HDFS(Hadoop Distributed File System)是Hadoop生态系统的核心组件,专为海量数据存储 设计,具有高容错性、高扩展性、高吞吐量 的特点。本次实验围绕HDFS的三大操作方式展开:Shell命令交互 、Web界面管理 和Java API编程,帮助你从命令行到代码层面全面掌握HDFS的使用。
一、HDFS架构概览
在深入实验之前,先了解HDFS的核心架构:
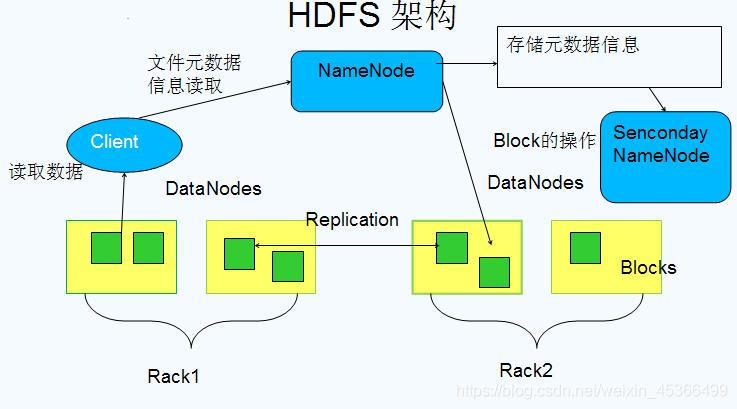
核心组件说明:
| 组件 | 角色 | 功能 |
|---|---|---|
| NameNode | 主节点 | 管理文件系统命名空间,维护元数据(文件目录树、文件属性、块位置映射) |
| DataNode | 从节点 | 存储实际的数据块(Block),执行数据的读写操作 |
| Secondary NameNode | 辅助节点 | 定期合并FsImage和EditLog,减轻NameNode负担 |
| Client | 客户端 | 通过NameNode获取元数据,直接与DataNode交互读写数据 |
关键特性:
- 分块存储:默认128MB/块,适合大文件存储
- 多副本机制:默认3副本,保证数据可靠性
- 一次写入多次读取:不支持随机写,适合批处理场景
🖥️ 实验一:Shell命令与HDFS交互
1.1 环境准备
确保Hadoop集群已启动,可通过以下命令检查:
bash
jps
# 应看到 NameNode、DataNode、SecondaryNameNode 等进程1.2 文件上传命令
① -moveFromLocal:剪切粘贴到HDFS
bash
hadoop fs -moveFromLocal jdk-8u212-linux-x64.tar.gz /input/⚠️ 注意 :执行后本地文件
jdk-8u212-linux-x64.tar.gz会消失 ,相当于mv操作。
② -copyFromLocal:拷贝到HDFS
bash
hadoop fs -copyFromLocal hadoop-3.1.3.tar.gz /input/✅ 执行后本地文件
hadoop-3.1.3.tar.gz仍然存在 ,相当于cp操作。
③ -put:等同于copyFromLocal(生产环境常用)
bash
hadoop fs -put localfile.txt /input/💡 生产环境更习惯用
-put,因为它更简洁,且支持从标准输入读取数据。
④ -appendToFile:追加文件到已有文件末尾
bash
hadoop fs -appendToFile local.txt /input/word.txt⚠️ 踩坑记录 :曾因HDFS路径写错导致追加失败,通过
-ls查看目录结构后修正路径才成功。养成操作前验证路径的习惯!
1.3 文件下载命令
① -copyToLocal:从HDFS拷贝到本地
bash
hadoop fs -copyToLocal /input/word.txt ./local.txt② -get:等同于copyToLocal(生产环境常用)
bash
hadoop fs -get /input/word.txt ./local.txt1.4 直接操作命令
① -ls:显示目录信息
bash
hadoop fs -ls /
hadoop fs -ls /input② -cat:显示文件内容
bash
hadoop fs -cat /input/word.txt③ -tail:显示文件末尾1KB数据
bash
hadoop fs -tail /input/word.txt④ -mkdir:创建路径
bash
hadoop fs -mkdir /dd
hadoop fs -mkdir -p /dd/subdir # 递归创建⑤ -cp:HDFS内部拷贝
bash
hadoop fs -cp /input/word.txt /dd/word.txt⑥ -mv:HDFS内部移动/重命名
bash
hadoop fs -mv /dd/word.txt /dd/word_new.txt⑦ -rm:删除文件
bash
hadoop fs -rm /dd/word_new.txt⑧ -rm -r:递归删除目录及内容
bash
hadoop fs -rm -r /dd⑨ -du:统计文件夹大小信息
bash
hadoop fs -du -h /input⑩ -setrep:设置文件副本数量
bash
hadoop fs -setrep 2 /input/word.txt # 设置副本数为2⑪ 权限管理命令
bash
hadoop fs -chmod 777 /input/word.txt
hadoop fs -chown lyq:lyq /input/word.txt💡 用法与Linux系统完全一致,降低了学习成本。
1.5 Shell命令速查表
| 命令 | 功能 | 本地文件是否保留 |
|---|---|---|
-moveFromLocal |
剪切上传到HDFS | ❌ 删除 |
-copyFromLocal / -put |
拷贝上传到HDFS | ✅ 保留 |
-copyToLocal / -get |
从HDFS下载 | ✅ 保留 |
-appendToFile |
追加本地文件到HDFS文件 | ✅ 保留 |
-cp |
HDFS内部拷贝 | - |
-mv |
HDFS内部移动 | - |
-rm -r |
递归删除 | - |
🌐 实验二:Web界面管理HDFS
2.1 访问方式
在浏览器地址栏输入:
http://hadoop101:9870📌 Hadoop 3.x默认端口为9870 ,Hadoop 2.x为50070
2.2 Web界面功能展示
Web界面核心功能:
| 菜单 | 功能说明 |
|---|---|
| Overview | 查看NameNode状态、版本、启动时间、集群ID等概览信息 |
| Datanodes | 查看所有DataNode状态、容量、已用空间、剩余空间 |
| Datanode Volume Failures | 查看磁盘故障信息 |
| Snapshot | 管理目录快照 |
| Startup Progress | 查看NameNode启动进度 |
| Utilities → Browse the file system | 浏览文件目录,查看文件大小、副本数、修改时间、块信息 |
| Utilities → Logs | 查看HDFS日志 |
2.3 实际应用场景
通过Web界面浏览/input目录时,可以直接看到:
- 文件大小
- 副本数量(Replication)
- 修改时间
- 块大小(Block Size)
- 块位置信息
💡 实验心得:Web界面比命令行输出更直观,方便快速验证Shell命令和API操作的结果,极大提升了实验效率!
☕ 实验三:Java API与HDFS交互
3.1 Maven依赖配置
在pom.xml中添加Hadoop客户端依赖:
xml
<dependencies>
<!-- Hadoop Common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<!-- HDFS Client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<!-- Hadoop Client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>⚠️ 踩坑记录 :必须准确引入
hadoop-client等核心包,否则会出现ClassNotFoundException错误!
3.2 获取FileSystem对象
所有HDFS操作都通过FileSystem类完成,需要先建立连接:
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class HDFSClient {
public static void main(String[] args) throws Exception {
// 1. 创建配置对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop101:8020");
// 2. 获取FileSystem对象
FileSystem fs = FileSystem.get(
new URI("hdfs://hadoop101:8020"),
conf,
"lyq" // 用户名
);
// 3. 关闭资源
fs.close();
}
}3.3 核心操作代码详解
① 创建文件夹 mkdirs()
java
// 创建/dd目录(递归创建父目录)
fs.mkdirs(new Path("/dd"));
System.out.println("文件夹创建成功!");② 上传文件 copyFromLocalFile()
java
// 将Windows本地文件上传到HDFS
fs.copyFromLocalFile(
new Path("D:/Desktop/dd.txt"), // 本地路径
new Path("/dd/") // HDFS目标路径
);
System.out.println("文件上传成功!");📌 参数说明:第一个Path是本地文件系统路径,第二个Path是HDFS路径。
③ 下载文件 copyToLocalFile()
java
// 将HDFS文件下载到Windows本地
fs.copyToLocalFile(
new Path("/dd/dd.txt"), // HDFS源路径
new Path("D:/Desktop/") // 本地目标路径
);
System.out.println("文件下载成功!");⚠️ 注意 :
copyToLocalFile默认会下载.crc校验文件,如需忽略可传入false参数:
javafs.copyToLocalFile(false, new Path("/dd/dd.txt"), new Path("D:/Desktop/"), true);
④ 文件更名 rename()
java
// 将/dd/dd.txt 改名为 /dd/aa.txt
fs.rename(
new Path("/dd/dd.txt"), // 旧路径
new Path("/dd/aa.txt") // 新路径
);
System.out.println("文件更名成功!");⑤ 删除文件夹 delete()
java
// 删除/tt文件夹(第二个参数true表示递归删除)
fs.delete(new Path("/tt"), true);
System.out.println("文件夹删除成功!");⚠️ 危险操作 :
delete(path, true)会递归删除目录及所有内容,且不可恢复!
⑥ 显示文件详情 listFiles()
java
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.fs.BlockLocation;
import java.util.Arrays;
// 获取/dd/目录下所有文件详情(true表示递归)
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/dd/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========" + fileStatus.getPath() + "=========");
System.out.println("权限: " + fileStatus.getPermission());
System.out.println("所有者: " + fileStatus.getOwner());
System.out.println("所属组: " + fileStatus.getGroup());
System.out.println("文件长度: " + fileStatus.getLen());
System.out.println("修改时间: " + fileStatus.getModificationTime());
System.out.println("副本数: " + fileStatus.getReplication());
System.out.println("块大小: " + fileStatus.getBlockSize());
System.out.println("文件名: " + fileStatus.getPath().getName());
// 获取块位置信息(分布式存储的核心!)
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println("块位置: " + Arrays.toString(blockLocations));
}输出示例:
========hdfs://hadoop101:8020/dd/aa.txt=========
权限: rw-r--r--
所有者: lyq
所属组: supergroup
文件长度: 1024
修改时间: 1699104000000
副本数: 3
块大小: 134217728
文件名: aa.txt
块位置: [0, 1024, hadoop102, hadoop103, hadoop104]💡 关键理解 :
BlockLocation数组展示了HDFS的分布式存储原理------一个文件被分成多个块,每个块存储在多个DataNode上!
⑦ 创建文件 create()
java
// 在/dd/目录下创建dd.txt文件(空文件)
fs.create(new Path("/dd/dd.txt"));
System.out.println("文件创建成功!");📌 也可以写入内容:
javaFSDataOutputStream fos = fs.create(new Path("/dd/hello.txt")); fos.write("Hello HDFS!".getBytes()); fos.close();
⑧ 判断文件/文件夹 listStatus()
java
import org.apache.hadoop.fs.FileStatus;
// 查看/dd/目录下所有文件和文件夹
FileStatus[] listStatus = fs.listStatus(new Path("/dd"));
for (FileStatus fileStatus : listStatus) {
if (fileStatus.isFile()) {
System.out.println("f:" + fileStatus.getPath().getName()); // 文件标记f
} else {
System.out.println("d:" + fileStatus.getPath().getName()); // 文件夹标记d
}
}输出示例:
f:aa.txt
f:dd.txt
d:subdir3.4 Java API操作速查表
| 方法 | 功能 | 关键参数 |
|---|---|---|
mkdirs(Path) |
创建目录 | HDFS路径 |
copyFromLocalFile(Path, Path) |
上传文件 | 本地路径 → HDFS路径 |
copyToLocalFile(Path, Path) |
下载文件 | HDFS路径 → 本地路径 |
rename(Path, Path) |
重命名/移动 | 旧路径 → 新路径 |
delete(Path, boolean) |
删除 | 路径 + 是否递归 |
listFiles(Path, boolean) |
遍历文件详情 | 路径 + 是否递归 |
listStatus(Path) |
查看目录状态 | 路径 |
create(Path) |
创建文件 | HDFS路径 |
📝 实验心得与总结
🎯 核心收获
| 维度 | 收获 |
|---|---|
| Shell命令 | 掌握hadoop fs系列命令,理解-moveFromLocal与-copyFromLocal的本质区别(剪切vs拷贝) |
| Web界面 | 可视化查看集群状态,快速验证操作结果,提升调试效率 |
| Java API | 深入理解FileSystem编程模型,通过BlockLocation直观感受分布式存储原理 |
🔧 踩坑记录
- 路径错误 :使用
-appendToFile时因HDFS路径写错导致失败 → 操作前先用-ls验证路径 - 依赖缺失 :Maven未引入
hadoop-client导致ClassNotFoundException→ 仔细检查pom.xml依赖完整性 - 权限问题 :Web UI或API操作因权限不足失败 → 注意
-chown和-chmod的正确使用
🧠 设计思想理解
通过本次实验,深刻理解了HDFS的分布式设计哲学:
- 多副本冗余:默认3副本,即使2个节点故障数据依然安全
- 块存储机制:大文件分块存储,提升并行读写效率
- 元数据与数据分离:NameNode管目录,DataNode管数据,各司其职