如何提升模型编码能力
编程 Agent 接入开源模型的时候,很多时候表现差不是模型本身差,而是系统层没有把请求、缓存、模型路由和服务商能力处理好。
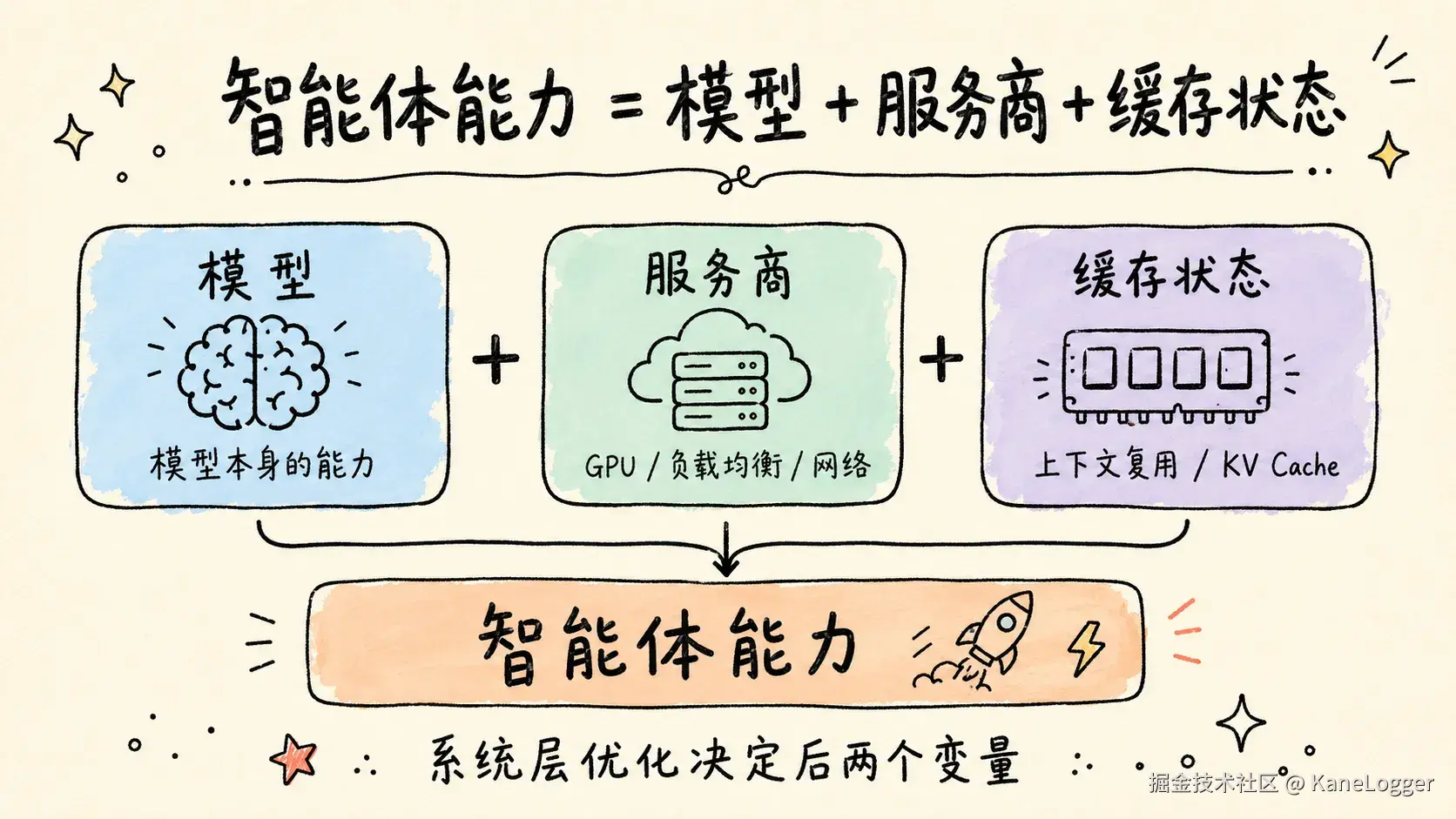
智能体能力 = 模型 + 服务商 + 缓存状态
系统层(harness)决定了后两个变量。
提升Agent能力的三个要点:
- 缓存要命中
- 模型名要统一
- 多轮对话要稳定。
同一个对话要尽量发到同一台 GPU 服务器上
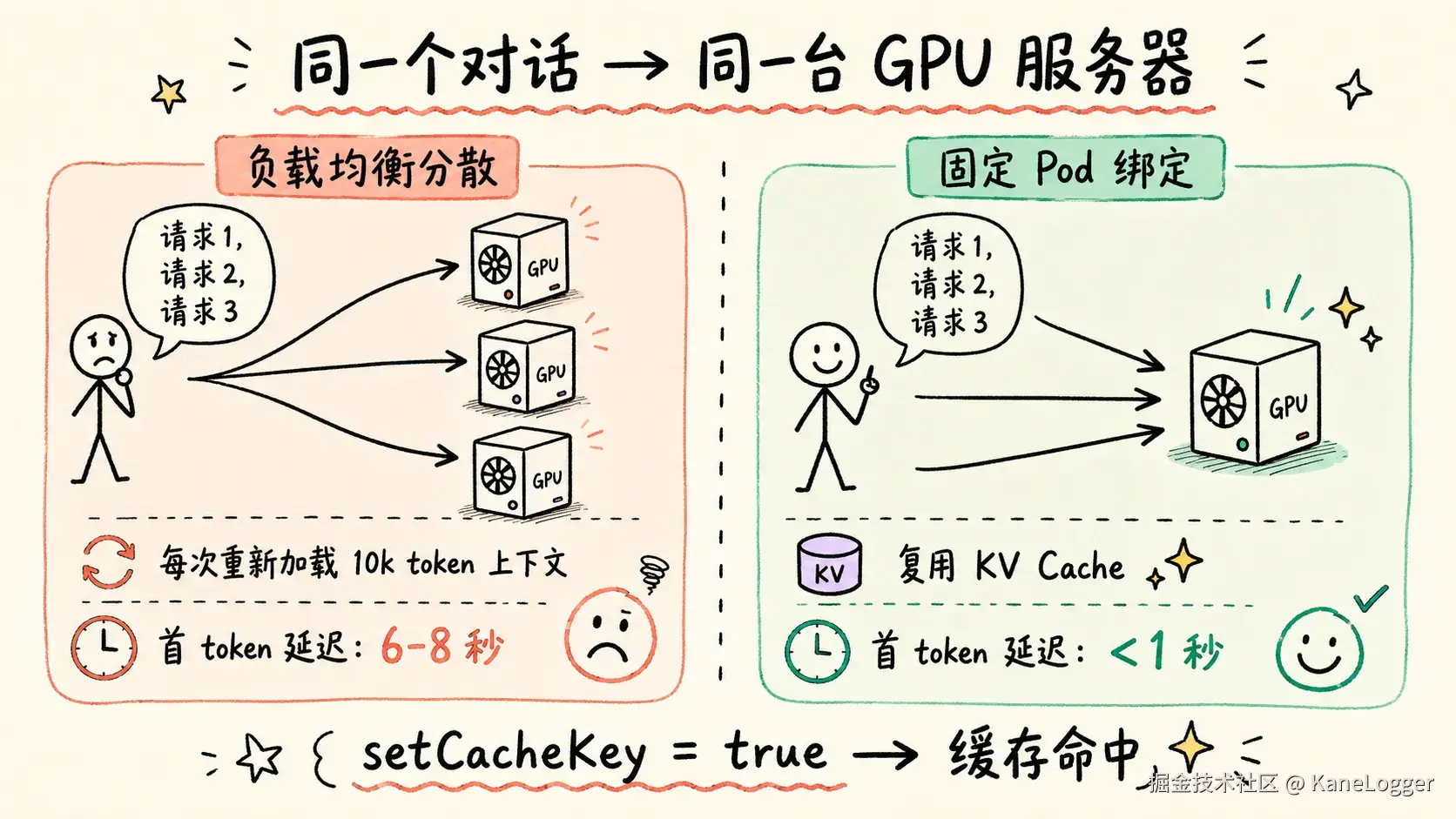
编程 Agent 每一轮对话前面都有一大段固定内容,比如系统提示词、工具列表、历史上下文。
这些内容很长,大概 10k token。理论上,服务器可以把这些内容缓存起来,下一轮直接复用,速度会快很多。
问题是,负载均衡器把连续请求分配到了不同 GPU Pod,导致每一轮都重新读取一遍长上下文,首 token 延迟变成 6--8 秒。
可以通过一个简单的配置,来提升效果。
提升 kimi k2.6 缓存命中率,以 opencode 为例,配置 /.config/opencode/opencode.json
json
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"kimi-for-coding": {
// 如果是 connect 方式连接的,需要看 .local/auth.json 的配置,provider 的 key 要保持一致。
"options": {
"setCacheKey": true
}
}
}
}统一模型ID
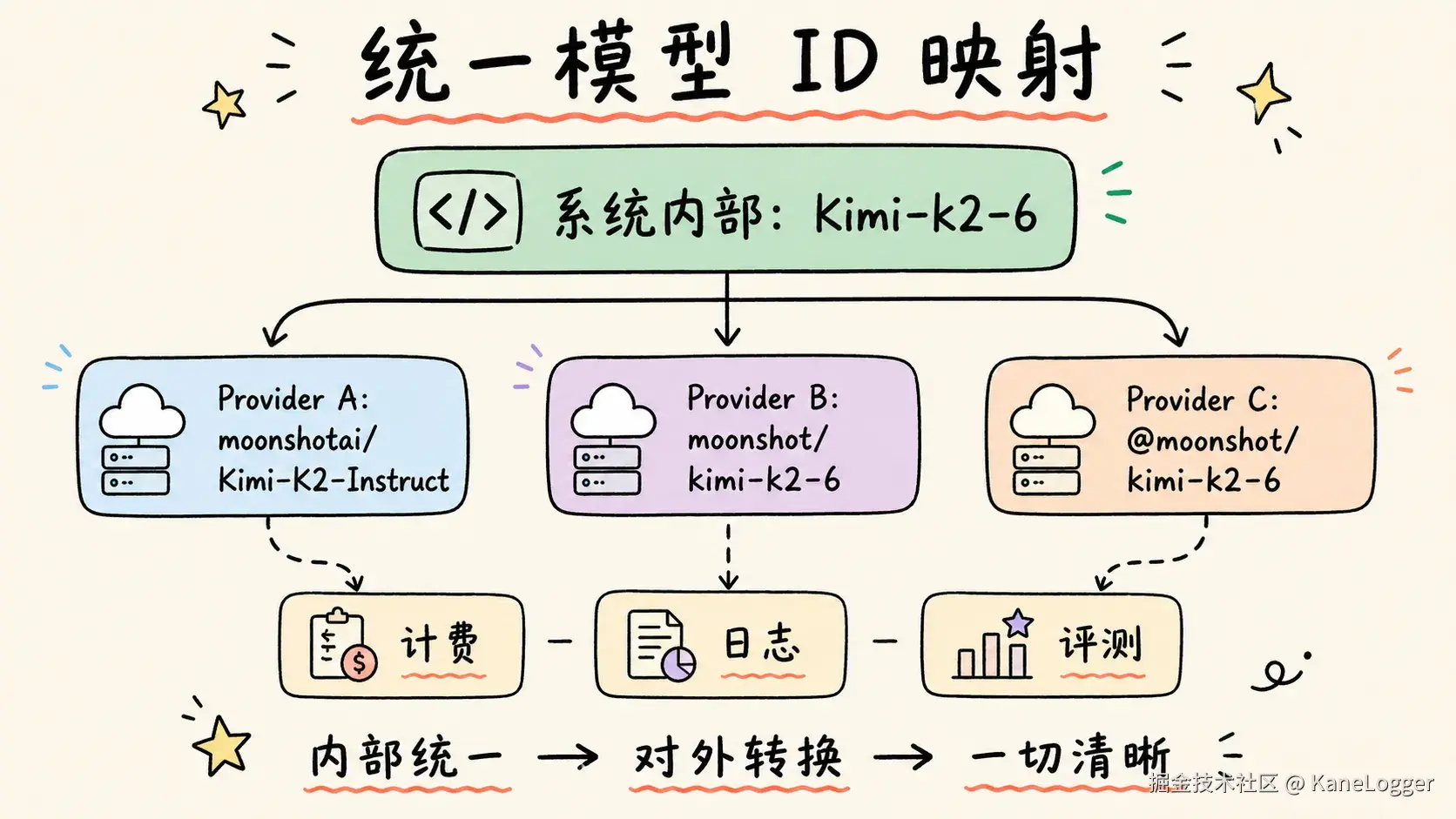
系统内部只认一个统一模型名。
比如同一个 Kimi 模型,不同服务商叫法不同:moonshotai/Kimi-K2-Instruct、moonshot/kimi-k2-6、@moonshot/kimi-k2-6。
我的做法是,系统内部永远使用统一名称 kimi-k2-6,只有真正发给服务商之前才转换成各家的模型 ID。这样计费、日志、评测、故障回退都清楚。否则搞不清一次调的是哪个模型。
同一任务尽量在一个会话中完成
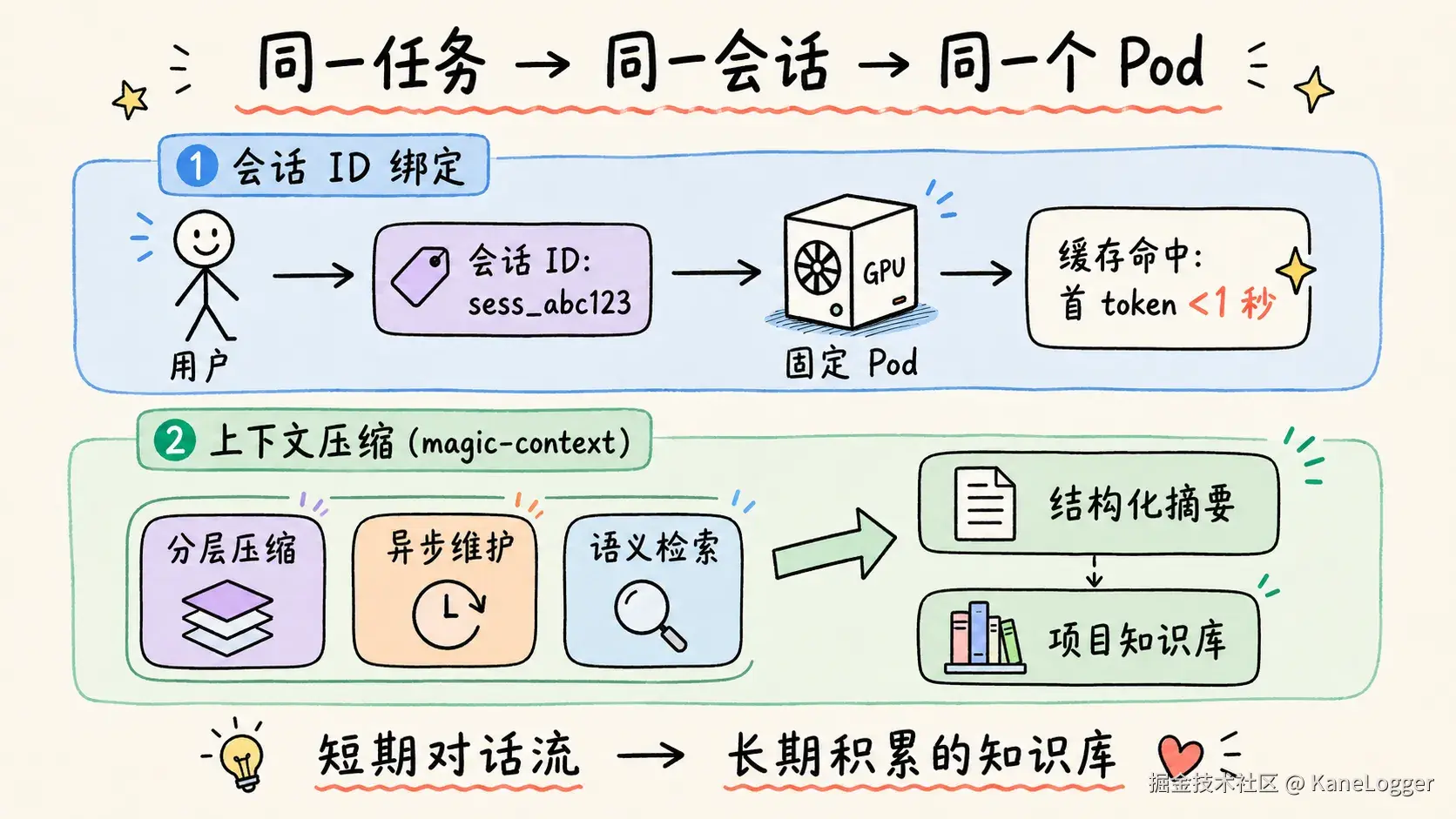
也可以增加一个会话 ID,让同一会话尽量落到同一个 Pod,缓存命中后首 token 延迟降到 1 秒以内。
如果是 opencode 用户可以参考使用 magic-context 这个插件。核心功能:异步压缩旧对话为结构化摘要,用分层压缩 + 异步维护 + 语义检索,把短期对话流转化为可长期积累的项目知识库。