**摘要:**本文聚焦LlamaIndex,作为LLM应用的核心数据框架,它搭建起通用大模型与私有数据的桥梁。文章系统拆解其四大核心流程:Loading完成文档加载与节点分割,Indexing构建向量索引实现语义检索,Storing借助StorageContext实现数据持久化,Querying提供自然语言查询接口。同时深入解析Workflows模块,涵盖事件驱动的控制流、状态管理与可视化调试能力。全文帮助开发者掌握从数据接入到复杂AI代理编排的完整路径,助力构建高效RAG应用。
回顾:LangChain 与 RAG 的演进
在上一篇文章中,深入探讨了从传统 RAG 到 GraphRAG 的演进过程。分析了传统检索增强生成在面对复杂推理场景时的局限性------难以处理多跳推理和实体关系建模。
为了解决这些问题,引入了 LangChain 作为大模型应用工程化的框架。LangChain 的核心价值在于它提供了一套完整的工具链,涵盖了 Model I/O (模型交互)、Data Connection (数据连接,即 RAG 的核心)、Chains (链式逻辑)、Memory (记忆)、Agents & Tools (智能代理)以及 Middleware(中间件)。
通过 LangChain,学会了如何将"模型能力"转化为"应用落地",例如构建智能招聘或电商助手。但随着技术的深入,也需要了解另一个同样强大的框架------LlamaIndex,它在数据索引和检索方面提供了独特的视角和更灵活的数据结构。
引言:为什么需要 LlamaIndex?
作为一名计算机相关专业的大学生,在探索生成式 AI 的浪潮中,我接触到了 LlamaIndex 。在学习了相关课程并查阅了大量资料后,我深刻体会到它作为"LLM 应用程序的数据框架"的价值。LlamaIndex 的核心使命非常明确:让大语言模型(LLM)能够轻松地理解、检索和使用私有或特定领域的数据。
这篇博客将记录我学习 LlamaIndex 的核心笔记,梳理其构建 RAG(检索增强生成)应用的完整流程,并分享关于组件化设计与工作流(Workflows)的思考。
一、什么是 LlamaIndex?
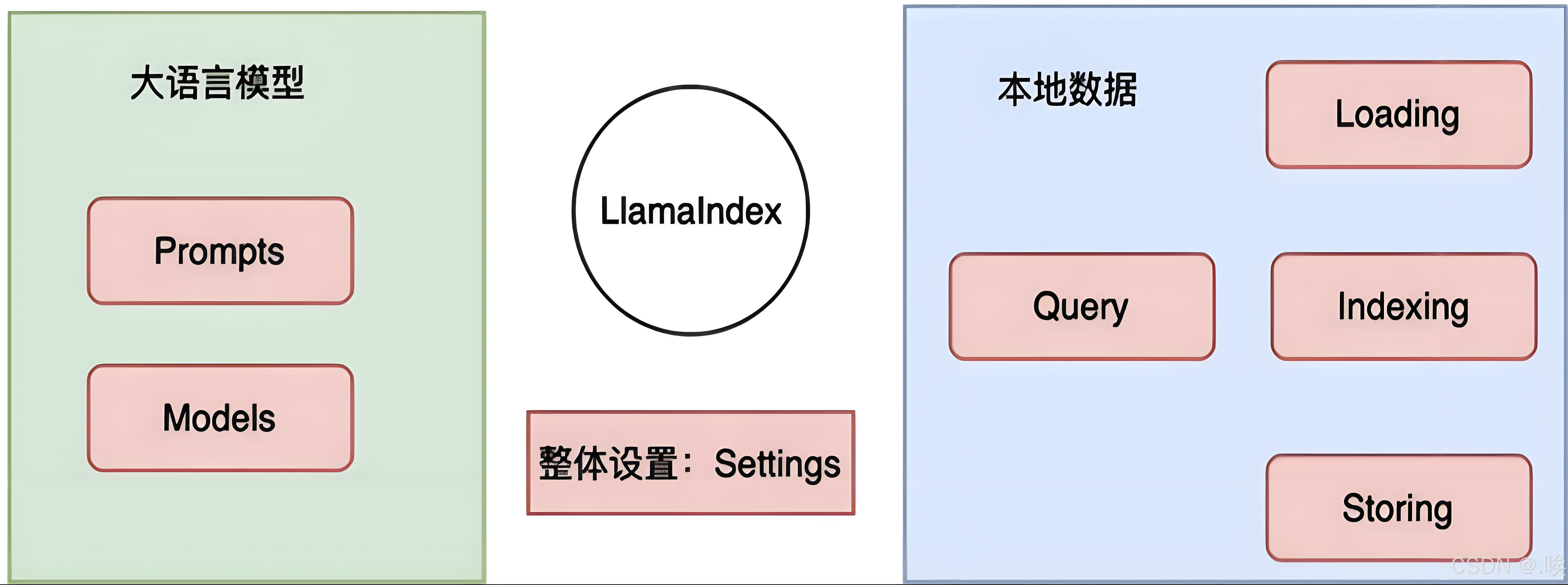
简单来说,LlamaIndex 就像是一座桥梁,连接了通用的大语言模型和我们手中的特定数据。 它本身并不限制你如何使用 LLM,而是提供了一套工具,帮助我们将外部数据"注入"到 LLM 中,使其能够基于这些数据生成更准确、更有依据的回答。
构建一个 RAG 应用通常遵循以下四个核心步骤:
- 文档加载 (Loading)
- 构建索引 (Indexing)
- 数据存储 (Storing)
- 查询引擎 (Querying)
二、核心组件详解
LlamaIndex 采用组件化的方式,将大模型、向量数据库、索引等进行灵活组合。以下是我在学习中总结的五大核心组件:
1. Loading:文档加载与处理
这是处理本地数据的起点。LlamaIndex 会将文档加载为 Document 对象,再将其拆分为 Node(节点),这是检索和推理的基本单元。
-
Document 对象属性:
text: 文档的主体文本。metadata: 存储附加信息的字典。relationships: 描述文档或节点间关系的字典。doc_id: 唯一标识符。
-
节点解析与分割:
- 基于文件的解析器 :如
SimpleFileNodeParser(智能调度)、HTMLNodeParser、JSONNodeParser等,用于处理不同格式的文件。 - 文本分割器 (Text-Splitters) :这是关键环节。推荐使用
SentenceSplitter(按句子分割,保持语义完整性),此外还有基于 Token 的分割和专门针对代码的CodeSplitter。
- 基于文件的解析器 :如
2. Indexing:索引构建
索引是一种组织 Node 的数据结构,旨在让 LLM 高效查询。
- VectorStoreIndex:最常用且强大的索引类型。
- 向量嵌入 (Vector Embeddings):核心原理是将文本语义转换为数字向量。LlamaIndex 调用嵌入模型(如 text-embedding-ada-002)将 Node 转化为向量存储。查询时,通过计算向量距离找到与问题"语义最相关"的文本块。
3. Storing:数据持久化
LlamaIndex 允许用户定制外部存储,主要包括:
- Document stores (存储文档/节点)
- Index stores (存储元数据)
- Vector stores (存储向量数据)
- 核心管理器 :
StorageContext。它是存储组件的"容器",支持内存默认实现,也支持保存到磁盘(persist_dir)或加载已有存储。
4. Querying:查询引擎
这是一个无状态的通用接口,用于用自然语言查询数据。通过 query_engine.query() 即可获取结果。
5. Settings:全局设置
作为全局配置管理器,可以统一设置 LLM、嵌入模型、查询引擎等参数,避免在代码各处重复配置。
三、LlamaIndex 工作流 (Workflows)
随着应用复杂度的增加,简单的线性流程往往不够用。LlamaIndex 的 Workflows 提供了事件驱动、基于步骤的执行控制方式,非常适合构建复杂的 AI 应用程序。
为什么选择工作流? 工作流将应用分解为更小的步骤,结合代理(Agents)和工具,能够有效管理复杂的数据流。它支持原生 Python 编程,并且非常适合部署为生产级别的微服务。
1. 核心特性:
- 可视化 (Visualization) :LlamaIndex 内置了强大的可视化功能。通过
draw_all_possible_flows可以查看所有理论路径,通过draw_most_recent_execution可以查看实际运行轨迹,这对调试分支逻辑非常有帮助。 - 控制流:支持线性、循环(Loop)和分支(Branch)逻辑。通过自定义事件类型,可以轻松实现复杂的业务逻辑。
- 状态管理 (Context) :为了解决步骤间数据传递繁琐的问题,工作流提供了
Context对象。它像一个共享储物柜,在整个生命周期中存在,任何步骤都可以存取数据(如大型索引对象)。 - 可观测性与调试 :
- Verbose 模式:开启后打印详细日志。
- 检查点 (Checkpoints):对于包含昂贵 LLM 调用的长流程,检查点能防止因中间出错而需要从头开始重跑,极大节省时间和成本。
- 部署 :通过
llama_deploy项目,可以将工作流部署为多 Agent 服务,利用控制平面和消息队列实现高可用的服务架构。
2. 总结表:
为了方便记忆,我整理了以下核心组件对照表:
| 组件类型 | 核心作用 | 关键类/概念 |
|---|---|---|
| 加载 (Loading) | 将数据转化为 LLM 可读的节点 | Document, Node, SentenceSplitter |
| 索引 (Indexing) | 组织数据以供高效检索 | VectorStoreIndex, Embeddings |
| 存储 (Storing) | 持久化数据与状态 | StorageContext, Vector Stores |
| 工作流 (Workflow) | 控制复杂应用的执行流程 | Workflow, Context, draw_all_possible_flows |
四、总结
通过这篇笔记,我系统地梳理了 LlamaIndex 作为 LLM 数据框架的核心架构。总结来说,LlamaIndex 的核心价值在于**"连接"** 与**"编排"**:
- 数据连接层 :通过 Loading (文档加载与节点分割)和 Indexing(向量嵌入与索引构建),LlamaIndex 解决了大模型"知识过期"和"缺乏私有数据"的痛点,让模型能够读懂你的数据。
- 持久化与查询 :利用 Storing 组件实现数据的长期记忆,通过 Querying 引擎实现自然语言的精准检索。
- 复杂流程编排 :当应用逻辑变得复杂时,Workflows 提供了强大的事件驱动机制。它不仅支持循环与分支等控制流,还通过可视化(Visualization)和检查点(Checkpoints)提供了卓越的可观测性与调试能力,是构建生产级 AI Agent 的关键。
掌握这些核心概念,就掌握了构建高效、可靠 RAG 应用的钥匙。