目录
[最直觉的方案:用 MySQL 存向量](#最直觉的方案:用 MySQL 存向量)
[2.1 IVF 的工作原理](#2.1 IVF 的工作原理)
[2.2 IVF 的优缺点](#2.2 IVF 的优缺点)
[3.1 HNSW 的核心思想:多层图结构](#3.1 HNSW 的核心思想:多层图结构)
[3.2 用一个具体例子走一遍 HNSW 的检索过程](#3.2 用一个具体例子走一遍 HNSW 的检索过程)
[3.3 为什么 HNSW 这么快](#3.3 为什么 HNSW 这么快)
[3.4 HNSW 的代价:内存占用](#3.4 HNSW 的代价:内存占用)
[为什么选 Milvus](#为什么选 Milvus)
[Milvus 核心概念:和传统数据库做类比](#Milvus 核心概念:和传统数据库做类比)
[Collection = 表](#Collection = 表)
[Schema = 表结构](#Schema = 表结构)
[2.1 向量字段和标量字段的区别](#2.1 向量字段和标量字段的区别)
[Index = 索引](#Index = 索引)
[Partition = 分区](#Partition = 分区)
[一张图看懂 Milvus 的数据组织](#一张图看懂 Milvus 的数据组织)
[5.1 HNSW 索引参数](#5.1 HNSW 索引参数)
[5.2 IVF 索引参数](#5.2 IVF 索引参数)
向量存到哪里:为什么普通数据库不够用
最直觉的方案:用 MySQL 存向量
既然向量就是一组浮点数,那最直觉的想法就是------存 MySQL 呗。
方案很简单:在表里加一个 TEXT 或 JSON 字段,把向量序列化成字符串存进去。检索的时候把所有向量读出来,在应用层逐个计算余弦相似度,排序取 Top-K。
暴力搜索在数据量小的时候没问题,但一旦数据量和并发量上去,就完全不可用了。
近似最近邻搜索
答案是可以。这就是 ANN(Approximate Nearest Neighbor,近似最近邻搜索)的核心思想。
注意这里的关键词是"近似"------ANN 不保证找到的一定是全局最相似的向量,但它能在极短的时间内找到非常接近最优解的结果。
打个比方:暴力搜索就像你要在一个 100 万人的城市里找和你最像的人,挨个去比对。ANN 则是先按区域划分,再按特征缩小范围,最后只在一小撮人里精确比较。你可能会错过某个住在偏远角落的"最佳匹配",但你找到的人已经足够像了,而且速度快了几百倍。
用数字来感受一下差距:
|-------------|----------|--------------|
| 指标 | 暴力搜索 | ANN 检索 |
| 100 万向量查询耗时 | 2~5 秒 | 1~10 毫秒 |
| 召回率(Recall) | 100%(精确) | 95%~99%(近似) |
| 是否需要专门索引 | 不需要 | 需要 |
| 适用数据量 | < 10 万 | 百万~亿级 |
1~10 毫秒 vs 2~5 秒,速度差了几百到几千倍,而召回率只损失了 1%~5%。在实际的 RAG 场景中,这点精度损失几乎感知不到------你本来就是取 Top-K 个结果丢给大模型做参考,少了一个排名第 47 的 chunk 对最终回答没有影响。
这就是向量数据库存在的核心理由:它不只是存向量,更重要的是提供高效的 ANN 检索能力。普通数据库能存向量,但做不了高效的 ANN 检索。
一句话概括:向量数据库 = 向量存储 + ANN 索引 + 高效检索。它是专门为"在海量向量中快速找到最相似的那几个"这件事而设计的。
向量检索的核心算法:怎么不用逐个比较就能找到最相似的
两种最主流的 ANN 索引算法:IVF 和 HNSW。
IVF(倒排文件索引):先分区再搜索
IVF 的全称是 Inverted File Index(倒排文件索引)。名字听起来很学术,但思路非常直觉。
2.1 IVF 的工作原理
IVF 的核心思想就一句话:把向量空间划分成若干个区域,查询时只在最可能的几个区域里搜索。
具体怎么做?分两个阶段:
建索引阶段(离线):
- 用聚类算法(通常是 K-Means)把所有向量分成
nlist个簇(cluster) - 每个簇有一个中心点(centroid),代表这个簇里所有向量的"平均位置"
- 每个向量被分配到离它最近的那个簇
检索阶段(在线):
- 拿到查询向量后,先计算它和所有簇中心点的距离
- 找到最近的
nprobe个簇(nprobe 是一个可调参数) - 只在这
nprobe个簇里的向量中做精确搜索
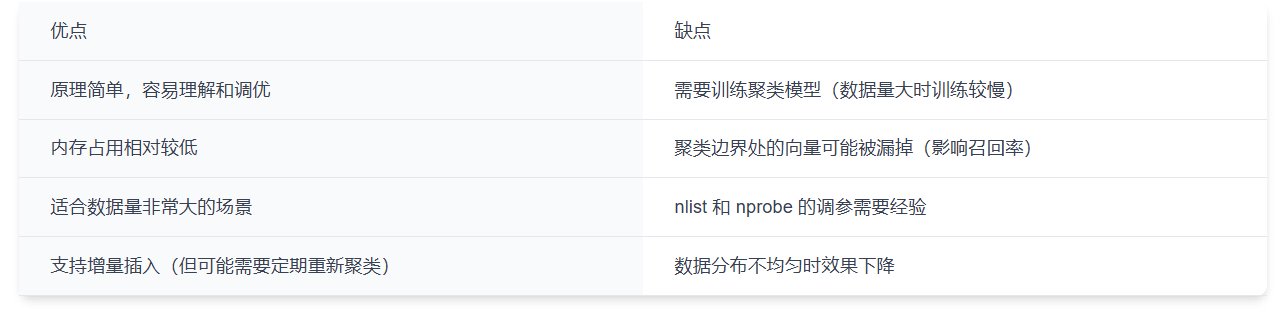
2.2 IVF 的优缺点
HNSW(分层可导航小世界图):最主流的索引算法
HNSW 的全称是 Hierarchical Navigable Small World Graph(分层可导航小世界图)。名字很长,但它是目前最主流、效果最好的 ANN 索引算法,几乎所有向量数据库都把它作为默认或推荐的索引类型。
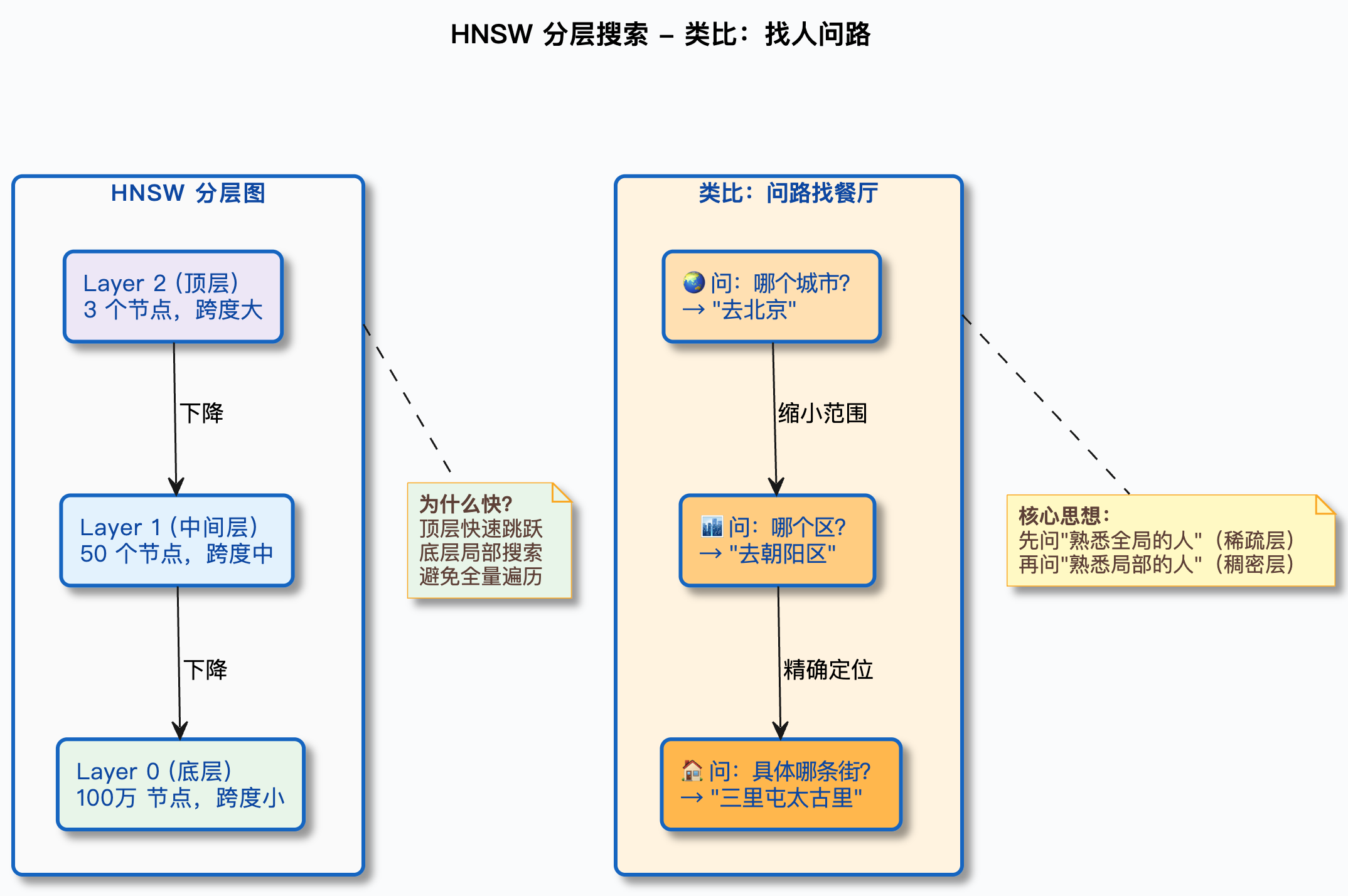
3.1 HNSW 的核心思想:多层图结构
要理解 HNSW,先从一个生活场景开始。
假设你要找一个"住在北京朝阳区、会写 Java、喜欢打篮球"的人,但你手上没有任何名单,只能通过社交关系去找。你会怎么做?
你不会挨个问全中国 14 亿人。你会这样:
- 先在你认识的人里找------"谁在北京?"------你的朋友老王在北京
- 问老王------"你认识朝阳区的人吗?"------老王介绍了他同事小李
- 问小李------"你认识会写 Java 的人吗?"------小李介绍了他的大学同学张三
- 张三恰好也喜欢打篮球------找到了!
每一步你都在靠近目标,而且每一步只需要问几个人,不需要遍历所有人。
HNSW 的思路和这个完全一样,只不过把"人"换成了"向量",把"社交关系"换成了"图中的边"。
HNSW 的核心结构是一个多层图:
- 最底层(Layer 0)包含所有向量,每个向量和它附近的若干个向量相连
- 往上每一层的向量数量越来越少(随机抽取),但连接的跨度越来越大
- 最顶层只有很少的几个向量,但它们之间的连接覆盖了整个向量空间
检索的时候,从最顶层开始,快速定位到目标的大致区域,然后逐层下降,每一层都在更精细的范围内搜索,最终在最底层找到最相似的向量。
3.2 用一个具体例子走一遍 HNSW 的检索过程
为了让你更直观地理解,咱们用一个简化的例子走一遍。
假设向量数据库里有 8 个向量(A、B、C、D、E、F、G、H),HNSW 建了 3 层图。现在要查询和向量 Q 最相似的向量。
Layer 2(顶层):只有 A 和 E 两个向量
- 从 A 开始,计算 Q 和 A 的距离、Q 和 E 的距离
- 发现 E 离 Q 更近,移动到 E
Layer 1(中间层):有 A、C、E、G 四个向量
- 从 E 出发,看 E 的邻居:C 和 G
- 计算 Q 和 C、Q 和 G 的距离
- 发现 G 离 Q 更近,移动到 G
Layer 0(底层):所有 8 个向量都在
- 从 G 出发,看 G 的邻居:F 和 H
- 计算 Q 和 F、Q 和 H 的距离
- 发现 H 离 Q 最近
- 再看 H 的邻居,没有比 H 更近的了
- 结果:H 是和 Q 最相似的向量
3.3 为什么 HNSW 这么快
HNSW 快的原因可以归结为两点:
第一,多层结构实现了"粗到细"的搜索 。顶层的少量向量帮你快速跳到目标附近,底层的密集连接帮你精确定位。这和跳表(Skip List)的思想很像------如果你了解 Redis 的有序集合(ZSet),它底层用的就是跳表,原理是相通的。
第二,**"小世界"特性保证了图的连通性。**在 HNSW 的图中,任意两个向量之间只需要经过很少的"跳转"就能到达(类似"六度分隔理论"------你和世界上任何一个人之间最多只隔 6 个人)。这意味着搜索不会陷入死角,总能快速逼近目标。
3.4 HNSW 的代价:内存占用
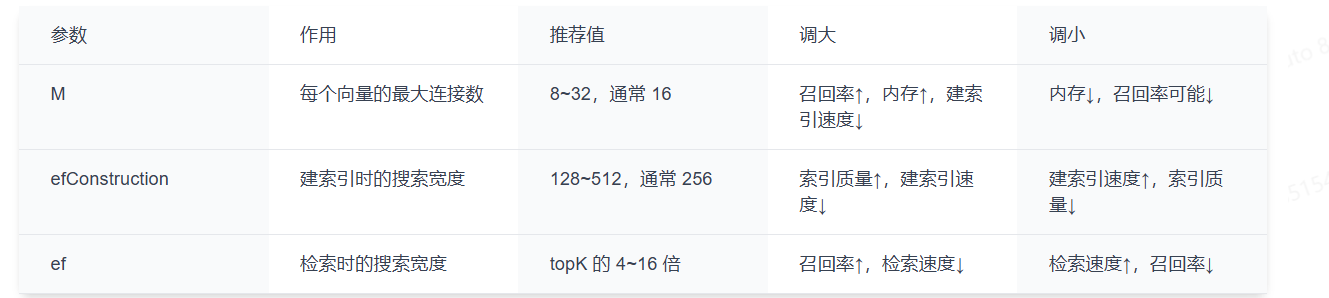
HNSW 的检索速度和精度都很优秀,但它有一个明显的代价:内存占用大。

M = 自己有几个邻居名额
efConstruction = 帮你海选找邻居的范围大小
索引算法对比:怎么选
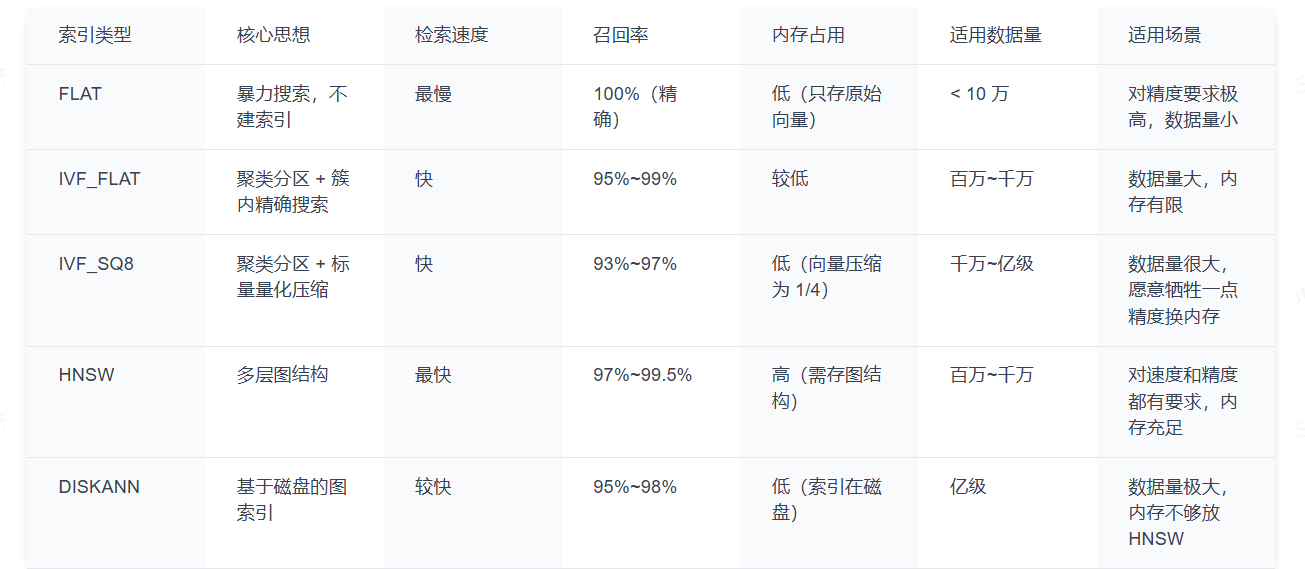
主流向量数据库对比与选型
主流方案对比
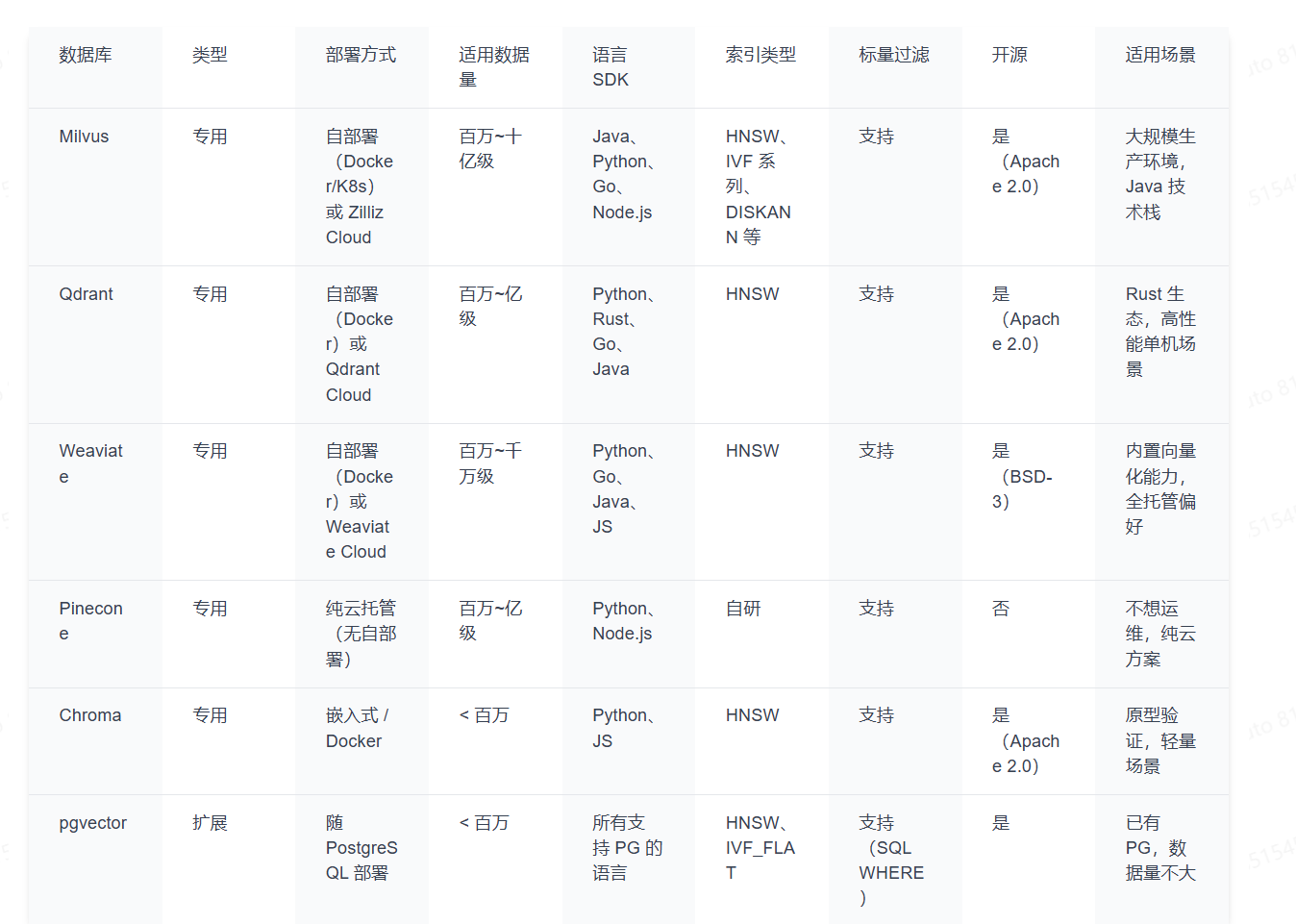
为什么选 Milvus
本系列选择 Milvus 作为向量数据库,原因有几个:
- 开源且社区活跃:Apache 2.0 协议,截止 26.2.20 号 GitHub 上 42.8k+ star,文档和社区资源丰富
- Java SDK 完善:本系列的代码示例用 Java,Milvus 的 Java SDK(
io.milvus:milvus-sdk-java)功能完整,API 设计清晰 - 支持大规模数据:从几万到几十亿向量都能应对,单机模式适合开发和中小规模,集群模式适合大规模生产
- 索引类型丰富:HNSW、IVF_FLAT、IVF_SQ8、DISKANN 等都支持,可以根据场景灵活选择
- 标量过滤能力强:支持在向量检索的同时按元数据字段过滤(比如:只在退货政策类的 chunk 里检索),这在 RAG 场景中非常实用
- 本地部署简单:一个
docker compose up -d就能启动,开发环境零门槛
Milvus 核心概念:和传统数据库做类比
在动手写代码之前,先搞清楚 Milvus 里的几个核心概念。如果你用过 MySQL,理解起来会很快------Milvus 的概念体系和关系型数据库有很多对应关系。
Collection = 表
Collection 是 Milvus 中数据组织的基本单位,对应 MySQL 中的表(Table)。
一个 Collection 存储一类向量数据。比如在我们的电商客服知识库场景中,可以创建一个名为 customer_service_chunks 的 Collection,里面存所有客服知识库的 chunk 向量。
如果你有多个业务场景(比如客服知识库、商品搜索、内容推荐),通常每个场景创建一个独立的 Collection。
Schema = 表结构
Schema 定义了 Collection 中每条数据包含哪些字段,对应 MySQL 中的表结构(CREATE TABLE 时定义的列)。
一个典型的 RAG 场景的 Schema 包含三类字段:
|------|------------------------------|------------------------|
| 字段类型 | 示例 | 说明 |
| 主键字段 | id(Int64 或 VarChar) | 每条数据的唯一标识,类似 MySQL 的主键 |
| 向量字段 | vector(FloatVector) | 存储 Embedding 向量,需要指定维度 |
| 标量字段 | chunk_text、doc_id、category 等 | 存储元数据,用于过滤和展示 |
2.1 向量字段和标量字段的区别
这里要特别说明一下向量字段和标量字段的区别,因为这是 Milvus 和传统数据库最大的不同。
标量字段存储的是普通数据(字符串、数字、布尔值等),和 MySQL 的列没什么区别。你可以对标量字段建索引、做等值查询、范围查询、模糊匹配等。
向量字段存储的是高维浮点数数组(比如 4096 维的 float 数组),它不能做等值查询(两个向量完全相等的概率几乎为零),只能做相似度检索(找最近的 Top-K 个)。向量字段需要建专门的向量索引(HNSW、IVF 等),这和标量字段的 B+ 树索引是完全不同的东西。
Index = 索引
Milvus 中的索引分两种:
- 向量索引:为向量字段创建的 ANN 索引(HNSW、IVF_FLAT 等),用于加速向量相似度检索。这是 Milvus 的核心能力。
- 标量索引:为标量字段创建的索引,用于加速过滤条件的执行。类似 MySQL 的 B+ 树索引。
在 RAG 场景中,通常需要同时用到两种索引:向量索引用于找到语义最相似的 chunk,标量索引用于按元数据过滤(比如只搜索某个类别的 chunk)。
Partition = 分区
Partition 是 Collection 内部的数据分区,对应 MySQL 的分区表。
你可以按某个业务维度把数据分到不同的 Partition 里。比如按文档类别分区:退货政策放一个 Partition,物流规则放一个 Partition,促销活动放一个 Partition。
检索的时候可以指定只在某个 Partition 里搜索,这样搜索范围更小,速度更快。
不过需要注意:Partition 不是必须的。如果你的数据量不大(< 100 万),或者没有明确的分区维度,不分区也完全没问题。用标量过滤(在 WHERE 条件里加 category = 'return_policy')也能达到类似的效果,只是在数据量很大时性能不如 Partition。
一张图看懂 Milvus 的数据组织
把上面的概念串起来,Milvus 的数据组织结构是这样的:
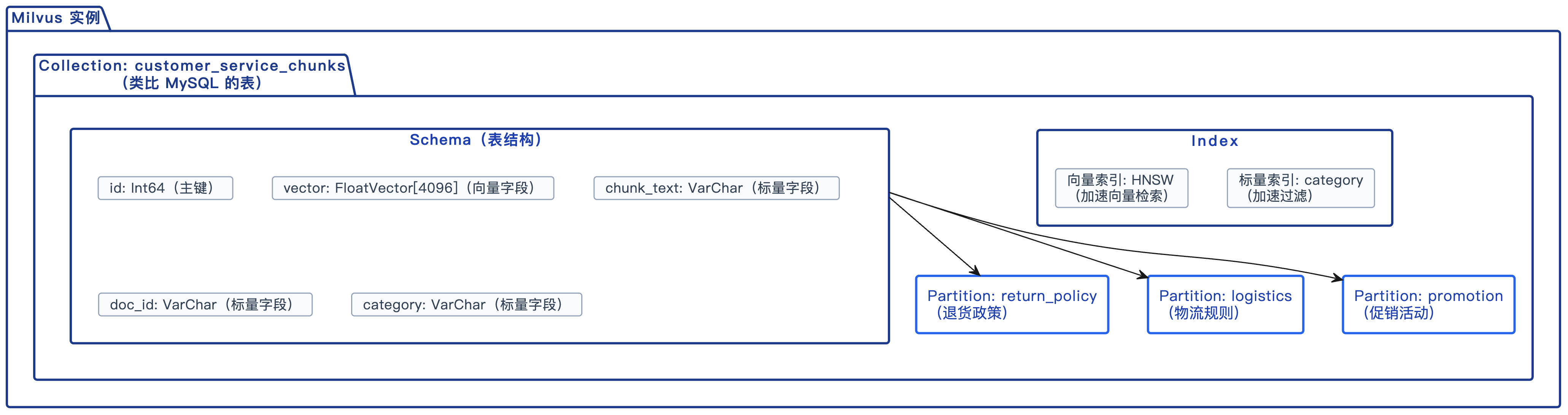
和 MySQL 做个对照:

实际项目中的关键决策
跑通了 demo,接下来聊聊实际项目中你会遇到的几个关键决策。这些决策没有标准答案,取决于你的数据量、性能要求和资源限制。
索引类型怎么选
前面的"索引算法对比"表格已经给了一个大致的方向,这里再给一个更实操的决策流程:
- 先问自己:数据量有多大?
-
- < 10 万条:直接用
FLAT,暴力搜索就够了,省去调参的麻烦 - 10 万 ~ 500 万条:优先选
HNSW,速度快、召回率高 - 500 万 ~ 5000 万条:看内存够不够。够就
HNSW,不够就IVF_SQ8(向量压缩到原来的 1/4) - 5000 万条:考虑
DISKANN(索引放磁盘)或IVF_PQ(更激进的压缩)
- < 10 万条:直接用
- 再问自己:对召回率的要求有多高?
-
- RAG 场景通常取 Top-5 到 Top-10,对召回率的容忍度较高,
HNSW和IVF_FLAT都能满足 - 如果是人脸识别、指纹匹配等对精度要求极高的场景,可能需要
FLAT或者把 HNSW 的参数调得很大
- RAG 场景通常取 Top-5 到 Top-10,对召回率的容忍度较高,
对于大多数 RAG 项目,HNSW 是默认选择,不需要纠结。
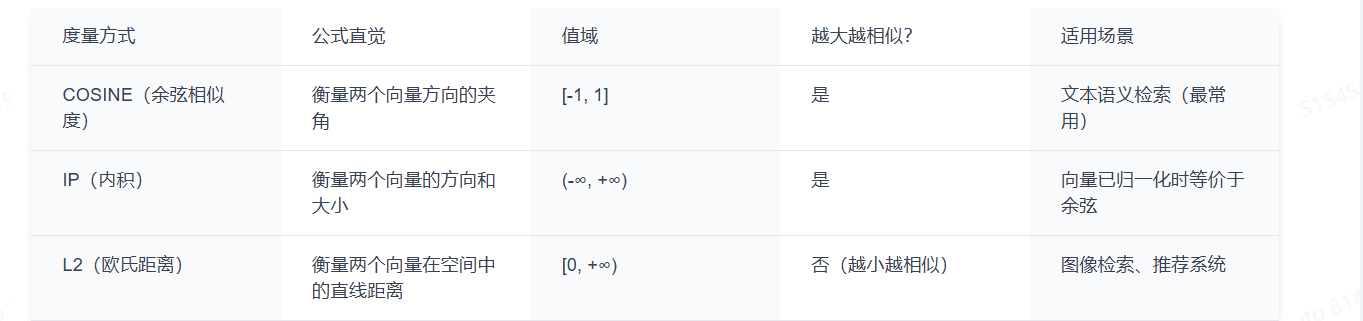
相似度度量怎么选
Milvus 支持三种相似度度量方式:
分区策略设计
Milvus 的 Partition 可以按业务维度把数据分开存储,检索时指定 Partition 可以缩小搜索范围。
常见的分区策略:

性能调优的几个关键参数
5.1 HNSW 索引参数
5.2 IVF 索引参数

小结与下一篇预告
这一篇我们解决了向量存到哪里的问题。从暴力搜索的性能瓶颈出发,理解了为什么需要专门的向量数据库;学习了 IVF 和 HNSW 两种主流的 ANN 索引算法;对比了市面上的向量数据库方案,选定了 Milvus;最后用 Java 代码跑通了从建表到检索的完整流程。
到这里,RAG 的离线数据准备链路已经打通了:原始文档 → Tika 提取文本 → 分块 → 元数据管理 → 向量化 → 存入 Milvus。
但数据准备好只是第一步。当用户真正提问的时候,怎么从 Milvus 里检索出最相关的 chunk?只靠向量相似度够吗?
答案是:不够。
纯向量检索有一个天然的短板------它擅长语义匹配,但对关键词匹配不敏感。比如用户问:订单号 2026012345 的物流状态,这里面最关键的信息是订单号,但向量检索可能会忽略这个精确的数字,转而匹配一些语义上"像是在问物流"的 chunk。
下一篇我们就来解决这个问题:检索策略。会讲到关键词检索(BM25)、混合检索(向量 + 关键词)、以及重排序(Reranking)------这些策略组合起来,才能让 RAG 系统的检索质量真正达到生产可用的水平。