t> push_count_{0}, pop_count_{0};
public:
StressTest(Queue& q, int p, int c, int items)
: queue_(q), num_producers_(p), num_consumers_(c),
items_per_producer_(items) {}
void run() {
std::vector<std::thread> threads;
uint64_t total = static_cast<uint64_t>(num_producers_) * items_per_producer_;
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < num_producers_; ++i) {
threads.emplace_back([this, i]() {
for (int j = 0; j < items_per_producer_; ++j) {
while (!queue_.try_enqueue(i * items_per_producer_ + j))
std::this_thread::yield();
push_count_.fetch_add(1, std::memory_order_relaxed);
}
});
}
for (int i = 0; i < num_consumers_; ++i) {
threads.emplace_back([this, total]() {
while (pop_count_.load(std::memory_order_relaxed) < total) {
if (queue_.try_dequeue().has_value())
pop_count_.fetch_add(1, std::memory_order_relaxed);
else
std::this_thread::yield();
}
});
}
for (auto& t : threads) t.join();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::high_resolution_clock::now() - start).count();
assert(push_count_.load() == total);
assert(pop_count_.load() == total);
std::cout << "Time: " << ms << "ms, Ops/sec: "
<< total * 2 * 1000 / (ms + 1) << " PASSED" << std::endl;
}
};22.3 形式化验证工具
推荐工具:
1. CDS Checker ------ C++11 内存模型的模型检查器,能穷举所有可能的执行序列
2. Relacy Race Detector ------ 模拟各种调度情况,检测数据竞争和死锁
3. CBMC ------ 有界模型检查器,可验证 C/C++ 程序的正确性
4. CDSChecker + GenMC ------ 更新的工具,支持更多 C++11/14 特性23. 性能基准测试方法论
23.1 正确的 Benchmark 方法
cpp
#include <chrono>
#include <vector>
#include <numeric>
#include <algorithm>
#include <iostream>
#include <cmath>
#include <atomic>
#include <thread>
// 基准测试最佳实践
class Benchmark {
public:
struct Result {
double mean_ns; // 平均延迟(纳秒)
double median_ns; // 中位数延迟
double p99_ns; // P99 延迟
double stddev_ns; // 标准差
double ops_per_sec; // 每秒操作数
};
// 运行基准测试
// fn: 被测函数
// warmup_iterations: 预热次数(让 CPU 缓存和分支预测器稳定)
// measure_iterations: 测量次数
template<typename Func>
static Result run(Func fn, int warmup = 1000, int measure = 10000) {
// 1. 预热阶段(不计入结果)
for (int i = 0; i < warmup; ++i) {
fn();
}
// 2. 测量阶段
std::vector<double> latencies;
latencies.reserve(measure);
for (int i = 0; i < measure; ++i) {
auto start = std::chrono::high_resolution_clock::now();
fn();
auto end = std::chrono::high_resolution_clock::now();
double ns = std::chrono::duration_cast<std::chrono::nanoseconds>(
end - start).count();
latencies.push_back(ns);
}
// 3. 统计分析
std::sort(latencies.begin(), latencies.end());
double sum = std::accumulate(latencies.begin(), latencies.end(), 0.0);
double mean = sum / measure;
double median = latencies[measure / 2];
double p99 = latencies[static_cast<int>(measure * 0.99)];
double sq_sum = 0;
for (double l : latencies) sq_sum += (l - mean) * (l - mean);
double stddev = std::sqrt(sq_sum / measure);
return {mean, median, p99, stddev, 1e9 / mean};
}
};23.2 常见陷阱
cpp
// ❌ 陷阱 1:编译器优化掉了被测代码
// 如果结果没有被使用,编译器可能直接删除整个计算
void bad_benchmark() {
auto start = std::chrono::high_resolution_clock::now();
int result = expensive_computation();
// result 没有被使用,编译器可能把 expensive_computation() 优化掉!
auto end = std::chrono::high_resolution_clock::now();
}
// ✅ 解决方法:使用 benchmark::DoNotOptimize(Google Benchmark 库)
// 或使用 volatile sink
static volatile int sink;
void good_benchmark() {
auto start = std::chrono::high_resolution_clock::now();
int result = expensive_computation();
sink = result; // volatile 写入,编译器不会优化掉
auto end = std::chrono::high_resolution_clock::now();
}
// ❌ 陷阱 2:没有预热
// CPU 频率可能从低频启动(节能模式),前几次测量会偏慢
// ❌ 陷阱 3:没有关闭 CPU 频率缩放
// sudo cpupower frequency-set -g performance # Linux 上设置为性能模式
// ❌ 陷阱 4:没有绑定 CPU 核心
// taskset -c 0 ./benchmark # 绑定到核心 0,避免线程迁移带来的抖动24. 常见面试题与深度解答
面试题 1:请解释 memory_order_acquire 和 memory_order_release 的配对语义
答 :release 和 acquire 构成了一个"同步点 "。当线程 B 对某个原子变量执行 acquire load,并且读到了 线程 A 通过 release store 写入的值时,线程 A 在 release store 之前 的所有内存写入(包括非原子写入),都保证对线程 B 在 acquire load 之后可见。
核心机制:
release相当于一个"单向屏障":它之前的操作不能重排到它之后acquire也是一个"单向屏障":它之后的操作不能重排到它之前
面试题 2:compare_exchange_weak 和 strong 有什么区别?
答 :weak 版本可能发生"伪失败 "(spurious failure)。在 ARM 等 LL/SC 平台上,任何干扰都可能导致 SC 失败。选择原则:循环中用 weak (省去编译器生成的重试循环),单次尝试用 strong。
面试题 3:什么是 ABA 问题?如何解决?
答:值从 A 变为 B 再变回 A,CAS 无法检测到中间变化。解决方案包括:Tagged Pointer(版本号)、Hazard Pointers、Epoch-Based Reclamation、不回收策略(内存池)。
面试题 4:什么是 False Sharing?
答 :两个线程频繁访问不同的变量 ,但这些变量在同一条 64 字节缓存行 上,导致缓存行在核心之间频繁失效和传输。解决方法:alignas(64) 对齐。
面试题 5:volatile 能用于线程间同步吗?
答 :在 C++ 中不能 。volatile 只阻止编译器优化,不保证原子性,不阻止 CPU 重排序,不建立 happens-before 关系。Java 的 volatile 有 acquire/release 语义,但 C++ 的 volatile 没有。线程间同步必须使用 std::atomic。
面试题 6:seq_cst 和 acquire/release 的区别是什么?
答 :acquire/release 只保证配对的两个线程之间 的同步关系。seq_cst 额外保证所有线程看到的所有 seq_cst 操作存在一个全局一致的全序关系。经典例子:两个线程分别写不同的 seq_cst 变量,第三和第四个线程观察它们的顺序------使用 seq_cst 时所有线程对顺序的观察一致,使用 acquire/release 则不一定。
25. 总结与进阶路线
25.1 核心知识树
内存模型与无锁编程 知识树(增强版)
│
├── 硬件基础
│ ├── CPU 缓存层次(L1/L2/L3)与关联性
│ ├── 缓存一致性协议(MESI / MOESI / MESIF)
│ ├── Store Buffer / Invalidate Queue
│ ├── 内存屏障(Memory Barrier)
│ └── 编译器屏障 vs 硬件屏障
│
├── C++ 内存模型
│ ├── std::atomic 基本操作与 is_lock_free
│ ├── volatile vs std::atomic 辨析
│ ├── std::atomic_flag(唯一保证 lock-free)
│ ├── 六种 Memory Order(relaxed → seq_cst)
│ ├── Happens-Before 形式化定义
│ ├── Modification Order 与 Release Sequence
│ ├── std::atomic_thread_fence 独立屏障
│ └── C++20 新特性(wait/notify、atomic_ref、atomic<float>)
│
├── CAS 与无锁原语
│ ├── compare_exchange_weak/strong
│ ├── 退避策略(指数退避、适应性退避)
│ ├── 进度保证层级(Wait-Free > Lock-Free > Obstruction-Free)
│ ├── ABA 问题与解决方案
│ │ ├── Tagged Pointer
│ │ ├── Hazard Pointers
│ │ └── 【新】Epoch-Based Reclamation(完整实现)
│ ├── RCU(Read-Copy-Update)
│ ├── Double-Checked Locking 正确实现
│ └── False Sharing 与缓存行对齐
│
├── 无锁数据结构
│ ├── SPSC Queue(环形缓冲区,性能最优)
│ ├── MPSC Queue(Vyukov 链表 / 侵入式链表)
│ ├── MPMC Queue(Vyukov 有界队列,sequence 状态机)
│ ├── Lock-Free Stack(Treiber Stack + 内存回收)
│ └── 无锁计数器(分布式计数器、限流器、Snowflake ID)
│
└── 工程实践
├── 游戏服务器架构中的无锁队列应用
├── 调试工具(TSan, Relacy, CDS Checker, CBMC)
├── 性能基准测试方法论
└── 选型原则(正确性 > 性能,先 mutex 再无锁)25.2 选型原则
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 临界区很短(< 100ns) | 无锁 / 自旋锁 | 避免线程切换开销 |
| 临界区较长(> 1μs) | std::mutex | 自旋会浪费 CPU |
| 读多写少 | std::shared_mutex / RCU | 读不需要互斥 |
| 单生产者单消费者 | SPSC Queue | 最简单、最快 |
| 多生产者单消费者 | MPSC Queue | 游戏服务器最常见 |
| 多生产者多消费者 | MPMC Queue / 加锁队列 | 无锁 MPMC 复杂 |
| 简单计数器 | std::atomic + relaxed | 零额外开销 |
| 不确定 | 先用 mutex,确认瓶颈再优化 | 正确性 > 性能 |
25.3 最后的忠告
永远不要过早优化 。先用
std::mutex写一个正确的实现,用性能分析工具确认它确实是瓶颈,然后再考虑无锁方案。无锁代码的正确性极难保证,一个微妙的 memory order 错误可能在百万次执行中才出现一次,调试成本远高于使用锁的性能损失。
正确性永远是第一位的。一个用了 mutex 但正确的程序,比一个无锁但有 Bug 的程序好上一万倍。