我最近越来越强烈地感觉到一件事:AI 写代码已经挺能打了,速度很快,补函数、改组件、写测试都能帮上很多忙。
但一到架构设计,情况就不一样了。很多时候,AI 能把代码写出来,却不太能决定系统应该怎么拆、边界应该放在哪里、哪些抽象现在值得做,哪些应该先忍住。最后架构还是得人自己定。
那人怎么定?一个很常见的做法,就是去调研别人已经做过的项目:看看成熟仓库怎么组织模块、怎么处理主流程、怎么把复杂度收起来。本来我以为这件事也可以交给 AI,让它帮我分析一下参考项目的架构。结果经常发现,AI 分析别人项目的能力也不太行,经常读到最后只剩目录结构、函数调用关系和一些泛泛的模块说明。
它很像一个刚入职、很努力、但还没学会抓重点的同事。
你把一个项目丢给它,它会认真读 README,扫目录,列模块,画几个箭头。说得都对,但你读完总觉得少了点什么。
少的不是"信息",而是"判断"。
比如你真正想知道的是:
- 这个项目为什么这么拆模块?
- 哪条主流程最能暴露作者的设计意图?
- 哪些抽象值得我偷师,哪些只是历史包袱?
- 如果要把这种设计迁移到自己的项目,该复制什么,千万别复制什么?
但普通提示词下的 AI,经常给你一份"目录树豪华版"。看上去很充实,脑子里还是没有架构。
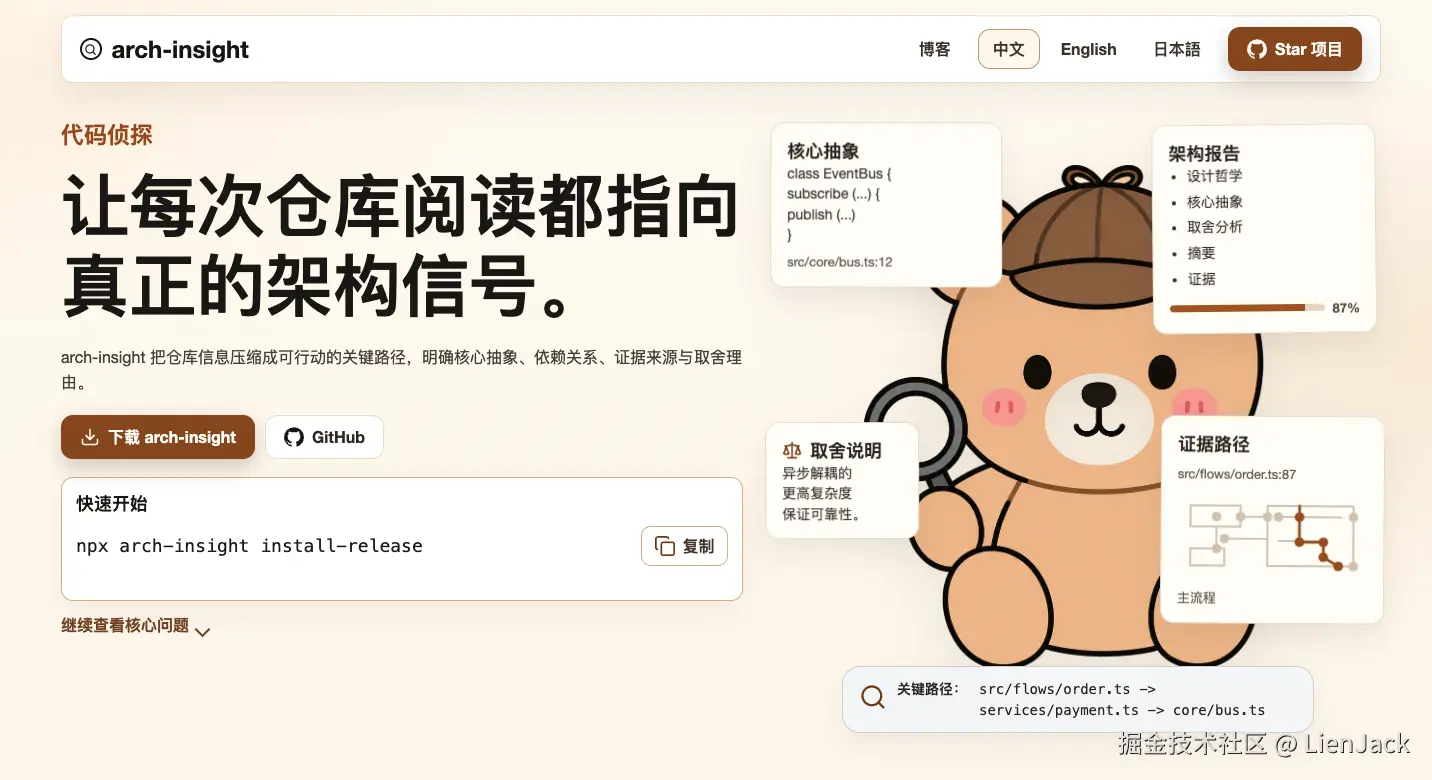
于是我写了一个项目:Arch Insight。它是一个 Agent Skill,目标不是让 AI "总结代码",而是让 AI 把源码仓库转成设计判断。
更准确地说,它试图教 AI 一件事:
读代码不是把文件读完,而是找到系统真正站在什么设计选择上。
目前我已经开源,放在GitHub上,欢迎stars。
安装命令
arduino
npx arch-insight install-release并且花了3个小时做了个官网展示(前端已经死的很安详)。
一、我为什么要写它:AI 读仓库时,经常很努力但跑偏了
AI 通常会很配合:
- 先介绍项目是干什么的。
- 再列目录结构。
- 再说每个模块负责什么。
- 最后给一段"整体架构清晰、模块职责明确"的评价。
这当然不算错,但不够有用。
真正的问题在于,AI 默认并不知道"架构分析"到底要分析什么。它很容易把架构理解成:
txt
目录结构 + 模块职责 + 调用关系 + 一点点总结可在真实工程里,架构更像是:
txt
问题约束 + 主流程 + 核心抽象 + 边界设计 + 取舍理由 + 可迁移条件这两个东西差别很大。
前者像把厨房里的抽屉都打开,告诉你锅在哪、刀在哪、盐在哪。后者才是在解释:为什么这个厨房这么布局,主厨每天最高频的动作是什么,什么设计提升了效率,什么设计以后会卡住扩张。
我遇到的具体痛点主要有五个。
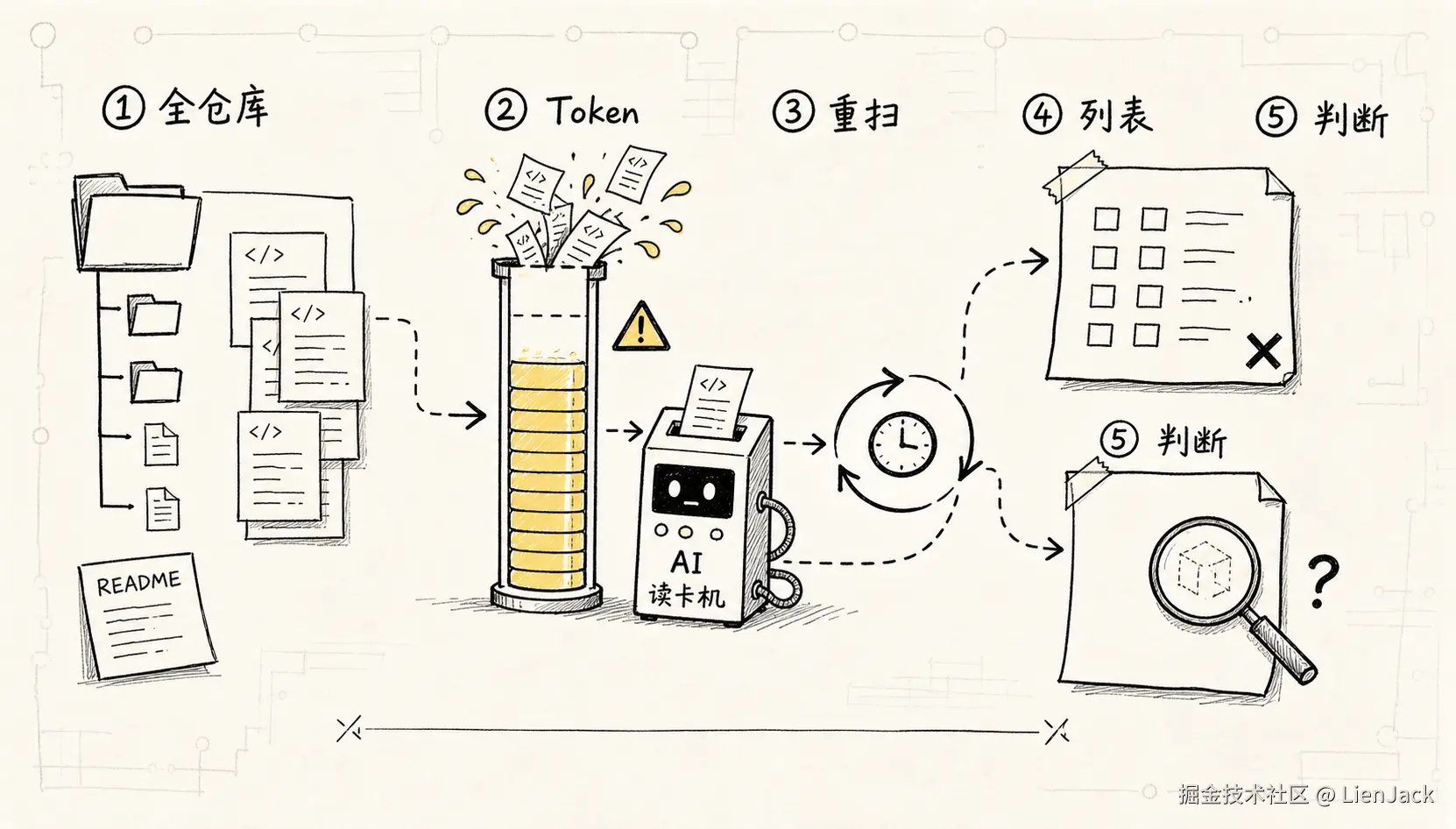
第一,Token 烧得太快。 每次新对话都把整个仓库扫一遍,上下文哗啦哗啦烧掉,真正需要深挖的文件反而没读透。
第二,重复劳动。 同一个项目,今天问一次,明天换个角度再问,AI 又从零开始读。你付过的"理解成本",下一轮不一定能复用。
第三,分析太浅。 AI 很擅长复述"这里有什么",但回答"为什么这么设计"不太稳定。尤其是项目有构建层、安装层、发布层、适配层时,它容易被文件数量带着走。
第四,风格不对。 有时我想要一篇能发表的技术长文,它给我模板报告;有时我想要结构化研究包,它又写得像博客散文。
第五,不会引导。 我自己有时也说不清该问什么。AI 如果没有一套固定研究路径,就会在"读得很多"和"读得有用"之间摇摆。
所以 arch-insight 的出发点不是"再写一个总结工具",而是把我希望 AI 遵守的源码研究方法固化成 Skill。
它不是让 AI 更会夸项目,而是让 AI 更会质疑项目。
二、先看效果:好的架构分析应该长什么样
说一堆"研究路径""设计判断",确实容易变成空话。更直接的方式,是看它到底能产出什么。
由于最近在写Agent相关,要设计项目的coding workflow提效和Agent的Memory的设计。所以我用 arch-insight跑过两类参考项目:一类是 LLM coding workflow,一类是 agent memory system。它们的共同点是:如果只按目录和函数调用读,很容易读成"这个文件调用那个文件";但真正有用的地方,是它们背后的工程取舍。
1. 分析 LLM coding workflow:不只是列功能,而是比较协作机制
以下文章都是通过Arch Insight直接生成
比如这篇样例:五个 LLM 编码助理工作流的深度对比分析。
它分析的不是单个仓库,而是 cc-sdd、Compound Engineering、Superpowers、Trellis、Spec Kit 五个项目。普通分析很可能会写成:
txt
每个项目有哪些命令、有哪些 skill、有哪些模板、有哪些 agent。但真正有价值的分析应该先把它们放到同一张坐标系里:
| 维度 | 真正要看的问题 |
|---|---|
| 工作流编排 | 人类和 LLM 的职责边界在哪里?哪些阶段必须审批? |
| 子代理机制 | 是一个 agent 从头做到尾,还是 per-task 隔离实现、审查和调试? |
| 上下文管理 | 项目知识靠 prompt 临时塞进去,还是有文件系统/JSONL/状态协议承接? |
| 知识积累 | 一次工作结束后,经验会不会进入下一次默认上下文? |
| 跨平台策略 | 是单平台 prompt,还是把同一套工作流翻译到多个编码助理? |
这样一对比,项目之间的性格就出来了:
- cc-sdd 押注的是契约驱动:spec 不是"给 agent 的说明书",而是系统各部分之间的边界契约。
- Compound Engineering 押注的是复合效应:每次工程工作都应该让后续工作更容易,而不是只完成当下任务。
- Superpowers 押注的是流程纪律:防止 agent 一上来就写代码,强制先设计、再计划、再执行、再审核。
- Trellis 押注的是结构化上下文:用
.trellis/目录、任务状态和 JSONL 注入,替代 LLM 不可靠的短期记忆。 - Spec Kit 押注的是规格平台化:让 spec 不只是文档,而是可以驱动代码生成和扩展生态的输入。
这就不是"函数调用关系"了,而是在回答:
如果我要设计自己的 AI coding workflow,应该借鉴谁的哪一部分,又应该避开谁的代价?
比如样例里最后给出的启示,就已经很接近可迁移的设计建议:
| 值得借鉴的机制 | 来源 | 为什么有用 |
|---|---|---|
| workflow-state breadcrumb 协议 | Trellis | 用很轻的文本标签,让 agent 每轮都知道自己处在哪个阶段 |
| Boundary-First 任务切分 | cc-sdd | 避免 agent 在长 session 里被上下文污染 |
| 多 persona 并行 code review | Compound Engineering | 用不同视角弥补单个 agent 的审查盲区 |
| 每 task 三角色闭环 | cc-sdd / Superpowers | 把实现、审查、调试拆开,降低自我确认偏差 |
| 文档复合系统 | Compound Engineering | 让一次解决问题的经验进入后续工作 |
这才是我想要的架构分析:不是告诉我"它有几个命令",而是告诉我"这些命令背后在押注什么协作模型"。
2. 分析 agent memory:找出设计分水岭,而不是堆 API 名字
另一篇样例是:代理记忆系统的设计哲学。
这个主题更容易被 AI 分析歪。因为 memory 项目里有大量 API、数据库、embedding、search、tool calling,如果没有抓重点,很容易写成:
txt
mem0 有 add/search,Graphiti 有 add_episode/search,Letta 有 memory block,LangMem 有 manage_memory tool。这些都对,但没什么决策价值。
真正的重点,是先问一个更上层的问题:
"记忆"到底以什么物理形式存在,什么时候进入模型视野?
这个问题一出来,五个项目马上分成两类:
| 类型 | 代表项目 | 核心取舍 |
|---|---|---|
| 基于检索 | mem0 / Graphiti / LangMem / Basic Memory | 记忆放在外部,需要时检索,规模大,但可能检索失败 |
| 基于编译 | Letta | 核心记忆每轮编译进上下文,不会漏,但受上下文窗口限制 |
这个分水岭比"用了什么数据库"重要得多。因为它直接决定了系统的使用场景:
对于任务长、工具结果多的 CLI 编程代理,基于检索更合适;对于需要稳定知道"用户是谁"的聊天同伴或客服代理,基于编译更合适。通用代理平台往往需要两者都要。
再往下,样例不是平铺五个项目的功能,而是继续抽出真正的设计权衡:
| 设计选择 | 代表项目 | 背后的判断 |
|---|---|---|
| ADD-only vs CRUD | mem0 / LangMem | 是把写入做简单,还是让记忆始终代表最新状态? |
| 时态图 vs 向量数据库 | Graphiti / mem0 | 是要关系和时间推理,还是先满足语义相似检索? |
| 自动提取 vs agent 主动管理 | mem0 / LangMem / Basic Memory | 是保证重要信息不丢,还是相信 agent 自己判断何时记住? |
| 人类可读 vs 机器优化 | Basic Memory / 向量记忆系统 | 人类是否需要检查、编辑、拥有最终控制权? |
比如 mem0 V3 的 ADD-only 设计,表面看是一个实现细节:只追加,不更新,不删除。真正的架构判断是:
把写入时的冲突解决成本,转移到检索时的排序和筛选成本。
这句话就有迁移价值。它会提醒你:如果你的记忆主要是用户偏好、项目约定、经验沉淀,ADD-only 可能很稳;如果你的记忆是权限、配置、规则这种必须准确的事实,那就不能简单照抄。
Graphiti 的事实有效性窗口也是类似:
txt
EntityEdge {
valid_at
invalid_at
}这不是"多了两个字段"。它表达的是一种设计哲学:
不删除旧事实,但也不让旧事实继续污染当前判断。
这类结论才是我想从参考项目里带走的东西。
3. 这些样例真正展示了什么
看完这两篇样例,我觉得好的架构分析至少应该有三个特征。
第一,它会主动找分水岭。 比如 memory 系统里的"检索 vs 编译",coding workflow 里的"流程刚度 vs 灵活性"。分水岭找到了,后面的模块和文件才有意义。
第二,它会把实现细节翻译成工程取舍。 ADD-only、workflow breadcrumb、Boundary-First、human/persona block,这些都不是孤立技巧,而是在用不同方式解决成本、可靠性、上下文污染、知识积累这些问题。
第三,它会给迁移建议。 不是"这个项目很好",而是"什么场景适合借,什么场景不要借,先验证哪一个风险"。
所以 arch-insight 想解决的不是"让 AI 多读几个文件"。
我真正想要的是:当我准备设计自己的系统时,AI 能先帮我把别人的项目读成可复用的设计判断。
三、我是怎么把这套分析方法做成 Skill 的
有了上面这些样例之后,下一步就是把这种分析方式固定下来。
我不想每次都在对话里重新解释:"不要只列目录""先找设计分水岭""要给迁移建议""不要把函数调用关系当架构"。这些要求靠临场 prompt 可以做到一次,但很难稳定复用。
所以我做 arch-insight 的思路很简单:把一次有效的架构分析过程拆成几个固定动作,再把这些动作写进 Skill 里。
大概流程是:
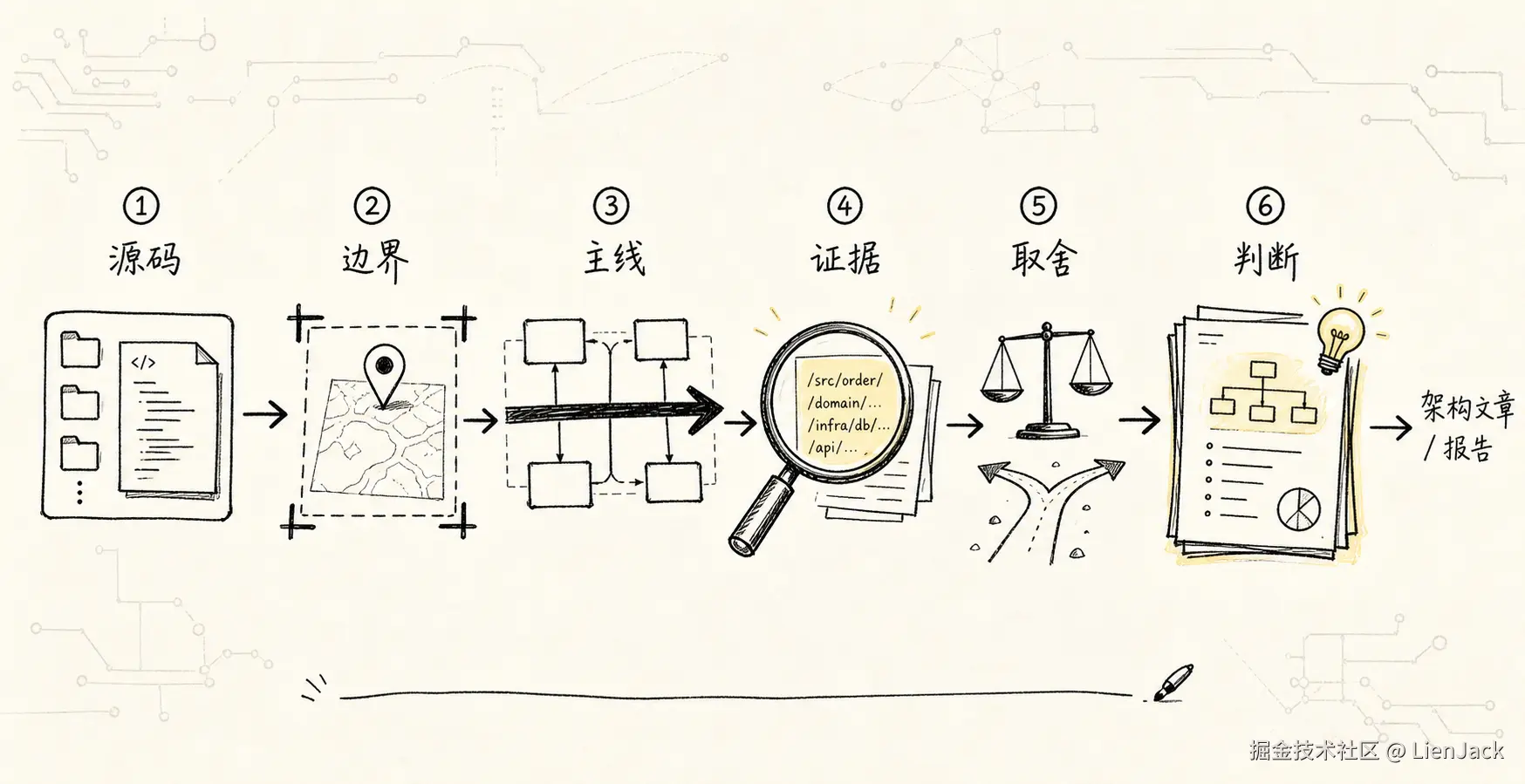
txt
先问清楚这次想看什么
-> 再决定哪些代码要重点读
-> 找出项目最关键的那条主线
-> 解释作者为什么这么设计
-> 最后写成能直接参考的内容这几步其实是在把我平时手动分析项目的过程写下来。
比如先问清楚目标,是为了避免 AI 一上来就把仓库全扫一遍;先决定重点读哪些代码,是为了把精力放在真正决定系统形状的地方;找主线和解释设计原因,是为了让它不要停在"这个函数调用那个函数";最后写成能参考的内容,是为了让分析结果真的能帮我设计自己的项目。
这部分写完以后,我一开始以为差不多了:不就是把提示词整理好,放进 SKILL.md,然后让 AI 按这套流程工作吗?
但很快我发现,新的问题出现了。
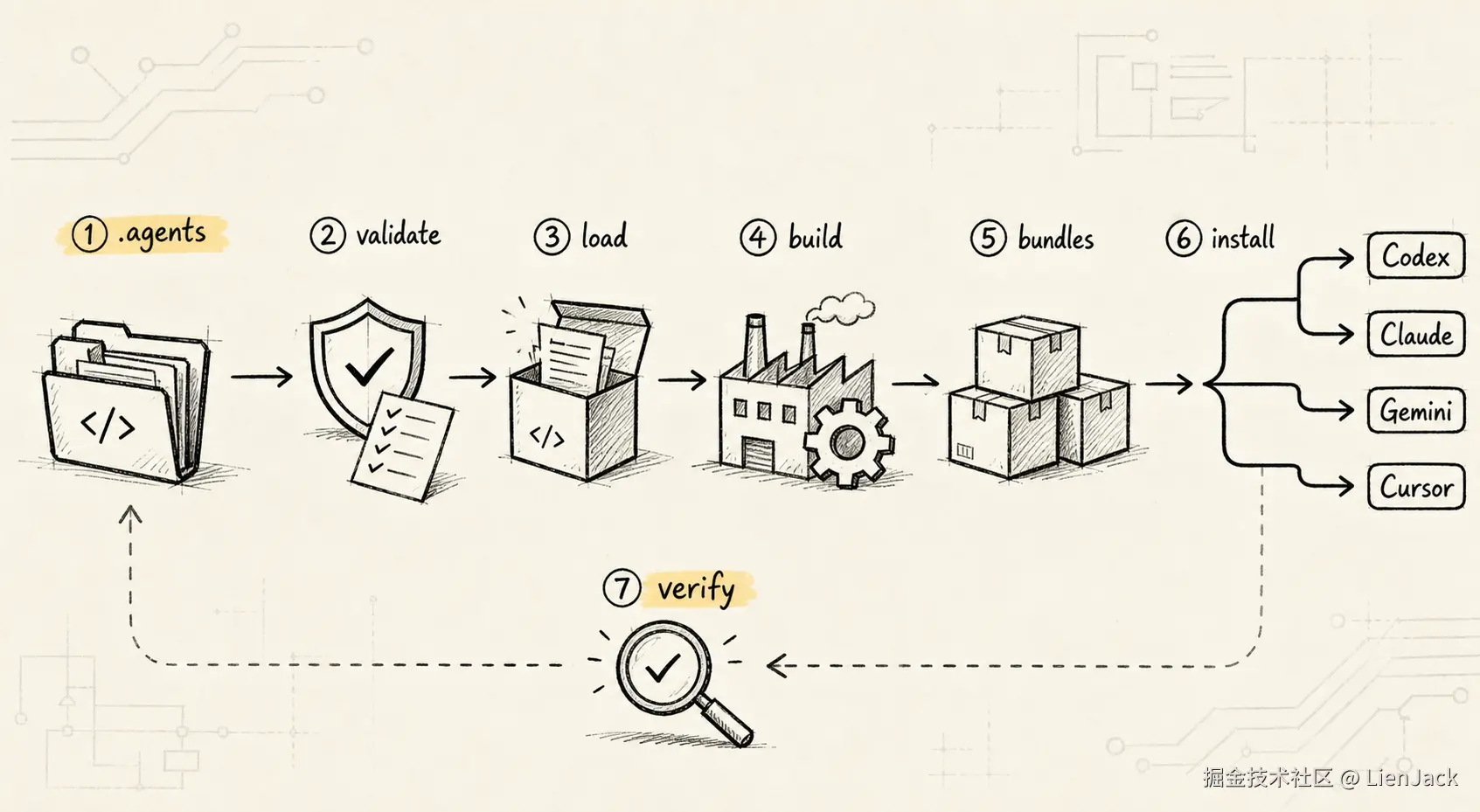
如果这个 Skill 只给自己用,可能确实就是写好文件,放到对应目录,结束。可一旦想让它在 Codex、Claude、Gemini、OpenCode、Pi、Kiro、Cursor 这些环境里都能安装和使用,它就会从"写一份提示词"变成"做一个多平台发行工具"。
这也是我实现过程中踩得最多的工程问题:同一套分析方法,怎么构建成不同平台能识别的包,怎么装到正确位置,怎么确认装完以后真的能被平台看见。
1. Skill 不只是提示词,还要工程化
arch-insight 不是一个复杂业务系统,更像一个"Skill 分发器 + Skill 本体"的组合。
整个项目有两条主线:
- Skill 主线:定义 AI 应该如何分析仓库。
- 工程主线:把这个 Skill 构建、发布、安装到不同 Agent 平台。
2. CLI 只做调度,平台差异放到后面
入口在 bin/arch-insight.js,实际调度在 src/cli/run.js。
runCli 解析命令,然后分发到几个核心动作:
build:从.agents构建平台包。install:从本地 bundle 安装。install-release/update/upgrade:从发布产物下载安装。release:构建发布清单和 bundle。
设计很直接,但边界很清楚:CLI 只做调度,不直接知道每个平台怎么生成 manifest,也不直接知道每个平台怎么安装。
src/cli/run.js 是控制层,不是平台知识层。
这个边界很重要。因为多平台发行真正麻烦的不是"多复制几份文件",而是每个平台都在问不同的问题:manifest 长什么样、入口文件叫什么、默认目录在哪里、装完以后平台能不能看见。
3. 构建层处理 manifest 差异
构建主流程在 src/build/build-bundles.js。
它先调用 validatePluginSource(sourceDir) 检查 .agents 是否完整,再用 loadPluginSource(sourceDir) 把 Skill、Runner、prompts、templates 读成统一结构,然后根据目标平台调用对应 builder。
关键映射:
js
const TARGET_BUILDERS = {
claude: buildClaudeBundle,
codex: buildCodexBundle,
gemini: buildGeminiBundle,
opencode: buildOpenCodeBundle,
pi: buildPiBundle,
kiro: buildKiroBundle,
cursor: buildCursorBundle
};这是项目的第一个核心抽象:target builder。
它把"平台差异"集中在 src/build/targets/*.js,不污染 Skill 本体。
Codex 需要 .codex-plugin/plugin.json,里面有 interface.displayName、capabilities、defaultPrompt 等字段;Claude 需要 .claude-plugin/plugin.json,还涉及本地 marketplace 注册;Gemini 使用 gemini-extension.json,并额外放入 GEMINI.md。OpenCode、Pi、Kiro、Cursor 又各有自己的插件或 skill 约定。
所以项目没有试图写一个"万能 manifest",而是用 src/build/targets/*.js 为每个平台生成自己的外壳。
同一个 Skill 内容,不同平台外壳。这是一种很实用的架构选择:领域内容保持稳定,平台包装单独变化。
别假装平台差异不存在,把差异收口到适配器里。
4. 安装层处理路径和可见性
构建完还不够。Skill 不是放进某个目录就一定可用。
安装主流程在 src/install/install-bundle.js,通过 TARGET_INSTALLERS 选择平台 installer,再通过 resolvePlatformInstall 决定默认安装路径。
不同平台路径差异很明显:
- Codex:
~/.codex/skills/arch-insight - Gemini:
~/.gemini/skills/arch-insight - OpenCode:
~/.config/opencode/skills/arch-insight - Cursor:
~/.cursor/plugins/local/arch-insight - Claude:
~/.claude/plugins/local/arch-insight
这是项目的第二个核心抽象:target installer。
builder 解决"包长什么样",installer 解决"放哪里、怎么让平台识别"。
更麻烦的是,"复制成功"不等于"平台可见"。
有些平台只要文件在目录里就行;有些平台需要重启;有些平台会出现同名 Skill 冲突;有些平台还要额外注册。
比如 Gemini installer 里有 detectGeminiVisibility,会调用 gemini skills list,检查是否存在 arch-insight、是否出现 Skill conflict detected,并返回 visibilityCheck。
这说明安装器不应该只做:
txt
copy files -> done更合理的是:
txt
copy files -> verify entrypoint -> detect visibility -> give failure hint一个给人用的安装器,最重要的不是永远成功,而是失败时知道下一步该干什么。
5. 发布层让安装可以跨机器复用
如果只支持本地安装,用户需要 clone 仓库、构建、再安装。对一个 Skill 来说,门槛太高。
所以项目还有发布主线:
src/release/build-release-artifacts.js:构建dist/bundles/<platform>和install-manifest.json。src/release/download-release-bundle.js:根据 manifest 下载对应平台 bundle,用 cache key 复用本地缓存。
发布层的价值在于,用户可以直接:
bash
npx arch-insight install-release不需要关心仓库内部怎么构建。
到这里,工程主流程就完整了。
实现不炫技,但有一个清晰的工程判断:
Skill 的内容和 Skill 的分发是两件事,应该解耦。
6. 交互安装、CI 安装和缓存是发行工具的细节
项目支持:
bash
npx arch-insight install-release也支持:
bash
npx arch-insight install-release --platform codex --platform claude前者适合人用,会进入多选交互;后者适合脚本或 CI。
但这带来一个细节:--json 模式下必须显式传 --platform,否则不能弹交互选择。这个约束在 src/cli/run.js 的 resolveTargetPlatforms 里处理。
这类小设计很容易被忽略,但它决定了工具是否适合自动化。
如果每次安装都重新下载,不仅慢,也容易被网络状态影响。
所以 downloadReleaseBundle 用 release URL、manifest version、platform 生成 cache key,并校验 bundle-index.json 的文件数量和 hash。
不是为了显得复杂,而是因为发布工具一旦给别人用,就要对"我到底装了什么"有基本可追溯性。
写到这里我才意识到:一个 Skill 真正产品化后,已经不只是 prompt 文件了。
它变成了:
txt
认知流程 + 文件规范 + 构建系统 + 安装器 + 发布机制 + 可见性诊断也就是说,AI 时代的"提示词工程",最后还是会长回软件工程。
四、哪些设计可以借鉴,哪些别急着复制
如果你也想写类似的 Skill,arch-insight 里有几件事值得借鉴。
可以借鉴:别把所有要求塞进一段提示词
我以前也会写那种很长的提示词:既要求它看目录,又要求它找主线,还要求它写得像文章,最后再补一句"请深入分析"。
这种写法的问题是,所有要求混在一起,AI 很容易不知道先做什么。
后来我改成拆步骤:先问清楚目标,再挑重点代码,再找主线,最后再写结果。
这比一上来丢一句"请深入分析架构"稳定得多。
可以借鉴:把平台差异放进 target adapter
如果你的 Skill 也要支持多个 Agent 平台,建议一开始就区分:
- source:唯一内容源。
- build target:生成平台包。
- install target:安装和验证。
- release:分发和缓存。
别为每个平台维护一份复制出来的 Skill 内容。短期省事,长期一定漂移。
可以借鉴:让 AI 明确证据等级
在分析文章里,我很喜欢区分:
- Fact:源码或文档直接支持。
- Inference:从多个事实推导出来。
- Pending Verification:当前证据不够,但值得保留。
这能让 AI 的语气更诚实,也让读者更容易判断哪些结论可以直接拿走。
不建议复制:一上来就做全平台支持
如果只是给自己用,先支持一个平台就够了。
多平台支持真正麻烦的不是写几个路径,而是:
- manifest 不同。
- 安装行为不同。
- 用户验证方式不同。
- 冲突诊断不同。
- 文档说明不同。
- 版本发布不同。
只有当你明确希望别人安装,或者自己在多个 Agent 环境之间切换时,多平台分发才值得做。
不建议复制:把静态分析当成架构真相
arch-insight 主要处理源码阅读和设计判断,但它不能替代运行时观测。
比如并发行为、真实数据流、性能瓶颈、生产环境故障路径,只靠静态代码不一定看得准。
所以它适合做设计参考、源码导览、架构文章,不适合直接当成生产审计结论。
五、AI 缺的不是聪明,是工作方法
我写 arch-insight 之后,对 AI Coding 有一个更强的感觉:
很多时候,AI 不是不会做,而是不知道你心里那套"好工作"的标准。
你让它"分析架构",它就用默认理解去分析。默认理解不一定差,但很可能不是你要的。
Skill 的意义,就是把你的标准写下来。
你希望它先定边界,就写进 Skill。 你希望它少复述目录树,就写进 Skill。 你希望它用源码路径支撑判断,就写进 Skill。 你希望它区分报告、长文和仓库导览,就写进 Skill。 你希望它每次都记得这些,而不是靠你现场提醒,也写进 Skill。
所以这篇文章的标题虽然有点开玩笑,说"AI 架构设计不太行",但更准确的说法可能是:
AI 不是天生不会做架构分析,只是它需要一套可执行的架构阅读训练。
而 arch-insight 就是我给它写的那套补课材料。
如果一个人类工程师可以通过 code review、复盘、架构文档逐渐形成判断力,那 AI 也可以通过 Skill,把一次次好的工作流沉淀成下一次的默认动作。
这件事真正有意思的地方不在于"我写了一个工具",而在于它暗示了一种新的工程习惯:
不只让 AI 帮我们写代码,也把我们读代码、判断设计、形成经验的方法,反过来工程化地教给 AI。
这可能才是 Agent Skill 最值得玩的地方。
最后
如果想了解更多,可以来我个人Blog,里面有Agent相关的文章,还有Claude Code源码解析。