你每天都在用 AI。问它问题,让它写代码,让它帮你翻译文章。但你有没有想过:它到底在"做"什么?
大多数人以为 AI 在"思考"------它理解了你的问题,查了查脑子里的知识,最后给出一个"它认为对的答案"。
错了。
大模型真正做的事,比你想象的简单得多:
猜下一个词。
不是"理解",不是"思考",不是"推理"------就是给定前面的文字,预测下一个最可能出现的词。ChatGPT、Claude、DeepSeek,所有大模型的底层任务都是同一个。
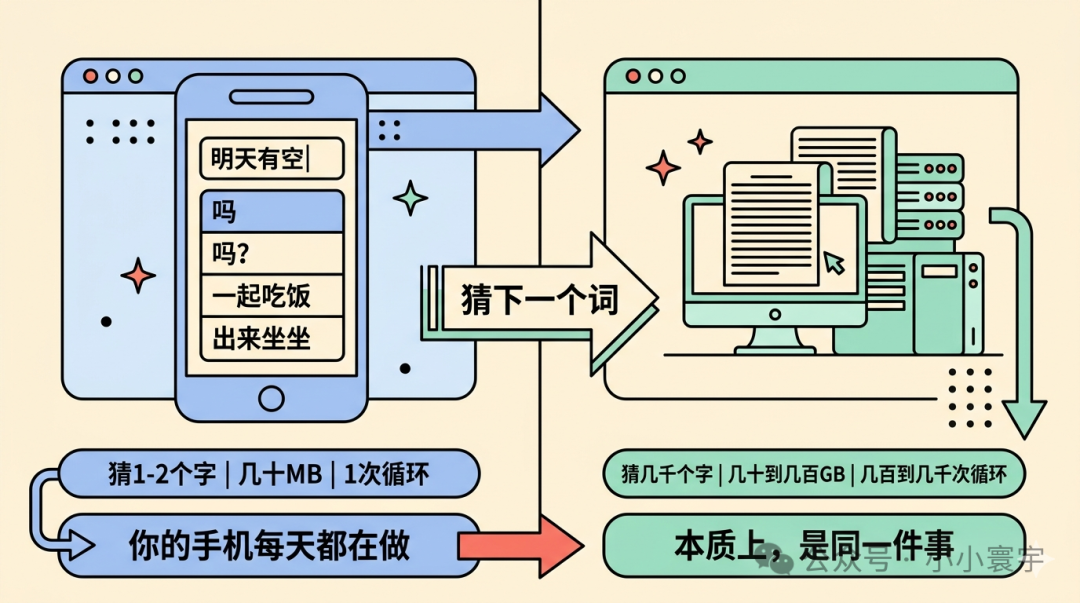
你用微信给人发消息,打出四个字:
"明天有空"
输入法立刻弹出几个选项:吗、吗?、一起吃饭、出来坐坐。你选了"吗",接着打出"出来",输入法又弹出:聚、聊聊、吃个饭。
这就是下一个词预测。你手机里那个几十 MB 的小模型,做的事情和 ChatGPT 本质上完全一样。
区别只在规模:
-
• 参考的信息:输入法看最近几个字,大模型看整段上下文(几千到几十万字)
-
• 模型大小:几十 MB vs. 几十到几百 GB
-
• 循环次数:1 次 vs. 几百到几千次
输入法猜下一两个字,大模型猜几千个字------是同一个动作推到极致。
一个具体的例子
来看看这个过程是怎么运作的。模拟大模型处理一个请求。
你的输入:
"请把这句话翻译成法语:The cat is sleeping on the red couch."
第一步:文字变成数字
模型不认识英文字母。它先把这句话拆成 Token(词元),每个 Token 对应一个数字 ID。
"The" → 42,"cat" → 1089,"is" → 58,"sleeping" → 7234......
所以模型看到的不是文字,而是一串数字:[42, 1089, 58, 7234, 22, 5, 8, 42, 337, 15, 5, 2217]
第二步:穿过神经网络
这串数字进入一个巨大的多层神经网络。每一层都在做同一件事:根据上下文,给每个可能的下一个词打分。
第一层看到 "The cat is sleeping",打出一堆可能性分数。
第二层看到更多上下文,调整。
第三百层看完了整句话,把每个可能的法语词都排好序。它可能算出来:Le 35%、Un 18%、chat 12%、Ce 8%......
第三步:按概率转盘选词
然后,模型按照概率分布转动"转盘"。不是选概率最高的词,而是按概率随机抽取------概率高的词格子大,但也有机会转到概率低的词。
所以你问同一个问题两次,答案往往不一样。这不是 AI"想出了不同的答案",而是转盘每次转到的地方略有不同。
第四步:拼上去,循环
选出一个词(比如"Le"),拼到句子后面,整个过程重新开始------把"Le"作为新的输入,重新算概率,重新转盘,选下一个词(比如"chat"),继续......
一直重复,直到模型决定"说完了"。

为什么能写文章、做翻译、解数学题?
你可能会说:好吧,就算它是在"猜",但它能写文章、解数学题,这总得是"真正的能力"吧?
不,这些都是"猜下一个词"的副产品。
翻译
你输入:
"翻译成法语:The cat is sleeping on the red couch."
模型依次预测"Le"、"chat"、"dort"、"sur"、"le"、"canapé"、"rouge"......
它不是"会法语"。它是在训练数据里见过海量法语文章------法国小说、新闻、论文、网页,看到"on the red couch",就知道法语里大概率说"sur le canapé rouge"。这个规律是记住的,不是理解的。
数学
你输入:
"小明有 12 个苹果,给了小红 5 个,又买了 8 个,小明现在有多少个苹果?"
模型看到"12"、"5"、"8",在训练数据里见过太多这类题目:数字换一换,句式换一换,但结构几乎一样。它预测出"1"、"9"。
不是它在计算------是见过足够多次类似题目,预测得准。
但这里有个陷阱。如果题目是训练数据里没见过的类型,或者数字很大,模型就会胡说八道。不是因为它粗心,而是它的本质是预测下一个词,不是做算术。
写代码
你输入:
bash
def calculate_factorial(n):模型预测下一个词是 if,再下一个是 n,再下一个是 <,再下一个是 2......
它不是"懂编程"。它对编程语言的语法模式极其熟悉------在 GitHub 上看过几万亿行代码。但它不保证代码一定正确、一定高效、一定安全。它只是在猜最可能的那串代码。
为什么它有时候"看起来像在推理"?
你可能有过这个体验:你问 AI 一道复杂数学题,它一步一步写出来,最后得出正确答案,好像真的在思考。
这其实是另一个技巧在起作用:思维链提示(Chain-of-Thought)。
你在 prompt 里加一句"请一步一步思考",模型输出的内容里,会把推理过程也写出来。
但注意:它并不是真正在思考。它只是在预测"一个正在认真思考的人,接下来会写什么"。把推理过程写出来,恰恰是因为训练数据里包含大量解题步骤------教科书、例题、论坛讨论。模型学的就是这种"先写一步、再写一步、最终得出答案"的模式。
这让输出看起来像推理,而且往往能得到正确答案。但它和真正的推理有本质区别:
真正的推理是有因果链的:知道 A,推导出 B,因为 B 所以 C。
大模型是统计模式匹配:在见过的所有文字里,遇到这种输入,最常见的下一步是这种输出。
区别在于:如果遇到训练数据里没出现过的全新问题,真正的推理能应对,模型会胡说八道。
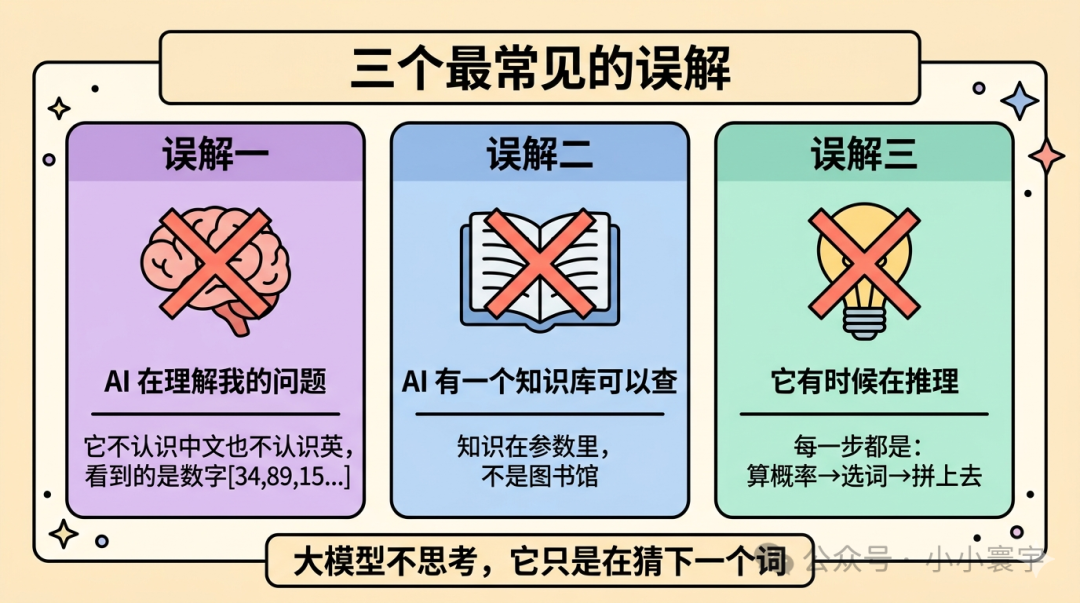
三个最常见的误解
误解一:AI 在理解我的问题。
不。它不认识你,不理解中文,也不理解英语。
你问它"为什么天是蓝的",它看到的是一串数字 [34, 89, 15, 203, 445, ...],然后根据这串数字,预测你接下来最想看到什么文字。
它给出一个好的回答,是因为在训练数据里见过这个问题被认真回答过很多次。它不是在理解问题然后给出答案,而是在预测"这类问题,高质量的回答通常长什么样"。
误解二:AI 有一个知识库可以查。
不。它没有图书馆,没有数据库,没有索引。
你可能会想象一个大模型像图书馆管理员,收到问题后,在海量书籍里翻找相关章节。这完全是错的。
它的"知识"全在参数里------不是存储的知识,而是训练出来的预测能力。几千亿个数字,是通过海量文本反复练习"猜下一个词"练出来的。
打个比方:一个看过几百万场比赛的围棋选手,下棋的时候并不是在回忆之前看过的某场比赛,而是在训练过程中形成了某种判断模式。这个模式存在于他下棋的直觉里,而不是某个记忆宫殿里。
误解三:它有时候在推理。
不。每一步都是同一个操作:算概率、选词、拼上去、继续算。
"推理"只是看起来像推理,本质还是概率游戏。它和真正的推理之间的区别,就像照着菜谱做饭和真正理解化学反应之间的区别------菜谱能做出好吃的菜,但如果食材变了、火候变了,照着菜谱就可能做出黑暗料理。
边界在哪里
知道大模型本质是"猜下一个词",不是否定它的价值,而是让你更聪明地使用它。
它擅长的:
-
• 模式清晰的写作任务(邮件、报告、格式化的文字)
-
• 见过大量类似例子的任务(常见语言的翻译、标准编程问题)
-
• 给你提供思路、框架、初稿
-
• 回答它训练数据里覆盖得很好的问题
它的局限:
-
• 全新问题、没有先例的问题(概率预测在这里失效)
-
• 需要精确计算的任务(尤其是大数运算)
-
• 需要最新信息的问题(它的知识有截止日期)
-
• 需要 100% 准确的事实性回答(它可能一本正经地胡说八道)
理解了它的边界,你就能用它做它擅长的事,而不是在它不擅长的地方和它较劲。
下一次你用它时,想想这个画面
现在你知道了大模型在做什么:
你的文字变成一串数字(Token),穿过几十层神经网络,被层层打分,概率最高的几个词进入转盘,随机选出一个,拼到原句后面,整个过程重复几百次,最终拼出你看到的一整段话。
它不知道自己在说什么。它只是在猜。
而"猜"得足够准,我们就叫它------智能。
文章首发于 「小小寰宇」
