目录
[2.1:NVIDIA GPU,先装 CUDA 版 torch:](#2.1:NVIDIA GPU,先装 CUDA 版 torch:)
[2.2:安装:transformers:HuggingFace 官方库](#2.2:安装:transformers:HuggingFace 官方库)
[三.Hugging Face 注册 + 模型下载配置](#三.Hugging Face 注册 + 模型下载配置)
[2、生成 Access Token](#2、生成 Access Token)
[3.点击 New token 新建令牌:](#3.点击 New token 新建令牌:)
[4.复制生成的 Token(一长串字符,类似 hf_xxxxxxx),先存好,等下要用](#4.复制生成的 Token(一长串字符,类似 hf_xxxxxxx),先存好,等下要用)
[1.打开你的 Anaconda Prompt,先激活你之前的虚拟环境:](#1.打开你的 Anaconda Prompt,先激活你之前的虚拟环境:)
[2.安装 Hugging Face CLI](#2.安装 Hugging Face CLI)
[五、transformers 库:跑通最简文本生成(调用现有模型)](#五、transformers 库:跑通最简文本生成(调用现有模型))
[六、本地跑通 轻量小 LLM(Qwen-1_8B-Chat)](#六、本地跑通 轻量小 LLM(Qwen-1_8B-Chat))
[七、模型加载 / 推理 / 本地缓存保存](#七、模型加载 / 推理 / 本地缓存保存)
[1. 模型自动缓存位置](#1. 模型自动缓存位置)
[2. 手动保存模型到本地](#2. 手动保存模型到本地)
[八、多轮上下文 AI 对话脚本](#八、多轮上下文 AI 对话脚本)
资料:
15分钟弄懂Token和Embedding -- 详解LLM与RAG的数据处理机制
一.统一前置安装
1.进入虚拟环境
2.安装torch和transformers
2.1:NVIDIA GPU,先装 CUDA 版 torch:
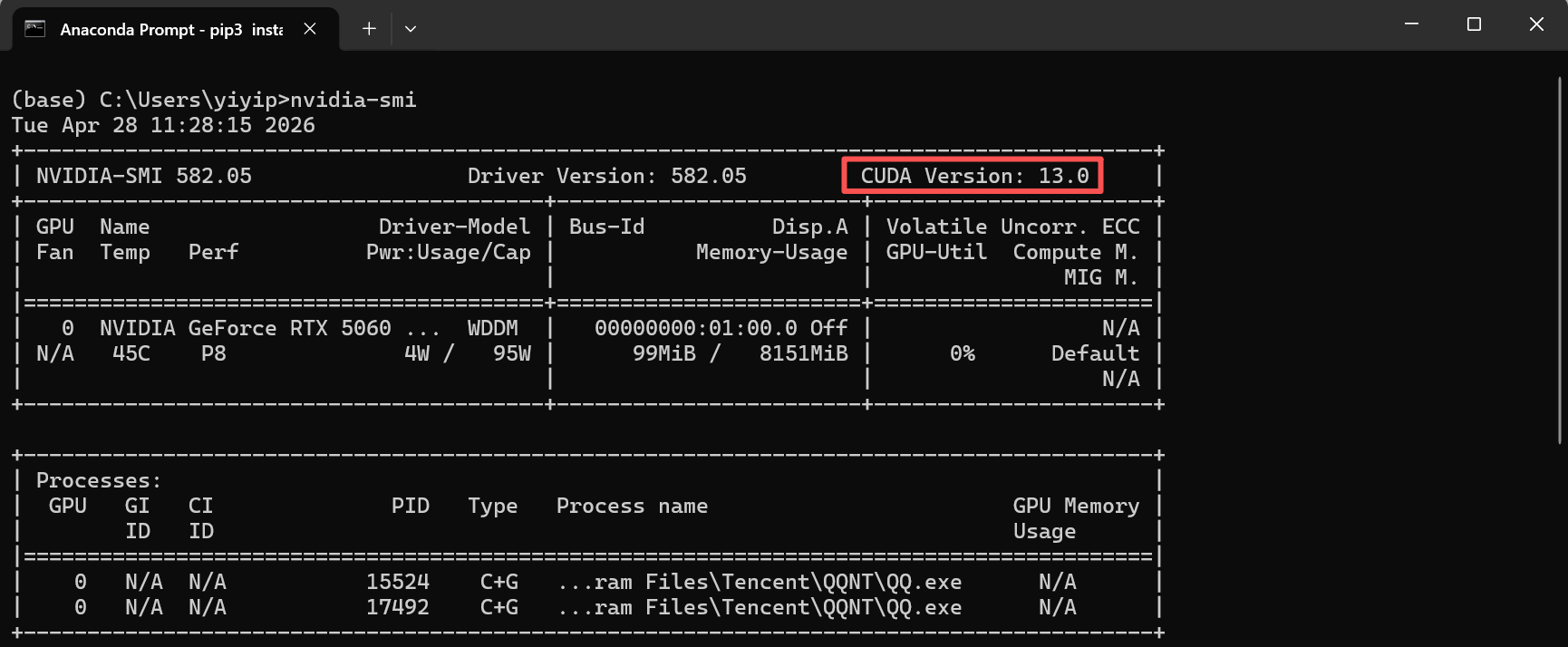
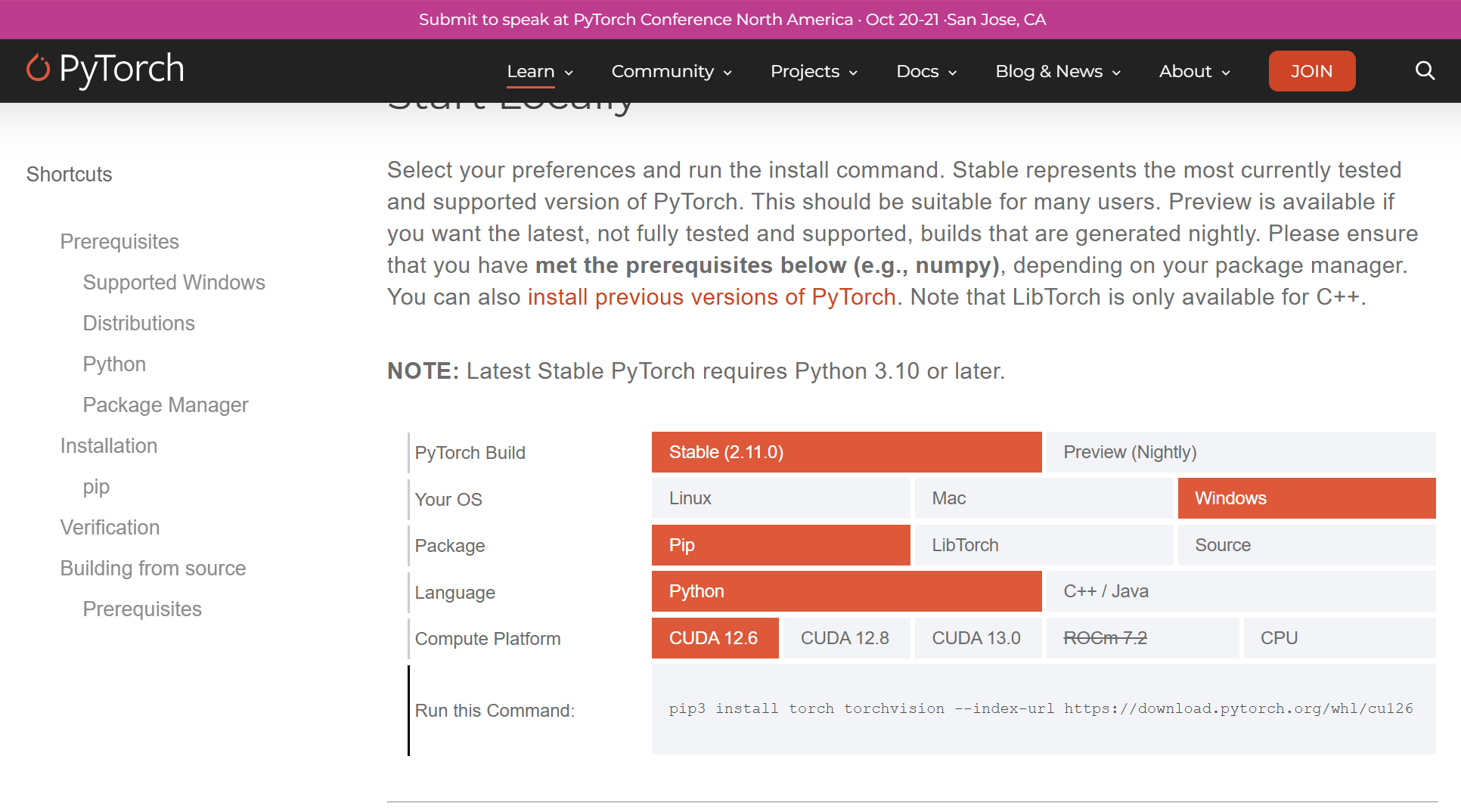
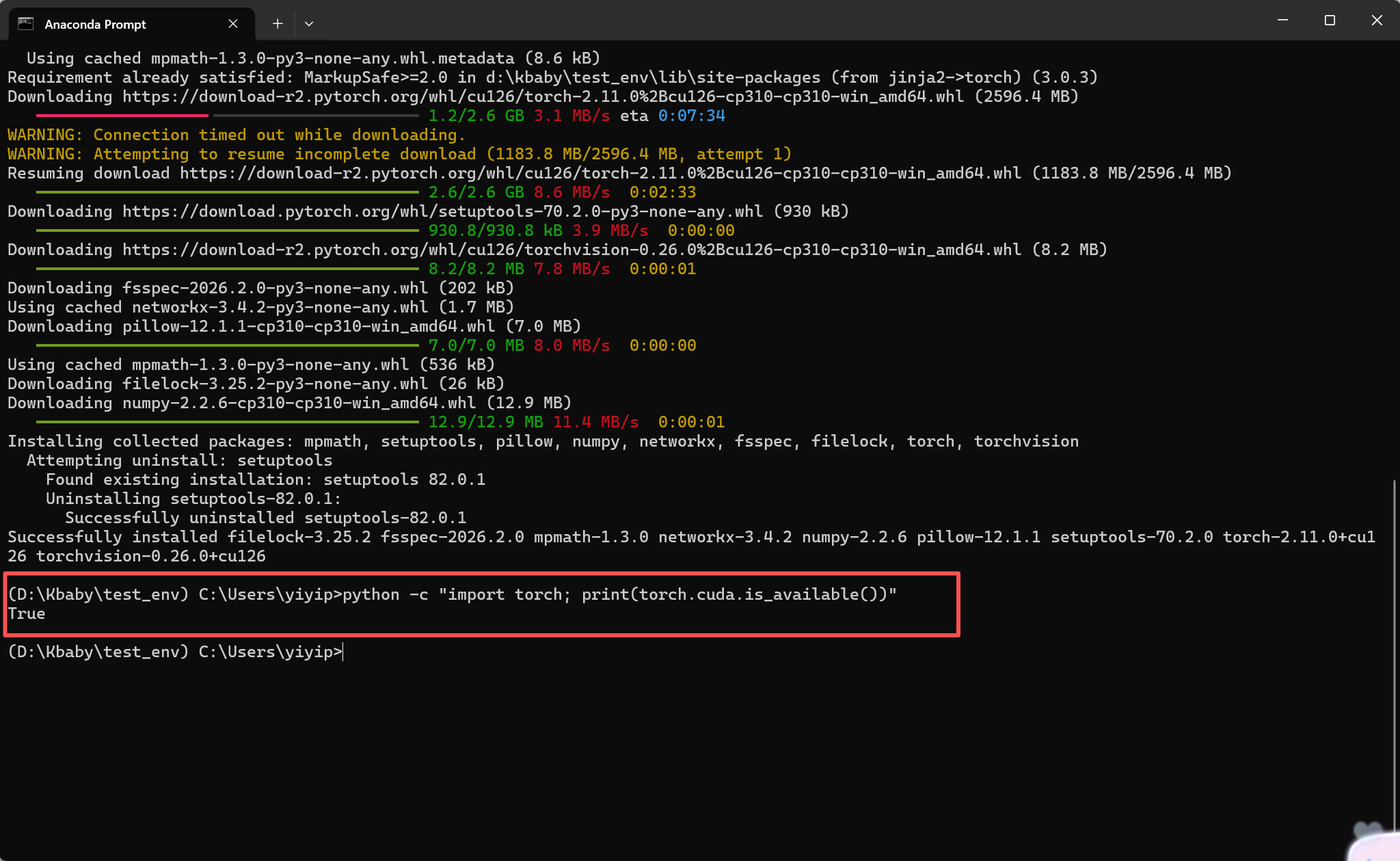
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu126安装完验证:
python -c "import torch; print(torch.cuda.is_available())"安装成功显示:
2.2:安装:transformers:HuggingFace 官方库
accelerate:加速模型加载、自动适配 CPU/GPU
sentencepiece:多语言分词
pip install transformers sentencepiece accelerate二.名词解释:
model :负责思考、计算、生成文字(神经网络权重)
Tokenizer 分词器 :负责把中文切成模型能看懂的符号 (词典、规则)。因为模型看不懂汉字 / 英文,需要先切成小 token→转数字 ID,才能输入模型。
**token:**一个个字词的编号
词表大小(Vocab Size):一个tokenizer认识所有的token数量,最小的词表是gpt-2
转化token的过程属于数据的预处理
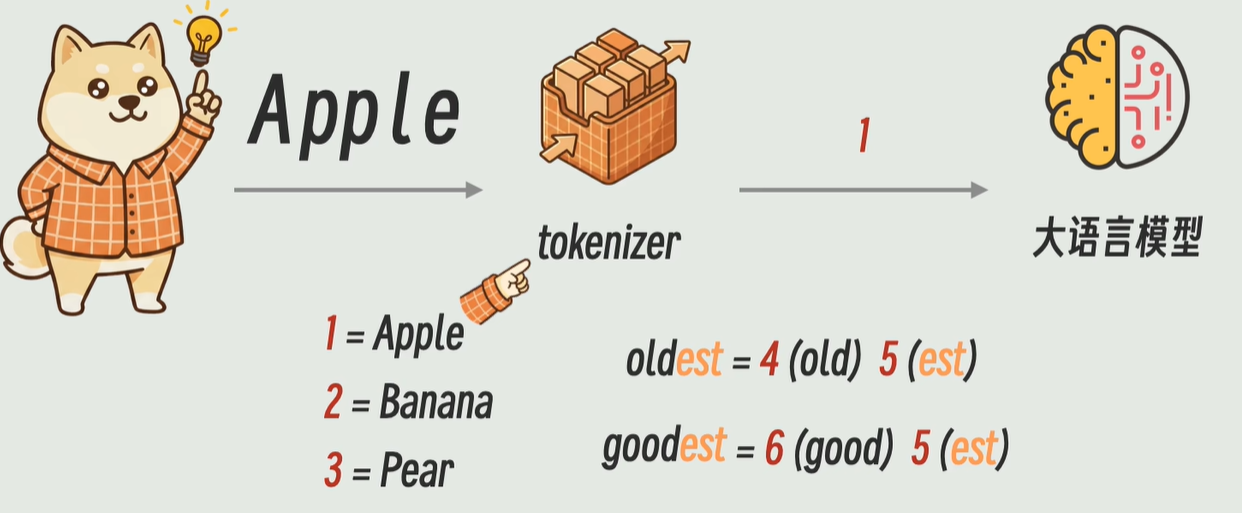
常见的tokenizer库有(内部算法不同,功能相同):OpenAI的tiktoken和谷歌的WordPiece
**Embedding 向量:**把文字→稠密数字向量,用来做:相似度对比、RAG 检索、语义匹配。是大语言模型的一部分。
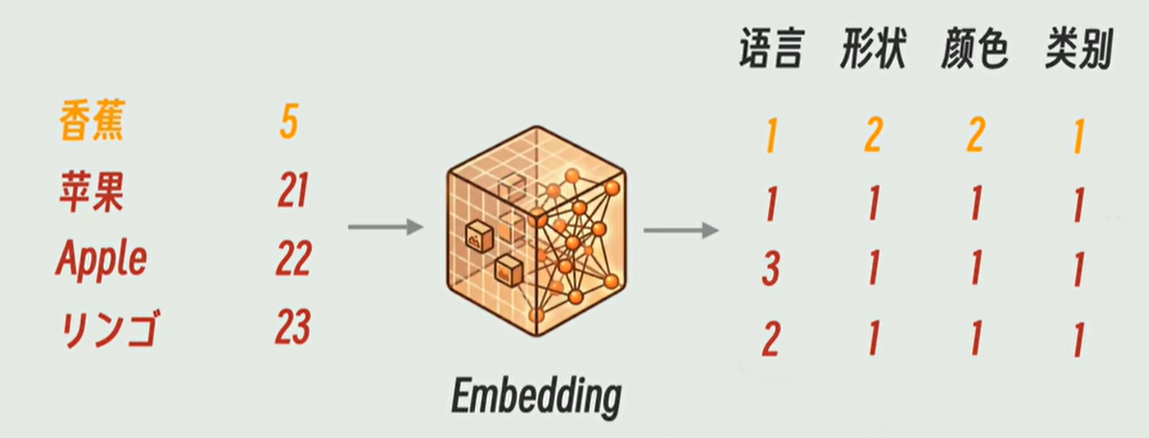
Ps:向量的每个数字的意思不是人工定义的
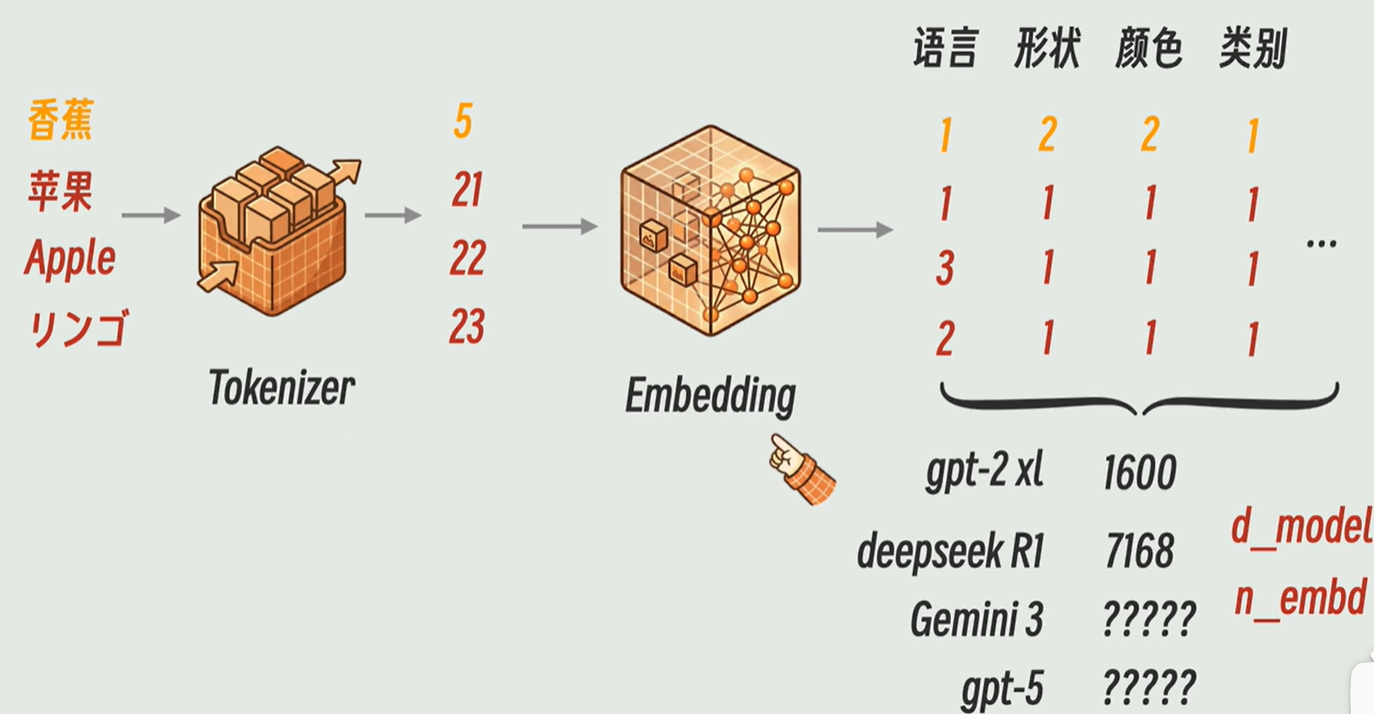
tokenizer:文字转化成token
Embedding:token转化成向量
LLM的Embedding与RAG的Embedding:
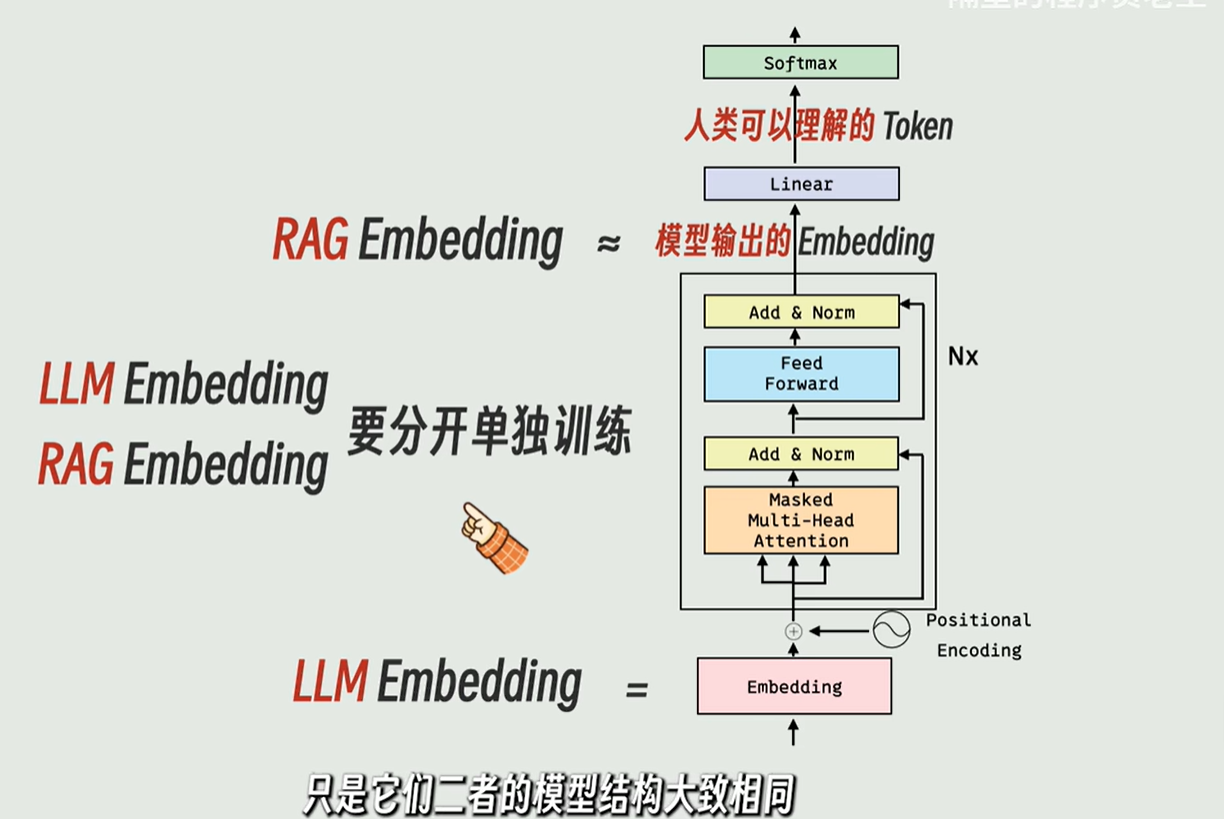
LLM模型和RAG模型:
- LLM模型:大语言模型,类似词语接龙
- RAG:检索增强生成,类似算命的
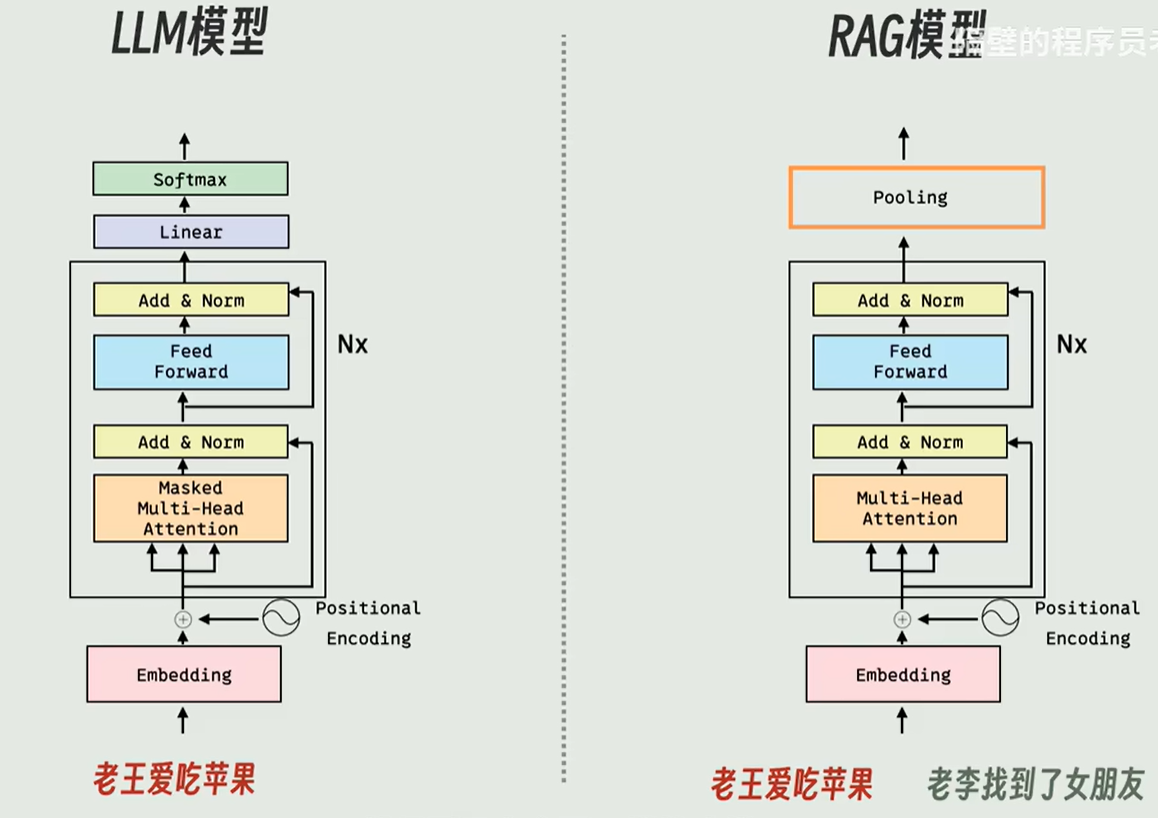
区别:
1.知识来源
LLM:靠训练背诵 RAG:实时检索外部资料
2.时效性
LLM:陈旧固定 RAG:随时更新
3.准确率
LLM:易幻觉 RAG:有据可依、更准
4.适用场景
LLM:通用对话、创作、简单推理 RAG:知识库问答、企业资料、最新资讯
总结:LLM 是 会说话的大脑,RAG 是给大脑配一本实时查阅的参考书。
三.Hugging Face 注册 + 模型下载配置
1、官网注册账号
浏览器,访问:
https://huggingface.co/join2、生成 Access Token
1.登录 Hugging Face 后,点击右上角你的头像 → 选择 Settings(设置)
2.在左侧菜单找到 Access Tokens(访问令牌),点进去
3.点击 New token 新建令牌:
- 给令牌起个名字(比如
first-token) - 权限选择:Read(只读)
- 点击 Generate token 生成
4.复制生成的 Token(一长串字符,类似 hf_xxxxxxx),先存好,等下要用
四、hf本地终端登录
1.打开你的 Anaconda Prompt,先激活你之前的虚拟环境:

2.安装 Hugging Face CLI
pip install huggingface_hub检查:
hf --version
3.执行登录,本地登录(终端执行)命令:
hf auth login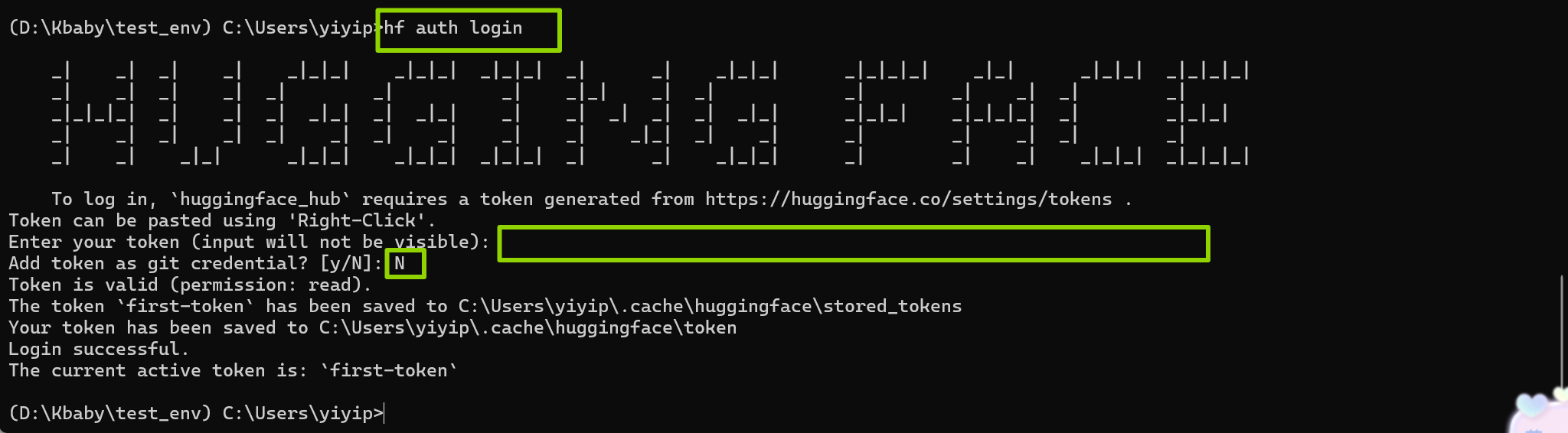
如果登录过了,显示:

五、transformers 库:跑通最简文本生成(调用现有模型)
调用推理模型distilgpt2:
python
from transformers import pipeline
#文本生成
generator =pipeline(
task="text-generation",
model="distilgpt2",
device=-1
)
# 简单推理
res=generator(
"人工智能未来发展是",
max_length=50,
do_sample=True
)
print(res[0]["generated_text"])
pipeline:HF 一键调用各类 AI 能力(文本生成、翻译、摘要), 官方通用接口(所有模型都能用)
device=-1:纯 CPU 运行
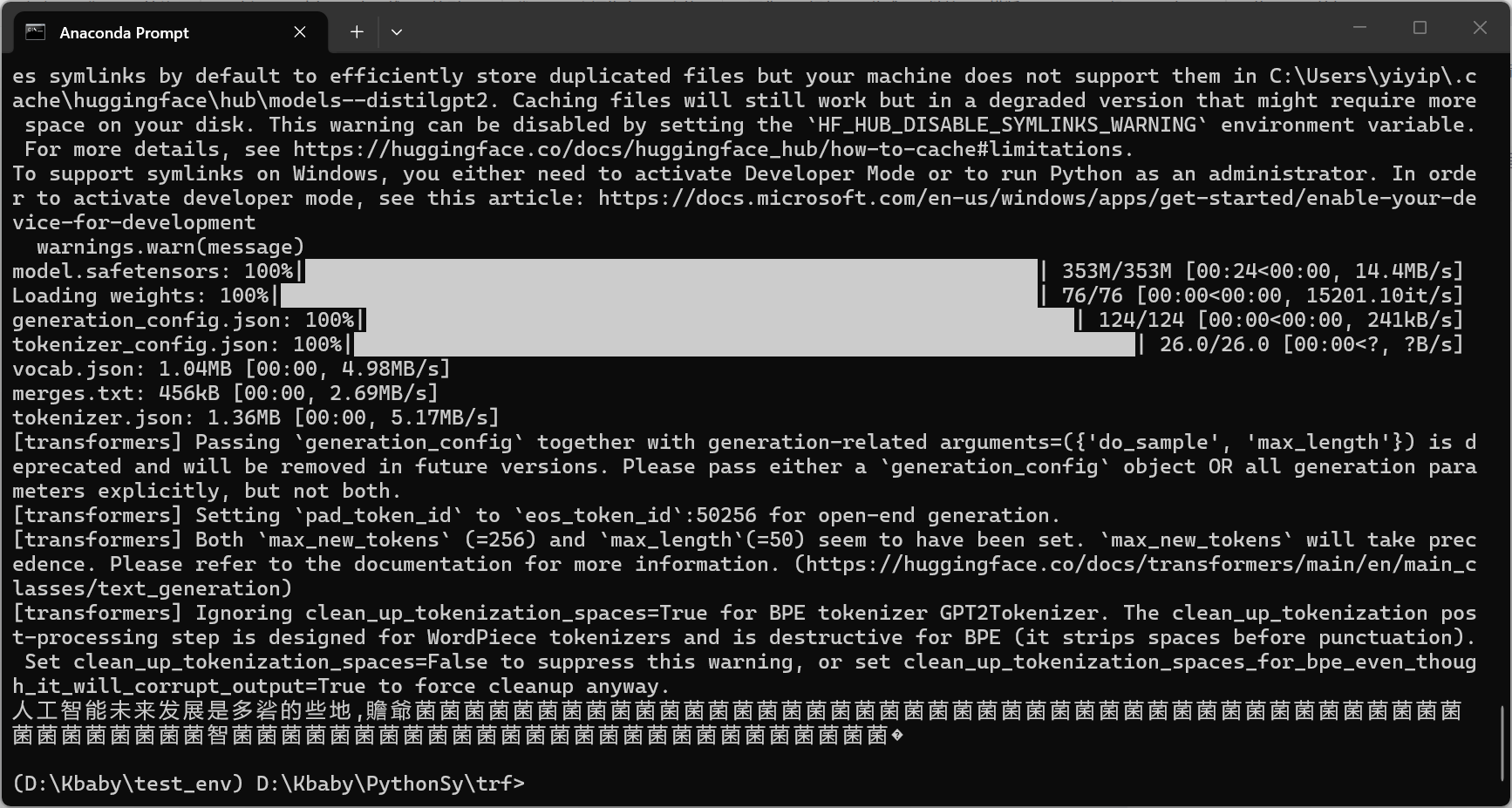
分析效果差的原因:
1.模型本身的局限性:
distilgpt2是 GPT-2 的轻量版,参数量只有 1.2 亿,是个非常基础的英文模型- 它没有经过中文训练,对中文理解和生成能力极差,只能随机拼字,所以会出现乱码、重复的 "菌菌菌";
- 它本身也不是为 "高质量续写" 设计的,哪怕是英文任务,也很容易生成无意义文本。
2.代码里的参数冲突 & 过时写法
- max_length=50 和默认的 max_new_tokens=256 冲突,max_new_tokens 会覆盖 max_length,但设置混乱会影响生成稳定性;
- generation_config 和 do_sample/max_length 混用,属于过时写法,新版本不推荐;
- 没有设置中文专用的参数,比如 pad_token_id,导致 tokenizer 处理中文时容易出问题。
3.采样参数没调好,生成太 "随机"
do_sample=True开启了随机采样,但你没控制temperature、top_k、top_p,默认参数对弱模型来说太 "放飞",容易生成无意义的重复字符;- 弱模型需要更 "保守" 的采样策略,才能减少乱码和重复。
4.环境和 tokenizer 的适配问题
环境和 tokenizer 的适配问题 GPT2 的 tokenizer 对中文支持很差,会把中文拆成零散的 token,模型很难学到连贯的中文语法,自然生成不出通顺的句子。
六、本地跑通 轻量小 LLM(Qwen-1_8B-Chat)
python
from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
model_name="Qwen/Qwen1.5-1.8B-Chat"
# 加载分词器+模型
# from_pretrained:从 HF 下载 / 加载本地模型
tokenizer=AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to("cpu")
# 构建文本生成pipeline
generator=pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
device=-1
)
#对话调用
prompt="简单介绍一下什么是猫"
response=generator(
prompt,
max_new_tokens=300,# 最大生成新token长度
temperature=0.7,# 随机性:越低回答越严谨,越高越有创意
top_p=0.9, # 核采样,控制生成多样性
do_sample=True# 随机采样模式
)
print("ai回答:",response[0]["generated_text"])成功运行 Qwen 小模型、本地输出问答结果。
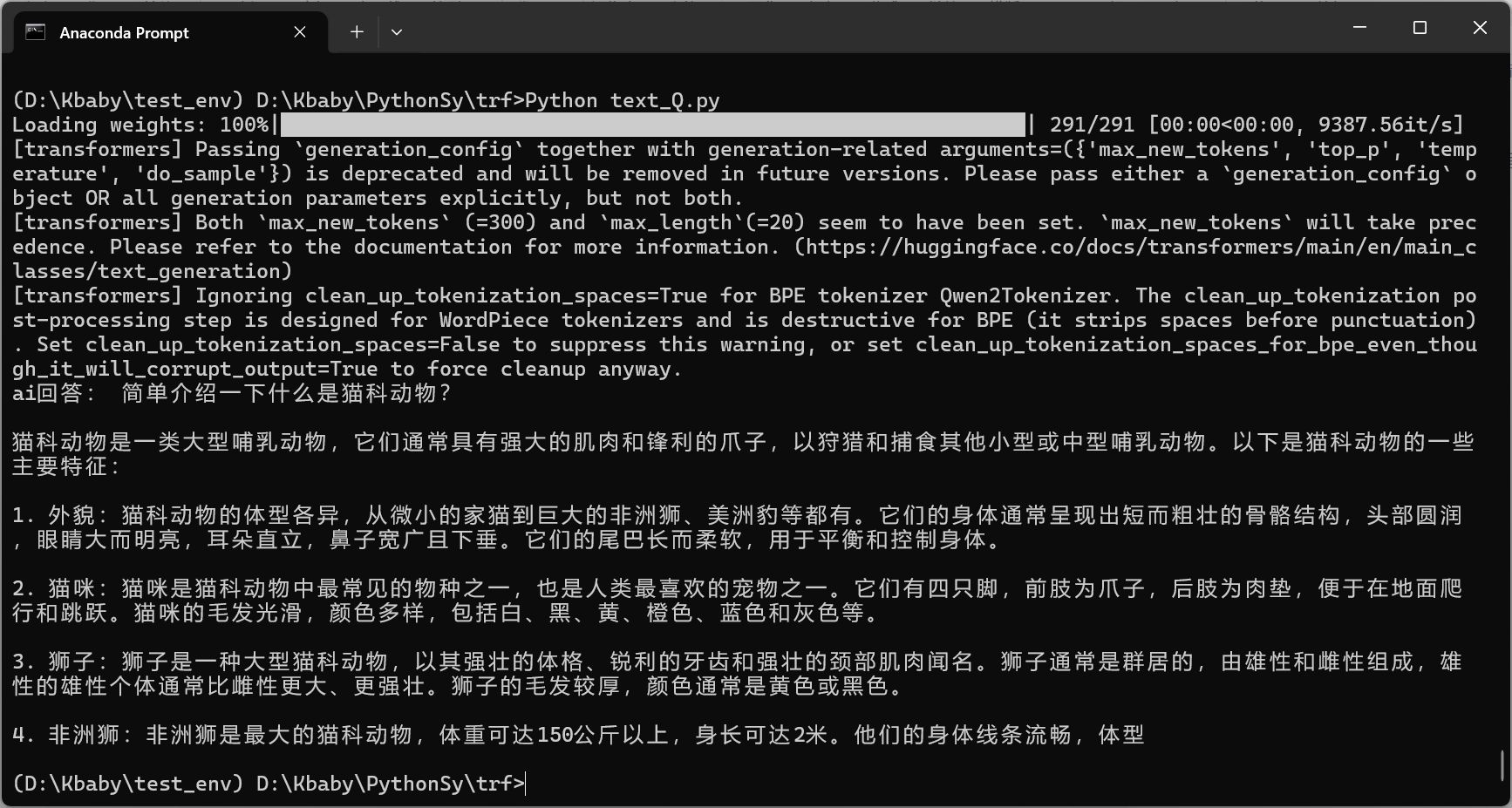
解释:
1.为什么会把 "猫" 变成 "猫科动物"?
Qwen1.5-1.8B-Chat 模型的正常 "语义扩展",模型理解的是 "介绍猫",但它的训练数据里 "猫" 和 "猫科动物" 是高度相关的概念,所以在生成时自动把话题扩展成了更宽泛的 "猫科动物"
2.pipeline("text-generation") 是做「文本续写」的,它的逻辑是:你给一段开头(prompt),模型在后面接着写下去。
3.do_sample
- do_sample=True启用随机采样,模型会根据词的概率分布随机选择下一个词,生成结果更流畅、多样、自然,但每次运行结果不同。
- do_sample=False禁用采样,使用贪心搜索,每次都选概率最大的词,生成结果固定、重复、不自然。
七、模型加载 / 推理 / 本地缓存保存
1. 模型自动缓存位置
下载一次后,下次不用重复下:
2. 手动保存模型到本地
python
# 保存到本地文件夹
# 保存模型:1.权重文件(.bin / .safetensors)2.模型配置
model.save_pretrained("./qwen-local-model")
# 保存分词器:1.词汇表2.分词规则3.特殊符号配置
tokenizer.save_pretrained("./qwen-local-model")
3.从本地离线加载(无网络也能用)
python
model = AutoModelForCausalLM.from_pretrained("./qwen-local-model", trust_remote_code=True)
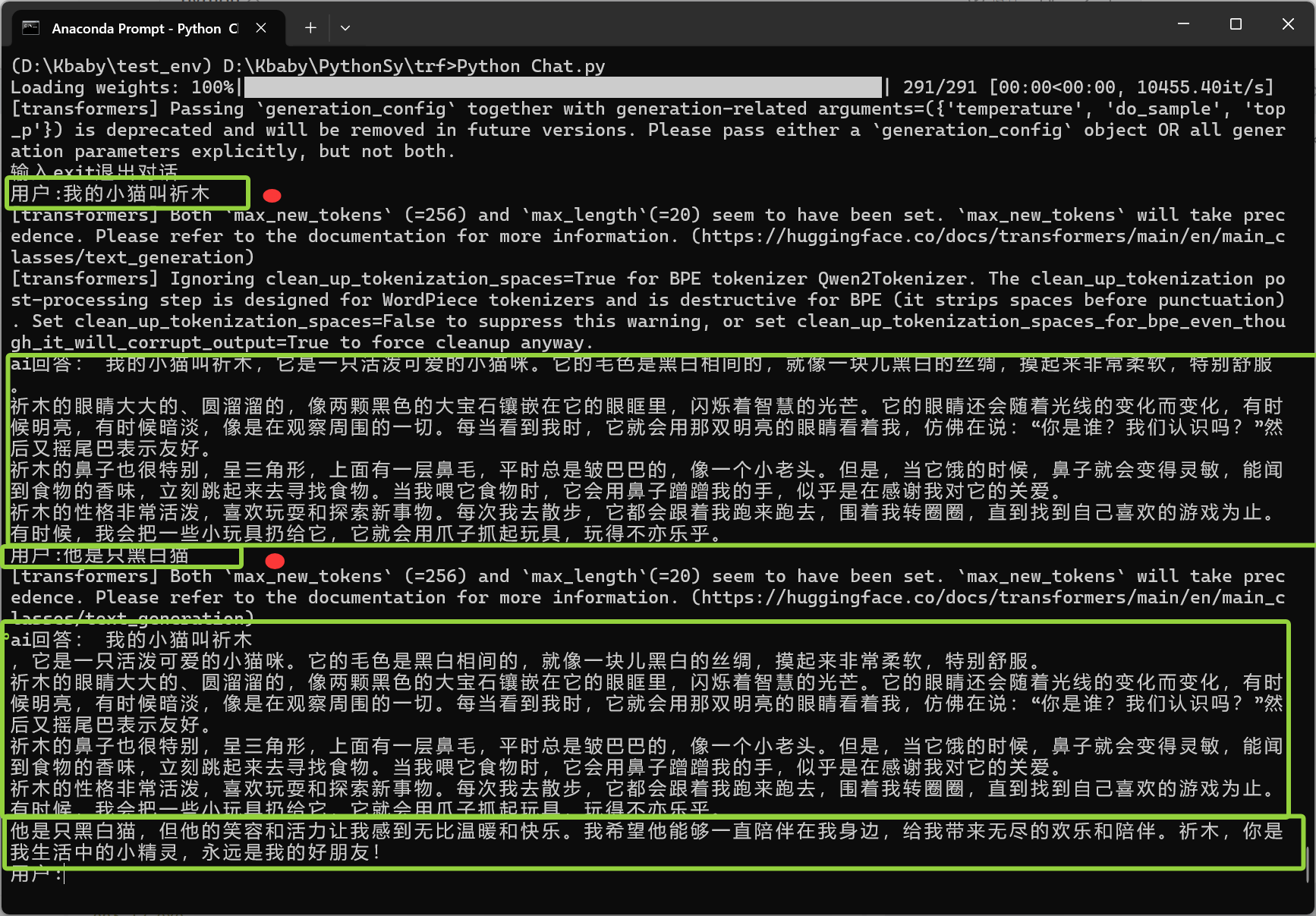
tokenizer = AutoTokenizer.from_pretrained("./qwen-local-model", trust_remote_code=True)八、多轮上下文 AI 对话脚本
python
from text_G import generator
from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
# 模型
model_name="Qwen/Qwen1.5-1.8B-Chat"
# 加载分词器+模型
tokenizer=AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to("cpu")
# 构建pipeline
generator=pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
device=-1,
temperature=0.7,
top_p=0.9,
do_sample=True
)
# 多轮对话
history = []
print("输入exit退出对话")
while True:
user_input=input("用户:")
if user_input=="exit":
break
# 把历史对话+当前问题 拼在一起
prompt = "\n".join(history) + "\n" + user_input
# 生成回答
output=generator(prompt)[0]["generated_text"]
# 输出完整内容
print("ai回答:",output.strip())
# 更新历史
history.append(user_input)
# 只存新生成的回答
history.append(output[len(prompt):])实现连续多轮聊天