文章目录
- 一.前言
- 二.核心技术&知识
-
- 1.PyQt5
- 2.YOLOv8
- 3.DeepSeek
- 4.Sqlite3
- 5.多线程
- 6.安全帽
- 7.舌苔情况检测的意义
-
- [1. 基层中医诊所与社区健康驿站的快速初筛](#1. 基层中医诊所与社区健康驿站的快速初筛)
- [2. 居家慢病管理与体质跟踪](#2. 居家慢病管理与体质跟踪)
- [3. 中医远程会诊与教学数据标注](#3. 中医远程会诊与教学数据标注)
- 三.核心功能
- 四.数据集
- 五.关于项目
- 六.总结
本篇博客可能会引起不适,请谨慎阅读!
本系统功能强大!支持对输入数据源的舌苔情况进行检测,支持多种数据数据源输入并且接入了AI实现了对当前分析结果的评估,欢迎了解!
@项目名称:基于PyQt+YOLO+DeepSeek的的舌苔情况检测系统
@仓库名称:yolov8-tongue-detect
@作者:懷淰メ
@主页地址:https://blog.csdn.net/a1397852386
@定制:A1397852386
@开发日期:2026年4月
关键字:#PyQt5 #YOLOv8 #DeepSeek #SQLite3 #多线程 #舌苔检测 #目标检测 #中医舌诊 #智能诊断 #图像识别 #计算机视觉 #深度学习 #AI辅助诊断 #PyQt5GUI #QtDesigner #实时检测 #模型训练 #数据集 #XML转YOLO #YOLO标注 #训练评估 #mAP #混淆矩阵 #PR曲线 #PyQt5多线程 #QThread #系统设置 #历史数据 #登录注册 #论文复现 #毕业设计 #开源项目 #B站项目 #安全帽检测 #舌象分析 #舌苔分类 #镜面舌 #白腻苔 #薄白苔 #黄腻苔 #灰黑苔 #医疗AI #智慧医疗 #远程健康管理 #中医现代化 #桌面应用开发 #跨平台应用 #实时目标检测 #视频流检测 #摄像头检测 #可视化分析 #热力图 #置信度分布 #检测结果导出 #AI智能分析 #大模型 #DeepSeekAPI #数据存储 #数据管理 #分页展示 #用户管理 #模型评估 #训练日志 #损失曲线 #收敛分析 #泛化能力 #超参数调优 #学习率调度 #PyTorch #CUDA #OpenCV #Pillow #Pandas #NumPy #Matplotlib #PyQtGraph #QtAwesome #PyQtWebEngine #echarts #项目部署 #开发环境 #Python3.8 #Windows11 #PyCharm #技术博客 #CSDN #怀淰
一.前言
随着人工智能与医疗影像技术的快速发展,基于深度学习的智能辅助诊断系统正逐步应用于中医舌诊领域。舌苔作为中医辨证的重要依据,其形态变化(如镜面舌、白腻苔、薄白苔、黄腻苔、灰黑苔)能够反映人体的寒热虚实及脏腑功能状态。然而,传统舌诊高度依赖医师经验,主观性强、标准不统一,难以实现规模化与精准化应用。在此背景下,构建一款基于PyQt图形界面、YOLO目标检测模型以及DeepSeek智能分析能力的舌苔检测系统,具有重要的研究与应用价值。该系统能够实现舌像的自动识别与分类,提高诊断效率与一致性,同时降低对专业经验的依赖,为基层医疗与远程健康管理提供技术支持。此外,该项目有助于推动中医诊断标准化与数字化进程,促进人工智能技术与传统医学的深度融合,对提升智慧医疗水平具有积极意义。
二.核心技术&知识
在这章我将要介绍本系统的核心技术。
1.PyQt5
PyQt5 是一套用于创建跨平台桌面应用程序的 Python GUI 工具包,它是 Qt 应用框架的 Python 绑定。通过 PyQt5,开发者可以使用 Python 编写具有现代图形界面的应用程序,支持丰富的控件、信号与槽机制、窗口管理、事件处理等功能。它兼容主流操作系统(如 Windows、macOS 和 Linux),适用于开发各种规模的桌面软件,常与 Qt Designer 配合使用以加快开发效率。

2.YOLOv8
YOLOv8(You Only Look Once version 8)是由 Ultralytics 推出的最新一代实时目标检测模型,属于 YOLO 系列的改进版本。相比前代模型,YOLOv8 在精度、速度和灵活性上都有显著提升,支持目标检测、图像分割、姿态估计等多任务处理。它采用了更加高效的网络结构和训练策略,并提供开箱即用的 Python 接口和命令行工具,适用于边缘设备和云端部署,广泛应用于安防监控、自动驾驶、工业检测等场景。

3.DeepSeek
DeepSeek是由深度求索公司开发的AI大模型助手,作为纯文本模型,我擅长自然语言处理、文档分析和智能对话。当与YOLO(You Only Look Once)实时目标检测系统结合时,可以形成强大的多模态应用架构------YOLO系统负责实时视觉识别和目标检测,快速准确地识别图像或视频流中的物体;而我则对YOLO检测到的结果进行深度语义分析和上下文理解,提供物体属性的详细解读、场景描述、行为分析以及决策建议。这种结合使得计算机视觉的"看到"与AI的"理解"完美融合,可广泛应用于智能监控、自动驾驶、工业质检等领域,实现从视觉感知到智能决策的完整闭环。

4.Sqlite3
本系统使用Sqlite3进行数据的存储与管理。
SQLite3是一种轻量级的嵌入式关系型数据库管理系统,广泛应用于桌面软件、移动应用以及各类嵌入式设备中。与传统的客户端-服务器数据库(如MySQL、PostgreSQL)不同,SQLite3无需独立的数据库服务器进程,整个数据库以单一文件形式存储在本地,应用程序可直接通过库文件进行读写操作。这种架构使其具有部署简单、占用资源少、跨平台性强等显著优势。SQLite3遵循ACID事务特性,能够保证数据的一致性与可靠性,同时支持标准SQL语法,包括表的创建、查询、索引、触发器等常见功能,能够满足中小规模数据管理需求。在性能方面,SQLite3在读操作上表现高效,并通过锁机制实现多线程环境下的基本并发控制。由于其零配置特性和稳定性,SQLite3被广泛集成于Android、iOS等操作系统中,也常用于缓存数据存储、本地日志管理以及离线数据处理等场景。总体而言,SQLite3以其简洁高效的设计理念,在轻量级数据管理领域占据了重要地位。

5.多线程
QThread 是 PyQt5 提供的线程类,主要用于在图形界面程序中安全、高效地执行耗时任务,从而避免主线程阻塞导致界面卡顿或无响应的问题。在典型的GUI应用中,界面渲染与用户交互通常运行在主线程,一旦在该线程中直接执行诸如数据处理、深度学习模型推理、视频流分析或文件读写等耗时操作,就容易造成界面冻结,严重影响用户体验。QThread 的引入正是为了解决这一问题。
通过 QThread,开发者可以将这些计算密集型或IO密集型任务封装到子线程中独立运行,使主线程专注于界面更新与交互响应。同时,QThread 提供了基于信号与槽机制的线程间通信方式,能够在不同线程之间安全地传递数据与状态信息。例如,子线程在完成检测或处理任务后,可以通过发送信号将结果传递给主线程,由主线程负责更新界面控件,从而避免直接跨线程操作UI带来的风险。
此外,QThread 还支持线程的生命周期管理,包括启动、暂停、退出以及资源回收等,使得多线程程序结构更加清晰可控。合理使用 QThread 不仅可以显著提升应用程序的响应速度和运行效率,还能增强系统的稳定性与扩展能力。在涉及实时数据处理、视频监控或智能分析等复杂桌面应用开发场景中,QThread 已成为不可或缺的重要工具。
6.安全帽
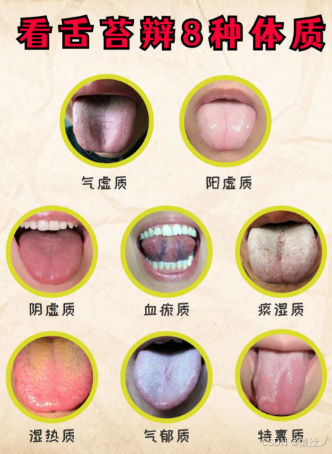
舌苔是舌面上的一层薄白湿润的苔状物,由脱落的角化上皮、唾液、细菌、食物残屑等组成,能反映人体健康状况。其中,薄白苔(舌苔薄白均匀、干湿适中)属正常舌象,提示表证初起或病势轻浅;白腻苔(苔质颗粒细腻致密、揩之不去,呈白色)多主湿浊、痰饮或食积;黄腻苔(苔色黄而厚腻)常见于湿热内蕴或痰热腑实;灰黑苔(苔色呈灰黑、深浅不一)多属热极或寒极重证,灰黑干燥起刺为热盛津枯,灰黑润滑多津则属寒湿内盛。而镜面舌(舌苔完全剥落、舌面光滑如镜)为阴液大伤或胃阴枯竭的危重征象,多见于重症消耗性疾病或长期营养吸收障碍。
7.舌苔情况检测的意义
1. 基层中医诊所与社区健康驿站的快速初筛
在缺乏资深中医师的基层医疗机构或社区卫生站,该系统可作为智能预检工具。患者只需将手机或外接摄像头对准舌面,系统即通过YOLO实时检测舌苔区域,自动分类为镜面舌、白腻苔等五类典型舌象。例如,对于疑似糖尿病或贫血患者的镜面舌(舌乳头萎缩、舌面光滑),系统会标记风险等级并生成结构化报告;对于儿童积食常见的白腻苔,系统可结合DeepSeek的医学知识库给出通俗解释和饮食建议。整个过程无创、即时(单次检测<3秒),辅助护士或全科医生快速筛选需转诊的患者,缓解中医资源分布不均问题。
2. 居家慢病管理与体质跟踪
慢性胃炎、高血压或肿瘤康复期患者可每日使用该系统自我监测舌苔变化。比如,肾病患者出现灰黑苔(常提示寒湿或热极)时,系统通过PyQt桌面端记录时间轴图谱,对比历史数据提示恶化趋势;服用抗生素后出现黄腻苔(湿热标志),系统利用DeepSeek分析用药与舌象关联,并推荐健脾化湿的食疗方案(如薏米赤小豆粥)。用户无需专业医疗知识,仅需按界面提示操作,系统自动生成周报并支持导出给医生,解决传统"仅凭患者主诉难以准确调整药方"的痛点。
3. 中医远程会诊与教学数据标注
在互联网中医院或医学院校中,该系统可嵌入远程诊疗平台。接诊医生获取患者舌部高清图像后,系统实时显示YOLO标注的苔色、厚薄、区域置信度(如薄白苔置信度>95%),并调用DeepSeek生成类似"舌象:舌红少苔(镜面)→提示阴津亏虚,建议配合麦冬、石斛"的辨证参考。同时,系统内置的增量学习模块支持专家对自动分类结果进行纠偏(如将误判的"黄腻苔"修正为"白苔染黄"),累积的标注数据反过来训练模型。这在中医教学中尤为实用------学生可对比系统输出与老师解析,加速掌握五类典型病理舌象的辨识技能。
三.核心功能
1.登录注册
1.登录
软件启动后首先进入登录页面,用户需要输入正确的用户名和密码,经过系统验证后方可使用本系统的正式功能。登录页面整体采用垂直布局,使信息层次清晰、结构简洁,同时在局部区域辅以水平布局,以提升界面的灵活性与可读性。整体设计风格遵循"简约而不简单"的原则,在保证视觉美观的同时,也兼顾操作的直观性与易用性。
在功能实现方面,登录模块的后端采用sqlite3文件型数据库来存储用户信息,包括用户名、密码及相关基础数据。每次用户发起登录请求时,系统都会通过查询数据库进行身份校验,确保输入信息的准确性与安全性,从而实现规范化、标准化的登录流程。
同时,我们设计了统一风格的登录与注册界面,用于展示系统与用户交互所需的全部组件。界面顶部以醒目的标题形式展示系统名称,增强整体识别度与专业性。通过合理布局输入框、按钮及提示信息,使用户在使用过程中能够快速理解操作步骤,从而提升整体使用体验。
2.注册
对于尚未拥有账号的用户,需要先完成注册操作后才能使用系统功能。整体注册流程设计得较为简洁直观,用户只需在登录界面点击"注册"按钮,即可快速跳转至注册窗口,无需复杂的页面切换或额外步骤。在注册界面中,用户需要填写自定义的用户名,并输入两次一致的密码以完成身份信息的确认。这种双重密码输入机制可以有效避免因输入错误而导致的登录失败问题,从而提升系统的可靠性与用户体验。
在用户成功完成注册后,系统还提供了一项便捷的优化设计:自动将刚刚注册的用户名和密码填充到登录界面中。用户无需再次手动输入信息,即可直接进行登录操作。这一设计在一定程度上简化了登录流程路径,减少了重复操作,提高了整体使用效率。同时,该功能也体现了系统在交互细节上的人性化考虑,使用户在首次使用时能够获得更加顺畅和友好的体验。
2.主界面
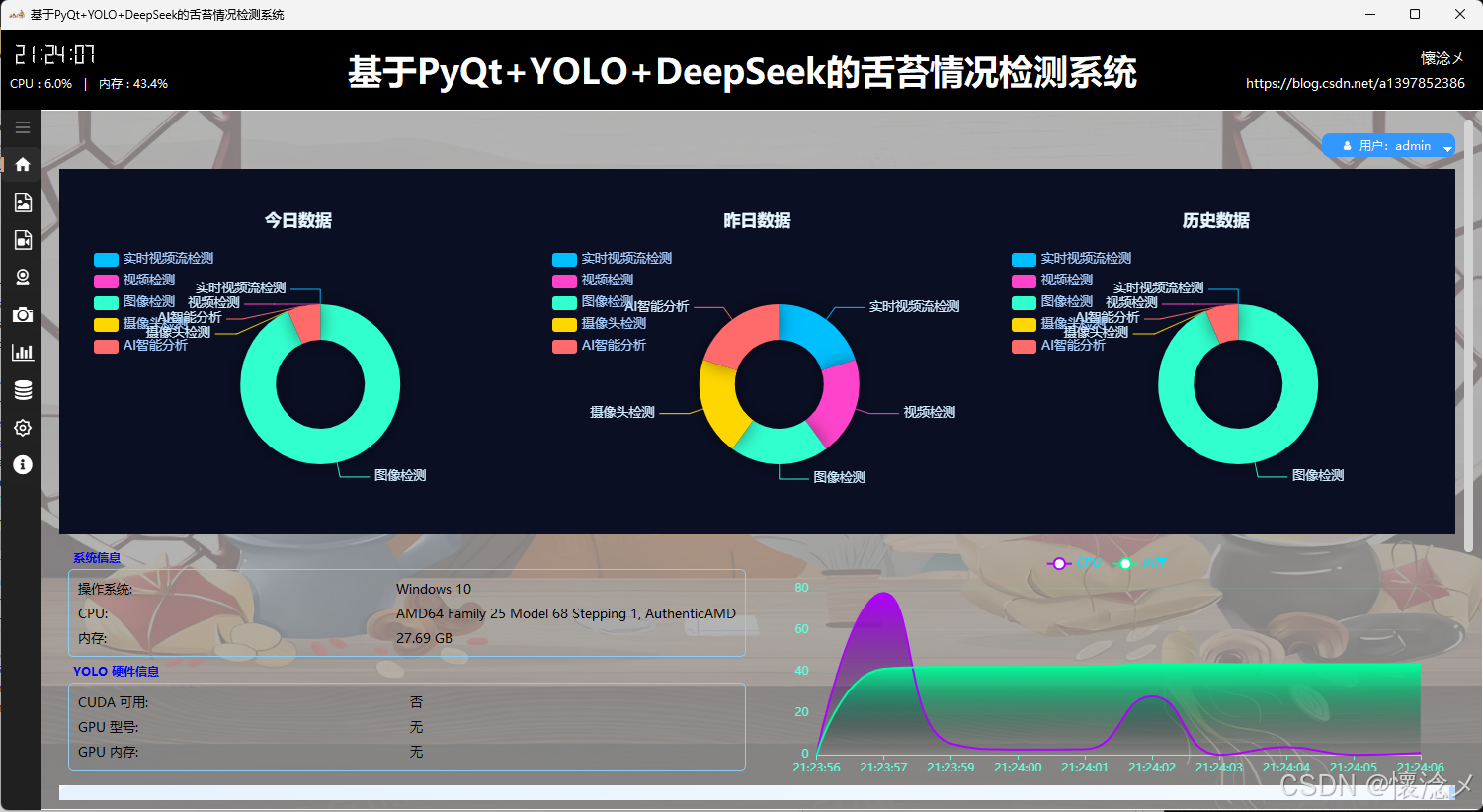
用户通过输入自己的用户名和密码登录到本系统后进入主界面,主界面内容十分丰富,我来一一介绍:首先软件整体是垂直布局,顶部是系统的标题,从左到右依次展示了系统的作者信息、系统名称、当前时间以及CPU内存占用情况,下方为水平布局,左侧是系统的导航区域,我们设计了windows风格支持展开与收缩的内容导航区域,右侧是内容核心区域,通过点击导航按钮切换展示内容,主界面主要展示了以日期为维度统计的数据、用户信息操作按钮、系统信息、系统环境信息以及实时CPU、内存可视化折线图
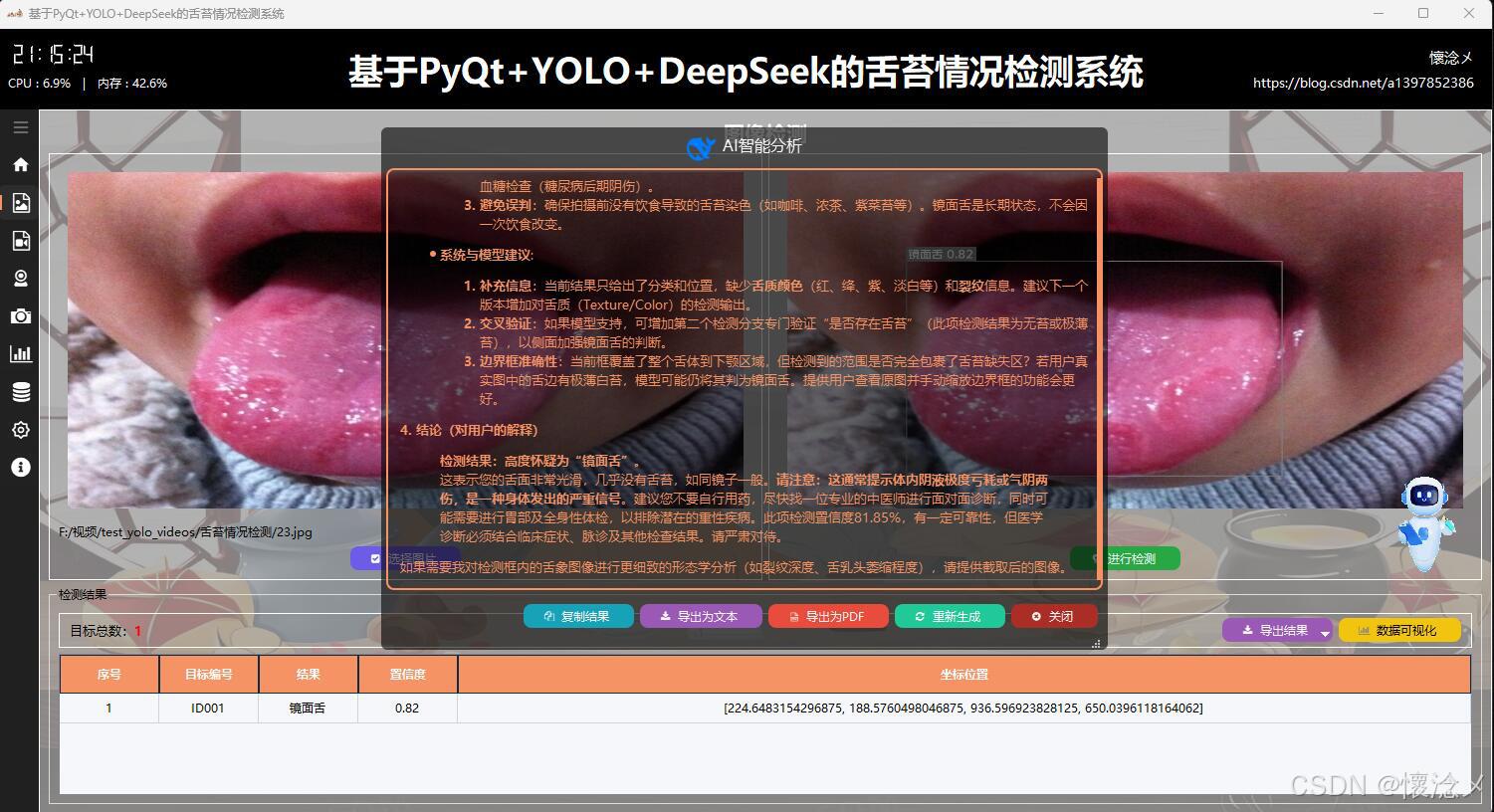
3.图像检测界面
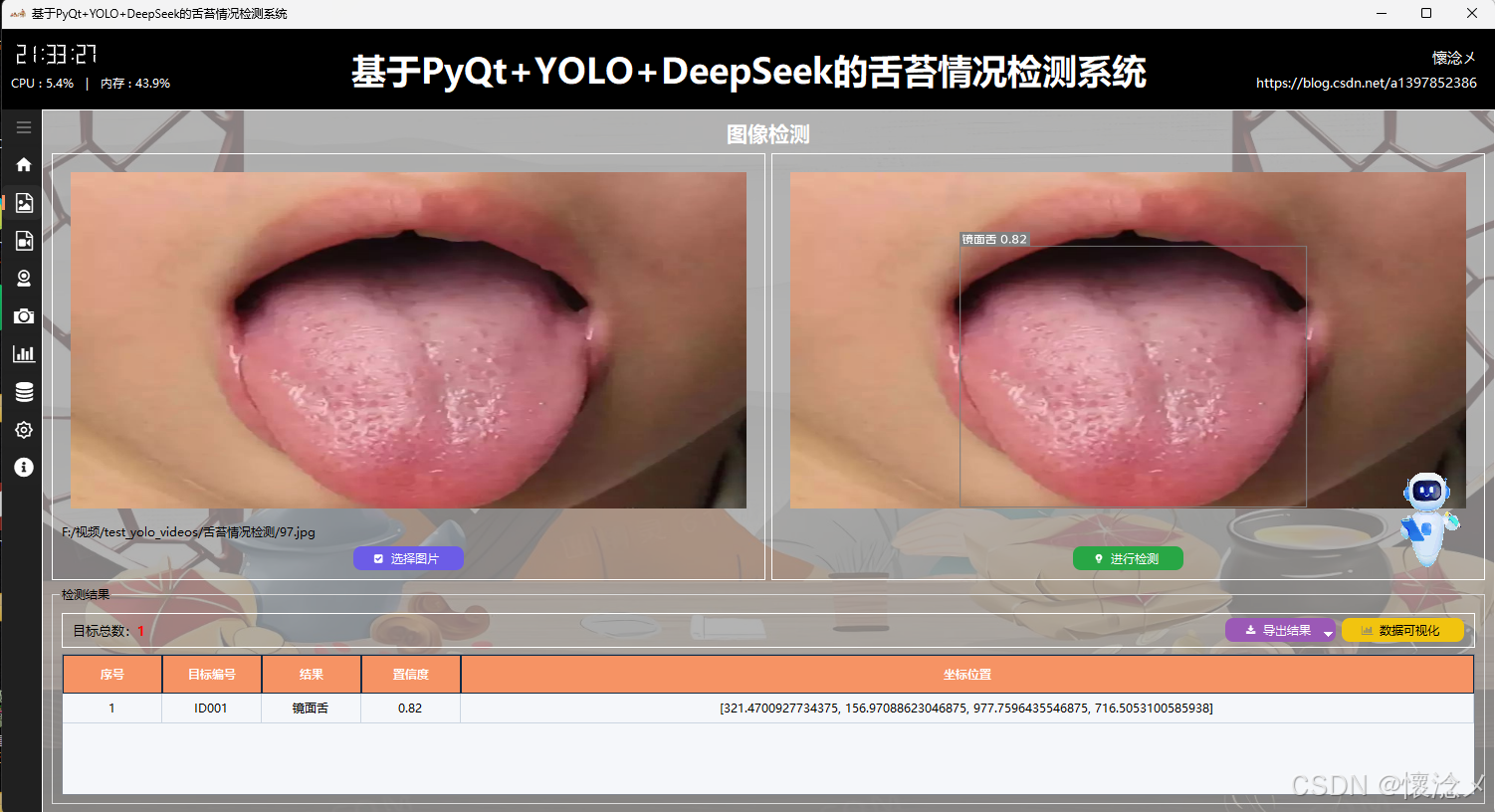
1.检测结果展示
用户通过点击左侧导航栏按钮切换到图像检测界面,在此界面支持选择图像进行输入,用户选择完之后被选择的图像会展示在左侧并且展示图像绝对路径信息,用户可以通过点击右侧的"进行检测"按钮对输入的图像数据进行检测,系统会自动调用YOLOv8相关算法根据指定的参数对输入图像内容进行检测,最后将检测结果展示到右侧,这样用户可以通过比对左右图像的区别得到直观的检测结果,系统自动使用红色边框框选出目标区域并且使用红色文字展示出目标类别以及它的置信度,这些参数和展示效果都可以在设置页面进行详细设置。
2.导出检测结果
我们在界面中专门设置了检测结果展示区域,用于集中呈现系统输出的信息。该区域不仅包含检测目标数量的统计展示,还提供了结构清晰的详细检测结果表格。通过这种方式,用户可以直观地查看每一条检测数据,包括目标类别、置信度以及对应位置信息等内容,从而更全面地了解检测情况。整体布局兼顾信息密度与可读性,使数据展示既完整又不显杂乱。
此外,在检测任务完成之后,界面右侧的三个功能按钮会自动由不可用状态切换为可点击状态,避免用户在未生成结果前进行误操作。这三个按钮分别承担不同的功能,其中"导出结果"按钮允许用户将检测数据保存到本地。系统支持多种导出格式,包括Excel、CSV以及TXT,用户可以根据实际需求灵活选择合适的文件类型,以便后续分析或归档使用。以Excel格式为例,导出的文件通常采用表格结构,对应字段清晰排列,便于用户进一步查看与处理数据。

3.可视化展示
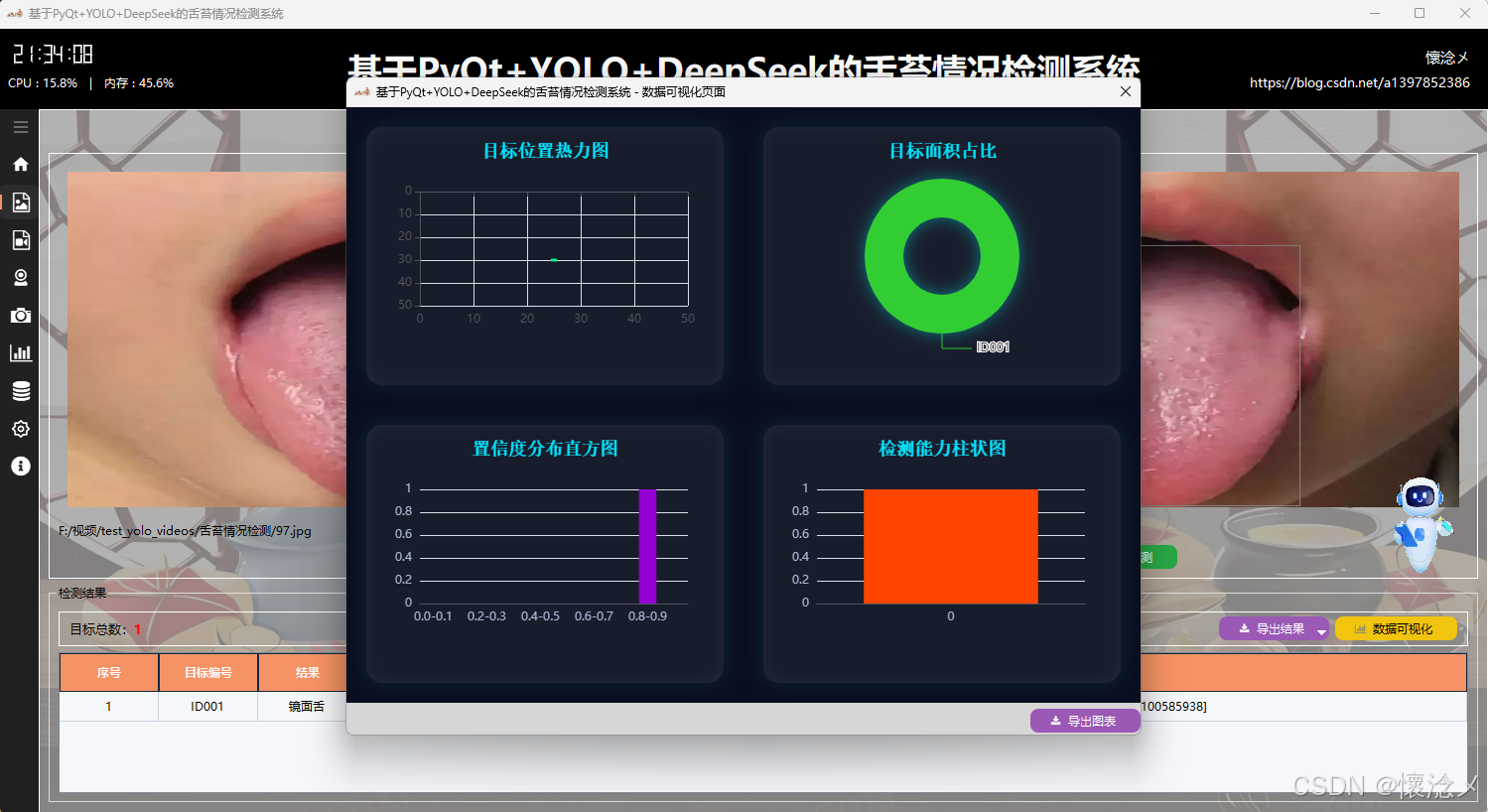
然后就是可视化展示,用户可以点击进行可视化按钮,查看对于本次检测的可视化效果,系统内置了四种可视化效果:分别是:目标位置热力图、目标面积占比、置信度分布直方图、检测能力柱状图,这些图标通过不同维度对当前数据进行了可视化展示,更便于用户理解,这里指的一体的是,支持可视化图表进行导出操作,用户可以点击紫色的导出按钮,对当前的可视化效果图表进行导出,生成一张本地的PNG图像文件。
4.AI(DeepSeek)智能分析
在每次检测任务完成并展示检测结果之后,系统为用户提供了一种便捷且智能的交互方式:用户只需点击界面右下角悬浮的机器人图标,即可触发对当前检测结果的深度AI分析功能。系统会自动将本次检测所得到的所有关键信息------包括检测到的目标类别、置信度分数、目标位置坐标、数量统计以及可能存在的异常或遮挡情况等------完整地作为输入传递给后端AI大模型。AI模型接收到这些数据后,会基于其强大的语义理解与逻辑推理能力,对本次检测结果进行多维度的智能评估。评估内容可以包括:检测结果的准确性与可靠性判断、识别结果中可能存在的误检或漏检风险提示、针对当前场景的优化建议、对异常情况的详细解释。这一设计不仅使用户无需手动复制或整理检测数据就能获得即时的专业分析反馈,更重要的是,它实现了一种通用化的AI能力接入机制:检测模块与分析模块实现了解耦,任何检测结果都可以以统一格式传递给AI进行分析,而AI的具体分析逻辑可以根据需要灵活替换、升级或定制。这使得系统在未来可以轻松扩展更多智能功能,例如接入不同的大模型、增加多模态分析能力、实现检测策略的自适应调整等,极大地提升了整个系统的可扩展性与智能化水平。
这里是软件的另外一个核心:AI智能分析,我们的目标检测系统接入了DeepSeek大模型,支持对当前检测结果数据进行AI分析,AI会通过不同维度对当前检测结果进行多角度分析,最后生成检测结果分析报告,用户可以根据这个结果对系统进行调整,不断完善系统功能和目标检测准确度!
在AI分析结束后下方会展示一些按钮,用户可以方便地复制结果、导出文本内容、生成PDF报告、重新生成以及关闭,多重的操作方式给于用户了多种选择!

4.视频检测界面
1.视频文件检测
我们的系统具备对视频内容中安全帽佩戴情况的智能检测能力,能够适配多种输入来源,包括本地视频文件、实时视频流以及各类摄像头设备,满足不同应用场景下的使用需求。系统通过对视频画面逐帧解析,利用先进的图像识别算法对画面中的目标进行精准检测,并实时完成标注与可视化展示,使用户能够直观了解检测效果。在性能方面,系统引入了灵活的帧率控制机制,在保证检测精度的同时有效提升视频播放的流畅性,避免出现卡顿或延迟问题,从而提升整体使用体验。
此外,系统界面设计注重用户交互体验,支持左右画面对比显示,用户可以通过肉眼直观对比原始画面与检测结果,快速评估算法表现与准确性。这种对比方式不仅便于结果验证,也有助于进一步优化检测参数。值得一提的是,视频检测界面在功能设计上与图像检测界面保持高度一致,操作逻辑统一,用户无需额外学习成本即可快速上手使用,包括基本的播放控制、暂停、逐帧查看以及检测结果开关等功能。因此,在保证功能完整性的同时,也兼顾了系统的易用性与扩展性。
2.摄像头内容检测
当用户点击"进行检测"按钮后,系统会自动调用本地摄像头设备并完成初始化,随即在界面中实时展示摄像头采集到的画面内容。在视频流持续输入的过程中,系统会同步启动目标检测算法,对当前画面中的目标进行实时识别与标注处理,确保检测结果能够及时反馈给用户。同时,界面采用左右分屏的展示方式,一侧显示原始画面,另一侧显示叠加检测结果的画面,用户可以通过直观对比快速判断检测效果与准确性。这种设计不仅提升了交互体验,也便于用户观察算法在不同场景下的表现情况。至于摄像头画面中是否出现本人,这里就暂时保持低调,不做展示了。
5.模型指标评估
在这个页面中我们通过三个tab展示了模型训练结果评估,分别是:训练结果图、训练结果详情、整体评估,所有的训练结果文件(夹)以及相关作用可见下面图标:
| 文件/文件夹名 | 类型 | 作用说明 |
|---|---|---|
weights/ |
文件夹 | 存放训练得到的模型权重 |
├─ best.pt |
文件 | 在验证集上表现最好的模型(推荐用于推理/部署) |
├─ last.pt |
文件 | 最后一轮训练结束时的模型(包含最新状态) |
results.csv |
文件 | 每个 epoch 的训练与验证指标(loss、mAP、precision 等) |
results.png |
图片 | 训练过程中各类指标变化曲线(loss、mAP 等可视化) |
confusion_matrix.png |
图片 | 混淆矩阵,展示类别预测情况 |
confusion_matrix_normalized.png |
图片 | 归一化后的混淆矩阵 |
PR_curve.png |
图片 | Precision-Recall 曲线 |
P_curve.png |
图片 | Precision 曲线 |
R_curve.png |
图片 | Recall 曲线 |
F1_curve.png |
图片 | F1-score 曲线 |
labels.jpg |
图片 | 数据集中标签分布(类别统计) |
labels_correlogram.jpg |
图片 | 标签相关性图(用于分析数据分布) |
train_batch*.jpg |
图片 | 训练批次样本可视化(带标注框) |
val_batch*.jpg |
图片 | 验证批次样本可视化 |
args.yaml |
文件 | 本次训练的完整参数配置(超参数、路径等) |
hyp.yaml(部分版本) |
文件 | 超参数配置(学习率、增强策略等) |
opt.yaml(旧版本可能有) |
文件 | 训练选项记录(已逐渐被 args.yaml 替代) |
events.out.tfevents.* |
文件 | TensorBoard 日志文件(用于可视化训练过程) |
1.训练结果图tab
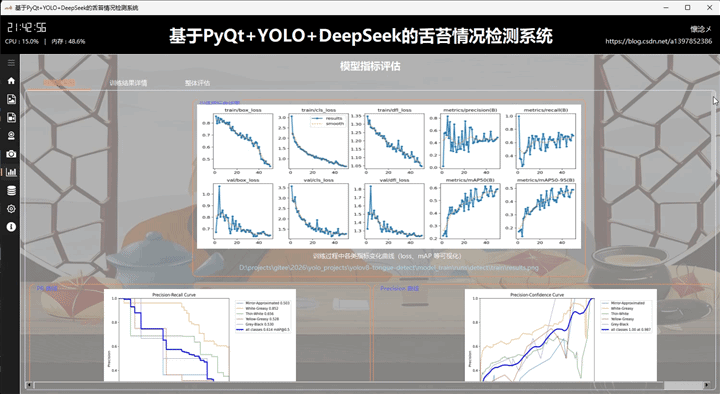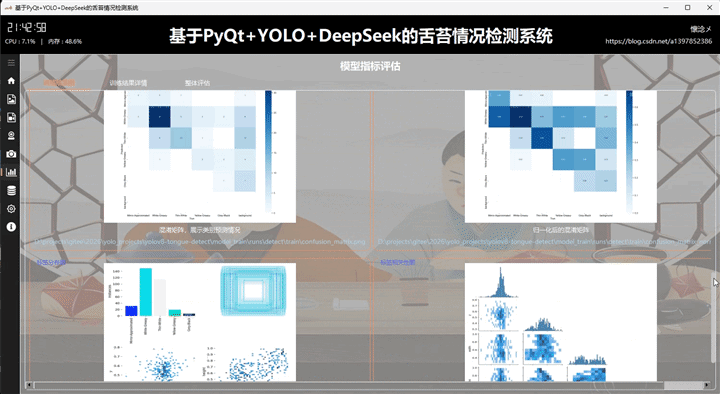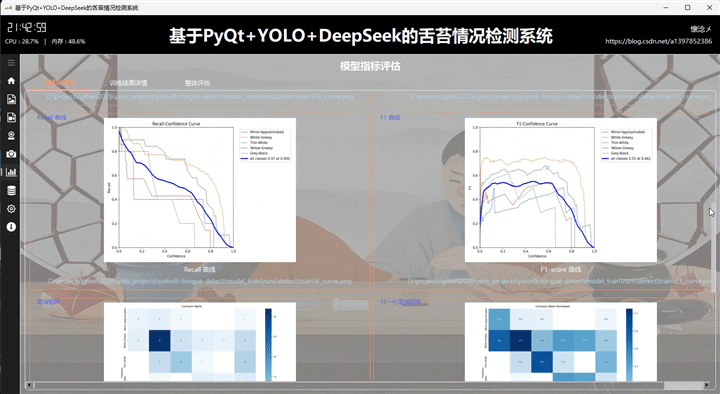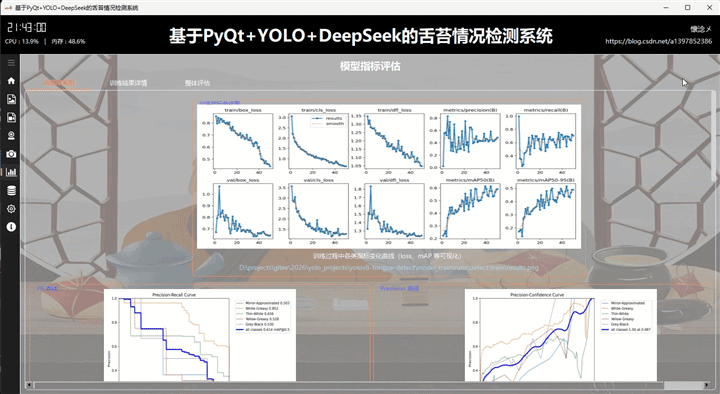
本系统基于 PyQt5 + YOLOv8 + DeepSeek 构建,实现对口罩佩戴状态的智能检测与可视化分析。在结果展示模块的该 tab 页面中,集中呈现模型训练与评估阶段生成的多维度指标图像,包括训练损失与性能指标曲线图、PR 曲线、Precision 曲线、Recall 曲线、F1 曲线,以及混淆矩阵与归一化混淆矩阵。同时还提供标签分布图与标签相关性图,用于分析数据集结构与类别关系。
这些图像以直观的方式嵌入界面中,用户无需额外操作即可快速浏览模型整体表现。例如,PR 曲线可反映模型在不同阈值下的查准率与召回率平衡,F1 曲线用于综合衡量模型性能,而混淆矩阵则清晰展示分类正确与误判情况。标签分布与相关性图则有助于判断数据是否均衡及类别间的潜在关联。
在交互设计上,用户可通过点击图像本身,或点击底部提供的图像路径,调用系统默认图像查看工具进行放大查看,提升细节分析能力。每张图像下方均附有简明且专业的说明文案,帮助用户理解其评估意义及应用价值,从而更全面地掌握模型训练效果与优化方向。
2.训练结果详情tab
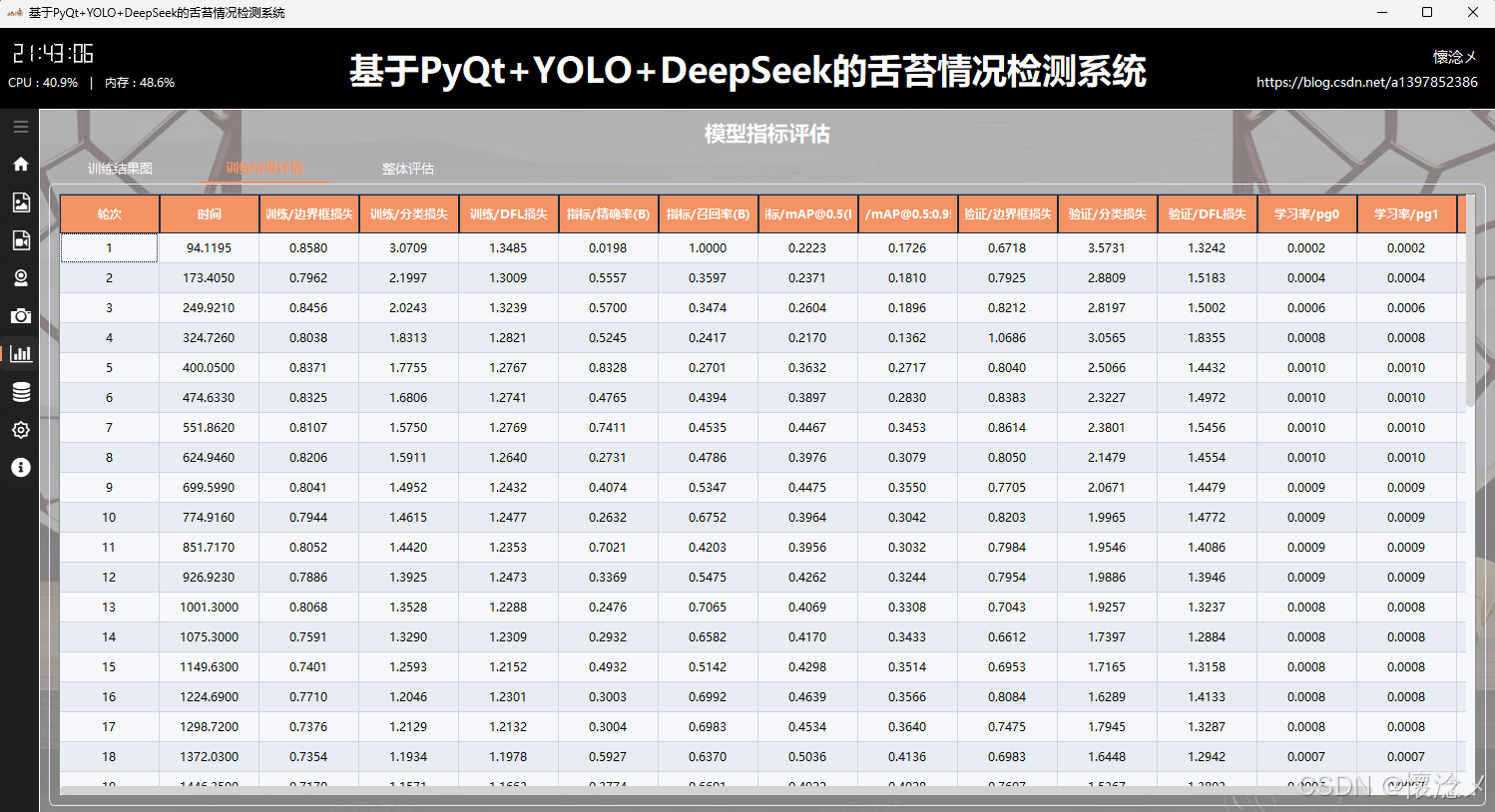
在该子 tab 页面中,系统进一步对训练过程中的 results.csv 数据进行了结构化展示。通过将原始训练日志解析为二维表格,完整呈现模型在每一轮(epoch)中的关键指标变化情况,使用户能够以更加清晰、系统化的方式回顾训练全过程。界面设计上采用了简洁清新的视觉风格,并结合横向渐变配色对不同数值区间进行区分,使数据变化趋势更加直观,重点指标一目了然。
表格中包含了完整的字段信息,例如"轮次"和"时间"用于标识训练进度;"训练/边界框损失""训练/分类损失""训练/DFL损失"反映模型在训练阶段的收敛情况;"指标/精确率(B)""指标/召回率(B)"以及"指标/mAP@0.5(B)"和"指标/mAP@0.5:0.95(B)"用于综合评估模型检测性能;对应的"验证/边界框损失""验证/分类损失""验证/DFL损失"则用于判断模型的泛化能力与是否存在过拟合现象。此外,"学习率/pg0""学习率/pg1""学习率/pg2"展示了不同参数组在训练过程中的学习率动态变化,有助于分析优化策略的效果。
在交互体验方面,表格支持滚动浏览与高亮显示,用户可以快速定位关键轮次的数据变化。同时结合渐变色视觉编码,能够快速识别性能提升或波动区间。通过这一模块,用户不仅可以精确掌握模型训练的细节,还能够为后续参数调优与模型改进提供可靠的数据支撑,实现从"可视化观察"到"数据驱动优化"的有效过渡。
3.整体评估tab
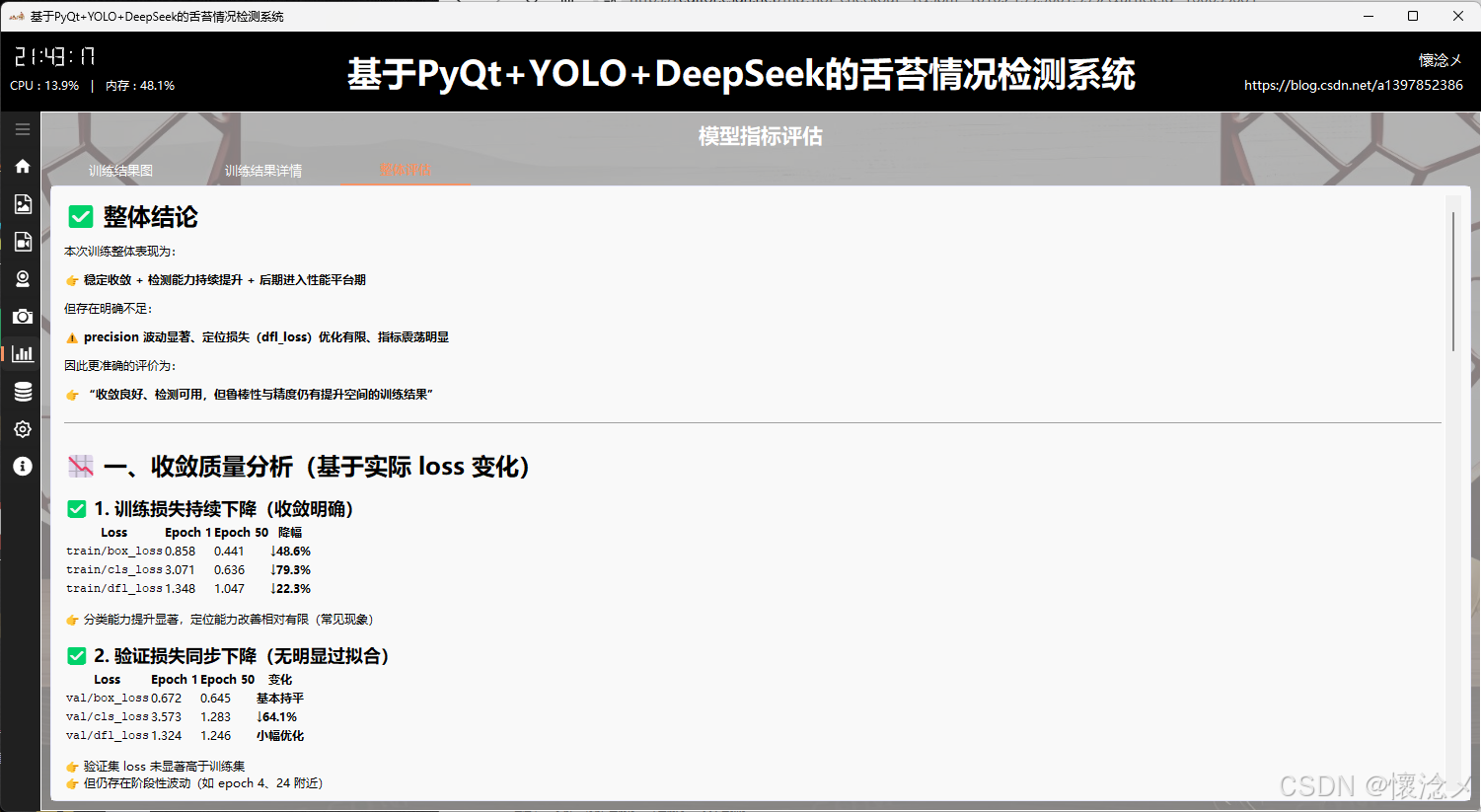
在该页面中,系统对模型训练结果进行了更高层次的综合评估与总结分析。通过对关键指标进行统一整理与可视化表达,结合细致的颜色编码机制,将不同阶段的性能变化趋势清晰呈现出来,使用户能够从整体上把握模型训练的动态过程,而不仅仅停留在单一指标的观察。
在评估维度上,系统重点围绕多个核心方面展开。首先是收敛质量 ,通过训练与验证损失曲线的变化趋势,判断模型是否稳定收敛以及是否存在震荡或过早收敛的问题;其次是检测性能 ,结合 Precision、Recall 以及 F1 等指标,分析模型在目标检测任务中的准确性与覆盖能力;在泛化能力 方面,通过对比训练集与验证集指标差异,评估模型是否存在过拟合或欠拟合现象;同时利用 mAP 综合表现 (包括 mAP@0.5 与 mAP@0.5:0.95)对模型整体检测能力进行量化衡量,从多阈值角度反映检测精度的稳定性。
此外,系统还对学习率调度策略 进行了分析,通过展示不同参数组学习率随训练轮次的变化情况,帮助用户判断当前优化策略是否合理,以及是否需要进一步调整以提升训练效率或稳定性。所有评估结果均通过分层颜色与趋势变化进行突出展示,使关键结论更加直观易读。
在页面的最后部分,系统基于上述多维度分析结果,自动生成整体评估结论,并从工程应用视角给出总结性判断。例如模型是否已达到可部署标准、是否需要继续训练或优化数据集、以及在实际口罩检测场景中的预期表现。这种从数据到结论的完整闭环设计,有助于用户快速完成模型质量评估,并为后续系统部署与迭代提供明确依据。
6.数据查看界面
"历史数据"页面是系统中用于集中查看与管理过往记录的重要模块,整体设计清晰直观,通过两个独立的 Tab 实现不同维度数据的分类展示,方便用户快速切换与定位信息。
总体而言,"历史数据"页面通过清晰的结构划分与完善的功能设计,实现了检测记录与用户信息的高效管理与展示,为系统的运维与决策提供了有力支持。
1.历史数据tab
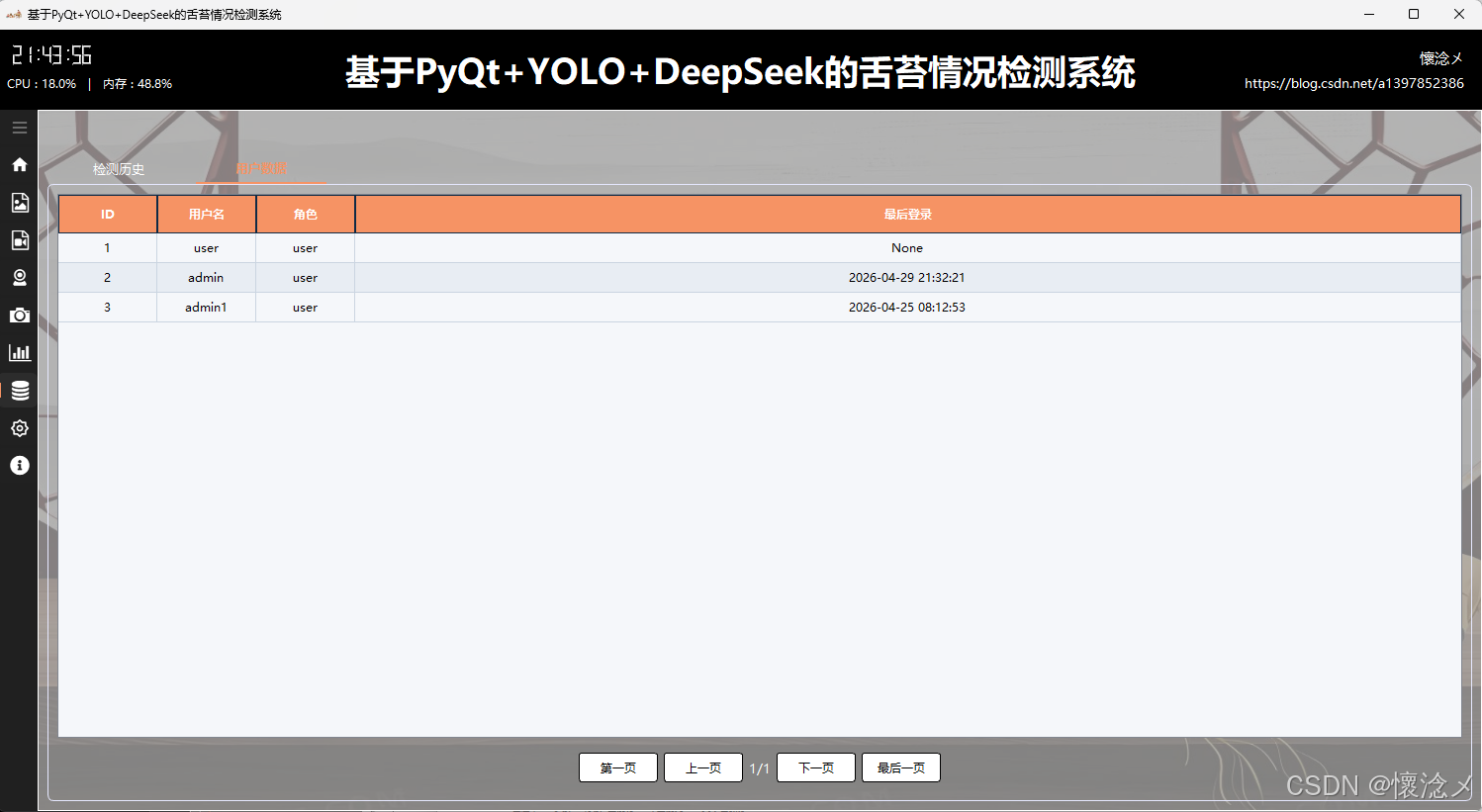
在"检测历史数据"Tab中,页面以结构化表格的形式呈现所有检测相关记录。每一条数据都包含关键字段:数据库ID用于唯一标识记录,目标类型用于说明检测对象的类别,检测结果用于反馈检测结论,检测日期则记录具体的时间信息。该模块不仅实现了数据的完整展示,还特别强化了可用性与交互体验------支持分页浏览功能,用户可以根据数据量分批查看内容,同时提供"跳转到第一页"、"上一页"、"下一页"以及"最后一页"等操作按钮,便于在大量数据中高效导航。这种分页机制有效避免了数据过载带来的性能问题,同时也提升了界面的响应速度和用户体验。

2.用户数据tab
其次,在"用户数据"Tab中,系统汇总展示了所有已注册用户的信息,是一个用于用户管理与审计的重要视图。页面同样采用表格形式,列出了数据库ID、用户名、用户角色以及最后登录日期时间等核心字段。通过这些信息,管理员可以快速了解系统用户的基本情况及活跃状态,例如判断某些用户是否长期未登录,从而进行进一步管理操作。该部分数据覆盖范围全面,确保系统管理者能够掌握整体用户分布与使用情况。
6.系统设置界面
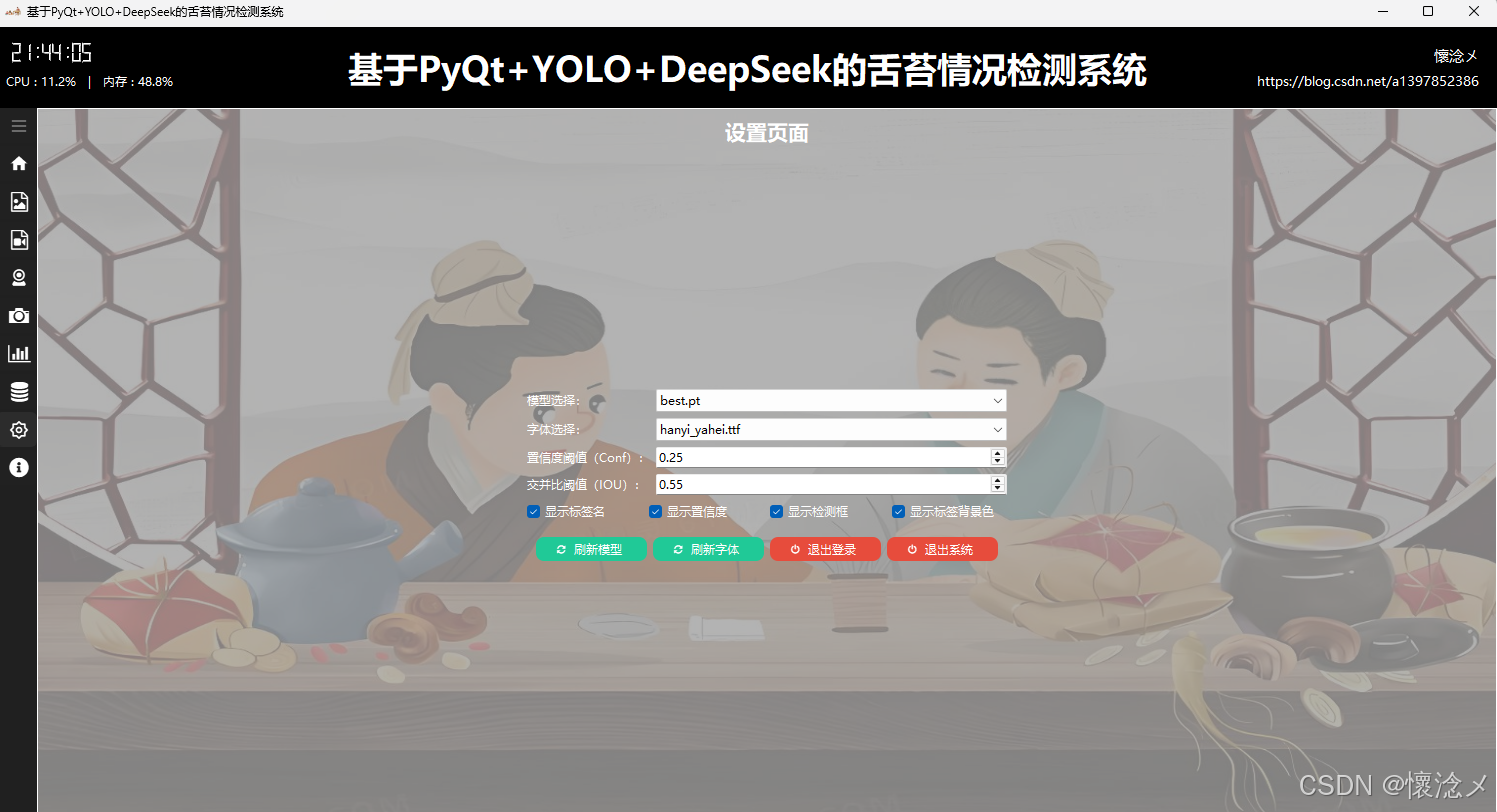
我们的系统是支持简单的参数设置的,具体可以设置目标检测模型、置信度阈值(Conf)、交并比阈值(IOU)、还有一些检测结果控制参数,比如检测框展示、目标类别展示、目标置信度展示,用户可以点击绿色的刷新按钮刷新可用模型,亦可通过点击退出按钮退出系统或者退出登录,本设置页面实现了目标检测参数的灵活配置!
7.关于软件界面
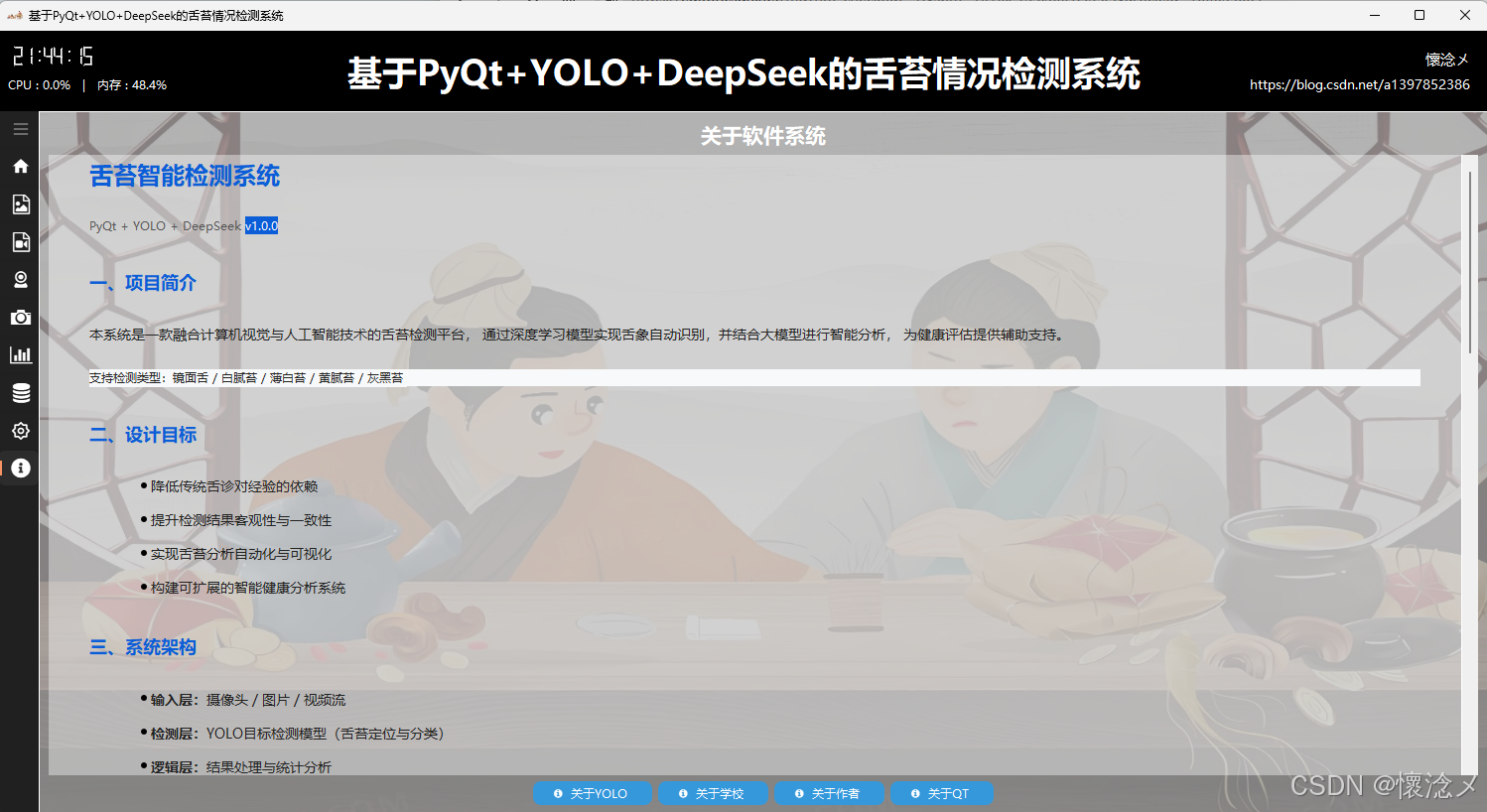
我们使用富文本html的形式展示了软件相关的信息,包括系统用到的相关技术,对于二维的数据使用二维表进行了展示,最底部放置了四个按钮,分别是:关于YOLO、关于软件、关于作者、关于QT,点击之后都会弹出对应的信息提示框,这个页面的作用是让用户更多的了解软件和创作者信息,跨过技术的鸿沟!
四.数据集
本系统为"一款基于PyQt+YOLO+DeepSeek的安全帽检测系统",用以检测输入数据源是否佩戴安全帽。
一款"基于PyQt5+YOLOv8+DeepSeek的安全帽检测系统"用以检测输入数据源是否佩戴安全帽。本系统所采用的数据集围绕安全帽检测的多场景、多角度、多状态采集构建而成,旨在提升模型在真实工业环境中的适应性与鲁棒性。数据来源涵盖建筑工地、工厂车间、港口码头、物流园区以及户外作业现场等多类复杂应用环境,结合不同光照条件、摄像设备分辨率、拍摄角度、人员姿态差异以及背景干扰因素,使模型能够学习到丰富且多样化的安全帽佩戴特征与环境变化。
图像内容覆盖多种实际佩戴情况,包括不同尺寸、不同颜色、不同类型(如普通安全帽、带反光条安全帽、特种作业安全帽)的安全帽,同时包含正确佩戴、未佩戴、佩戴不规范(如未系下颏带、歪戴)等情况,以及局部遮挡、背光、远距离、多人同框等挑战性样本。此外,还考虑了不同季节着装、不同工种装备差异及拍摄视角变化带来的视觉多样性,以增强模型的泛化能力。
数据集中不仅包含高质量标注的安全帽边界框与佩戴状态标签,还对类别(如"佩戴安全帽""未佩戴安全帽""佩戴不规范")及标注一致性进行了严格校验,确保训练数据的准确性与可靠性。经过数据清洗、去重、增强及标准化处理后,最终数据集能够满足YOLOv8等高性能目标检测模型的训练需求。
在此基础上,模型在实际部署过程中,即便在光照不足、安全帽目标过小、人员密集或背景复杂等情况下,仍能够保持稳定且高精度的检测效果。该数据集为系统实现高精度、高实时性的安全帽佩戴检测提供了坚实的数据支撑。
1.数据准备
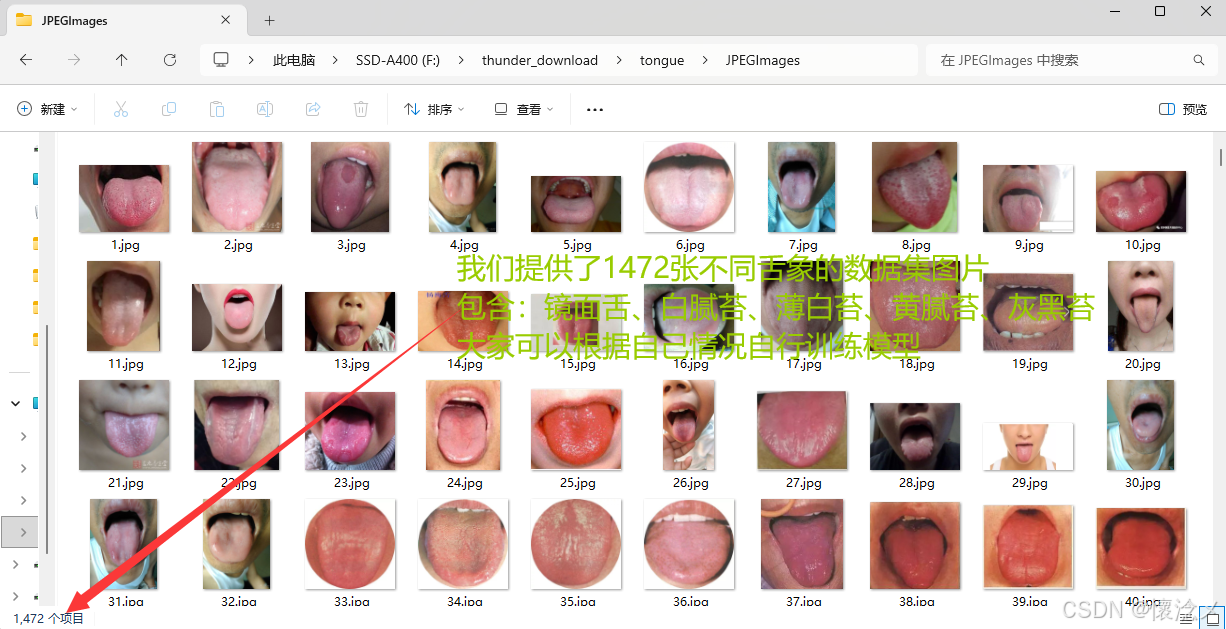
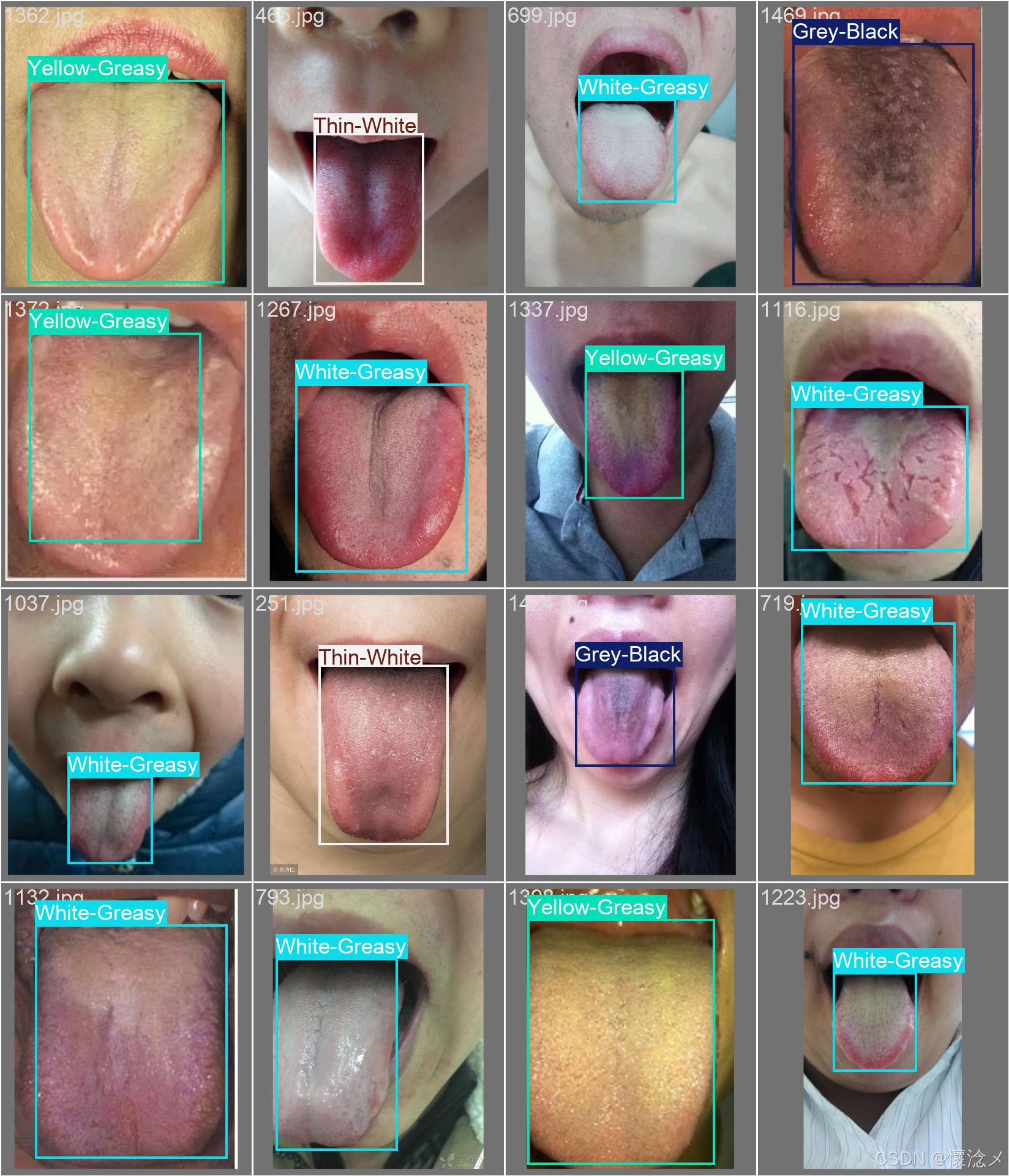
本系统附带1472张不同图像和1472个数据标注文件,大家可以根据自己的情况自行训练数据自己的模型!
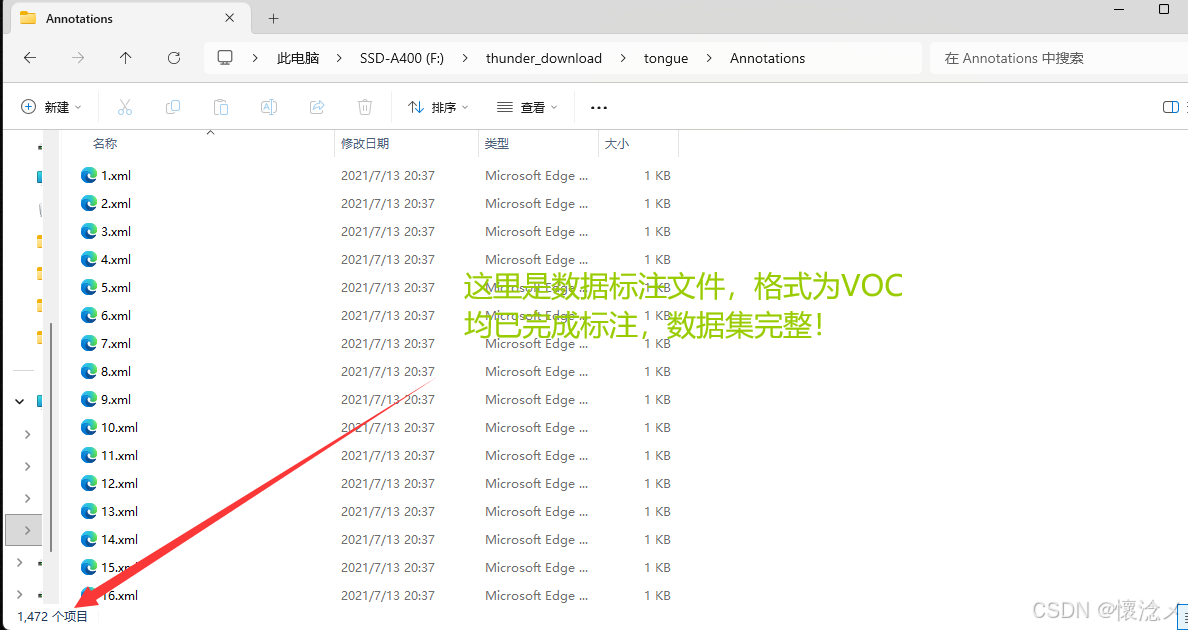
上图是数据标注文件,格式为xml,下面我们提供了相关脚本支持将xml转为YOLO的txt格式
我们使用json的格式存储数据标注文件,单数据标注文件内容如下:
bash
<?xml version='1.0' encoding='us-ascii'?>
<annotation>
<folder>A</folder>
<filename>21.jpg</filename>
<path>D:\舌象\数据集分类\A\21.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>400</width>
<height>400</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Mirror-Approximated</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>114</xmin>
<ymin>138</ymin>
<xmax>358</xmax>
<ymax>343</ymax>
</bndbox>
</object>
</annotation>2.数据集处理
1.数据集标注文件类型转换
直接使用VOC格式的数据标注文件进行训练是不行的,需要我们将xml转成txt文件,
这段代码的作用是将指定文件夹中的 Pascal VOC 格式的 XML 标注文件批量转换为 YOLO 格式的 TXT 标注文件。它会先遍历所有 XML 自动统计有效类别并生成类别到 ID 的映射表,忽略类别名为 "not" 的标注,然后读取对应图片的尺寸,将 XML 中的边界框坐标转换为 YOLO 的归一化格式(class_id x_center y_center width height),最后将生成的 TXT 文件保存到指定目录中,便于直接用于 YOLO 训练。
大家首先执行step1_voc_to_txt.py
python
import os
import xml.etree.ElementTree as ET
from PIL import Image
from train_conf import BASE_DIR
# 原始路径
xml_dir = BASE_DIR + r"Annotations"
img_dir = BASE_DIR + r"JPEGImages"
# YOLO标签输出路径
yolo_txt_dir = BASE_DIR + r"labels"
os.makedirs(yolo_txt_dir, exist_ok=True)
# ===== 自动生成类别映射 =====
class_map = {}
next_class_id = 0
# 支持的图像扩展
img_exts = [".jpg", ".jpeg", ".png", ".bmp"]
# 遍历 XML 文件
for xml_file in os.listdir(xml_dir):
if not xml_file.endswith(".xml"):
continue
xml_path = os.path.join(xml_dir, xml_file)
tree = ET.parse(xml_path)
root = tree.getroot()
# --- 以 XML 文件名匹配图像 ---
base = os.path.splitext(xml_file)[0]
img_path = None
for ext in img_exts:
candidate = os.path.join(img_dir, base + ext)
if os.path.exists(candidate):
img_path = candidate
break
if img_path is None:
print(f"Warning: 图像文件与 {xml_file} 同名的图片不存在,跳过")
continue
# 获取图像尺寸
try:
with Image.open(img_path) as img:
w, h = img.size
except Exception as e:
print(f"无法打开图片 {img_path}: {e}")
continue
txt_lines = []
# 遍历目标
for obj in root.findall("object"):
name_node = obj.find("name")
if name_node is None:
continue
label = name_node.text.strip()
# === 自动分配 class_id ===
if label not in class_map:
class_map[label] = next_class_id
next_class_id += 1
class_id = class_map[label]
bndbox = obj.find("bndbox")
if bndbox is None:
continue
xmin = float(bndbox.find("xmin").text)
ymin = float(bndbox.find("ymin").text)
xmax = float(bndbox.find("xmax").text)
ymax = float(bndbox.find("ymax").text)
x_center = ((xmin + xmax) / 2) / w
y_center = ((ymin + ymax) / 2) / h
box_width = (xmax - xmin) / w
box_height = (ymax - ymin) / h
txt_lines.append(
f"{class_id} {x_center:.6f} {y_center:.6f} {box_width:.6f} {box_height:.6f}"
)
# 保存 YOLO txt
txt_file_path = os.path.join(yolo_txt_dir, base + ".txt")
with open(txt_file_path, "w") as f:
f.write("\n".join(txt_lines))
# ===== 输出类别映射 =====
print("\n类别映射 class_map:")
for k, v in class_map.items():
print(f"{v}: {k}")
print(f"\n转换完成!YOLO TXT 文件已保存在: {yolo_txt_dir}")2.数据集拆分
YOLO 推荐训练集和测试集按 8:2 划分,主要是因为目标检测对样本量非常依赖,需要尽可能多的训练数据来学习特征,同时又必须保留足够的独立测试数据来评估模型的真实泛化能力。8:2 被证明在"训练数据够多"与"测试评估足够稳定"之间取得了较好平衡,因此成为默认且通用的实践比例。
这个脚本的作用是从已有的图片和 YOLO 标注文件中随机抽取 200 张图片,并将它们按照训练集和验证集的比例进行划分,然后将对应的图片和 TXT 标注文件复制到新的数据集目录中,方便直接用于训练 YOLO 模型。脚本会先创建训练集和验证集的图片、标签子目录,然后随机选择 指定数量的张图片,其中 五分之一作为验证集,其余 五分之四作为训练集,复制过程中会保证每张图片对应的标注文件也被同步复制,如果标注文件不存在,会生成一个空的 TXT 文件,以保持文件结构完整。运行完成后,新的数据集就整理好了,可以直接用于训练和验证。。最终会在目标目录下生成:

执行脚本step2_auto_part.py
bash
import os
import random
import shutil
from train_conf import BASE_DIR
# 原始数据路径
img_dir = BASE_DIR + "images"
label_dir = BASE_DIR + "labels"
# 新数据集路径
dataset_dir = BASE_DIR + "dataset"
MAX_IMAGE_COUNT = 400
SP_COUNT = int(MAX_IMAGE_COUNT * 0.2)
train_img_dir = os.path.join(dataset_dir, "train", "images")
train_label_dir = os.path.join(dataset_dir, "train", "labels")
val_img_dir = os.path.join(dataset_dir, "val", "images")
val_label_dir = os.path.join(dataset_dir, "val", "labels")
# 创建目录
for dir_path in [train_img_dir, train_label_dir, val_img_dir, val_label_dir]:
os.makedirs(dir_path, exist_ok=True)
# 获取所有图片文件
all_images = [f for f in os.listdir(img_dir) if f.lower().endswith((".jpg", ".png", ".jpeg"))]
# 随机抽取MAX_IMAGE_COUNT张
if len(all_images) < MAX_IMAGE_COUNT:
raise ValueError(f"图片数量不足MAX_IMAGE_COUNT张,当前数量: {len(all_images)}")
selected_images = random.sample(all_images, MAX_IMAGE_COUNT)
# 分割训练集和验证集
random.shuffle(selected_images)
val_images = selected_images[:SP_COUNT]
train_images = selected_images[SP_COUNT:]
def copy_files(image_list, target_img_dir, target_label_dir):
for img_file in image_list:
# 复制图片
src_img_path = os.path.join(img_dir, img_file)
dst_img_path = os.path.join(target_img_dir, img_file)
shutil.copy(src_img_path, dst_img_path)
# 对应的txt
label_file = os.path.splitext(img_file)[0] + ".txt"
src_label_path = os.path.join(label_dir, label_file)
if os.path.exists(src_label_path):
dst_label_path = os.path.join(target_label_dir, label_file)
shutil.copy(src_label_path, dst_label_path)
else:
# 如果没有对应txt文件,创建一个空文件
open(os.path.join(target_label_dir, label_file), "w").close()
# 复制训练集
copy_files(train_images, train_img_dir, train_label_dir)
# 复制验证集
copy_files(val_images, val_img_dir, val_label_dir)
print(f"随机抽取完成!训练集: {len(train_images)} 张,验证集: {len(val_images)} 张")
print(f"数据集路径: {dataset_dir}")3.模型训练
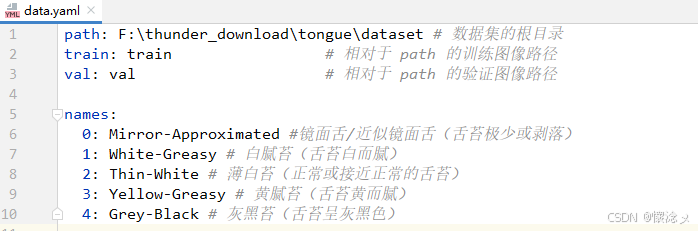
数据集准备好之后就可以开始模型训练了,我们首先准备一个训练的配置文件,比如说是data.yaml
然后就可以开始模型训练了,直接执行我们准备好的train.bat文件,内容就是下面的内容
bash
yolo task=detect mode=train model=../data/model/yolov8n.pt data=./data.yaml epochs=30 imgsz=640 batch=16 lr0=0.01用户亦可执行step3_train_model.py脚本进行模型训练
python
from ultralytics import YOLO
def main():
# 加载模型
model = YOLO("../data/model/yolov8n.pt")
# 开始训练
model.train(
data="./data.yaml", # 数据集配置
epochs=50, # 训练轮数
imgsz=640, # 输入尺寸
batch=16, # batch size
lr0=0.01, # 初始学习率
task="detect" # 任务类型
)
if __name__ == "__main__":
main()然后模型就开始训练了
这里我贴一些训练验证结果截图
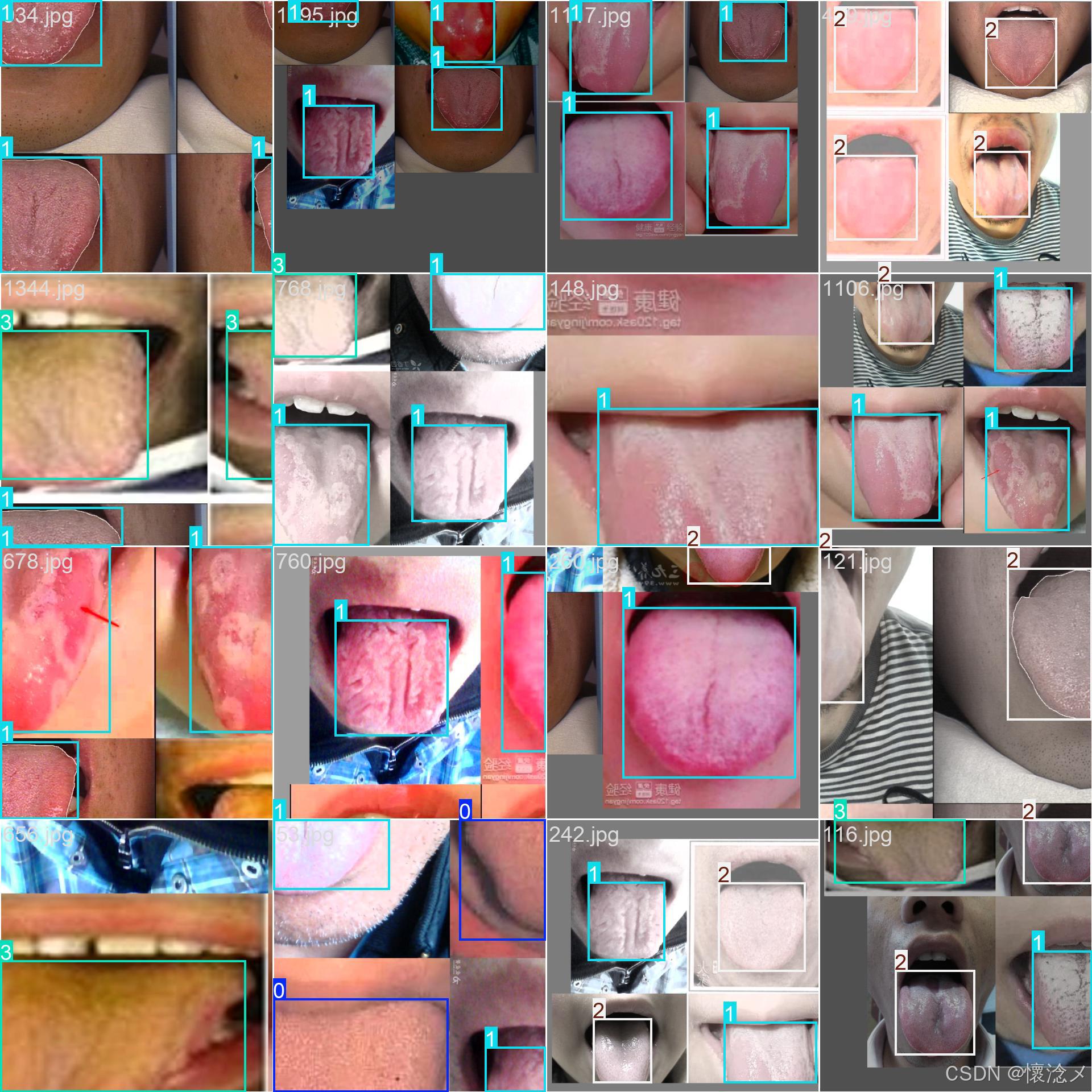
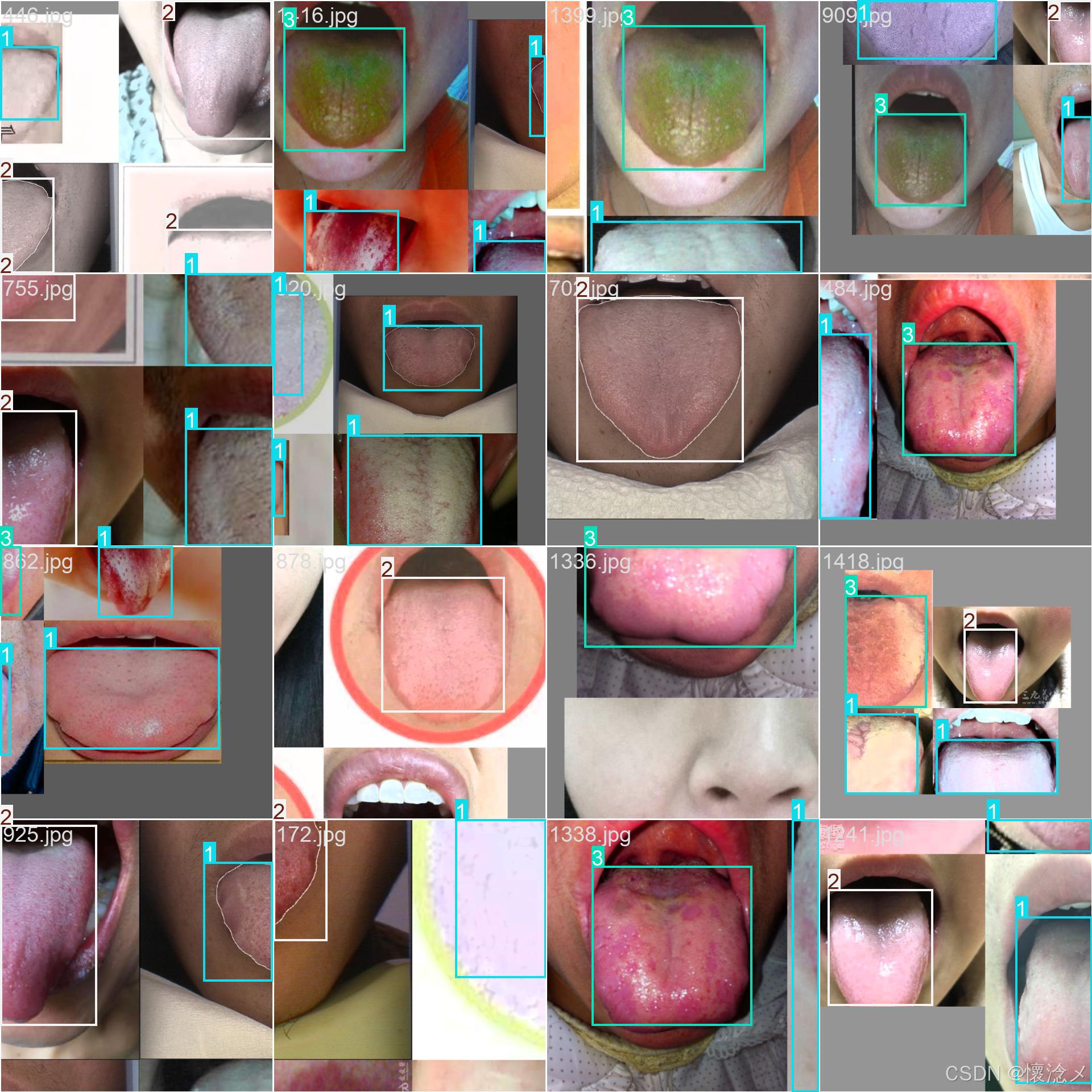
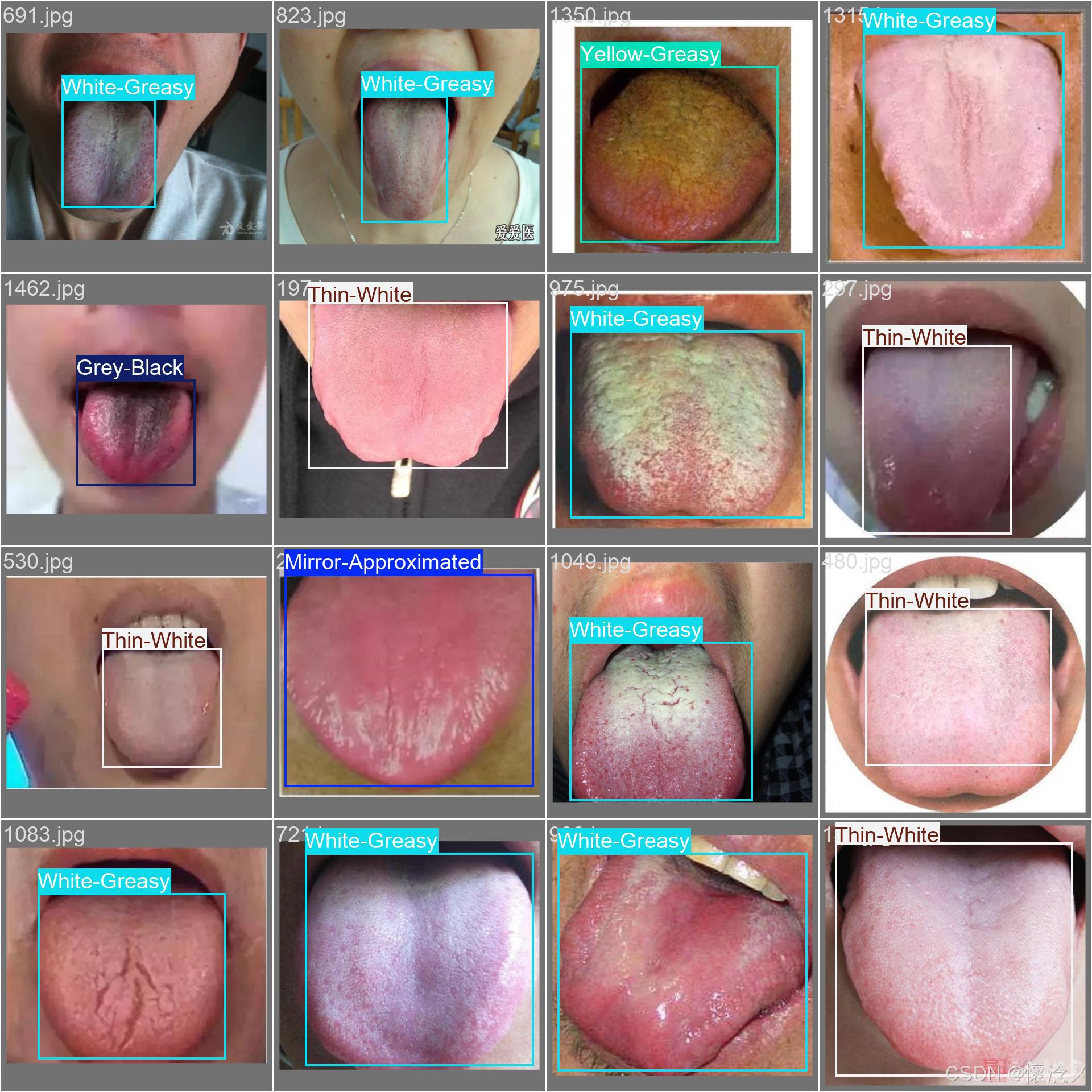
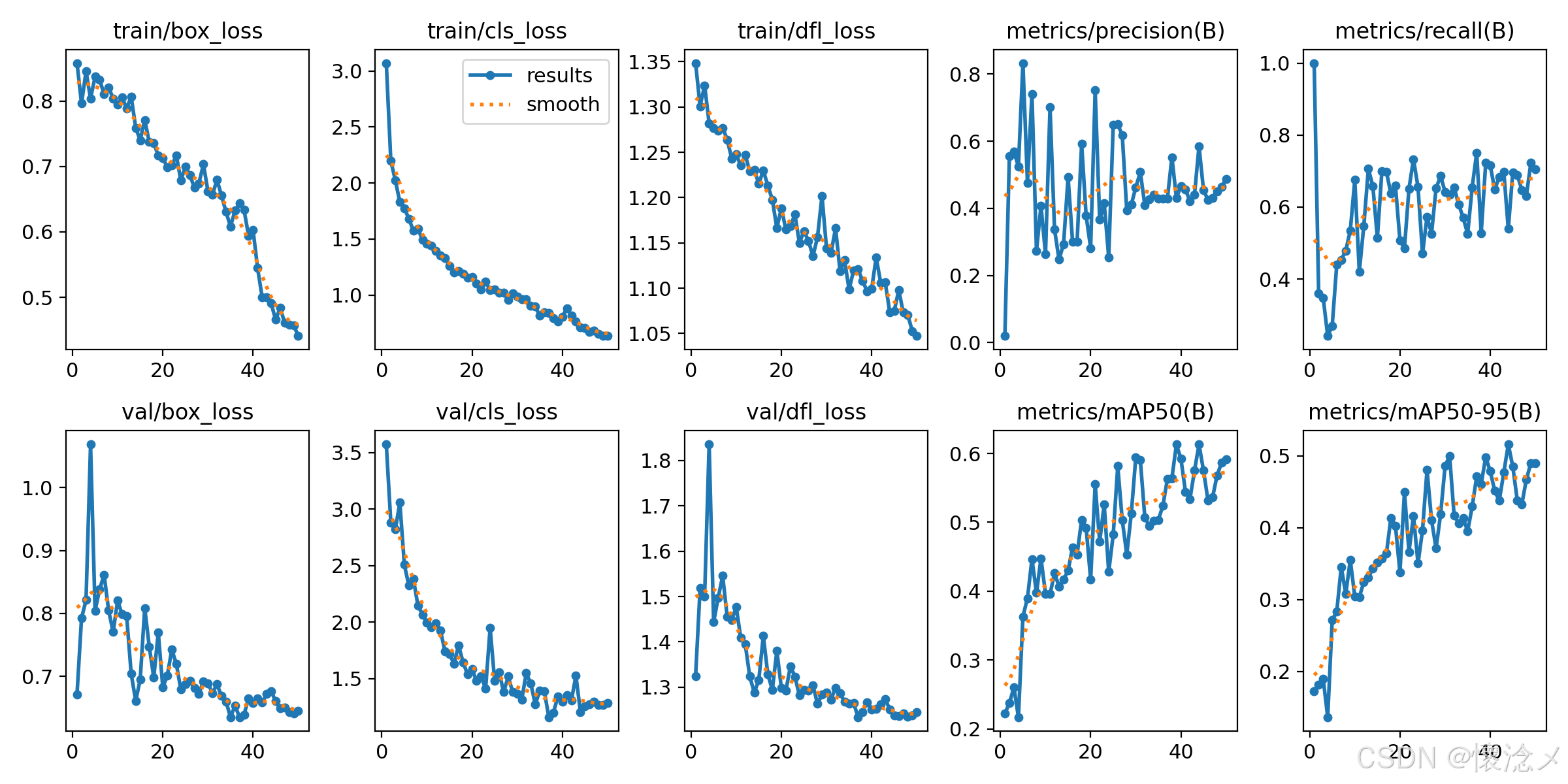
最后的results.png见下图,训练效果还是可以的!
bash
# ✅ **整体结论**
本次训练整体表现为:
👉 **稳定收敛 + 检测能力持续提升 + 后期进入性能平台期**
但存在明确不足:
⚠️ **precision 波动显著、定位损失(dfl_loss)优化有限、指标震荡明显**
因此更准确的评价为:
👉 **"收敛良好、检测可用,但鲁棒性与精度仍有提升空间的训练结果"**
---
# 📉 **一、收敛质量分析(基于实际 loss 变化)**
## ✅ 1. 训练损失持续下降(收敛明确)
| Loss | Epoch 1 | Epoch 50 | 降幅 |
|------|---------|----------|------|
| `train/box_loss` | 0.858 | 0.441 | **↓48.6%** |
| `train/cls_loss` | 3.071 | 0.636 | **↓79.3%** |
| `train/dfl_loss` | 1.348 | 1.047 | **↓22.3%** |
👉 分类能力提升显著,定位能力改善相对有限(常见现象)
## ✅ 2. 验证损失同步下降(无明显过拟合)
| Loss | Epoch 1 | Epoch 50 | 变化 |
|------|---------|----------|------|
| `val/box_loss` | 0.672 | 0.645 | **基本持平** |
| `val/cls_loss` | 3.573 | 1.283 | **↓64.1%** |
| `val/dfl_loss` | 1.324 | 1.246 | **小幅优化** |
👉 验证集 loss 未显著高于训练集
👉 但仍存在阶段性波动(如 epoch 4、24 附近)
📌 **结论**:
✔ 无过拟合
⚠️ 模型收敛不完全平滑,仍存在轻微不稳定
---
# 🚀 **二、检测性能演化(基于 mAP / precision / recall)**
## ✅ 1. 初期(epoch 1--5):快速建立基础能力
- mAP50:0.22 → 0.36
- precision:0.02 → 0.83(剧烈波动)
- recall:1.0 → 0.27(明显回落)
👉 典型 warmup 阶段
⚠️ 指标极不稳定,但模型已"学会检测"
## ✅ 2. 中期(epoch 6--25):性能增长 + 波动并存
- mAP50:0.39 → **0.55**
- mAP50-95:0.28 → **0.45**
- recall:逐步提升至 **0.65+**
👉 整体提升趋势清晰
⚠️ precision / recall 多次出现明显反复(epoch 9--12、17--20)
📌 **数据可能存在一定复杂性或噪声,模型仍在寻找稳定决策边界**
## ✅ 3. 后期(epoch 30--50):进入平台期
最终性能(epoch 50):
| 指标 | 值 |
|------|-----|
| mAP50 | **0.592** |
| mAP50-95 | **0.490** |
| precision | 0.488 |
| recall | 0.705 |
👉 mAP 持续提升并稳定在较高水平
👉 recall 明显高于 precision
📌 **模型偏向"多检出"(高召回),但存在一定误检(precision偏低)**
---
# 🎯 **三、Precision / Recall 结构分析(本次训练关键特征)**
- **recall**:从 epoch 30 起稳定在 **0.65--0.75**
- **precision**:始终在 **0.25--0.75** 之间大幅波动(epoch 5、7、10、15、21、26 等)
👉 典型 **高召回、低精度稳定** 结构
📌 含义:
✔ 优点:不易漏检(适合安全类场景)
⚠️ 风险:误检偏多,输出结果"干净度"一般
---
# 📊 **四、mAP 表现(本次训练最大亮点)**
- mAP50 从 0.22 → **0.59**
- mAP50-95 从 0.17 → **0.49**
👉 **持续增长,无显著回退**
👉 后期稳定在高位
📌 **模型整体检测能力是可靠的**
⚠️ 但检测质量(精度)明显落后于召回能力
---
# ⚙️ **五、学习率策略与实际表现对应关系**
- 初期(warmup):lr 升至 0.001 → 快速建立能力
- 后期:lr 衰减至 3.3e-5 → 稳定优化
👉 实际对应现象:
✔ 前期快速收敛
⚠️ 后期指标仍存在波动(说明 lr 衰减未能完全抑制震荡)
📌 **LR 策略有效,但并非最优**
---
# 🧠 **六、本次训练的关键问题总结**
| 问题 | 严重程度 | 说明 |
|------|----------|------|
| precision 波动 | ⚠️ 中高 | 长期在 0.3--0.7 反复 |
| dfl_loss 优化有限 | ⚠️ 中 | 定位能力提升缓慢 |
| 指标震荡 | ⚠️ 中 | 尤其在中期 |
| 高召回、低精度 | ⚠️ 中 | 可用但不够干净 |
| 过拟合 | ✅ 无 | --- |
---
# 🏁 **最终评价(基于本次训练数据)**
👉 **本次训练可以明确定义为:**
> **"收敛良好、检测能力可用,但预测精度与稳定性仍存在明显不足的中等偏上质量训练结果"**
---
# 📌 一句话总结(贴合本次数据)
👉
**模型训练过程整体稳定并成功收敛,mAP50 达到 0.59、mAP50-95 达到 0.49,召回能力持续提升至 0.70+,但 precision 长期大幅波动,最终维持在 0.49 左右,表现为明显的高召回导向,模型具备实际检测能力,但误检偏多、定位提升有限,仍有明确优化空间。五.关于项目
1.开发环境
本系统是在 Windows 11 操作系统上进行开发的,Python 环境采用的是 Python 3.8 版本,硬件方面使用的是 AMD 处理器 ,未配备独立显卡,开发工具为 *PyCharm 2021.3
- 版本。在整个开发与测试过程中,我们严格遵循了上述环境配置,确保了系统的稳定运行。在此特别建议所有使用者:为了避免出现因版本过新而导致的"不兼容"情况,请大家尽量不要使用过高的 Python 版本(如 Python 3.11 及以上),也不要使用最新的 PyCharm 或操作系统版本。因为较新的环境可能对部分依赖库或语法特性支持不佳,容易引发意外的报错或功能异常。遵循本项目所推荐的版本配置,能够最大程度地保证系统的顺利部署与稳定运行。
2.项目部署
1.项目依赖
博主是在Windows电脑上使用Python3.8开发的本系统,建议大家使用的Python版本别太高。
其中项目依赖为:
bash
PyQt5==5.15.11
QtAwesome==1.3.1
torch==2.4.1
torchvision==0.19.1
Pillow==9.3.0
pyqtgraph===0.13.3
PyQtWebEngine==5.15.5
opencv-python==4.10.0.82
ultralytics==8.3.234
Requests==2.32.5
pandas==2.0.3
numpy==1.24.4
Markdown==3.4.4我已经整理到了requirements.txt,大家直接使用命令
pip install -r requirements.txt
即可一键安装项目依赖,其中的torch和torchvision只要匹配即可,不一定非要和博主开发环境的版本一致。
2.项目结构
很多小伙伴担心拿到代码后项目看不懂,这个大家不必担心,我们采用文件+类名对相关功能进行了模块化定义,大家见名知意。
下图博主采用tree命令生成了文件、目录树
bash
tree "D:\projects\gitee\2026\yolo_projects\yolov8-tongue-detect" /f /a
bash
D:\PROJECTS\GITEE\2026\YOLO_PROJECTS\yolov8-tongue-detect
| main.py
| record.txt
| requirements.txt
|
+---data
| +---database
| | data.db
| |
| +---db
| | db.csv
| |
| +---font
| | hanyi_yahei.ttf
| |
| |
| \---model
| best.pt
| yolov8n.pt
+---script
| create_qrc.py
|
\---src
+---conf
| style_conf.py
| system_conf.py
| test_data.py
| __init__.py
|
+---engine
| engines.py
| __init__.py
|
+---resource
| | resource.qrc
| | resource_rc.py
| | __init__.py
| |
| +---imgs
| | ai.gif
| | ai.svg
| | bg.jpeg
| | login_gif.gif
| |
| \---js
| echarts.min.js
|
+---threads
| main_threads.py
| signal_bus.py
| __init__.py
|
+---utils
| custom_utils.py
| __init__.py
|
\---widgets
base_widgets.py
custom_pages.py
custom_widgets.py
main_page.py
unique_widgets.py
__init__.py
3.项目启动
本系统的项目启动十分简单:在安装好所有相关依赖之后,直接执行 main.py 文件,即可自动打开系统的登录注册页面。用户进入该页面后,通过输入匹配的用户名和密码完成登录操作。为方便初次体验,系统内置了一个默认账号,用户名为 admin,密码也为 admin,用户可以直接使用这组账号进行快速登录。当用户成功登录后,系统主界面会完整展示出来,而之前的登录注册页面则会自动隐藏,从而为用户提供清晰、流畅的操作体验。
4.往期优秀作品
六.总结
本项目旨在开发一款基于 PyQt5、YOLOv8 与 DeepSeek 技术融合的舌苔情况检测系统,实现对视频流或图像数据中人员是否佩戴安全帽的自动识别与智能分析。通过引入高精度目标检测算法 YOLOv8,提高复杂环境下的识别准确率,并结合 DeepSeek 的语义理解能力,对检测结果进行进一步分析与优化,同时借助 PyQt5 构建友好的人机交互界面,实现实时监控与结果可视化。该系统可广泛应用于建筑工地、工厂车间等高风险作业场景,有效减少人工巡检成本,提升安全监管效率,降低安全事故发生概率,对于推动智慧工地建设与安全生产信息化具有重要现实意义。
本次给大家介绍了我使用PyQt5+YOLOv8+DeepSeek的舌苔情况检测系统,本系统功能强大,支持多种数据源输入,包含多种用户交互按钮以及模式,内置数据可视化方案、大模型AI加持,是您学习、工作使用的不错选择!
需要代码的朋友可以点击箭头下方的二维码加我好友,欢迎您了解!
如需帮助请私聊博主!