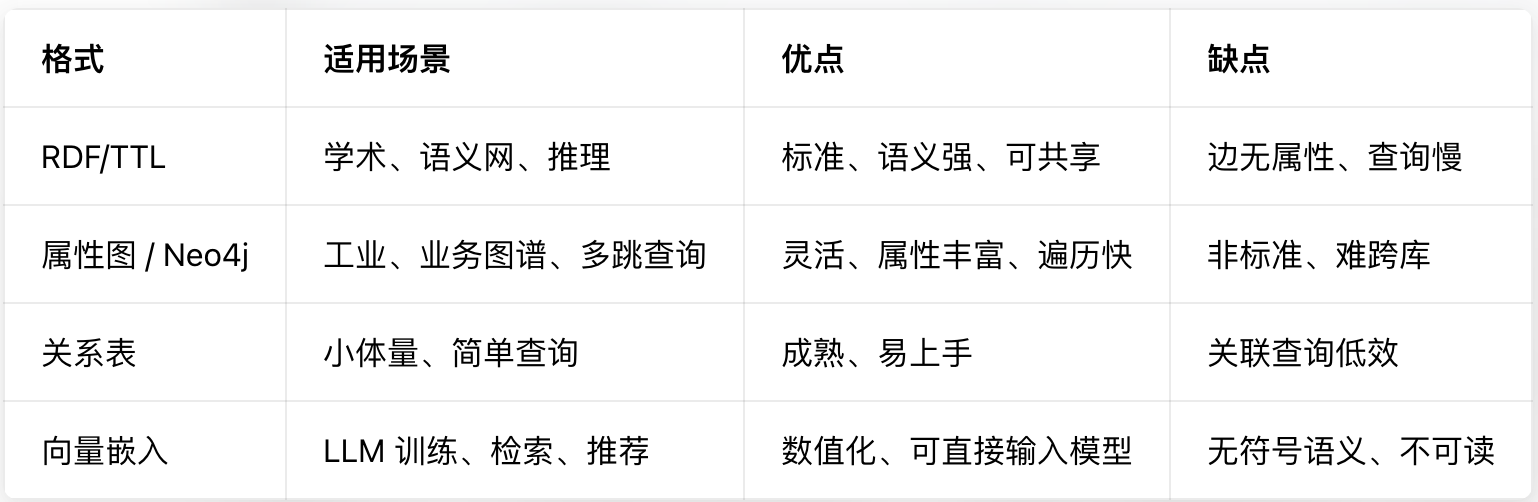
知识图谱在模型侧(含训练 / 推理、存储与交换、以及输入大模型的向量格式)主要分三类:符号化三元组(RDF / 属性图)、结构化文本 / JSON、嵌入向量(Embedding)。
一、核心数据模型(存储的逻辑格式)
- RDF 三元组(学术 / 标准)
格式:(主体 Subject, 谓词 Predicate, 客体 Object),简称 SPO。示例:
(马云, 是创始人, 阿里巴巴)
(阿里巴巴, 总部位于, 杭州)
特点:W3C 标准,国际通用;语义强、支持推理;但是边不能直接带属性。RDF 的关系只能是一个名字,不能像 Neo4j 那样给关系直接加年份、分值、类型等附加字段。Neo4j 可以创建类似马云 --创立年份:1999--> 阿里巴巴;直接添加年份等形式的附加字段,但是如果使用RDF三元组,则需要使用两条三元组来进行表述,例如(马云 创立 阿里巴巴)和(创立事件 发生年份 1999)。
常用的序列化文件格式:
.nt(N-Triples):每行一个三元组,无冗余,适合批量处理。
.ttl(Turtle):可读性好,支持前缀缩写。
.jsonld:JSON+RDF,Web 友好。
- 属性图(工业界 / 图数据库,如 Neo4j)
格式:节点 (实体,标签,属性) + 边 (关系,属性)。
节点: 马云 {标签:人物, 年龄:59}
边: 马云 -创始人, 年份:1999-> 阿里巴巴
特点:节点和边都能挂多个属性,贴近业务,查询快。
常用文件:.graphml、.csv(节点 / 边分表)、.json。
- 关系数据库表(传统存储)
三元组表:(s,p,o) 三列表,最简单但查询慢。
属性表:实体一行,属性多列(如:人物 (姓名,年龄,国籍))。
水平表 / 垂直划分:按类型分表,提升查询效率。
二、从知识图谱到graphRAG
把知识图谱直接给到大模型,大模型自身是很难高效利用已有的图谱知识结构的,大模型是序列模型,天然擅长连续文本和自然语言;相比较下并不擅长:图结构遍历、路径搜索、多跳关联、拓扑推理;海量离散三元组的全局关联建模;因此Graph RAG 就是为解决这个问题诞生。
-
普通 RAG vs Graph RAG 核心区别
普通 RAG:切块文档 → 向量相似度检索 → 塞给大模型,只能做到「关键词相似」,完全没有关系、逻辑、链路
Graph RAG:
把知识固化成 实体节点 + 关系边 的图结构,检索时不是向量瞎搜,而是先找实体 → 再遍历关系 → 抓取关联路径 / 子图 → 再喂给大模型
-
Graph RAG 标准处理流程
步骤 1:图谱结构化入库
把你的 JSON:
entities → 存入图数据库节点(人物 / 企业 / 地点)
relations → 存入图数据库有向边(所属、总部、隶属、创立)
存储载体:Neo4j、Nebula、Dgraph、轻量图结构索引
步骤 2:用户问题 → 实体抽取
大模型 / 实体链接模型,从问题里抠出关键实体
例如针对问题:华为创始人所在关联的省份有哪些?抽取实体:华为、任正非
步骤 3:图检索(核心!区别普通 RAG)
在图中命中「任正非、华为」节点
按关系向外多跳遍历:任正非 → 创立 → 华为;华为 → 总部 → 深圳;深圳 → 隶属 → 广东
裁剪出和问题强相关的局部子图
步骤 4:子图结构化压缩
把遍历出来的小范围关联图谱,整理成干净三元组 / 结构化文本:
plaintext:任正非 创立 华为;华为 总部位于 深圳市;深圳市 隶属于 广东省
步骤 5:送入大模型生成答案
大模型拿到浓缩、有关联、有链路的结构化知识,轻松完成:多跳推理、溯源、链路拆解、因果分析。
三、实际工业使用
实际工业使用中会综合多种检索方式,即混合检索,核心的解决问题思想是互补兜底。
| 检索类型 | 核心能力 | 负责场景 |
|---|---|---|
| 稠密向量 Embedding | 语义理解、上下文、同义、模糊 | 泛化问答、语义类问题 |
| BM25 稀疏检索 | 关键词、实体、术语、精准词 | 专有名词、专业内容、硬匹配 |
| 结构化检索 | 字段过滤、图谱关系、条件筛选 | 知识图谱、表格、业务结构化数据 |
整体架构:
分词 / 实体抽取 → 多路并行检索(向量 + BM25 + 结构化)→ 结果融合 → 重排序 Rerank → 上下文拼接 → LLM 生成
分步拆解
- 文档预处理层
通用文本:分词、分块、清洗
知识图谱数据:实体 / 关系单独建结构化索引
同时构建两套索引:
向量库:Chunk Embedding 存入 Milvus/FAISS/ES-dense
稀疏倒排库:全文分词,构建 BM25 索引(Elasticsearch/Whoosh) - 问题预处理
问句分词、关键词提取、实体识别
拆分:语义问题 + 关键实体 / 术语 - 多路并行检索(核心)
向量检索:问句 Embedding → 向量库 Top-K 召回
BM25 检索:问句关键词 → 全文倒排索引 Top-K 召回
结构化检索(图谱场景):
抽取实体 / 关系 → 图数据库 / 结构化索引精准过滤 - 多路结果融合(Reciprocal Rank Fusion RRF)
不用简单拼接,用RRF 算法加权融合:
避免单一检索偏科
向量高分 + BM25 高分的内容优先保留
解决「向量召回垃圾、关键词漏召回」问题 - 重排序 Rerank
用轻量交叉编码器模型(BGE-Rerank、Cohere Rerank)
对融合后的候选片段精细打分,筛选最相关上下文 - 大模型生成
把高质量、强相关的上下文送入 LLM,最终回答
四、BM25的算法原理
BM25 检索原理 通俗+公式+完整拆解
BM25 是改进版 TF-IDF ,目前 RAG 稀疏检索、全文检索工业界事实标准,专门解决 TF-IDF 的缺陷:词频无限叠加、文档长度不敏感、长尾词权重不合理。
一、先搞懂 3 个基础概念
1. TF (Term Frequency)词频
TF(t,d)TF(t,d)TF(t,d)
词汇 ttt 在当前文档 ddd 里出现的次数。
关键词出现越多,和问题越相关。
2. IDF (IDF:Inverse Document Frequency )逆文档频率
IDF(t)IDF(t)IDF(t)
词汇在全局所有文档里稀有程度。
- 冷门专业词(Lidar、QAR):IDF 高,权重极高
- 通用停用词(的、是、和):IDF 极低,几乎无权重
3. 文档长度
BM25 核心优化点:惩罚长文档、优待紧凑短文档
TF-IDF 缺陷:长文档随便堆词,分数天然更高,不合理。
二、BM25 核心公式(最常用 BM25 Okapi)
单词条 ttt 对文档 ddd 的得分:
score(t,d)=IDF(t)⏟稀有度权重×TF(t,d)⋅(k1+1)⏞词频饱和上限TF(t,d)+k1⋅(1−b+b⋅∣d∣avgdl)⏟文档长度归一化惩罚 \text{score}(t,d) = \underbrace{IDF(t)}{\text{稀有度权重}} \times \frac {\overbrace{TF(t,d)\cdot (k_1+1)}^{\text{词频饱和上限}}} {\underbrace{TF(t,d) + k_1 \cdot \big(1-b + b\cdot \frac{|d|}{\text{avgdl}}\big)}{\text{文档长度归一化惩罚}}} score(t,d)=稀有度权重 IDF(t)×文档长度归一化惩罚 TF(t,d)+k1⋅(1−b+b⋅avgdl∣d∣)TF(t,d)⋅(k1+1) 词频饱和上限
整体文档得分 = 问句所有关键词得分累加
三、逐段拆解关键参数(超好懂)
1. k1k_1k1:词频饱和系数(一般取值 1.2 ~ 2.0)
- 作用:限制词频无限暴涨
- TF-IDF 问题:一个词重复100遍,分数无限涨
- BM25:词频涨到一定程度就饱和封顶,杜绝恶意堆砌关键词
实际意义:关键词出现 3次 和 30次,分数差距不会离谱拉大
2. bbb:文档长度平衡系数(一般取 0.75)
- b∈0,1b \in 0,1b∈0,1
- ∣d∣\boldsymbol{|d|}∣d∣:当前文档长度
- avgdl\boldsymbol{\text{avgdl}}avgdl:全部文档平均长度
逻辑:
- b=1b=1b=1:完全参考文档长度,严格惩罚长文档
- b=0b=0b=0:完全忽略文档长度,退化成无长度约束模型
3. IDF 改良公式(BM25 专用)
IDF(t)=ln(N−df(t)+0.5df(t)+0.5+1) IDF(t) = \ln\left( \frac{N - df(t) + 0.5}{df(t) + 0.5} + 1 \right) IDF(t)=ln(df(t)+0.5N−df(t)+0.5+1)
- NNN:总文档数
- df(t)df(t)df(t):包含词 ttt 的文档数量
改良亮点:
- 避免 IDF 出现负数(TF-IDF 高频词会负分)
- 平滑处理,防止生僻词/新词计算异常
四、BM25 对比 TF-IDF 核心优势
-
词频饱和
TF-IDF:词越多分越高 ❌
BM25:词频到达阈值不再加分 ✅
-
文档长度归一化
长文档天然降权,不会因为字数多无脑排前面 ✅
-
IDF 平滑稳定
高频通用词不会负分,检索更稳 ✅
-
适合短问句+长文档
完美匹配 RAG 场景:用户短句提问、知识库长文档检索
五、BM25 工作流程(RAG 落地视角)
-
建库阶段(离线)
- 全文档分词(中文:jieba/hanlp)
- 统计:每个词 TF、全局 DF、文档平均长度 avgdl
- 构建倒排索引:词语 → 包含该词的文档列表
-
检索阶段(在线)
- 用户问题分词,提取关键词
- 逐个关键词查倒排索引,命中候选文档
- 套 BM25 公式逐篇计算相关性分数
- 按分数从高到低排序,返回 Top-K
六、通俗大白话总结
- 一个词越少见(专业术语、专有名词),权重越高;
- 关键词在文档里适量出现最好,疯狂重复不加分;
- 同样关键词密度下:短文档 > 长文档;
- 只看关键词字面精准匹配,完全不懂语义、同义词、意译;
七、RAG 里为什么必须「BM25 + 向量Embedding」组合
| 维度 | BM25(稀疏检索) | Embedding向量(稠密检索) |
|---|---|---|
| 匹配逻辑 | 关键词字面精准 | 语义、上下文、同义、模糊 |
| 擅长内容 | 编号、术语、实体、人名、代码 | 口语提问、改写、理解类问题 |
| 缺点 | 不懂语义,换种说法搜不到 | 专有名词易被稀释、易幻觉召回 |
五、RRF(Reciprocal Rank Fusion,倒数排名融合
RRF(Reciprocal Rank Fusion,倒数排名融合) 是一种只靠排名、不靠原始分数 就能把多个排序列表合并成一个高质量列表的算法;在RAG/混合检索里是BM25+向量检索融合的标配。
一、核心定义与公式
- 全称:Reciprocal Rank Fusion(RRF)
- 用途:融合多个独立排序结果(如BM25、向量检索、多查询结果)
- 核心思想:在多个列表里都排得靠前的文档,最终得分更高
公式(标准):
RRF_score(d)=∑i=1n1k+ranki(d)\text{RRF\score}(d)=\sum{i=1}^{n}\frac{1}{k+\text{rank}_i(d)}RRF_score(d)=i=1∑nk+ranki(d)1
- (d):当前文档
- (n):参与融合的列表数
- ranki(d)\text{rank}_i(d)ranki(d):文档 ddd 在第 iii 个列表中的排名(从1开始)
- (k):平滑常数 (常用值 60,可调;作用:降低排名靠后的噪声、削弱极端高排名的主导)
二、为什么用RRF(解决什么问题)
混合检索(如BM25 + 向量检索)中常见痛点:
- 分数分布完全不一样:
- BM25:0~几十
- 向量余弦相似度:0~1
- 直接相加不可行:量纲不同、一个容易"盖住"另一个
- 归一化复杂、易失真
✅ RRF的解决方式:
- 扔掉原始分数,只看排名
- 排名越靠前,贡献的分数越大(倒数衰减)
- 多列表累加,共同靠前的文档自然上浮
三、假设两路检索结果(取前3):
- 列表A(BM25):
Doc1(第1)、Doc2(第2)、Doc3(第3) - 列表B(向量):
Doc2(第1)、Doc1(第2)、Doc4(第3)
取 (k=60),计算每个文档RRF分数:
-
Doc1:
160+1+160+2≈0.0164+0.0161=0.0325 \frac{1}{60+1}+\frac{1}{60+2}\approx0.0164+0.0161=0.0325 60+11+60+21≈0.0164+0.0161=0.0325 -
Doc2:
160+2+160+1≈0.0161+0.0164=0.0325 \frac{1}{60+2}+\frac{1}{60+1}\approx0.0161+0.0164=0.0325 60+21+60+11≈0.0161+0.0164=0.0325 -
Doc3:
160+3+0≈0.0159 \frac{1}{60+3}+0\approx0.0159 60+31+0≈0.0159 -
Doc4:
0+160+3≈0.0159 0+\frac{1}{60+3}\approx0.0159 0+60+31≈0.0159
最终排序:Doc1 ≈ Doc2 > Doc3 ≈ Doc4(在两路检索结果中都靠前的文档,融合后排名会更靠前)
四、关键特性(优缺点)
优点
- 无需归一化:不关心原始分数,只看位次,天然适配多源融合
- 简单稳定、少调参:仅 (k) 一个参数,默认60即很好用
- 公平融合:多个列表的贡献被平滑,不易被单一检索器主导
- 增强鲁棒性:个别列表排序波动影响小
缺点
- 完全抛弃原始分数信息:如果某检索器分数非常高(强相关),RRF无法利用这一点
- 排名"断层"不敏感:第1名和第2名差距远大于第10名和第11名,但RRF只看位次
- 对极端排名依赖 (k):(k) 太小易受噪声影响,太大则区分度下降
五、和其他融合方法对比
- 直接加权求和:依赖分数分布、需归一化、调参成本高
- CombMNZ:分数求和 × 出现次数,仍依赖原始分数
- Condorcet:两两比较,计算复杂、效率低
- RRF :仅用排名、公式简单、效果稳定、落地成本低(工业首选)
RRF是"用排名投票"的融合算法 :不看分数、只看位次,简单有效,是当前混合检索与RAG系统的标配融合方案。