TL;DR
- 场景:开发者需要把本地模型、云端模型和开发工具连接成一套可用的AI工作流,而非单纯在本地运行模型
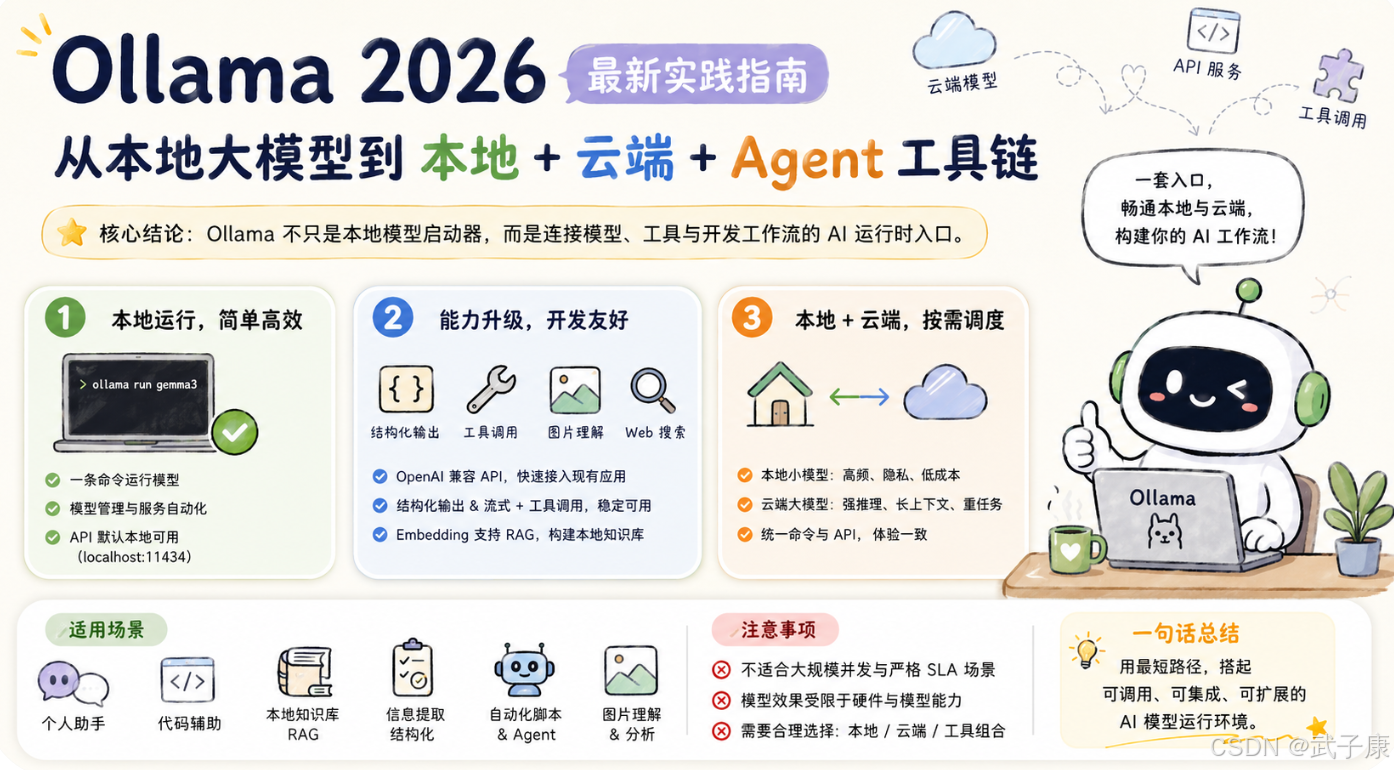
- 结论:Ollama已从"本地大模型启动器"演变为面向开发者的本地AI运行时入口,支持OpenAI兼容API、Structured Outputs、Tool Calling、Vision、Embeddings、Web Search、Cloud Models及IDE集成
- 产出:完整的Ollama能力全景图、分层使用建议(日常问答/编程/推理/Vision/RAG)、最小实践路线(8步从安装到接入Agent工具链)
版本矩阵
| 功能 | 版本/年份 | 状态 | 说明 |
|---|---|---|---|
| Ollama | 2026年最新版 | ✅ 已验证 | 本地AI运行时入口 |
| OpenAI-compatible API | Ollama内置 | ✅ 已验证 | base_url改为http://localhost:11434/v1 |
| Structured Outputs | Ollama内置 | ✅ 已验证 | 通过format参数指定JSON Schema |
| Tool Calling | Ollama内置 | ✅ 已验证 | 支持Function Calling |
| Streaming + Tool Calling | Ollama内置 | ✅ 已验证 | 流式输出配合工具调用 |
| Thinking控制 | 支持模型如qwen3/deepseek-r1 | ✅ 已验证 | 通过think参数控制 |
| Vision多模态 | 支持gemma3等模型 | ✅ 已验证 | 支持图片输入 |
| Embeddings | Ollama内置 | ✅ 已验证 | ollama run embeddinggemma |
| Web Search | Ollama云服务 | ✅ 已验证 | 需要API Key |
| Cloud Models | Ollama 2026新增 | ✅ 已验证 | qwen3-coder:480b-cloud类云端模型 |
| Claude Code集成 | 第三方工具链 | ✅ 已验证 | 支持Ollama作为后端 |
| VS Code/Cline/Zed | 第三方工具链 | ✅ 已验证 | 可接入Ollama模型 |
文章正文
Ollama 2026 最新实践指南:从本地大模型到本地 + 云端 + Agent 工具链
如果你在 2024 或 2025 年写过一篇 Ollama 入门文章,那么到 2026 年,这篇文章大概率已经过时了。
过去很多人理解 Ollama,核心只有一句话:在本地一行命令运行大模型。
这个理解没有错,但已经不完整。
2026 年再看 Ollama,它已经不是单纯的"本地大模型启动器",而更像一个面向开发者的本地 AI 运行时入口。它把模型下载、模型运行、API 服务、OpenAI 兼容接口、结构化输出、工具调用、图片理解、Embedding、Web Search、云端大模型、IDE 集成、Agent 工具链连接到了一起。
简单说,过去的 Ollama 解决的是"怎么在电脑上跑一个模型"。
现在的 Ollama 解决的是"怎么把本地模型、云端模型和现有开发工具连接成一套可用的 AI 工作流"。
一、Ollama 到底是什么
Ollama 是一个用于运行大语言模型和多模态模型的工具。它最大的特点是使用门槛低。
安装 Ollama 之后,可以直接通过命令运行模型:
bash
ollama run gemma3也可以运行其他模型:
bash
ollama run qwen3
ollama run deepseek-r1:8b
ollama run qwen3-coder:30b它会自动处理模型拉取、模型管理、本地推理服务等细节。
对普通用户来说,Ollama 是一个本地 AI 对话工具。
对开发者来说,Ollama 更重要的价值是:它默认在本地启动一个 API 服务,地址通常是:
http://localhost:11434这意味着你可以把它接入 Python、JavaScript、Go、Java、RAG 系统、智能体框架、IDE 插件、自动化脚本,甚至接入你自己的业务系统。
二、为什么旧版 Ollama 文章会过时
旧版 Ollama 教程通常会讲这些内容:
- 如何安装 Ollama
- 如何运行 llama、mistral、qwen 等模型
- 如何通过 API 调用
- 如何接入 LangChain 或本地知识库
- 如何用 Docker 部署
这些内容现在仍然有用,但已经不够。
因为 Ollama 的关键变化不只是"支持了更多模型",而是整个能力边界扩大了。
现在写 Ollama,至少要补上这些内容:
- 本地模型和云端模型的统一体验
- OpenAI-compatible API
- Structured Outputs 结构化输出
- Tool Calling 工具调用
- Streaming + Tool Calling
- Vision 图片理解
- Embeddings 与 RAG
- Web Search API
- IDE 与 Coding Agent 集成
- 模型调度与多 GPU 性能优化
- 与 Claude Code、Codex、VS Code、Zed、Cline、Roo Code 等工具的连接方式
所以,如果你的旧文还停留在"本地跑 llama2 / llama3"这种角度,那它已经不适合继续代表 2026 年的 Ollama。
三、Ollama 的核心价值:把模型运行变简单
很多开源模型本身并不难找,真正麻烦的是运行。
你需要考虑:
- 模型格式
- 量化版本
- 显存占用
- CPU/GPU 调度
- 推理服务
- API 封装
- 模型更新
- 多模型切换
- 本地开发工具接入
Ollama 把这些复杂度收敛到几个命令里。
查看本地已有模型:
bash
ollama list运行模型:
bash
ollama run gemma3拉取模型:
bash
ollama pull qwen3删除模型:
bash
ollama rm qwen3查看运行中的模型:
bash
ollama ps本质上,Ollama 做的是一层"模型运行抽象"。你不需要每次都手动处理模型文件、推理后端、服务启动和参数配置。
四、Ollama 的 API:真正适合开发者的部分
Ollama 默认提供本地 API。
最基础的文本生成接口:
bash
curl http://localhost:11434/api/generate -d '{
"model": "gemma3",
"prompt": "用一句话解释什么是 Ollama"
}'对话接口:
bash
curl http://localhost:11434/api/chat -d '{
"model": "gemma3",
"messages": [
{
"role": "user",
"content": "为什么本地大模型对开发者重要?"
}
]
}'这意味着你可以把 Ollama 当成本地 LLM 服务使用。
如果你之前用过 OpenAI API,会更容易迁移。Ollama 支持部分 OpenAI-compatible API,很多工具只需要把 base_url 改成:
http://localhost:11434/v1例如 Python 里可以这样写:
python
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama"
)
response = client.chat.completions.create(
model="gemma3",
messages=[
{"role": "user", "content": "写一个 Python 快速排序示例"}
]
)
print(response.choices[0].message.content)这对开发者很关键。
因为你不用重写整个应用,只需要把原来面向 OpenAI 的调用改成本地 Ollama 服务,就可以快速验证本地模型效果。
五、Structured Outputs:让模型输出稳定 JSON
以前用本地模型做业务集成,最大的问题之一是输出不稳定。
你希望它返回 JSON,它可能返回一段解释。
你希望字段叫 name,它可能写成 username。
你希望返回数组,它可能混入 Markdown。
这对业务系统是灾难。
Structured Outputs 的价值就在这里:你可以给模型一个 JSON Schema,让它尽量按照固定结构返回。
示例:
bash
curl -X POST http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "gemma3",
"messages": [
{
"role": "user",
"content": "从这句话中提取人物、地点和时间:明天下午三点,张三要去北京开会。"
}
],
"stream": false,
"format": {
"type": "object",
"properties": {
"person": { "type": "string" },
"location": { "type": "string" },
"time": { "type": "string" }
},
"required": ["person", "location", "time"]
}
}'这类能力特别适合:
- 信息抽取
- 表单解析
- 文档结构化
- 图片内容结构化
- 业务参数提取
- Function Call 前置参数整理
- RAG 检索结果规范化
对于开发者来说,Structured Outputs 是 Ollama 从"玩具工具"走向"工程工具"的关键能力。
六、Tool Calling:让本地模型调用外部工具
Tool Calling 也叫 Function Calling。它的作用是让模型不只是回答文本,而是可以决定是否调用某个外部函数。
例如你给模型一个天气工具:
json
{
"type": "function",
"function": {
"name": "get_temperature",
"description": "Get the current temperature for a city",
"parameters": {
"type": "object",
"required": ["city"],
"properties": {
"city": {
"type": "string",
"description": "The name of the city"
}
}
}
}
}当用户问:
What is the temperature in New York?模型可以判断:这个问题不能只靠模型内部知识回答,需要调用 get_temperature 工具。
这就是 Agent 的基础。
没有 Tool Calling,本地模型只能聊天。
有了 Tool Calling,本地模型就可以连接外部世界。
它可以调用:
- 天气 API
- 搜索 API
- 数据库查询
- 文件系统
- 代码执行器
- 内部业务系统
- IoT 设备
- 机器人控制接口
- 企业知识库
- MCP Server
这也是为什么 2026 年写 Ollama,不能只写"本地聊天"。它已经进入了 Agent 工具链。
七、Streaming + Tool Calling:体验更接近真实产品
过去工具调用常见的问题是:模型必须先完整生成,再调用工具,再返回结果。
这会导致等待时间长,交互体验差。
Ollama 后续增强了 Streaming responses with tool calling。它允许应用一边流式输出内容,一边处理工具调用。
这对语音助手、聊天机器人、Coding Agent、Web 助手都很重要。
例如一个 AI 助手回答用户问题时,可以先显示"正在查询天气",同时触发天气工具,然后继续生成最终答案。
这类能力看起来只是体验优化,但在真实产品中非常关键。
因为用户不是只看结果,还会感知响应速度、等待过程和系统是否"活着"。
八、Thinking:控制模型是否显示思考过程
Ollama 也支持 thinking 相关能力。
在一些支持 thinking 的模型中,可以通过参数控制是否启用思考过程。
例如:
bash
curl http://localhost:11434/api/chat -d '{
"model": "qwen3",
"messages": [
{
"role": "user",
"content": "9.9 和 9.11 哪个更大?"
}
],
"think": true,
"stream": false
}'这类能力适合需要推理的任务,比如数学、代码分析、复杂决策、逻辑推断。
但不是所有任务都适合打开 thinking。
如果只是做摘要、翻译、简单问答、分类,thinking 可能会增加延迟。
更合理的方式是:
- 简单任务:关闭 thinking,追求速度
- 复杂任务:开启 thinking,追求准确性
- 产品场景:隐藏 thinking,只展示最终结果
- 调试场景:保留 thinking,用于观察模型行为
开发者需要明白:thinking 不是越多越好,它是一种成本和质量之间的调节旋钮。
九、Vision:Ollama 不再只是文本模型入口
2026 年再看 Ollama,另一个重要变化是多模态能力。
Vision models 可以接收图片,然后回答关于图片的问题。
命令行示例:
bash
ollama run gemma3 ./image.png "这张图里有什么?"API 中也可以传入图片。
这类能力适合:
- 图片描述
- 图片分类
- 截图理解
- 文档图像解析
- UI 分析
- 票据识别
- 表格截图理解
- 设备巡检图片分析
- 技术博客封面草图分析
这让 Ollama 的定位继续扩大:它不只是 LLM Runtime,也是本地多模态模型入口。
十、Embeddings:本地 RAG 的基础
如果你要做本地知识库,Embedding 是绕不开的。
Ollama 支持生成 Embeddings,可以用于语义搜索、文档检索、RAG。
示例:
bash
ollama run embeddinggemma "Hello world"也可以通过 API 调用生成向量,然后存入向量数据库。
典型 RAG 流程是:
- 把文档切块
- 对每个文本块生成 embedding
- 存入向量数据库
- 用户提问时生成 query embedding
- 检索最相关的文本块
- 把检索结果交给大模型回答
Ollama 在这里的价值是:Embedding 和生成模型都可以本地化。
这对隐私敏感、内网部署、企业知识库、个人资料管理都很有意义。
十一、Web Search:弥补本地模型知识过时问题
本地模型有一个天然问题:知识截止时间固定。
它不知道今天新闻。
不知道实时价格。
不知道最新政策。
不知道刚发布的技术文档。
Web Search API 的意义就是把模型和最新信息连接起来。
这类能力适合:
- 新闻查询
- 技术资料更新
- 价格查询
- 产品规格对比
- 最新文档检索
- 长任务研究
- Agent 自主搜索
不过要注意,Web Search 不是本地能力,它需要 Ollama 账号和 API key。它更像是 Ollama 提供的一种云端检索能力。
如果你做的是纯本地、纯离线场景,就不能依赖它。
十二、Cloud Models:本地电脑不够用时的补充
Ollama 的另一个重要变化是 Cloud Models。
过去,Ollama 强调本地运行。
但现实是,大模型越来越大。不是每个人都有 24GB、48GB、80GB 显存,也不是所有模型都适合在本地跑。
Cloud Models 的思路是:保留 Ollama 的使用方式,但模型可以跑在云端。
例如:
bash
ollama run qwen3-coder:480b-cloud这类体验的价值是:你仍然可以用熟悉的 Ollama 命令、API 和工具链,但不再受限于本地硬件。
这不是取代本地模型,而是补充本地模型。
合理的使用方式是:
- 本地小模型:处理日常任务、隐私数据、低成本推理
- 云端大模型:处理复杂代码、长上下文、强推理任务
- 本地 Embedding:处理知识库索引
- 云端模型:处理高质量生成和复杂 Agent 流程
Ollama 未来的关键价值,很可能就是把本地和云端统一到一个开发体验里。
十三、IDE 和 Coding Agent 集成:Ollama 正在进入开发工作流
Ollama 现在已经不是孤立运行模型了。
它开始和开发者日常工具结合。
例如:
- VS Code
- Zed
- Claude Code
- Codex
- Cline
- Roo Code
- OpenCode
- Droid
这意味着你可以把 Ollama 模型直接接入代码编辑器和 Coding Agent。
比如在 VS Code 中,可以让 Copilot Chat 选择 Ollama 模型。
在 Claude Code 或其他 Agent 工具里,可以让本地模型作为模型后端。
在 Codex 类工具中,也可以通过 Ollama 接入模型。
这类能力对程序员的价值很大。
因为本地模型不一定要替代最强的闭源模型,但它可以承担很多低成本、高频、可本地化的任务:
- 解释代码
- 生成小函数
- 写测试用例
- 扫描日志
- 总结文档
- 生成 SQL
- 生成脚本
- 重构小模块
- 辅助写博客
- 处理隐私代码片段
真正合理的 AI 编程工作流,不是所有任务都用最贵的模型,而是按任务分层。
复杂架构设计、困难 Bug、长上下文重构,可以用强模型。
简单解释、模板生成、局部修改、日志分析,可以用本地模型。
Ollama 正好适合作为这一层本地模型入口。
十四、模型调度和性能:2026 年更值得关注
本地模型最大的问题之一是资源管理。
模型太大,会爆显存。
上下文太长,会占用大量显存。
多模型同时运行,会出现调度问题。
多 GPU 或异构 GPU,也会有资源分配问题。
Ollama 的新模型调度能力,重点就是改善这些问题。
它会更精确地测量模型运行所需内存,减少显存溢出,并提高 GPU 利用率。
这对个人用户和工作站用户都很重要。
尤其是下面这些场景:
- 24GB 显存运行中型模型
- 48GB 或多卡运行长上下文模型
- 同时运行 embedding 模型和 chat 模型
- 在本地跑 vision 模型
- 让多个工具共享同一个 Ollama 服务
过去你可能会觉得 Ollama 只是"能跑起来"。
现在更应该关注它"能不能稳定跑、能不能高效跑、能不能调度多个模型"。
十五、推荐的模型选择思路
模型选择没有固定答案,但可以按任务分类。
1. 日常问答和轻量任务
可以选择较小的通用模型,例如:
bash
ollama run gemma3
ollama run qwen3适合:
- 日常问答
- 摘要
- 翻译
- 简单写作
- 文本分类
- 短代码解释
2. 编程任务
可以选择 coder 类模型:
bash
ollama run qwen3-coder:30b如果本地硬件不够,可以考虑 cloud 版本:
bash
ollama run qwen3-coder:480b-cloud适合:
- 代码生成
- 单文件页面生成
- 单元测试
- 脚本生成
- 局部重构
- 报错分析
3. 推理任务
可以选择支持 thinking 的模型,例如:
bash
ollama run deepseek-r1:8b
ollama run qwen3适合:
- 数学推理
- 逻辑分析
- 多步骤问题
- 决策比较
- 复杂代码解释
4. 图片理解
可以选择 vision 模型,例如:
bash
ollama run gemma3 ./image.png "分析这张图片"适合:
- 图片问答
- 截图理解
- 图表理解
- 文档图片分析
- UI 分析
5. RAG 和语义搜索
可以选择 embedding 模型:
bash
ollama run embeddinggemma "要向量化的文本"适合:
- 本地知识库
- 文档检索
- 相似内容搜索
- 问答系统
- 个人资料库
十六、Ollama 适合什么场景
Ollama 适合这些场景:
- 个人本地 AI 助手
- 本地知识库
- 内网 RAG
- 代码辅助
- 自动化脚本
- Agent 原型验证
- 结构化信息提取
- 图片理解实验
- 企业内部模型验证
- 低成本 AI 开发环境
尤其适合开发者。
因为开发者真正需要的不是一个聊天窗口,而是一个可以被程序调用、可以接入工具、可以和系统结合的模型运行环境。
十七、Ollama 不适合什么场景
Ollama 也不是万能的。
它不适合这些情况:
- 你没有本地硬件,又必须运行大模型
- 你要求模型质量稳定超过顶级闭源模型
- 你需要大规模并发生产服务
- 你需要严格 SLA
- 你需要复杂权限、审计、计费、队列、监控体系
- 你希望完全不用理解模型差异
Ollama 很适合开发、实验、原型、个人工具、内部工具、小规模服务。
但如果是高并发生产系统,仍然需要更完整的模型服务架构,比如队列、限流、缓存、监控、模型网关、日志审计、异常降级等。
不能因为 Ollama 简单,就把它误认为完整的企业级 LLM 平台。
十八、一个更现实的 Ollama 工作流
我认为 2026 年更合理的 Ollama 使用方式是分层。
第一层:本地模型用于高频低成本任务。
例如:
- 总结
- 翻译
- 日志分析
- 简单代码
- 文档整理
- 本地知识库问答
第二层:云端大模型用于复杂任务。
例如:
- 大项目重构
- 架构设计
- 复杂推理
- 长上下文分析
- 高质量代码生成
第三层:Tool Calling 和 MCP 接入外部系统。
例如:
- 搜索
- 数据库
- 文件系统
- 内部 API
- 自动化工具
- 机器人或设备控制
第四层:IDE 和 Agent 工具承载实际工作流。
例如:
- VS Code
- Claude Code
- Codex
- Cline
- Roo Code
- Zed
这样 Ollama 就不是一个孤立工具,而是 AI 工作流中的模型运行层。
十九、最小实践路线
如果你是第一次使用 Ollama,可以按这个路线走。
第一步,安装 Ollama。
第二步,运行一个通用模型:
bash
ollama run gemma3第三步,测试 API:
bash
curl http://localhost:11434/api/chat -d '{
"model": "gemma3",
"messages": [
{
"role": "user",
"content": "用三句话介绍 Ollama"
}
]
}'第四步,测试 OpenAI-compatible API,把你的应用 base_url 改成:
http://localhost:11434/v1第五步,测试结构化输出,让模型返回固定 JSON。
第六步,测试 embedding,做一个本地知识库 Demo。
第七步,测试 tool calling,把模型接入一个真实函数。
第八步,把 Ollama 接入 VS Code、Claude Code、Cline 或其他开发工具。
这条路线比单纯聊天更有价值。
因为它能让你从"会用 Ollama"走向"能把 Ollama 集成到系统里"。
二十、结论:Ollama 的定位已经变了
2026 年再看 Ollama,它的核心价值不是"本地运行模型"这么简单。
它真正的价值是:
把模型运行、API 调用、结构化输出、工具调用、图片理解、Embedding、云端模型、开发工具集成,压缩成一个简单的开发者入口。
过去它是本地大模型入门工具。
现在它更像是本地 AI Runtime。
未来它可能会成为个人和团队搭建 AI 工作流的基础组件。
所以,如果你现在重新写 Ollama 文章,不应该只写安装和运行命令。
更应该写清楚:
- Ollama 为什么从本地工具变成 AI 开发入口
- 它如何连接本地模型和云端模型
- 它如何兼容 OpenAI API
- 它如何支持结构化输出和工具调用
- 它如何进入 IDE 和 Coding Agent 工作流
- 它适合哪些场景,不适合哪些场景
一句话总结:
Ollama 2026 年的意义,不是让你"本地跑一个模型玩玩",而是让你用最短路径搭起一套可调用、可集成、可扩展的 AI 模型运行环境。
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| API调用返回"model not found" | 模型未拉取或名称拼写错误 | ollama list查看已下载模型 | 使用ollama pull重新拉取,确认模型名大小写一致 |
| Structured Outputs返回非JSON | format参数未设置或模型不支持 | 检查format JSON Schema是否正确 | 确认模型支持structured outputs,format参数放在请求体内 |
| Tool Calling不触发工具 | tools参数未正确传递或格式错误 | 检查API请求中tools数组 | 使用标准Function Calling格式,确认tools在messages同级传递 |
| Vision模型无法识别图片 | 图片路径错误或格式不支持 | 检查ollama run命令图片路径 | 确保.png/.jpg格式,路径使用绝对路径 |
| Embedding向量质量差 | 用了chat模型而非专用embedding模型 | 检查是否使用embeddinggemma | 专用embedding模型效果远优于chat模型做embedding |
| 本地模型回答质量差 | 硬件不足导致量化版本太激进 | 观察显存占用和模型量化级别 | 尝试qwen3-coder:480b-cloud云端版本 |
| Claude Code/Cline无法连接Ollama | base_url配置错误或端口被占用 | 检查Ollama服务是否在11434端口运行 | 确认http://localhost:11434可访问,base_url不要漏掉/v1 |
| Web Search返回空结果 | 缺少API Key或网络问题 | 检查Ollama账号和API Key配置 | Web Search需要Ollama云服务账号,纯离线环境不可用 |
作者:武子康的个人博客