1. 宏观视角:什么是LangGraph的"图"?
在传统的LangChain中,我们习惯使用"链(Chain)",它像是一条单行道,数据从A流向B,再流向C,无法回头。
而在LangGraph中,我们使用"图(Graph)",它更像是一个有向有环图(Directed Cyclic Graph)。这意味着:
- 有向:数据流动的方向是明确的。
- 有环 :流程可以回到过去的步骤(例如:代码写错了,需要回到上一步重新写)。
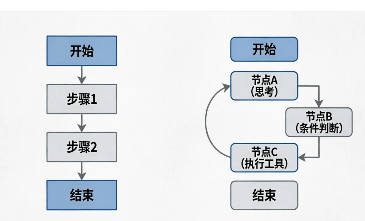
解读:
- 链:适合简单的问答,一旦出错很难修正。
- 图 :适合复杂的Agent,支持循环(Cycles) (如自我修正)和分支(Branching)(如根据意图选择不同路径)。
2. 核心组件一:状态(State)------ 图的"记忆"
在LangGraph中,图本身是无状态的,所有的数据都存储在State 中。State就像是一个共享白板 或背包,它在所有节点之间传递。
每个节点读取白板上的信息,处理后,更新白板上的内容,然后传给下一个节点。
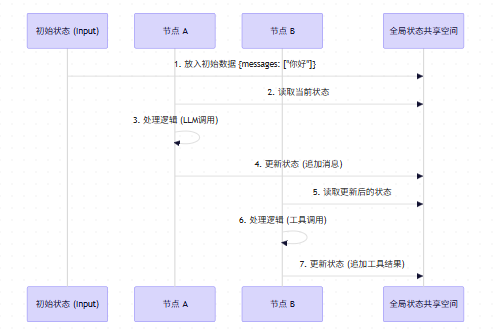
代码实现视角:
我们需要定义一个继承自 TypedDict 的类来规范这个"白板"的格式。
from typing import TypedDict, Annotated, List
import operator
class AgentState(TypedDict):
# messages 列表会自动进行"追加"操作 (Reducer)
# 这意味着节点A添加的消息,节点B也能看到,且不会覆盖旧消息
messages: Annotated[List[str], operator.add]
# 其他自定义字段
current_step: str
retry_count: int关键点: State不仅传递数据,还定义了如何合并数据(Reducer)。例如,对于消息列表,我们通常希望是"追加"而不是"覆盖"。
3. 核心组件二:节点(Nodes)------ 图的"工人"
节点是图中执行具体工作的单元。你可以把它想象成工厂流水线上的工人 ,或者交通网络中的城市。
- 本质:一个Python函数。
- 输入 :当前的
State。 - 输出 :对
State的更新(字典格式)。
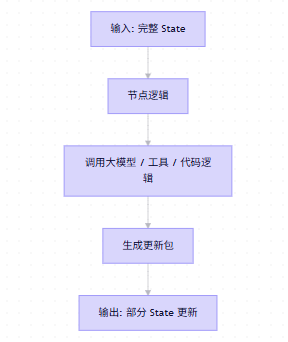
节点应该是原子化的。不要把太多功能塞进一个节点。
-
好的设计 :
搜索节点、写作节点、审查节点。 -
坏的设计 :一个巨大的
处理所有事情的节点。def research_node(state: AgentState):
"""负责搜索信息的节点"""
query = state['messages'][-1]
# 模拟搜索
search_result = f"搜索到的关于 '{query}' 的信息..."
# 返回更新,只更新 messages 字段
return {"messages": [search_result]}def writer_node(state: AgentState):
"""负责写报告的节点"""
# 基于搜索结果写报告
report = "这是生成的报告..."
return {"messages": [report], "current_step": "finished"}
4. 核心组件三:边(Edges)------ 图的"道路"
边决定了流程的走向。如果说节点是"做什么",边就是决定"下一步去哪"。LangGraph中有两种主要的边:
4.1 普通边(Normal Edges)
就像高速公路,从A到B是固定的,没有选择。
- 场景:步骤1做完必须做步骤2。
4.2 条件边(Conditional Edges)
就像十字路口,需要根据路况(State)决定往左走还是往右走。
- 场景:如果用户问天气,去"天气节点";如果用户写代码,去"代码节点"。
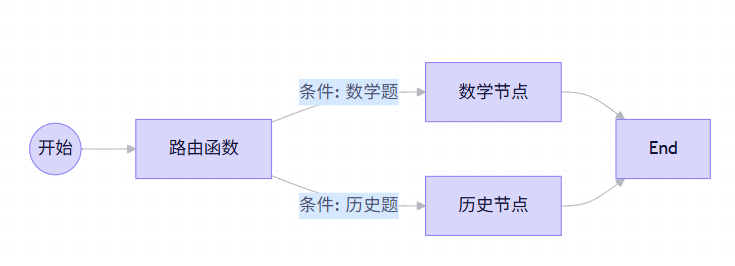
# 1. 定义路由函数
def route_by_topic(state: AgentState):
last_message = state['messages'][-1]
if "数学" in last_message:
return "math_node" # 返回下一个节点的名称
else:
return "history_node"
# 2. 添加到图中
builder.add_conditional_edges(
"router_node", # 从哪个节点出来
route_by_topic, # 路由函数
["math_node", "history_node"] # 可能的去向列表
)5. 深入理解:图的编译与执行(Pregel模型)
当你定义好节点和边后,需要调用 .compile()。这一步会将你的逻辑转化为一个可执行的机器。LangGraph底层基于 Pregel 模型。
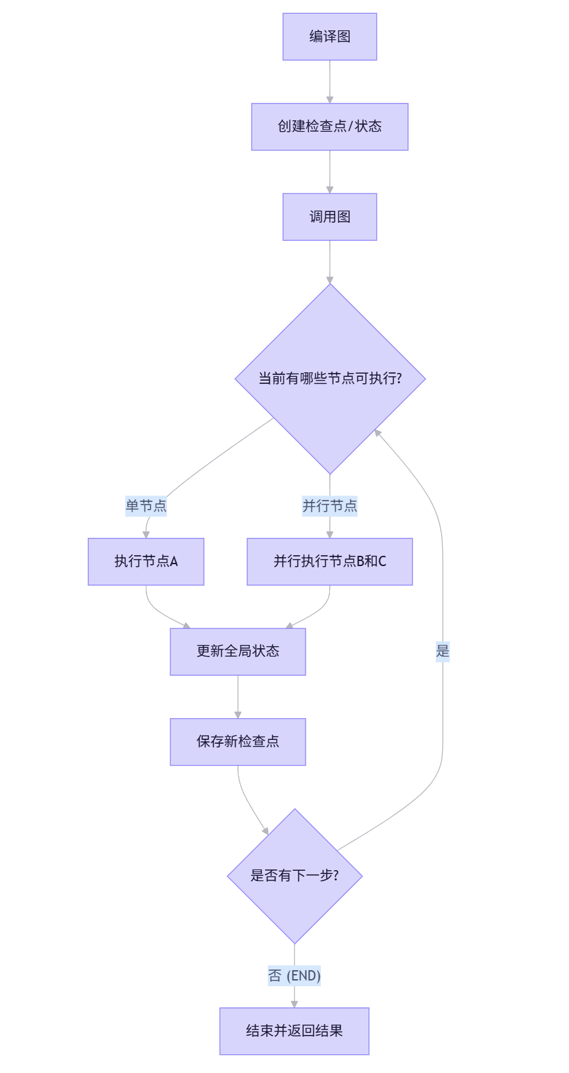
解读:
- 并行性:如果你的图结构允许(例如两个分支互不干扰),LangGraph可以并行执行节点。
- 持久化:每执行一步,状态都会被保存(如果你配置了Checkpointer),这就是"时间旅行"的基础。
6. 综合实战:构建一个"自我修正"的图
让我们把以上概念串起来,构建一个包含循环的图:写代码 -> 检查 -> (如果有错) -> 重写。
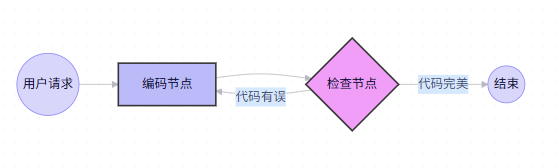
from langgraph.graph import StateGraph, END
# 1. 定义状态
class CodeState(TypedDict):
code: str
error_log: str
# 2. 定义节点
def coding_node(state):
# 模拟生成代码
return {"code": "print('Hello')", "error_log": ""}
def checking_node(state):
# 模拟检查代码
if "error" in state['code']:
return {"error_log": "发现语法错误"}
return {"error_log": "OK"}
# 3. 构建图
builder = StateGraph(CodeState)
# 添加节点
builder.add_node("coder", coding_node)
builder.add_node("checker", checking_node)
# 添加边
builder.set_entry_point("coder") # 入口
builder.add_edge("coder", "checker") # 写完必须检查
# 添加条件边 (核心逻辑:循环)
def decide_next(state):
if state['error_log'] == "OK":
return "end"
else:
return "coder" # 有错就回去重写
builder.add_conditional_edges(
"checker",
decide_next,
{"coder": "coder", "end": END}
)
# 4. 编译
app = builder.compile()
# 5. 运行
result = app.invoke({"code": "", "error_log": ""})总结
| 概念 | 类比 | 技术本质 | 核心作用 |
|---|---|---|---|
| State | 共享白板/背包 | TypedDict + Reducers |
跨节点传递数据,保持记忆 |
| Node | 工人/城市 | Python 函数 | 执行具体的业务逻辑 (LLM/Tool) |
| Edge | 道路/路标 | add_edge / add_conditional_edges |
控制流程走向,实现分支与循环 |
| Graph | 交通网 | 有向有环图 (DCG) | 编排复杂任务,实现Agent自主性 |