往期回顾
如何速成LLM以伪装成一个AI研究者(1)------循环,卷积,编解码器,注意力,Transformer
如何速成LLM以伪装成一个AI研究者(2)------Pre-LN,KV-Cache优化,MoE
如何速成LLM以伪装成一个AI研究者(3)------预训练,监督微调,强化学习RLHF/DPO
免责声明:作者也是伪装的,有错漏属于正常现象,欢迎评论指正。
PPO
PPO ,全程 Proximal Policy Optimization(近端策略优化) ,是OpenAI在2017年提出的算法:Proximal Policy Optimization Algorithms
PPO是在传统强化学习的脉络上诞生的算法,所以我们先回顾一下传统强化学习面临的是什么问题:Agent从状态 s 1 s_1 s1出发,在 T T T的时间单位内,要不断选择动作 a 1 , a 2 , ⋯ , a T a_1,a_2,\cdots,a_T a1,a2,⋯,aT,每一个时间单位做完动作 a t a_t at后,环境状态会变成 s t + 1 s_{t+1} st+1 (故交互过程可以形成轨迹 τ = ( s 1 , a 1 , s 2 , a 2 , ⋯ , s T , a T \tau=(s_1,a_1,s_2,a_2,\cdots,s_T,a_T τ=(s1,a1,s2,a2,⋯,sT,aT)。最终轨迹会有一个对应的奖励分数 R ( τ ) R(\tau) R(τ),也就是Agent完成这一系列动作的得分。
- 对于一个走迷宫游戏,动作是往上下左右走,状态是Agent的位置,初始状态是起点,而奖励是是否走到了终点。
- 对于数学题证明推导,动作是使用哪个数学定理,状态是已经完成的推导过程,初始状态是问题,奖励是是否成功证明。
- 对于LLM文本输出,动作是输出哪个token,状态是已经形成的句子,初始状态是用户指令,而奖励是最终的文本是否符合用户的心意。
直观想法是,我们想优化:
max θ J ( θ ) = max θ E τ ∼ π θ R ( τ ) = max θ ∑ τ P ( τ ∣ θ ) R ( τ ) \max_{\theta} J(\theta)=\max_{\theta} E_{\tau \sim \pi_{\theta}} R(\tau)=\max_{\theta} \sum_{\tau} P(\tau | \theta)R(\tau) θmaxJ(θ)=θmaxEτ∼πθR(τ)=θmaxτ∑P(τ∣θ)R(τ)
对这玩意求导可以推导:
∇ θ J ( θ ) = ∑ τ ∇ θ P ( τ ∣ θ ) R ( τ ) \nabla_{\theta} J(\theta)=\sum_{\tau} \nabla_{\theta}P(\tau | \theta)R(\tau) ∇θJ(θ)=∑τ∇θP(τ∣θ)R(τ)
= ∑ τ P ( τ ∣ θ ) ∇ θ P ( τ ∣ θ ) P ( τ ∣ θ ) R ( τ ) =\sum_{\tau} P(\tau | \theta) \frac{\nabla_{\theta}P(\tau | \theta)}{P(\tau | \theta)}R(\tau) =∑τP(τ∣θ)P(τ∣θ)∇θP(τ∣θ)R(τ)
= ∑ τ P ( τ ∣ θ ) ∇ θ log P ( τ ∣ θ ) R ( τ ) =\sum_{\tau} P(\tau | \theta) \nabla_{\theta} \log {P(\tau | \theta)}R(\tau) =∑τP(τ∣θ)∇θlogP(τ∣θ)R(τ)
= E τ ∼ π θ ∇ θ log P ( τ ∣ θ ) R ( τ ) =E_{\tau \sim \pi_{\theta}} \nabla_{\theta} \log P(\tau | \theta)R(\tau) =Eτ∼πθ∇θlogP(τ∣θ)R(τ)
又有 P ( τ ∣ θ ) = ∏ t = 0 T P ( s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) P(\tau | \theta) = \prod_{t=0}^T P(s_{t+1}|s_t,a_t) \pi_{\theta}(a_t|s_t) P(τ∣θ)=∏t=0TP(st+1∣st,at)πθ(at∣st)
故 ∇ θ log P ( τ ∣ θ ) = ∇ θ ∑ t = 0 T log P ( s t + 1 ∣ s t , a t ) + ∑ t = 0 T log π θ ( a t ∣ s t ) = ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) \nabla_{\theta} \log P(\tau | \theta)=\nabla_{\theta}\\sum_{t=0}\^T \\log P(s_{t+1}\|s_t,a_t)+\\sum_{t=0}\^T \\log \\pi_{\\theta} (a_t\|s_t)=\sum_{t=0}^T \nabla_{\theta} \log \pi_{\theta}(a_t|s_t) ∇θlogP(τ∣θ)=∇θ∑t=0TlogP(st+1∣st,at)+∑t=0Tlogπθ(at∣st)=∑t=0T∇θlogπθ(at∣st)
最终得到策略梯度为:
∇ θ J ( θ ) = E τ ∼ π θ ( ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) ) R ( τ ) \begin{equation} \nabla_{\theta}J(\theta)=E_{\tau \sim \pi_{\theta}} (\sum_{t=0}^T \nabla_{\theta} \log \pi_{\theta}(a_t|s_t))R(\tau) \end{equation} ∇θJ(θ)=Eτ∼πθ(t=0∑T∇θlogπθ(at∣st))R(τ)
这个 E E E可以使用采样 m m m条轨迹的形式来近似拟合,最终使用 θ ← θ + α ∇ θ J ( θ ) \theta \leftarrow \theta+\alpha \nabla_{\theta} J(\theta) θ←θ+α∇θJ(θ),就可以用梯度下降算法优化策略函数了。这就是策略梯度算法(Policy Gradient Methods)。
但是策略梯度算法有个问题,就是它在实践中非常不稳定,梯度经常过大。所以人们希望在一次梯度更新之前,限制梯度更新的幅度。
但是目前这个算法还有各种各样的问题,所以需要慢慢解决。
问题1:使用 R ( τ ) R(\tau) R(τ)作为奖励,看不见每一步的贡献。
R ( τ ) R(\tau) R(τ)是整条轨迹的奖励,但是当整条轨迹奖励为正时,不代表轨迹的每个动作都是好的。所以,我们可以定义 优势函数 取代 R ( τ ) R(\tau) R(τ):
A ( s t , a t ) = Q ( s t , a t ) − V ( s t ) A(s_t,a_t)=Q(s_t,a_t)-V(s_t) A(st,at)=Q(st,at)−V(st)
其中 Q ( s t , a t ) = E τ ∼ π θ ∑ k = 0 ∞ γ k r t + k + 1 ∣ S t = s , A t = a Q(s_t,a_t)=E_{\tau \sim \pi_{\theta}} \\sum_{k=0}\^{\\infty} \\gamma\^k r_{t+k+1} \| S_t=s,A_t=a Q(st,at)=Eτ∼πθ∑k=0∞γkrt+k+1∣St=s,At=a, γ \gamma γ为超参数,一般小于1,表示离 t t t越近获得的奖励,和第 t t t步的关系越大。而 r t + k + 1 r_{t+k+1} rt+k+1则表示这一步的"部分分"。这个 Q Q Q代表了在状态 s t s_t st下选择动作 a t a_t at,遵循策略 π θ \pi_{\theta} πθ可以得到的期望累积折扣回报。
对于没有部分分,只有轨迹最终得分的情况,中间的步骤 r r r都为0,只有最后一步(第 T T T步的 r T r_T rT可能不为0)
而 V ( s t ) = E a t = s i m π θ ( ⋅ ∣ s t ) Q ( s t , a t ) V(s_t)=E_{a_t =sim \pi_{\theta}(\cdot|s_t)}Q(s_t,a_t) V(st)=Eat=simπθ(⋅∣st)Q(st,at),表示状态 s t s_t st下,遵循策略 π θ \pi_{\theta} πθ可以得到的期望累积折扣回报。
接下来,我们定义 A t ^ \hat{A_t} At^,这个加了小帽的符号,代表我们因为测不准 A t A_t At,所以对 A t A_t At的估计。为了估计这个 A t A_t At,我们需要训练一个Critic神经网络 ,用于估计 V ( s t ) V(s_t) V(st)。估计方法如下卡片所示:
GAE(Generalized Advantage Estimation,广义优势估计)
一种平衡优势函数的偏差(估计量期望值与真实值的差值)/方差的技巧。GAE需要额外定义一个超参数 λ ∈ 0 , 1 \lambda \in 0,1 λ∈0,1。
设 δ t V = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t^V=r_t+\gamma V(s_{t+1})-V(s_t) δtV=rt+γV(st+1)−V(st)为一步TD误差 。
则 A t ^ G A E = ∑ k = 0 ∞ ( γ λ ) k δ t + k V \hat{A_t}^{GAE}=\sum_{k=0}^{\infty} (\gamma \lambda)^k \delta_{t+k}^V At^GAE=∑k=0∞(γλ)kδt+kV(注意 δ \delta δ的公式里是有 γ \gamma γ的,而 λ \lambda λ只用在外面),这个公式被称为 T D ( λ ) TD(\lambda) TD(λ) 。
当 λ = 0 \lambda=0 λ=0时,这个估计退化为 A t ^ = δ t \hat{A_t}=\delta_t At^=δt,高偏差,无方差。
当 λ = 1 \lambda=1 λ=1时,这个估计退化为蒙特卡洛优势 A t ^ = ∑ k = 0 ∞ γ k δ t + k V \hat{A_t}=\sum_{k=0}^{\infty} \gamma^k \delta_{t+k}^V At^=∑k=0∞γkδt+kV,低偏差、高方差。
通过调节 λ \lambda λ(通常0.95-0.99),调节方差和偏差,从而加速收敛。
对于稀疏奖励(没有部分分)的情况,在 λ = 0 \lambda=0 λ=0时 A t ^ = γ V ( s t + 1 ) − V ( s t ) \hat{A_t}=\gamma V(s_{t+1})-V(s_t) At^=γV(st+1)−V(st),在 λ = 1 \lambda=1 λ=1时, A t ^ = γ T − 1 − t R ( τ ) − V ( s t ) \hat{A_t}=\gamma^{T-1-t}R(\tau)-V(s_t) At^=γT−1−tR(τ)−V(st)。
总之,知道有这个估计 A t ^ \hat{A_t} At^就可以了。然后就可以把策略梯度的表示修改:
∇ θ J ( θ ) = E τ ∼ π θ ( ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) A t ^ ) \begin{equation} \nabla_{\theta}J(\theta)=E_{\tau \sim \pi_{\theta}} (\sum_{t=0}^T \nabla_{\theta} \log \pi_{\theta}(a_t|s_t)\hat{A_t}) \end{equation} ∇θJ(θ)=Eτ∼πθ(t=0∑T∇θlogπθ(at∣st)At^)
而 V V V一般使用 均方误差(MSE) 进行训练,记 A t ^ = G t − V o l d ( s t ) \hat{A_t}=G_t-V_{old}(s_t) At^=Gt−Vold(st),则:
L o s s V = E τ ∼ π θ ∑ t = 1 T ( V ( s t ) − G t ) 2 Loss_V=E_{\tau \sim \pi_{\theta}}\\sum_{t=1}\^T(V(s_t)-G_t)\^2 LossV=Eτ∼πθt=1∑T(V(st)−Gt)2
问题2:我必须实时采样吗?
原始的策略梯度有一个问题,就是 τ ∼ π θ \tau \sim \pi_{\theta} τ∼πθ导致轨迹必须从当前策略模型获得。假如我想要一次性采样一大批数据,然后统一做一次梯度更新怎么办?
也即,我想优化的是:
max θ J ( θ ) = max θ E τ ∼ π θ R ( τ ) \max_{\theta} J(\theta)=\max_{\theta} E_{\tau \sim \pi_{\theta}} R(\tau) θmaxJ(θ)=θmaxEτ∼πθR(τ)
但是我实际的 τ \tau τ采样自 π o l d \pi_{old} πold。此时,考虑到:
E τ ∼ π θ R ( τ ) = ∫ π θ ( τ ) R ( τ ) d τ = ∫ π o l d ( τ ) π θ ( τ ) π o l d ( τ ) R ( τ ) d τ = E τ ∼ π o l d π θ ( τ ) π o l d ( τ ) R ( τ ) E_{\tau \sim \pi_{\theta}} R(\tau)=\int \pi_{\theta}(\tau) R(\tau)d\tau=\int \pi_{old}(\tau)\frac{ \pi_{\theta}(\tau)}{ \pi_{old}(\tau)} R(\tau)d\tau=E_{\tau \sim \pi_{old}} \frac{ \pi_{\theta}(\tau)}{ \pi_{old}(\tau)} R(\tau) Eτ∼πθR(τ)=∫πθ(τ)R(τ)dτ=∫πold(τ)πold(τ)πθ(τ)R(τ)dτ=Eτ∼πoldπold(τ)πθ(τ)R(τ)
记概率比值 r t ( θ ) = π θ ( a t ∣ s t ) π o l d ( a t ∣ s t ) r_t(\theta)=\frac{\pi_{\theta} (a_t |s_t)}{\pi_{old}(a_t|s_t)} rt(θ)=πold(at∣st)πθ(at∣st)。
则优化目标可以变成:
max θ J ( θ ) = r t ( θ ) A t ^ \begin{equation} \max_{\theta} J(\theta)=r_t(\theta)\hat{A_t} \end{equation} θmaxJ(θ)=rt(θ)At^
这样就可以降低采样的实时性,提升并行性和训练效率。
问题3:怎样控制梯度更新的幅度?
这就是PPO的核心,裁剪(clip) 技术。它会截断 r t ( θ ) r_t(\theta) rt(θ),限制它在 1 − ϵ , 1 + ϵ 1-\\epsilon, 1+\\epsilon 1−ϵ,1+ϵ区间内( ϵ \epsilon ϵ为超参数,一般取0.2左右)。
所以最终,PPO的优化目标是:
max θ J P P O ( θ ) = E min ( r t ( θ ) A \^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A \^ t ) \begin{equation} \max_{\theta} J_{PPO}(\theta)=E\\min (r_t(\\theta) \\hat{A}_t, clip(r_t(\\theta), 1-\\epsilon, 1+\\epsilon)\\hat{A}_t) \end{equation} θmaxJPPO(θ)=Emin(rt(θ)A\^t,clip(rt(θ),1−ϵ,1+ϵ)A\^t)
然后,还有独属于LLM的一个Trick:和DPO一样,我们希望RL对模型参数的更新不要偏离SFT后的直接结果 π r e f \pi_{ref} πref太远,所以会增加一个KL Penalty:
L P P O = min ( r t ( θ ) A ^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) − β D K L ( π θ ∥ π r e f ) L_{PPO}=\min (r_t(\theta) \hat{A}t, clip(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}t)-\beta D{KL}(\pi{\theta} \parallel \pi_{ref}) LPPO=min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)−βDKL(πθ∥πref)
最后总结:
整个PPO的训练过程,需要维护四个模型:
- 策略模型(Policy Model) π θ \pi_{\theta} πθ,即训练的目标。
- 价值模型(Value Model) V V V,参数随策略模型一起更新。
- 参考模型(Reference Model) π r e f \pi_{ref} πref,即SFT结束后的模型,也是策略/价值模型的初始化模型。冻结参数。
- 奖励模型(Reward Model) R ϕ R_{\phi} Rϕ,上一篇文章我们讲过它是怎么计算的,可以计算整个轨迹的奖励。冻结参数。
这也是它训起来"贵"的原因。
GRPO
相关论文:(2024年,DeepSeek)DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
GRPO (Group Relative Policy Optimization) 的主要优化目标是解决 V V V占显存还可能训练不稳定的问题。具体而言,它依靠 一个询问 q q q生成一组 G G G个输出 o 1 , o 2 , ⋯ , o G o_1,o_2,\cdots, o_G o1,o2,⋯,oG 替代原本的价值模型 V V V的作用。
假设 o 1 , o 2 , ⋯ , o G o_1,o_2,\cdots, o_G o1,o2,⋯,oG的Reward Model得分分别为 R ( q , o 1 ) , R ( q , o 2 ) , ⋯ , R ( q , o G ) R(q,o_1),R(q, o_2),\cdots, R(q,o_G) R(q,o1),R(q,o2),⋯,R(q,oG),则第 i i i个输出的第 t t t个token的 A ^ i , t \hat A_{i,t} A^i,t为:
A ^ i , t = R ( q , o i ) − m e a n ( R ( q , o ) ) s t d ( R ( q , o ) ) + ε \hat A_{i,t}=\frac{R(q, o_i)-mean(R(q,o))}{std(R(q,o))+\varepsilon} A^i,t=std(R(q,o))+εR(q,oi)−mean(R(q,o))
ε \varepsilon ε防止std为0。
最终:
max θ J G R P O ( θ ) = E 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( r t ( θ ) A \^ i , t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A \^ i , t ) \begin{equation} \max_{\theta} J_{GRPO}(\theta)=E\\frac{1}{G}\\sum_{i=1}\^G \\frac{1}{\|o_i\|}\\sum_{t=1}\^{\|o_i\|}\\min (r_t(\\theta) \\hat{A}_{i,t}, clip(r_t(\\theta), 1-\\epsilon, 1+\\epsilon)\\hat{A}_{i,t}) \end{equation} θmaxJGRPO(θ)=EG1i=1∑G∣oi∣1t=1∑∣oi∣min(rt(θ)A\^i,t,clip(rt(θ),1−ϵ,1+ϵ)A\^i,t)
是的,没错,这是一个完全 output级 的优势计算,没有使用 token级 的信息,相应地,GAE之类的技巧也就用不到了。可谓简单粗暴,力大砖飞,但又行之有效。
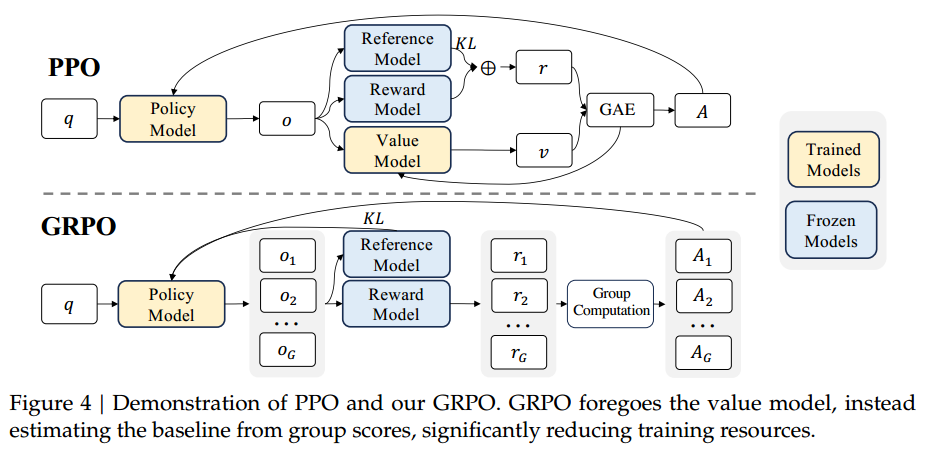
GRPO的优点很明显:舍弃了训练不稳定的Value Model,节省内存,并且让训练更加稳定。
但它的缺点也同样明显:Advantage完全token无关,对于长回答粒度不足,容易分不清哪部分是对reward有贡献,哪一部分没有,从而可能训崩。
DAPO
相关论文:(2025年,ByteDance Seed)DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO (Decouple Clip and Dynamic sAmpling Policy Optimization,好复杂的缩写啊!) 主要面向长CoT(Chain of Thought)的改进,使用了多个Trick。
Tirck 1: Clip-Higher
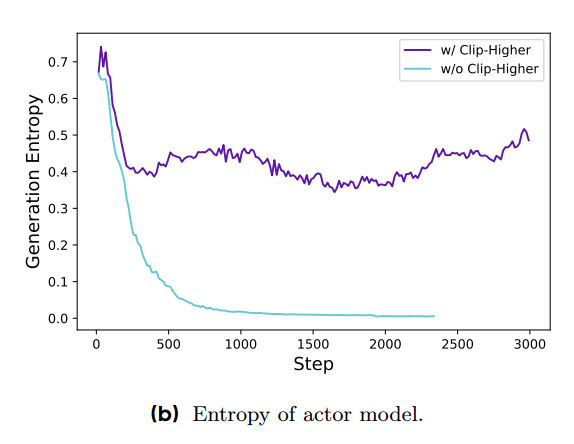
在作者们的实验中,经常观察到Entropy Collapse的现象。
Entropy Collapse
假如词表大小为 V V V,模型在给定上下文下预测下一个 token 的概率分布为 p 1 , p 2 , ⋯ , p V p_1,p_2,\\cdots,p_V p1,p2,⋯,pV,则Entropy(熵)为 H = − ∑ i = 1 V p i log p i H=-\sum_{i=1}^V p_i \log p_i H=−∑i=1Vpilogpi。熵是模型训练过程中的一个重要监控指标。如果熵过高说明模型的策略还未收敛,但如果熵过低(Entropy Collapse),也是不好的,因为这说明:(1)模型的输出模式单一,难以探索新的策略。(2)模型输出极容易陷入死循环。
在GRPO继承自PPO的clip技巧中, c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i ) clip(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}i) clip(rt(θ),1−ϵ,1+ϵ)A^i)这一项的clip是左右对称的,DAPO的作者认为这不利于探索,是导致Entropy Collapse的主要原因之一。具体地,他们解耦了clip的上下界,用了两个参数 ϵ l o w \epsilon{low} ϵlow和 ϵ h i g h \epsilon_{high} ϵhigh将clip改成了 c l i p ( r t ( θ ) , 1 − ϵ l o w , 1 + ϵ h i g h ) A ^ i ) clip(r_t(\theta), 1-\epsilon_{low}, 1+\epsilon_{high})\hat{A}i) clip(rt(θ),1−ϵlow,1+ϵhigh)A^i),并且令 ϵ h i g h > ϵ l o w \epsilon{high}>\epsilon_{low} ϵhigh>ϵlow。
回顾 r t ( θ ) r_t(\theta) rt(θ)的定义,它表示的是当前policy产生这个token的概率,比上policy更新前产生这个token的概率。也就是说,如果 r t ( θ ) > 1 r_t(\theta)>1 rt(θ)>1,表示这个token的概率被增加了,如果小于1,则表示这个token的概率被减少了。前者发生在 A ^ i > 0 \hat{A}_i>0 A^i>0时,后者则发生在 A ^ i < 0 \hat{A}i<0 A^i<0时。DAPO放宽 ϵ h i g h \epsilon{high} ϵhigh的主要目的是:对于出现概率较低,但是比较好的行为,给予更宽容的更新幅度,鼓励模型探索出新的优秀行为模式。
Tirck 2: Dynamic Sampling
在GRPO中,假如一组的output全部正确或者错误,则归一化后的优势值 A ^ i , t = R ( q , o i ) − m e a n ( R ( q , o ) ) s t d ( R ( q , o ) ) + ε \hat A_{i,t}=\frac{R(q, o_i)-mean(R(q,o))}{std(R(q,o))+\varepsilon} A^i,t=std(R(q,o))+εR(q,oi)−mean(R(q,o))为0,意味着该批次的样本对训练完全没有贡献。因此在采样过程中,DAPO会先把这种样本组给剔除。如果因为剔除机制导致样本数量填不满batch,则会对这些被剔除的 q q q进行重采样。
Trick 3: Token-Level Policy Gradient Loss
在原版GRPO中,有一项 1 G ∑ i = 1 G \frac{1}{G}\sum_{i=1}^G G1∑i=1G,即视作每一条回答(无论是长是短)对策略梯度贡献均等。而DAPO认为应该是每个token共享均等,于是将原公式的: 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ \frac{1}{G}\sum_{i=1}^G \frac{1}{|o_i|}\sum_{t=1}^{|o_i|} G1∑i=1G∣oi∣1∑t=1∣oi∣改为了 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ \frac{1}{\sum_{i=1}^G |o_i|}\sum_{i=1}^G \sum_{t=1}^{|o_i|} ∑i=1G∣oi∣1∑i=1G∑t=1∣oi∣。
Trick 4: Overlong Reward Shaping
"软化"奖励中的长度惩罚,提高对超长输出的容忍度。和强化学习算法关联较小,故略。
Trick 5 : 取消KL-Penalty
在长CoT的训练实践中,最终的策略模型和初始策略模型的差距可能较大,因此取消了KL-Penalty这一项。
汇总一下,DAPO的主要公式为:
max θ J D A P O ( θ ) = E 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ min ( r t ( θ ) A \^ i , t , c l i p ( r t ( θ ) , 1 − ϵ l o w , 1 + ϵ h i g h ) A \^ i , t ) \begin{equation} \max_{\theta} J_{DAPO}(\theta)=E\\frac{1}{\\sum_{i=1}\^G \|o_i\|}\\sum_{i=1}\^G \\sum_{t=1}\^{\|o_i\|}\\min (r_t(\\theta) \\hat{A}_{i,t}, clip(r_t(\\theta), 1-\\epsilon_{low}, 1+\\epsilon_{high})\\hat{A}_{i,t}) \end{equation} θmaxJDAPO(θ)=E∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣min(rt(θ)A\^i,t,clip(rt(θ),1−ϵlow,1+ϵhigh)A\^i,t)
GSPO
相关论文:(2025年,Qwen)Group Sequence Policy Optimization
相信看了前面的算法,你肯定会有一个疑问:GRPO系用全局回答的奖励算具体token的优势,一个回答序列里所有的token的优势都是一样的,这合理吗?感觉不太合理啊?
GSPO (Group Sequence Policy Optimization) 也觉得这件事不太合理,甚至表示,GRPO的token级优化目标是"病态(ill-posed)"的。具体地,对于重要性比率(importance sampling ratio):
r t ( θ ) = π θ ( o t ∣ q , o < t ) π o l d ( o t ∣ q , o < t ) r_t(\theta)=\frac{\pi_{\theta} (o_t |q,o_{<}t)}{\pi_{old}(o_t|q,o_{<t})} rt(θ)=πold(ot∣q,o<t)πθ(ot∣q,o<t)
它有如下问题:
- 高方差问题。由于每个token的权重是近乎独立计算的,随着序列增长,这些权重的乘积(即整个序列的权重)的方差会迅速累积。这导致梯度估计充满噪声,训练变得非常不稳定,模型甚至很容易"崩溃"。
- 由于MoE会对每个token分配专家,当策略更新时,token级别的路由决策可能发生剧烈变化,这会进一步显著加剧方差。
- GRPO的每个token的优势值一致,这会导致长序列中的少量异常token严重影响其他所有token的优势值。
因此,GSPO完全放弃了token级优势,而是使用序列级优势来替代:
max θ J G S P O ( θ ) = E 1 G ∑ i = 1 G min ( s i ( θ ) A \^ i , c l i p ( s i ( θ ) , 1 − ϵ , 1 + ϵ ) A \^ i ) \begin{equation} \max_{\theta} J_{GSPO}(\theta)=E\\frac{1}{G}\\sum_{i=1}\^G\\min (s_i(\\theta) \\hat{A}_i, clip(s_i(\\theta), 1-\\epsilon, 1+\\epsilon)\\hat{A}_i) \end{equation} θmaxJGSPO(θ)=EG1i=1∑Gmin(si(θ)A\^i,clip(si(θ),1−ϵ,1+ϵ)A\^i)
其中
s i ( θ ) = ( π θ ( o i ∣ q ) π o l d ( o i ∣ q ) ) 1 ∣ o i ∣ = e x p ( 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ log π θ ( o i , t ∣ q , o i < t ) π o l d ( o i , t ∣ q , o i < t ) ) s_i(\theta)=(\frac{\pi_{\theta} (o_i |q)}{\pi_{old} (o_i|q)})^{\frac{1}{|o_i|}}=exp(\frac{1}{|o_i|}\sum_{t=1}^{|o_i|} \log \frac{\pi_{\theta}(o_{i,t} | q, o_{i<t})}{\pi_{old}(o_{i,t} | q, o_{i<t})}) si(θ)=(πold(oi∣q)πθ(oi∣q))∣oi∣1=exp(∣oi∣1t=1∑∣oi∣logπold(oi,t∣q,oi<t)πθ(oi,t∣q,oi<t))
在进行这番修改后,MoE训练就变得稳定多了。