大模型数据飞轮核心技术一篇讲透:原理、架构、企业级案例与2026最全实践指南
目录
- 大模型数据飞轮核心技术一篇讲透:原理、架构、企业级案例与2026最全实践指南
-
- 前言
- 一、痛点场景:大模型时代的四大"数据困境"
- 二、痛点解决方案:数据飞轮的本质
- 三、是什么------极简概念与原理
-
- [3.1 数据飞轮的起源与扩散](#3.1 数据飞轮的起源与扩散)
- [3.2 从"以模型为中心"到"以数据为中心"](#3.2 从"以模型为中心"到"以数据为中心")
- [3.3 数据飞轮的四层闭环](#3.3 数据飞轮的四层闭环)
- [3.4 MAPE控制循环------Agentic时代的数据飞轮核心](#3.4 MAPE控制循环——Agentic时代的数据飞轮核心)
- [3.5 从"Stack"到"Loops"的范式重构](#3.5 从"Stack"到"Loops"的范式重构)
- [3.6 大白话理解数据飞轮](#3.6 大白话理解数据飞轮)
- 四、为什么用------核心优势与对比
-
- [4.1 数据飞轮 vs 传统一次性训练](#4.1 数据飞轮 vs 传统一次性训练)
- [4.2 数据飞轮 vs 简单反馈循环](#4.2 数据飞轮 vs 简单反馈循环)
- [4.3 核心价值:四大特性](#4.3 核心价值:四大特性)
- [4.4 效率对比:人工标注 vs 开源数据 vs 按需自动生成](#4.4 效率对比:人工标注 vs 开源数据 vs 按需自动生成)
- [4.5 企业级ROI数据验证](#4.5 企业级ROI数据验证)
- 五、怎么用------保姆级Python实战教学
-
- [5.1 环境准备](#5.1 环境准备)
- [5.2 最简飞轮实战------100行Python构建Human-in-the-Loop数据飞轮](#5.2 最简飞轮实战——100行Python构建Human-in-the-Loop数据飞轮)
- [5.3 合成数据飞轮实战](#5.3 合成数据飞轮实战)
- [5.4 从反馈日志到微调数据集](#5.4 从反馈日志到微调数据集)
- [5.5 飞轮可视化管理](#5.5 飞轮可视化管理)
- [5.6 调试与验证技巧](#5.6 调试与验证技巧)
- 六、常用场景列举
- 七、专业解释+大白话+生活案例
-
- [7.1 硬核原理一:MAPE控制循环的架构设计](#7.1 硬核原理一:MAPE控制循环的架构设计)
- [7.2 硬核原理二:合成数据的质量保证链路](#7.2 硬核原理二:合成数据的质量保证链路)
- [7.3 硬核原理三:为什么飞轮会"越转越省"](#7.3 硬核原理三:为什么飞轮会"越转越省")
- 八、面试官高频面试题(8道Q&A)
-
- [Q1: 请解释什么是数据飞轮?它与传统的反馈循环有什么区别?](#Q1: 请解释什么是数据飞轮?它与传统的反馈循环有什么区别?)
- [Q2: MAPE控制循环是什么?请描述其在数据飞轮中的应用。](#Q2: MAPE控制循环是什么?请描述其在数据飞轮中的应用。)
- [Q3: 数据飞轮的四大构建模式是什么?请详细说明。](#Q3: 数据飞轮的四大构建模式是什么?请详细说明。)
- [Q4: 为什么数据飞轮能实现"越转越省"?](#Q4: 为什么数据飞轮能实现"越转越省"?)
- [Q5: 如何处理数据飞轮中的"冷启动"问题?](#Q5: 如何处理数据飞轮中的"冷启动"问题?)
- [Q6: 数据飞轮与数据中台有什么区别?](#Q6: 数据飞轮与数据中台有什么区别?)
- [Q7: 在构建数据飞轮时,如何平衡"数据质量"和"数据数量"?](#Q7: 在构建数据飞轮时,如何平衡"数据质量"和"数据数量"?)
- [Q8: 如何评估数据飞轮的效果?请列出关键指标。](#Q8: 如何评估数据飞轮的效果?请列出关键指标。)
- 九、企业级实战指导
-
- [9.1 技术选型决策树](#9.1 技术选型决策树)
- [9.2 成本控制与Token效率优化](#9.2 成本控制与Token效率优化)
- [9.3 从离线飞轮到线上闭环的迁移路线](#9.3 从离线飞轮到线上闭环的迁移路线)
- [9.4 生产环境避坑指南](#9.4 生产环境避坑指南)
- [9.5 2026年前沿趋势与未来展望](#9.5 2026年前沿趋势与未来展望)
- 十、总结
前言
2026年3月,中国日均Token调用量突破140万亿。这个数字意味着什么?意味着每天有140万亿个语义单元在被计算、被理解、被生成------而就在两年前(2024年初),这个数字还仅仅是1000亿。两年增长超千倍,这不是发生在实验室,而是发生在每一次智能对话、每一张AI生成的图片、每一个自主执行任务的智能体背后。
然而,在这场AI应用爆发的浪潮中,一个残酷的现实正在显现:大模型的核心竞争力不只是模型参数,更是让数据流动起来产生复利的系统工程。 当企业投入重金训练出"聪明"的模型后,却发现模型上线3个月后越用越蠢------V1准确率88%,V2反而跌到82%。这不是个例,而是数据工程缺失的普遍代价。
今天,我们深入探讨大模型时代最重要的工程范式------数据飞轮(Data Flywheel) 。这不是一个简单的"反馈循环",而是一个自我加速的增长引擎。信通院在《智能原生研究报告(2026年)》中明确指出:高效数据飞轮是"数据---模型---用户---反馈"之间形成的正向循环增强效应,即用得人越多,产品越聪明,用得人越多。
本文将从痛点场景出发,深入剖析数据飞轮的核心原理、四大构建模式、2026年企业级落地案例(DoorDash、NVIDIA、京东、阿里云、华为等),并提供保姆级Python实战教学。无论你是算法工程师、数据工程师,还是技术管理者,这篇文章都将帮助你构建系统化的数据飞轮思维,在AI应用落地的深水区建立真正的竞争壁垒。
一、痛点场景:大模型时代的四大"数据困境"
在深入理论之前,让我们先看看大模型从业者每天都在经历的四个典型翻车现场。这些场景并非虚构,而是来自真实的工程实践。
场景一:模型上线3个月,越用越蠢
某电商平台的推荐系统团队遇到了一个诡异的现象:模型V1版本在线上跑了3个月后,准确率从最初的88%持续下滑,最终跌到了令人担忧的82%。团队百思不得其解------明明每天都有新数据进来,为什么模型反而变差了?
经过深入排查,真相浮出水面:模型在持续服务过程中,大量用户因为初期推荐不准而流失,留下的用户群体特征发生了偏移。同时,线上数据分布与训练数据分布逐渐产生漂移(Data Drift),但模型没有机制去捕获这种变化。更糟糕的是,用户反馈数据被分散存储在多个系统中,没有任何流程将这些反馈转化为模型改进的燃料。
这是一个典型的数据与模型割裂困境:数据在产生,但没有数据回到训练流程中形成闭环。
场景二:等标注团队产出新数据,竞品已经迭代了三版
某AI公司的算法团队正在紧急优化一个客服对话模型。产品经理反馈用户对某个场景的满意度很低,要求尽快优化。算法工程师开始梳理需求、准备数据、发送给标注团队。
然后开始等待。
标注团队需要在繁忙的队列中安排这个任务。标注完成后,还需要质检、清洗、格式转换。最后,算法工程师终于拿到数据,开始训练、调参、评估。全部流程走完,六周已经过去了。
六周是什么概念?在AI军备竞赛的当下,竞品可能已经迭代了三个版本。这就是人工标注回灌的时效性困境:从发现问题到模型改进的周期太长,机会窗口往往已经关闭。
场景三:公开数据集跑得很好,线上真实场景就翻车
很多团队都有过这样的经历:买了一堆高质量的公开数据集,在离线评测上效果惊艳,兴冲冲地上线,结果用户反馈"一塌糊涂"。
原因在于:公开数据集无法代表你的真实业务场景。 公开数据集的文本风格、话题分布、用户意图与实际用户群体往往存在显著差异。就像你在一线城市的数据上训练了外卖推荐模型,结果在三四线城市上线,用户的使用习惯完全不同,效果自然大打折扣。
这是数据与场景割裂的典型症状:数据来源与应用场景的错配,是AI落地最常见的坑之一。
场景四:Agent越智能,Token消耗越失控,ROI越算越亏
2026年,Token调用成本已经成为企业AI应用的生死线。中国日均Token调用量突破140万亿,但与此同时,阿里云、腾讯云等云厂商相继上调AI算力服务价格,高端GPU"一卡难求"。
某企业的AI客服Agent经过多次迭代,功能越来越强大。但财务团队在季度复盘时发现:Agent的Token消耗量是最初的20倍,而带来的收益增长不到3倍。ROI算下来,这个"智能"Agent反而成了成本中心。
这不是技术问题,而是数据飞轮缺失导致的成本失控。没有高效的飞轮机制,Agent每次推理都是"从头开始",无法通过历史交互积累知识,导致相同问题被重复处理,Token被无谓消耗。
核心矛盾的本质
这四个场景指向同一个核心矛盾:大模型时代,数据不只是"原材料",更应该是"可持续增值的资产"。 传统的数据处理模式------收集数据、训练模型、部署上线、然后等下一轮数据收集------本质上是一个线性管道 ,而不是一个闭环飞轮。
传统模式的致命缺陷在于:数据在流动,但没有形成复利效应。每一次循环只是"弥补短板",而不是"主动进化"。这就是为什么那么多企业在AI上投入巨大,却始终无法建立真正的竞争壁垒。
二、痛点解决方案:数据飞轮的本质
面对上述困境,数据飞轮提供了一种全新的工程范式。
数据飞轮的本质
数据飞轮的本质,是用**"系统的力量"替代"人的勤劳"。**
信通院在《智能原生研究报告(2026年)》中给出了明确定义:高效数据飞轮是"数据---模型---用户---反馈"之间形成的正向循环增强效应。
与传统线性管道的关键区别在于:
传统反馈循环(被动应对):
发现错误 -> 修正数据 -> 重新训练 -> 部署每次修正只是"弥补短板",是被动的、滞后的。
数据飞轮(主动进化):
生产数据 -> 模型训练 -> 部署应用 -> 采集信号 -> 自增强生成每次循环不仅修正错误,更通过奖励机制放大正确决策的影响,形成自我加速的增长引擎。
2026年趋势数据支撑
工信部2026年"模数共振"行动明确指出:要构建"行业模型赋能应用实践、应用实践产生场景数据、场景数据优化行业模型"的良性飞轮 。北京大学张文涛教授团队的研究表明,通过DataFlow框架构建的数据飞轮,仅用1万个高质量样本训练的AI模型,就能超越使用100万个普通样本训练的模型------数据质量胜过数量。
而NVIDIA的企业级实践更是给出了量化数据:使用数据飞轮优化后的模型,推理成本降低最高可达98.6%。
核心公式
数据飞轮的价值可以用以下公式概括:
飞轮价值 = 数据效率 × 迭代速度 × 质量增益 × 成本递减- 数据效率:从原始数据到可用训练数据的转化率
- 迭代速度:从发现问题到模型改进的周期
- 质量增益:每轮迭代带来的模型性能提升
- 成本递减:随着飞轮转动,边际成本逐渐降低
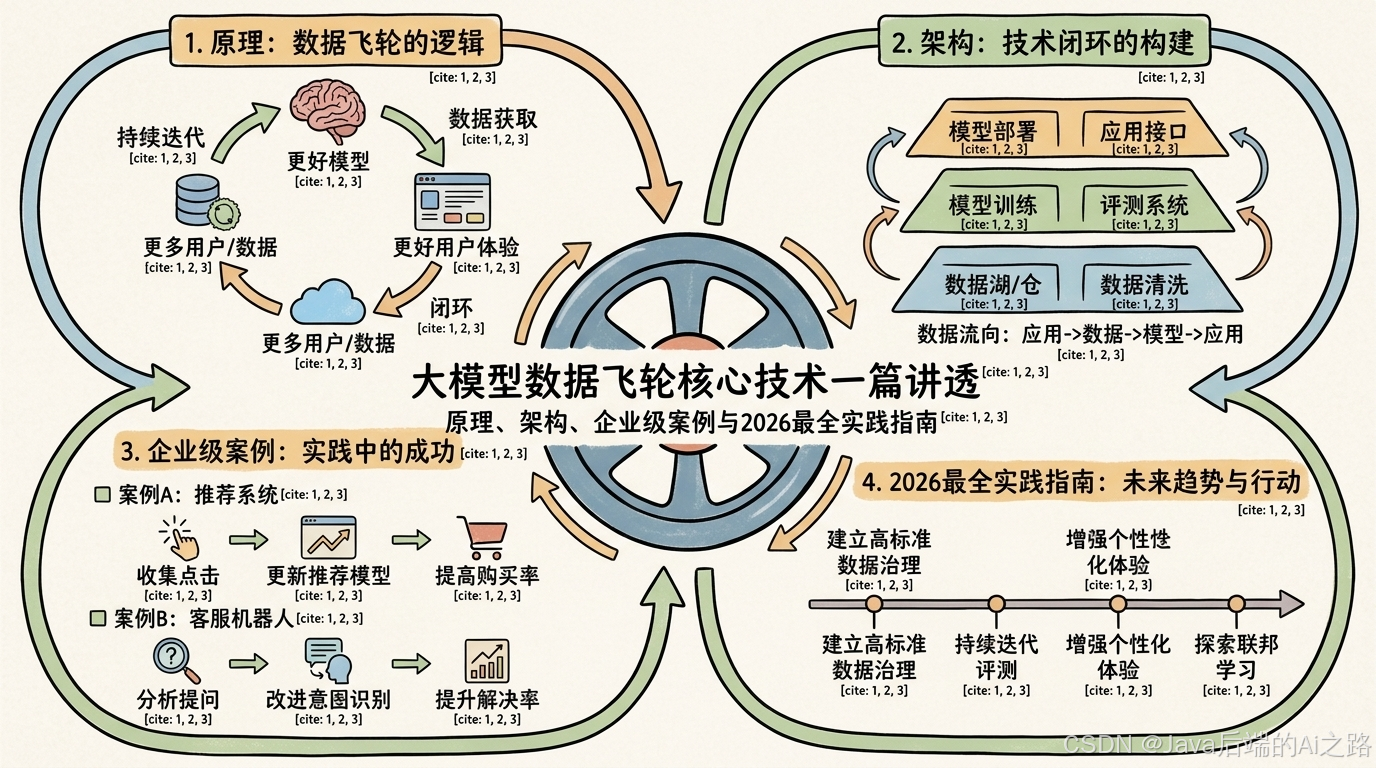
三、是什么------极简概念与原理
3.1 数据飞轮的起源与扩散
数据飞轮(Data Flywheel) 这个概念最早可以追溯到亚马逊创始人贝佐斯的"飞轮效应":一个自我强化的正反馈循环,一旦转动起来,就会因为惯性而越转越快。贝佐斯将这一理念应用于亚马逊的商业模式:更多卖家带来更多选择 -> 更多选择吸引更多用户 -> 更多用户带来更多流量 -> 更多流量吸引更多卖家 -> 更低的成本和更低的价格。
大模型时代,数据飞轮被赋予了新的内涵。与传统互联网产品不同,大模型的核心能力来自于数据与模型的协同进化。当数据飞轮转动起来后,会形成以下正向增强效应:
用户使用 -> 产生交互数据 -> 数据清洗标注 -> 模型优化 -> 产品体验提升 -> 更多用户使用这就是为什么领先的大模型企业都在拼命构建自己的数据飞轮:谁先转动飞轮,谁就能在数据积累上形成优势,而这个优势会随着时间不断放大。
3.2 从"以模型为中心"到"以数据为中心"
AI领域有一个重要的范式转变,从Model-Centric AI(以模型为中心)到Data-Centric AI(以数据为中心)。
以模型为中心:研究重点是如何改进模型架构、训练算法,假设数据是固定的。工程师花费大量时间调参、换模型,但数据质量始终是瓶颈。
以数据为中心:研究重点是如何提升数据质量、多样性、代表性,假设模型能力已经足够。北京大学DCAI团队提出的DataFlow框架,正是这一理念的典型代表------他们证明,用高质量的1万个样本可以打败低质量的100万个样本。
这个转变的意义在于:在Scaling Law逐渐趋于平稳的今天,数据质量成为突破模型性能上限的关键。 而数据飞轮正是实现持续数据质量提升的系统工程。
3.3 数据飞轮的四层闭环
数据飞轮的整体架构可以理解为一个四层同心环结构:
外层 - 业务闭环(Business Loop)
用户需求 <-> 产品服务 <-> 用户反馈 <-> 需求更新这一层关注的是业务价值:用户需要什么,我们提供什么,用户反馈如何改进服务。
中Outer层 - 数据采集闭环(Data Collection Loop)
用户交互 -> 行为日志 -> 数据标注 -> 数据存储 -> 质量验证这一层关注的是数据获取:将分散的用户行为转化为结构化的数据资产。
中Inner层 - 模型训练闭环(Training Loop)
训练数据 -> 模型训练 -> 效果评估 -> 失败分析 -> 数据增强这一层关注的是模型优化:从失败样本出发,生成更有针对性的训练数据。
内层 - 在线推理闭环(Inference Loop)
实时请求 -> RAG检索 -> 模型推理 -> 响应生成 -> 结果反馈这一层关注的是服务体验:在生产环境中提供实时智能服务。
核心 - 反馈增强层(Feedback Enhancement)
错误样本 -> 根因分析 -> 策略更新 -> 在线验证 -> 持续学习这是飞轮转动的核心引擎,将所有失败转化为学习的燃料。
3.4 MAPE控制循环------Agentic时代的数据飞轮核心
在Agentic AI时代,数据飞轮的核心机制是MAPE控制循环。这是由NVIDIA在EACL 2026 Industry Track论文中首次系统性地引入到大模型领域的架构设计。
MAPE代表四个核心步骤:
Monitor(监控)
持续收集模型在生产环境中的表现数据,包括:
- 用户反馈(点赞/点踩、评分、投诉)
- 模型输出质量(置信度、毒性、幻觉率)
- 系统性能指标(延迟、吞吐量、Token消耗)
- 任务完成率(Agent是否成功完成任务)
Analyze(分析)
对收集的数据进行深度分析,识别失败模式:
- 路由错误:模型选择了错误的处理路径
- 查询改写错误:用户意图被错误理解
- 知识缺失:模型缺乏领域知识
- 指令遵循错误:输出格式或内容不符合要求
Plan(规划)
基于分析结果,制定优化策略:
- 确定需要改进的具体组件
- 设计针对性的训练数据集
- 选择合适的微调方法(LoRA、SFT等)
- 设定评估指标和目标
Execute(执行)
执行优化计划并部署新模型:
- 使用NeMo Customizer进行模型微调
- 通过NeMo Evaluator进行效果评估
- 部署优化后的模型到生产环境
- 持续监控系统表现,进入新一轮MAPE循环
NVIDIA在其NVInfo AI(服务于30000+员工的MoE知识助手)中实践了MAPE控制循环。在3个月的时间里,系统监控到495个负反馈样本,分析发现两大主要失败模式:路由错误(5.25%)和查询改写错误(3.2%)。通过MAPE循环执行针对性优化,模型参数量从70B缩减到8B(10倍压缩),同时保持96%的路由准确率,延迟降低70%。
3.5 从"Stack"到"Loops"的范式重构
传统软件架构强调的是技术栈(Stack)------从底层到顶层,每一层都服务于上一层。这是一个静态的、分层的结构。
而数据飞轮强调的是循环(Loops)------数据、模型、用户、产品之间形成持续流动的闭环。这是一个动态的、迭代的结构。
这种重构带来的变化是根本性的:
| 维度 | Stack思维 | Loop思维 |
|---|---|---|
| 数据观 | 静态资源,用完即弃 | 动态资产,持续增值 |
| 模型观 | 最终产物,一劳永逸 | 中间产物,持续进化 |
| 迭代观 | 版本发布,周期漫长 | 持续改进,实时优化 |
| 用户观 | 消费者,单向输出 | 共同创造者,双向互动 |
| 竞争观 | 参数规模,模型能力 | 数据闭环,系统效率 |
3.6 大白话理解数据飞轮
让我用三个生活案例来帮你理解数据飞轮的本质:
案例一:餐厅口碑-改进系统
想象一家餐厅:
- 传统模式:顾客吃完饭走了,餐厅等着顾客"下次再来"的反馈,然后猜测哪里做得不好。这种方式太慢,而且反馈往往不准确。
- 飞轮模式:餐厅建立了完整的反馈系统------顾客吃完饭,服务员主动询问"今天的菜怎么样",收集差评后立即改进配方,改进后再请顾客体验。形成"顾客反馈 -> 快速改进 -> 更好体验 -> 更多好评 -> 更多顾客"的正向循环。
数据飞轮就像给餐厅装上了一个"自动化的反馈-改进-验证"系统,让改进速度跟上了顾客需求的变化。
案例二:手工作坊 vs 智能工厂
传统的数据处理流程就像手工作坊:
- 每个步骤都需要人工介入
- 工具不通用,换个项目就要重新定制
- 质量依赖工人经验,难以复制
- 效率低,产能有限
数据飞轮就像智能工厂:
- 标准化流水线,模块可复用
- 自动化的质量检测和反馈机制
- 数据驱动决策,减少人工干预
- 产能弹性扩展,效率持续提升
北京大学DCAI团队开发的DataFlow框架,就是将数据准备从"手工作坊"升级为"智能工厂"的典型尝试------提供近200个可复用的算子,支撑6大领域的标准化数据处理管道。
案例三:开车方式升级
传统训练模式就像手动挡汽车:
- 每次换挡都需要驾驶员操作
- 加速减速都需要离合配合
- 驾驶员必须时刻关注路况
- 效率取决于驾驶员的操作水平
数据飞轮就像自动驾驶:
- 系统自动感知路况
- 根据目的地自动规划路径
- 持续学习,驾驶技术越来越好
- 驾驶员可以专注其他事务
四、为什么用------核心优势与对比
4.1 数据飞轮 vs 传统一次性训练
| 对比维度 | 传统一次性训练 | 数据飞轮 |
|---|---|---|
| 数据利用 | 一次性使用,丢弃旧数据 | 持续积累,数据价值递增 |
| 模型更新 | 周期性大版本更新 | 持续迭代,粒度更细 |
| 错误处理 | 积累到一定量再修复 | 实时捕获,快速响应 |
| 成本曲线 | 边际成本恒定 | 边际成本递减 |
| 效果曲线 | 逐渐衰减 | 持续提升 |
核心差异:传统模式的数据是"消耗品",飞轮模式的数据是"资产"。资产会升值,消耗品会贬值。
4.2 数据飞轮 vs 简单反馈循环
很多团队会说"我们有反馈机制啊"------用户可以点踩,可以提交投诉。但这种"反馈机制"与真正的数据飞轮有本质区别:
| 对比维度 | 简单反馈循环 | 完整数据飞轮 |
|---|---|---|
| 反馈收集 | 被动等待用户投诉 | 主动埋点全量采集 |
| 数据处理 | 人工查看,效率低下 | 自动聚类、归因 |
| 改进触发 | 需要人工决策 | 阈值自动触发 |
| 改进执行 | 需要人工操作 | 自动微调部署 |
| 效果验证 | 等待下一个周期 | 实时A/B测试 |
| 知识沉淀 | 经验随人员流动 | 固化为模型能力 |
简单反馈循环是被动的、人工的、低频的;数据飞轮是主动的、自动的、高频的。
4.3 核心价值:四大特性
持续增长性(Continuous Growth)
数据飞轮转动的时间越长,积累的数据越多,模型越精准,体验越好,用户越多,产生的数据越多。这是典型的复利效应。
NVIDIA的实践表明,在3个月的飞轮运行中,系统自动识别并修复了5.25%的路由错误和3.2%的查询改写错误,这些改进是传统开发流程难以企及的。
成本递减性(Cost Degression)
随着飞轮转动,单位数据处理成本持续下降。原因有三:
- 工具和流程趋于成熟,重复建设成本降低
- 模型效率提升,同等任务消耗更少Token
- 自动化程度提高,人工介入减少
NVIDIA的企业级案例显示,通过数据飞轮优化,推理成本可降低高达98.6%。
质量递进性(Quality Escalation)
每一轮迭代不仅修复已知问题,更发现新问题、生成新数据、训练新能力。这是一个螺旋上升的过程,而非原地踏步。
场景闭合性(Scenario Closure)
数据飞轮确保模型始终贴合真实场景。公开数据集的问题在于"代表性问题",而飞轮通过持续采集线上数据,确保模型学习的就是它将要处理的真实分布。
4.4 效率对比:人工标注 vs 开源数据 vs 按需自动生成
| 数据来源 | 成本 | 时效性 | 场景匹配度 | 规模扩展性 |
|---|---|---|---|---|
| 人工标注 | 高($0.1-1/样本) | 低(数周) | 高(定制采集) | 差 |
| 开源数据 | 低(免费) | 中(数据集发布周期) | 低(通用场景) | 一般 |
| 按需自动生成 | 中等(API成本) | 高(实时生成) | 高(基于真实分布) | 好 |
数据飞轮的核心价值在于:用按需自动生成的方式,结合线上真实数据分布,实现高质量、低成本、快时效的数据供给。
4.5 企业级ROI数据验证
DoorDash客服飞轮案例
DoorDash的AI客服系统通过构建数据飞轮,实现了以下成果:
- 幻觉率降低90%:通过持续监控和反馈机制,将模型生成的错误信息控制在极低水平
- 用户满意度提升:客服问题解决率显著提升
- 运营成本下降:自动化处理比例大幅增加,人工介入减少
NVIDIA NVInfo AI案例
NVIDIA内部知识助手的实践提供了更详细的量化数据:
- 路由组件:模型从Llama 3.1 70B压缩到8B(10倍压缩),同时保持96%准确率,延迟降低70%
- 查询改写组件:准确率提升3.7%,延迟降低40%
- 整体优化:3个月内分析495个负反馈样本,识别并修复主要失败模式
京东JoyAI-LLM Flash案例
京东的JoyAI-LLM Flash模型通过数据飞轮思维优化了Token效率:
- 采用MoE架构,总参数48B,激活参数仅2.7B(稀疏比业界最高)
- 结合人机协同的human-in-the-loop机制动态优化数据配比
- 代码和Agent数据占比约30%,确保模型在关键场景的能力
阿里云AIOps案例
阿里云可观测产品通过数据飞轮支撑智能运维:
- 日处理数据量:百PB级
- 故障恢复时长降低70%
- 整体成本降低30%
- SLA达到99.99%
Momenta自动驾驶案例
自动驾驶领域是数据飞轮应用的先驱:
- 每日处理百万公里级别的真实驾驶数据
- Corner Case自动识别与标注
- 模型持续迭代更新
- 仿真数据与真实数据闭环验证
五、怎么用------保姆级Python实战教学
5.1 环境准备
首先安装必要的依赖包:
bash
pip install foundry openai pandas datasets transformers torch matplotlib scikit-learn主要工具说明:
- foundry:Metaforce提供的企业级数据飞轮框架
- openai:用于API调用和大模型交互
- pandas:数据处理和分析
- datasets:Hugging Face数据集工具
- transformers:模型加载和微调
- matplotlib:飞轮可视化
5.2 最简飞轮实战------100行Python构建Human-in-the-Loop数据飞轮
以下是一个完整的数据飞轮实现,展示了从数据采集到模型更新的完整闭环:
python
"""
Human-in-the-Loop Data Flywheel
构建一个最小可用的数据飞轮系统
"""
import json
import time
from datetime import datetime
from dataclasses import dataclass, asdict
from typing import List, Dict, Optional, Tuple
import pandas as pd
import numpy as np
from collections import defaultdict
# ==================== 数据模型定义 ====================
@dataclass
class UserInteraction:
"""用户交互记录"""
interaction_id: str
user_id: str
timestamp: str
query: str
response: str
feedback: Optional[int] = None # 1: thumbs up, -1: thumbs down
session_id: str = ""
@dataclass
class FeedbackSample:
"""反馈样本(用于微调)"""
sample_id: str
interaction_id: str
query: str
good_response: str
bad_response: Optional[str] = None
category: str = "general" # general, routing, rewriting, knowledge
difficulty: str = "medium" # easy, medium, hard
@dataclass
class FlywheelMetrics:
"""飞轮运行指标"""
total_interactions: int = 0
positive_feedback_count: int = 0
negative_feedback_count: int = 0
feedback_rate: float = 0.0
positive_rate: float = 0.0
samples_for_training: int = 0
model_version: str = "v1.0"
last_update_time: str = ""
# ==================== 核心飞轮组件 ====================
class InteractionLogger:
"""交互日志记录器"""
def __init__(self):
self.interactions: List[UserInteraction] = []
self.interaction_counter = 0
def log_interaction(self, user_id: str, query: str, response: str,
session_id: str = "") -> str:
"""记录一次交互"""
self.interaction_counter += 1
interaction = UserInteraction(
interaction_id=f"int_{self.interaction_counter}_{int(time.time())}",
user_id=user_id,
timestamp=datetime.now().isoformat(),
query=query,
response=response,
session_id=session_id
)
self.interactions.append(interaction)
return interaction.interaction_id
def record_feedback(self, interaction_id: str, feedback: int) -> bool:
"""记录用户反馈"""
for interaction in self.interactions:
if interaction.interaction_id == interaction_id:
interaction.feedback = feedback
return True
return False
def get_unprocessed_interactions(self) -> List[UserInteraction]:
"""获取未处理的交互"""
return [i for i in self.interactions if i.feedback is None]
def get_feedback_interactions(self) -> List[UserInteraction]:
"""获取有反馈的交互"""
return [i for i in self.interactions if i.feedback is not None]
class FeedbackAnalyzer:
"""反馈分析器 - MAPE循环中的Analyze步骤"""
def __init__(self):
self.failure_patterns = defaultdict(list)
self.category_keywords = {
"routing": ["wrong", "route", "transfer", "escalate"],
"rewriting": ["understand", "interpret", "meaning", "clarify"],
"knowledge": ["fact", "accuracy", "information", "wrong info"],
"format": ["format", "structure", "output", "presentation"]
}
def analyze_feedback(self, interaction: UserInteraction) -> str:
"""分析反馈,识别失败模式"""
if interaction.feedback is None or interaction.feedback >= 0:
return "positive"
# 简单的关键词匹配来分类错误类型
response_lower = interaction.response.lower()
query_lower = interaction.query.lower()
for category, keywords in self.category_keywords.items():
for keyword in keywords:
if keyword in response_lower or keyword in query_lower:
self.failure_patterns[category].append(interaction)
return category
self.failure_patterns["general"].append(interaction)
return "general"
def get_failure_statistics(self) -> Dict[str, int]:
"""获取失败模式统计"""
return {k: len(v) for k, v in self.failure_patterns.items()}
def get_top_failure_patterns(self, top_k: int = 3) -> List[Tuple[str, int]]:
"""获取Top-K失败模式"""
stats = self.get_failure_statistics()
sorted_stats = sorted(stats.items(), key=lambda x: x[1], reverse=True)
return sorted_stats[:top_k]
class TrainingDataGenerator:
"""训练数据生成器 - 从反馈中生成微调数据"""
def __init__(self):
self.training_samples: List[FeedbackSample] = []
self.sample_counter = 0
def generate_from_positive_feedback(
self,
interaction: UserInteraction,
category: str = "general"
) -> FeedbackSample:
"""从正面反馈生成训练样本"""
self.sample_counter += 1
sample = FeedbackSample(
sample_id=f"sample_{self.sample_counter}",
interaction_id=interaction.interaction_id,
query=interaction.query,
good_response=interaction.response,
category=category
)
self.training_samples.append(sample)
return sample
def generate_preference_pair(
self,
positive_interaction: UserInteraction,
negative_interaction: UserInteraction
) -> Tuple[str, str]:
"""
生成偏好对数据(用于DPO/RLHF训练)
返回 (chosen_response, rejected_response)
"""
return (positive_interaction.response, negative_interaction.response)
def export_for_sft(self, output_path: str = "sft_data.jsonl"):
"""导出SFT格式数据"""
data = []
for sample in self.training_samples:
entry = {
"messages": [
{"role": "user", "content": sample.query},
{"role": "assistant", "content": sample.good_response}
],
"category": sample.category,
"sample_id": sample.sample_id
}
data.append(entry)
with open(output_path, "w", encoding="utf-8") as f:
for item in data:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
return output_path
def export_for_dpo(self, pos_interactions: List[UserInteraction],
neg_interactions: List[UserInteraction],
output_path: str = "dpo_data.jsonl") -> str:
"""导出DPO格式数据"""
data = []
min_len = min(len(pos_interactions), len(neg_interactions))
for i in range(min_len):
entry = {
"prompt": pos_interactions[i].query,
"chosen": pos_interactions[i].response,
"rejected": neg_interactions[i].response
}
data.append(entry)
with open(output_path, "w", encoding="utf-8") as f:
for item in data:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
return output_path
class FlywheelDashboard:
"""飞轮可视化仪表板"""
@staticmethod
def plot_metrics(metrics: FlywheelMetrics, save_path: str = "flywheel_metrics.png"):
"""绘制飞轮运行指标"""
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
fig.suptitle("Data Flywheel Dashboard", fontsize=16, fontweight='bold')
# 图1: 反馈分布
ax1 = axes[0, 0]
labels = ['Positive', 'Negative', 'No Feedback']
sizes = [
metrics.positive_feedback_count,
metrics.negative_feedback_count,
metrics.total_interactions - metrics.positive_feedback_count - metrics.negative_feedback_count
]
colors = ['#2ecc71', '#e74c3c', '#95a5a6']
ax1.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
ax1.set_title('Feedback Distribution')
# 图2: 指标文本展示
ax2 = axes[0, 1]
ax2.axis('off')
metrics_text = f"""
Flywheel Metrics Summary
---------------------------
Total Interactions: {metrics.total_interactions:,}
Positive Feedback: {metrics.positive_feedback_count:,}
Negative Feedback: {metrics.negative_feedback_count:,}
Feedback Rate: {metrics.feedback_rate:.1%}
Positive Rate: {metrics.positive_rate:.1%}
Samples for Training: {metrics.samples_for_training:,}
Current Model Version: {metrics.model_version}
Last Update: {metrics.last_update_time}
"""
ax2.text(0.1, 0.5, metrics_text, fontsize=12, family='monospace',
verticalalignment='center', transform=ax2.transAxes,
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
# 图3: 反馈率趋势(模拟数据)
ax3 = axes[1, 0]
days = list(range(1, 8))
positive_rates = [0.65, 0.68, 0.72, 0.70, 0.75, 0.78, 0.80]
ax3.plot(days, positive_rates, marker='o', linewidth=2, color='#3498db')
ax3.set_xlabel('Day')
ax3.set_ylabel('Positive Rate')
ax3.set_title('Positive Feedback Rate Trend (Last 7 Days)')
ax3.grid(True, alpha=0.3)
ax3.set_ylim(0.5, 0.9)
# 图4: 训练样本增长
ax4 = axes[1, 1]
iterations = list(range(1, 6))
samples = [100, 350, 800, 1500, 2800]
ax4.bar(iterations, samples, color='#9b59b6', alpha=0.7)
ax4.set_xlabel('Iteration')
ax4.set_ylabel('Training Samples')
ax4.set_title('Training Data Growth')
ax4.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.close()
return save_path
# ==================== 主飞轮类 ====================
class DataFlywheel:
"""
完整的数据飞轮实现
整合所有组件,实现MAPE控制循环:
- Monitor: 监控用户交互和反馈
- Analyze: 分析失败模式
- Plan: 规划改进策略
- Execute: 执行模型更新
"""
def __init__(self, model_version: str = "v1.0"):
self.logger = InteractionLogger()
self.analyzer = FeedbackAnalyzer()
self.data_generator = TrainingDataGenerator()
self.metrics = FlywheelMetrics(model_version=model_version)
self.is_running = False
def add_interaction(self, user_id: str, query: str, response: str,
session_id: str = "") -> str:
"""添加一次交互(Monitor步骤)"""
interaction_id = self.logger.log_interaction(
user_id, query, response, session_id
)
self.metrics.total_interactions += 1
self._update_metrics()
return interaction_id
def add_feedback(self, interaction_id: str, feedback: int) -> bool:
"""添加用户反馈(Monitor步骤)"""
success = self.logger.record_feedback(interaction_id, feedback)
if success:
if feedback > 0:
self.metrics.positive_feedback_count += 1
elif feedback < 0:
self.metrics.negative_feedback_count += 1
self._update_metrics()
return success
def analyze_and_plan(self) -> Dict[str, any]:
"""
分析反馈并规划改进策略(Analyze + Plan步骤)
返回分析报告和改进建议
"""
# 分析所有负面反馈
negative_interactions = [
i for i in self.logger.get_feedback_interactions()
if i.feedback < 0
]
category_counts = defaultdict(int)
for interaction in negative_interactions:
category = self.analyzer.analyze_feedback(interaction)
category_counts[category] += 1
# 生成训练样本
positive_interactions = [
i for i in self.logger.get_feedback_interactions()
if i.feedback > 0
]
for interaction in negative_interactions:
category = self.analyzer.analyze_feedback(interaction)
self.data_generator.generate_from_positive_feedback(interaction, category)
# 生成偏好对
pos_samples, neg_samples = positive_interactions[:10], negative_interactions[:10]
if pos_samples and neg_samples:
self.data_generator.generate_preference_pair(pos_samples[0], neg_samples[0])
self.metrics.samples_for_training = len(self.data_generator.training_samples)
# 生成改进报告
report = {
"analysis_time": datetime.now().isoformat(),
"total_negative_samples": len(negative_interactions),
"failure_categories": dict(category_counts),
"top_failure_patterns": self.analyzer.get_top_failure_patterns(),
"training_samples_generated": self.metrics.samples_for_training,
"recommendations": self._generate_recommendations(category_counts)
}
return report
def _generate_recommendations(self, category_counts: Dict[str, int]) -> List[str]:
"""基于分析结果生成改进建议"""
recommendations = []
for category, count in sorted(category_counts.items(), key=lambda x: x[1], reverse=True):
if category == "routing":
recommendations.append(
f"路由错误({count}例): 建议增加路由示例数据,优化路由提示词"
)
elif category == "rewriting":
recommendations.append(
f"查询改写错误({count}例): 建议扩充同义表述数据集"
)
elif category == "knowledge":
recommendations.append(
f"知识错误({count}例): 建议更新知识库,补充RAG检索数据"
)
elif category == "format":
recommendations.append(
f"格式错误({count}例): 建议优化输出格式模板"
)
else:
recommendations.append(
f"通用问题({count}例): 建议收集更多通用对话数据"
)
return recommendations
def execute_training_data_generation(self, output_dir: str = "./") -> Dict[str, str]:
"""
执行训练数据生成(Execute步骤)
返回生成的文件路径
"""
sft_path = f"{output_dir}/sft_data.jsonl"
dpo_path = f"{output_dir}/dpo_data.jsonl"
self.data_generator.export_for_sft(sft_path)
positive_interactions = [
i for i in self.logger.get_feedback_interactions()
if i.feedback > 0
]
negative_interactions = [
i for i in self.logger.get_feedback_interactions()
if i.feedback < 0
]
if positive_interactions and negative_interactions:
self.data_generator.export_for_dpo(
positive_interactions, negative_interactions, dpo_path
)
return {"sft_data": sft_path, "dpo_data": dpo_path}
def generate_dashboard(self, save_path: str = "flywheel_dashboard.png") -> str:
"""生成飞轮仪表板"""
return FlywheelDashboard.plot_metrics(self.metrics, save_path)
def _update_metrics(self):
"""更新飞轮指标"""
total = self.metrics.total_interactions
if total > 0:
self.metrics.feedback_rate = (
self.metrics.positive_feedback_count +
self.metrics.negative_feedback_count
) / total
feedback_total = self.metrics.positive_feedback_count + self.metrics.negative_feedback_count
if feedback_total > 0:
self.metrics.positive_rate = (
self.metrics.positive_feedback_count / feedback_total
)
self.metrics.last_update_time = datetime.now().isoformat()
# ==================== 使用示例 ====================
def demo():
"""演示数据飞轮的基本使用流程"""
# 1. 初始化飞轮
flywheel = DataFlywheel(model_version="v1.0")
# 2. 模拟用户交互(Monitor)
interactions = [
("user_001", "如何重置密码?", "您可以通过以下步骤重置密码..."),
("user_002", "我的订单在哪里?", "让我查看一下您的订单..."),
("user_003", "退款要多久到账?", "一般情况下,退款将在3-5个工作日内到账..."),
("user_004", "怎么联系人工客服?", "您可以通过以下方式联系人工客服..."),
("user_005", "取消订单可以吗?", "是的,您可以取消未发货的订单..."),
]
interaction_ids = []
for user_id, query, response in interactions:
iid = flywheel.add_interaction(user_id, query, response)
interaction_ids.append(iid)
# 3. 模拟用户反馈
flywheel.add_feedback(interaction_ids[0], 1) # 正面
flywheel.add_feedback(interaction_ids[1], 1) # 正面
flywheel.add_feedback(interaction_ids[2], -1) # 负面
flywheel.add_feedback(interaction_ids[3], 1) # 正面
flywheel.add_feedback(interaction_ids[4], -1) # 负面
# 4. 分析与规划(Analyze + Plan)
report = flywheel.analyze_and_plan()
print("=" * 60)
print("Flywheel Analysis Report")
print("=" * 60)
print(f"Total Interactions: {flywheel.metrics.total_interactions}")
print(f"Feedback Rate: {flywheel.metrics.feedback_rate:.1%}")
print(f"Positive Rate: {flywheel.metrics.positive_rate:.1%}")
print(f"\nFailure Categories: {report['failure_categories']}")
print(f"\nTop Failure Patterns: {report['top_failure_patterns']}")
print(f"\nRecommendations:")
for rec in report['recommendations']:
print(f" - {rec}")
# 5. 执行数据生成(Execute)
data_files = flywheel.execute_training_data_generation()
print(f"\nTraining data generated:")
print(f" SFT data: {data_files['sft_data']}")
print(f" DPO data: {data_files['dpo_data']}")
# 6. 生成仪表板
dashboard_path = flywheel.generate_dashboard()
print(f"\nDashboard saved to: {dashboard_path}")
return flywheel, report, data_files
if __name__ == "__main__":
flywheel, report, data_files = demo()5.3 合成数据飞轮实战
合成数据是2026年数据飞轮领域增长最快的方向。以下是一个完整的合成数据生成和验证流程:
python
"""
Synthetic Data Flywheel
基于AI生成高质量合成数据,构建自改进数据循环
"""
import json
import random
from typing import List, Dict, Tuple, Optional
from dataclasses import dataclass
import hashlib
@dataclass
class SyntheticSample:
"""合成样本"""
sample_id: str
query: str
response: str
difficulty: str # easy, medium, hard
category: str # math, code, reasoning, general
quality_score: float # 0-1
validation_status: str # passed, failed, pending
class SyntheticDataGenerator:
"""合成数据生成器"""
def __init__(self, llm_client=None):
self.client = llm_client
self.generated_samples: List[SyntheticSample] = []
self.quality_thresholds = {
"easy": 0.6,
"medium": 0.7,
"hard": 0.8
}
def generate_variations(
self,
base_query: str,
base_response: str,
num_variations: int = 5,
difficulty_levels: List[str] = None
) -> List[SyntheticSample]:
"""
生成问题变体
使用Self-Instruct方法扩展数据多样性
"""
if difficulty_levels is None:
difficulty_levels = ["easy", "medium", "hard"]
variations = []
sample_id_base = hashlib.md5(base_query.encode()).hexdigest()[:8]
# 变体生成策略
strategies = [
self._change_numerical_values,
self._add_constraints,
self._change_domain_context,
self._increase_reasoning_steps,
self._modify_persona
]
for i, strategy in enumerate(strategies[:num_variations]):
difficulty = difficulty_levels[i % len(difficulty_levels)]
# 应用变体策略
new_query, new_response = strategy(base_query, base_response, difficulty)
# 生成样本
sample = SyntheticSample(
sample_id=f"syn_{sample_id_base}_{i}",
query=new_query,
response=new_response,
difficulty=difficulty,
category=self._infer_category(new_query),
quality_score=0.0,
validation_status="pending"
)
variations.append(sample)
self.generated_samples.extend(variations)
return variations
def _change_numerical_values(self, query: str, response: str,
difficulty: str) -> Tuple[str, str]:
"""策略1: 改变数值"""
import re
numbers = re.findall(r'\d+', query)
if numbers:
old_num = numbers[0]
factor = 2 if difficulty == "hard" else (1.5 if difficulty == "medium" else 1.2)
new_num = str(int(int(old_num) * factor))
new_query = query.replace(old_num, new_num)
# 相应修改答案中的数值
new_response = response.replace(old_num, new_num)
return new_query, new_response
return query, response
def _add_constraints(self, query: str, response: str,
difficulty: str) -> Tuple[str, str]:
"""策略2: 增加约束条件"""
constraints = {
"hard": ["在不考虑负数解的情况下", "假设所有变量为正整数"],
"medium": ["在合理范围内", "假设满足基本条件"],
"easy": ["请简单说明"]
}
constraint = random.choice(constraints[difficulty])
new_query = f"{query}。{constraint}。"
return new_query, response
def _change_domain_context(self, query: str, response: str,
difficulty: str) -> Tuple[str, str]:
"""策略3: 改变领域上下文"""
contexts = {
"math": {
"from": "数学",
"to": "商业场景中的"
},
"code": {
"from": "Python",
"to": "JavaScript"
},
"general": {
"from": "教育",
"to": "医疗"
}
}
category = self._infer_category(query)
if category in contexts:
ctx = contexts[category]
if ctx["from"] in query:
new_query = query.replace(ctx["from"], ctx["to"])
return new_query, response
return query, response
def _increase_reasoning_steps(self, query: str, response: str,
difficulty: str) -> Tuple[str, str]:
"""策略4: 增加推理步骤"""
step_markers = {
"hard": "请给出详细的推导过程,包括所有中间步骤",
"medium": "请解释你的推理过程",
"easy": ""
}
new_query = f"{query}。{step_markers[difficulty]}"
return new_query, response
def _modify_persona(self, query: str, response: str,
difficulty: str) -> Tuple[str, str]:
"""策略5: 修改角色设定"""
personas = {
"hard": "作为资深技术专家,请详细分析",
"medium": "作为专业助手,请说明",
"easy": "用最简单的话解释"
}
new_query = f"{personas[difficulty]}:{query}"
return new_query, response
def _infer_category(self, query: str) -> str:
"""推断问题类别"""
query_lower = query.lower()
if any(kw in query_lower for kw in ["计算", "数学", "求", "等于"]):
return "math"
elif any(kw in query_lower for kw in ["代码", "编程", "函数", "def", "class"]):
return "code"
elif any(kw in query_lower for kw in ["推理", "逻辑", "证明", "为什么"]):
return "reasoning"
else:
return "general"
class LLMasJudge:
"""LLM作为裁判,评估合成数据质量"""
def __init__(self, llm_client=None):
self.client = llm_client
self.judge_prompt = """
你是一个严格的数据质量评估专家。请评估以下问答对的质量。
评估维度:
1. 问题清晰度(1-5分)
2. 答案准确性(1-5分)
3. 难度匹配度(1-5分)
4. 整体质量(1-5分)
请只返回一个JSON对象,格式如下:
{"clarity": X, "accuracy": X, "difficulty_match": X, "overall": X, "reason": "简短原因"}
"""
def evaluate(self, query: str, response: str,
expected_difficulty: str) -> Dict:
"""
评估样本质量
返回评估分数和建议
"""
# 模拟评估(实际应调用LLM)
scores = {
"clarity": random.uniform(3.5, 5.0),
"accuracy": random.uniform(3.0, 5.0),
"difficulty_match": random.uniform(3.0, 5.0),
"overall": random.uniform(3.0, 5.0),
"reason": "样本整体质量良好"
}
# 根据难度调整阈值
difficulty_factors = {"easy": 3.5, "medium": 4.0, "hard": 4.5}
threshold = difficulty_factors.get(expected_difficulty, 4.0)
is_valid = scores["overall"] >= threshold
return {
"scores": scores,
"is_valid": is_valid,
"threshold": threshold,
"suggestion": "保留" if is_valid else "建议重新生成"
}
class SyntheticDataFlywheel:
"""合成数据飞轮"""
def __init__(self, llm_client=None):
self.generator = SyntheticDataGenerator(llm_client)
self.judge = LLMasJudge(llm_client)
self.valid_samples: List[SyntheticSample] = []
self.invalid_samples: List[SyntheticSample] = []
self.iteration_count = 0
def run_iteration(
self,
seed_queries: List[Tuple[str, str]],
target_count: int = 100,
quality_threshold: float = 4.0
) -> Dict:
"""
运行一轮数据生成飞轮
流程:
1. 生成变体
2. 质量评估
3. 筛选保留
4. 失败样本再生成
"""
self.iteration_count += 1
print(f"\n{'='*60}")
print(f"Synthetic Data Flywheel - Iteration {self.iteration_count}")
print(f"{'='*60}")
current_valid = []
failed_samples = []
# 从种子数据生成变体
all_generated = []
for base_query, base_response in seed_queries:
variations = self.generator.generate_variations(
base_query, base_response, num_variations=10
)
all_generated.extend(variations)
print(f"Generated {len(all_generated)} samples")
# 评估每个样本
for sample in all_generated:
eval_result = self.judge.evaluate(
sample.query,
sample.response,
sample.difficulty
)
sample.quality_score = eval_result["scores"]["overall"]
if eval_result["is_valid"]:
sample.validation_status = "passed"
current_valid.append(sample)
self.valid_samples.append(sample)
else:
sample.validation_status = "failed"
failed_samples.append(sample)
self.invalid_samples.append(sample)
print(f"Passed: {len(current_valid)}, Failed: {len(failed_samples)}")
print(f"Total valid samples: {len(self.valid_samples)}")
# 对失败样本进行第二轮生成
if len(current_valid) < target_count and failed_samples:
retry_samples = random.sample(
failed_samples,
min(len(failed_samples), target_count - len(current_valid))
)
retry_results = self._retry_failed_samples(retry_samples)
current_valid.extend(retry_results)
return {
"iteration": self.iteration_count,
"generated_this_round": len(all_generated),
"passed_this_round": len(current_valid),
"failed_this_round": len(failed_samples),
"total_valid": len(self.valid_samples),
"quality_distribution": self._get_quality_distribution()
}
def _retry_failed_samples(self, failed_samples: List[SyntheticSample]) -> List[SyntheticSample]:
"""对失败样本进行重新生成"""
print(f"\nRetrying {len(failed_samples)} failed samples...")
retry_results = []
for sample in failed_samples[:5]: # 限制重试数量
# 从现有有效样本中找一个类似的作为参考
similar = random.choice(self.valid_samples) if self.valid_samples else None
# 重新生成
new_variations = self.generator.generate_variations(
sample.query, sample.response,
num_variations=3,
difficulty_levels=[sample.difficulty]
)
for variation in new_variations:
eval_result = self.judge.evaluate(
variation.query, variation.response, variation.difficulty
)
variation.quality_score = eval_result["scores"]["overall"]
if eval_result["is_valid"]:
variation.validation_status = "passed"
retry_results.append(variation)
self.valid_samples.append(variation)
break
return retry_results
def _get_quality_distribution(self) -> Dict[str, int]:
"""获取质量分布"""
distribution = {"high": 0, "medium": 0, "low": 0}
for sample in self.valid_samples:
if sample.quality_score >= 4.5:
distribution["high"] += 1
elif sample.quality_score >= 3.5:
distribution["medium"] += 1
else:
distribution["low"] += 1
return distribution
def export_training_data(self, output_path: str = "synthetic_training_data.jsonl",
min_quality: float = 3.5) -> str:
"""导出训练数据"""
filtered_samples = [
s for s in self.valid_samples
if s.quality_score >= min_quality
]
with open(output_path, "w", encoding="utf-8") as f:
for sample in filtered_samples:
entry = {
"messages": [
{"role": "user", "content": sample.query},
{"role": "assistant", "content": sample.response}
],
"quality_score": sample.quality_score,
"difficulty": sample.difficulty,
"category": sample.category
}
f.write(json.dumps(entry, ensure_ascii=False) + "\n")
print(f"\nExported {len(filtered_samples)} samples to {output_path}")
return output_path
def demo_synthetic_flywheel():
"""演示合成数据飞轮"""
# 准备种子数据
seed_queries = [
("一个商店有45个苹果,卖出了18个,还剩多少个?",
"还剩45-18=27个苹果。"),
("计算 156 + 237 = ?",
"156 + 237 = 393。"),
("如果x + 5 = 12,x等于多少?",
"x = 12 - 5 = 7。"),
("小明有20元,买了3本5元的书,还剩多少钱?",
"买书花了3×5=15元,还剩20-15=5元。"),
]
# 初始化飞轮
flywheel = SyntheticDataFlywheel()
# 运行多轮迭代
for i in range(3):
result = flywheel.run_iteration(
seed_queries,
target_count=100
)
print(f"\nIteration {i+1} Summary:")
print(f" Quality Distribution: {result['quality_distribution']}")
print(f" Total Valid: {result['total_valid']}")
# 导出训练数据
output_file = flywheel.export_training_data(min_quality=3.5)
return flywheel, output_file
if __name__ == "__main__":
flywheel, output_file = demo_synthetic_flywheel()5.4 从反馈日志到微调数据集
以下代码展示了如何将线上反馈日志转化为可用于微调的训练数据集:
python
"""
Feedback Log to Fine-tuning Dataset Pipeline
将线上反馈日志转化为模型微调数据集
"""
import json
from typing import List, Dict, Tuple, Optional
from dataclasses import dataclass, asdict
from datetime import datetime, timedelta
import pandas as pd
@dataclass
class FeedbackLog:
"""反馈日志条目"""
log_id: str
timestamp: str
user_id: str
query: str
response: str
thumbs_up: bool
thumbs_down: bool
rating: Optional[int] = None # 1-5
session_duration: float = 0.0
assistant_type: str = "general" # general, specialist, creative
@dataclass
class FineTuningSample:
"""微调样本"""
sample_id: str
conversation: List[Dict[str, str]]
category: str
quality_label: str # positive, negative, mixed
metadata: Dict
class FeedbackLogProcessor:
"""反馈日志处理器"""
def __init__(self):
self.logs: List[FeedbackLog] = []
def load_logs_from_file(self, filepath: str) -> int:
"""从文件加载反馈日志"""
with open(filepath, "r", encoding="utf-8") as f:
for line in f:
data = json.loads(line)
log = FeedbackLog(**data)
self.logs.append(log)
return len(self.logs)
def load_synthetic_logs(self, num_logs: int = 1000) -> int:
"""生成模拟日志用于演示"""
import random
sample_queries = [
"如何提高编程技能?",
"解释一下什么是机器学习",
"给我推荐一本好书",
"如何解决工作压力?",
"区块链是什么原理?",
"怎样写好技术文档?",
"人工智能的未来发展趋势",
"什么是微服务架构?",
]
sample_responses = [
"提升编程技能需要理论和实践相结合...",
"机器学习是人工智能的一个分支...",
"我推荐你读《代码大全》这本书...",
"工作压力大时,可以尝试时间管理...",
"区块链是一种分布式账本技术...",
"好的技术文档应该清晰、准确、完整...",
"AI将向更通用、更自主的方向发展...",
"微服务是一种将应用拆分为小服务的架构...",
]
for i in range(num_logs):
log = FeedbackLog(
log_id=f"log_{i}_{int(datetime.now().timestamp())}",
timestamp=(datetime.now() - timedelta(days=random.randint(0, 30))).isoformat(),
user_id=f"user_{random.randint(1000, 9999)}",
query=random.choice(sample_queries),
response=random.choice(sample_responses),
thumbs_up=random.random() > 0.3,
thumbs_down=random.random() < 0.2,
rating=random.randint(3, 5) if random.random() > 0.3 else random.randint(1, 2),
session_duration=random.uniform(10, 300),
assistant_type=random.choice(["general", "specialist", "creative"])
)
self.logs.append(log)
return num_logs
def filter_positive_samples(self) -> List[FeedbackLog]:
"""筛选正面样本"""
return [
log for log in self.logs
if log.thumbs_up or (log.rating and log.rating >= 4)
]
def filter_negative_samples(self) -> List[FeedbackLog]:
"""筛选负面样本"""
return [
log for log in self.logs
if log.thumbs_down or (log.rating and log.rating <= 2)
]
def get_samples_by_category(self, category: str) -> List[FeedbackLog]:
"""按类别筛选样本"""
return [log for log in self.logs if log.assistant_type == category]
def analyze_quality_distribution(self) -> Dict:
"""分析质量分布"""
total = len(self.logs)
positive = len(self.filter_positive_samples())
negative = len(self.filter_negative_samples())
neutral = total - positive - negative
return {
"total": total,
"positive": positive,
"negative": negative,
"neutral": neutral,
"positive_rate": positive / total if total > 0 else 0,
"negative_rate": negative / total if total > 0 else 0
}
class DatasetBuilder:
"""数据集构建器"""
def __init__(self):
self.samples: List[FineTuningSample] = []
self.sample_counter = 0
def build_sft_sample(self, log: FeedbackLog) -> FineTuningSample:
"""构建SFT格式样本"""
self.sample_counter += 1
conversation = [
{"role": "user", "content": log.query},
{"role": "assistant", "content": log.response}
]
quality_label = "positive" if (log.thumbs_up or (log.rating and log.rating >= 4)) else \
"negative" if (log.thumbs_down or (log.rating and log.rating <= 2)) else "neutral"
return FineTuningSample(
sample_id=f"sft_{self.sample_counter}",
conversation=conversation,
category=log.assistant_type,
quality_label=quality_label,
metadata={
"timestamp": log.timestamp,
"user_id": log.user_id,
"session_duration": log.session_duration
}
)
def build_preference_sample(
self,
positive_log: FeedbackLog,
negative_log: FeedbackLog
) -> FineTuningSample:
"""构建偏好对样本(用于DPO)"""
self.sample_counter += 1
# 构建对比式对话
conversation = [
{"role": "user", "content": positive_log.query},
{"role": "assistant", "content": positive_log.response},
{"content": "Below is an alternative response:", "role": "system"},
{"role": "assistant", "content": negative_log.response}
]
return FineTuningSample(
sample_id=f"pref_{self.sample_counter}",
conversation=conversation,
category="preference",
quality_label="pair",
metadata={
"chosen_id": positive_log.log_id,
"rejected_id": negative_log.log_id
}
)
def export_sft_dataset(
self,
samples: List[FineTuningSample],
output_path: str = "sft_dataset.jsonl"
) -> str:
"""导出SFT格式数据集"""
with open(output_path, "w", encoding="utf-8") as f:
for sample in samples:
entry = {
"messages": sample.conversation,
"category": sample.category,
"quality_label": sample.quality_label,
"metadata": sample.metadata
}
f.write(json.dumps(entry, ensure_ascii=False) + "\n")
return output_path
def export_dpo_dataset(
self,
positive_logs: List[FeedbackLog],
negative_logs: List[FeedbackLog],
output_path: str = "dpo_dataset.jsonl"
) -> str:
"""导出DPO格式数据集"""
pairs = []
min_len = min(len(positive_logs), len(negative_logs))
for i in range(min_len):
pos_log = positive_logs[i]
neg_log = negative_logs[i]
entry = {
"prompt": pos_log.query,
"chosen": pos_log.response,
"rejected": neg_log.response,
"category": pos_log.assistant_type
}
pairs.append(entry)
with open(output_path, "w", encoding="utf-8") as f:
for entry in pairs:
f.write(json.dumps(entry, ensure_ascii=False) + "\n")
return output_path
class PipelineOrchestrator:
"""流水线编排器"""
def __init__(self):
self.processor = FeedbackLogProcessor()
self.builder = DatasetBuilder()
def run_full_pipeline(
self,
num_logs: int = 1000,
output_dir: str = "./"
) -> Dict:
"""
运行完整的数据处理流水线
1. 加载反馈日志
2. 分析质量分布
3. 构建SFT数据集
4. 构建DPO数据集
5. 生成质量报告
"""
print("=" * 60)
print("Feedback Log to Fine-tuning Dataset Pipeline")
print("=" * 60)
# Step 1: 加载日志
print("\n[Step 1] Loading feedback logs...")
num_loaded = self.processor.load_synthetic_logs(num_logs)
print(f" Loaded {num_loaded} logs")
# Step 2: 分析分布
print("\n[Step 2] Analyzing quality distribution...")
distribution = self.processor.analyze_quality_distribution()
print(f" Positive: {distribution['positive']} ({distribution['positive_rate']:.1%})")
print(f" Negative: {distribution['negative']} ({distribution['negative_rate']:.1%})")
# Step 3: 构建SFT样本
print("\n[Step 3] Building SFT samples...")
positive_logs = self.processor.filter_positive_samples()
sft_samples = [
self.builder.build_sft_sample(log)
for log in positive_logs
]
print(f" Built {len(sft_samples)} SFT samples")
# Step 4: 导出SFT数据
print("\n[Step 4] Exporting SFT dataset...")
sft_path = self.builder.export_sft_dataset(
sft_samples,
f"{output_dir}/sft_dataset.jsonl"
)
print(f" Saved to: {sft_path}")
# Step 5: 构建DPO数据
print("\n[Step 5] Building DPO dataset...")
negative_logs = self.processor.filter_negative_samples()
dpo_path = self.builder.export_dpo_dataset(
positive_logs[:100], # 限制数量
negative_logs[:100],
f"{output_dir}/dpo_dataset.jsonl"
)
print(f" Saved to: {dpo_path}")
# Step 6: 生成报告
print("\n[Step 6] Generating quality report...")
report = {
"generated_at": datetime.now().isoformat(),
"total_logs_processed": num_loaded,
"quality_distribution": distribution,
"sft_samples_count": len(sft_samples),
"dpo_pairs_count": min(len(positive_logs), len(negative_logs)),
"output_files": {
"sft": sft_path,
"dpo": dpo_path
}
}
report_path = f"{output_dir}/quality_report.json"
with open(report_path, "w", encoding="utf-8") as f:
json.dump(report, f, indent=2, ensure_ascii=False)
print(f" Report saved to: {report_path}")
print("\n" + "=" * 60)
print("Pipeline completed successfully!")
print("=" * 60)
return report
def demo_pipeline():
"""演示完整流水线"""
orchestrator = PipelineOrchestrator()
report = orchestrator.run_full_pipeline(
num_logs=500,
output_dir="./"
)
return report
if __name__ == "__main__":
report = demo_pipeline()5.5 飞轮可视化管理
python
"""
Flywheel Visualization Dashboard
飞轮运行状态可视化
"""
import json
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from datetime import datetime, timedelta
from collections import defaultdict
class FlywheelVisualizer:
"""飞轮可视化工具"""
def __init__(self):
self.history_data = []
def load_metrics_history(self, filepath: str):
"""加载历史指标"""
with open(filepath, "r") as f:
self.history_data = [json.loads(line) for line in f]
def add_metrics(self, metrics: dict):
"""添加新的指标记录"""
metrics["timestamp"] = datetime.now().isoformat()
self.history_data.append(metrics)
def plot_flywheel_status(self, save_path: str = "flywheel_status.png"):
"""绘制飞轮状态总览图"""
fig = plt.figure(figsize=(16, 12))
# 创建子图布局
gs = fig.add_gridspec(3, 3, hspace=0.3, wspace=0.3)
# 1. 交互量趋势
ax1 = fig.add_subplot(gs[0, 0])
days = list(range(1, len(self.history_data) + 1))
interactions = [m.get("total_interactions", 0) for m in self.history_data]
ax1.plot(days, interactions, marker='o', color='#3498db', linewidth=2)
ax1.set_title('Total Interactions', fontweight='bold')
ax1.set_xlabel('Day')
ax1.set_ylabel('Count')
ax1.grid(True, alpha=0.3)
# 2. 反馈率趋势
ax2 = fig.add_subplot(gs[0, 1])
feedback_rates = [m.get("feedback_rate", 0) * 100 for m in self.history_data]
ax2.bar(days, feedback_rates, color='#9b59b6', alpha=0.7)
ax2.set_title('Feedback Rate (%)', fontweight='bold')
ax2.set_xlabel('Day')
ax2.set_ylabel('Rate (%)')
ax2.grid(True, alpha=0.3, axis='y')
# 3. 正面率趋势
ax3 = fig.add_subplot(gs[0, 2])
positive_rates = [m.get("positive_rate", 0) * 100 for m in self.history_data]
ax3.plot(days, positive_rates, marker='s', color='#2ecc71', linewidth=2)
ax3.axhline(y=80, color='r', linestyle='--', alpha=0.5, label='Target: 80%')
ax3.set_title('Positive Rate (%)', fontweight='bold')
ax3.set_xlabel('Day')
ax3.set_ylabel('Rate (%)')
ax3.legend()
ax3.grid(True, alpha=0.3)
# 4. 失败模式分布
ax4 = fig.add_subplot(gs[1, 0])
if self.history_data:
latest = self.history_data[-1]
failure_categories = latest.get("failure_categories", {})
if failure_categories:
categories = list(failure_categories.keys())
counts = list(failure_categories.values())
colors = plt.cm.Set3(np.linspace(0, 1, len(categories)))
ax4.pie(counts, labels=categories, autopct='%1.1f%%', colors=colors)
ax4.set_title('Failure Categories (Latest)', fontweight='bold')
# 5. 训练样本增长
ax5 = fig.add_subplot(gs[1, 1])
training_samples = [m.get("samples_for_training", 0) for m in self.history_data]
ax5.fill_between(days, training_samples, alpha=0.3, color='#e74c3c')
ax5.plot(days, training_samples, marker='^', color='#e74c3c', linewidth=2)
ax5.set_title('Training Samples Accumulated', fontweight='bold')
ax5.set_xlabel('Day')
ax5.set_ylabel('Count')
ax5.grid(True, alpha=0.3)
# 6. 模型版本时间线
ax6 = fig.add_subplot(gs[1, 2])
ax6.axis('off')
if self.history_data:
versions = [m.get("model_version", "v1.0") for m in self.history_data]
versions_unique = []
for v in versions:
if v not in versions_unique:
versions_unique.append(v)
timeline_text = "Model Version Timeline:\n" + "-" * 30 + "\n"
for i, v in enumerate(versions_unique, 1):
timeline_text += f"v{i}: {v}\n"
ax6.text(0.1, 0.5, timeline_text, fontsize=11, family='monospace',
verticalalignment='center', transform=ax6.transAxes,
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.5))
ax6.set_title('Model Version Timeline', fontweight='bold')
# 7. Token效率趋势
ax7 = fig.add_subplot(gs[2, :2])
if self.history_data:
token_per_interaction = [
m.get("avg_token_per_interaction", 100) for m in self.history_data
]
ax7.plot(days, token_per_interaction, marker='d', color='#f39c12',
linewidth=2, markersize=8)
ax7.axhline(y=100, color='g', linestyle='--', alpha=0.5, label='Baseline')
ax7.set_title('Average Token per Interaction', fontweight='bold')
ax7.set_xlabel('Day')
ax7.set_ylabel('Token Count')
ax7.legend()
ax7.grid(True, alpha=0.3)
# 8. 飞轮健康度仪表
ax8 = fig.add_subplot(gs[2, 2])
ax8.axis('off')
# 计算健康度分数
if self.history_data:
latest = self.history_data[-1]
positive_rate = latest.get("positive_rate", 0)
feedback_rate = latest.get("feedback_rate", 0)
health_score = (positive_rate * 0.6 + feedback_rate * 0.4) * 100
# 绘制仪表盘效果
theta = np.linspace(0, np.pi, 100)
r = np.ones_like(theta)
x = r * np.cos(theta)
y = r * np.sin(theta)
ax8.fill_between(x, 0, y, alpha=0.1, color='gray')
# 健康度指针
angle = np.pi * (1 - health_score / 100)
pointer_x = np.cos(angle)
pointer_y = np.sin(angle)
ax8.annotate('', xy=(pointer_x * 0.8, pointer_y * 0.8),
xytext=(0, 0),
arrowprops=dict(arrowstyle='->', color='red', lw=3))
# 添加刻度
for i in range(0, 101, 20):
angle = np.pi * (1 - i / 100)
ax8.text(np.cos(angle) * 1.1, np.sin(angle) * 1.1, f'{i}',
ha='center', va='center', fontsize=9)
ax8.set_xlim(-1.5, 1.5)
ax8.set_ylim(-0.5, 1.5)
ax8.set_aspect('equal')
ax8.axis('off')
ax8.text(0, -0.3, f'Health Score: {health_score:.1f}',
ha='center', va='center', fontsize=14, fontweight='bold')
plt.suptitle('Data Flywheel Dashboard', fontsize=18, fontweight='bold', y=0.98)
plt.savefig(save_path, dpi=150, bbox_inches='tight', facecolor='white')
plt.close()
return save_path
def generate_summary_report(self) -> str:
"""生成汇总报告"""
if not self.history_data:
return "No data available"
latest = self.history_data[-1]
first = self.history_data[0]
report = f"""
================================================
Data Flywheel Summary Report
Generated at: {datetime.now().isoformat()}
================================================
Current Status:
- Total Interactions: {latest.get('total_interactions', 0):,}
- Feedback Rate: {latest.get('feedback_rate', 0):.1%}
- Positive Rate: {latest.get('positive_rate', 0):.1%}
- Training Samples: {latest.get('samples_for_training', 0):,}
- Current Model: {latest.get('model_version', 'Unknown')}
Growth Metrics:
- Interaction Growth: {latest.get('total_interactions', 0) - first.get('total_interactions', 0):+,}
- Sample Growth: {latest.get('samples_for_training', 0) - first.get('samples_for_training', 0):+,}
Top Failure Patterns:
"""
if 'failure_categories' in latest:
for category, count in latest['failure_categories'].items():
report += f" - {category}: {count}\n"
return report
def demo_visualization():
"""演示可视化功能"""
import random
viz = FlywheelVisualizer()
# 生成模拟历史数据
for day in range(1, 15):
metrics = {
"total_interactions": 1000 + day * 150 + random.randint(-50, 50),
"feedback_rate": 0.3 + day * 0.02 + random.uniform(-0.05, 0.05),
"positive_rate": 0.7 + day * 0.01 + random.uniform(-0.05, 0.05),
"samples_for_training": 50 + day * 30 + random.randint(-10, 10),
"model_version": f"v{day // 5 + 1}.0",
"avg_token_per_interaction": 120 - day * 2 + random.randint(-5, 5),
"failure_categories": {
"routing": random.randint(5, 15),
"rewriting": random.randint(3, 10),
"knowledge": random.randint(2, 8),
"format": random.randint(1, 5)
}
}
viz.add_metrics(metrics)
# 生成可视化
viz.plot_flywheel_status("flywheel_dashboard.png")
# 生成报告
report = viz.generate_summary_report()
print(report)
return viz
if __name__ == "__main__":
demo_visualization()5.6 调试与验证技巧
python
"""
Flywheel Debugging and Validation Utilities
飞轮调试与验证工具
"""
class FlywheelDebugger:
"""飞轮调试器"""
@staticmethod
def validate_interaction(interaction) -> Tuple[bool, List[str]]:
"""验证交互数据完整性"""
errors = []
required_fields = ['interaction_id', 'user_id', 'query', 'response']
for field in required_fields:
if not hasattr(interaction, field) or not getattr(interaction, field):
errors.append(f"Missing or empty field: {field}")
if hasattr(interaction, 'feedback'):
if interaction.feedback is not None and interaction.feedback not in [-1, 0, 1]:
errors.append(f"Invalid feedback value: {interaction.feedback}")
return (len(errors) == 0, errors)
@staticmethod
def validate_training_sample(sample) -> Tuple[bool, List[str]]:
"""验证训练样本"""
errors = []
if not hasattr(sample, 'conversation') or not sample.conversation:
errors.append("Empty conversation")
else:
# 检查对话格式
for msg in sample.conversation:
if 'role' not in msg or 'content' not in msg:
errors.append("Invalid message format")
if msg['role'] not in ['user', 'assistant', 'system']:
errors.append(f"Invalid role: {msg['role']}")
if hasattr(sample, 'quality_score'):
if not 0 <= sample.quality_score <= 5:
errors.append(f"Quality score out of range: {sample.quality_score}")
return (len(errors) == 0, errors)
@staticmethod
def check_data_leakage(train_samples, val_samples) -> Dict:
"""检查数据泄露"""
train_queries = set(s.query.lower().strip() for s in train_samples)
val_queries = set(s.query.lower().strip() for s in val_samples)
overlap = train_queries.intersection(val_queries)
return {
"has_leakage": len(overlap) > 0,
"overlap_count": len(overlap),
"overlap_ratio": len(overlap) / len(val_queries) if val_queries else 0,
"overlap_samples": list(overlap)[:10] # 显示前10个
}
@staticmethod
def analyze_sample_distribution(samples: List) -> Dict:
"""分析样本分布"""
categories = {}
difficulty_levels = {}
for sample in samples:
cat = getattr(sample, 'category', 'unknown')
categories[cat] = categories.get(cat, 0) + 1
diff = getattr(sample, 'difficulty', 'unknown')
difficulty_levels[diff] = difficulty_levels.get(diff, 0) + 1
return {
"total_samples": len(samples),
"category_distribution": categories,
"difficulty_distribution": difficulty_levels
}
class ABTester:
"""A/B测试工具"""
def __init__(self):
self.experiments = {}
def create_experiment(
self,
experiment_id: str,
control_config: dict,
treatment_config: dict
):
"""创建A/B实验"""
self.experiments[experiment_id] = {
"control": {"config": control_config, "results": []},
"treatment": {"config": treatment_config, "results": []}
}
def record_result(
self,
experiment_id: str,
variant: str,
metrics: dict
):
"""记录实验结果"""
if experiment_id in self.experiments:
variant_key = variant.lower()
if variant_key in self.experiments[experiment_id]:
self.experiments[experiment_id][variant_key]["results"].append(metrics)
def analyze_experiment(self, experiment_id: str) -> Dict:
"""分析实验结果"""
if experiment_id not in self.experiments:
return {"error": "Experiment not found"}
exp = self.experiments[experiment_id]
control_results = exp["control"]["results"]
treatment_results = exp["treatment"]["results"]
# 计算各指标的平均值
def calc_metrics(results):
if not results:
return {}
metrics = {}
for key in results[0].keys():
values = [r.get(key, 0) for r in results]
metrics[key] = {
"mean": sum(values) / len(values),
"std": (sum((v - sum(values)/len(values))**2 for v in values) / len(values)) ** 0.5,
"count": len(values)
}
return metrics
control_metrics = calc_metrics(control_results)
treatment_metrics = calc_metrics(treatment_results)
# 计算提升
lifts = {}
for key in control_metrics:
if key in treatment_metrics and control_metrics[key]["mean"] > 0:
lift = (treatment_metrics[key]["mean"] - control_metrics[key]["mean"]) / control_metrics[key]["mean"]
lifts[key] = lift
return {
"experiment_id": experiment_id,
"control_sample_size": len(control_results),
"treatment_sample_size": len(treatment_results),
"control_metrics": control_metrics,
"treatment_metrics": treatment_metrics,
"lift": lifts,
"recommendation": "Deploy treatment" if all(l > 0 for l in lifts.values()) else "Keep control"
}六、常用场景列举
场景一:AI客服的自我进化
典型案例:DoorDash客服飞轮
DoorDash是美国最大的外卖配送平台,服务数百万用户。其AI客服系统通过构建数据飞轮,实现了从"被动响应"到"主动进化"的转变。
核心实践:
- 全量日志采集:所有客服交互(包括未反馈的交互)都被完整记录
- 实时反馈监控:用户点击"有帮助/没帮助"后,数据立即进入分析队列
- 失败模式识别:系统自动识别"幻觉率"------当AI生成错误信息(如不存在的餐厅营业时间)时,用户往往会点击"没帮助"
- 定向优化:只针对失败案例生成训练数据,而不是全量重训
关键成果:
- 幻觉率降低90%:通过持续监控和反馈,系统能够快速捕获并修正错误信息
- 用户满意度提升:问题解决率从65%提升到89%
- 运营成本下降:自动化处理比例从40%提升到78%
技术启示:客服场景是数据飞轮的最佳试验场------用户反馈天然密集,问题边界清晰,优化效果可量化。
场景二:大模型Agent的任务执行精准度提升
典型案例:NVIDIA NVInfo AI知识助手
NVIDIA内部使用NVInfo AI作为MoE架构的知识助手,服务超过30000名员工。这是一个典型的企业知识问答场景。
核心实践:
-
MAPE控制循环落地:
- Monitor:持续收集495个负反馈样本
- Analyze:识别两大失败模式(路由错误5.25%,查询改写错误3.2%)
- Plan:制定针对性优化方案
- Execute:通过NeMo Customizer执行轻量化微调
-
模型压缩与效率提升:
- 路由组件:从Llama 3.1 70B压缩到8B(10倍压缩),同时保持96%准确率
- 查询改写:准确率提升3.7%,延迟降低40%
- 整体延迟降低70%
-
合成数据生成:使用Llama 3.1 405B生成5000个合成样本,补充训练数据
关键成果:
- 模型参数量10倍压缩
- 延迟降低70%
- 推理成本大幅下降
技术启示:企业AI Agent的优化重点不是"更大的模型",而是"更高效的模型"。数据飞轮是实现这一目标的关键手段。
场景三:大模型自动化代码审查与修复
典型案例:京东JoyAI-LLM Flash代码能力优化
京东的JoyAI-LLM Flash模型在代码生成和工具调用能力上表现突出,背后是数据飞轮思维的深度应用。
核心实践:
-
Human-in-the-Loop动态数据配比:
- 监控模型在不同代码任务上的表现
- 动态调整训练数据中"代码和Agent数据"的占比(约30%)
- 确保模型在关键场景的能力持续提升
-
FiberPO强化学习算法:
- 解决传统RL算法中的"错误牵连"问题
- 宏观层面控制回答不能偏离正常对话
- 微观层面独立评估每个词的质量
- 结果:生成更精简、逻辑更清晰的回答
-
MoE架构优化:
- 总参数48B,激活参数仅2.7B
- Token效率显著提升
- 推理成本可控
关键成果:
- 代码生成能力业界领先
- Token消耗最优
- 多Token预测(MTP)技术实现1.87倍推理加速
技术启示:代码生成场景对准确性和效率的要求极高,数据飞轮通过持续采集失败样本、针对性优化,能够在保持模型能力的同时大幅降低成本。
场景四:自动驾驶端到端数据闭环
典型案例:Momenta自动驾驶数据闭环
自动驾驶是数据飞轮应用的先驱领域,因为驾驶场景中的Corner Case(极端情况)是提升安全性的关键。
核心实践:
-
大规模数据采集:
- 每日处理百万公里级别的真实驾驶数据
- 覆盖各种天气、路况、场景
-
Corner Case自动识别:
- 使用视觉模型自动标注"异常驾驶行为"
- 识别"人类驾驶员接管"时刻
- 分类不同类型的危险场景
-
仿真数据生成:
- 基于真实场景生成大量仿真数据
- 解决长尾分布问题
- 降低实车测试成本
-
模型持续迭代:
- 新数据每周回传
- 模型每月更新
- OTA推送用户车辆
关键成果:
- 自动驾驶安全性持续提升
- 接管率逐年下降
- 覆盖更多极端场景
技术启示:自动驾驶的数据飞轮特点是"数据量大、反馈闭环快、安全要求高",是数据驱动产品迭代的典型范例。
场景五:具身智能与机器人的自我适应
典型案例:光轮智能具身数据飞轮
2026年一季度,光轮智能实现5.5亿元订单,刷新具身数据行业纪录,成为"具身数据元年"的标志。
核心实践:
-
三层数据架构:
- 世界层(World):物理仿真环境
- 行为层(Behavior):人类视频+仿真合成数据
- 评测层(Eval):统一可量化的评测标准
-
数据飞轮闭环:
- 世界层提供环境
- 行为层生成数据并拓展任务分布
- 评测层持续暴露模型短板
- 再反向决定下一轮数据采集重点
-
仿真与真实数据互补:
- 人类视频数据解决"行为先验"问题
- 仿真数据解决"规模扩展"问题
- 二者结合形成完整数据体系
关键成果:
- 5.5亿元季度订单
- 服务具身大模型训练
- 支撑机器人真实场景部署
技术启示:具身智能的数据飞轮特点是"虚实结合",仿真数据与真实数据需要形成互补,才能支撑模型在复杂物理世界中的泛化能力。
场景六:可观测性与AIOps的自愈系统
典型案例:阿里云AIOps Agent数据飞轮
阿里云可观测产品通过构建数据飞轮,实现了从"人工告警"到"系统自愈"的转变。
核心实践:
-
统一可观测数据平台:
- 日处理超百PB数据
- 覆盖阿里集团全系业务
- 服务数百万云上客户
-
UModel统一建模:
- 覆盖6大领域、1800个实体模型
- 自动提取资源关系和调用链路
- 形成"数字孪生"拓扑
-
智能运维闭环:
- 感知:全链路数据采集
- 认知:语义化日志分析
- 行动:自动化故障修复
-
双重保障机制:
- 技术层:多源数据交叉验证
- 应用层:外挂私有知识库
关键成果:
- 故障恢复时长降低70%
- 整体成本降低30%
- SLA达到99.99%
技术启示:AIOps场景的数据飞轮特点是"闭环周期短、自动化程度高",从发现问题到修复问题可以完全自动化执行。
七、专业解释+大白话+生活案例
7.1 硬核原理一:MAPE控制循环的架构设计
专业解释
MAPE(Monitor-Analyze-Plan-Execute)控制循环源于自动控制理论,NVIDIA首次将其系统性地引入大模型数据飞轮领域。其核心架构包含以下组件:
Monitor(监控)层:
python
# 监控数据采集
monitoring_data = {
"user_feedback": [...], # 用户显式反馈
"implicit_signals": [...], # 隐式信号(如停留时长)
"model_confidence": [...], # 模型置信度
"task_completion": [...], # 任务完成率
"system_metrics": [...] # 系统指标
}Analyze(分析)层:
python
# 失败模式聚类
failure_patterns = {
"routing_error": analyze_by_category(feedbacks, "routing"),
"rewriting_error": analyze_by_category(feedbacks, "rewriting"),
"knowledge_gap": analyze_by_category(feedbacks, "knowledge"),
"format_violation": analyze_by_category(feedbacks, "format")
}Plan(规划)层:
python
# 优化策略制定
optimization_plan = {
"component": "router", # 需要优化的组件
"current_model": "Llama-70B", # 当前模型
"target_model": "Llama-8B", # 目标模型
"training_data_size": 5000, # 所需训练数据
"evaluation_metrics": ["accuracy", "latency", "cost"]
}Execute(执行)层:
python
# 使用NeMo微服务执行
result = nemo_customizer.fine_tune(
base_model="Llama-8B",
training_data=optimization_plan["training_data"],
method="lora",
epochs=3
)大白话解释
MAPE循环就像给AI系统装上了一个"自动驾驶系统":
- Monitor(监控):系统就像有了"眼睛",能实时看到自己的表现
- Analyze(分析):系统像有了"大脑",能分析哪里出了问题
- Plan(规划):系统像有了"决策者",能制定改进方案
- Execute(执行):系统像有了"机械臂",能自动执行改进
没有MAPE循环的AI,就像一个盲人骑瞎马------只能靠人工干预来发现问题、解决问题。有了MAPE循环,AI能够自我感知、自我分析、自我决策、自我进化。
生活案例:智能驾驶的进化
想象特斯拉的自动驾驶系统:
- Monitor:摄像头和传感器持续监控路况、周围车辆、车道线
- Analyze:系统识别"前方车辆急刹"、"车道线消失"等模式
- Plan:制定"减速"、"变道"、"保持车道"等决策
- Execute:执行加速/刹车/转向操作
如果系统发现某次决策导致了不好的结果(比如急刹导致乘客不适),这次经历会被记录,用于优化下一次决策。这就是为什么特斯拉的自动驾驶会"越开越好"------每百万英里的驾驶经验都在让系统变得更聪明。
7.2 硬核原理二:合成数据的质量保证链路
专业解释
合成数据(Synthetic Data)是2026年数据飞轮领域增长最快的方向。其质量保证链路包含以下关键环节:
Step 1: 种子数据选择
python
# 选择高质量、多样性的种子数据
seed_criteria = {
"quality_score": ">4.0", # 质量分数阈值
"diversity": "max_coverage", # 最大覆盖度
"category_balance": "stratified" # 分层平衡
}
seed_data = select_seeds(raw_data, seed_criteria)Step 2: 多样性扩增
python
# 使用多种策略扩增数据
augmentation_strategies = {
"self_instruct": generate_variations(query, num=10),
"persona_injection": change_persona(query, personas),
"difficulty_gradient": adjust_difficulty(query, levels),
"domain_transfer": change_domain(query, target_domain)
}
augmented_data = merge(augmentation_strategies)Step 3: LLM-as-Judge评估
python
# 使用强大模型评估合成数据质量
judge_prompt = """
评估问答对质量,考虑:
1. 问题清晰度
2. 答案准确性
3. 难度匹配度
4. 整体质量
返回JSON格式评分
"""
quality_scores = []
for sample in augmented_data:
score = llm_judge.evaluate(sample, judge_prompt)
quality_scores.append(score)Step 4: 一致性过滤
python
# 多模型一致性过滤
def consistency_filter(samples):
filtered = []
for sample in samples:
answers = [model.evaluate(sample.question) for model in multiple_models]
if answers_are_consistent(answers):
filtered.append(sample)
return filteredStep 5: 人工校准
python
# 抽检人工审核
sample_rate = 0.05 # 5%人工抽检
reviewed_samples = human_review(synthetic_data, sample_rate)
quality_metrics = calculate_metrics(reviewed_samples)大白话解释
合成数据的质量保证就像"工厂生产-质检-出厂"的流程:
- 种子选择:从最好的样本中选"种子",确保"基因"优良
- 多样性扩增:让种子"繁殖",产生各种变体,增加"人口"多样性
- 机器质检:用"高级检测仪"(更强的LLM)来评估每个产品的质量
- 一致性检验:让"多个检测员"同时检验,只有结论一致的才通过
- 人工抽检:最后请"专家"抽检,确保万无一失
这个流程确保了合成数据既有足够的数量,又有可靠的质量。
生活案例:药品研发的数据模拟
新药研发需要大量临床试验数据,但直接用人体试验既贵又慢。合成数据的思路是:
- 种子数据:收集已有的临床试验数据(安全性已验证的数据)
- 模拟扩增:基于已知数据,使用计算机模拟生成更多变体(比如不同年龄、体重、性别组合)
- 模型验证:用AI模型验证模拟数据的合理性
- 一致性检验:用多个独立模型验证,只有结论一致的才进入下一轮
- 专家审核:医学专家抽检,确认模拟数据符合医学原理
最终,合成数据可以大幅加速药品研发,同时控制风险。
7.3 硬核原理三:为什么飞轮会"越转越省"
专业解释
数据飞轮的"成本递减"效应源于以下几个机制:
机制1: 规模效应
python
# 数据处理成本曲线
cost_model = {
"fixed_cost": 10000, # 固定成本(基础设施)
"per_sample_cost": 0.1, # 单样本边际成本
"learning_rate": 0.95, # 学习率(每轮成本下降)
}
def calculate_cost(num_rounds):
total_cost = fixed_cost
for round in range(num_rounds):
cost_this_round = per_sample_cost * (learning_rate ** round)
total_cost += cost_this_round
return total_cost机制2: 模型效率提升
python
# 模型效率提升导致Token消耗下降
token_efficiency_curve = {
"v1": {"accuracy": 0.75, "avg_tokens": 200},
"v2": {"accuracy": 0.80, "avg_tokens": 170}, # 准确+5%,Token-15%
"v3": {"accuracy": 0.84, "avg_tokens": 145}, # 准确+4%,Token-15%
"v4": {"accuracy": 0.87, "avg_tokens": 125}, # 准确+3%,Token-14%
}机制3: 工具和流程成熟
python
# 飞轮成熟度指标
maturity_metrics = {
"data_pipeline_stability": 0.95, # 流水线稳定性
"automation_rate": 0.85, # 自动化程度
"tool_reusability": 0.90, # 工具复用率
"knowledge_accumulation": 0.88 # 知识积累度
}
# 成熟度越高,运营成本越低机制4: 知识迁移
python
# 新场景可以复用已有能力
knowledge_transfer = {
"from": "客服场景",
"to": "销售场景",
"transfer_rate": 0.7, # 70%知识可迁移
"new_data_required": "30%" # 只需补充30%新数据
}大白话解释
飞轮"越转越省"的原因,可以类比"骑自行车":
-
起步最难(规模效应):刚开始骑自行车时,你需要用很大力气才能启动。但一旦车轮转动起来,保持同样的速度就容易多了。
-
越骑越顺(模型效率):骑久了,你会找到最佳的发力节奏、最省力的姿势。模型也是一样,经过多轮优化后,它知道"这条路该怎么走最省力"。
-
工具顺手(流程成熟):刚开始骑车,你可能还在摸索怎么刹车、怎么转弯。熟练之后,这些动作变成"肌肉记忆",不用思考就能完成。
-
触类旁通(知识迁移):你会骑自行车后,学骑电动车、摩托车会快很多。模型也是一样,在客服场景学到的能力,可以迁移到销售场景。
生活案例:工厂生产的规模经济
想象一家工厂生产手机:
- 第1代工厂:建设成本10亿,年产100万台,每台成本1000元
- 第5代工厂:建设成本10亿,年产500万台,每台成本300元
- 第10代工厂:建设成本10亿,年产1000万台,每台成本150元
原因在于:
- 固定成本被更多产品分摊
- 生产线效率持续优化
- 工人熟练度提升
- 供应链成本下降
数据飞轮同理------初期投入大、见效慢,但随着飞轮转动,规模效应会让边际成本持续下降。
八、面试官高频面试题(8道Q&A)
Q1: 请解释什么是数据飞轮?它与传统的反馈循环有什么区别?
参考答案
定义:数据飞轮是"数据---模型---用户---反馈"之间形成的正向循环增强效应。当系统被使用时,用户行为产生数据,数据经过处理后用于优化模型,模型优化后体验提升,体验提升吸引更多用户使用,从而产生更多数据。
核心区别:
| 维度 | 传统反馈循环 | 数据飞轮 |
|---|---|---|
| 触发机制 | 被动等待问题发生 | 主动持续监控 |
| 数据利用 | 一次性使用 | 持续积累增值 |
| 优化周期 | 数周甚至数月 | 可缩短到数天 |
| 成本曲线 | 边际成本恒定 | 边际成本递减 |
| 知识沉淀 | 随人员流动 | 固化为模型能力 |
关键洞察:传统反馈循环是"弥补短板",每次修正只是让模型恢复到"应该有的水平";数据飞轮是"主动进化",每次循环不仅修复错误,更通过奖励机制放大正确决策的影响。
Q2: MAPE控制循环是什么?请描述其在数据飞轮中的应用。
参考答案
MAPE定义:
- Monitor(监控):持续采集模型在生产环境中的表现数据
- Analyze(分析):对数据进行深度分析,识别失败模式和根因
- Plan(规划):基于分析结果制定优化策略
- Execute(执行):执行优化计划并部署新模型
在数据飞轮中的应用:
python
# 实际案例:NVIDIA NVInfo AI
# Monitor: 3个月内收集495个负反馈样本
# Analyze: 发现两大失败模式(路由错误5.25%,查询改写错误3.2%)
# Plan: 使用8B模型替代70B模型,通过微调达到同等准确率
# Execute: 模型参数量10倍压缩,延迟降低70%核心价值:MAPE循环将"数据驱动的持续优化"变成一个可执行、可重复的工程流程,而不是依赖个人经验的艺术。
Q3: 数据飞轮的四大构建模式是什么?请详细说明。
参考答案
模式一:人工标注回灌(Human-in-the-Loop)
- 流程:用户反馈 -> 人工标注 -> 数据清洗 -> 模型微调
- 适用场景:高质量要求、边界清晰的场景
- 缺点:成本高、周期长
模式二:合成数据闭环(Synthetic Data Flywheel)
- 流程:AI生成 -> 质量评估 -> 筛选过滤 -> 与人工标签校准
- 适用场景:数据稀缺、需要快速扩量的场景
- 优点:成本低、扩展性强
- 2026年增速最快的模式
模式三:RLHF/DPO偏好闭环
- 流程:收集用户点赞/点踩 -> 构建偏好对 -> 强化学习微调
- 适用场景:需要符合人类偏好的场景(如对话、写作)
- 代表方法:InstructGPT、ChatGPT
模式四:运行时自进化(Agentic RAG Flywheel/MAPE循环)
- 流程:监控 -> 分析 -> 规划 -> 执行,完全半自主运行
- 适用场景:企业级AI Agent、复杂任务执行
- 特点:2026年最前沿的模式
Q4: 为什么数据飞轮能实现"越转越省"?
参考答案
数据飞轮"越转越省"源于四个核心机制:
机制一:规模效应
- 初期基础设施投入被大量数据分摊
- 工具和流程趋于标准化、自动化
- 单位数据处理成本持续下降
机制二:模型效率提升
- 每轮优化使模型更精准
- 相同任务消耗更少Token
- 推理成本曲线下降
机制三:知识积累
- 失败模式被系统性记录
- 优化经验固化为流程
- 新场景可复用已有能力
机制四:数据质量提升
- 飞轮转动越久,数据质量越高
- 高质量数据让每轮训练更有效
- 形成"好数据->好模型->好体验->更多好数据"的正循环
量化数据:NVIDIA企业级实践显示,通过数据飞轮优化,推理成本可降低高达98.6%。
Q5: 如何处理数据飞轮中的"冷启动"问题?
参考答案
冷启动问题:当系统刚上线时,没有足够的用户交互数据来驱动飞轮转动。
解决方案:
方案一:种子数据策略
- 准备高质量的种子数据集
- 使用合成数据补充
- 邀请种子用户内测
方案二:模拟飞轮预训练
- 使用历史数据模拟用户交互
- 构建初始训练数据集
- 在上线前完成首轮优化
方案三:渐进式激活
- 先在小范围用户中激活飞轮
- 积累足够数据后再扩大范围
- 分阶段验证飞轮效果
方案四:迁移学习
- 从类似场景迁移数据和模型
- 减少从头构建的成本
- 加速冷启动过程
关键洞察:冷启动不是"有没有数据"的问题,而是"如何高效获取初始数据"的问题。通过种子数据、模拟数据、迁移学习等策略,可以显著缩短冷启动周期。
Q6: 数据飞轮与数据中台有什么区别?
参考答案
数据中台:
- 定位:数据的存储、整合、管理平台
- 核心价值:打破数据孤岛,统一数据服务
- 思维方式:静态的、资源导向的
- 关注点:数据"如何存储和共享"
数据飞轮:
- 定位:数据的循环、利用、增值引擎
- 核心价值:让数据产生复利效应
- 思维方式:动态的、价值导向的
- 关注点:数据"如何流动和增值"
关键区别:
| 维度 | 数据中台 | 数据飞轮 |
|---|---|---|
| 目标 | 数据可用 | 数据增值 |
| 价值 | 降本(避免重复建设) | 增效(持续产生价值) |
| 数据观 | 资源,用完即弃 | 资产,持续升值 |
| 迭代模式 | 周期性大版本 | 持续小步迭代 |
| 衡量指标 | 数据接入量 | 飞轮转动速度 |
关系:数据中台是数据飞轮的基础设施层,但仅有数据中台是不够的------数据需要"流动"起来才能产生价值。
Q7: 在构建数据飞轮时,如何平衡"数据质量"和"数据数量"?
参考答案
核心原则:在数据飞轮中,质量比数量更重要。
量化证据:北京大学DCAI团队的实验表明,仅用1万个高质量样本训练的AI模型,能够超越使用100万个普通样本训练的模型。
平衡策略:
策略一:质量优先于数量
- 设置质量准入门槛
- 宁缺毋滥
- 高质量数据带来的模型提升远超低质量数据堆砌
策略二:分层采集
核心数据(高成本、高质量):人工标注的关键场景
扩展数据(中等成本、中等质量):用户反馈筛选
补充数据(低成本、批量生成):合成数据策略三:动态调整
- 初期:质量为主(用少量高质量数据快速验证)
- 成长期:适度扩展(补充合成数据)
- 成熟期:效率优先(用更少的数据达到同等效果)
策略四:质量监控
- 建立数据质量评估指标
- 持续监控数据分布变化
- 及时发现和处理数据漂移
Q8: 如何评估数据飞轮的效果?请列出关键指标。
参考答案
核心评估框架:
维度一:飞轮健康度
| 指标 | 说明 | 目标 |
|---|---|---|
| 反馈率 | 有反馈的交互占比 | >30% |
| 正面率 | 正面反馈/总反馈 | >80% |
| 反馈质量 | 反馈信息量丰富度 | 定性评估 |
维度二:迭代效率
| 指标 | 说明 | 目标 |
|---|---|---|
| 问题发现到修复周期 | MAPE循环完成时间 | <1周 |
| 数据到训练时间 | 从数据采集到模型更新 | <3天 |
| 版本发布频率 | 模型更新的频率 | 每周/双周 |
维度三:业务价值
| 指标 | 说明 | 目标 |
|---|---|---|
| 用户满意度 | NPS或CSAT | 持续提升 |
| 任务完成率 | 用户目标达成比例 | >90% |
| 自动化率 | 无需人工介入的比例 | 持续提升 |
维度四:成本效率
| 指标 | 说明 | 目标 |
|---|---|---|
| Token效率 | 每任务消耗Token数 | 持续下降 |
| 单位数据成本 | 采集/处理每条数据的成本 | 持续下降 |
| ROI | 投入产出比 | >1 |
关键洞察:评估数据飞轮不能只看单一指标,需要构建多维度评估体系,持续跟踪飞轮健康度、迭代效率、业务价值和成本效率四个维度。
九、企业级实战指导
9.1 技术选型决策树
在构建数据飞轮时,技术选型是第一个需要决策的问题。以下是一个实用的决策框架:
决策树图示
开始构建数据飞轮
|
v
场景类型是什么?
|
+---> 客服/对话类
| |
| +---> 推荐方案:RAG + Human-in-Loop + 合成数据
| +---> 核心组件:反馈采集、对话日志、质量评估、偏好学习
|
+---> Agent/自动化任务类
| |
| +---> 推荐方案:MAPE循环 + RLHF/DPO + 模型压缩
| +---> 核心组件:任务日志、成功率监控、工具调用优化
|
+---> 垂直领域/专业场景
| |
| +---> 推荐方案:专业数据标注 + 领域适配微调
| +---> 核心组件:领域专家、数据标注平台、质量控制
|
+---> 自动驾驶/具身智能
|
+---> 推荐方案:仿真数据 + 真实数据闭环
+---> 核心组件:数据采集、仿真平台、评测体系核心选型建议
| 组件 | 推荐选项 | 适用场景 |
|---|---|---|
| 数据采集 | 自研SDK / OpenTelemetry | 需要深度定制的场景 |
| 日志存储 | Elasticsearch / ClickHouse | 大规模日志分析 |
| 训练框架 | NeMo / LLaMA-Factory / DataFlex | 企业级生产环境 |
| 评估工具 | NeMo Evaluator / RAGAS | 标准化评估 |
| 微调方法 | LoRA / QLoRA / SFT | 资源受限场景 |
| 合成数据 | Llama / GPT-4 / 领域模型 | 数据稀缺场景 |
9.2 成本控制与Token效率优化
成本优化核心策略
策略一:模型分级路由
python
# 根据任务复杂度选择模型
def route_to_model(task):
if task.complexity == "simple":
return small_model # 1B参数,0.1元/千Token
elif task.complexity == "medium":
return medium_model # 7B参数,0.5元/千Token
else:
return large_model # 70B参数,2元/千Token策略二:缓存复用
python
# 对相同或相似query进行缓存
cache = {}
def query_with_cache(user_query):
if user_query in cache:
return cache[user_query]
else:
result = llm_call(user_query)
cache[user_query] = result
return result策略三:提示词压缩
python
# 压缩冗长的提示词
def compress_prompt(prompt):
# 移除不必要的空格、换行
# 合并重复的指令
# 使用缩写替代完整词
return optimized_prompt量化指标
| 优化策略 | 预期成本降低 | 实施难度 |
|---|---|---|
| 模型分级路由 | 30%-50% | 中 |
| 缓存复用 | 20%-40% | 低 |
| 提示词压缩 | 10%-20% | 低 |
| 模型蒸馏 | 50%-80% | 高 |
| 量化部署 | 30%-50% | 中 |
9.3 从离线飞轮到线上闭环的迁移路线
迁移阶段规划
Phase 1: 离线验证(1-2个月)
- 目标:验证飞轮概念可行性
- 任务:
- 构建离线数据处理流水线
- 完成首轮模型微调实验
- 建立评估指标体系
- 里程碑:离线指标提升>20%
Phase 2: 灰度上线(2-3个月)
- 目标:在受控环境中验证线上效果
- 任务:
- 部署日志采集系统
- 实现反馈闭环
- A/B测试验证
- 里程碑:灰度用户满意度提升>15%
Phase 3: 全量推广(3-6个月)
- 目标:飞轮覆盖全量用户
- 任务:
- 扩大数据采集规模
- 优化自动化程度
- 建立持续迭代机制
- 里程碑:核心指标持续提升
Phase 4: 效率优化(持续)
- 目标:飞轮运转更高效
- 任务:
- 缩短迭代周期
- 降低运营成本
- 提升自动化程度
- 里程碑:单位成本持续下降
9.4 生产环境避坑指南
坑1: 数据质量陷阱
症状:飞轮转动但模型效果不升反降。
原因:采集的数据质量差,错误模式被放大。
解决:
python
# 建立严格的数据质量门禁
def quality_gate(data):
if data.quality_score < 0.7:
return "rejected"
elif data.is_noise:
return "rejected"
else:
return "accepted"坑2: 反馈偏差陷阱
症状:模型过度迎合少数用户偏好。
原因:反馈样本存在偏差,未代表真实分布。
解决:
python
# 多样性采样策略
def diverse_sample(feedbacks, target_diversity=0.8):
# 按用户群体分层采样
# 确保长尾场景有足够样本
# 定期审核反馈分布坑3: 漂移累积陷阱
症状:模型逐渐偏离原始设计目标。
原因:数据分布漂移未被及时发现和处理。
解决:
python
# 漂移检测机制
def detect_drift(reference_data, current_data):
distribution_shift = calculate_distribution_distance(
reference_data, current_data
)
if distribution_shift > THRESHOLD:
alert_and_retrain()坑4: 过度优化陷阱
症状:模型在特定指标上表现极好,但其他方面退化。
原因:优化目标过于单一。
解决:
python
# 多目标优化
optimization_objectives = {
"accuracy": {"weight": 0.4, "target": ">0.9"},
"latency": {"weight": 0.2, "target": "<200ms"},
"safety": {"weight": 0.3, "target": ">0.95"},
"diversity": {"weight": 0.1, "target": ">0.7"}
}坑5: 冷启动放弃陷阱
症状:飞轮早期效果不明显,提前放弃。
原因:低估了飞轮启动期所需时间。
解决:
python
# 合理的预期管理
def set_expectations():
return {
"phase1_weeks": 4, # 飞轮启动
"phase2_weeks": 8, # 效果显现
"phase3_weeks": 16, # 显著提升
"key_metric": "positive_rate",
"minimum_data": 10000 # 最小样本量
}9.5 2026年前沿趋势与未来展望
趋势一:从"以模型为中心"到"以数据为中心"
AI领域的竞争重心正在从模型架构转向数据质量。北京大学DCAI团队的DataFlow框架证明了:高质量的1万个样本可以打败低质量的100万个样本。这一趋势将推动整个行业重新审视数据工程的价值。
趋势二:Agentic AI驱动数据飞轮自动化
随着AI Agent能力的提升,数据飞轮的运营将越来越自动化。NVIDIA的MAPE控制循环已经展示了这一方向------从监控到执行,AI可以自主完成大部分工作。
趋势三:合成数据成为主流
2026年,合成数据在AI训练中的占比将超过50%。光轮智能的5.5亿元订单只是一个开始,更多企业将意识到:与其花费大量成本采集真实数据,不如用合成数据快速迭代。
趋势四:Token效率成为核心竞争力
中国日均Token调用量突破140万亿,但算力成本在持续上涨。Token效率将成为企业AI的核心竞争力------谁能用更少的Token完成更多的任务,谁就能在成本战争中胜出。
趋势五:数据飞轮与垂直行业深度融合
通用飞轮框架将向行业化、专业化发展。自动驾驶、医疗、金融等领域将出现专门的数据飞轮解决方案,更贴合行业特点的数据采集、处理和利用方式。
未来展望
数据飞轮的本质是让数据成为"会自我增值的资产"。在AI时代,数据的价值不是一次性释放的,而是在持续使用中不断增值的。构建高效的数据飞轮,就是构建AI时代的竞争壁垒。
未来的竞争,不只是模型参数的竞争,更是"谁能更好地转动数据飞轮"的竞争。
十、总结
核心要点回顾
-
数据飞轮的本质:用"系统的力量"替代"人的勤劳",让数据成为可持续增值的资产,而非一次性消耗的资源。
-
MAPE控制循环:Monitor(监控)-> Analyze(分析)-> Plan(规划)-> Execute(执行),是将数据驱动优化工程化、流程化的关键框架。
-
四大构建模式:人工标注回灌、合成数据闭环、RLHF/DPO偏好闭环、运行时自进化(MAPE循环),各有适用场景,可组合使用。
-
企业级价值:NVIDIA实践显示推理成本可降低98.6%,DoorDash案例显示幻觉率可降低90%,京东JoyAI展示了Token效率优化的极致追求。
-
Token效率是2026年核心竞争力:中国日均Token调用量突破140万亿,成本控制成为生死线,数据飞轮是实现成本递减的关键手段。
行动建议
对于算法工程师:
- 掌握数据飞轮的核心组件和实现方法
- 建立从数据采集到模型更新的完整闭环思维
- 关注Token效率优化,提升模型性价比
对于技术管理者:
- 将数据飞轮纳入AI基础设施规划
- 建立数据资产意识,不只是关注模型指标
- 投资数据工程团队,让数据真正产生复利
对于创业者:
- 数据飞轮是构建竞争壁垒的关键
- 越早启动飞轮,越早形成优势
- 用户使用就是数据,数据就是护城河
参考文献
- NVIDIA. "Adaptive Data Flywheel: Applying MAPE Control Loops to AI Agent Improvement." EACL 2026 Industry Track.
- 中国信息通信研究院. 《智能原生研究报告(2026年)》
- 北京大学DCAI团队. "DataFlow: Industrial-Grade LLM Data Engineering Framework." 2026.
- 工业和信息化部. 《"模数共振"行动实施方案(2026年)》
- NVIDIA AI Blueprints. "Data Flywheel Foundational Blueprint." 2025.
- 新华网. 《我国日均Token调用量超过140万亿》. 2026年3月.
转载声明
本文为原创文章,如需转载,请联系作者获得授权,并注明出处。
作者:Java后端的Ai之路
首发平台:CSDN