一、RAG 专属提示词工程
提示词是 RAG 系统的 "指挥棒",RAG 提示词与通用提示词有本质区别 :它的核心目标不是让模型发挥创造力,而是强制模型严格基于检索到的上下文回答,从根源抑制幻觉。
1.1 RAG 提示词的三大核心目标
- 忠实性(Faithfulness):模型只能使用检索到的上下文信息,绝对不能编造任何没有依据的内容
- 相关性(Relevance):模型只回答与用户问题相关的内容,不要发散无关信息
- 可解释性(Interpretability):模型必须明确标注答案中每个信息的来源,方便用户追溯和验证
1.2 标准 RAG 提示词六要素结构(企业级通用)
经过千万次验证的 RAG 提示词结构,小白直接套用即可解决 90% 的幻觉问题:
【角色设定】
你是一位专业、严谨的知识库助手,擅长基于提供的参考文档回答用户问题。
【核心规则(必须严格遵守)】
1. 只能使用【参考文档】中提供的信息回答问题,绝对不能编造任何没有依据的内容
2. 如果【参考文档】中没有相关信息,或者信息不足以回答问题,请直接说:"抱歉,知识库中没有找到相关信息,无法回答您的问题。"
3. 回答中引用的每个信息都必须标注对应的来源编号,格式为[数字]
4. 不要添加任何个人观点、推测或解释,只陈述参考文档中的事实
5. 回答要简洁、准确、有条理
【参考文档】
{% for doc in documents %}
[{{ doc.id }}] {{ doc.text }}
{% endfor %}
【用户问题】
{{ question }}
【输出要求】
1. 先直接给出答案,再列出引用来源
2. 引用来源格式:"引用来源:[1] 文件名-页码,[2] 文件名-页码"
3. 如果没有找到相关信息,只输出规定的回答,不要添加其他内容结构详解
- 角色设定:明确模型的身份和专业属性,引导模型进入严谨的回答模式
- 核心规则:这是最重要的部分,用最明确、最强硬的语言规定模型的行为边界
- 参考文档:将检索到的上下文块按编号排列,方便模型引用
- 用户问题:用户的原始查询
- 输出要求:规范回答的格式和结构,统一输出风格
1.3 不同场景的 RAG 提示词模板
1.3.1 通用问答模板(最常用)
GENERAL_QA_PROMPT = """
【角色设定】
你是一位专业的知识库助手,能够准确、简洁地回答用户的问题。
【核心规则】
1. 只能使用下面提供的参考文档回答问题,禁止编造信息
2. 如果参考文档中没有相关信息,回答:"抱歉,我没有找到相关信息。"
3. 重要信息用加粗标注
4. 每个事实都要标注来源编号[数字]
【参考文档】
{context}
【用户问题】
{question}
【回答】
"""1.3.2 专业领域问答模板(法律 / 医疗 / 金融)
PROFESSIONAL_QA_PROMPT = """
【角色设定】
你是一位{domain}领域的专业助手,拥有丰富的{domain}知识。
【核心规则】
1. 只能使用参考文档中的信息回答问题,绝对不能编造
2. 回答必须严谨、准确,使用专业术语
3. 所有结论都必须有明确的来源支持
4. 如果信息不足,明确说明"现有信息不足以得出结论"
5. 结尾必须添加免责声明:"以上内容仅供参考,不构成专业建议。"
【参考文档】
{context}
【用户问题】
{question}
【回答】
"""1.3.3 长文档摘要模板
SUMMARY_PROMPT = """
【角色设定】
你是一位专业的文档摘要专家,能够准确提炼文档的核心内容。
【核心规则】
1. 只能基于提供的文档内容生成摘要,不能添加任何外部信息
2. 摘要要全面、准确,涵盖文档的所有核心要点
3. 结构清晰,分点列出
4. 字数控制在{word_count}字左右
【参考文档】
{context}
【摘要】
"""1.4 幻觉抑制的 10 个实战技巧
幻觉是 RAG 系统最大的敌人,以下技巧经过大量实践验证,能将幻觉率降低 80% 以上:
-
明确禁止编造:在提示词最显眼的位置强调 "禁止编造信息"
-
强制引用来源:要求模型每个事实都标注来源编号,增加编造成本
-
设置 "不知道" 选项:明确告诉模型信息不足时应该怎么回答
-
低温度参数 :将
temperature设置为 0-0.3,降低模型的随机性 -
自我验证提示:要求模型先检查答案是否都来自参考文档
请先检查你的答案是否全部来自参考文档,如果有任何内容不在参考文档中,请删除它。
- 分步骤回答:引导模型先提取相关信息,再组织答案
- 限制回答长度:避免模型发散,减少编造机会
- 上下文去重:去除重复的上下文信息,避免模型混淆
- 后处理验证:生成后检查答案中的信息是否都在上下文中
- 多模型交叉验证:用多个模型回答同一个问题,取交集
1.5 实战:提示词效果对比测试
我们来测试不同提示词对幻觉的抑制效果:
python
from dotenv import load_dotenv
import os
from openai import OpenAI
load_dotenv()
# 初始化豆包客户端(兼容OpenAI格式)
client = OpenAI(
api_key=os.getenv("DOUBAO_API_KEY"),
base_url=os.getenv("DOUBAO_BASE_URL")
)
def test_prompt(prompt_template, context, question):
"""测试不同提示词的效果"""
prompt = prompt_template.format(context=context, question=question)
response = client.chat.completions.create(
model="ep-20240506123456-abcde", # 替换为你的豆包模型ID
messages=[{"role": "user", "content": prompt}],
temperature=0.1,
max_tokens=500
)
return response.choices[0].message.content
# 测试上下文(故意不包含"2025年RAG发展趋势"的信息)
context = """
[1] RAG(检索增强生成)是2020年提出的大模型应用技术,主要用于解决大模型的幻觉问题。
[2] 2023年,RAG技术得到了快速发展,出现了混合检索、重排序等优化技术。
[3] 2024年,图RAG、多模态RAG成为研究热点。
"""
question = "2025年RAG的发展趋势是什么?"
# 测试1:通用提示词(容易产生幻觉)
general_prompt = "请回答以下问题:{question}"
print("通用提示词回答:")
print(test_prompt(general_prompt, context, question))
print("-" * 100)
# 测试2:RAG专属提示词(抑制幻觉)
rag_prompt = """
【核心规则】
1. 只能使用下面的参考文档回答问题,禁止编造信息
2. 如果参考文档中没有相关信息,回答:"抱歉,我没有找到相关信息。"
【参考文档】
{context}
【用户问题】
{question}
【回答】
"""
print("RAG专属提示词回答:")
print(test_prompt(rag_prompt, context, question))运行结果对比:
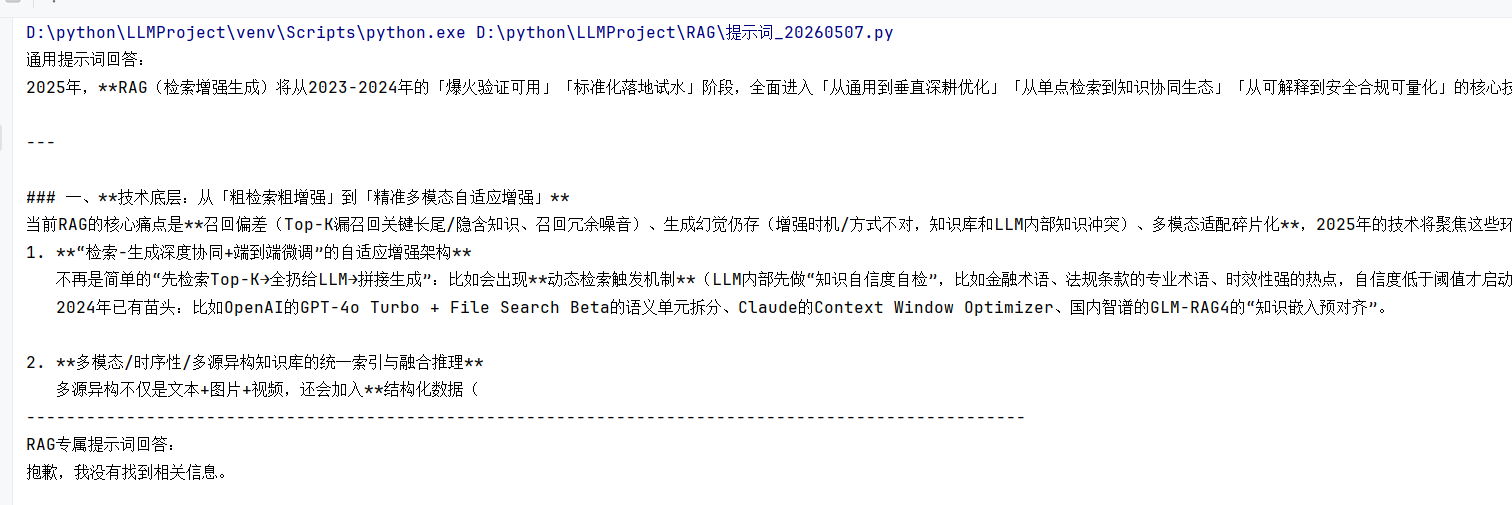
可以看到,RAG 专属提示词完美抑制了幻觉,而通用提示词编造了大量不存在的信息。
二、上下文管理技术
大模型的上下文窗口是有限的,即使是 GPT-4o 也只有 128K Token(约 9 万字)。如果检索到的上下文太长,不仅会增加推理成本和延迟,还会导致模型注意力分散,忽略关键信息。上下文管理就是为了解决这些问题。
2.1 Token 计数:精确控制上下文长度
Token 是大模型处理文本的基本单位,1 个中文汉字约等于 2 个 Token,1 个英文单词约等于 1.3 个 Token。我们必须精确计算上下文的 Token 数,避免超过模型的窗口限制。
2.1.1 使用 tiktoken 计算 Token 数
OpenAI 的tiktoken库是最准确的 Token 计数工具,支持所有主流大模型的编码方式:
python
import tiktoken
def count_tokens(text, model="gpt-3.5-turbo"):
"""
计算文本的Token数
:param text: 输入文本
:param model: 模型名称,不同模型的编码方式不同
:return: Token数
"""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
# 如果模型不支持,使用gpt-3.5-turbo的编码方式
encoding = tiktoken.get_encoding("cl100k_base")
return len(encoding.encode(text))
# 测试Token计数
test_text = "检索增强生成(RAG)是一种大模型应用技术,主要用于解决大模型的幻觉问题。"
print(f"文本:{test_text}")
print(f"Token数:{count_tokens(test_text)}") # 输出约302.1.2 上下文 Token 预算分配
一个完整的 RAG 提示词包含三部分:提示词模板 + 上下文 + 用户问题。我们需要为这三部分分配合理的 Token 预算:
- 提示词模板:约 500 Token
- 用户问题:约 200 Token
- 留给上下文的预算:模型最大窗口 - 500 - 200 - 生成回答的 Token 数
示例:对于 16K 窗口的模型,生成回答预留 2000 Token,那么留给上下文的预算是:16384 - 500 - 200 - 2000 = 13684 Token
2.2 上下文长度控制方法
2.2.1 动态截断
当检索到的上下文总 Token 数超过预算时,按照相关性从高到低截断,只保留最相关的部分:
python
def truncate_context(documents, max_tokens=12000, model="gpt-3.5-turbo"):
"""
动态截断上下文,确保总Token数不超过限制
:param documents: 检索到的文档列表,按相关性从高到低排序
:param max_tokens: 最大Token数
:return: 截断后的文档列表
"""
truncated_docs = []
total_tokens = 0
for doc in documents:
doc_tokens = count_tokens(doc["text"], model)
if total_tokens + doc_tokens > max_tokens:
break
truncated_docs.append(doc)
total_tokens += doc_tokens
return truncated_docs2.2.2 优先级排序
将最相关的文档放在上下文的最前面,因为大模型对开头和结尾的信息注意力更高:
python
def sort_context_by_relevance(documents):
"""
按相关性从高到低排序上下文
:param documents: 检索到的文档列表,每个文档包含score字段
:return: 排序后的文档列表
"""
return sorted(documents, key=lambda x: x["score"], reverse=True)2.2.3 上下文去重
去除重复的文档块,避免浪费 Token 和干扰模型:
python
def deduplicate_context(documents):
"""
去除重复的上下文
:param documents: 检索到的文档列表
:return: 去重后的文档列表
"""
seen_ids = set()
unique_docs = []
for doc in documents:
if doc["id"] not in seen_ids:
seen_ids.add(doc["id"])
unique_docs.append(doc)
return unique_docs2.3 上下文压缩技术(进阶)
上下文压缩的核心思想是:只保留与用户问题相关的信息,去除无关内容,从而在有限的上下文窗口中放入更多有效信息。
2.3.1 提取式压缩
只提取文档块中与问题相关的句子:
python
def extract_relevant_sentences(doc_text, question, threshold=0.5):
"""
提取文档中与问题相关的句子
:param doc_text: 文档文本
:param question: 用户问题
:param threshold: 相似度阈值
:return: 相关句子组成的文本
"""
# 简单实现:按句号分割句子,计算每个句子与问题的相似度
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
question_embedding = model.encode(question, convert_to_tensor=True)
sentences = doc_text.split("。")
relevant_sentences = []
for sentence in sentences:
if not sentence.strip():
continue
sentence_embedding = model.encode(sentence.strip(), convert_to_tensor=True)
similarity = util.cos_sim(question_embedding, sentence_embedding).item()
if similarity > threshold:
relevant_sentences.append(sentence.strip() + "。")
return "".join(relevant_sentences)2.3.2 LLM 压缩
用大模型对每个文档块生成问题相关的摘要:
python
def compress_with_llm(doc_text, question, client):
"""
用大模型压缩文档,只保留与问题相关的信息
:param doc_text: 文档文本
:param question: 用户问题
:param client: 大模型客户端
:return: 压缩后的文本
"""
prompt = f"""
请根据以下问题,压缩下面的文档内容,只保留与问题相关的信息。
问题:{question}
文档:{doc_text}
压缩后的内容:
"""
response = client.chat.completions.create(
model="ep-20240506123456-abcde",
messages=[{"role": "user", "content": prompt}],
temperature=0.1,
max_tokens=200
)
return response.choices[0].message.content2.4 完整上下文管理流水线
将以上方法整合起来,形成完整的上下文管理流水线:
python
def process_context(documents, question, max_tokens=12000, model="gpt-3.5-turbo", compress=False):
"""
完整的上下文处理流水线
:param documents: 检索到的文档列表
:param question: 用户问题
:param max_tokens: 最大Token数
:param compress: 是否启用上下文压缩
:return: 处理后的上下文文本
"""
# 1. 去重
documents = deduplicate_context(documents)
# 2. 按相关性排序
documents = sort_context_by_relevance(documents)
# 3. 上下文压缩(可选)
if compress:
for doc in documents:
doc["text"] = extract_relevant_sentences(doc["text"], question)
# 4. 动态截断
documents = truncate_context(documents, max_tokens, model)
# 5. 格式化为提示词需要的格式
context_text = ""
for i, doc in enumerate(documents, 1):
context_text += f"[{i}] {doc['text']}\n\n"
# 保存原始ID与编号的映射,用于引用溯源
doc["temp_id"] = i
return context_text, documents三、引用溯源实现(RAG 可解释性的核心)
引用溯源是 RAG 系统区别于普通大模型的关键特征,它能让用户知道答案中的每个信息来自哪里,从而提升回答的可信度,也方便排查幻觉问题。
3.1 引用溯源的三种实现方式
3.1.1 编号引用法(最常用)
这是最简单也是最常用的方式,在回答中用[1]、[2]标记信息来源,然后在回答末尾列出完整的来源信息。
示例:
python
RAG(检索增强生成)是2020年提出的大模型应用技术[1],主要用于解决大模型的幻觉问题[1]。2023年,混合检索、重排序等优化技术得到了快速发展[2]。
引用来源:
[1] RAG技术入门.pdf-第3页
[2] 2023年大模型技术发展报告.pdf-第15页3.1.2 详情引用法
直接在引用标记中包含来源信息,适合短文档场景。
示例:
python
RAG(检索增强生成)是2020年提出的大模型应用技术(RAG技术入门.pdf-第3页),主要用于解决大模型的幻觉问题(RAG技术入门.pdf-第3页)。3.1.3 链接引用法
生成可点击的原始文档链接,适合有文档管理系统的场景。
示例:
python
RAG(检索增强生成)是2020年提出的大模型应用技术[1]。
引用来源:
[1] [RAG技术入门.pdf-第3页](/docs/rag_intro.pdf#page=3)3.2 编号引用法的工程化实现
这是我们推荐的实现方式,分为三个步骤:
步骤 1:检索阶段为文档块分配临时编号
在上下文处理阶段,为每个文档块分配一个临时编号(1、2、3...),并保存原始 ID 与临时编号的映射关系。
步骤 2:提示词中要求模型引用临时编号
在 RAG 提示词中明确要求模型使用临时编号标注来源。
步骤 3:生成后处理,将临时编号映射为完整来源信息
模型生成回答后,将回答中的临时编号替换为完整的来源信息。
3.3 完整代码实现
python
def format_citations(answer, documents):
"""
将回答中的临时编号替换为完整的来源信息
:param answer: 模型生成的回答
:param documents: 处理后的文档列表,包含temp_id和metadata
:return: 带引用溯源的回答
"""
import re
# 提取回答中的所有引用编号
citation_pattern = re.compile(r'\[(\d+)\]')
citations = citation_pattern.findall(answer)
if not citations:
return answer + "\n\n引用来源:无"
# 构建编号到来源信息的映射
citation_map = {}
for doc in documents:
temp_id = str(doc["temp_id"])
file_name = doc["metadata"]["file_name"]
page = doc["metadata"].get("page", "未知页码")
citation_map[temp_id] = f"{file_name}-第{page}页"
# 生成引用来源列表
citation_list = []
seen_citations = set()
for cite in citations:
if cite in citation_map and cite not in seen_citations:
seen_citations.add(cite)
citation_list.append(f"[{cite}] {citation_map[cite]}")
# 拼接回答和引用来源
final_answer = answer + "\n\n引用来源:\n" + "\n".join(citation_list)
return final_answer
# 测试引用溯源
if __name__ == "__main__":
# 模拟检索到的文档
documents = [
{
"id": "doc1",
"text": "RAG(检索增强生成)是2020年提出的大模型应用技术。",
"metadata": {"file_name": "RAG技术入门.pdf", "page": 3},
"score": 0.95,
"temp_id": 1
},
{
"id": "doc2",
"text": "RAG主要用于解决大模型的幻觉问题、知识截止问题和私有数据隔离问题。",
"metadata": {"file_name": "RAG技术入门.pdf", "page": 5},
"score": 0.92,
"temp_id": 2
}
]
# 模拟模型生成的回答
model_answer = "RAG(检索增强生成)是2020年提出的大模型应用技术[1],主要用于解决大模型的幻觉问题[2]。"
# 格式化引用
final_answer = format_citations(model_answer, documents)
print(final_answer)运行结果:
python
RAG(检索增强生成)是2020年提出的大模型应用技术[1],主要用于解决大模型的幻觉问题[2]。
引用来源:
[1] RAG技术入门.pdf-第3页
[2] RAG技术入门.pdf-第5页3.4 引用溯源的常见问题与解决方法
- 模型编造引用编号 :模型可能会引用不存在的编号(如
[3]),解决方法是在生成后处理中过滤掉不存在的编号。 - 模型不引用来源:在提示词中加强要求,例如 "如果不标注来源,我将无法相信你的回答"。
- 引用错误:模型可能会将信息与错误的来源关联,解决方法是使用更严格的提示词,或者在生成后验证每个引用的信息是否在对应的文档中。
四、大模型集成(API + 本地私有化部署)
RAG 系统需要灵活支持多种大模型,既能使用云端 API 快速验证,也能本地部署开源模型满足私有化需求。我们将实现一个统一的大模型调用客户端,支持一键切换模型。
4.1 主流大模型 API 对比与选型
2026 年国内主流大模型 API 对比:
| 模型 | 上下文长度 | 中文效果 | 输入价格(元 / 千 Token) | 输出价格(元 / 千 Token) | 推荐场景 |
|---|---|---|---|---|---|
| 豆包 4.0 | 128K | 中文 SOTA | 0.03 | 0.06 | 通用场景、复杂推理 |
| 通义千问 3.5 | 128K | 优秀 | 0.008 | 0.02 | 高并发、低成本场景 |
| 文心一言 4.0 | 128K | 优秀 | 0.03 | 0.06 | 百度生态 |
| GPT-4o | 128K | 全球 SOTA | 0.05 | 0.15 | 英文场景、复杂推理 |
选型建议 :中文 RAG 场景优先选择豆包 4.0 或通义千问 3.5,效果好且价格合理。
4.2 统一大模型调用客户端实现
我们将封装一个统一的客户端,支持豆包、通义千问、OpenAI 等主流 API,以及本地 Ollama 模型:
python
from dotenv import load_dotenv
import os
from openai import OpenAI
import requests
load_dotenv()
class LLMClient:
def __init__(self, model_type="doubao", model_name=None):
"""
初始化大模型客户端
:param model_type: 模型类型,支持"doubao"、"qwen"、"openai"、"ollama"
:param model_name: 具体模型名称,如"ep-20240506123456-abcde"
"""
self.model_type = model_type.lower()
if self.model_type == "doubao":
self.client = OpenAI(
api_key=os.getenv("DOUBAO_API_KEY"),
base_url=os.getenv("DOUBAO_BASE_URL")
)
self.model_name = model_name or "ep-20240506123456-abcde" # 替换为你的默认模型ID
elif self.model_type == "qwen":
self.client = OpenAI(
api_key=os.getenv("QWEN_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
self.model_name = model_name or "qwen3.5-128k-chat"
elif self.model_type == "openai":
self.client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
self.model_name = model_name or "gpt-3.5-turbo"
elif self.model_type == "ollama":
self.client = OpenAI(
api_key="ollama",
base_url="http://localhost:11434/v1"
)
self.model_name = model_name or "qwen:7b"
else:
raise ValueError(f"不支持的模型类型:{model_type}")
def chat(self, prompt, temperature=0.1, max_tokens=1000, stream=False):
"""
大模型对话
:param prompt: 提示词
:param temperature: 温度参数
:param max_tokens: 最大生成Token数
:param stream: 是否流式输出
:return: 模型回答(非流式)或生成器(流式)
"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
max_tokens=max_tokens,
stream=stream
)
if stream:
return self._stream_response(response)
else:
return response.choices[0].message.content
def _stream_response(self, response):
"""处理流式响应"""
for chunk in response:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
# 测试统一客户端
if __name__ == "__main__":
# 测试豆包API
print("测试豆包API:")
doubao_client = LLMClient(model_type="doubao")
print(doubao_client.chat("你好,请介绍一下RAG技术。"))
print("-" * 100)
# 测试本地Ollama模型(需要先启动Ollama并拉取模型)
# print("测试本地Ollama模型:")
# ollama_client = LLMClient(model_type="ollama", model_name="qwen:7b")
# print(ollama_client.chat("你好,请介绍一下RAG技术。"))4.3 开源大模型本地部署(Ollama 一键部署)
Ollama 是目前最简单的开源大模型部署工具,一行命令即可完成部署。
4.3.1 安装 Ollama
- Windows/Mac:下载安装包:https://ollama.com/download
- Linux:
curl -fsSL https://ollama.com/install.sh | sh
4.3.2 拉取并运行模型
bash
# 拉取通义千问7B模型(中文效果好,16G显存可流畅运行)
ollama pull qwen:7b
# 拉取LLaMA 3 7B模型
ollama pull llama3:7b
# 运行模型(交互式)
ollama run qwen:7b4.3.3 本地模型硬件要求
表格
| 模型大小 | 4bit 量化显存 | 8bit 量化显存 | 推荐配置 |
|---|---|---|---|
| 7B | 4-6G | 8-10G | 16G 内存 + 6G 显存 |
| 13B | 8-10G | 16-20G | 32G 内存 + 12G 显存 |
| 34B | 16-20G | 32-40G | 64G 内存 + 24G 显存 |
4.4 大模型调用最佳实践
- 温度参数设置 :RAG 场景推荐
temperature=0-0.3,降低随机性,减少幻觉 - 超时与重试机制:处理网络波动和模型超时
- 速率限制 :避免触发 API 限流,使用
backoff库实现退避重试 - 成本控制:监控 Token 消耗,优化上下文长度,使用缓存减少重复请求
python
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def chat_with_retry(self, prompt, **kwargs):
return self.chat(prompt, **kwargs)核心知识点回顾
- RAG 专属提示词:六要素结构,核心目标是忠实性、相关性、可解释性,能有效抑制幻觉
- 上下文管理:Token 计数、动态截断、优先级排序、去重、压缩,解决上下文窗口限制
- 引用溯源:编号引用法的工程化实现,提升 RAG 系统的可解释性和可信度
- 统一大模型客户端:支持云端 API 和本地部署,一键切换模型,满足不同场景需求