文章目录
-
- [1 任务目标](#1 任务目标)
- [2 数据集介绍](#2 数据集介绍)
-
- [2.1 数据量](#2.1 数据量)
- [2.2 特征(Features)](#2.2 特征(Features))
- [2.3 标签(Target)](#2.3 标签(Target))
- [3 划分数据集](#3 划分数据集)
- [4 创建决策树模型和训练](#4 创建决策树模型和训练)
- [5 模型预测](#5 模型预测)
- [6 结果评估](#6 结果评估)
-
- [6.1 准确率](#6.1 准确率)
- [6.2 分类报告](#6.2 分类报告)
- [6.3 混淆矩阵](#6.3 混淆矩阵)
- [7 可视化](#7 可视化)
-
- [7.1 决策树可视化](#7.1 决策树可视化)
- [7.2 特征重要性分析](#7.2 特征重要性分析)
- 总结
1 任务目标
本文将以经典的鸢尾花(Iris)数据集为例,完整演示决策树分类算法的使用全流程。我们将从数据加载开始,逐步完成模型训练、预测、评估,并最终通过多种可视化手段深入理解决策树的决策过程与特征重要性。通过这个完整的案例,读者可以掌握如何应用决策树解决实际分类问题,并学会解读模型结果。
2 数据集介绍
我们使用的鸢尾花数据集是机器学习领域的经典入门数据集,可直接从 scikit-learn 库中加载:
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data # 特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
y = iris.target # 标签:0-山鸢尾, 1-变色鸢尾, 2-维吉尼亚鸢尾
feature_names = iris.feature_names # 特征名
target_names = iris.target_names # 标签名2.1 数据量
该数据集包含 150 个样本,均匀分布在 3 个类别中,每个类别恰好有 50 个样本,不存在类别不平衡问题。
2.2 特征(Features)
数据集包含 4 个数值型特征,单位均为厘米:
- 花萼长度(sepal length)
- 花萼宽度(sepal width)
- 花瓣长度(petal length)
- 花瓣宽度(petal width)
这些特征都是连续数值,由于决策树算法对特征尺度不敏感,通常不需要进行标准化处理。
2.3 标签(Target)
数据包含 3 种鸢尾花品种:
- 0:山鸢尾(Iris setosa)
- 1:变色鸢尾(Iris versicolor)
- 2:维吉尼亚鸢尾(Iris virginica)
3 划分数据集
为了评估模型性能,我们需要将数据划分为训练集和测试集。这里按照 7:3 的比例划分,并固定随机种子以确保结果可复现:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)参数说明:
test_size=0.3:测试集占 30%random_state=42:固定随机种子,确保每次划分结果一致stratify=y:按标签分层抽样,确保训练集和测试集中各类别比例与原始数据一致
4 创建决策树模型和训练
接下来我们创建决策树分类器并进行训练:
from sklearn.tree import DecisionTreeClassifier
# 创建决策树模型
print("\n=== 创建决策树模型 ===")
# 常用参数说明:
# - criterion: 分裂标准,'gini'(基尼系数) 或 'entropy'(信息增益)
# - max_depth: 树的最大深度,防止过拟合
# - min_samples_split: 节点最少样本数,小于此值则不分裂
# - min_samples_leaf: 叶节点最少样本数
# - random_state: 随机种子,确保结果可重复
dt_classifier = DecisionTreeClassifier(
criterion='gini', # 使用基尼系数作为分裂标准
max_depth=3, # 限制树深度为3,防止过拟合
min_samples_split=2, # 节点至少2个样本才分裂
min_samples_leaf=1, # 叶节点至少1个样本
random_state=42 # 确保结果可复现
)
# 训练模型
dt_classifier.fit(X_train, y_train)
print("模型训练完成!")5 模型预测
使用训练好的模型对测试集进行预测:
# 预测测试集
y_pred = dt_classifier.predict(X_test) # 预测类别标签
y_pred_proba = dt_classifier.predict_proba(X_test) # 预测每个类别的概率predict_proba 方法返回每个样本属于各个类别的概率,这在需要了解模型置信度时非常有用。
6 结果评估
6.1 准确率
首先计算模型在测试集上的整体准确率:
from sklearn import metrics
# 计算准确率
accuracy = metrics.accuracy_score(y_test, y_pred)
print(f"\n模型准确率: {accuracy:.4f}")6.2 分类报告
分类报告提供了更详细的性能评估,包括精确率、召回率和 F1 分数:
from sklearn.metrics import classification_report
# 生成分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=target_names))输出结果如下:
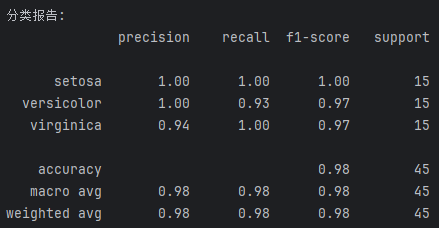
输出结果解读:
-
总体概览
- **样本总数 (support)**:测试集共有 45 个样本(3 个类别各 15 个)
- 准确率 (accuracy):0.98,模型在测试集上的预测正确率高达 98%,仅错了 1 个样本
-
各类别表现详解
-
**Setosa (山鸢尾)**:
- 表现完美,精确率、召回率、F1 分数均为 1.00
- 模型对这类花的识别毫无压力,15 个样本全部认对。这通常是因为 Setosa 的花瓣尺寸特征与其他两类差异极大,很容易区分
-
**Versicolor (变色鸢尾)**:
- 精确率 1.00:模型预测为 Versicolor 的样本,100% 真的是 Versicolor
- 召回率 0.93:在所有真实的 Versicolor 样本中,模型找出了 93%(14 个),漏掉了 1 个(错认成 Virginica)
- 模型非常确信自己的判断,极少"误杀",但漏判了一个同类样本
-
**Virginica (维吉尼亚鸢尾)**:
- 精确率 0.94:模型预测为 Virginica 的样本中,有 94% 是正确的
- 召回率 1.00:所有的真实 Virginica 样本都被找出来了
- 模型没有漏掉任何一个 Virginica,但为了不漏掉它们,稍微多猜了几个(导致误报率略高)
-
-
平均指标
- **Macro avg (宏平均)**:0.98,不考虑样本数量,直接对三个类别的指标求平均
- **Weighted avg (加权平均)**:0.98,考虑了每个类别的样本数量后的平均值
6.3 混淆矩阵
混淆矩阵直观展示了模型的分类情况:
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 可视化混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=target_names, yticklabels=target_names)
plt.title('混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.tight_layout()
plt.show()混淆矩阵打印如下:
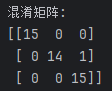
混淆矩阵解读:
-
矩阵结构解析
- 行代表真实类别 ,列代表预测类别
- 对角线:预测正确的样本(数值越大越好)
- 非对角线:预测错误的样本(数值越小越好)
-
详细解读
- **第一行 (Setosa)**:
[15, 0, 0],15 个真实的 Setosa 样本全部正确预测 - **第二行 (Versicolor)**:
[0, 14, 1],14 个正确预测,1 个被错误预测为 Virginica - **第三行 (Virginica)**:
[0, 0, 15],15 个真实的 Virginica 样本全部正确预测
- **第一行 (Setosa)**:
关键发现:唯一的错误发生在 1 个 Versicolor 样本被误判为 Virginica,这通常是因为这两类花在某些特征上比较接近。
7 可视化
7.1 决策树可视化
决策树最大的优势之一是模型可解释性强,我们可以直接可视化决策过程:
from sklearn.tree import plot_tree
# 可视化决策树
print("\n=== 决策树结构可视化 ===")
plt.figure(figsize=(12, 8))
plot_tree(
dt_classifier,
feature_names=feature_names,
class_names=target_names,
filled=True, # 用颜色填充节点
rounded=True, # 圆角节点
proportion=True # 显示样本比例而非具体数量
)
plt.title("决策树结构可视化", fontsize=16, pad=20)
plt.tight_layout()
plt.show()决策树显示如下:
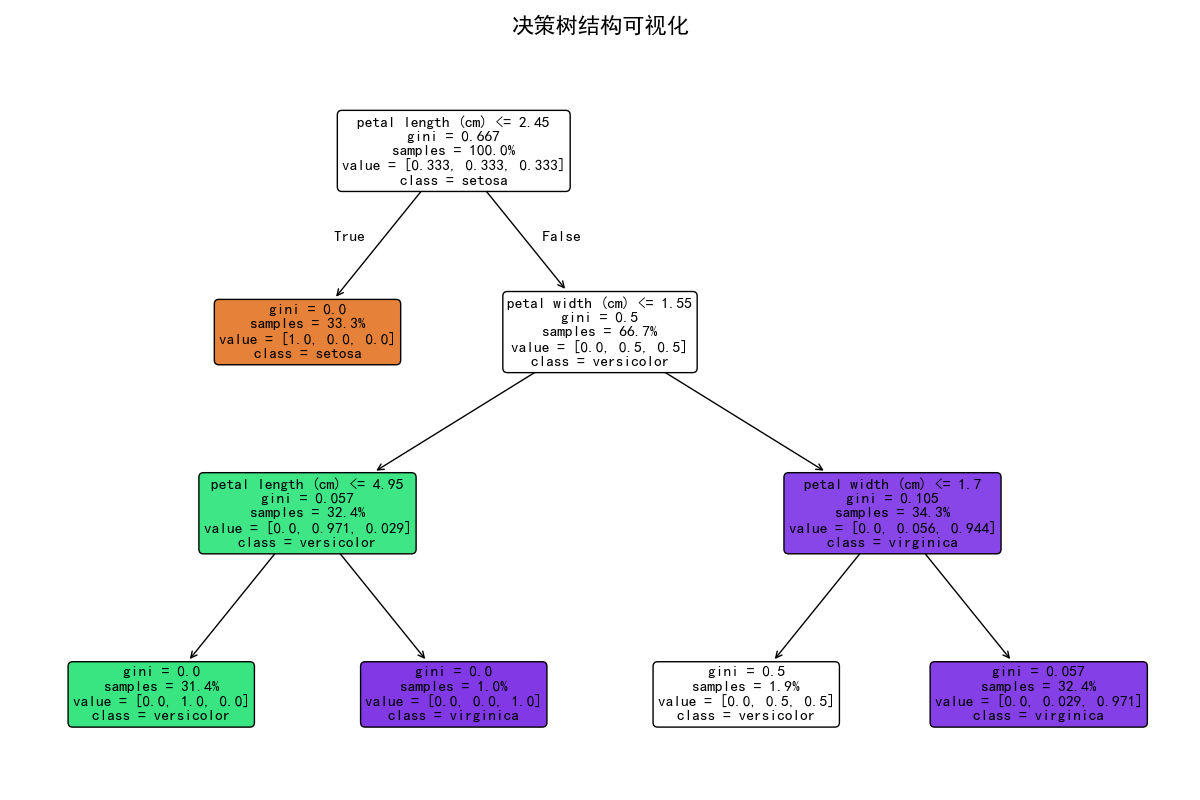
决策树结构解读:
-
**第一层关卡(根节点)**:
- 判断条件:花瓣长度 ≤ 2.45
- 如果满足,直接判定为 Setosa,这部分分类完全准确
-
第二层关卡:
- 如果花瓣长度 > 2.45,进入下一层判断:花瓣宽度 ≤ 1.55
- 这里出现了分类的关键节点:大部分样本被正确分类,但有一个 Versicolor 样本因为花瓣宽度较大(>1.55)被误判为 Virginica
-
底层节点:
- 紫色区域(右侧路径)主要为 Virginica
- 绿色区域(左侧路径)主要为 Versicolor
- 节点颜色深度表示类别的纯度,颜色越深表示该节点中某一类别占比越高
核心发现 :模型主要依靠花瓣长度 和花瓣宽度做决策。误判的根源在于部分 Versicolor 的花瓣宽度较大,超过了 1.55 的阈值,导致模型将其与 Virginica 混淆。
7.2 特征重要性分析
决策树可以计算每个特征在决策中的重要性:
import pandas as pd
import numpy as np
print("\n=== 特征重要性分析 ===")
# 计算特征重要性
feature_importance = pd.DataFrame({
'feature': feature_names,
'importance': dt_classifier.feature_importances_
}).sort_values('importance', ascending=False)
print("特征重要性排序:")
print(feature_importance)
print()
# 可视化特征重要性
plt.figure(figsize=(8, 5))
plt.barh(range(len(feature_importance)), feature_importance['importance'])
plt.yticks(range(len(feature_importance)), feature_importance['feature'])
plt.xlabel('特征重要性')
plt.title('决策树特征重要性分析')
plt.tight_layout()
plt.show()显示结果如下:
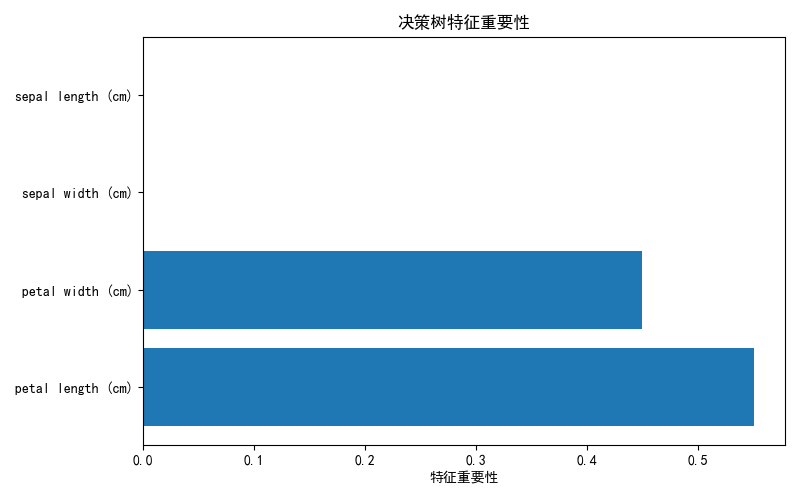
特征重要性解读:
-
花瓣特征是核心
- 花瓣长度重要性最高(超过 0.5),是区分鸢尾花类别的最关键特征
- 花瓣宽度重要性次之,是第二重要的判断依据
- 两者合计重要性接近 1.0,说明模型几乎完全依赖花瓣特征做决策
-
花萼特征几乎无用
- 花萼长度 和花萼宽度的重要性极低,接近 0
- 模型自动忽略了这些特征,说明在区分这三类鸢尾花时,花萼尺寸提供的判别信息很少
生物学启示:这一发现与植物学知识一致------同一属不同种的鸢尾花,其花瓣形态差异往往比花萼形态差异更显著,更能反映物种特性。
总结
通过本次实践,我们完成了从数据加载到模型评估的完整机器学习流程,并利用决策树的可解释性优势深入分析了模型的决策过程。关键发现包括:
- 决策树在鸢尾花数据集上表现优异,达到 98% 的准确率
- 可视化显示模型主要依赖花瓣长度和宽度做决策
- 唯一的误判源于 Versicolor 和 Virginica 在花瓣特征上的相似性
- 特征重要性分析证实花瓣特征是区分三类鸢尾花的关键
决策树算法的优势在于模型直观、易于解释,特别适合特征重要性分析和决策过程可视化。在实际应用中,我们可以通过调整树深度、最小样本数等参数来平衡模型复杂度与泛化能力。