前面文章我们介绍了向量数据库,Text2SQL查询MySQL的知识内容。了解了在RAG系统中会存在多个不同的数据库。那么问题来了,用户提出问题,什么问题会去检索向量数据库的内容,什么问题会Text2SQL 查询MySQL数据库的信息呢,又或者用户提出的问题是否两个数据库都要检索查询呢。这就引出了本文所要分享的内容,查询前处理。
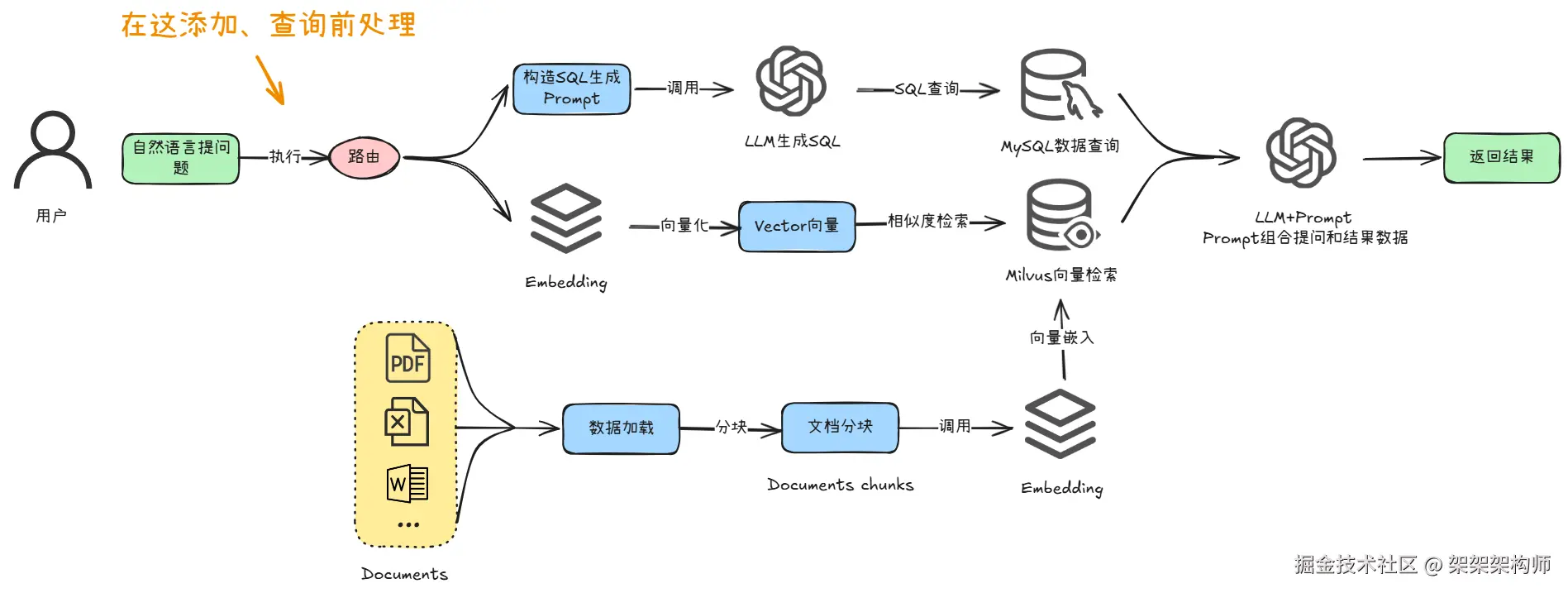
查询前处理是在用户提问之后,RAG系统去做检索查询之前做的事情。为了系统能够给出最精确的回答,需要在查询的过程做些优化。其实就是调用LLM模型将用户提出的问题处理一遍,再进行下一步动作。以下是查询前处理的一些思路。
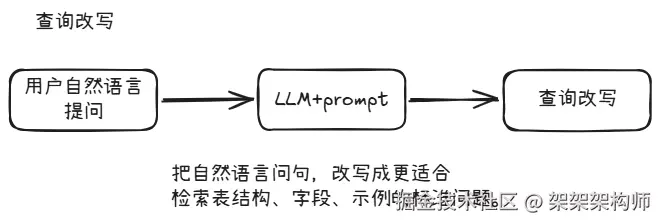
查询改写
在用户提出问题后,调用LLM大模型看下问题描述是否清晰。如果问题描述不清晰让LLM大模型对问题进行改写,改写成更适合检索表结构、字段、示例的标准问题。
比如提问:今年一二月大概赚了多少钱,各项收入和纯利润分别是多少呀?
改写后:今年1月至2月的净利润和各项收入明细是多少?
流程图
代码样例
ini
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv()
# 配置你的大模型API
API_KEY = os.getenv("R_PROXY_AI_API_KEY")
BASE_URL = os.getenv("R_PROXY_AI_BASE_URL")
MODEL = os.getenv("MODEL")
# DeepSeek、openAI都可以
client = OpenAI(
base_url=BASE_URL,
api_key=API_KEY
)
def finance_rewrite_query(question: str) -> str:
"""财务业务专用:用户口语问题清洗重写"""
prompt = """你是财务数据分析助手,对用户的财务问题进行重写优化。
规则:
1. 去掉无关闲聊、个人感慨、语气助词、废话
2. 替换为标准财务术语:净利润、主营业务收入、应收账款、应付账款、管理费用、资产负债等
3. 保留原始查询核心意图:时间、维度、统计诉求
4. 把模糊口语改成精准可查询的问句
只返回重写后的问题,不要任何解释、不要多余文字。
原始问题:{question}
"""
response = client.chat.completions.create(
model= MODEL,
messages=[{"role": "user", "content": prompt.format(question=question)}],
temperature=0
)
return response.choices[0].message.content.strip()
# 测试(财务口语问题)
if __name__ == "__main__":
raw_q = "今年一二月大概赚了多少钱,各项收入和纯利润分别是多少呀?"
print("原始问题:", raw_q)
print("重写后:", finance_rewrite_query(raw_q))查询拆分
在用户提出问题后,调用LLM大模型将问题拆分成几个小问题,系统对每个小问题进行检索查询。
流程图

代码样例
ini
from openai import OpenAI
import os
import logging
from dotenv import load_dotenv
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever
# 加载环境
load_dotenv()
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# ===================== 你的 LLM 配置 =====================
API_KEY = os.getenv("R_PROXY_AI_API_KEY")
BASE_URL = os.getenv("R_PROXY_AI_BASE_URL")
MODEL = os.getenv("MODEL")
llm = OpenAI(
base_url=BASE_URL,
api_key=API_KEY,
default_headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
)
# ===================== 1. 加载财务知识库文档 =====================
# 你可以换成你的财务制度/报销规则文档
loader = TextLoader("你的财务知识库.txt", encoding='utf-8')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
splits = text_splitter.split_documents(data)
# 向量库
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=splits, embedding=embed_model)
# ===================== 2. 多问题检索器(自动拆分问题) =====================
from langchain_openai import ChatOpenAI
# 包装成 LangChain LLM(必须这一步,才能用 MultiQueryRetriever)
langchain_llm = ChatOpenAI(
base_url=BASE_URL,
api_key=API_KEY,
model=MODEL,
temperature=0
)
# 核心:自动把用户问题拆成多个子问题 + 自动检索
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(search_kwargs={"k": 3}),
llm=langchain_llm
)
# ===================== 3. 测试:财务复杂问题 =====================
if __name__ == "__main__":
# 你的复杂问题(包含多个诉求)
raw_query = """今年一二月大概赚了多少钱,各项收入和纯利润分别是多少呀?"""
print("原始问题:", raw_query)
print("=" * 80)
# 自动拆分 + 自动检索
docs = multi_query_retriever.invoke(raw_query)
print("最终检索到的文档:")
for idx, doc in enumerate(docs):
print(f"\n【文档 {idx+1}】")
print(doc.page_content)生成HyDE假设性文档
在用户提出问题后,调用LLM大模型把问题回答一遍,生成假设性文档**HyDE (Hypothetical Document Embeddings)** ,再把这篇HyDE文档做向量,去 Milvus 做相似度检索。
流程图

代码案例
ini
# ======================== 财务场景 HyDE 实现 ========================
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
from dotenv import load_dotenv
import os
# 加载环境变量
load_dotenv()
API_KEY = os.getenv("R_PROXY_AI_API_KEY")
BASE_URL = os.getenv("R_PROXY_AI_BASE_URL")
MODEL = os.getenv("MODEL")
# ===================== 1. 初始化 LLM =====================
llm = ChatOpenAI(
base_url=BASE_URL,
api_key=API_KEY,
model=MODEL,
temperature=0
)
# ===================== 2. 财务知识库向量库(你已有的) =====================
# 这里你可以继续用你的财务制度/报销文档
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma(
embedding_function=embed_model,
persist_directory="./chroma_db" # 你已有的向量库
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# ===================== 3. 【财务专用】HyDE 假设文档生成模板 =====================
hyde_template = """你是一位专业的财务分析师,请根据以下财务问题,撰写一段专业、详细、结构完整的假设性财务分析文档。
不需要真实数据,只需模拟正式的财务报告内容,用于文档检索。
问题:{question}
财务分析文档:
"""
hyde_prompt = ChatPromptTemplate.from_template(hyde_template)
# 构建 HyDE 文档生成链
hyde_chain = hyde_prompt | llm | StrOutputParser()
# ===================== 4. 测试:你的财务问题 =====================
if __name__ == "__main__":
# 你的真实业务问题
question = "今年一二月大概赚了多少钱,各项收入和纯利润分别是多少呀?"
print("原始问题:")
print(question)
print("=" * 80)
# --------------------- ① 生成 HyDE 假设文档 ---------------------
hyde_doc = hyde_chain.invoke({"question": question})
print("生成的 HyDE 假设性财务文档:")
print(hyde_doc)
print("=" * 80)
# --------------------- ② 用 HyDE 文档去检索真实知识库 ---------------------
retrieved_docs = retriever.invoke(hyde_doc)
print("根据 HyDE 文档检索到的财务知识:")
for i, doc in enumerate(retrieved_docs, 1):
print(f"\n检索文档 {i}:")
print(doc.page_content)
print("=" * 80)
# --------------------- ③ 最终生成答案 ---------------------
answer_prompt = ChatPromptTemplate.from_template("""
你是专业财务助手,请根据检索到的财务资料,准确回答用户问题。
资料:
{context}
用户问题:{question}
请给出专业、简洁、清晰的回答:
""")
final_chain = answer_prompt | llm | StrOutputParser()
final_answer = final_chain.invoke({
"context": retrieved_docs,
"question": question
})
print("最终财务回答:")
print(final_answer)查询路由
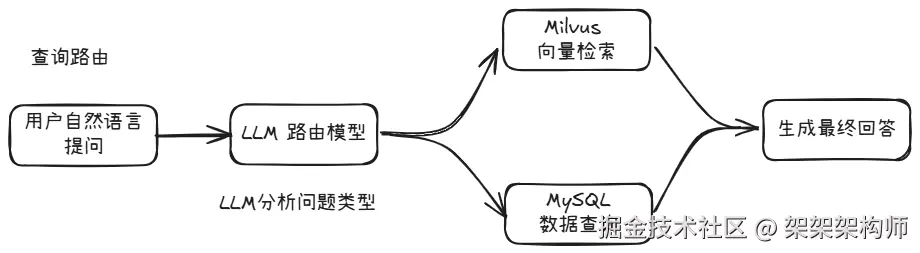
按问题领域分到不同的数据库,比如统计类问题查询MySQL 数据,语义相关问题检索Milvus向量数据库数据。调用LLM模型分析问题走哪个数据库,进而进行相对应数据库的查询。
流程图
代码样例
ini
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
import json
# ===================== 加载环境 =====================
load_dotenv()
API_KEY = os.getenv("R_PROXY_AI_API_KEY")
BASE_URL = os.getenv("R_PROXY_AI_BASE_URL")
MODEL = os.getenv("MODEL")
# ===================== LLM =====================
llm = ChatOpenAI(
base_url=BASE_URL,
api_key=API_KEY,
model=MODEL,
temperature=0
)
# ===================== 路由提示词=====================
system_prompt = """
你是专业财务数据路由专家,只按规则判断,输出纯JSON,不要其他内容。
规则:
1)统计、数值、收入、利润、金额、报表 → "mysql"
2)制度、报销、流程、规则、政策、定义 → "milvus"
输出格式:
{{"datasource": "mysql"}} 或 {{"datasource": "milvus"}}
"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{question}")
])
# 构建路由链
route_chain = prompt | llm
# ===================== 执行路由 =====================
def finance_route_question(question: str) -> str:
response = route_chain.invoke({"question": question})
result = json.loads(response.content.strip())
return result["datasource"]
# ===================== 测试 =====================
if __name__ == "__main__":
q1 = "今年一二月收入和净利润是多少?"
q2 = "财务报销流程是什么?"
print("问题1:", q1)
print("路由结果:", finance_route_question(q1))
print("-" * 50)
print("问题2:", q2)
print("路由结果:", finance_route_question(q2))总结
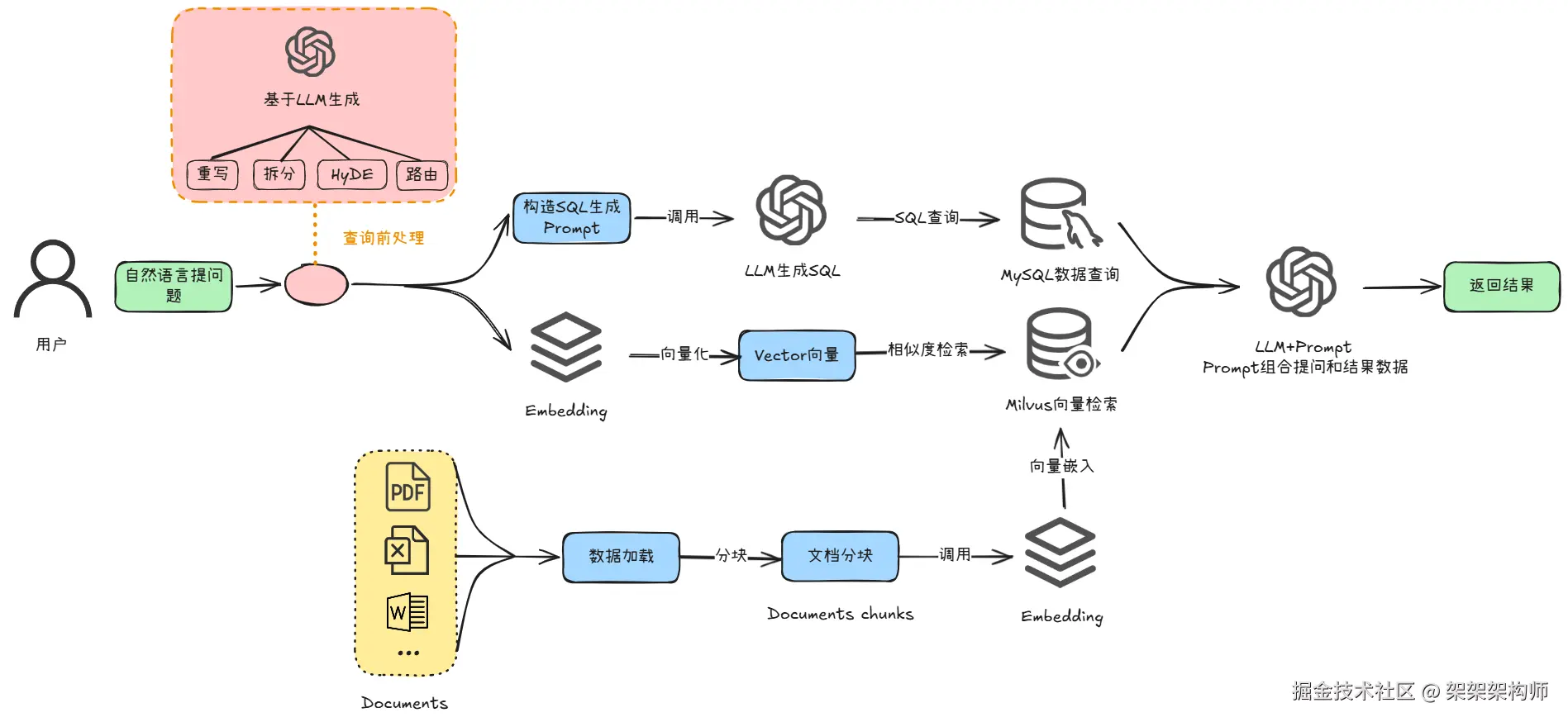
查询前处理的目的,是为了让我们RAG系统能够给出最精确的回答!