手把手教你分析深度学习目标检测模型------以YOLOv5为例
我们常常会接触各类预训练模型,但很多时候只知道"模型能做什么",却不清楚"模型内部在做什么"。今天,我们就以经典的YOLOv5目标检测模型为例,结合Netron可视化工具,一步步教你如何完整分析一个深度学习模型,从输入到输出、从宏观到微观,读懂模型的每一个细节。
一、先明确核心:模型的定位与核心功能
分析模型前,首先要明确模型的核心用途------我们本次分析的YOLOv5模型,是一款主流的目标检测模型,核心功能是:输入一张图片,通过模型内部的特征提取与计算,最终输出带有目标边界框(bbox)、目标类别和置信度的检测结果,直白地说,就是让计算机"看到"图片里有什么、在什么位置。
这也是我们分析模型的核心逻辑:从"输入什么"出发,拆解"模型做了什么",最终理解"输出什么、怎么用",形成完整的分析闭环。
二、准备工作:模型输入前的预处理
深度学习模型对输入数据有严格的格式要求,并非直接输入原始图片就能运行,这一步是模型分析的基础,也是我们容易忽略的细节。
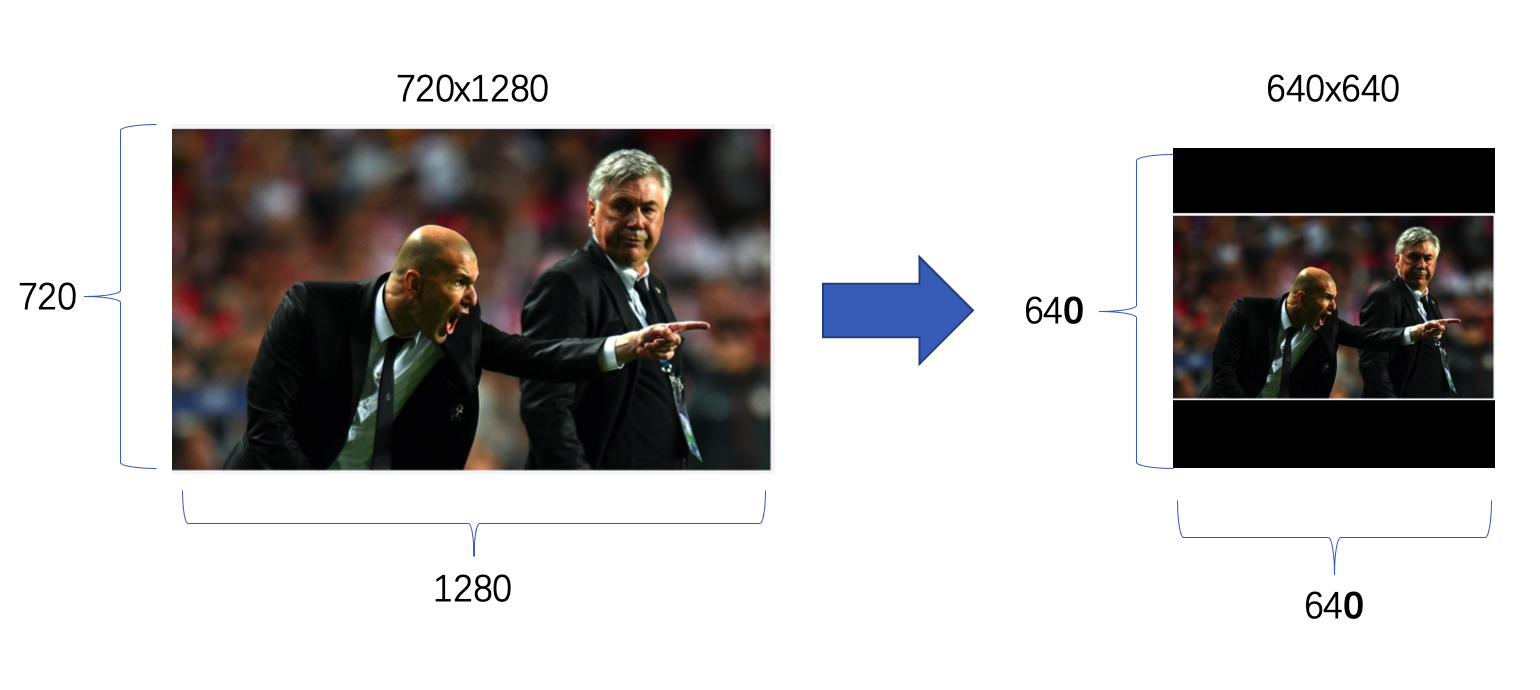
以本次分析的YOLOv5模型为例,它要求的输入数据格式为:float32[1, 3, 640, 640],我们逐一对这个格式进行解读,这也是所有深度学习模型输入格式的通用分析方法:
- float32:数据类型,代表输入的每个像素值都是32位浮点数,这是深度学习模型中最常用的数据类型,保证计算精度的同时兼顾效率;
- 1:批量大小(batch size),表示一次输入1张图片进行推理,实际应用中可调整为批量输入(如8, 3, 640, 640表示一次输入8张图);
- 3:输入通道数,对应RGB彩色图像的3个通道(红色R、绿色G、蓝色B),如果是灰度图,通道数则为1;3 个通道(R、G、B),每个通道都是 640×640 的 "灰度图",每个通道里的每个像素点,都用 32 位浮点数存储亮度值,3 个通道的亮度值叠加,形成彩色像素。
- 640×640:输入图像的高度和宽度,即模型要求将原始图片缩放至640像素×640像素,确保输入尺寸统一,这是目标检测模型的常见输入分辨率。
哈哈,是不是看到这里感觉有点头晕,都不知道这些是什么,也不知道这个参数是怎么来的?且看下面分析
三、核心工具:用Netron可视化模型内部结构
分析模型内部结构,我们不需要手动拆解代码,借助Netron可视化工具就能直观看到模型的每一个节点、每一层计算------Netron是一款专门用于可视化ONNX、TensorFlow等格式模型的工具,操作简单,无需编程基础,是深度学习学生分析模型的必备工具。
使用方法非常简单:打开官网(https://netron.app/),上传模型文件(本次分析的YOLOv5模型为ONNX格式),即可自动生成模型的可视化结构图,我们可以通过这个图,从宏观到微观,逐步拆解模型。
模型分析第一步:宏观概览------读懂模型的输入、输出与规模
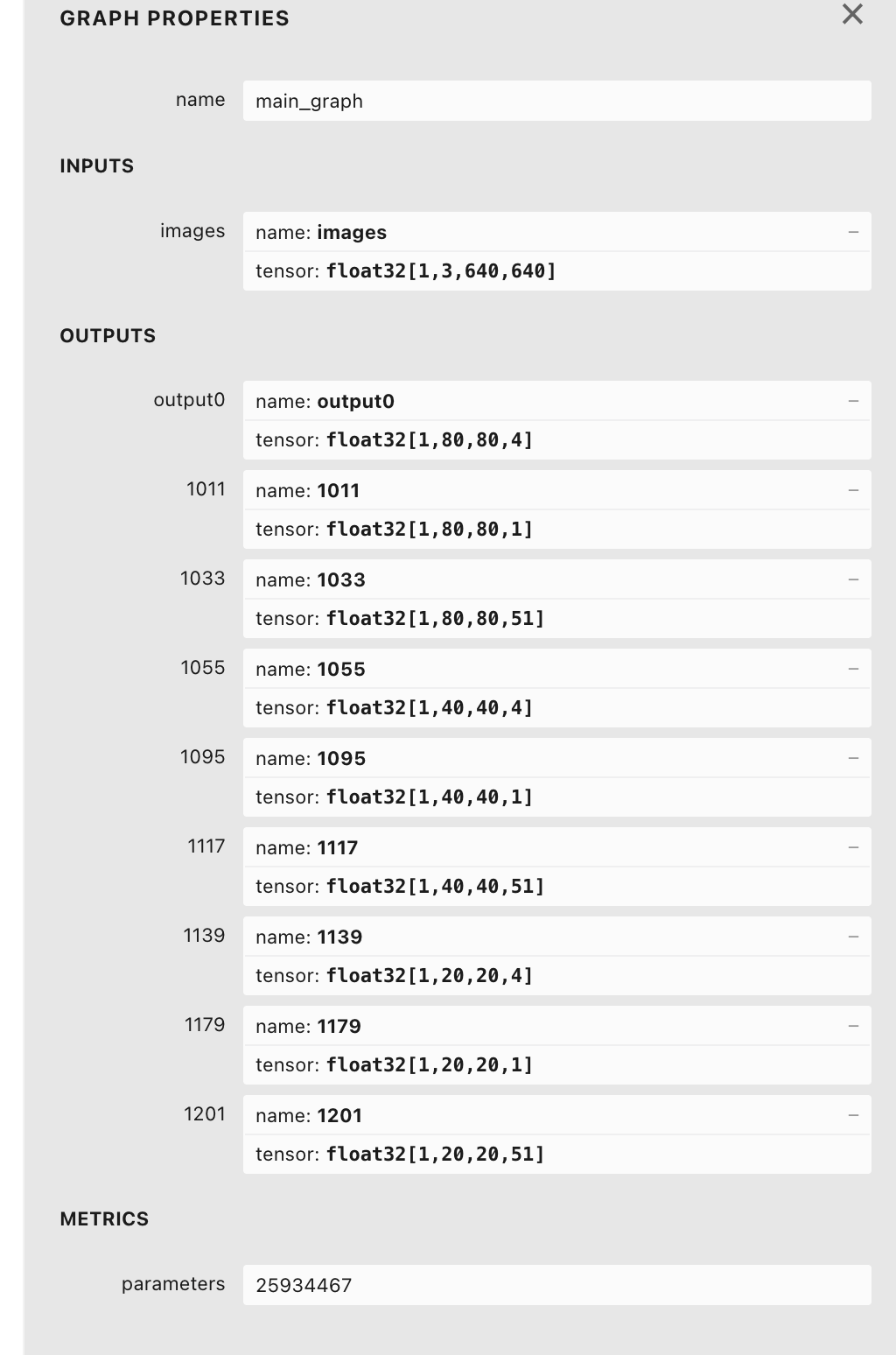
上传模型后,首先看到的是模型的"全局视图"(对应参考图1),这一步的核心是掌握3个关键信息:模型参数量、输入、输出,快速建立对模型的整体认知。
这里就可以看到模型的输入输出要求是什么了。
1. 模型参数量
本次分析的YOLOv5模型,总参数量为25934467(约2593万),参数量直接反映模型的复杂程度:参数量越大,模型的特征提取能力越强,但计算成本越高,部署难度也越大;参数量越小,模型越轻量化,适合边缘设备部署。对于学生而言,通过参数量可以快速判断模型的适用场景。
2. 模型输入
全局视图中明确标注了输入为images: float32[1, 3, 640, 640],与我们预处理的输入格式完全对应,这也验证了我们预处理的正确性------模型的输入必须与预处理后的输出完全匹配,否则会报错。
3. 模型输出
这是宏观概览的重点,也是目标检测模型的核心特征。本次模型共输出9个张量,分为3个尺度,每个尺度包含3个分支,这是YOLO系列模型典型的多尺度检测设计,目的是兼顾小、中、大不同尺寸的目标检测,我们用表格清晰整理(对应参考图1的输出信息):
| 输出名称 | 张量形状(float321, H, W, C) | 下采样倍数 | 分支类型 | 作用 |
|---|---|---|---|---|
| output0 | 1, 80, 80, 4 | 8倍 | 坐标分支 | 小目标检测:预测边界框(x, y, w, h) |
| 1011 | 1, 80, 80, 1 | 8倍 | 置信度分支 | 小目标置信度:判断该网格是否存在目标 |
| 1033 | 1, 80, 80, 51 | 8倍 | 分类分支 | 小目标分类:51个类别的概率分布 |
| 1055 | 1, 40, 40, 4 | 16倍 | 坐标分支 | 中目标检测:预测边界框 |
| 1095 | 1, 40, 40, 1 | 16倍 | 置信度分支 | 中目标置信度 |
| 1117 | 1, 40, 40, 51 | 16倍 | 分类分支 | 中目标分类 |
| 1139 | 1, 20, 20, 4 | 32倍 | 坐标分支 | 大目标检测:预测边界框 |
| 1179 | 1, 20, 20, 1 | 32倍 | 置信度分支 | 大目标置信度 |
| 1201 | 1, 20, 20, 51 | 32倍 | 分类分支 | 大目标分类 |
这里我们补充两个关键知识点,帮助大家理解:
- 下采样倍数:8倍、16倍、32倍代表特征图相对于原始输入图片(640×640)的缩小比例,下采样倍数越小,特征图尺寸越大(如8倍下采样对应80×80),越适合检测小目标;下采样倍数越大,特征图尺寸越小(如32倍下采样对应20×20),越适合检测大目标。
- 三分支设计:每个尺度的3个分支各司其职------坐标分支(4通道)预测目标位置,置信度分支(1通道)判断是否有目标,分类分支(51通道)预测目标属于哪一类(本次模型支持51个类别),三者结合才能完整描述一个目标。
总结:宏观概览的核心是"摸清模型的基本情况",知道模型的输入要求、输出形式和规模,为后续微观拆解打下基础。
五、模型分析第二步:微观拆解------读懂核心层(Conv层)的工作原理
宏观概览后,我们需要深入模型内部,拆解核心层的工作机制------对于目标检测模型而言,卷积层(Conv层)是最核心的层,负责提取图片的特征,也是我们分析的重点(对应参考图2)。一般预训练的模型是没有什么问题的,但我们可以点击进去模型内部看它的内部信息。Conv层的核心计算公式 输出 = 输入 × 权重 + 偏置,依据这个公式如果数学功底好还可以自己输入图片来计算一下
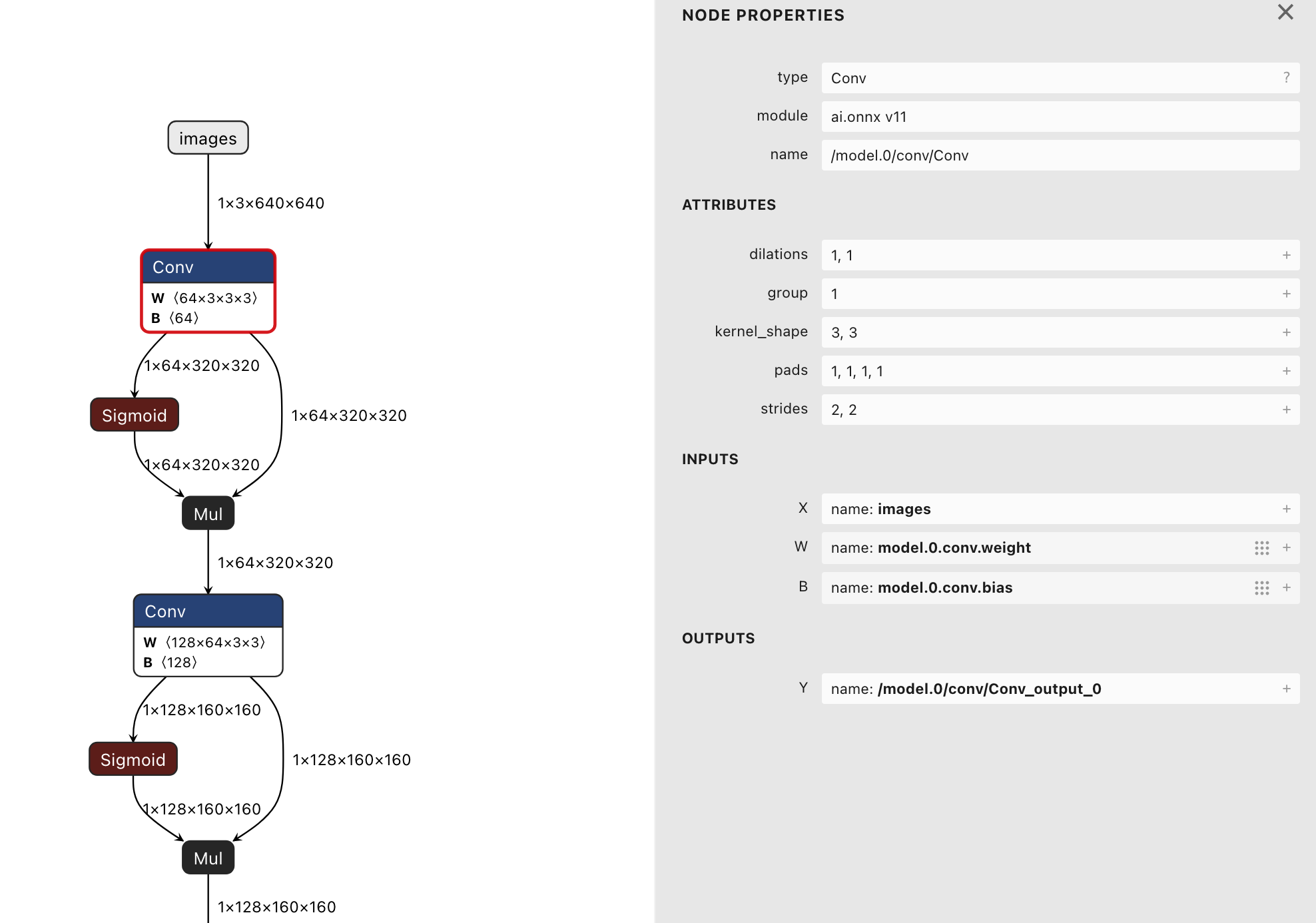
我们以模型的第一个Conv层(name: /model.0/conv/Conv)为例,拆解Conv层的输入、输出、参数和计算逻辑,这也是所有Conv层的通用分析方法。
1. Conv层的输入
该Conv层的输入是我们预处理后的图片张量1×3×640×640,同时还需要两个可学习参数:权重(W)和偏置(B),这两个参数是模型训练过程中学习到的,决定了Conv层的特征提取能力。
- 权重(W):形状为
64×3×3×3,含义是:该Conv层有64个卷积核,每个卷积核的尺寸为3×3,对应输入的3个通道(RGB); - 偏置(B):形状为
64,含义是:每个输出通道(共64个)对应1个偏置项,用于调整激活函数的输入,避免模型输出过于集中,提升模型的表达能力。
2. Conv层的核心参数
参考图2的属性面板,我们可以看到Conv层的关键参数,这些参数决定了卷积操作的方式,每一个参数都有明确的作用:
- dilations(扩张率):
1, 1,表示普通卷积,没有扩张感受野,卷积核按正常方式滑动; - group(分组数):
1,表示普通卷积(非分组卷积),所有输入通道共同参与计算; - kernel_shape(卷积核尺寸):
3, 3,最常用的卷积核尺寸,兼顾特征提取能力和计算效率; - pads(填充):
1, 1, 1, 1,表示上下左右各填充1个像素,目的是保证卷积后特征图的尺寸按步长规律变化,避免特征丢失; - strides(步长):
2, 2,表示卷积核每滑动一步跳过2个像素,核心作用是下采样,让特征图尺寸减半。
3. Conv层的计算逻辑与输出
Conv层的核心计算逻辑非常简单,公式为:输出 = 输入 × 权重 + 偏置,结合上面的参数,我们可以计算出该Conv层的输出尺寸:
输入尺寸:640×640,填充1,卷积核3×3,步长2,代入公式:
输出尺寸 = (输入尺寸 + 2×填充 - 卷积核尺寸)÷ 步长 + 1 = (640 + 2×1 - 3)÷ 2 + 1 = 320
因此,该Conv层的输出形状为1×64×320×320,其中64是输出通道数(与权重的第一个维度一致),320×320是下采样后的特征图尺寸。
补充:该Conv层之后,还连接了Sigmoid激活层和Mul(逐元素乘法)层,形成"Conv→Sigmoid→Mul"的门控结构,目的是动态选择和增强有用的特征,抑制无用特征,这是YOLOv5模型的优化设计之一。
总结:Conv层分析要点
对于任何深度学习模型的Conv层,我们都可以按"输入→参数→计算→输出"的逻辑分析:明确输入的形状和参数,理解每个参数的作用,计算输出尺寸,就能读懂Conv层的核心功能------提取特征、下采样,这是模型完成目标检测的基础。
四、模型分析第三步:输出后处理------从张量到可视化检测框
模型输出的9个张量(out0, out1, out2, out3, out4, out5, out6, out7, out8),并不是我们最终看到的"带框图片",而是一堆数字,需要经过后处理,才能将这些数字转换成我们能直观理解的检测结果。我们需要明确这个模型的作用就是检测,它的输出就是检测的结果。那么后处理就是把检测结果输出到原始图片上就可以
后处理的流程非常固定,适合所有YOLO系列模型,记住这5个步骤即可:
步骤1:分组
将9个输出张量按"尺度"分成3组,每组对应一个尺度的3个分支(坐标+置信度+分类):
- 第一组(80×80,小目标):out0(坐标)、out1(置信度)、out2(分类);
- 第二组(40×40,中目标):out3(坐标)、out4(置信度)、out5(分类);
- 第三组(20×20,大目标):out6(坐标)、out7(置信度)、out8(分类)。
步骤2:拼接
对每组的3个张量进行拼接,将"坐标(4通道)+ 置信度(1通道)+ 分类(51通道)"合并为一个56通道的张量,每组的形状变为:
- 第一组:1, 80, 80, 56;
- 第二组:1, 40, 40, 56;
- 第三组:1, 20, 20, 56。
步骤3:展平
将3组拼接后的张量全部展平,变成一维列表,合并所有预测框:
- 80×80 = 6400个预测框;
- 40×40 = 1600个预测框;
- 20×20 = 400个预测框;
- 总计:6400+1600+400 = 8400个预测框,展平后形状为(8400, 56)。
步骤4:过滤低分框
设定一个置信度阈值(通常为0.25),过滤掉置信度低于阈值的预测框------这些框的可信度太低,大概率是误检,过滤后通常只剩下几百个有效框。
步骤5:NMS非极大值抑制
同一个目标可能会被多个预测框检测到,NMS的作用是保留置信度最高的那个框,删除重复的框,最终得到干净、准确的检测结果。
最终结果
经过以上5个步骤,我们会得到一个简洁的数组,每一行代表一个检测到的目标,格式为:x1, y1, x2, y2, 置信度, 类别ID,例如:
100, 200, 300, 400, 0.92, 0 → 表示在图片(100,200)到(300,400)的位置,有一个置信度为92%的目标,类别ID为0(假设0对应"人")。
最后,我们将这些坐标绘制在原始图片上,就能得到一张带有边界框、类别和置信度的可视化检测图,这就是模型的最终输出。

五、总结:深度学习模型分析的通用流程
通过本次YOLOv5模型的分析,我们可以总结出一套适用于所有深度学习模型的分析流程,无论是目标检测、图像分类还是其他任务,都可以按这个逻辑逐步拆解:
- 明确模型定位:知道模型的核心功能(做什么);
- 分析输入预处理:明确模型的输入格式、尺寸和数据类型;
- 宏观概览模型:用Netron查看模型的参数量、输入和输出,建立整体认知;重点分析Conv层等核心层的输入、参数、计算逻辑和输出;
- 解读输出与后处理:理解模型输出的含义,掌握后处理流程,将模型输出转换成直观结果。
学会分析模型不仅能帮助我们理解模型的工作原理,更能为后续的模型改进、优化和部署打下基础。建议大家多找几个不同的模型(如ResNet、YOLOv7等),按照这个流程反复练习,逐步提升自己的模型分析能力。