目录
-
- [1 前言](#1 前言)
- [2 技术背景](#2 技术背景)
-
- [2.1 MoE架构与DeepSeek V4的定位](#2.1 MoE架构与DeepSeek V4的定位)
- [2.2 API兼容模式与思考模式](#2.2 API兼容模式与思考模式)
- [2.3 定价策略与选型建议](#2.3 定价策略与选型建议)
- [3 快速上手:30分钟跑通第一个应用](#3 快速上手:30分钟跑通第一个应用)
-
- [3.1 环境准备与安装](#3.1 环境准备与安装)
- [3.2 基础对话调用](#3.2 基础对话调用)
- [3.3 流式输出](#3.3 流式输出)
- [4 四大核心集成场景](#4 四大核心集成场景)
-
- [4.1 工具调用(Tool Calling)](#4.1 工具调用(Tool Calling))
- [4.2 结构化JSON输出](#4.2 结构化JSON输出)
- [4.3 思考模式(Reasoning)](#4.3 思考模式(Reasoning))
- [4.4 RAG知识库问答](#4.4 RAG知识库问答)
- [5 生产环境注意事项](#5 生产环境注意事项)
-
- [5.1 模型选型决策](#5.1 模型选型决策)
- [5.2 成本估算与限流处理](#5.2 成本估算与限流处理)
- [6 结语](#6 结语)
- 参考资料
1 前言
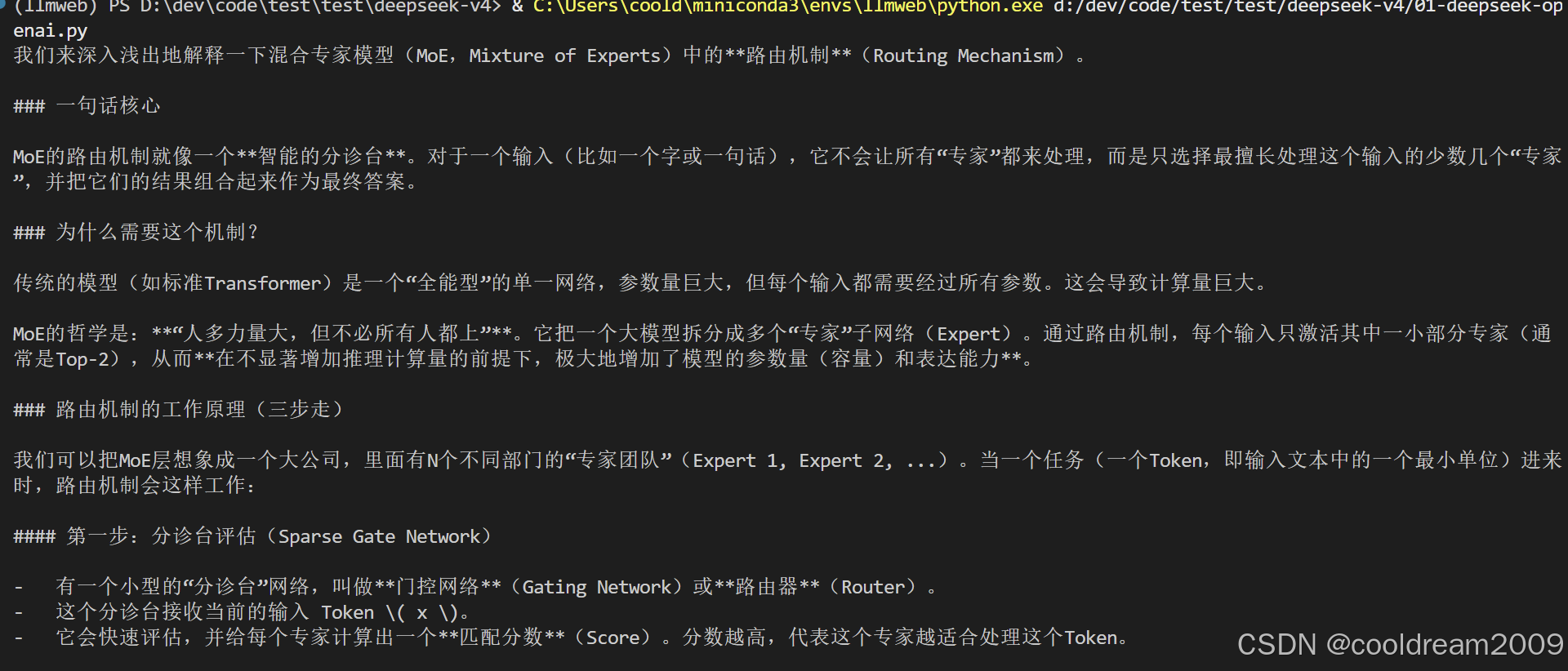
2026年4月24日,DeepSeek正式发布V4版本。作为国内最具影响力的开源大模型之一,V4在架构上延续了MoE(Mixture of Experts)路线,同时将上下文窗口提升至100万token,并原生支持OpenAI ChatCompletions和Anthropic Messages API两种兼容模式。这一发布的意义不仅是模型能力的提升,更意味着国产大模型与主流Agent开发框架的集成门槛已经降到了历史最低。
LangChain是当前最成熟的LLM应用开发框架,拥有庞大的组件生态------从Prompt模板、Chain链路、Memory对话记忆,到Tools工具调用、RAG知识库,再到Agent自主规划,几乎涵盖了LLM应用的所有核心场景。将DeepSeek V4接入LangChain,意味着开发者可以复用成熟的生态组件,快速构建基于国产大模型的智能应用。
本文围绕三个核心问题展开:DeepSeek V4是什么、有哪些核心优势;如何用LangChain调用DeepSeek V4;以及生产环境中需要注意哪些关键事项。本文面向具备一定Python基础的开发者,无需深度学习背景。
2 技术背景
2.1 MoE架构与DeepSeek V4的定位
DeepSeek V4是一系列基于MoE架构的开源大模型。MoE的核心思想是稀疏激活------模型由多个"专家"网络组成,每次推理时根据输入内容动态选择最相关的专家子集进行计算。这意味着尽管模型总参数庞大,但每次推理的实际计算量远小于总参数量,从而在效果和成本之间取得优秀平衡。
DeepSeek V4在MoE基础上还引入了两项关键技术:**MLA(Multi-head Latent Attention)**优化了注意力机制的计算效率;Auxiliary-Loss-Free Balancing解决了传统MoE训练中专家负载不均的问题,使训练过程更加稳定。
DeepSeek V4提供两个版本,其定位和适用场景有明确区分:
| 模型 | 总参数 | 活跃参数 | 上下文窗口 | 适用场景 |
|---|---|---|---|---|
| deepseek-v4-pro | 1.6万亿(1.6T) | 490亿(49B) | 1,000,000 tokens | 前沿推理、复杂Agent任务 |
| deepseek-v4-flash | 2840亿(284B) | 130亿(13B) | 1,000,000 tokens | 标准对话、RAG、分类等轻量任务 |
两者的活跃参数差距接近4倍,这个差异在复杂推理任务上会直接体现为效果差距,而在简单问答场景中体验差异则不明显。
2.2 API兼容模式与思考模式
DeepSeek V4 API于2026年4月24日上线,最大的设计理念是零学习成本。开发者无需任何新SDK,直接复用现有OpenAI工具链即可。
python
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com/v1"
)
response = client.chat.completions.create(
model="deepseek-v4-flash", messages=[{"role": "user", "content": "解释MoE路由机制"}]
)
DeepSeek V4同时支持Anthropic Messages API格式,可以直接替换Claude的调用代码。langchain-deepseek官方包继承自BaseChatOpenAI,因此所有OpenAI风格的参数如temperature、max_tokens、timeout均可直接使用,无需额外学习。
V4还引入了思考模式(Thinking Mode)。这不是简单的Chain-of-Thought,而是一种类似o1/r1的深度推理机制。思考模式有三个级别:
- disabled(默认):直接响应,速度优先
- enabled:开启结构化推理,可通过budget_tokens参数控制推理token预算
- max:最大推理强度,使用特殊系统提示词,要求至少384K token的上下文余量
在enabled和max模式下,模型的推理过程会通过reasoning_content字段单独输出,用户可以看到完整的思考链。
2.3 定价策略与选型建议
| 模型 | Cache Hit | 输入(未缓存) | 输出 |
|---|---|---|---|
| deepseek-v4-flash | $0.0028 / M tokens | $0.14 / M tokens | $0.28 / M tokens |
| deepseek-v4-pro | $0.0145 / M tokens | 0.435 / M tokens(促销)/ 1.74 / M tokens(正式) | 0.87 / M tokens(促销)/ 3.48 / M tokens(正式) |
V4-Flash的成本约为V4-Pro的1/12,日常轻量任务完全没有必要使用Pro版本。需要注意的是,旧模型ID(deepseek-chat和deepseek-reasoner)目前路由到V4-Flash,但将在2026年7月24日15:59 UTC彻底停用,新项目务必使用新ID。
3 快速上手:30分钟跑通第一个应用
3.1 环境准备与安装
LangChain官方维护了langchain-deepseek集成包,安装过程极为简单:
bash
pip install -qU langchain-deepseek langchain-core langchain-community langchain-text-splitters faiss-cpu sentence-transformers依赖要求:Python 3.10+、LangChain 0.3+。建议通过环境变量管理API Key,不要硬编码在代码中。
3.2 基础对话调用
ChatDeepSeek的核心用法与ChatOpenAI几乎完全一致:
python
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model="deepseek-v4-flash",
temperature=0,
max_tokens=512,
timeout=60,
max_retries=2,
)
messages = [
("system", "你是一位简洁的技术作者,用一句话解释概念。"),
("human", "什么是MoE路由机制?"),
]
response = llm.invoke(messages)
print(response.content)
print(response.usage_metadata) # 查看token用量
LangChain的消息格式使用(role, content)元组或BaseMessage对象。值得特别说明的是,DeepSeek API本身是无状态的,LangChain也不会自动维护对话历史。每次调用invoke都需要传入完整的消息数组,包括之前所有的对话轮次:
python
chat_history = [
("system", "你是一个友好的Python教学助手。"),
("human", "什么是列表推导式?"),
]
ai_msg_1 = llm.invoke(chat_history)
print(f"ai_msg_1:{ai_msg_1}")
# 下一轮对话需要包含AI的回复
chat_history = [
("system", "你是一个友好的Python教学助手。"),
("human", "什么是列表推导式?"),
("ai", ai_msg_1.content),
("human", "给个例子。"),
]
ai_msg_2 = llm.invoke(chat_history)
print(f"ai_msg_2:{ai_msg_2}")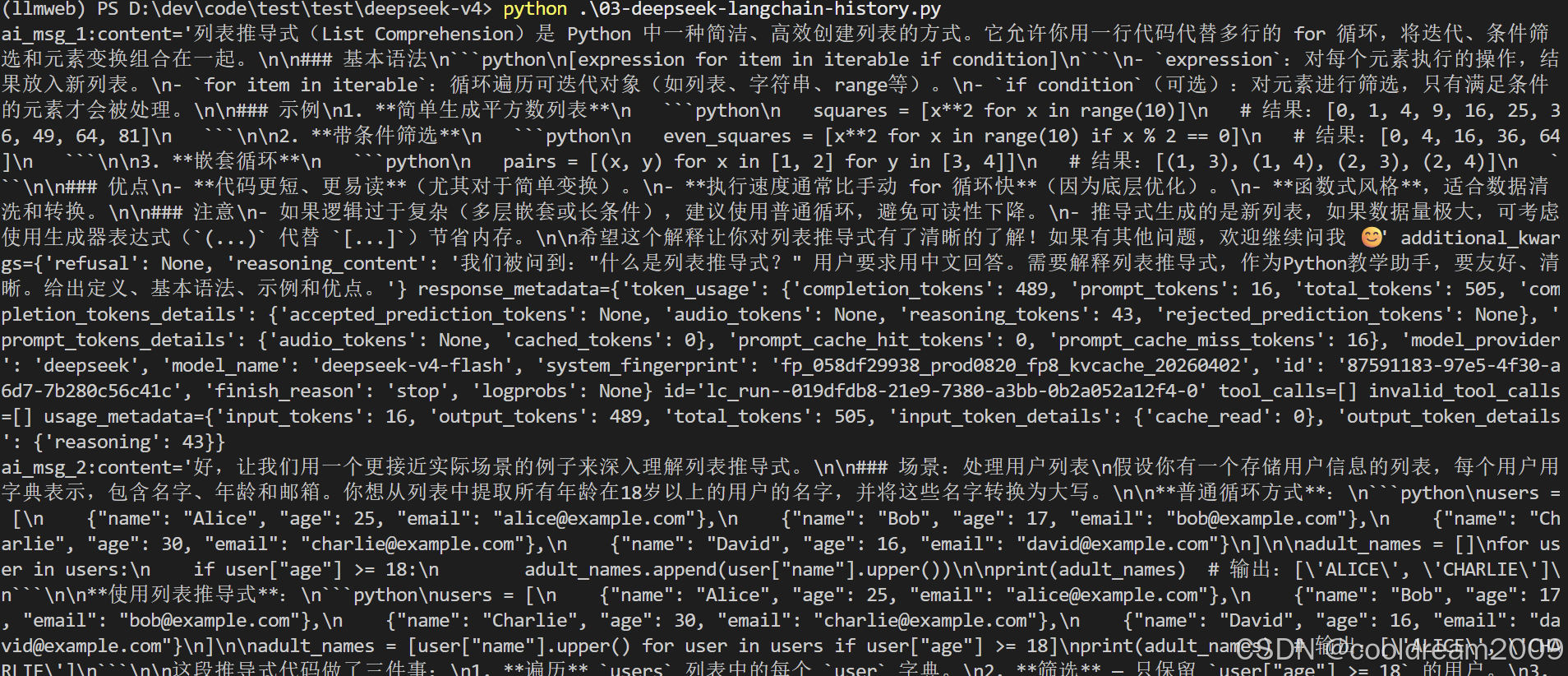
3.3 流式输出
python
for chunk in llm.stream("用三句话解释LangChain的核心思想"):
print(chunk.content, end="", flush=True)
在思考模式下,推理内容和最终答案会作为不同的chunks分别流出,通过检查chunk.additional_kwargs.get("reasoning_content")来区分两者。
4 四大核心集成场景
4.1 工具调用(Tool Calling)
工具调用是Agent系统的基石,让大模型能够调用外部工具突破自身的知识边界和能力限制。在LangChain中使用DeepSeek V4进行工具调用,只需三个步骤:
第一步,用@tool装饰器定义工具函数:
python
from langchain_core.tools import tool
@tool
def get_weather(city: str) -> str:
"""查询指定城市的当前天气"""
weather_data = {"北京": "14°C,多云", "上海": "18°C,小雨"}
return weather_data.get(city, f"未找到 {city} 的天气数据")
@tool
def calculator(expression: str) -> str:
"""执行数学表达式计算"""
try:
result = eval(expression, {"__builtins__": {}}, {})
return str(result)
except Exception as e:
return f"计算错误: {e}"第二步,将工具绑定到模型并发起调用:
python
llm = ChatDeepSeek(model="deepseek-v4-flash", temperature=0)
agent = llm.bind_tools([get_weather, calculator])
reply = agent.invoke("北京现在天气如何?顺便帮我算一下 256 * 128")
print(reply.tool_calls)第三步,将工具结果回传给模型生成最终答案:
这一步需要手动将工具返回值作为消息继续投入Chain,模型会根据工具结果给出最终回复。完整实现可结合LangChain的create_react_agent构建自动化的ReAct循环。
有一点需要特别注意:DeepSeek API对strict=True(强制严格工具调用格式)的支持是最佳努力级别。在复杂嵌套参数场景下,建议在system prompt中明确约定格式,并增加容错处理逻辑。

4.2 结构化JSON输出
很多应用场景要求模型输出机器可读的结构化数据,而非自然语言。ChatDeepSeek通过response_format参数支持JSON输出模式,但JSON模式的本质是"引导"模型输出JSON而非"强制",因此需要配套的工程手段确保可靠性:
在system prompt中明确要求输出JSON并在内容中包含"json"关键词;在prompt中给出字段示例以降低格式歧义;max_tokens需要设置足够大避免输出被截断;代码层实施容错解析:
python
import json
def extract_json(response_text: str, fallback: dict = None) -> dict:
try:
return json.loads(response_text)
except json.JSONDecodeError:
cleaned = response_text.strip().removeprefix("```json").removeprefix("```").strip()
try:
return json.loads(cleaned)
except json.JSONDecodeError:
return fallback or {}
llm = ChatDeepSeek(model="deepseek-v4-flash", temperature=0)
# 让模型输出 JSON 格式
response = llm.invoke(
"请以 JSON 格式返回北京和上海两个城市的天气信息,包含 city、weather、temperature 字段"
)
print("模型原始输出:")
print(repr(response.content))
# 提取 JSON
data = extract_json(response.content)
print("提取的 JSON 数据:")
print(data)
4.3 思考模式(Reasoning)
思考模式是V4-Pro最具差异化的特性。在enabled模式下,模型会先生成一段结构化的推理过程,再给出最终答案。这在数学推导、代码调试、逻辑分析等需要严密推理的场景中效果拔群:
python
reasoner = ChatDeepSeek(
model="deepseek-v4-pro",
temperature=0,
max_tokens=8192,
)
result = reasoner.invoke(
[("human", "鸡兔同笼:共有35个头,94只脚,问鸡和兔各多少只?请逐步推理。")]
)
print("推理过程:", result.additional_kwargs.get("reasoning_content"))
print("最终答案:", result.content)通过budget_tokens参数可以精细控制推理成本。例如设置budget_tokens为8000,模型的推理过程最多消耗8000个token后强制进入最终答案阶段。
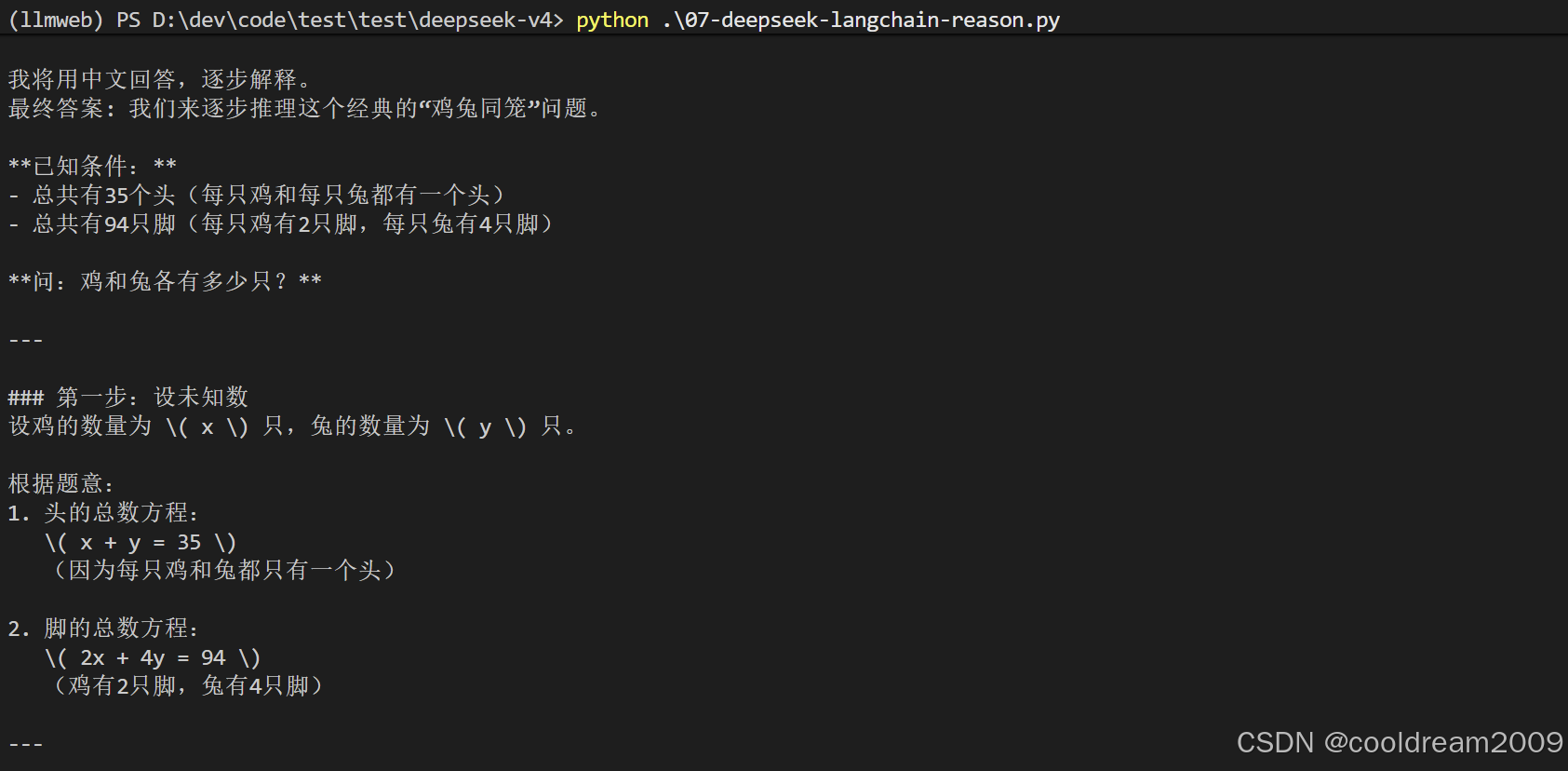
思考强度的提升会直接带来响应延迟的增加。对于实时客服等延迟敏感型场景,建议使用disabled模式。简单任务的推理开销往往大于直接回答的开销,选择合适的模式比一味开启推理更重要。
4.4 RAG知识库问答
RAG(Retrieval-Augmented Generation)是企业知识管理最成熟的技术路径。当模型需要回答关于私有文档、实时数据、特定领域知识的问题时,RAG通过"先检索再生成"的范式有效规避模型的幻觉问题。
DeepSeek目前尚未提供官方Embeddings API,因此需要引入第三方方案。HuggingFace的sentence-transformers是最流行的开源选择,完全免费且效果稳定。以下是LangChain中搭建完整RAG Chain的示例:
python
from langchain_deepseek import ChatDeepSeek
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 第一步:构建向量数据库
docs = [
"DeepSeek V4于2026年4月24日发布,包含Pro和Flash两个版本。",
"V4-Pro拥有1.6T总参数和49B活跃参数的MoE架构。",
"V4-Flash总参数284B,活跃参数13B,上下文窗口均为1M tokens。",
"DeepSeek API完全兼容OpenAI SDK,只需更换model名称即可迁移。",
]
emb = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
store = FAISS.from_texts(docs, emb)
# 第二步:配置检索器
retriever = store.as_retriever(search_kwargs={"k": 2})
# 第三步:组装LangChain Chain
llm = ChatDeepSeek(model="deepseek-v4-flash", temperature=0)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| ChatPromptTemplate.from_messages([
("system", "你是一个技术助手,使用提供的上下文信息回答用户问题。"
"如果上下文中没有相关信息,请直接说明,不要编造。"),
("human", "上下文信息:\n{context}\n\n用户问题:{question}")
])
| llm
| StrOutputParser()
)
# 第四步:执行查询
result = chain.invoke("DeepSeek V4的上下文窗口有多大?")
print(result)
向量数据库可根据规模选择不同方案:FAISS适合单机轻量部署;Milvus支持大规模分布式检索;Qdrant以Rust实现著称,高性能且支持元数据过滤;Chroma适合快速原型验证。
5 生产环境注意事项
5.1 模型选型决策
模型选型的基本原则是:简单任务用V4-Flash,复杂推理用V4-Pro,需要暴露推理过程时加思考模式。V4-Flash的成本约为V4-Pro的1/12,在大多数生产场景下应作为默认选择,只有在V4-Flash效果明显不足时才升级到Pro版本。
5.2 成本估算与限流处理
以一个月处理100万次请求的典型场景为例:每次请求携带2000 token的系统提示词(可缓存)、200 token用户消息(未缓存)、300 token回复。在缓存提示词的前提下,V4-Flash月度成本约为117美元,V4-Pro约为1421美元,成本差距超过12倍。
限流处理建议使用指数退避重试机制:
python
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def call_with_retry(llm, messages):
return llm.invoke(messages)多轮对话的上下文管理也很重要。尽管V4提供了1M token的超大上下文,但长期对话仍可能溢出。建议的做法是保留system prompt和最近10轮对话,对更早的消息进行截断。
6 结语
DeepSeek V4与LangChain的集成,标志着国产大模型与主流Agent开发框架的深度握手。从目前的生态完整性来看,工具调用、流式输出、结构化输出等核心能力均已支持,1M上下文窗口在开源模型中无出其右,为长文档处理和长程Agent提供了坚实底座。同时也要看到,官方Embeddings API尚待上线,思考模式在复杂工具调用场景下的遵循度有进一步提升空间。
未来有几个值得关注的演进方向:DeepSeek官方Embeddings API上线后将进一步简化RAG Pipeline并降低成本;LangChain Agent在工具调用上的可靠性将随模型迭代持续提升;vLLM和Ollama对V4的本地部署支持正在完善,适合对数据敏感或成本极度优化的场景;生产环境中基于任务复杂度自动路由到不同模型的智能路由方案也将逐步成熟。
参考资料
- DeepSeek API官方文档:https://api-docs.deepseek.com
- LangChain DeepSeek集成文档:https://docs.langchain.com/oss/python/integrations/chat/deepseek
- LangChain官方参考文档:https://reference.langchain.com/python/langchain-deepseek
- DeepSeek思考模式指南:https://api-docs.deepseek.com/guides/thinking_mode
- LangChain RAG教程:https://python.langchain.com/docs/tutorials/rag/