
1、什么是归并排序?
归并排序是一种经典的分治算法,它的核心思想是:先拆后合。
分:将数组从中间一分为二,递归地对左右两部分进行排序。
合:将两个有序子数组合并成一个有序数组。
这种思路有点像打牌时整理手牌----把两堆已经排好序的牌合成一堆。
2、生活中的类比
假如你手中有两堆已经排好序的牌
第一堆:2,5,7,10
第二堆:1,3,8,11
要把它们合并成一堆有序的牌,你只需要每次比较两堆最上面的牌,取较小的那张。这就是归并排序的核心操作--和并两个有序数组。
一句话总结:递归分割+合并有序数组
3、核心思想:分而治之
归并排序的工作流程可以用四个字概括**:分--治--合**
图解过程:以数组8,4,5,7,1,3,6,2为例:

分(拆分):
把数组从中间分成两半
递归的对左右两半继续分割
直到每组只剩一个元素(单个元素天然有序)
治:(合并)
从最底层开始,两两合并有序数组
逐层向上,直到整个数组有序
4、归并排序递归实现详解
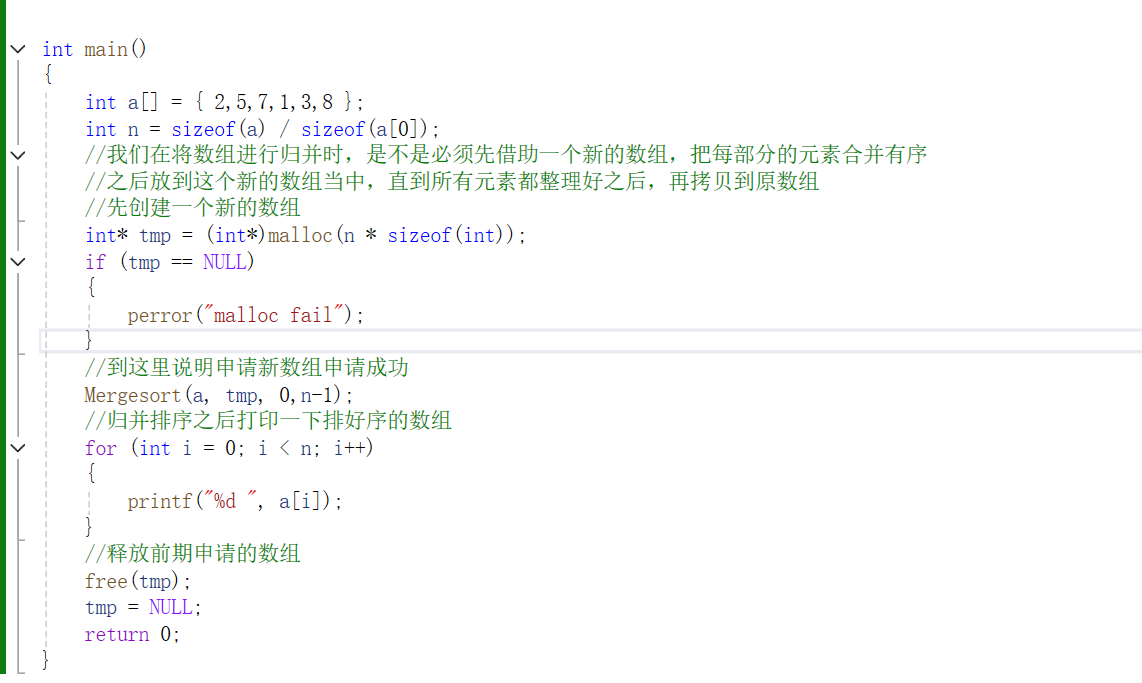
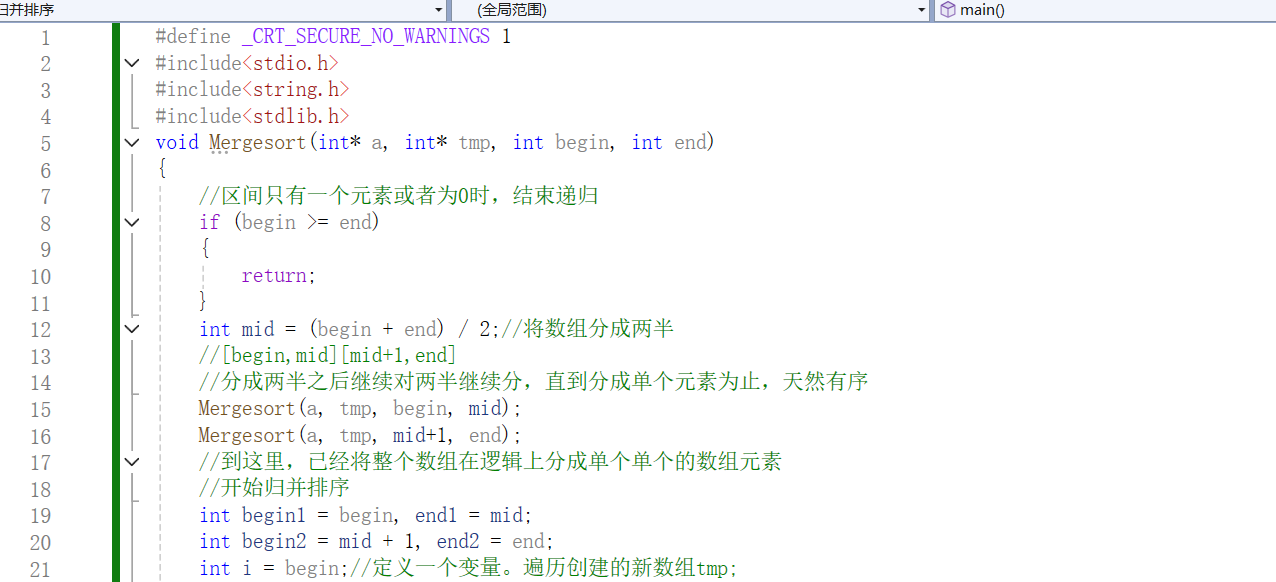
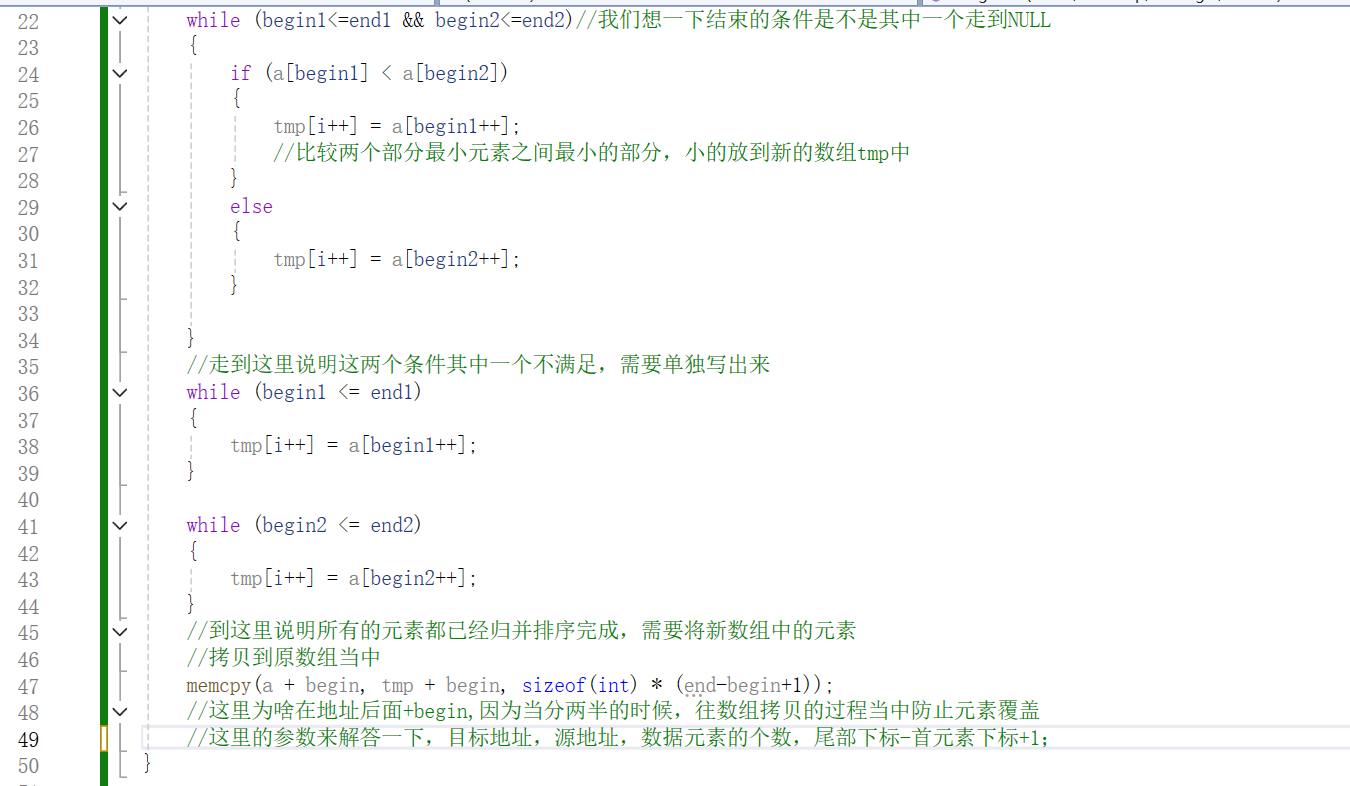
其实在Merge函数的最后隐藏了return函数,当执行一次Merge函数之后,又返回上一层函数,直到跳出递归条件
5、左右两部分递归的示意图
 这里的递归具体的步骤如下图所示
这里的递归具体的步骤如下图所示
da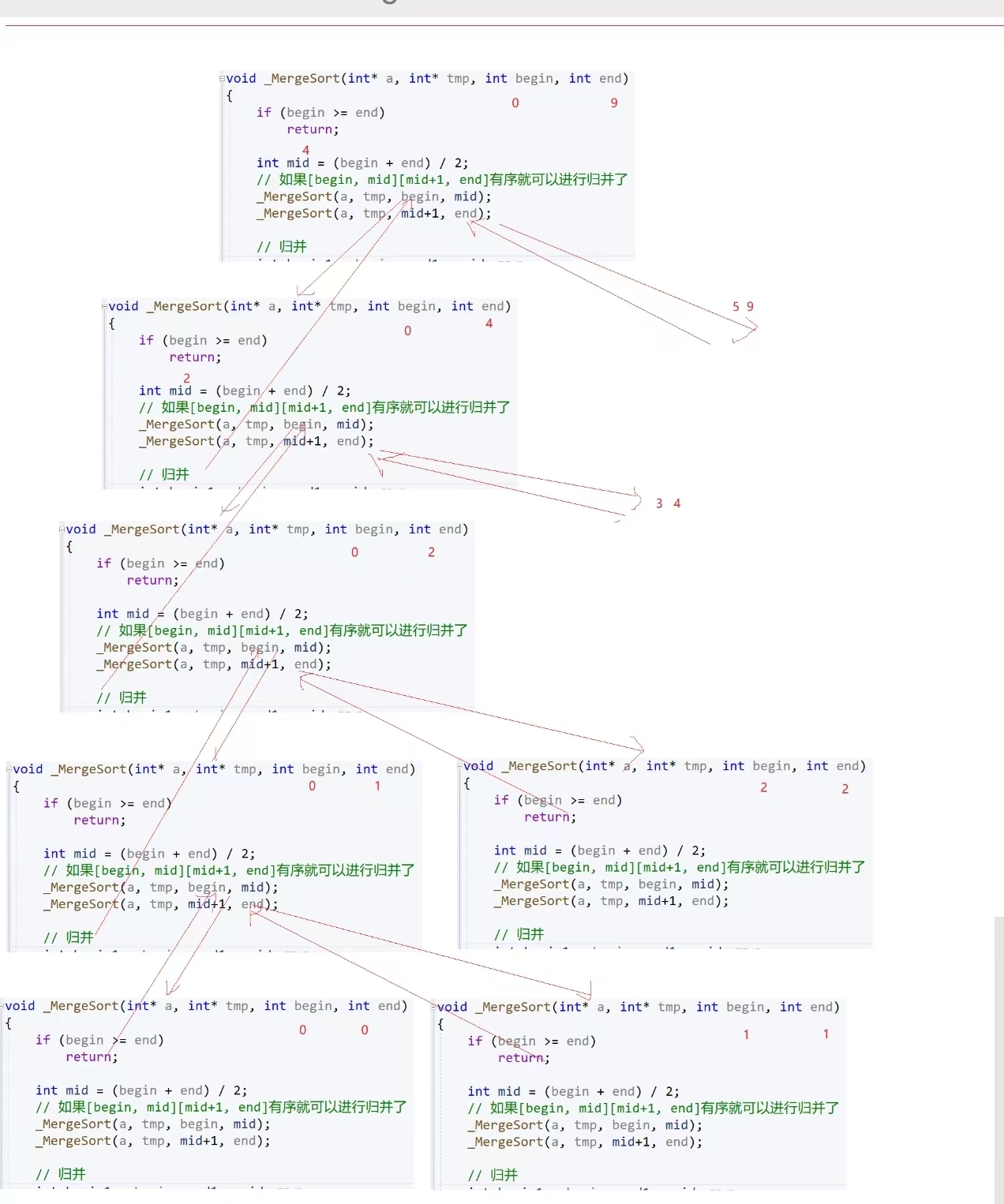
6、文字解说归并排序全过程
归并排序的递归过程可以通俗地理解为"先拆光,再逐层合并"。下面用文字完整叙述一遍。
一、准备阶段
有一个无序数组,例如 2, 5, 7, 1, 3, 8。
归并排序会申请一个同样大小的临时数组 tmp,用于存放合并过程中的有序结果。
然后调用递归函数 Mergesort(a, tmp, 0, 5),参数含义:对数组 a 的下标 0 到 5 这段区间进行排序。
二、递归拆分("递"的过程)
函数进入后,会做三件事:
-
如果当前区间长度 ≤ 1(即 begin >= end),则直接返回,不再拆分。
-
否则,计算中间点 mid = (begin+end)/2。
-
分别对左半区间 begin, mid 和右半区间 mid+1, end 递归调用自身。
这个过程就像一棵树从上往下生长,每次把区间切成两半,直到每个区间只剩一个元素。
以 2,5,7,1,3,8 为例(下标 0~5)
- 第一层:区间 0,5,长度 6 > 1,mid=2
· 调用左:Mergesort(0,2)
· 调用右:Mergesort(3,5)
- 左子树 0,2:长度 3 > 1,mid=1
· 调用左:Mergesort(0,1)
· 调用右:Mergesort(2,2)
- 0,1:长度 2 > 1,mid=0
· 调用左:Mergesort(0,0) → 长度 1,直接返回
· 调用右:Mergesort(1,1) → 长度 1,直接返回
- 2,2:长度 1,直接返回
至此,左半部分 0,2 的所有子区间都被拆到单个元素,并返回。
- 右子树 3,5:长度 3 > 1,mid=4
· 调用左:Mergesort(3,4)
· 调用右:Mergesort(5,5)
- 3,4:长度 2 > 1,mid=3
· 调用左:Mergesort(3,3) → 返回
· 调用右:Mergesort(4,4) → 返回
- 5,5:长度 1,返回
此时所有区间都被拆成单个元素,递归的"递"阶段结束。
三、合并排序("归"的过程)
当左右两边的递归调用都返回后,程序开始执行合并操作。
合并的前提是:左区间 begin, mid 和右区间 mid+1, end 已经各自有序(因为递归已经帮它们排好了)。
合并步骤如下:
- 用三个下标分别标记:
· begin1 指向左区间开头,end1 指向左区间结尾
· begin2 指向右区间开头,end2 指向右区间结尾
· i 指向临时数组 tmp 中当前要存放的位置(从 begin 开始)
- 同时遍历左右两个区间,每次比较 abegin1 和 abegin2:
· 谁小就把谁放入 tmpi,然后对应的指针后移一位,i 后移一位。
-
当其中一个区间遍历完后,把另一个区间剩余的所有元素直接拷贝到 tmp 后面。
-
最后将 tmp 中 begin, end 这一段有序数据拷贝回原数组 a 的相同位置。
逐层合并过程(从底层到顶层)
· 第1层合并(元素个数=1的区间两两合并)
· 合并 0,0 和 1,1 → 得到 2,5,放回原数组 0,1
· 2,2 只有一个,不参与合并(但它的上一层会处理)
· 实际上在 0,1 合并完成后,返回到上一级 0,2 时,还会合并 0,1(已有序)和 2,2(单元素)。
所以更准确地说:
当 0,1 合并完返回后,Mergesort(0,2) 内部会把左子区间 0,1(有序)和右子区间 2,2(有序)合并 → 得到 2,5,7 放回 0,2。
· 第2层合并(元素个数=2的区间)
· 右半部分类似:先合并 3,3 和 4,4 → 1,3 放回 3,4
然后合并 3,4(有序)和 5,5 → 1,3,8 放回 3,5
· 第3层合并(元素个数=4的区间)
· 此时左半 0,2 是 2,5,7,右半 3,5 是 1,3,8,两者均有序
· 合并它们:比较 2 和 1 → 取 1;比较 2 和 3 → 取 2;比较 5 和 3 → 取 3;比较 5 和 8 → 取 5;比较 7 和 8 → 取 7;最后取 8
· 得到 1,2,3,5,7,8 放回原数组 0,5
此时整个数组有序,递归结束,返回到主函数。
四、形象总结
递归归并就像一场淘汰赛:
先把所有选手(数组元素)分成一对一对的小组,每个小组内部分出名次(单个元素自然有名次)。
然后两两小组合并,合并时按名次重新排成新小组。
小组规模逐渐翻倍,直到只剩一个小组,此时整个队伍就是按名次排好的。
文字版伪代码过程:
```
function 归并排序(数组, 临时空间, 左边界, 右边界):
如果 左边界 >= 右边界:
返回
中点 = (左边界+右边界)/2
归并排序(左半边) // 等待左半边排好
归并排序(右半边) // 等待右半边排好
合并左半边和右半边 // 此时左右都已有序
将合并结果拷贝回原数组
```
这就是递归归并排序的完整叙述。
7、递归部分的图解
调用 Mergesort(0,5)
├── Mergesort(0,2)
│ ├── Mergesort(0,1)
│ │ ├── Mergesort(0,0) → 返回
│ │ └── Mergesort(1,1) → 返回
│ │ └── 合并 0,0 和 1,1 → 得到有序 0,1
│ └── Mergesort(2,2) → 返回
│ └── 合并 0,1 和 2,2 → 得到有序 0,2
└── Mergesort(3,5)
├── Mergesort(3,4)
│ ├── Mergesort(3,3) → 返回
│ └── Mergesort(4,4) → 返回
│ └── 合并 3,3 和 4,4 → 得到有序 3,4
└── Mergesort(5,5) → 返回
└── 合并 3,4 和 5,5 → 得到有序 3,5
└── 合并 0,2 和 3,5 → 得到最终有序 0,5
这就是关于递归的详细讲解,接下来我们来讲一下非递归的形式,当我们在面试当中,有些面试官需要让我们手撕非递归的写法,我们必须也要掌握,也是重中之重。
8、非递归解决归并排序
非递归在今后我们的找工作当中,出现的频率会很高,不光是在这道题道中,只要是能用递归解决的问题,都会牵扯非递归,下面我们用非递归来解决这个问题。
1.上面我们写的递归是自顶向下的(先分到最后,在逐层合并)。
而非递归是自底向上的:
先将数组看成一个个长度为1的有序子数组
两两合并为长度为2的有序子数组
再两两合并为长度为4的有序子数组
直到整个数组有序.............
2.非递归的实现的核心思路
用变量gap表示当前每组子数组的长度(元素的个数)
初始时gap=1,每次外循环gap*=2;
在每一轮中,每两个相邻的,长度均gap的子数组合并为一个
用i遍历数组,步长为2*gap,每次处理一对
第一组:i, i+gap-1
第二组:i+gap, i+2\*gap-1
```
然后对这两组执行标准的"合并两个有序数组"操作,结果存入临时数组,再拷贝回原数组。
边界处理(重要!)
因为数组长度 n 不一定是 2 的幂,最后一组可能不完整:
· 第二组完全不存在(begin2 >= n)→ 跳过本次归并
· 第二组部分存在(begin2 < n 但 end2 >= n)→ 将 end2 修正为 n-1
3.代码实现
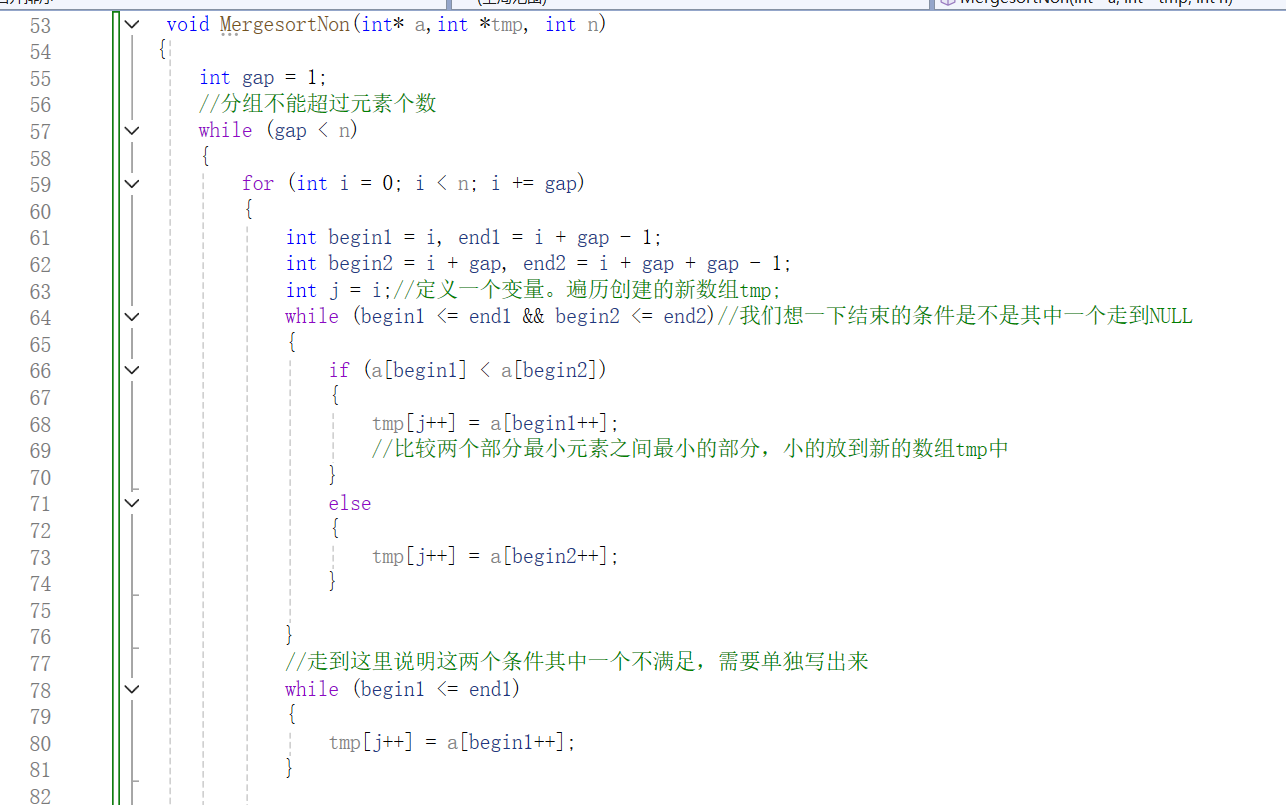

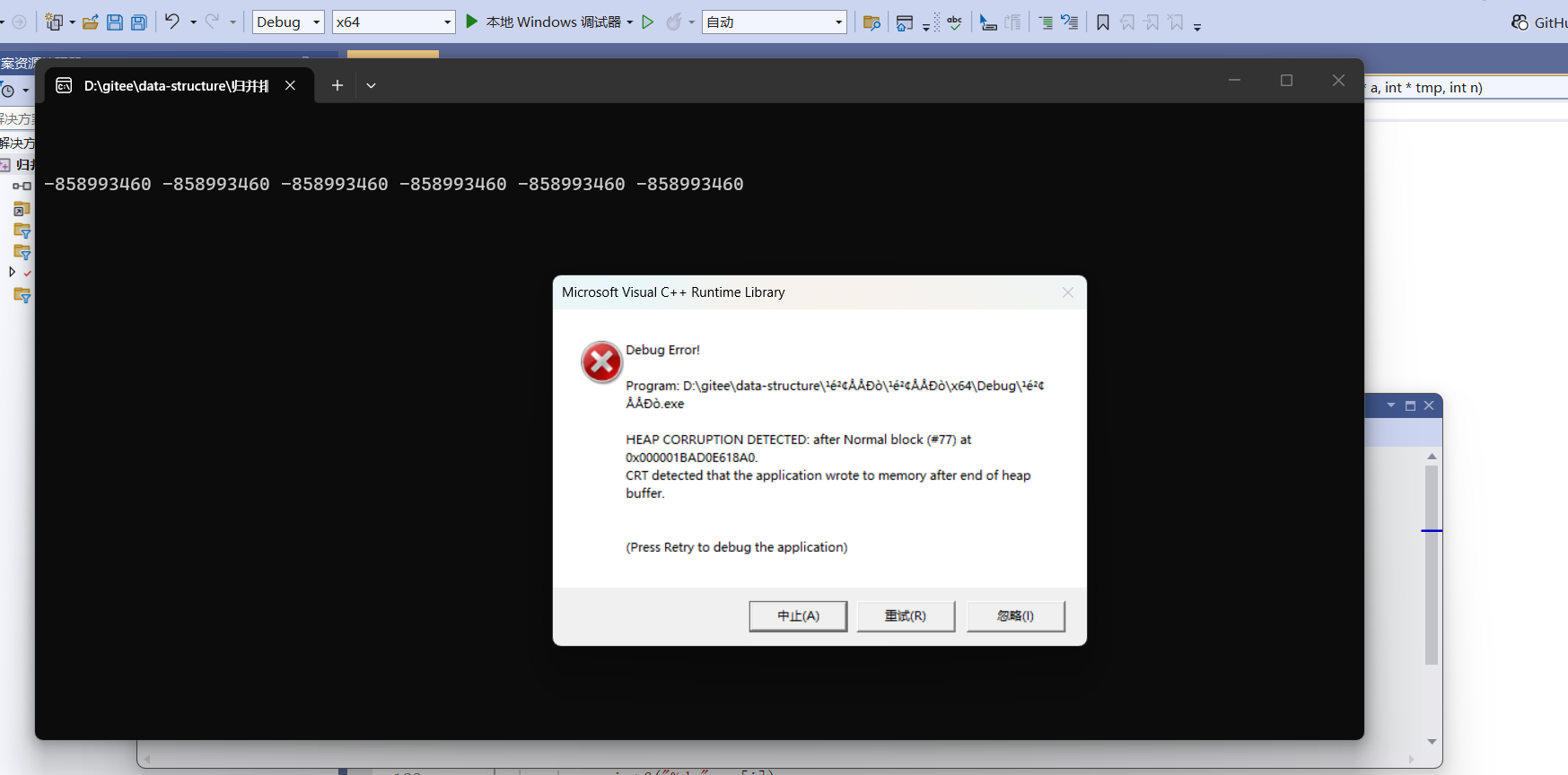 运行一下直接报错,为啥会出现这种情况呢?是因为我们忽略了边界
运行一下直接报错,为啥会出现这种情况呢?是因为我们忽略了边界
3.为啥需要考虑边界
因为有的数组长度n不一定是2的幂。比如n=7,gap=2
最后一组第二块只有1个元素(begin2=6,end2=7,但end2此时已经越界)
如果不判断并改正end2,代码就会去访问a7->越界写入->堆损坏/崩溃
在整个归并区间中,只有begin1是稳定的,因为它每次都是从0开始
end1不判断:因为任何可能导致end1越界的情况,都会导致begin2>=n,从而被提前break;
end2需要判断:end2越界不影响begin2的有效性(begin2仍然有效),只是第二组的末尾不够长,需要修正。

上面就是我们这次写的全部内容了,感觉写的还行的可以点个赞,关注一下我这个小博主呀!