一、引言
我们在日常的Flink作业开发测试中,通常都会配置作业的重启策略与故障恢复策略,来提升作业生产运行的可靠性与健壮性。重启策略(Restart Strategy) 与 故障恢复策略(Failover Strategy) 是 Flink 容错体系的两大支柱,各司其职:
- 重启策略:决定"要不要重启"以及"以什么节奏重启"。当 Task 发生故障时,Flink 需要重启出错的 Task 以及其他受影响的 Task,以将作业恢复到正常状态,而重启策略正是控制这组动作的开关和节拍器。
- 故障恢复策略:决定"重启哪些 Task"。它是更细粒度的恢复控制------可以只重启故障 Task 所在的 Region(区域故障恢复),也可以重启整个作业的全部 Task(全局重启)。
- Checkpoint:负责"从什么状态恢复"。它通过定期生成状态快照,为作业被重启后的数据一致性提供基石。
三者的关系可用一句话概括:Checkpoint 告诉你"从哪儿继续",重启策略决定"要不要继续",故障恢复策略告诉系统"哪些部分需要重新开始"。三者配合得当,作业的故障恢复才算真正形成了闭环,本文将聚焦重启策略进行介绍与阐述。

二、Flink重启策略全景图
Flink 提供了两层配置入口,优先级从低到高逐级覆盖:
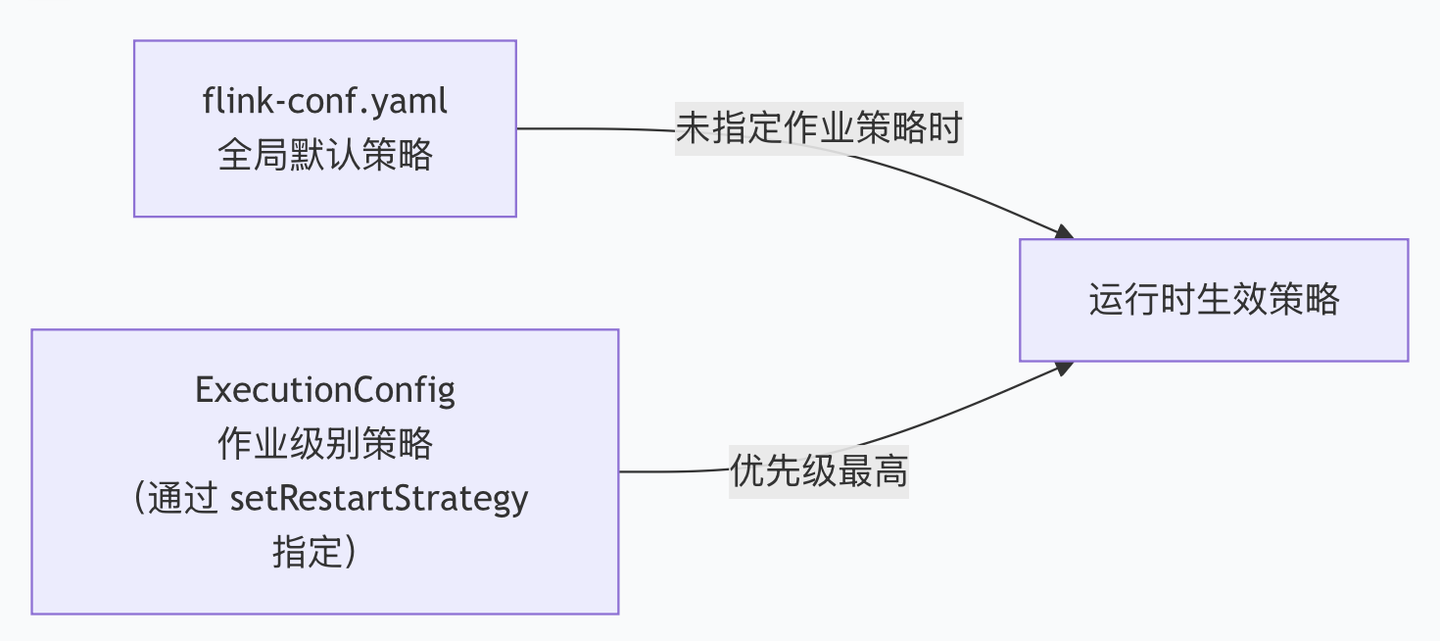
配置优先级原则:集群的默认重启策略通过 Flink 的配置文件flink-conf.yaml中的restart-strategy参数进行定义;如果在作业提交时指定了一个重启策略,该策略会覆盖集群的默认策略。
1.无重启策略(No Restart Strategy)
行为:作业在发生任何失败后直接终止,不进行自动重启尝试。任何成功的状态快照(Checkpoint)都不会被自动利用来恢复作业。
代码配置:
//java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
//flink-conf.yaml
restart-strategy: none优点:快速暴露致命故障,无资源无效消耗,便于快速定位问题。
缺点:无自愈能力,微小抖动也会中断业务,可用性极低。
适用场景:测试开发环境、一次性批处理任务、配置错误/数据损坏等致命故障场景。
2.固定延迟重启策略(Fixed Delay Restart Strategy)
行为:作业失败后,按固定时间间隔尝试重启,最多重试固定次数,达到上限后作业最终失败。
代码配置:
//java
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 最多重试次数
Time.seconds(10) // 固定重试延迟
));
//flink-conf.yaml
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 5
restart-strategy.fixed-delay.delay: 30 sFlink 官方对固定延迟策略的定位:适用于明确知道外部系统需要"冷却时间"的场景,例如下游数据库连接需要等待事务超时释放,此时固定延迟能让系统平稳度过外部不可用窗口。
优点:配置极简、逻辑直白、恢复时间可精准预估。
缺点:无动态适配能力,高频故障仍固定间隔重试,极易引发雪崩。
适用场景:测试开发环境、轻量级非核心小流量作业、故障原因固定、可瞬时恢复的简单任务。
3.失败率重启策略(Failure Rate Restart Strategy)
行为:在指定的时间窗口内,如果作业失败次数超过预设的阈值,则停止重启,作业最终失败。
代码配置:
//java
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个时间窗口内的最大失败次数
Time.minutes(5), // 测量失败率的时间窗口
Time.seconds(10) // 每次失败后的重启延迟
));
//flink-conf.yaml
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 sFlink 官方对失败率重启策略的定位:允许偶发失败快速恢复,但若"单位时间内失败太多",就直接让作业失败,避免无限重启掩盖真实问题。
优点:可抑制高频周期性故障,避免无效无限重试,兼顾自愈与资源保护。
缺点:参数调优复杂,仍采用固定重启间隔,存在雪崩隐患。
适用场景:周期性负载波动的非核心作业、故障频率可预判/有明显时间规律的作业。
4.指数延迟重启策略(Exponential Delay Restart Strategy)
行为:每次失败后的重启延迟按指数增长,直至达到预设的最大上限。如果作业成功运行超过一个"稳定阈值"(reset-backoff-threshold),则重置计数器,下一次失败又从头开始指数退避。增加 Jitter(抖动因子)还会在延迟上添加随机扰动,让多个作业的错峰启动得到进一步提升。
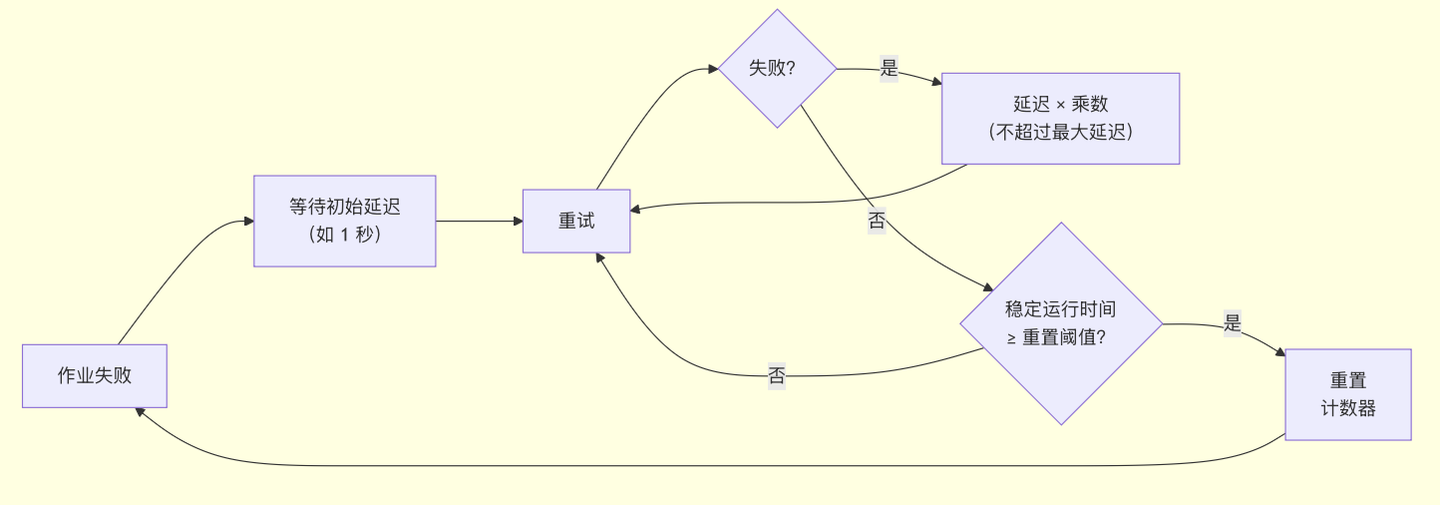
代码配置:
//java
env.setRestartStrategy(RestartStrategies.exponentialDelayRestart(
Time.seconds(1), // initialBackoff: 初始延迟 1 秒
Time.minutes(1), // maxBackoff: 最大延迟 60 秒
2.0, // backoffMultiplier: 指数增长倍率
Time.seconds(30), // resetThreshold: 稳定运行 30 秒不加延迟,则重置计数器
0.1 // jitterFactor: 随机抖动 ±10%,避免多个作业同时重启
));
//flink-conf.yaml
restart-strategy: exponential-delay
restart-strategy.exponential-delay.initial-backoff: 1 s
restart-strategy.exponential-delay.max-backoff: 60 s
restart-strategy.exponential-delay.backoff-multiplier: 2.0
restart-strategy.exponential-delay.reset-backoff-threshold: 30 s
restart-strategy.exponential-delay.jitter-factor: 0.1Flink 官方明确指出:强烈推荐(strongly recommend)Flink 用户使用指数延迟重启策略,因为该策略能在偶发故障时快速重试,同时又能在外部系统持续不可用时避免雪崩。
优点:偶发故障快速恢复,持续性故障自动限流,抖动错峰避免雪崩,作业稳定后恢复初始延迟,兼顾可用性与稳定性。(Flink 官方生产首选推荐)
缺点:配置参数多,调优存在一定门槛;恢复延迟不确定,高SLA作业重启间隔偏大,业务中断时间变长。
适用场景:绝大多数流式作业的生产默认选择。
三、Flink重启策略选型对比与原则
| 重启策略 | 核心特征 | 优势 | 短板 | 生产适配等级 |
|---|---|---|---|---|
| 指数延迟 | 指数衰减 + 抖动错峰 + 自适应重置 | 防雪崩、自愈强、官方默认 | 参数略多 | ⭐⭐⭐⭐⭐ 首选 |
| 失败率 | 时间窗口控故障频率 | 抑制周期性高频故障 | 调优复杂、仍有雪崩风险 | ⭐⭐⭐ 非核心场景 |
| 固定延迟 | 固定次数 + 固定间隔 | 配置简单、易理解 | 易引发故障雪崩 | ⭐ ⭐ 仅测试使用 |
| 无重启 | 故障直接终止 | 快速排障、零资源浪费 | 无自愈能力 | ⭐测试 / 离线任务 |
大多数生产场景下优先选择指数延迟重启策略,同时也需要结合业务的实际诉求。测试环境优先无重启或固定延迟,快速失败定位 Bug;周期性负载作业可选用失败率策略做频率管控;依赖外部中间件的作业强制开启指数延迟 + 抖动因子,杜绝雪崩。
常见避坑点:
- 指数延迟jitter-factor 不可设为 0,必须开启错峰机制。
- 不要使用指数延迟默认 1h 重置阈值,建议改为 5~10min,提升自适应效率。
- 避免失败率窗口时间设置太短引起误判,窗口长度应大致大于"失败恢复典型耗时 × 可容忍失败次数"。
- 必须配置连续失败最大次数,避免极端场景无限重试。
- 建议增加外部日志采集+jvm异常现场保留机制,用于重启策略迭代优化。
四、总结展望
Flink重启策略选型速记口诀:生产核心选指数,抖动必开防雪崩;轻量测试用固定,致命故障无重启;周期波动失败率,特殊业务自定义。
然而,重启策略不等于容错方案,我们还需要配合限流、异常处理、告警等机制联合保障Flink作业的稳定运行。真正成熟的Flink系统,不是"不失败",而是------在失败时依然保持系统稳定。