
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

Elasticsearch单机部署这件事,按部就班做其实不难,但有几个地方容易踩坑:不能用 root 启动、文件描述符限制默认太低、Linux 内核参数不满足 ES 要求......第一次搭的时候很可能在启动阶段就卡住,查半天不知道哪里出问题.这篇文章把整个流程过一遍:JDK 环境准备、ES 下载配置、常见报错的具体解决方法、基础的索引和文档操作、最后用 cpolar 打通远程访问.ES 版本用的是7.17,7.x 目前生产环境最稳的版本,8.x 的安全特性对本地测试来说反而麻烦,用7.x 搭学习环境更省事.几个关键前提:CentOS 7、root 或 sudo 权限、Java 8 以上.机器内存最好4G以上,ES 本身吃内存,小了跑起来比较勉强.不过,Elasticsearch 的部署并不是简单地解压、启动那么轻松.尤其是在 CentOS7系统中,JDK 版本、系统参数、内存限制、防火墙配置、网络绑定、安全策略等问题,都可能导致启动失败或外部无法访问.很多看似不起眼的配置项,如果没有提前处理好,就会在部署过程中反复踩坑.下面将围绕"CentOS7 部署 Elasticsearch 完整流程"展开,结合实际安装步骤,梳理从环境准备、下载安装、基础配置、启动验证,到常用操作和远程访问配置的完整过程.同时,也会总结部署过程中常见的问题与避坑经验,帮助你少走弯路,快速搭建一个可用、稳定的 Elasticsearch 环境.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!


目录
- 1.什么是Elasticsearch?
- 2.前提条件
- 3.安装Elasticsearch
- 4.Elasticsearch常规操作
- 5.安装cpolar实现随时随地开发
- 6.配置公网地址
- 7.保留固定公网地址
- 8.总结
1.什么是Elasticsearch?
Elasticsearch能让你在海量数据中"秒级"查到想要的内容,并支持复杂的聚合分析.
核心特性
1.全文搜索(Full-Text Search)
- 支持对文本内容进行高效、相关性排序的搜索(比如搜"苹果手机",能匹配"iPhone15").
- 内置分词器(如中文需配合IK分词插件).
- 支持模糊搜索、短语匹配、高亮显示等.
2.近实时(Near Real-Time)
数据写入后,默认1秒内即可被搜索到(不是传统数据库的"立即可见",但对大多数场景足够快).
3.分布式 & 高可用
- 数据自动分片(shard)并分布在多个节点上.
- 支持水平扩展:加机器就能提升性能和容量.
- 副本机制(replica)保证高可用,即使某个节点宕机,数据仍可访问.
4.RESTful API
- 所有操作通过HTTP接口完成,使用JSON作为数据格式.
- 易于与任何编程语言集成(Python、Java、Go等).
5.强大的聚合分析(Aggregations)
-
不只是"查找",还能"统计":
-
类似SQL中的GROUP BY + COUNT/SUM/AVG,但更灵活强大.
6.Schema-free(动态映射)
- 无需预先定义表结构(但建议显式定义mapping以优化性能和准确性).
- 插入JSON文档时,Elasticsearch自动推断字段类型(如price: 7999 → long).
| 场景 | 说明 |
|---|---|
| 电商网站搜索 | 用户输入关键词,快速返回相关商品 |
| 日志分析(ELK Stack) | 收集服务器/应用日志,用Kibana可视化(Logstash → Elasticsearch → Kibana) |
| APM(应用性能监控) | 如Elastic APM,追踪请求延迟、错误率 |
| 推荐系统 | 基于用户行为做相似内容推荐 |
| 安全分析(SIEM) | 检测异常登录、网络攻击等 |
2.前提条件
- 操作系统:CentOS 7
- Java环境(Elasticsearch 8.x要求Java环境)
- root或sudo权限
注意:Elasticsearch 8.x默认启用安全功能(TLS/HTTPS、内置用户等).若仅用于本地测试,可选择关闭安全特性(不推荐生产环境).
Elasticsearch是用Java编写的,因此需要Java 环境(https://so.csdn.net/so/search?q=Java 环境&spm=1001.2101.3001.7020).首先安装JDK(版本8或更高版本).
查看当前安装的java版本:
shell
java -version
3.安装Elasticsearch
3.1下载Elasticsearch
在Elasticsearch 官网下载最新版本的Elasticsearch.
选择适合你系统的版本(Linux、Windows等),下载并解压到合适的目录:
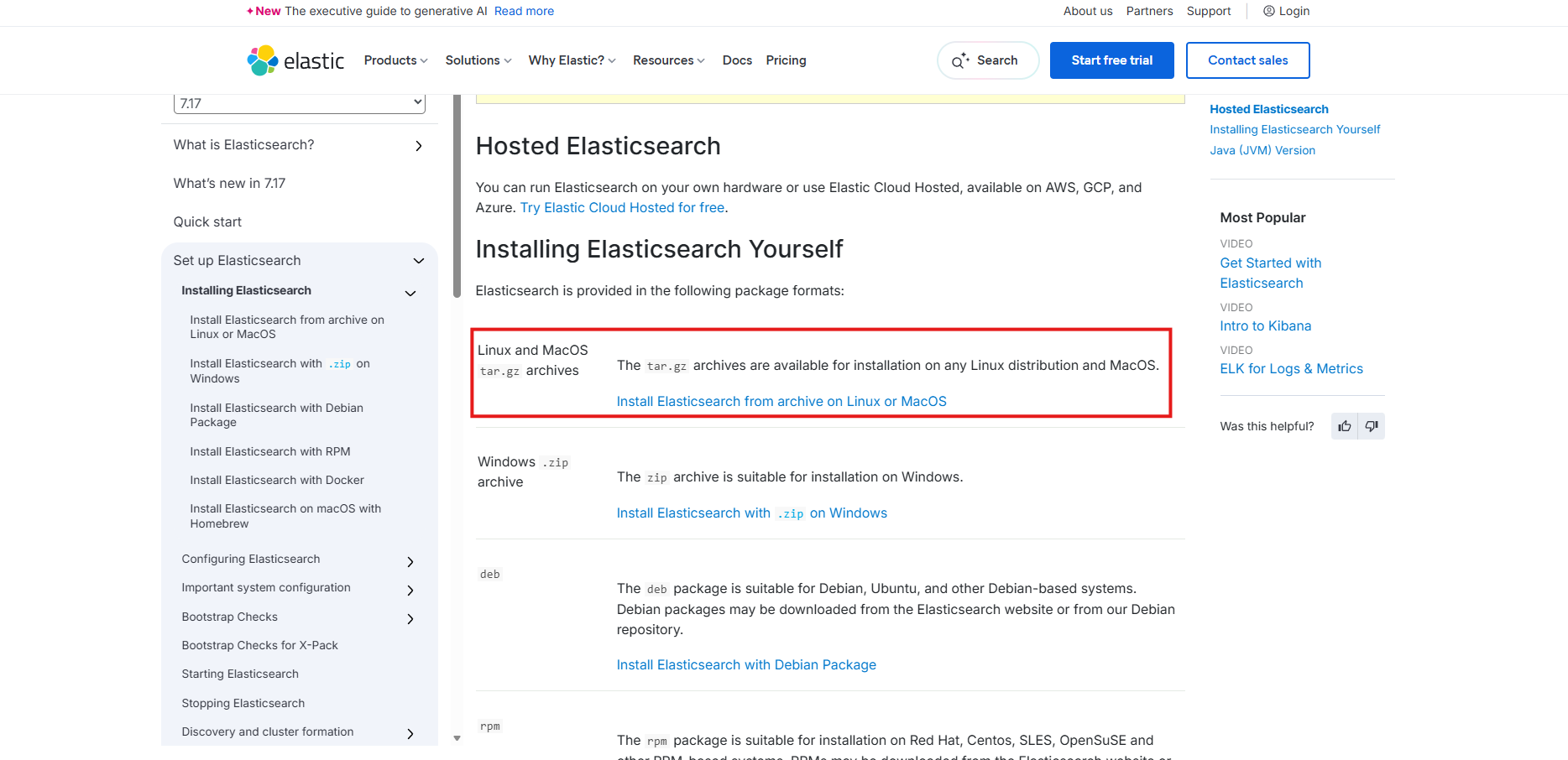
点进去后会有下载命令,复制即可,我这里下载到/app目录下:
shell
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.29-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.29-linux-x86_64.tar.gz.sha512
sha512sum -c elasticsearch-7.17.29-linux-x86_64.tar.gz.sha512
tar -xzf elasticsearch-7.17.29-linux-x86_64.tar.gz
mv elasticsearch-7.17.29 elasticsearch
cd elasticsearch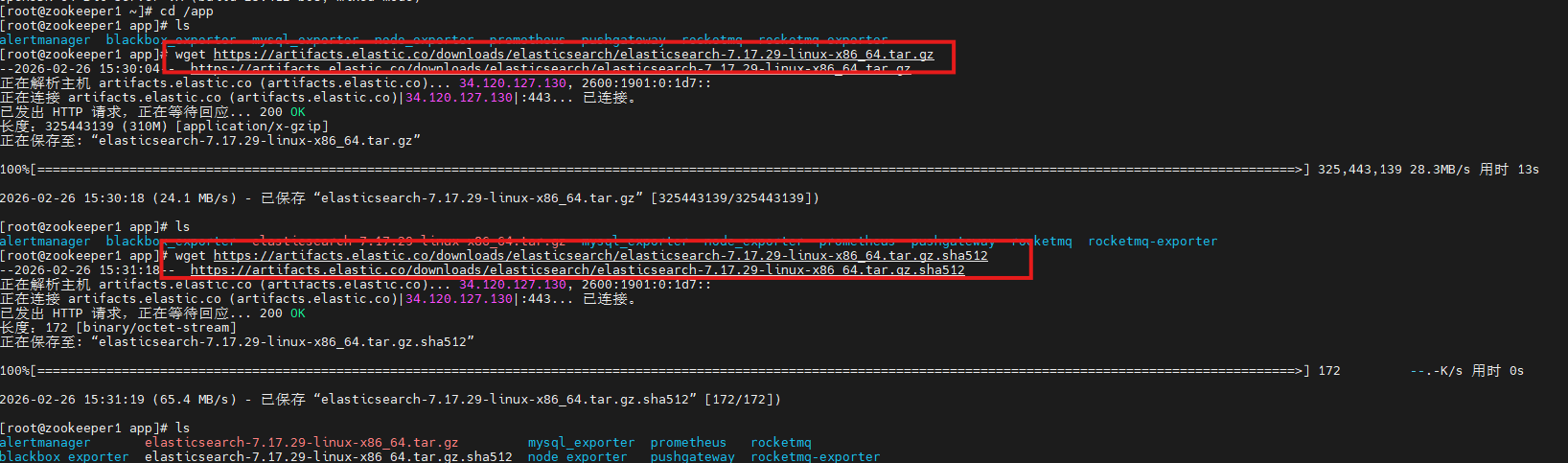
配置文件路径:config/elasticsearch.yml:
shell
vim config/elasticsearch.yml
shell
# 节点名称(可选)
node.name: node-1
# 绑定所有 IP(允许远程访问,测试用;生产请限制 IP)
network.host: 0.0.0.0
# 修改 HTTP 端口(9200端口冲突)
http.port: 9201
# 集群的名字,默认为 elasticsearch。可以根据需要修改。
cluster.name: my-app
# 在首次启动时指定初始主节点,用于集群发现。
cluster.initial_master_nodes: ["node-1"] 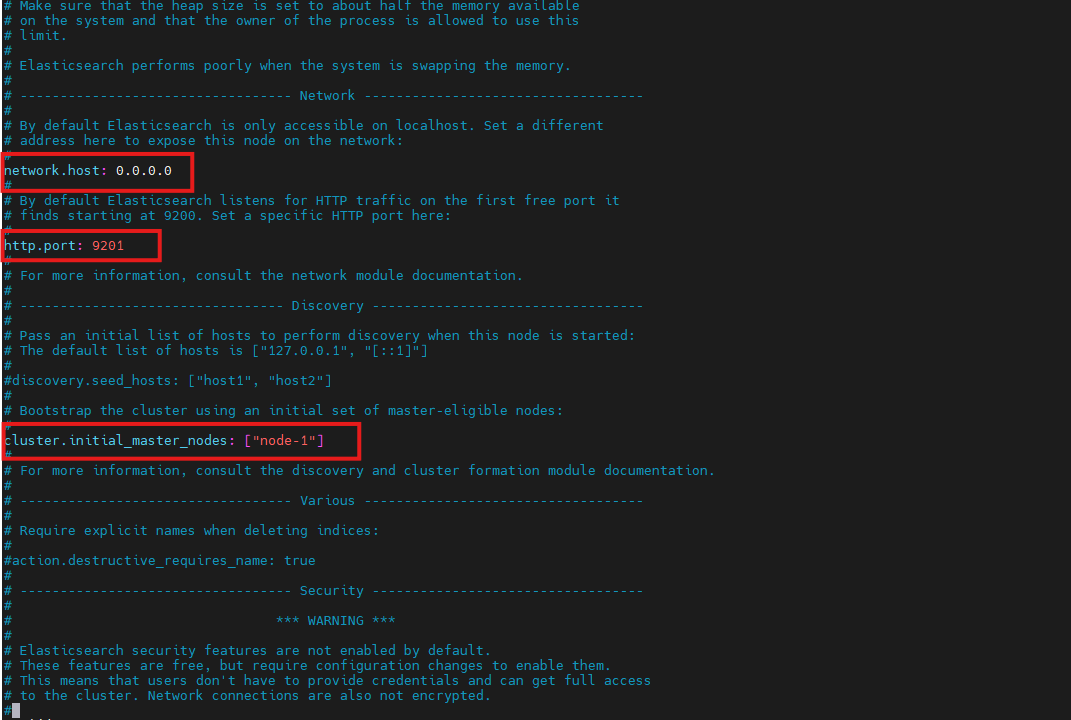
3.2启动Elasticsearch
启动Elasticsearch服务:
shell
./bin/elasticsearch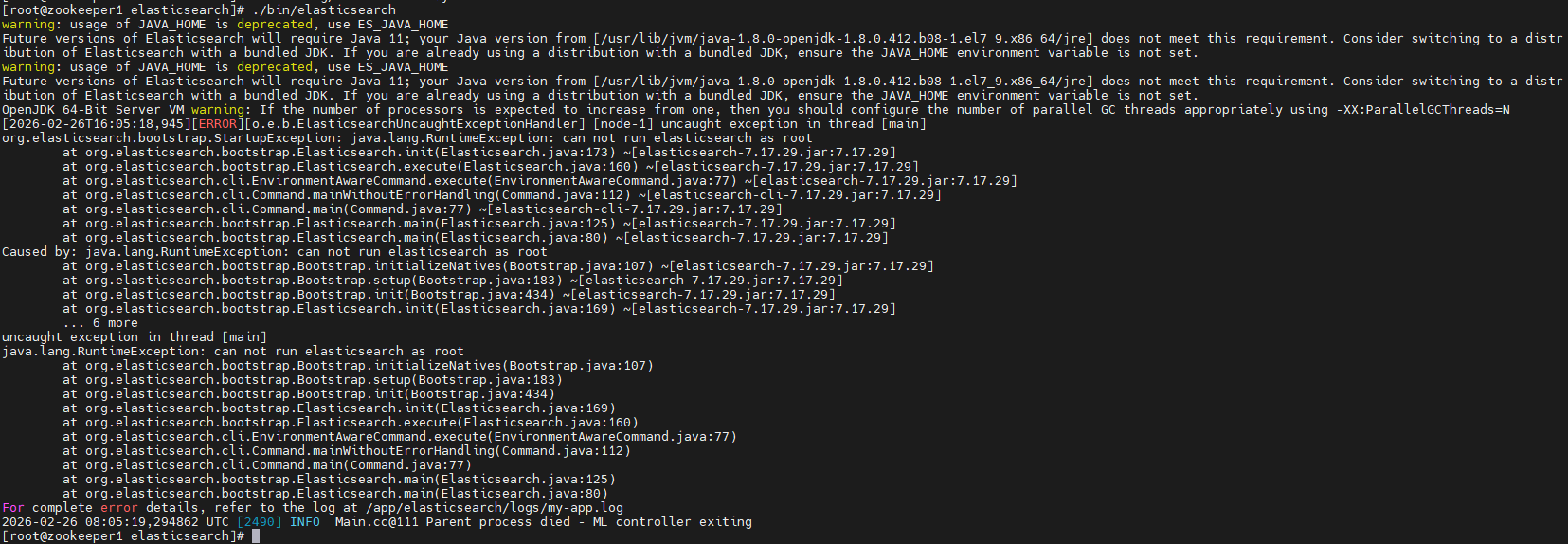
错误提示说明Elasticsearch无法以root用户启动.出于安全考虑,Elasticsearch明确禁止使用root账户运行.请创建一个普通(非root)用户,并使用该用户来启动和管理Elasticsearch服务.
创建一个新的用户:
shell
sudo useradd elasticsearch
sudo passwd elasticsearch 将Elasticsearch相关目录的所有权递归地分配给elasticsearch用户和elasticsearch用户组,以确保该用户有权限读写这些文件和目录:
shell
sudo chown -R elasticsearch:elasticsearch /app/elasticsearch/
sudo chown -R elasticsearch:elasticsearch /app/elasticsearch/data
sudo chown -R elasticsearch:elasticsearch /app/elasticsearch/logs
以新用户身份启动Elasticsearch:切换到新创建的elasticsearch用户:
shell
su - elasticsearch
shell
./app/elasticsearch/bin/elasticsearch
如果启动Elasticsearch服务成功,可以加上-d参数来后台启动:
shell
./bin/elasticsearch -d验证是否安装成功:
shell
curl http://localhost:9201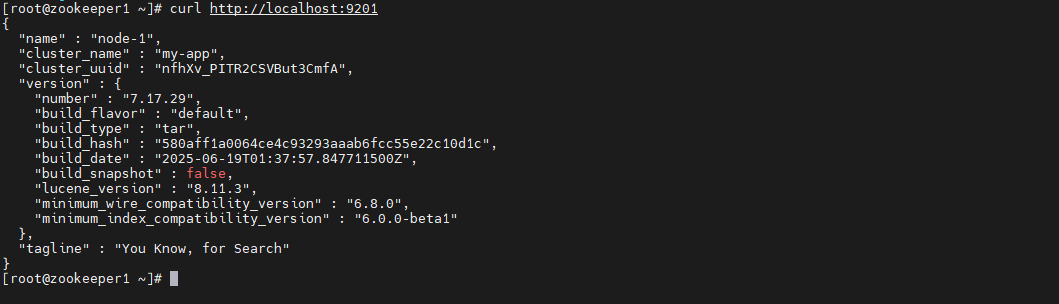
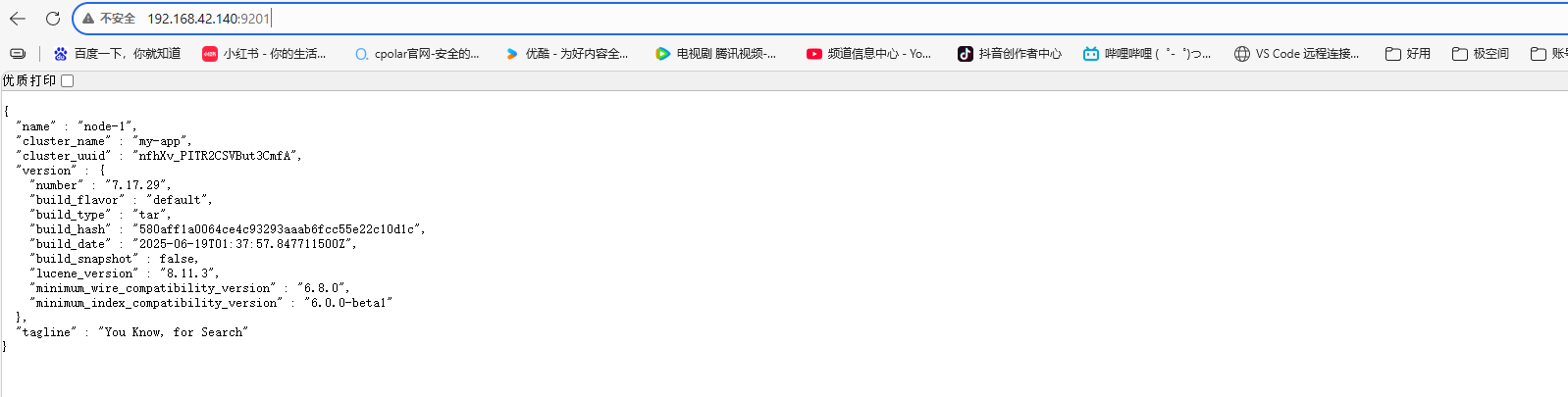
在浏览器中输入:http://192.168.42.140/:9201 即可看到elasticsearch的响应结果:
3.3启动过程中遇到的问题
问题1:文件描述符限制太低
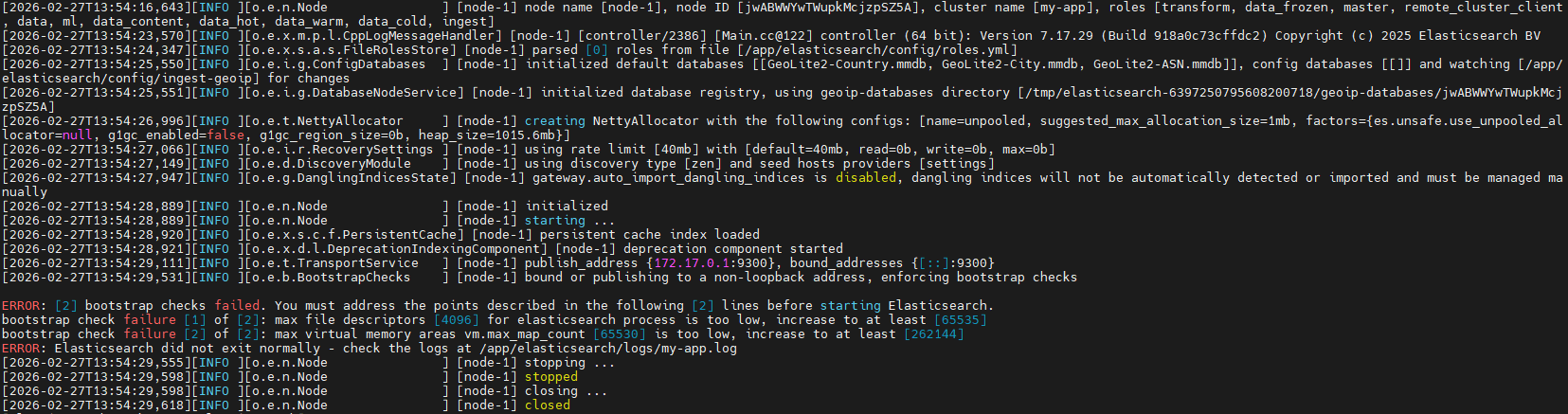
- 当前值:4096
- 要求至少:65535
- 影响:Elasticsearch需要同时打开大量文件(索引、日志、网络连接等),限制过低会导致性能下降或崩溃.
解决方法:永久提升vm.max_map_count.
shell
# 查看当前值
cat /proc/sys/vm/max_map_count
# 临时生效(重启失效)
sudo sysctl -w vm.max_map_count=262144
# 永久生效
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p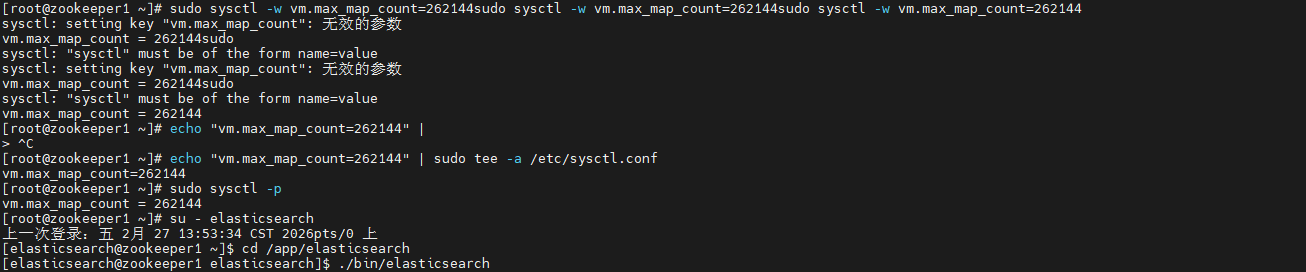
问题2:Bootstrap Check失败
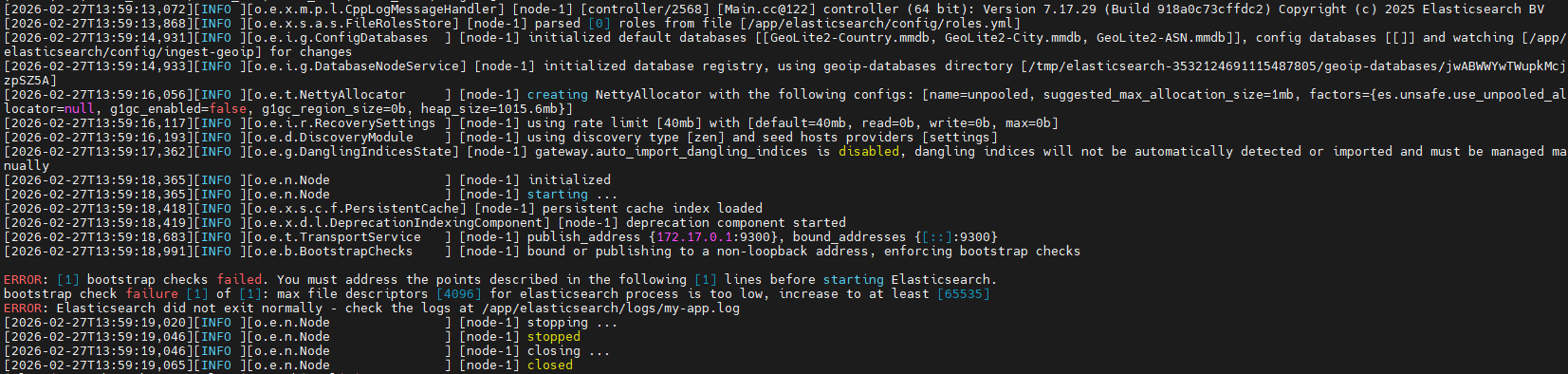
Linux系统对每个用户进程能打开的文件数量有限制.Elasticsearch是高并发、多文件系统应用(索引、日志、网络连接等),默认的4096远远不够.
解决方法:确认并修改对应配置.
1.确认limits配置已写入:
shell
sudo vi /etc/security/limits.conf确保包含以下内容(elasticsearch是你的运行用户):
shell
elasticsearch soft nofile 65535
elasticsearch hard nofile 655352.确保PAM支持limits:
检查/etc/pam.d/su是否包含(取消注释):
shell
session required pam_limits.so3.完全退出并重新登录elasticsearch用户:
shell
exit # 退出当前 elasticsearch 会话
# 重新 ssh 登录或 su - elasticsearch
su - elasticsearch4.验证当前限制
shell
ulimit -n
#正确输出应为:65535
4.Elasticsearch常规操作
确保Elasticsearch已正常运行,可通过curl http://localhost:9201 测试,返回类似以下JSON信息表示服务已就绪:
shell
{
"name" : "node-1",
"cluster_name" : "my-app",
"version" : { ... },
"tagline" : "You Know, for Search"
}4.1查看集群健康状态:
shell
curl -X GET "http://localhost:9201/_cluster/health?pretty"返回status: green表示一切正常.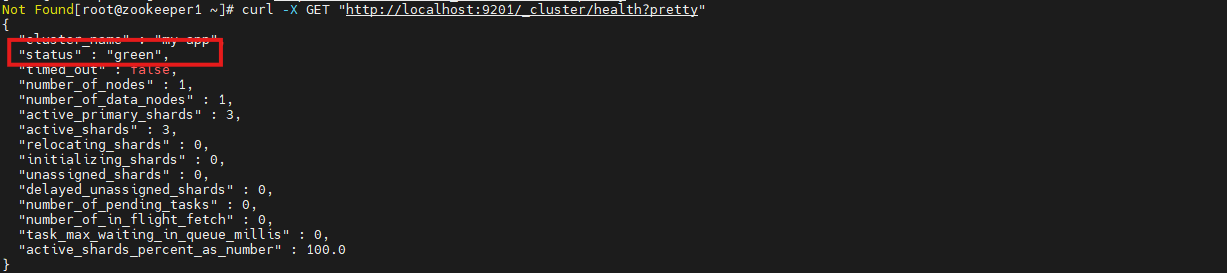
4.2创建索引(Index)
shell
curl -X PUT "http://localhost:9201/products?pretty"索引名必须小写.

4.3写入文档(自动创建ID)
shell
curl -X POST "http://localhost:9201/products/_doc" \
-H "Content-Type: application/json" \
-d '{
"name": "iPhone 15",
"price": 7999,
"category": "phone"
}'
4.4写入文档(指定ID)
shell
curl -X PUT "http://localhost:9201/products/_doc/1001" \
-H "Content-Type: application/json" \
-d '{
"name": "MacBook Pro",
"price": 15999,
"category": "laptop"
}'
4.5查询文档
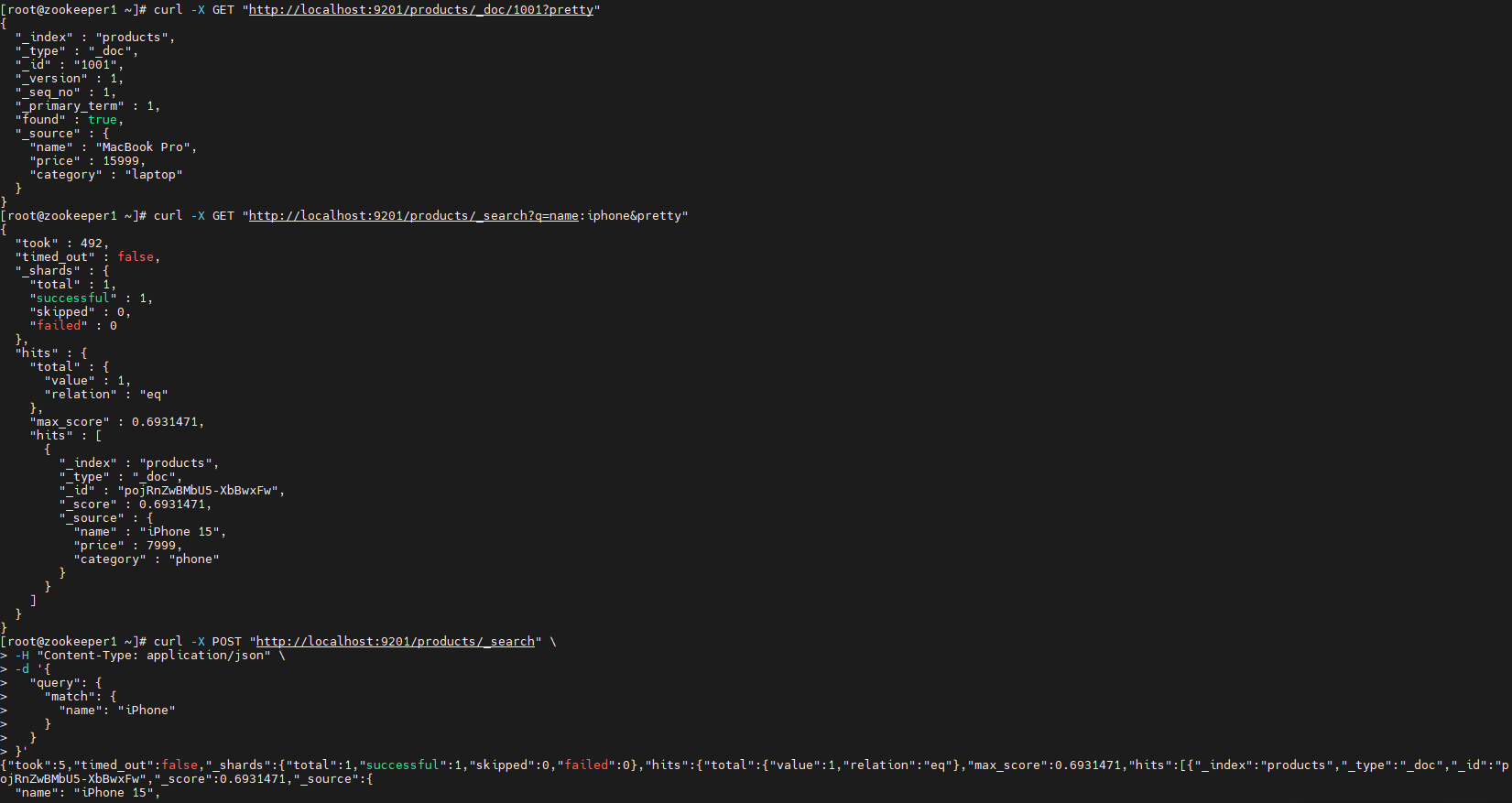
根据ID查询:
shell
curl -X GET "http://localhost:9201/products/_doc/1001?pretty"全文搜索(简单查询):
shell
curl -X GET "http://localhost:9201/products/_search?q=name:iphone&pretty"使用Query DSL(推荐):
shell
curl -X POST "http://localhost:9201/products/_search" \
-H "Content-Type: application/json" \
-d '{
"query": {
"match": {
"name": "iPhone"
}
}
}'
也可以使用浏览器搜索:192.168.42.140:9201/products/_search

4.6更新文档
shell
curl -X POST "http://localhost:9201/products/_doc/1001/_update" \
-H "Content-Type: application/json" \
-d '{
"doc": {
"price": 14999
}
}'更新后

4.7删除文档或索引
删除文档:
shell
curl -X DELETE "http://localhost:9201/products/_doc/1001"删除整个索引:
shell
curl -X DELETE "http://localhost:9201/products"
在去网页搜索发现报错是空的,代表删除成功:192.168.42.140:9201/products/_search

那么问题来了,假设你在本地开发了一套基于Elasticsearch的搜索系统(比如商品搜索、日志分析等),运行在你自己的电脑上(localhost:9201).
现在你想:
- 让同事访问你的Elasticsearch接口进行联调?
- 把本地数据展示给远程客户看?
- 在公网测试一个依赖ES的Web应用?
但你的电脑在内网,没有公网IP,也没有服务器.这时候,传统方式需要配置路由器、DDNS、端口映射......非常麻烦,甚至不可行.
解决方案:用cpolar内网穿透!
5.安装cpolar实现随时随地开发
5.1什么是cpolar?
cpolar是一款安全高效的内网穿透工具,无需公网IP或复杂配置,只需一条命令,即可将本地服务器、Web服务或任意端口映射到公网,让你随时随地远程访问内网应用,特别适合开发调试、远程运维和应急部署等场景.
5.2部署cpolar
cpolar 可以将你本地电脑中的服务(如 SSH、Web、数据库)映射到公网.即使你在家里或外出时,也可以通过公网地址连接回本地运行的开发环境.
❤️以下是安装cpolar步骤:
使用一键脚本安装命令:
shell
sudo curl https://get.cpolar.sh | sh
安装完成后,执行下方命令查看cpolar服务状态:(如图所示即为正常启动)
shell
sudo systemctl status cpolar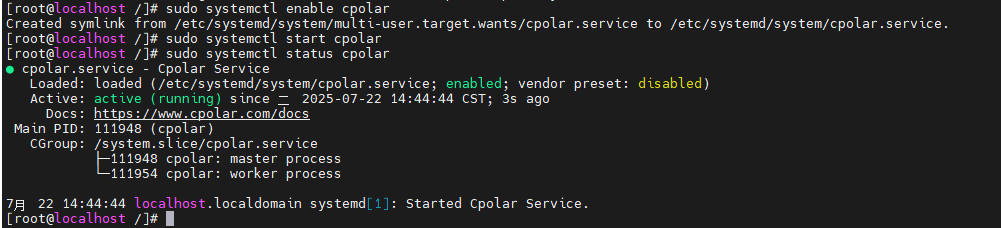
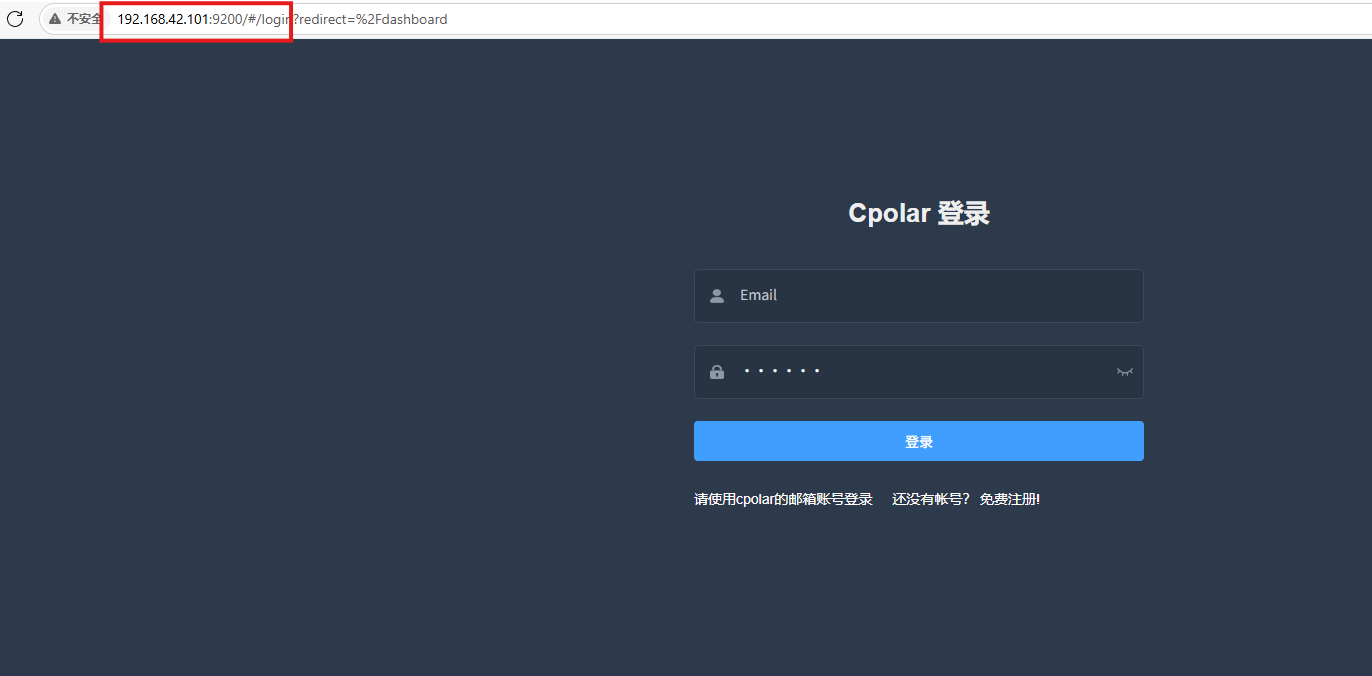
Cpolar安装和成功启动服务后,在浏览器上输入虚拟机主机IP加9200端口即:【http://ip:9200】访问Cpolar管理界面,使用Cpolar官网注册的账号登录,登录后即可看到cpolar web 配置界面,接下来在web 界面配置即可:
打开浏览器访问本地9200端口,使用cpolar账户密码登录即可,登录后即可对隧道进行管理.
6.配置公网地址
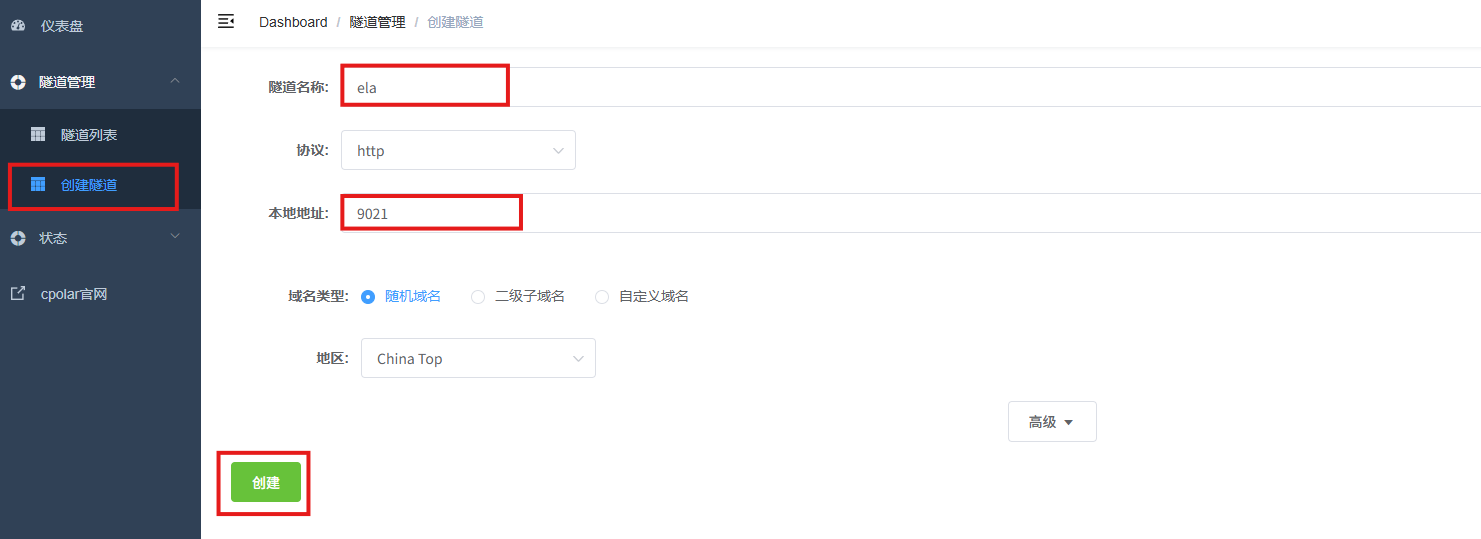
登录cpolar web UI管理界面后,点击左侧仪表盘的隧道管理------创建隧道:
- 隧道名称:可自定义,本例使用了:ela,注意不要与已有的隧道名称重复
- 协议:http
- 本地地址:9201
- 域名类型:随机域名
- 地区:选择China Top
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了公网地址,接下来就可以在其他电脑或者移动端设备(异地)上,使用地址访问.
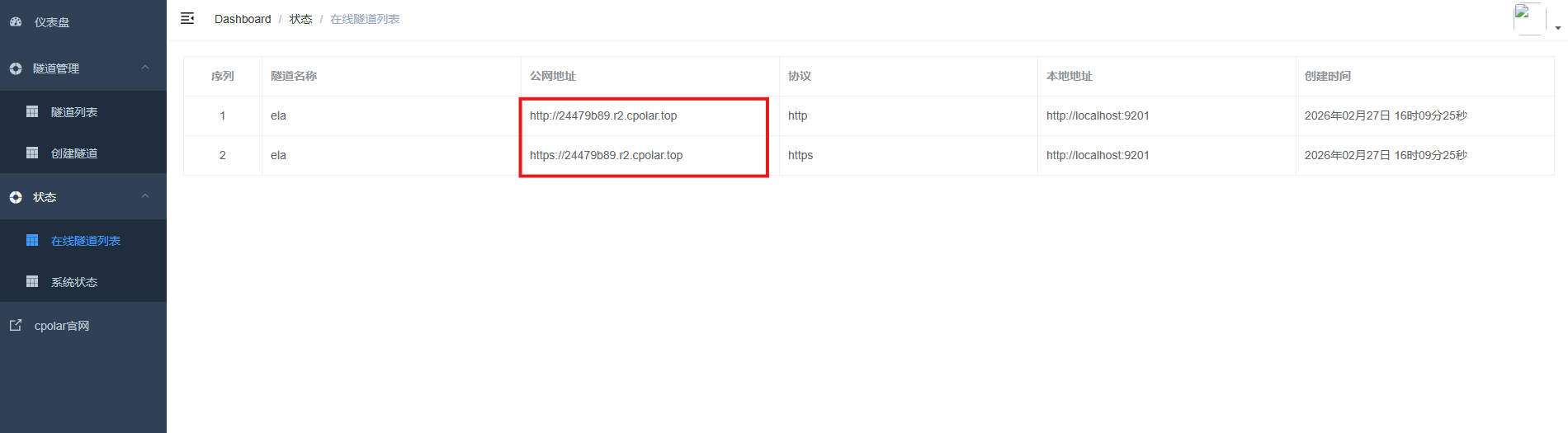
访问成功.
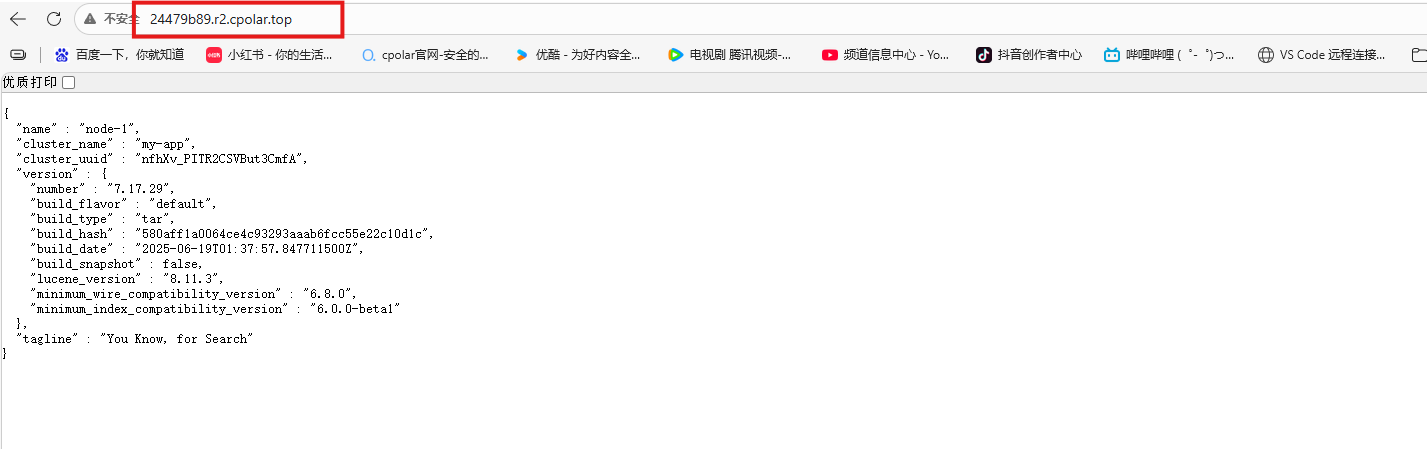
接下来可以尝试一下,在同事电脑创建索引~
shell
curl -X PUT "http://24479b89.r2.cpolar.top/products?pretty"
网页更新成功.
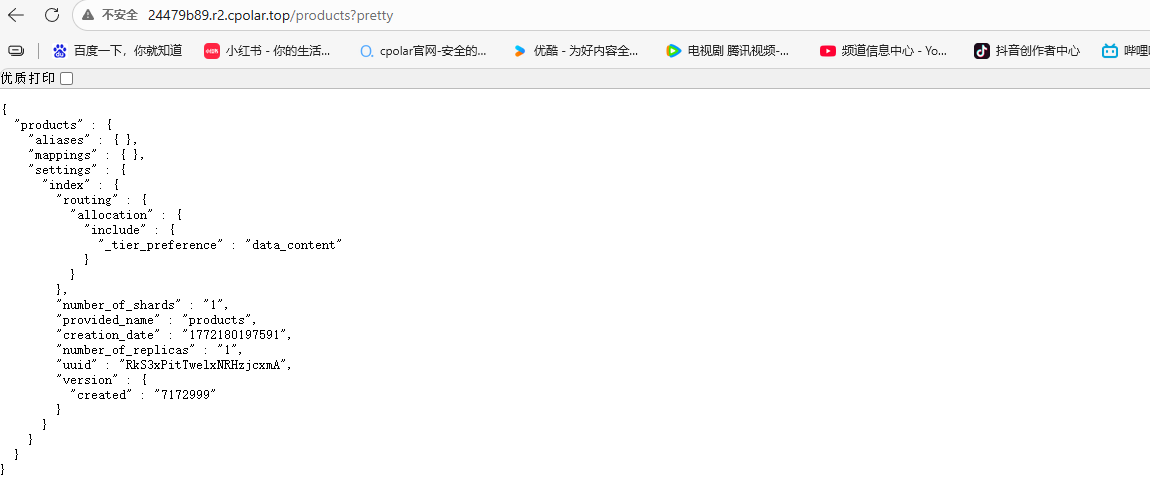
7.保留固定公网地址
使用cpolar为其配置二级子域名(cpolar官网-安全的内网穿透工具 | 无需公网ip | 远程访问 | 搭建网站),该地址为固定地址,不会随机变化.
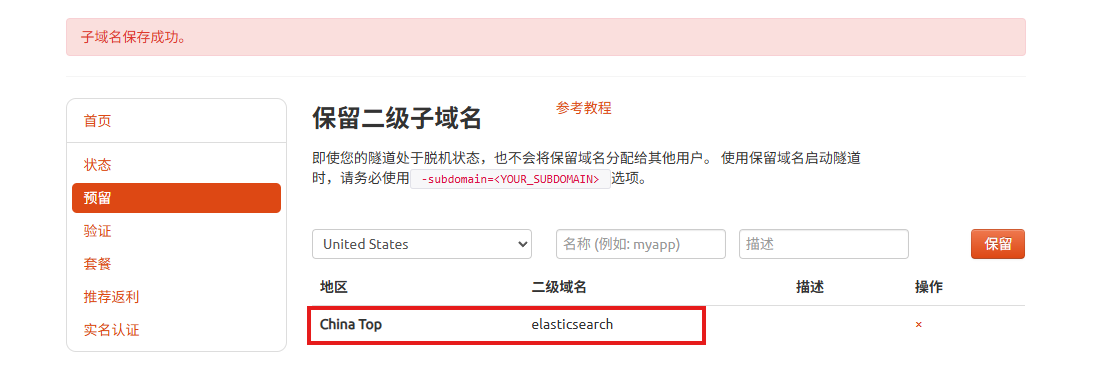
点击左侧的预留,选择保留二级子域名,地区选择china Top,然后设置一个二级子域名名称,我使用的是elasticsearch,大家可以自定义.填写备注信息,点击保留.
登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理------隧道列表,找到所要配置的隧道,点击右侧的编辑.
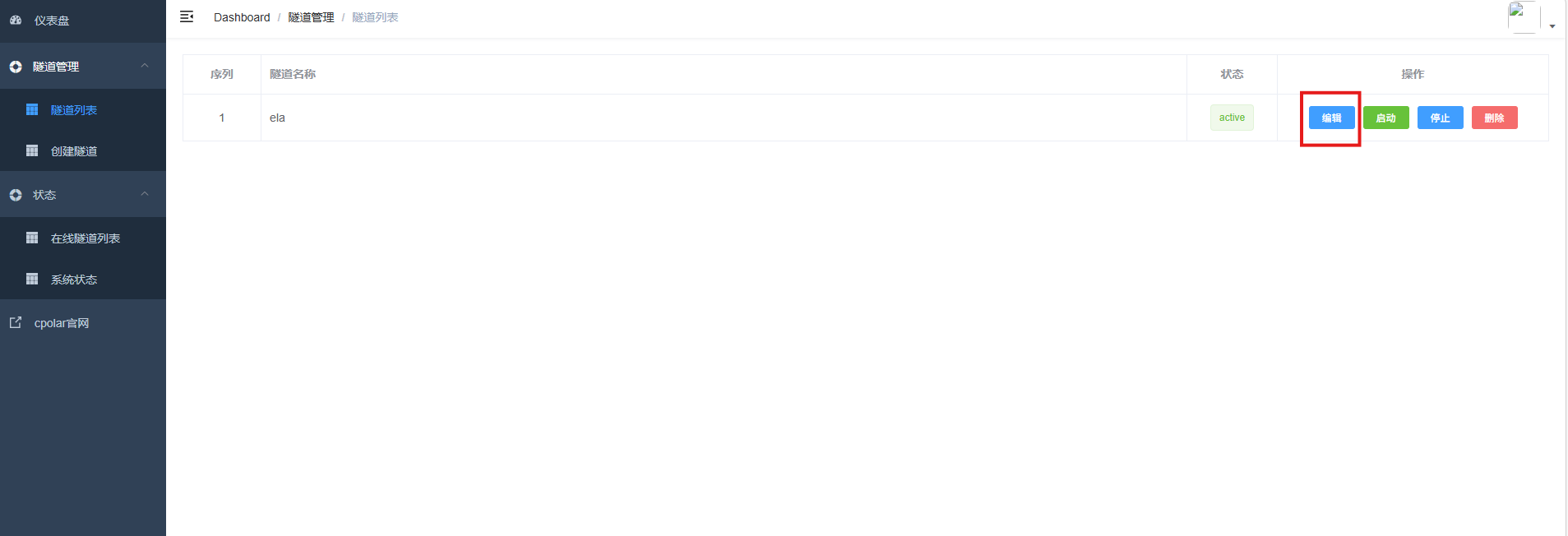
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
- 地区: China Top
点击更新
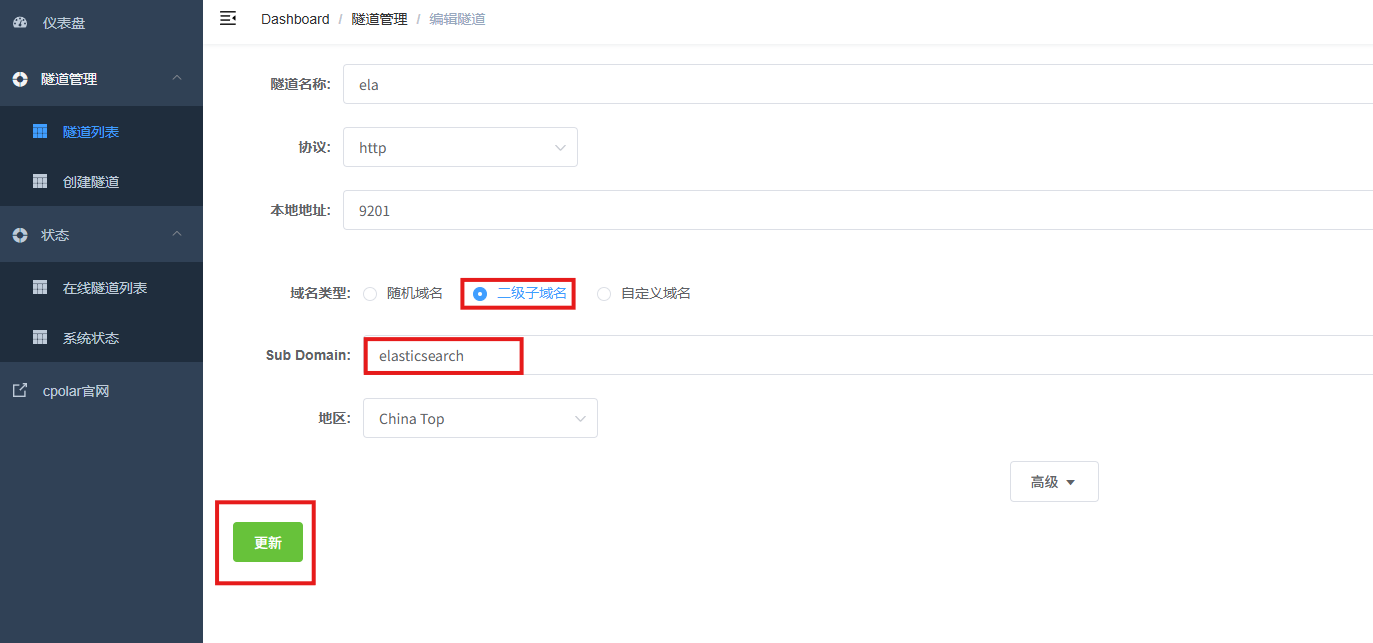
更新完成后,打开在线隧道列表,此时可以看到随机的公网地址已经发生变化,地址名称也变成了保留和固定的二级子域名名称.
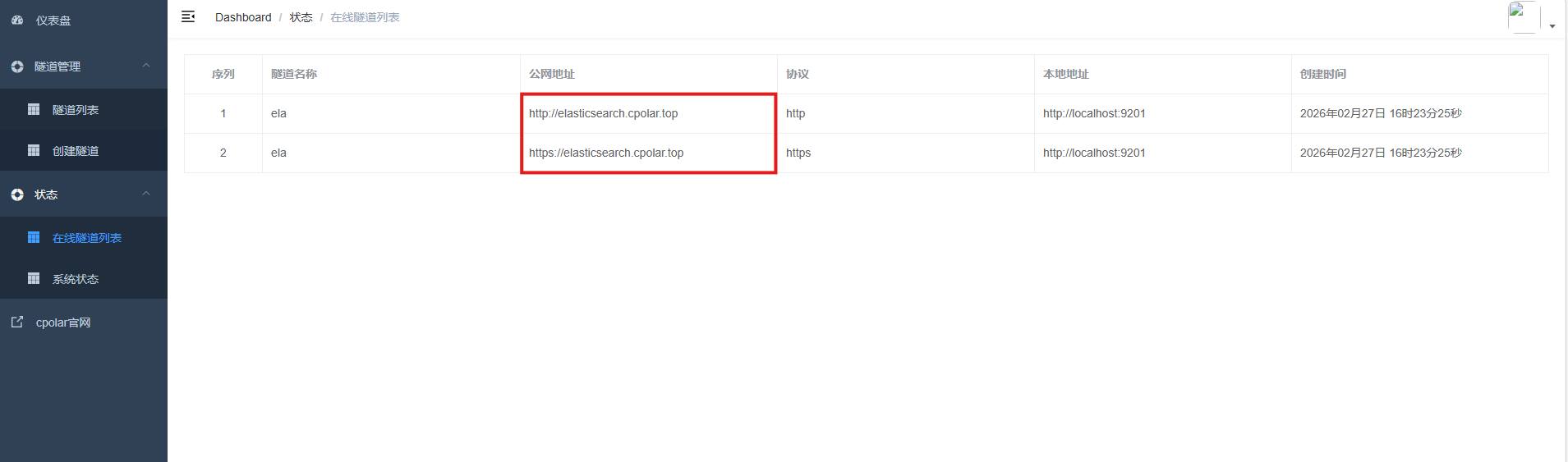
最后,我们使用固定的公网地址在任意设备的浏览器中访问,可以看到成功访问的页面,这样一个永久不会变化的二级子域名公网网址即设置好了.
8.总结
搭完之后跑一套基础验证:创建索引、写几条文档、查一下、看能不能跑通.集群健康状态用 /_cluster/health?pretty 看,status 变 green 就说明正常了.
如果需要远程访问或者异地联调,cpolar 配一条隧道指向 9201 端口,生成公网地址就能直接访问.固定二级子域名配好之后地址不会变,适合长期跑测试或者给客户演示用.
整个部署环节最值得注意的还是那几个系统级限制:max_map_count、文件描述符、用户权限.ES 启动报各种奇奇怪怪的错,十有八九是这三个地方没配到位.其他都按部就班来就行,没什么特别需要绕的地方.

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容的更新
每日心灵鸡汤:记住,别再等某个方长,人生只在此刻发生!
中国人好像不喜欢眼前的幸福,当我们说我们要去旅游的时候,父母可能就会说,趁你现在年轻,你就应该要多赚钱,不要去贪图享乐,不要去玩,多做点,好像我们一直都在等一直等等,一个没有人许诺你的未来.回头看,我非常希望能够告诉大家,不要等.其实我非常讨厌四个字叫做来日方长.后来才开始明白,我们真正拥有的,其实只有今天,只有这个当下.我相信很多人都听过一句话,叫做:欲买桂花同载酒,终不似少年游.
