RocketMQ的可靠性设计覆盖了消息流转的每个环节,但不是说用了RocketMQ消息就不会丢。它提供了机制,能不能用好取决于你怎么配、怎么写代码。
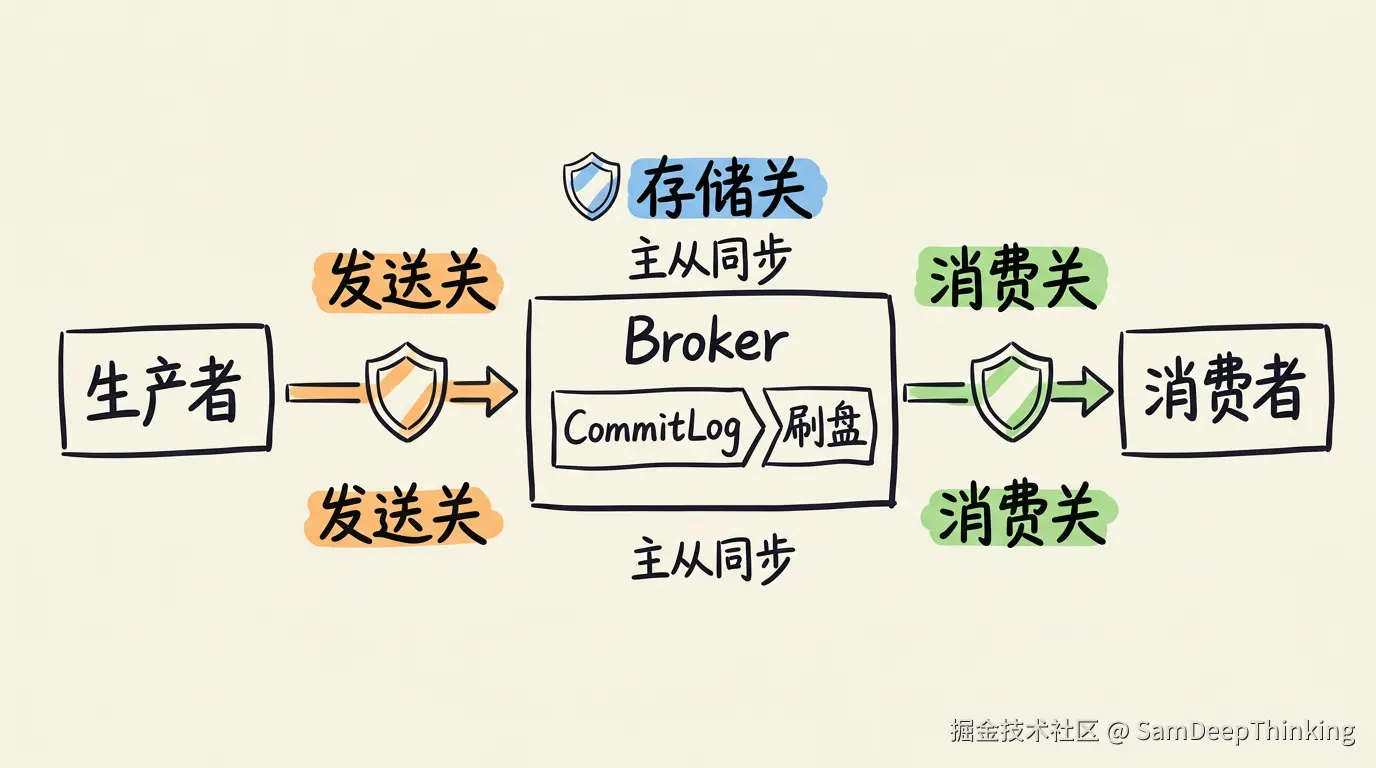
一条消息从发送到被消费,要过三道关卡:
- 生产端把消息送到Broker(发送关卡)
- Broker把消息持久化到磁盘(存储关卡)
- 消费端拉取消息并确认消费成功(消费关卡)
任何一道关卡出问题,消息就可能丢。接下来分别看看RocketMQ在每道关卡上做了什么设计。
发送关:生产端到Broker
三种发送方式的可靠性差异
RocketMQ提供三种发送方式:同步发送、异步发送、单向发送。它们在可靠性上的差距很大。
同步发送会阻塞当前线程等待Broker的响应。拿到响应后可以判断发送状态,失败了可以重试或者做补偿。这是最可靠的发送方式。
异步发送不阻塞当前线程,通过回调函数拿到发送结果。可靠性取决于回调函数的实现质量。
单向发送调完就走,不等响应,不知道成功还是失败。适合日志采集这类允许丢消息的场景。
| 发送方式 | 是否阻塞 | 能否感知失败 | 内部自动重试 | 适用场景 |
|---|---|---|---|---|
| 同步发送 | 是 | 能,通过返回值判断 | 有,默认重试2次 | 交易、支付等不能丢消息的场景 |
| 异步发送 | 否 | 能,通过回调判断 | 有网络层重试,但不切换Broker | 响应时间敏感但仍需保证可靠的场景 |
| 单向发送 | 否 | 不能 | 无 | 日志采集、监控指标上报等允许丢失的场景 |
这里有个容易踩的坑:异步发送在重试时不会切换Broker。同步发送失败后会自动换一个Broker再发一次,异步发送不会。异步发送虽然也有网络层重试(默认2次),但每次重试都是往同一个Broker发,不具备故障转移能力。如果某个Broker出了问题,异步发送的可靠性要比同步发送低一截。
发送重试与故障规避
同步发送的重试逻辑在DefaultMQProducerImpl的sendDefaultImpl方法中。总尝试次数 = 1 + retryTimesWhenSendFailed,默认值是2,也就是最多尝试3次。每次重试时会传入上一次使用的BrokerName,选队列时主动规避这个Broker,避免反复往同一个有问题的节点上发。
发送失败或抛异常时,客户端还会更新内部的故障表。MQFaultStrategy维护了一套延迟分级规避机制:根据某个Broker的响应耗时,把它标记为一段时间内不可用。比如响应耗时超过2000ms,这个Broker会被标记为120秒不可用;如果直接抛了网络异常,不可用时长会拉到10分钟。在这段时间内,发送消息时会优先选择其他Broker。
这个机制默认是关闭的,需要手动开启:
Java
producer.setSendLatencyFaultEnable(true);对于多Broker部署的集群,建议开启这个配置。它让生产端在重试时能更有效地避开有问题的Broker,提高发送成功率。
存储关:Broker的持久化
消息到了Broker,写入CommitLog之后还不算安全。消息先写到操作系统的PageCache里,如果这时候机器断电,PageCache里的数据就没了。需要把数据从PageCache刷到磁盘上,这个过程叫刷盘。
RocketMQ提供两种刷盘策略:同步刷盘和异步刷盘。
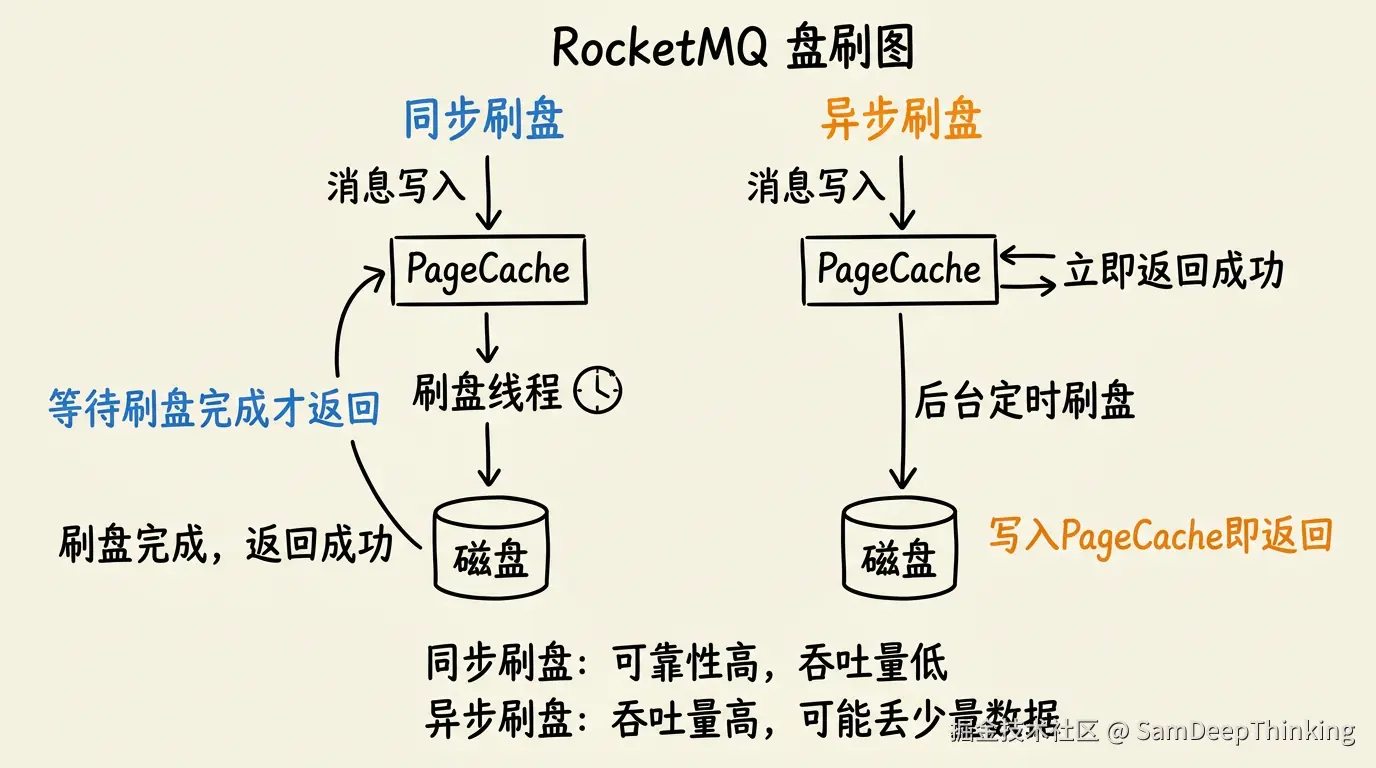
同步刷盘
同步刷盘由CommitLog内部的GroupCommitService实现。消息写入PageCache后,发送线程不会立即返回,而是阻塞等待刷盘线程把数据写到磁盘。刷盘完成后才唤醒发送线程,返回写入成功。
GroupCommitService的设计用了读写队列交换的方式来减少锁竞争:新的刷盘请求写入写队列,刷盘线程从读队列取请求处理,两个队列定期交换。这样写入和刷盘互不阻塞。
刷盘时对每个请求最多执行两次flush。为什么是两次?因为一条消息可能恰好写在一个MappedFile的尾部跨到了下一个文件,第一次flush刷当前文件,第二次flush刷下一个文件,两次足以覆盖这种边界情况。如果两次flush后位点仍未达标,返回FLUSH_DISK_TIMEOUT。
同步刷盘保证了每条消息都落盘后才返回成功,数据可靠性最高,但对磁盘IO压力大,吞吐量会受影响。
异步刷盘
异步刷盘由FlushRealTimeService实现。消息写入PageCache后立即返回成功,后台线程定时把PageCache的数据刷到磁盘。默认每500ms刷一次,且至少积累4个页(16KB)才触发。另外还有一个全量刷盘间隔(默认10秒),超过这个时间即使不够4页也会强制刷。
异步刷盘的吞吐量更高,但如果Broker在两次刷盘之间宕机,PageCache中还没来得及落盘的消息就会丢失。
主从同步
刷盘解决的是单机持久化的问题,但如果磁盘坏了呢?这就需要主从复制。
HAService负责主从之间的数据同步。Master维护一个字段记录已经同步到Slave的最大位点,用来判断Slave是否健康:必须有活跃连接,且主从数据差距不超过256MB(默认值)。
RocketMQ支持两种主从同步模式:
- 同步复制(SYNC_MASTER):消息写入Master后,等待至少一个Slave确认收到才返回成功
- 异步复制(ASYNC_MASTER):消息写入Master后立即返回成功,后台异步推送给Slave
可靠性与性能的组合选择
刷盘策略和主从模式可以自由组合,不同组合对应不同的可靠性和性能水平:
| 刷盘策略 | 主从模式 | 可靠性 | 性能 | 适用场景 |
|---|---|---|---|---|
| 同步刷盘 | 同步复制 | 消息不会丢失 | 吞吐量最低 | 金融级交易,对数据零容忍 |
| 同步刷盘 | 异步复制 | Master磁盘不坏就不丢 | 吞吐量较低 | 核心业务,可接受极端情况下极少丢失 |
| 异步刷盘 | 同步复制 | Master宕机可能丢少量 | 吞吐量较高 | 重要业务,对吞吐有要求 |
| 异步刷盘 | 异步复制 | 宕机会丢PageCache中未刷数据 | 吞吐量最高 | 日志类、可容忍少量丢失的业务 |
绝大多数线上系统用的是「异步刷盘 + 异步复制」或者「异步刷盘 + 同步复制」。同步刷盘对磁盘IO的压力很大,在高并发场景下会成为瓶颈。实际选择时,建议先看业务对消息丢失的容忍程度,再决定配置。大多数互联网业务场景下,异步刷盘 + 同步复制是一个比较均衡的选择。
对应的Broker配置项:
.properties
flushDiskType=ASYNC_FLUSH
brokerRole=SYNC_MASTER消费关:Broker到消费端
消息存储可靠了,消费端也可能丢消息。最常见的情况是消费位点提前提交了,消息还没处理完,消费者重启后这条消息就不会再被拉取。
RocketMQ在消费端的可靠性设计围绕一个原则:先消费,成功后才提交位点。
消费确认机制
消费者拉取消息后,由ConsumeMessageConcurrentlyService负责并发消费。消费结果的处理分两种情况:
集群模式下,消费失败的消息通过sendMessageBack发送回Broker,进入重试队列等待下次投递。如果sendMessageBack本身也失败了(比如网络断了),会把消息加入本地的失败列表,5秒后重新提交消费。
广播模式下消费失败直接丢弃,只打了一行warn日志。 这个行为很多人不知道。如果业务用了广播模式又要求消息不能丢,需要在业务层自己实现重试逻辑。
消费重试的延时策略
消息发送回Broker后,Broker根据已重试次数决定下次投递的延时。具体逻辑是:延时级别 = 3 + 已重试次数。RocketMQ内置了18个延时级别(从1秒到2小时),第一次重试从第3级(10秒)开始,逐级递增。完整的重试时间表:
| 重试次数 | 间隔时间 | 重试次数 | 间隔时间 |
|---|---|---|---|
| 第1次 | 10秒 | 第9次 | 7分钟 |
| 第2次 | 30秒 | 第10次 | 8分钟 |
| 第3次 | 1分钟 | 第11次 | 9分钟 |
| 第4次 | 2分钟 | 第12次 | 10分钟 |
| 第5次 | 3分钟 | 第13次 | 20分钟 |
| 第6次 | 4分钟 | 第14次 | 30分钟 |
| 第7次 | 5分钟 | 第15次 | 1小时 |
| 第8次 | 6分钟 | 第16次 | 2小时 |
死信队列
当重试次数达到上限(默认16次,由SubscriptionGroupConfig的retryMaxTimes配置),消息不再重试,转入死信队列。死信队列的Topic命名格式是%DLQ%加上消费者组名。进入死信队列的消息不会自动消费,需要人工介入处理。
线上系统必须对死信队列做监控。可以通过RocketMQ的Dashboard查看死信队列的消息数量,也可以写一个专门的消费者订阅死信队列Topic,做告警或者人工补偿。
消费位点的提交时机
消费完成后,客户端从本地的ProcessQueue中移除已消费的消息,返回剩余消息的最小位点,然后更新消费位点。这意味着如果有一批消息同时在消费,只有所有靠前的消息都处理完了,位点才会往前推进。
代价是:如果某条靠前的消息一直消费失败,后面的消息即使消费成功了位点也不会前进。消费者重启后会从旧位点重新拉取,导致后面那些已经消费成功的消息被重复消费。这就是RocketMQ选择了至少一次语义的体现,业务方需要做幂等来应对重复消费。
生产环境落地方案
把三道关卡的最佳实践汇总成一份可以直接用的方案:
生产端:
- 使用同步发送,检查返回的SendStatus是否为SEND_OK
- 设置retryTimesWhenSendFailed为3(多重试一次)
- 开启sendLatencyFaultEnable,让重试更有效
- 设置合理的sendMsgTimeout(建议5秒)
Broker端:
- 核心业务推荐异步刷盘 + 同步主从(兼顾性能和可靠性)
- 金融场景用同步刷盘 + 同步主从(绝对不丢)
消费端:
- 消费逻辑抛异常时返回RECONSUME_LATER,不要吞掉异常返回CONSUME_SUCCESS
- 业务代码做好幂等,用唯一消息ID或业务唯一键去重
- 根据业务需要调整最大重试次数,对于处理时间较长的消息适当增加
- 对死信队列配置监控告警,定期检查是否有消息进入死信
小结
消息可靠性是个全链路问题,不是配一个参数就能解决的。RocketMQ在每个环节都提供了保障机制,但每种机制都有对应的性能代价。同步刷盘保证了磁盘级别的可靠性,但会明显拉低吞吐量。同步主从保证了跨节点的冗余,但每条消息的响应时间都会增加一个网络往返。
我的建议是不要追求理论上的零丢失。在实际系统中,把三道关卡中最薄弱的那一道补强就够了。比如你的集群已经有了主从同步,那么单机的异步刷盘在大多数场景下就足够用了,没必要再开同步刷盘把性能再砍一刀。
对业务代码的要求反而是最容易被忽视也最容易出问题的环节。 发送端不检查发送结果、消费端吞掉异常返回成功、没有死信队列监控,这些代码层面的疏忽造成的消息丢失,比Broker配置问题要多得多。
最近在知乎出了「应付6000万会员的秒杀系统专栏」和「几亿用户,百万并发的C端商品系统实战」专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。「另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。」
知识星球内后续将推出20+个付费专栏,覆盖电商全链路:
| 选购线 | 用户会员营销线 | 中后台 |
|---|---|---|
| 购物车服务 | 营销系统 | 订单系统 |
| 商品服务 | 用户系统 | 支付系统 |
| 菜单服务 | 结算服务 |
从前台选购到中后台结算,星球成员全部免费,后续新增也不额外收费。
我的知乎账号:
- SamDeepThinking