16.内置模块

python
import os
import time
import random
...
# ctrl + 左键点击 --> 跳转至模块详情页📝 代码总结
- 核心知识点:内置标准库模块引入与源码探索
- 实现逻辑:导入常用系统模块,利用 IDE 快捷键跳转查看底层实现代码
- 关键语法 :
import os/time/random - 功能作用:引导开发者探索 Python 标准库底层逻辑,培养阅读源码与理解内置机制的习惯
17.模块导入方式-1
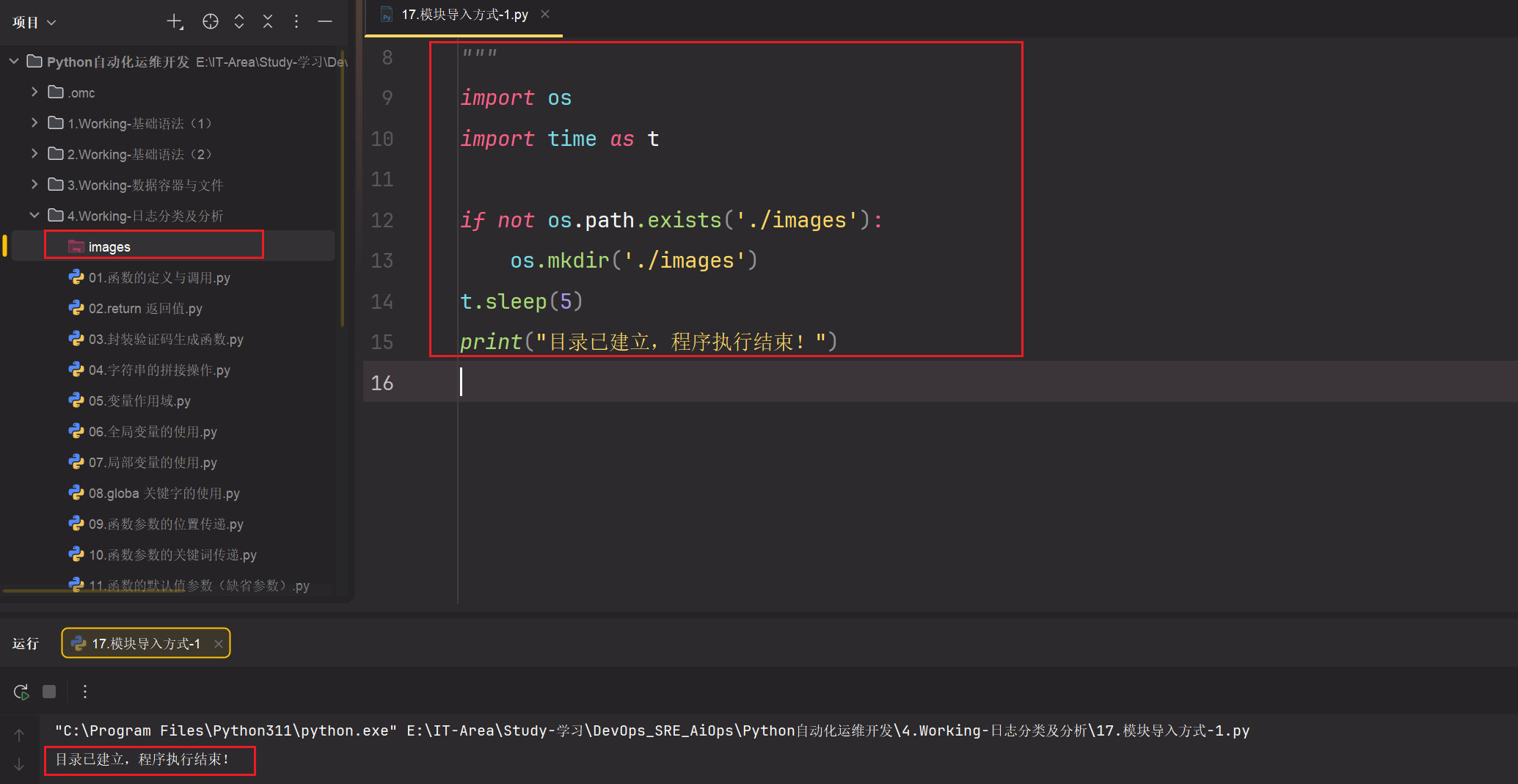
python
"""
import 导入基本语法:
import 模块名称
import 模块名称 as 别名 --> 简化后续操作
调用模块中的相关功能(函数)
模块名称.函数名称()
别名.函数名称()
"""
import os
import time as t
if not os.path.exists('./images'):
os.mkdir('./images')
t.sleep(5)
print("目录已建立,程序执行结束!")📝 代码总结
- 核心知识点 :
import完整导入与别名机制 - 实现逻辑 :导入完整模块或设置简化别名,通过
模块.方法()前缀语法调用功能 - 关键语法 :
import module,import module as alias,alias.func() - 功能作用:演示标准模块引入方式,别名机制简化长模块名调用,提升代码简洁度
18.模块导入方式-2

python
'''
除了使用import导入以外,我们在工作中也经常使用from导入模块
基本语法
from 模块名称 import * => 类似import 模块名称,导入这个模块的所有内容
from 模块名称 import 函数名1, 函数名2, 函数名3 => 随用随取,用哪些功能就取出哪些功能
通过from导入的模块,调用语法
函数名称()
函数名1()
函数名2()
函数名3()
from方式导入的模块,在调用时,不需要添加模块的前缀,而是直接调用即可。
'''
from os import *
from random import randint
# 调用模块中的方法
if path.exists('images'):
rmdir('images')
# 调用模块中的方法 => randint
print(randint(1, 9))📝 代码总结
- 核心知识点 :
from ... import精准导入机制 - 实现逻辑:从模块中提取特定函数或全部内容,调用时省略模块前缀直接使用函数名
- 关键语法 :
from module import func,from module import *,func() - 功能作用:提供按需导入方式,减少命名空间冗余,简化高频函数的调用语法
19.math数学模块

python
# 数学计算 --> + - * / % **
n1 = 4
print(n1,n1 + n1,n1 - n1,n1 * n1,n1 / n1,n1 % n1,n1 ** 2)
print('#' * 10)
# 引入数学模块
import math
print(math.sqrt(9)) # sqrt -> 开平方根
print(math.ceil(0.3)) # ceil -> 向上取整(示例:0.3 -> 1)
print(math.floor(0.3)) # floor -> 向下取整(示例:0.3 -> 0)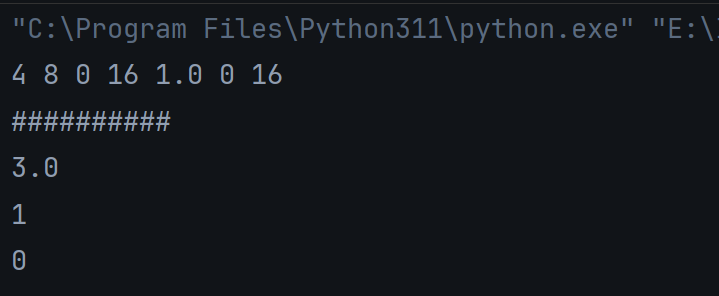
📝 代码总结
- 核心知识点 :基础幂运算与
math模块数学函数 - 实现逻辑 :使用内置
**运算符求幂;导入math模块调用平方根、向上/向下取整函数 - 关键语法 :
**,from math import sqrt, ceil, floor - 功能作用:扩展基础算术能力,演示标准数学库在复杂数值计算中的直接应用
20.内置魔法变量__name__
这是 Python 的惯用写法 。__name__ 是 Python 模块的内置属性:
- 当这个文件直接被 Python 执行 时,
__name__等于'__main__' - 当这个文件被别的模块导入 (
import)时,__name__等于文件名,不会执行这里的代码
python
# 把my_file.py当做一个配角,辅助主文件(主角)完成某些功能
import my_file
python
# my_file.py
print(__name__)
print(type(__name__))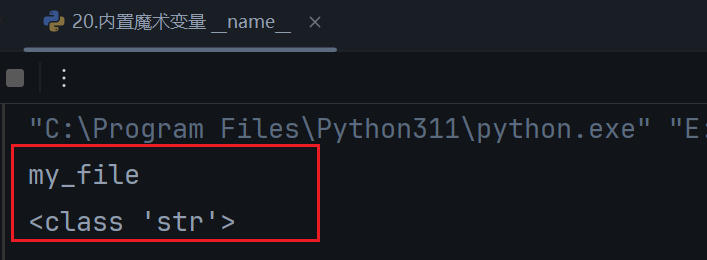
📝 代码总结
- 核心知识点:模块依赖导入与执行上下文概念引入
- 实现逻辑:导入辅助模块文件,为后续主程序入口机制与模块隔离做铺垫
- 关键语法 :
import my_file - 功能作用:演示文件间的依赖关系,引出 Python 文件作为模块被导入时的执行环境差异
21.自定义模块使用
python
# 角色:主角(主文件、主程序)
# 1. 导入模块
# 导入模块只是把模块的功能导入进来,本质模块中的功能不能直接执行
# 第一种导入 import my_script
# 第二种导入 from my_script import sum_num, sub_num
# 2. 准备调用模块中的方法(还未调用)
# 3. 调用模块中的方法
# 针对第一种调用方式 print(my_script.sum_num(10, 20))
# 针对第二种调用方式 print(sum_num(10, 20))📝 代码总结
- 核心知识点:自定义模块的导入规范与调用语法对比
- 实现逻辑:注释梳理两种导入方式及对应调用语法,明确"导入≠执行"的模块化原则
- 关键语法 :
import module/from module import func - 功能作用:建立模块化编程思维,区分导入阶段与执行阶段,规范跨文件功能引用方式
22.项目主程序入口文件
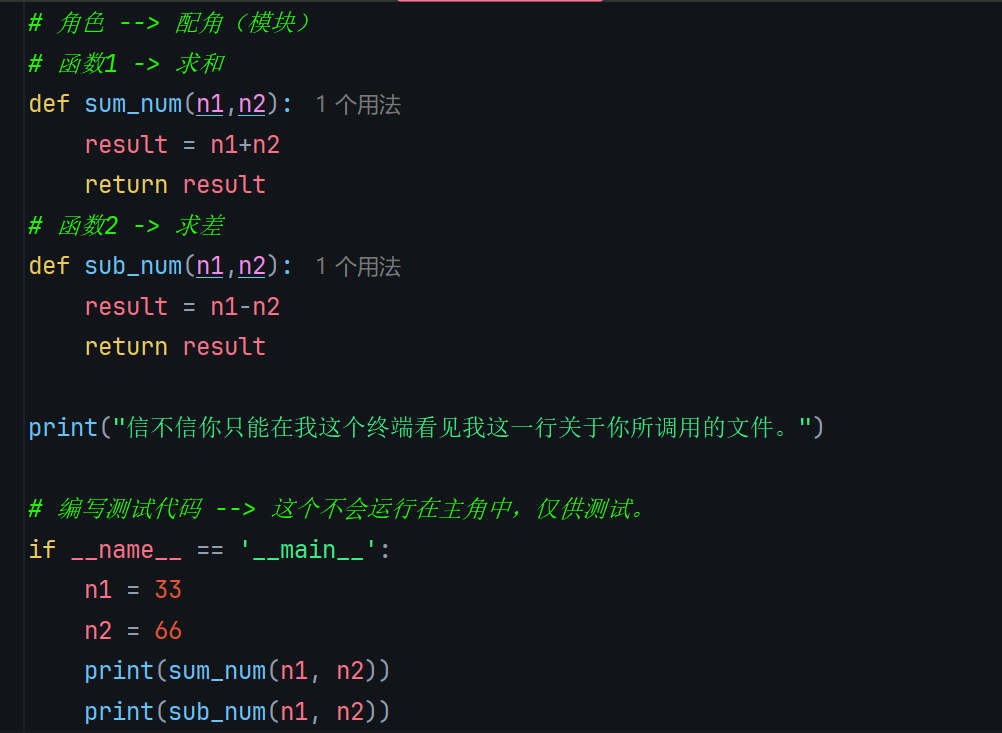
bash
# my_script.py
# 角色 --> 配角(模块)
# 函数1 -> 求和
def sum_num(n1,n2):
result = n1+n2
return result
# 函数2 -> 求差
def sub_num(n1,n2):
result = n1-n2
return result
print("信不信你只能在我这个终端看见我这一行关于你所调用的文件。")
# 编写测试代码 --> 这个不会运行在主角中,仅供测试。
if __name__ == '__main__':
n1 = 33
n2 = 66
print(sum_num(n1, n2))
print(sub_num(n1, n2))
python
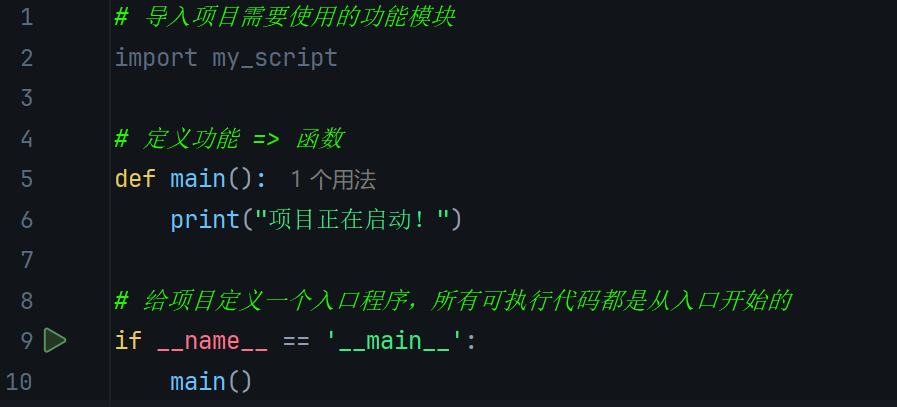
# 导入项目需要使用的功能模块
import my_script
# 定义功能 => 函数
def main():
print("项目正在启动!")
# 给项目定义一个入口程序,所有可执行代码都是从入口开始的
if __name__ == '__main__':
main()
📝 代码总结
- 核心知识点 :
if __name__ == '__main__':程序入口规范 - 实现逻辑:导入模块后定义启动函数,通过魔术变量判断当前文件是否为主运行文件,决定是否执行入口逻辑
- 关键语法 :
if __name__ == '__main__': - 功能作用:规范项目执行起点,防止模块被导入时意外执行测试代码,符合 Python 工程最佳实践
23.datetime模块strptime使用
python
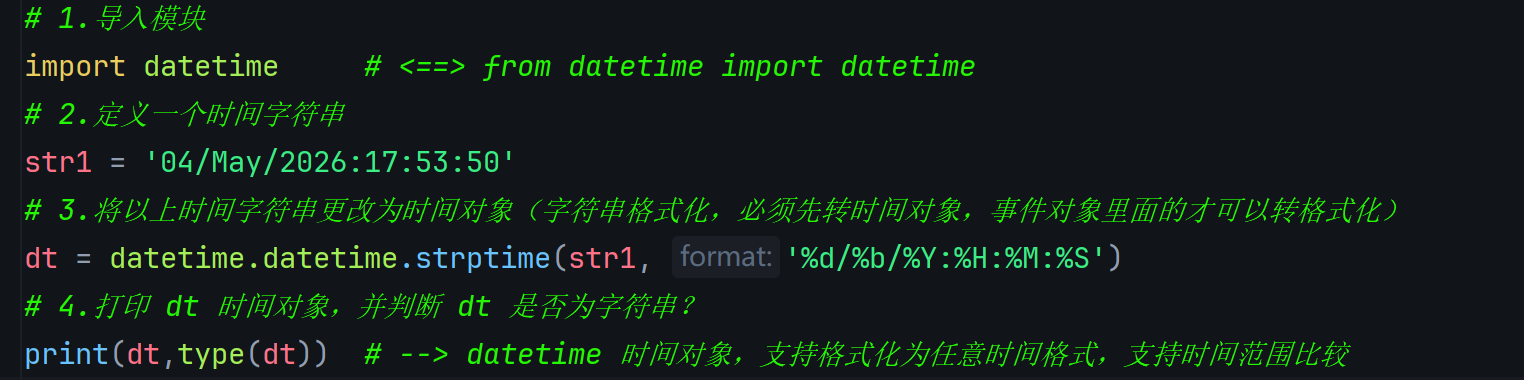
# 1. 导入模块
from datetime import datetime
# 2. 定义一个时间字符串
str1 = '09/May/2025:15:04:51'
# 3. 把以上时间格式更改为时间对象(字符串格式化,必须先转时间对象,时间对象里面的方法才能格式化)
dt = datetime.strptime(str1, '%d/%b/%Y:%H:%M:%S')
# 4. 打印dt时间对象
print(dt)
# 5. 判断dt是否为字符串?
print(type(dt)) # datetime时间对象,支持格式化为任意时间格式、支持时间范围比较
📝 代码总结
- 核心知识点 :
datetime.strptime字符串转时间对象 - 实现逻辑 :导入模块,定义非标准时间字符串,按格式模板解析为
datetime对象 - 关键语法 :
datetime.strptime(str, format) - 功能作用:实现日志/文本时间到 Python 时间对象的转换,为后续时间计算与比较奠定基础
24.datetime模块strftime使用

python
from datetime import datetime
str1 = '04/May/2026:17:53:50'
print(str1,type(str1),"时间字符串")
dt = datetime.strptime(str1, '%d/%b/%Y:%H:%M:%S')
print(dt, type(dt),"时间字符串 --> 时间对象 (字符串格式化)")
new_time = datetime.strftime(dt, '%Y/%m/%d %H:%M:%S')
print(new_time,type(new_time),"时间对象 --格式化--> 字符串 (主要用于显示数据,不能进行范围比较)")
📝 代码总结
- 核心知识点 :
datetime.strftime时间对象转字符串 - 实现逻辑 :将已解析的
datetime对象按新格式模板重新序列化为标准字符串 - 关键语法 :
datetime.strftime(dt, format) - 功能作用:实现时间数据的展示层格式化,明确时间对象(用于计算)与字符串(用于显示)的用途边界
25.日期对象范围比较

python
'''
需求:获取2025-05-09 15:00:00 ~ 2025-05-09 15:30:00
判断一个时间是否位于范围区间 => 统一操作规范:不限制版本 => 兼容时间对象 => datetime
'''
# 1. 导入datetime时间模块
from datetime import datetime
# 2. 定义一个时间范围
start_time = datetime.strptime('09/May/2025:15:00:00', '%d/%b/%Y:%H:%M:%S') # datetime对象
end_time = datetime.strptime('09/May/2025:15:30:00', '%d/%b/%Y:%H:%M:%S') # datetime对象
# 3、定义一个日志时间,判断是否位于start_time与end_time之间
log_time = '09/May/2025:15:20:30'
log_time = datetime.strptime(log_time, '%d/%b/%Y:%H:%M:%S') # datetime对象
# 4. datetime支持直接比较
if start_time <= log_time <= end_time:
print('位于时间范围区间')
else:
print('不位于时间范围区间')📝 代码总结
- 核心知识点 :
datetime对象的时间区间比较 - 实现逻辑 :将起止时间与目标时间统一转为
datetime对象,使用链式比较运算符判断是否落在区间内 - 关键语法 :
start <= target <= end(datetime 对象) - 功能作用:演示时间对象原生支持大小比较的特性,提供安全、直观的时间范围过滤逻辑
26.Nginx访问日志指定时间过滤操作
python
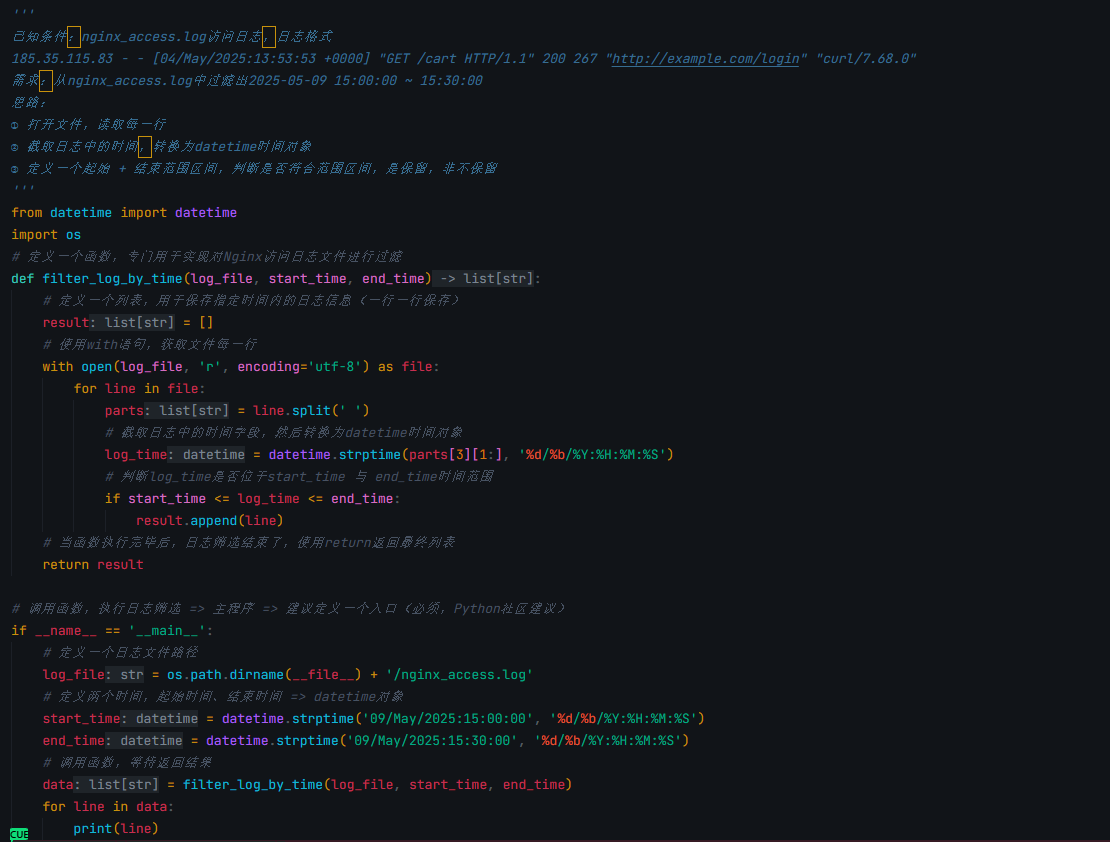
'''
已知条件:nginx_access.log访问日志,日志格式
185.35.115.83 - - [04/May/2025:13:53:53 +0000] "GET /cart HTTP/1.1" 200 267 "http://example.com/login" "curl/7.68.0"
需求:从nginx_access.log中过滤出2025-05-09 15:00:00 ~ 15:30:00
思路:
① 打开文件,读取每一行
② 截取日志中的时间,转换为datetime时间对象
③ 定义一个起始 + 结束范围区间,判断是否符合范围区间,是保留,非不保留
'''
from datetime import datetime
import os
# 定义一个函数,专门用于实现对Nginx访问日志文件进行过滤
def filter_log_by_time(log_file, start_time, end_time):
# 定义一个列表,用于保存指定时间内的日志信息(一行一行保存)
result = []
# 使用with语句,获取文件每一行
with open(log_file, 'r', encoding='utf-8') as file:
for line in file:
parts = line.split(' ')
# 截取日志中的时间字段,然后转换为datetime时间对象
log_time = datetime.strptime(parts[3][1:], '%d/%b/%Y:%H:%M:%S')
# 判断log_time是否位于start_time 与 end_time时间范围
if start_time <= log_time <= end_time:
result.append(line)
# 当函数执行完毕后,日志筛选结束了,使用return返回最终列表
return result
# 调用函数,执行日志筛选 => 主程序 => 建议定义一个入口(必须,Python社区建议)
if __name__ == '__main__':
# 定义一个日志文件路径
log_file = os.path.dirname(__file__) + '/nginx_access.log'
# 定义两个时间,起始时间、结束时间 => datetime对象
start_time = datetime.strptime('09/May/2025:15:00:00', '%d/%b/%Y:%H:%M:%S')
end_time = datetime.strptime('09/May/2025:15:30:00', '%d/%b/%Y:%H:%M:%S')
# 调用函数,等待返回结果
data = filter_log_by_time(log_file, start_time, end_time)
for line in data:
print(line)
📝 代码总结
- 核心知识点:日志时间过滤函数封装与工程化调用
- 实现逻辑 :逐行读取日志,切割提取时间字段转为
datetime对象,比对区间后符合条件则存入列表并返回;主程序规范入口调用 - 关键语法 :文件迭代,字符串切割,
strptime,区间判断,if __name__ == '__main__': - 功能作用:综合文件 I/O、时间处理与函数封装,实现真实运维场景的日志精准筛选工具
27.数据对象转换为JSON格式json.dump()
vscode 中使用
alt + shift + f转换为可读性更改的输出格式

python
import json
dict1 = {'name':'kaser','age':'21','address':'xian'}
dict2 = [{'name':'saker','age':'23','address':'shanghai'},{'name':'kkk','age':'26','address':'beijing'}]
# 单元素转化
with open('data-1.json','w') as file:
json.dump(dict1,file)
# 多元素转换
with open('data-2.json','w') as file:
json.dump(dict2,file)
print("python 对象转为 Json 数据转换完成,请查看相关文件!")

📝 代码总结
- 核心知识点 :Python 对象序列化 JSON (
json.dump) - 实现逻辑 :导入 json 模块,定义列表嵌套字典结构,使用
dump直接将内存对象写入 JSON 文件 - 关键语法 :
import json,json.dump(obj, file) - 功能作用:演示内存数据结构到 JSON 文件的持久化存储,支持复杂嵌套结构的直接转换
28.加载JSON文件到Python对象json.load()
python
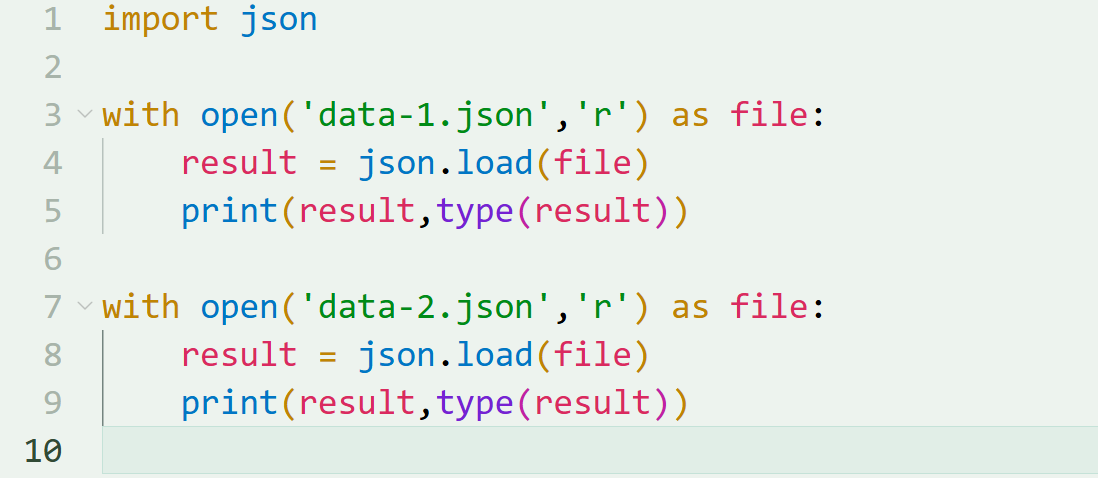
import json
# 读取JSON文件,把里面的数据转换为Python对象(如列表或者字典)
with open('data-1.json','r') as file:
result = json.load(file)
print(result,type(result))
# 读取JSON文件,把里面的数据转换为Python对象(如列表或者字典)
with open('data-2.json','r') as file:
result = json.load(file)
print(result,type(result))
📝 代码总结
- 核心知识点 :JSON 文件反序列化 (
json.load) - 实现逻辑 :打开 JSON 文件,使用
load读取内容并自动还原为 Python 列表/字典对象 - 关键语法 :
json.load(file) - 功能作用:实现 JSON 数据到内存对象的逆向转换,验证数据序列化/反序列化的完整闭环
29.对象转JSON格式数据之中文说明


python
import json
# 1. 定义一个Python字典对象
dict1 = {'name':'张三', 'age':23, 'address':'河南省郑州市'}
# 2. 把Python对象转换为JSON数据格式
with open('data.json', 'w', encoding='utf-8') as file:
json.dump(dict1, file, ensure_ascii=False)
# 3. 解析JSON文件到Python对象(列表、字典)
# with open('data.json', 'r', encoding='utf-8') as file:
# data = json.load(file)
# print(data)
📝 代码总结
- 核心知识点:JSON 序列化中文编码处理
- 实现逻辑 :序列化含中文字典时,添加
ensure_ascii=False参数防止中文被转义为 Unicode 编码 - 关键语法 :
json.dump(obj, file, ensure_ascii=False) - 功能作用:解决 JSON 存储中文时的可读性问题,确保跨语言数据交换时的字符保真与显示正确
30.实现Nginx访问日志分析与处理
nginx_access.log文件在文件夹中
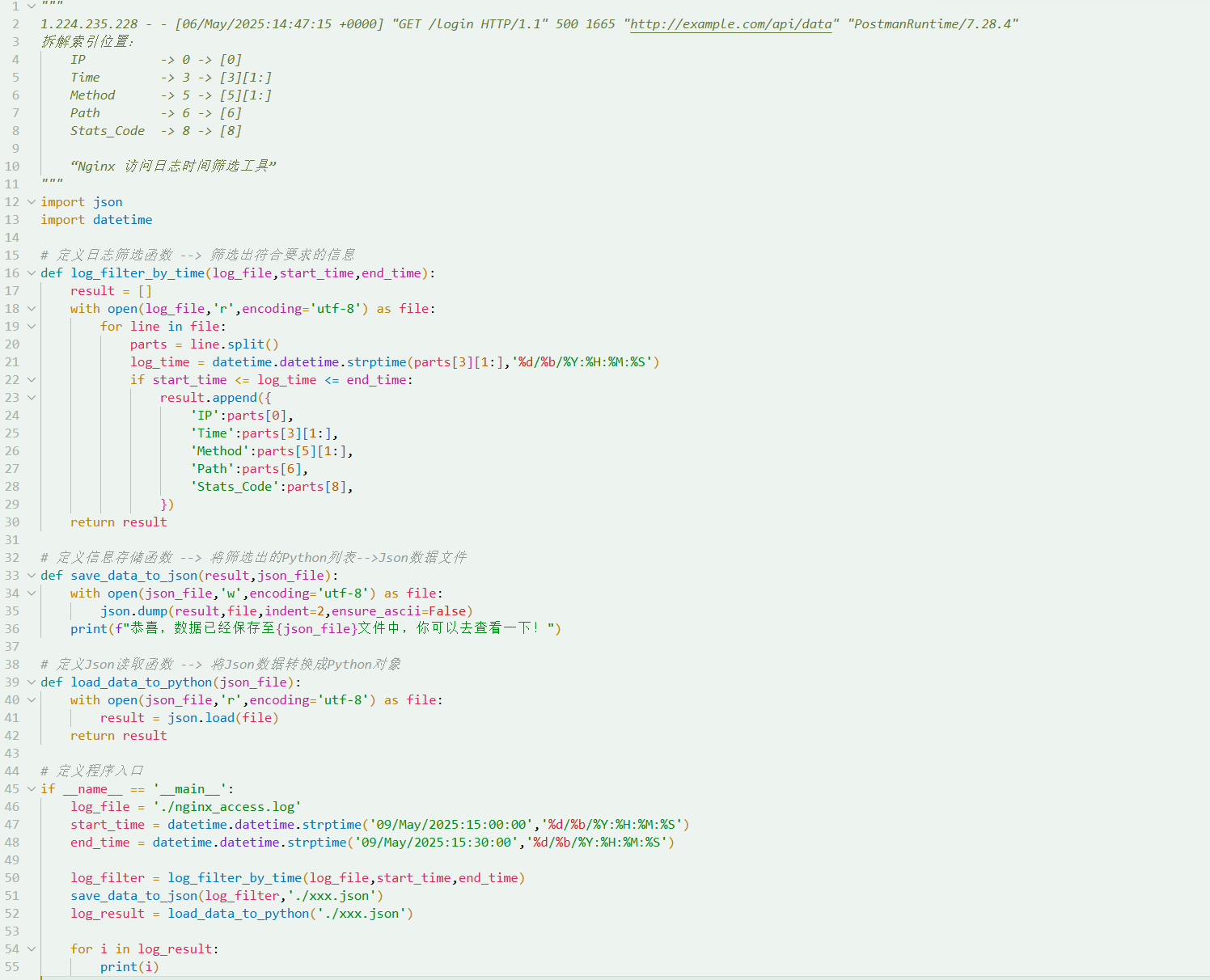
python
"""
1.224.235.228 - - [06/May/2025:14:47:15 +0000] "GET /login HTTP/1.1" 500 1665 "http://example.com/api/data" "PostmanRuntime/7.28.4"
拆解索引位置:
IP -> 0 -> [0]
Time -> 3 -> [3][1:]
Method -> 5 -> [5][1:]
Path -> 6 -> [6]
Stats_Code -> 8 -> [8]
"Nginx 访问日志时间筛选工具"
"""
import json
import datetime
# 定义日志筛选函数 --> 筛选出符合要求的信息
def log_filter_by_time(log_file,start_time,end_time):
result = []
with open(log_file,'r',encoding='utf-8') as file:
for line in file:
parts = line.split()
log_time = datetime.datetime.strptime(parts[3][1:],'%d/%b/%Y:%H:%M:%S')
if start_time <= log_time <= end_time:
result.append({
'IP':parts[0],
'Time':parts[3][1:],
'Method':parts[5][1:],
'Path':parts[6],
'Stats_Code':parts[8],
})
return result
# 定义信息存储函数 --> 将筛选出的Python列表-->Json数据文件
def save_data_to_json(result,json_file):
with open(json_file,'w',encoding='utf-8') as file:
json.dump(result,file,indent=2,ensure_ascii=False)
print(f"恭喜,数据已经保存至{json_file}文件中,你可以去查看一下!")
# 定义Json读取函数 --> 将Json数据转换成Python对象
def load_data_to_python(json_file):
with open(json_file,'r',encoding='utf-8') as file:
result = json.load(file)
return result
# 定义程序入口
if __name__ == '__main__':
log_file = './nginx_access.log'
start_time = datetime.datetime.strptime('09/May/2025:15:00:00','%d/%b/%Y:%H:%M:%S')
end_time = datetime.datetime.strptime('09/May/2025:15:30:00','%d/%b/%Y:%H:%M:%S')
log_filter = log_filter_by_time(log_file,start_time,end_time)
save_data_to_json(log_filter,'./xxx.json')
log_result = load_data_to_python('./xxx.json')
for i in log_result:
print(i)

📝 代码总结
- 核心知识点:日志解析、JSON 存储与读取全流程综合实战
- 实现逻辑:定义过滤函数提取日志关键字段构造字典列表;定义 JSON 读写函数封装序列化逻辑;主入口串联筛选、保存、回读打印全流程
- 关键语法 :函数模块化设计,
datetime解析,字典构造,json.dump/load,工程入口规范 - 功能作用:完整实现"日志解析→数据清洗→结构化存储→数据回读"的 ETL 流水线,展示模块化工程架构与真实数据处理能力