
文章目录
- [1. 什么是影子模式 (Shadow Mode)?](#1. 什么是影子模式 (Shadow Mode)?)
- [2. 什么是模仿学习 (Imitation Learning)?](#2. 什么是模仿学习 (Imitation Learning)?)
- [3. 两者的联系与区别](#3. 两者的联系与区别)
- [4. 智能驾驶训练与上线流程](#4. 智能驾驶训练与上线流程)
- [5. 总结](#5. 总结)
- [6. 扩展阅读------模仿学习 vs 监督学习](#6. 扩展阅读——模仿学习 vs 监督学习)
在智能驾驶领域,**影子模式(Shadow Mode)和 模仿学习(Imitation Learning)是两个非常核心的技术概念。为了让你通俗理解,我们可以把 AI 训练比作"培养一名赛车手"**的过程。
1. 什么是影子模式 (Shadow Mode)?

影子模式 是 AI 训练的"后台观察员",但它不会真的控制方向盘或油门!
- 形象解释: 你的车上虽然跑着 AI 系统,但真正的控制权还在人类司机手里。在这个模式下,AI 就像一个坐在副驾的"实习生",它也在观察路况,也在心中默念"如果是我的话,我会向左打方向盘"或"我会踩刹车"。
- 核心价值: AI 默念的答案会不断地与人类真实的操作进行比对。
- 如果 AI 的操作与人类一致,说明它学得不错。
- 如果 AI 想向左转,而人类选择了右转,AI 就会把这次"分歧"上传给云端。工程师通过这些"分歧点",专门教 AI 应对那些复杂、罕见的突发状况。
- 一句话总结: 这是在真实世界中进行的一场"永不结束的模拟考",用来找差距。
📌 举个例子:
- 人类司机往左打方向
- 影子系统却觉得应该往右
- 系统就记录下来:这里我判断错了
从影子模式中找到:
- AI犯错的场景(误判)
- 人类很复杂的操作(难样本)
- 极端情况(Corner Case)
比如:
- 雨天反光
- 夜间逆光
- 行人突然出现
2. 什么是模仿学习 (Imitation Learning)?
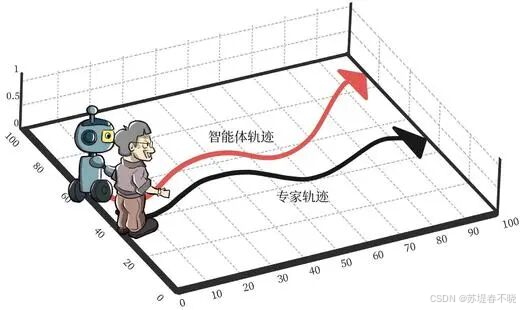
模仿学习是 AI 训练的"模仿教学法"。
- 形象解释: 就像学跳舞,教练(人类司机)在前面跳(操作汽车),AI 在后面跟着跳(学习动作)。AI 会观察大量人类司机的开车录像,学习在什么图像输入下,人类对应了什么样的动作指令。
- 核心价值: 不再需要人工编写极其复杂的规则(比如"看到红灯必须距离 10 米停下"),而是直接让 AI 观察人类经验,总结出"看到这种情况,我应该这样操作"的逻辑。
- 一句话总结: 这是通过"照猫画虎"让 AI 掌握人类开车技术的手段。
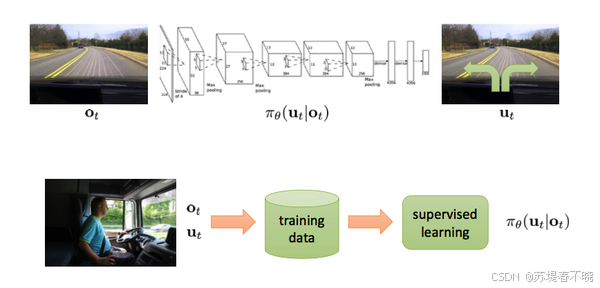
从"人类示范"中学习开车
3. 两者的联系与区别
我们可以用一个表格来对比:
| 维度 | 影子模式 (Shadow Mode) | 模仿学习 (Imitation Learning) |
|---|---|---|
| 角色 | 数据的筛选器/裁判 | 算法的导师/教学教材 |
| 发生地 | 在每一辆特斯拉真实行驶的车上 | 在实验室的超算机房里 |
| 目的 | 发现 AI 还没学会的"坑" | 将学到的经验"塞"进模型里 |
它们其实是一条成长路线上的两个阶段👇
1️⃣ 先用模仿学习
👉 AI先学会"像人一样开车"(基础能力)
2️⃣ 再用影子模式
👉 AI开始"自己尝试判断",但不接管车辆(安全验证 + 找错误)
3️⃣ 最后才真正上路
👉 AI成熟后,才敢真正控制车辆
这两个技术是紧密配合的,构成了一个完美的训练闭环:
- 影子模式 负责在全世界数百万辆车上挖掘人类处理不了的长尾场景(比如极其复杂的路口)。
- 这些场景被作为模仿学习 的顶级教材。
- AI 通过这些"错题本"不断升级,进化出新的驾驶逻辑。
- 升级后的模型再次装入新车,进入影子模式,开始新一轮的测试。
4. 智能驾驶训练与上线流程
csharp
┌──────────────────────────┐
│ 人类驾驶数据采集 │
│ (摄像头 / 雷达 / 控制信号) │
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ 数据处理 & 标注 │
│ 同步时间 / 清洗 / 标注行为 │
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ 模仿学习训练 (IL) │
│ 输入: 感知数据 │
│ 输出: 转向 / 油门 / 刹车 │
│ 本质: 学人类驾驶策略 │
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ 离线评估 (Offline) │
│ loss / 行为误差 / 回放验证 │
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ 上车部署 (Shadow Mode) │
│ 与真实驾驶并行运行 │
│ ❗不控制车辆 │
│ 输出: AI决策 vs 人类决策对比 │
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ 差异分析 & 挖掘Case │
│ 找出: AI犯错/不一致场景 │
│ Corner Case 收集 │
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ 数据回流 (Data Engine) │
│ 新数据加入训练集 │
└────────────┬─────────────┘
│
▼
(循环迭代训练)
│
▼
┌──────────────────────────┐
│ 安全验证 (闭环测试) │
│ 仿真 / 封闭道路 / 指标达标 │
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ 自动驾驶上线 (Drive) │
│ AI开始真正控制车辆 │
└──────────────────────────┘5. 总结
- 模仿学习 是 AI 的 "老师",教它怎么做;
- 影子模式 是 AI 的 "纠错本",帮它找到不会做的地方。
6. 扩展阅读------模仿学习 vs 监督学习
👉 模仿学习"看起来像"监督学习,但本质多了一层"决策问题"
🧠 一句话先说结论
👉 模仿学习 = 监督学习 + 决策场景(连续做选择)
🥇 一、什么是监督学习(Supervised Learning)
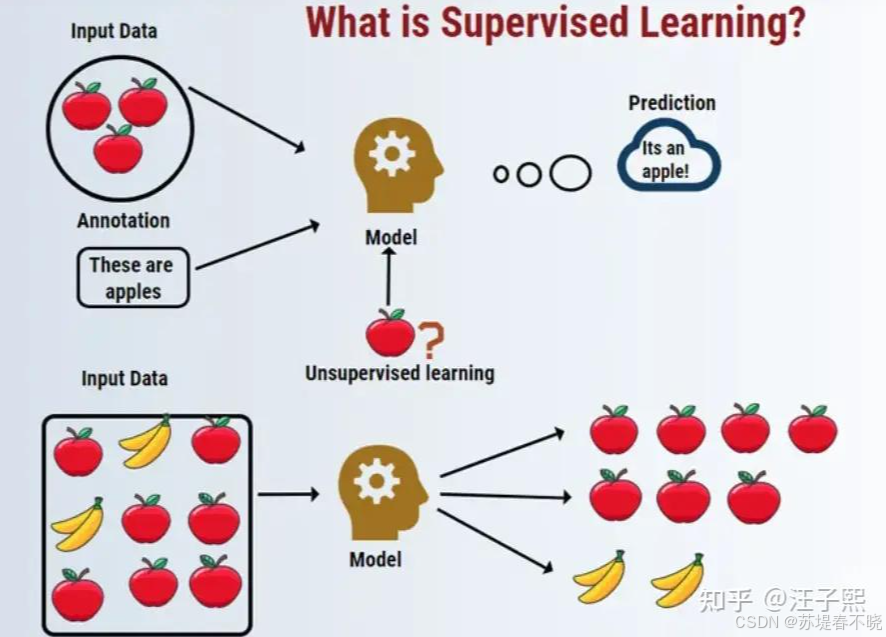
👉 可以理解为:做题训练
特点:
- 有标准答案(label)
- 一题一答案
- 做错了就改
📌 举例:
- 输入:图片
- 输出:猫 / 狗
👉 就像考试:
老师给题目 + 标准答案,你照着学

🚗 二、什么是模仿学习(Imitation Learning)
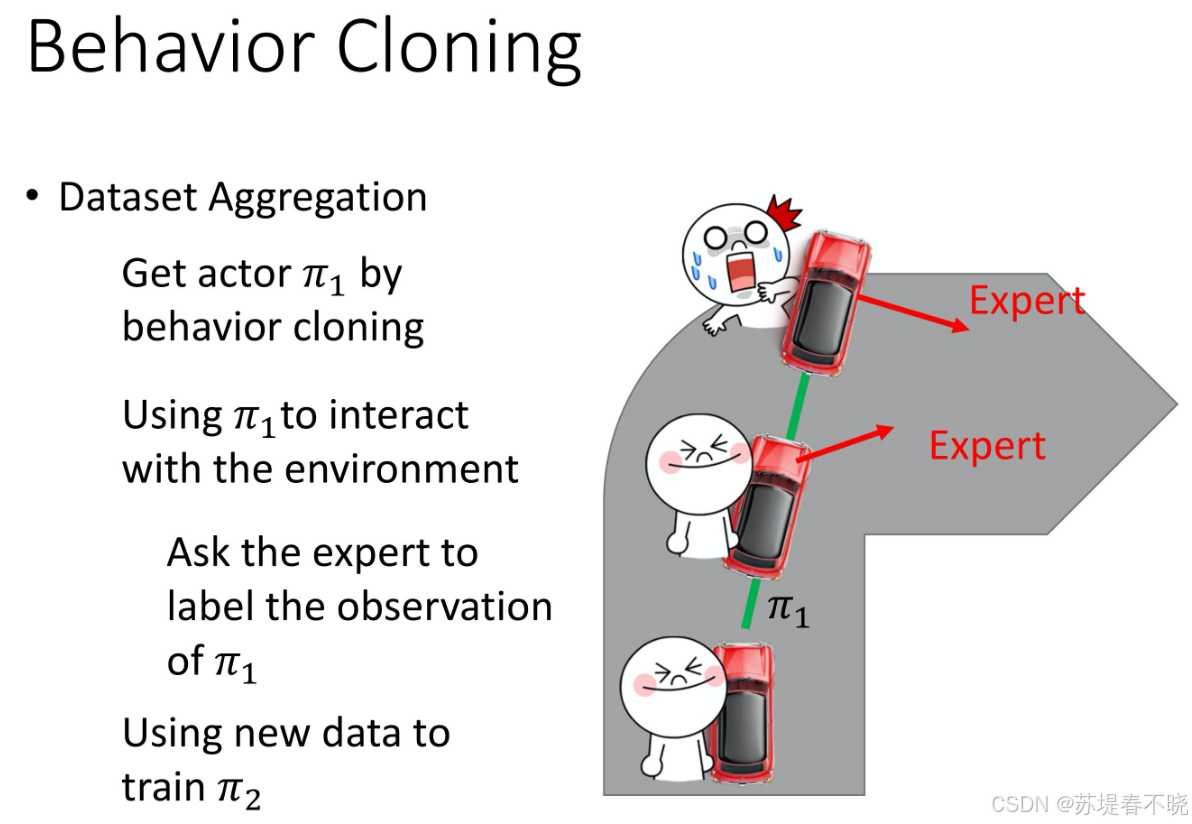
👉 可以理解为:学"连续做决定"
特点:
- 学的是"行为"(不是单一答案)
- 每一步都会影响下一步
- 错一步,后面可能全错
📌 自动驾驶例子:
- 输入:当前画面
- 输出:方向盘角度
但关键是:
text
每一步动作 → 会改变下一帧画面👉 这是和监督学习最大的不同
⚠️ 三、核心区别(最重要)
❗区别1:是否"会影响未来"
监督学习:👉 不影响
- 这张图片分类错了
- 不影响下一张图片
模仿学习:👉 会影响!
- 方向盘打歪一点
- 下一帧画面就变了
- 后面全错
👉 叫做:误差累积(error accumulation)
❗区别2:数据分布是否稳定
监督学习:
👉 数据是固定的
训练和测试:
text
train ≈ test模仿学习:
👉 数据会"被自己改变"
训练数据:
- 来自"人类正常驾驶"
但测试时:
- AI可能开歪 → 进入"奇怪状态"
👉 训练时没见过!
❗区别3:目标不同
监督学习:
👉 学"正确答案"
模仿学习:
👉 学"如何一步步做决策"
👉 更接近:强化学习
🧩 四、为什么看起来一样?
因为模仿学习最基础形式就是:
👉 用监督学习来训练
比如:
text
输入:图像
标签:人类方向盘角度训练方式:
- MSE loss
- 神经网络
👉 完全就是监督学习!
🚨 五、但问题来了(关键!)
直接用监督学习做模仿学习,会有问题:
👉 分布偏移(Distribution Shift)
举个简单例子👇
🚗 训练阶段:
人类一直开在车道中间→ 数据全是"正常画面"
🤖 测试阶段:
AI稍微偏一点:
- 画面变了(靠近车道边)
- 但模型没见过这种情况
👉 就不会修正!
六、工程上怎么解决?
这里才是模仿学习真正的内容👇
✅ 方法1:DAgger
核心思想:
text
让AI犯错 → 人类纠正 → 加入训练集👉 不断补"错误场景"
✅ 方法2:数据增强
- 加噪声
- 模拟偏离车道
👉 让模型见过"错误状态"
✅ 方法3:结合强化学习
👉 不只是模仿,还能自己优化
🧠 七、用一个最直观的比喻
🎓 监督学习:
👉 做数学题
- 每题独立
- 不影响下一题
🚴 模仿学习:
👉 学骑自行车
- 每一步都会影响下一步
- 歪一下就可能摔倒
- 需要不断修正
🔥 最终总结(非常关键)
👉 监督学习 = 静态问题(不会影响未来)
👉 模仿学习 = 动态决策问题(会影响未来)
👉 模仿学习只是"用监督学习来训练的一种决策学习方法"