✍✍计算机毕设指导师**
⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡有什么问题可以在主页上或文末下联系咨询博客~~
⚡⚡Java、Python、小程序、大数据实战项目集](https://blog.csdn.net/2301_80395604/category_12487856.html)
⚡⚡文末获取源码
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
猫眼电影票房数据可视化分析系统-简介
本系统是一个围绕"基于Hadoop的猫眼电影票房数据可视化分析系统"构建的综合性大数据分析平台。在技术架构上,系统采用Hadoop HDFS作为海量电影票房数据的分布式存储基础,确保了数据的可靠性和可扩展性。核心的数据处理与分析任务由Apache Spark承担,利用其内存计算能力和Spark SQL引擎,对存储在HDFS上的CSV格式数据集进行高效的清洗、转换、聚合与关联查询。后端服务采用Python语言的Django框架,负责接收前端请求、调用Spark分析任务并将处理结果以API形式返回。前端界面则基于Vue.js和ElementUI构建,通过Echarts图表库将Spark分析出的数据结果进行动态、直观的可视化呈现。系统功能涵盖了从宏观的每日、每周票房趋势,到微观的电影类型、制片地区、导演演员票房贡献,再到探索性的评分与票房相关性分析等共计15个维度,旨在构建一个功能完备、技术先进、交互友好的电影市场数据分析工具。
猫眼电影票房数据可视化分析系统-技术
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
数据库:MySQL
猫眼电影票房数据可视化分析系统-背景
选题背景
随着中国电影市场的持续繁荣,电影产业已成为文化娱乐领域的重要组成部分。每年上映的影片数量众多,市场竞争异常激烈,影片的票房表现不仅关系到制片方和投资方的直接经济回报,也反映了观众的喜好和市场潮流。猫眼电影等在线票务平台积累了海量的、真实的票房数据、用户评分和评论信息,这些数据背后隐藏着宝贵的市场规律和商业价值。然而,传统的数据处理工具面对如此量级的数据时显得力不从心,难以进行快速、深入的分析。因此,如何利用现代大数据技术,对这些宝贵的电影数据进行系统性的挖掘与分析,从而为市场参与者提供决策支持,成为一个具有现实意义的研究课题。
选题意义
本课题的意义在于,它将大数据技术理论与电影行业的实际需求相结合,提供了一个具有实践价值的解决方案。从技术角度看,本项目完整地实践了从数据采集、分布式存储(HDFS)、分布式计算到最终可视化呈现的全过程,对于计算机专业的学生而言,是巩固和综合运用Hadoop、Spark、Python等主流技术栈的绝佳机会,能有效提升工程实践能力。从应用角度看,系统通过多维度分析,能够帮助影视从业者,如发行方和投资方,更直观地了解不同类型电影的受欢迎程度、档期选择的重要性以及口碑与票房的关联,为其在项目立项、宣传策略制定等方面提供数据参考。虽然作为一个毕业设计,其分析深度和模型精度有限,但它为电影数据驱动的决策模式提供了一种可行的技术思路和实现原型。
猫眼电影票房数据可视化分析系统-视频展示
基于Hadoop的猫眼电影票房数据可视化分析系统
猫眼电影票房数据可视化分析系统-图片展示

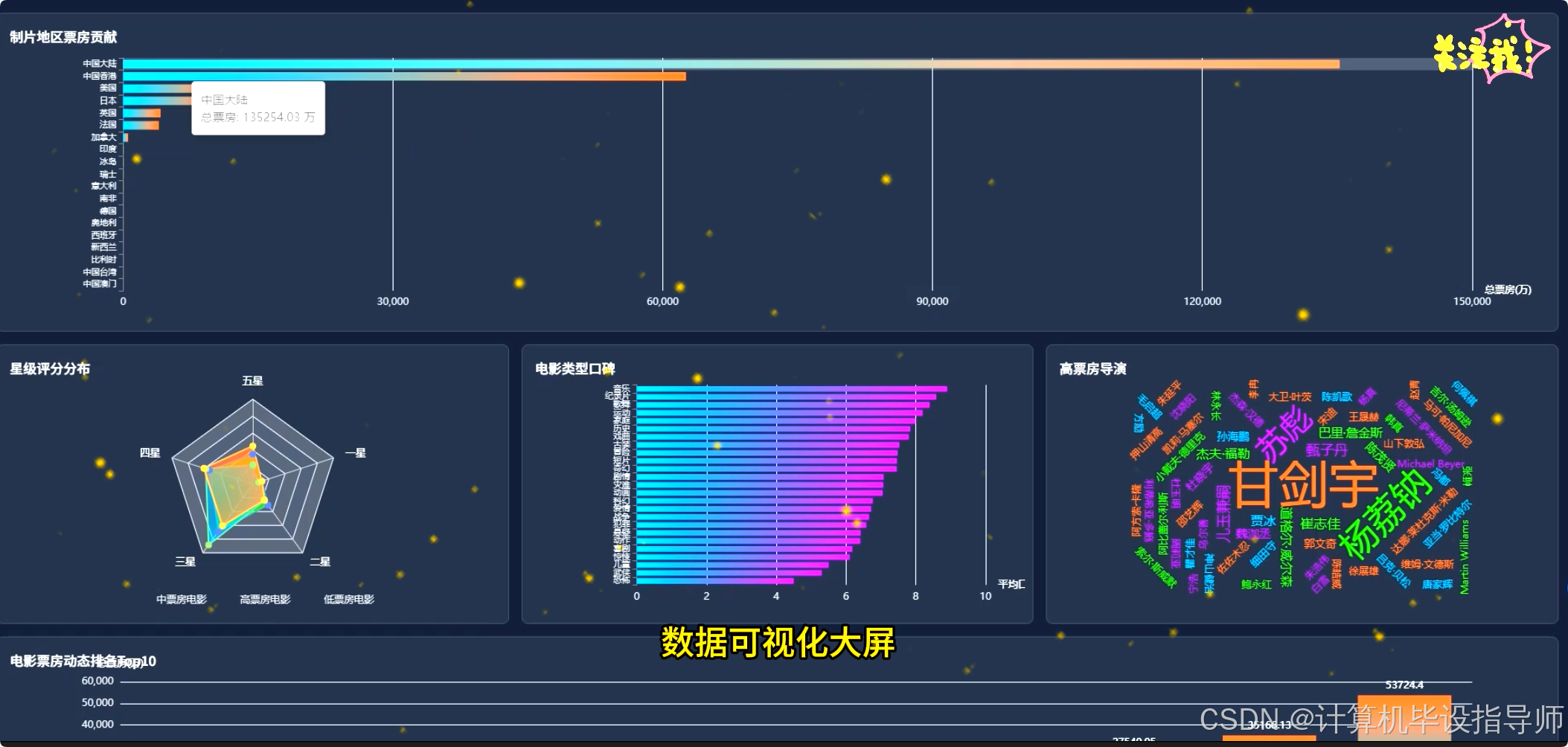
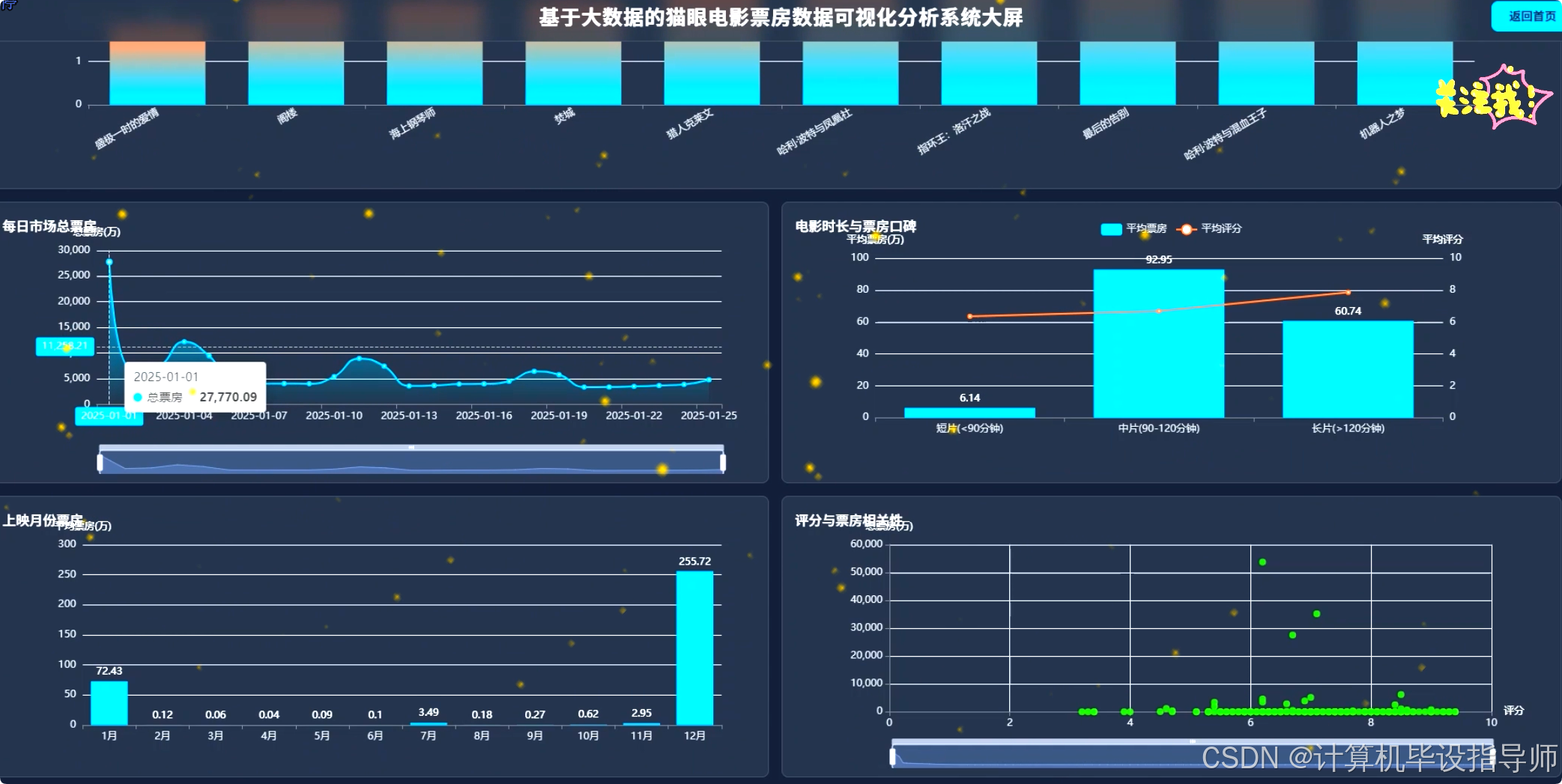
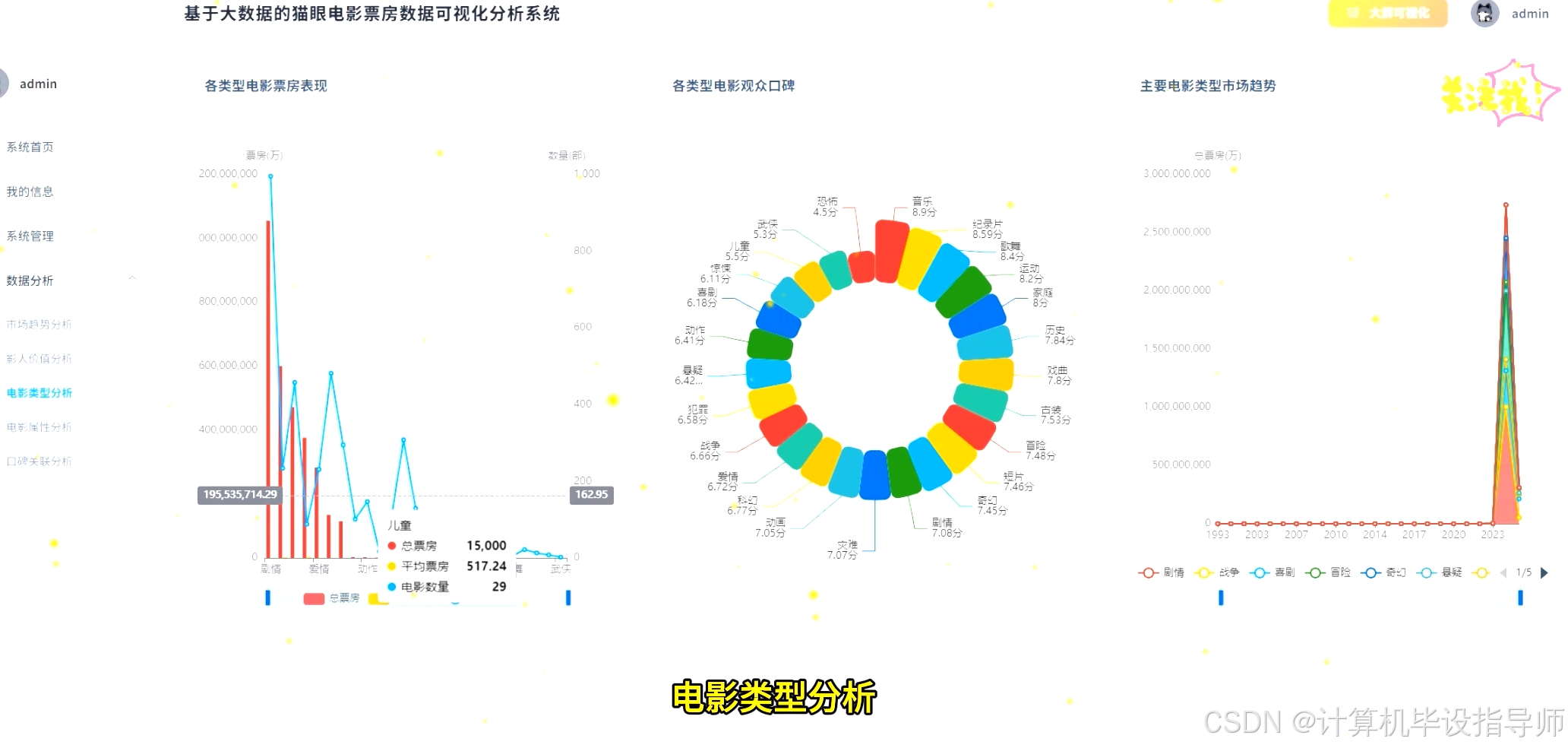
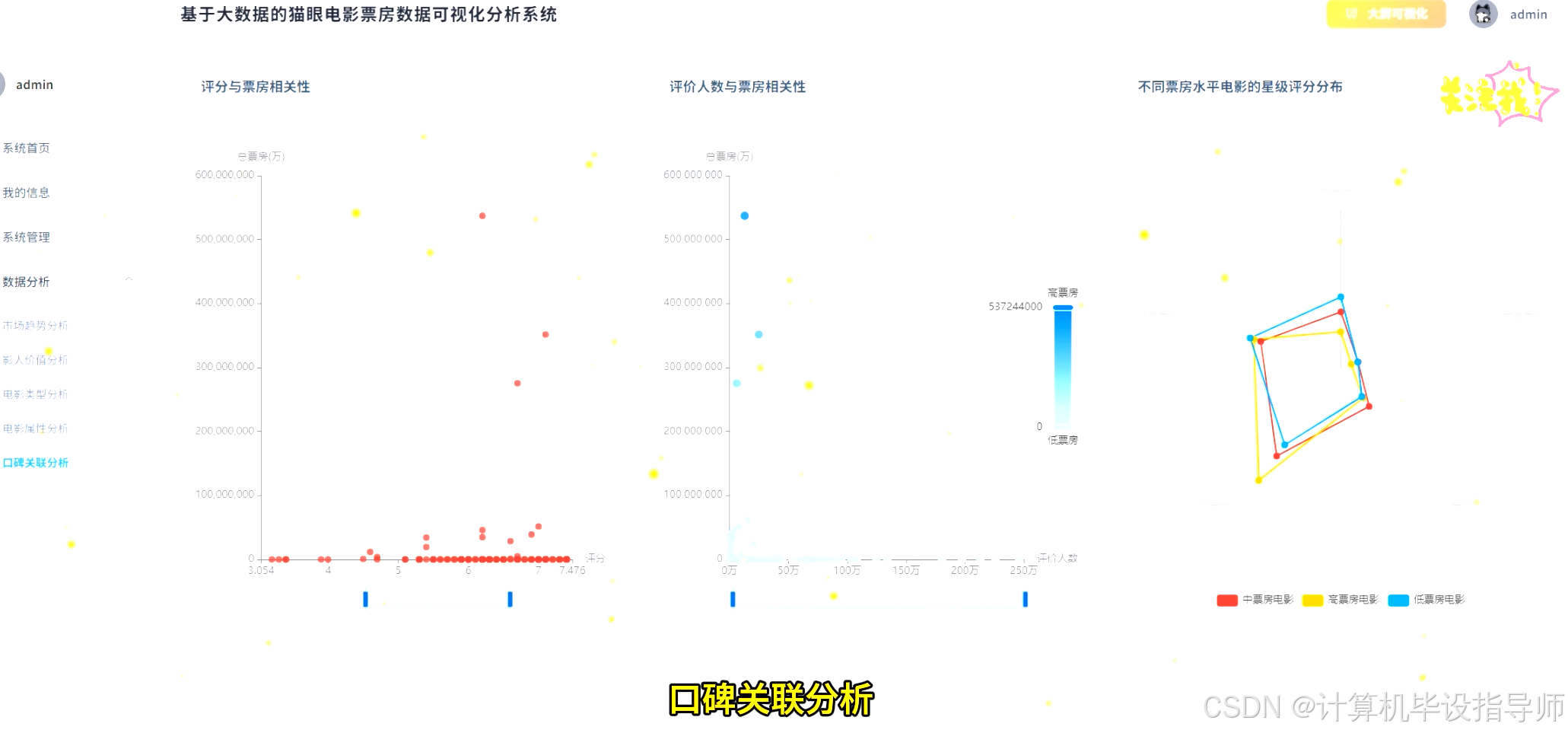
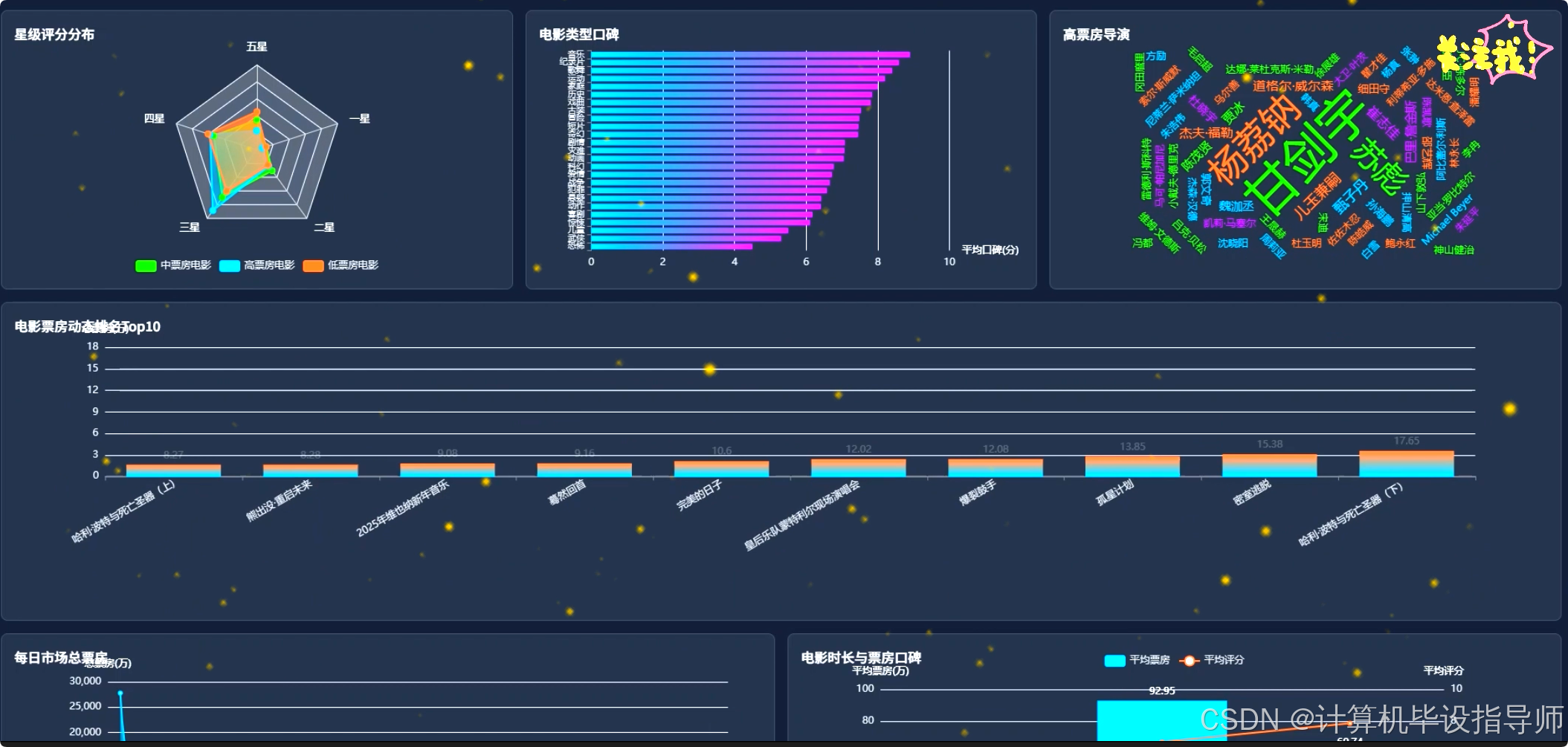
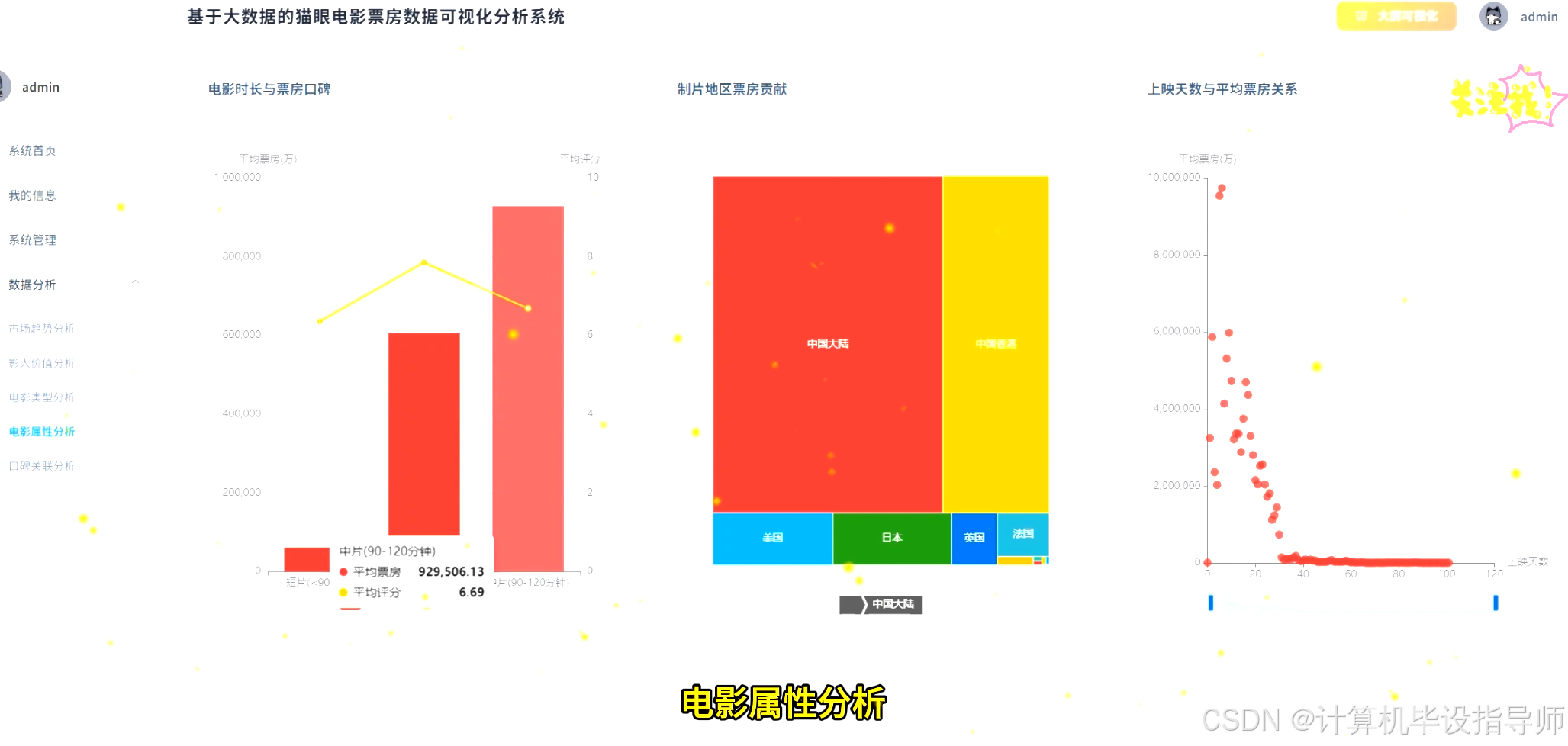
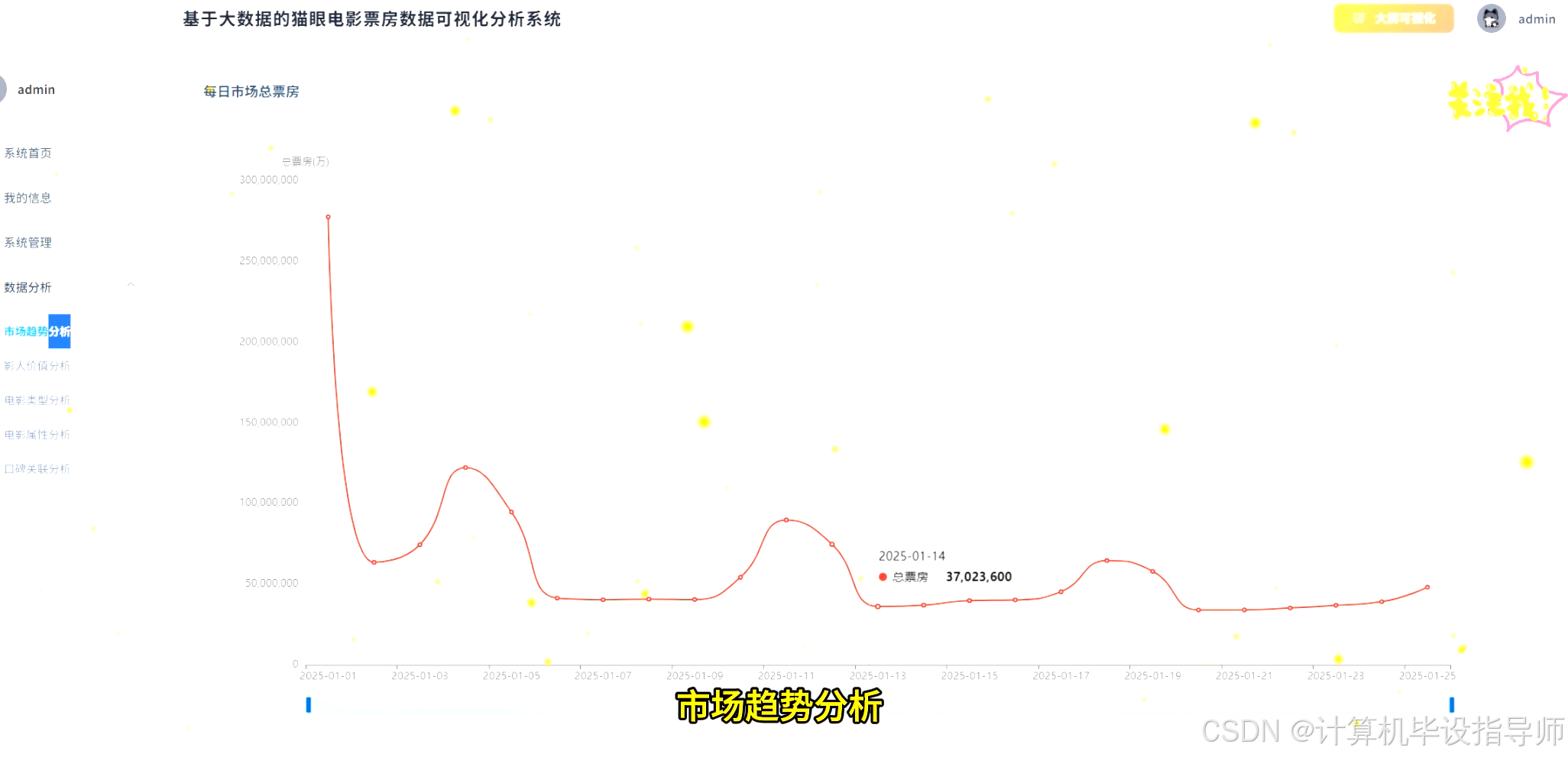
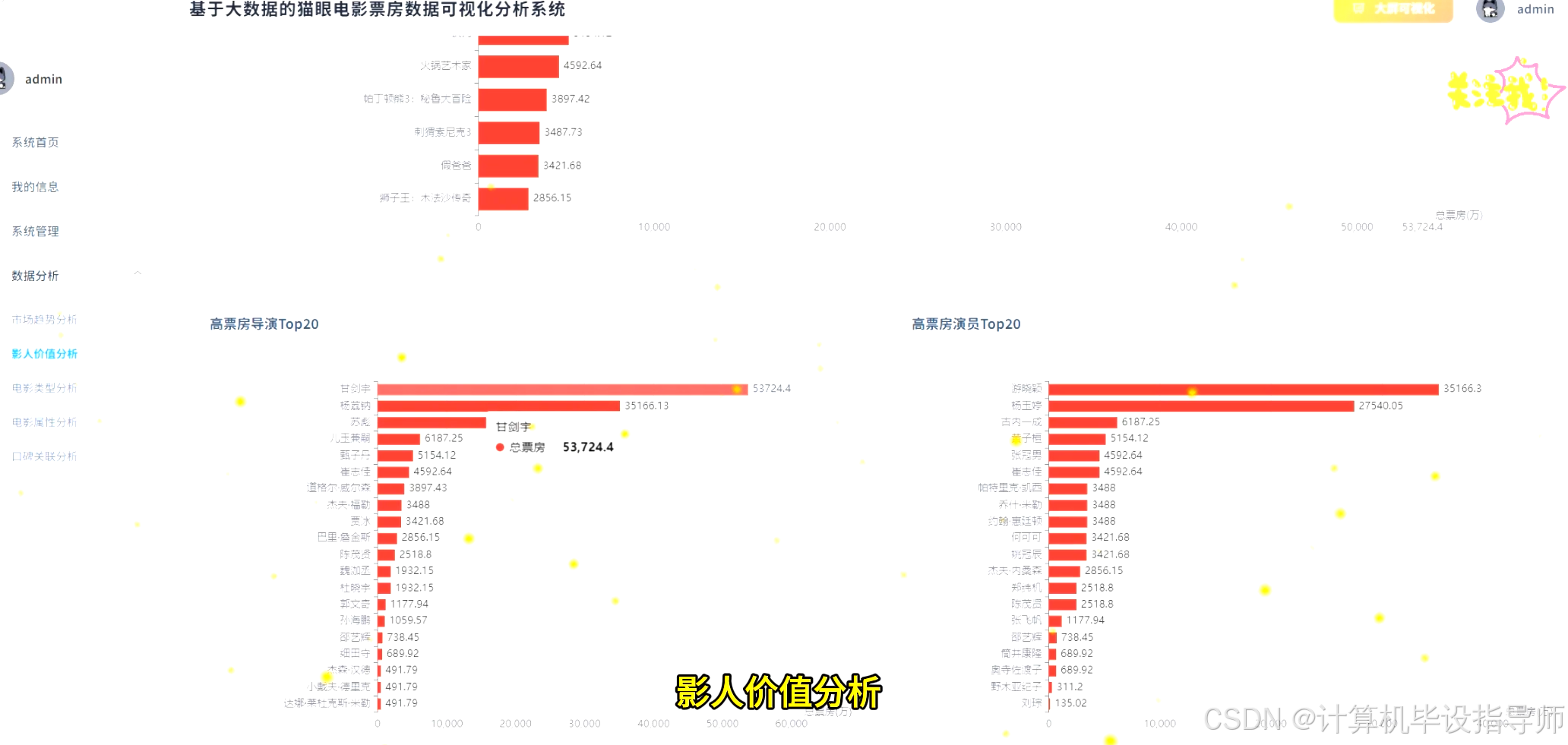

猫眼电影票房数据可视化分析系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum as _sum, avg as _avg, weekofyear, to_date
spark = SparkSession.builder.appName("MovieAnalysis").getOrCreate()
def analyze_daily_weekly_trend(spark):
xinxi_df = spark.read.csv("hdfs://path/to/XinXi.csv", header=True, inferSchema=True)
xinxi_df = xinxi_df.withColumn("date", to_date(col("日期"), "yyyy-MM-dd"))
daily_trend = xinxi_df.groupBy("date").agg(_sum(col("票房")).alias("daily_box_office")).orderBy("date")
weekly_trend = xinxi_df.withColumn("week", weekofyear(col("date"))).groupBy("week").agg(_sum(col("票房")).alias("weekly_box_office")).orderBy("week")
return daily_trend, weekly_trend
def analyze_genre_performance(spark):
dianying_df = spark.read.csv("hdfs://path/to/DianYing.csv", header=True, inferSchema=True)
xinxi_df = spark.read.csv("hdfs://path/to/XinXi.csv", header=True, inferSchema=True)
genre_performance = dianying_df.join(xinxi_df, "电影名", "inner") \
.groupBy(col("类型1").alias("genre")) \
.agg(_sum(col("票房")).alias("total_box_office"), _avg(col("评分")).alias("avg_rating"), _avg(col("票房")).alias("avg_box_office")) \
.orderBy(col("total_box_office").desc())
return genre_performance
def analyze_rating_vs_box_office(spark):
dianying_df = spark.read.csv("hdfs://path/to/DianYing.csv", header=True, inferSchema=True)
xinxi_df = spark.read.csv("hdfs://path/to/XinXi.csv", header=True, inferSchema=True)
movie_total_box_office = xinxi_df.groupBy("电影名").agg(_sum(col("票房")).alias("total_box_office"))
rating_box_office_data = dianying_df.join(movie_total_box_office, "电影名", "inner") \
.select(col("评分").alias("rating"), col("total_box_office")) \
.filter(col("rating").isNotNull() & col("total_box_office").isNotNull()) \
.orderBy(col("rating"))
return rating_box_office_data猫眼电影票房数据可视化分析系统-结语
本系统基本完成了基于Hadoop的猫眼电影票房数据可视化分析的设计与实现,成功搭建了一个从数据存储到前端展示的全流程分析平台。通过运用Spark SQL等技术,实现了对电影票房数据的多维度高效分析。当然,系统在数据源广度、分析模型复杂度等方面仍有提升空间。总体而言,本项目验证了大数据技术在电影数据分析领域的应用可行性,具有一定的实践参考价值。
同学们,毕设选题是不是还在头疼?这个基于Hadoop的电影票房分析系统,从技术选型到功能实现都给你理得明明白白,希望能给你带来一些思路。如果觉得这个项目对你有帮助,别忘了给UP主一个【一键三连】鼓励一下!有任何关于技术实现或者选题的问题,都欢迎在评论区留言,咱们一起交流讨论,共同进步!更多毕设干货和源码,可以来我主页看看哦。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡如果遇到具体的技术问题或其他需求,你也可以问我,我会尽力帮你分析和解决问题所在,支持我记得一键三连,再点个关注,学习不迷路!~~