2026 .NET 面试八股文:高频题 + 答案 + 原理(高级核心篇)
前言
2026年.NET生态持续升温,.NET 10正式普及、Native AOT成为企业选型核心、AI集成与云原生落地加速,面试考察重点也从基础语法转向「原理 + 实战 + 性能」三维考核。
本文整理了2026年.NET/C#面试高频题(覆盖初级 → 中级 → 高级),每道题均包含「高频提问场景 + 标准答案 + 底层原理 + 避坑提示」,拒绝无效背诵,帮你吃透核心逻辑,从容应对面试。
高级核心篇(资深/架构师必问,考察底层与实战)
核心考点:
GC垃圾回收、Native AOT、微服务、分布式,是资深开发/架构师的考察重点,重点考察「底层原理 + 实战落地能力」。
1. 高频题:.NET GC(垃圾回收)的原理是什么?分代回收的机制是什么?
提问场景:
资深开发/架构师必问,常追问「内存泄漏排查 」「GC调优」。
标准答案
(1)GC 核心原理
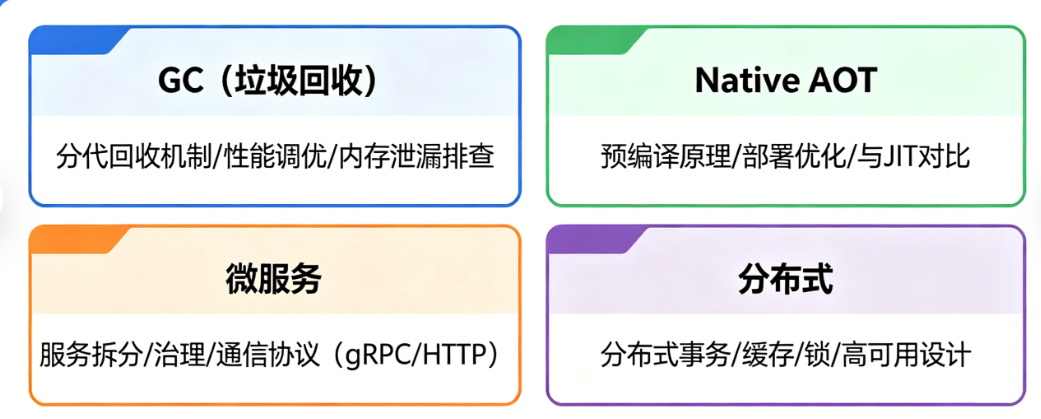
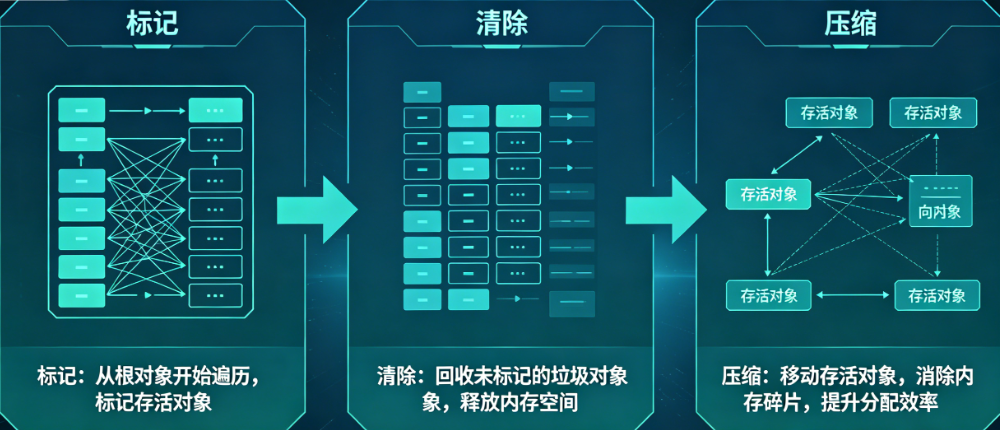
GC(垃圾回收器) 是 CLR 的核心组件,负责自动管理托管内存的分配与释放,核心目标是回收「不再被引用的对象」,避免内存泄漏,简化开发者的内存管理工作。其核心流程分为 3 步:
-
标记(Mark)
从应用程序的根(
Roots,如静态变量、局部变量、CPU 寄存器中的对象指针)出发,遍历堆上所有对象,标记出「可达对象」(仍被引用的对象),未被标记的对象即为垃圾。 -
清除(Sweep)
回收未被标记的垃圾对象,释放其占用的内存。
-
压缩(Compact)
移动堆上的可达对象,使它们连续排列,消除内存碎片,便于后续内存分配(大对象除外,GC 不会移动大对象,避免移动开销)。
(2)分代回收机制
GC 基于「大部分新对象生命周期短、老对象生命周期长 」的特点,将托管堆分为 3 代(Generation 0、1、2),实现高效回收,减少回收开销:
-
第 0 代(Gen 0)
存储新创建的对象,生命周期最短(如临时变量),回收频率最高,回收速度最快。
-
第 1 代(Gen 1)
存储第 0 代回收后幸存的对象,作为「过渡代」,回收频率较低,用于过滤短期对象。
-
第 2 代(Gen 2)
存储第 1 代回收后幸存的对象,生命周期最长(如单例对象),回收频率最低,回收开销最大。

底层原理
分代回收的核心是「局部回收优于全局回收 」,每次优先回收 第 0 代,仅当 第 0 代 内存不足时,才触发 第 1 代、第 2 代回收。
大对象 (默认大于 85000 字节)会直接分配在大对象堆(LOH),不参与压缩,避免移动大对象带来的性能开销。
避坑提示
内存泄漏的核心原因是「对象被无意引用,导致 GC 无法回收」,常见场景:
-
静态集合持有对象
-
事件订阅未取消
-
非托管资源未释放
排查内存泄漏可使用 WinDbg、dotnet-dump 等工具,分析 GC 堆、查找未释放的对象。
2. 高频题:.NET 10 Native AOT 的优势是什么?适用场景和局限是什么?
提问场景:
2026年高频新题,考察对 .NET 生态新特性的掌握,资深开发/架构师必问。
标准答案
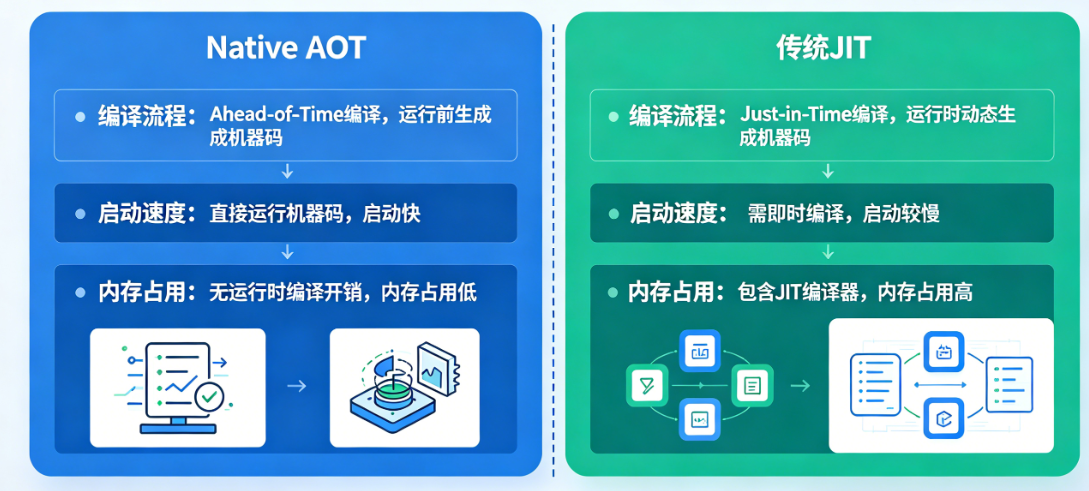
(1)Native AOT 核心优势
-
启动速度极快
将
IL代码提前编译为机器码,无需运行时 JIT 编译,启动时间比传统JIT减少50%以上,适合桌面应用、控制台应用、云原生轻量服务。 -
内存占用低
无需加载
JIT编译器和IL代码,内存占用比传统JIT减少20%--30%。 -
无需依赖 .NET 运行时
编译后生成独立可执行文件,可在未安装
.NET runtime的机器上运行,部署更便捷。 -
安全性更高
机器码比 IL 代码更难反编译,提升代码安全性。
(2)适用场景
-
桌面应用(
WPF、WinForms)、控制台应用、CLI工具 -
云原生轻量服务(如
Serverless、微服务边缘节点) -
对启动速度、内存占用要求高的场景(如物联网设备、嵌入式系统)
(3)局限
-
不支持动态特性
不支持反射、动态类型(
dynamic)、AppDomain、序列化/反序列化(部分场景) -
编译时间长
提前编译为机器码,编译时间比传统
JIT长 -
库支持有限
部分第三方库未适配
Native AOT,使用时需注意兼容性 -
不支持跨平台编译
Windows下编译的可执行文件,无法直接在Linux/macOS运行,需跨平台编译
底层原理
Native AOT 基于 CoreRT 编译器,将 .NET 代码(IL) 在编译时直接转换为目标平台的机器码,同时链接所需的依赖库,生成独立可执行文件;运行时无需 JIT 编译器 介入,直接执行机器码,大幅提升启动速度和运行效率。
3. 高频题:.NET 微服务架构中,服务注册发现、熔断降级、API网关分别用什么组件?核心原理是什么?
提问场景:
资深开发/架构师必问,考察微服务实战落地能力。
标准答案
(1)服务注册发现
-
常用组件 :
Consul(最常用)、Nacos、Eureka、Service Fabric(微软原生) -
核心原理
服务启动时,将自身信息(IP、端口、服务名)注册到注册中心;服务消费者从注册中心获取服务列表,通过负载均衡选择服务实例进行调用;注册中心定期检测服务健康状态,移除不可用的服务实例,确保服务可用性。
(2)熔断降级
-
常用组件 :
Polly(.NET 生态首选)、Steeltoe -
核心原理
熔断和降级是微服务容错机制,防止服务雪崩:-
熔断:当调用下游服务的失败率达到阈值(如 50%),暂时切断调用,直接返回失败,避免反复请求拖垮服务;熔断一段时间后,进入半开状态,尝试调用下游服务,若恢复正常则关闭熔断,否则继续熔断。
-
降级:熔断触发后,返回兜底数据(如缓存数据、默认值),保证核心功能可用,舍弃非核心功能(如商品详情页的推荐商品,降级后不展示)。
-
(3)API 网关
-
常用组件 :
Ocelot(.NET 轻量级首选)、Kong、Azure API Management -
核心原理
API 网关是微服务的入口,统一处理所有请求,实现路由转发、身份认证、权限控制、限流、日志监控、请求转换等功能;将分散的微服务接口统一暴露,简化客户端调用,同时隔离客户端和微服务,提升系统安全性和可维护性。
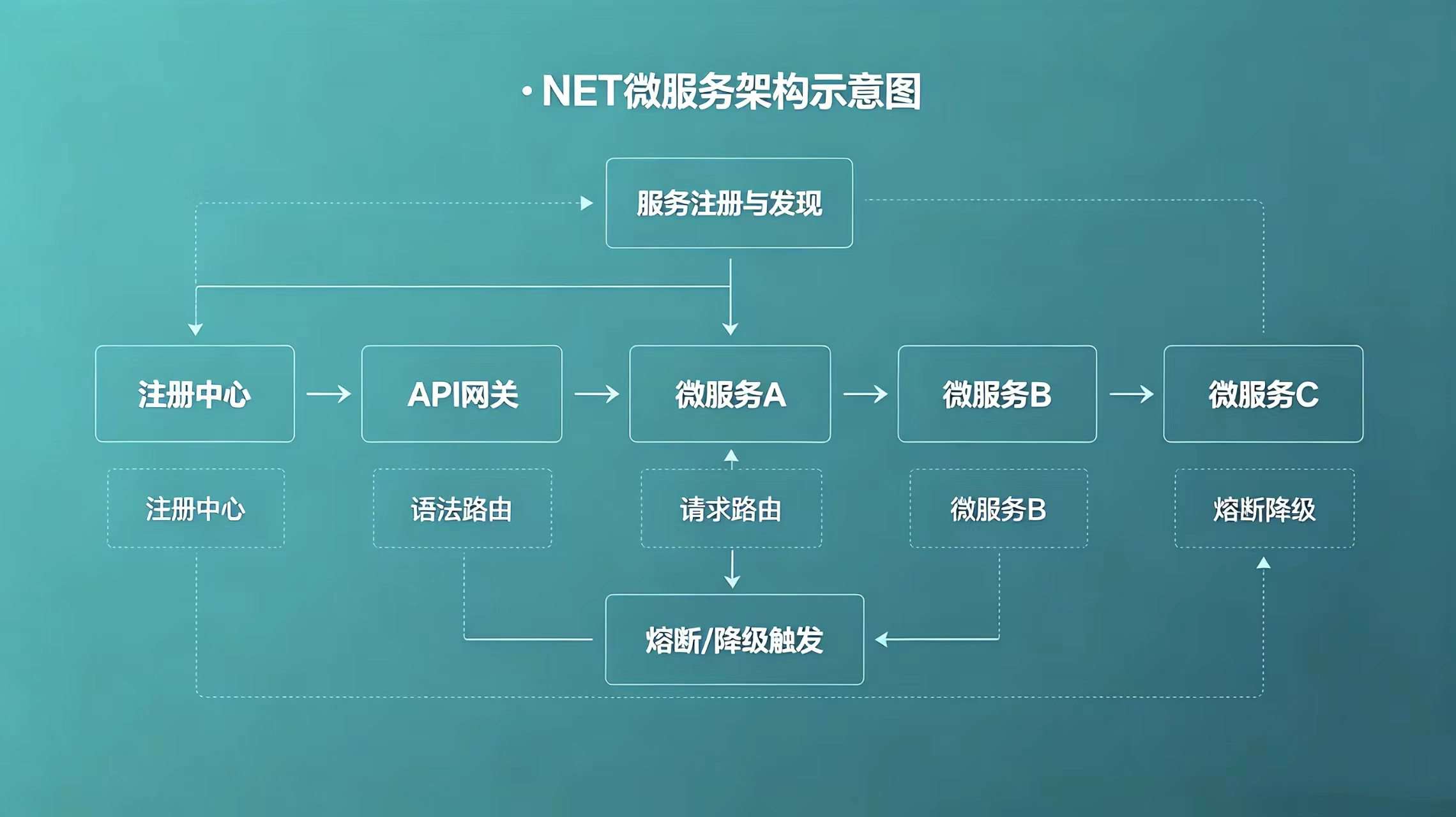
实战提示
.NET 微服务落地时,推荐组合:
Consul(注册发现) + Polly(熔断降级) + Ocelot(API 网关) + Docker + K8s(容器编排),贴合 .NET 生态,部署和维护更便捷。
高并发场景下,可搭配 RabbitMQ/Kafka 实现异步通信,解耦服务。
4. 高频题:分布式事务有哪些解决方案?.NET项目中如何落地?
提问场景:
资深开发/架构师必问,考察分布式系统数据一致性处理能力。
标准答案
分布式事务核心解决「跨服务、跨数据库的数据一致性」问题,常用解决方案分为 4 类,结合 .NET 实战落地如下:
-
2PC(两阶段提交)
-
原理:分为准备阶段(所有参与者确认可提交)和提交阶段(所有参与者统一提交),强一致性。
-
.NET 落地 :适合短事务、强一致性场景(如金融支付),可使用 .NET 自带的
TransactionScope(需数据库支持分布式事务)。 -
局限:性能差,存在阻塞问题,适合小并发场景。
-
-
TCC 模式(Try-Confirm-Cancel)
-
原理:将分布式事务拆分为 Try(尝试执行)、Confirm(确认执行)、Cancel(取消执行)三个步骤,业务侵入性强,需手动编写补偿逻辑。
-
.NET 落地 :适合核心业务(如订单创建),可自定义 TCC 逻辑,或使用开源框架(如
TCC-Transaction)。 -
优势:性能高,可灵活控制事务粒度。
-
-
SAGA 模式
-
原理:将大事务拆分为多个小事务(每个小事务对应一个服务),每个小事务执行成功后提交,若某一步失败,执行反向补偿操作,保证最终一致性。
-
.NET 落地 :适合长事务场景(如订单履约),可使用
MassTransit、CAP等框架实现。 -
优势:适配高并发,避免阻塞,适合复杂业务场景。
-
-
最终一致性(消息队列)
-
原理 :基于可靠消息队列(
RabbitMQ、Kafka),将事务操作拆分为「本地操作 + 消息发送」,确保消息不丢失、不重复,最终实现数据一致性。 -
.NET 落地 :主流方案,适合高并发、非强一致性场景(如订单通知、积分发放),推荐使用
CAP框架(.NET 生态专用,支持 RabbitMQ/Kafka,简化开发)。 -
优势:性能高,业务侵入性低,适配大部分分布式场景。
-

避坑提示
不要盲目追求强一致性(2PC),大部分业务场景下,最终一致性 即可满足需求。
使用消息队列实现最终一致性时,需处理「消息丢失、消息重复、消息顺序」三个问题,避免数据错乱。