1.1 环境安装
项目=模型的源码以及模型+python以及一堆包,比如YOLO项目=YOLO源码+python以及相关的包
安装模型环境:1、创建模型环境 2、安装pytorch 3、安装其他包
下载好的模型要放在源码里面
项目特别多的情况下就需要管理环境,可以用anaconda来管理环境,pycharm则是用来提供一个界面
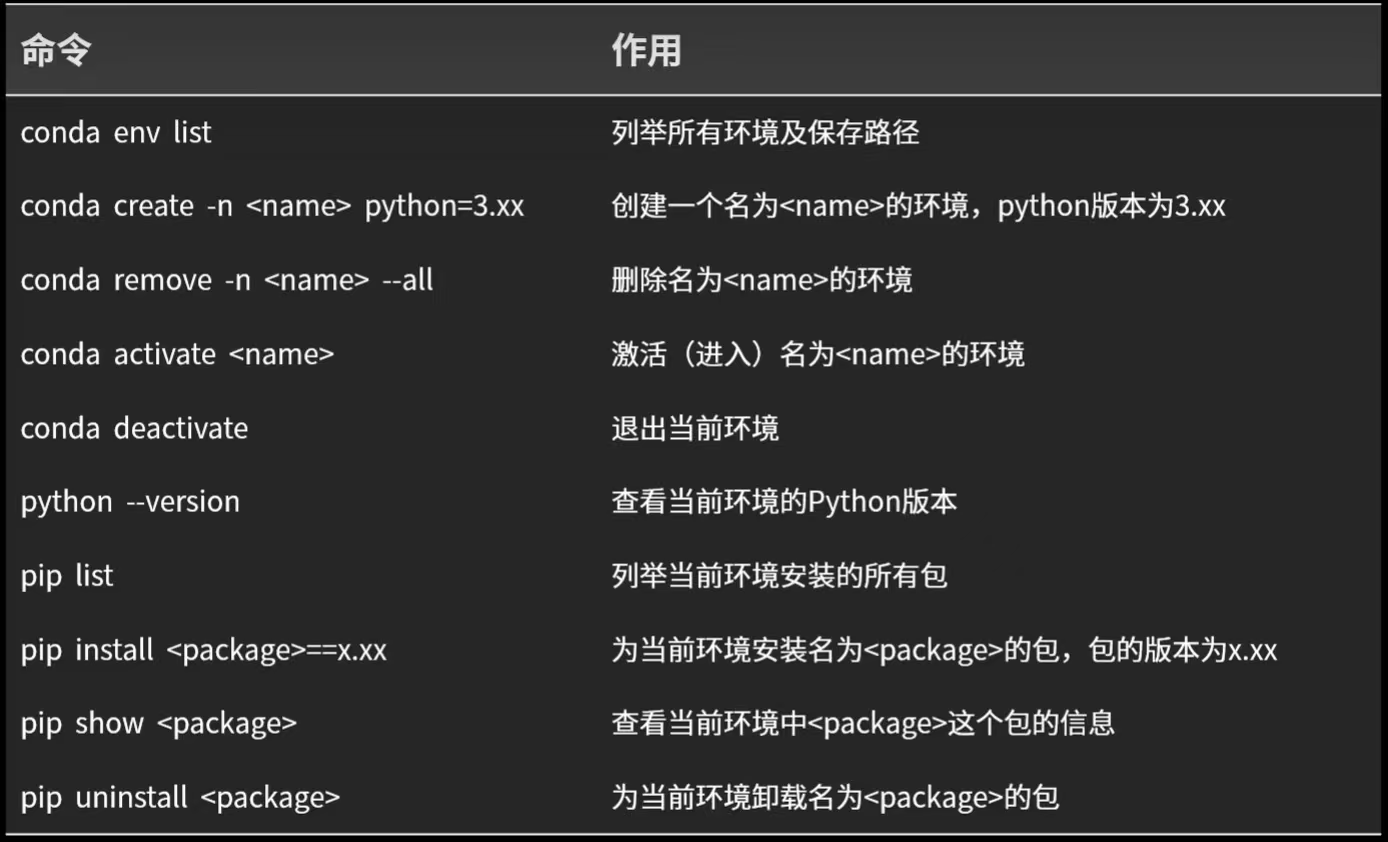
anaconda prompt则是用来提供安装各种包的环境,它的相关命令如下:
每一个环境都需要重新安装pytorch,pytorch的网址为pytorch.org,选择一个合适的版本
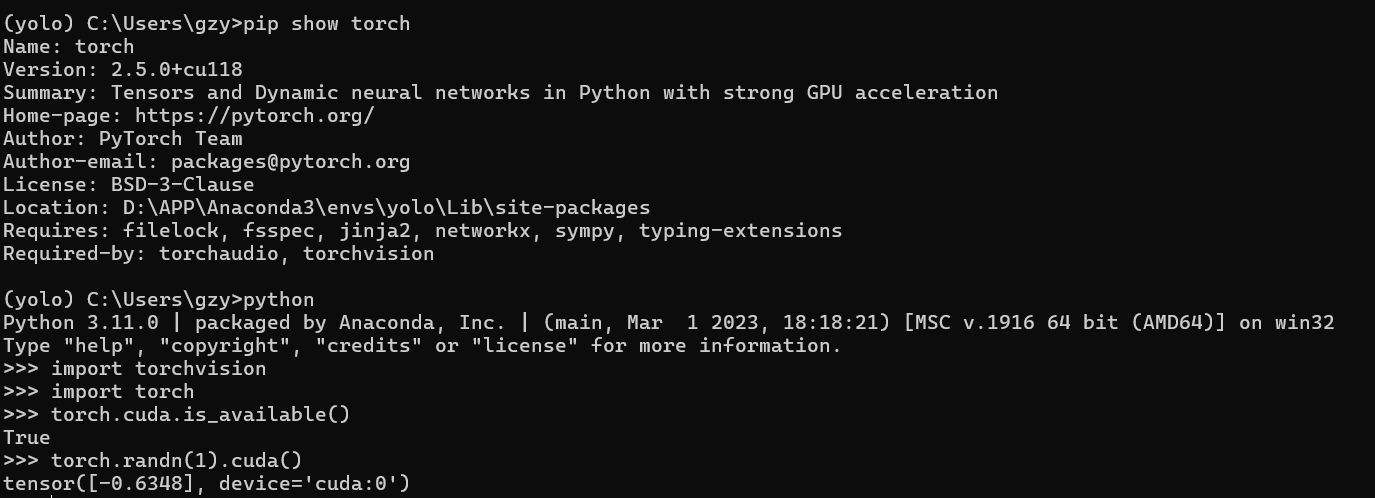
pytorch下载好之后,输入一些指令以验证是否安装成功:
安装其他包,根据从github下载的模型源码来下载其他包
首先找到你的源码安装路径
pushd 安装路径 回车
pip install -e . 回车 开始安装所有需要迭代包1.2 推理入门
学习ai就是学习如何解决推理和训练过程中遇到的各种问题
1.2.1 对模型的初步认识
1、模型的任务类型
以yolo为例:from ultralytics import YOLO
model = YOLO(r"yolo11n-cls.pt")
print(model.task)
这样就可以通过代码知道模型的任务类型
2、模型可预测的类型
print(model.names)
这样就可以知道可预测的物品类型
3、模型的大小
print(sum(p.numel() for p in model.parameters()))
用来看模型的参数数量,数量越多,训练越准确,同时所花费的训练时间也越久1.3 训练入门
什么是数据集?
通常会把图片和标签进行划分,划分为训练集+验证集,比如7:3或8:2
先用训练集训练模型以更新参数,再用验证集验证模型是否好用
所以每训练一轮都是训练+验证
测试集可有可无,在训练过程中用不到,但是在训练结束后可以用来评价模型
准备训练集和验证集
准备数据集文件夹:
1、包含图片和标签的数据集本身,目录结构需要符合一定的要求
2、数据集配置文件,以.yaml为后缀,不是所有模型都需要。作用:告诉模型训练集/验证集的图片/标签分别在哪个文件夹如何让训练跑得更快
两个高效率训练得典型特征:
1、cuda的利用率又高又稳
2、所有资源得利用率都不到100%1、图片尺寸越小,训练越快,但是有训练上限;并且会导致训练效果下降
2、每次从所有图片中拿出的一些图片就叫做一个批次(batch),一个批次中图片的数量就叫批量(batch size),每一轮训练就是给模型喂一个又一个的批次,喂一次批次,模型更新一次参数
硬件会影响batch的大小,所以选择合适的batch很重要,太大硬件不够用,太小时间比较长
3、cache是缓存,如果让cache="ram",就是指在训练前将所有的图片都放到内存里,这样在训练时就不需要涉及原图,但是前提是内存得足够大,但是不是所有的模型都有cache
数据集
数据增强:将一张图片随机缩放,随机旋转,随机调色和中间裁剪,可以得到多个图片,这就是数据增强
数据集如何获取?
1、数据集网址
2、自己制作数据集,拍摄视频,用python脚本来抽帧;
制作labels标签3、数据集划分,训练集和验证集按照7:3或8:2的比例划分,可以通过python脚本来划分(注意是随机提取)
可以直接写一个split.py
提示词:我现在需要一些python代码随机划分一下数据集,images文件夹里存放.jpg文件,labels文件 夹里存放.txt标签文件,划分结果统一保存到kunkun文件夹里,用这样的目录结构:kunkun\
images\
train\
val\
test\
labels\
train\
val\
test\划分比例设置成可以调整的参数,只复制粘贴文件,不要乱动原本的图片和标签,不要用sklearn这个包,划分的时候要用进度条提示一下进度,注释写清楚一点,我是python小白
模型评价
TP是匹配成功的预测结果,FP是匹配失败的预测结果,FN是匹配失败的真实结果
精确率§ = TP/(TP+FP) = 正确预测/预测总数
召回率® = TP/(TP+FN) = 正确预测/真实总数,召回率是指许多正确结果都被找到了
F1分数(F1 score) = 2×P×R/(P+R)
三个指标都是越接近1越好
PR曲线:当P曲线和R曲线都十分优秀的时候,PR曲线也会十分优秀,AP(平均精度)也会越接近1;PR曲线靠外,AP高的潜台词是能找到一个conf(置信度)使得P和R都很高,具体在哪不知道,只能通过观察P曲线和R曲线来分析
mAP(平均平均精度)