第 1 章 智能体基础
LLM 智能体的本质是一个具备通用推理能力的大语言模型,配合工具调用和执行循环,使其能够自主规划并执行复杂任务。这不是给传统软件套一个聊天界面,而是从根本上改变了软件的构建方式------从人工编写每一步逻辑,转向引导一个通用"大脑"自主思考、行动和学习。
本章回答的核心问题:
- 智能体究竟是什么,它与传统软件有什么本质区别
- 智能体技术是如何一步步从规则系统演进到今天 LLM 驱动的
- 一个完整的智能体由哪些核心组件构成,以及两种主流构建路线的差异
这一章的内容偏概念和全景认知,重点是建立对智能体技术的整体认知框架,不需要纠结细节,后面每一章都会深入到具体场景里反复用到今天的内容。
目录
- [1.1 什么是智能体](#1.1 什么是智能体 "#11-%E4%BB%80%E4%B9%88%E6%98%AF%E6%99%BA%E8%83%BD%E4%BD%93")
- [1.2 智能体发展史](#1.2 智能体发展史 "#12-%E6%99%BA%E8%83%BD%E4%BD%93%E5%8F%91%E5%B1%95%E5%8F%B2")
- [1.3 智能体架构全景](#1.3 智能体架构全景 "#13-%E6%99%BA%E8%83%BD%E4%BD%93%E6%9E%B6%E6%9E%84%E5%85%A8%E6%99%AF")
- 本章小结
1.1 什么是智能体
智能体是能够感知环境、自主决策、并通过行动达成特定目标的实体。
这个定义包含三个核心要素:
- 感知------通过传感器获取环境信息。摄像头、麦克风、API 返回的数据,都属于传感器的形式。
- 自主决策------不依赖人工实时干预,基于感知信息自己做判断。
- 目标导向------行动的目的是达成某个特定目标,而非盲目反应。
恒温器是最简单的智能体:感知温度、决定是否制冷、目标是维持设定温度。自动驾驶汽车和智能旅行助手也是智能体,只是复杂度不同。智能体不是单一概念,而是一个涵盖从简单到复杂的谱系。
1.1.1 智能体的核心特征
一个真正的智能体必须具备以下特征:
自主性(Autonomy):智能体不是被动响应外部指令的脚本,它能够基于感知和内部状态独立做决策。这是智能体与普通程序的分水岭。
反应性(Reactivity):智能体能够感知环境变化并及时做出响应。在动态环境中,上一次查询的结果可能下一秒就失效,智能体需要持续监控环境。
主动性(Proactiveness):智能体不只是对刺激做出反应,还会主动采取行动以达成目标。它会规划路径、探索未知、尝试不同的策略。
社交性(Social Ability):在复杂场景中,智能体需要与其他智能体或人类进行交互和协作。多智能体系统正是基于这一特征构建。
1.1.2 智能体与传统软件的区别
在 LLM 出现之前,软件系统的行为完全由工程师的显式编程决定。LLM 改变了这一模式:
| 维度 | 传统软件 | LLM 智能体 |
|---|---|---|
| 行为驱动 | 人工编写的确定性逻辑 | 大语言模型的推理能力 |
| 知识来源 | 工程师手动编码到代码中 | 海量数据预训练获得的隐式知识 |
| 交互方式 | 结构化输入(表单、按钮、API) | 自然语言 |
| 处理模糊需求 | 无法处理,必须明确定义 | 可以理解意图并自主拆解 |
| 能力边界 | 固定且明确,超出范围即失效 | 灵活可泛化,但存在不确定性 |
| 错误模式 | 逻辑错误或崩溃 | 幻觉、推理链断裂 |
输入"帮我规划一次厦门之旅"------传统软件无法处理这种非结构化指令,除非工程师预先编写完整的旅行规划模块。而 LLM 智能体能够理解意图,并自主拆解为查天气、找景点、订酒店、排行程等子任务。
核心变化:从编写代码解决问题,转向引导一个具有通用推理能力的模型去自主规划、行动和学习。
不过,获得灵活性的同时,也必须面对新的问题。传统软件的输出是确定性的,同样的输入必然得到同样的结果。LLM 智能体的输出带有概率性,可能产生看似合理但实际错误的信息(幻觉),也可能在推理链的某个环节断裂。这就要求我们引入新的机制来保证可靠性。
1.1.3 智能体的类型与典型应用场景
按照决策机制的复杂度,智能体可以划分为五种类型,从简单到复杂依次递进:
简单反射智能体(Simple Reflex Agent)
基于"条件-动作"规则运行。恒温器的规则是"温度超过 26 度则制冷"。它只依赖当前感知,没有记忆,不具备规划能力。适用于规则明确、场景固定的自动化任务,如工业控制、简单的消息过滤。它的代价是完全无法处理规则外的任何情况。当环境存在不可预测的变化,或者需要根据历史经验做判断时,就不该选它。
基于模型的反射智能体(Model-Based Reflex Agent)
引入了内部世界模型,能够跟踪传感器无法直接观测到的环境状态。自动驾驶汽车进入隧道时,即使摄像头暂时看不到前方车辆,内部模型仍然维持对该车辆位置和速度的判断。适用于环境信息不完整但需要持续决策的场景。它的代价是维护内部世界模型需要额外的计算开销,且模型本身可能与真实环境存在偏差。当环境动态变化极快、内部模型难以准确更新时,基于模型的反射可能不如简单反射来得可靠。
基于目标的智能体(Goal-Based Agent)
不仅对当前环境做出反应,还会主动规划如何达成特定目标。GPS 导航系统是典型代表:给定目的地后,它会搜索最优路径。适用于需要多步骤规划才能完成的任务,如物流调度、项目排期。它的代价是搜索最优路径可能计算量巨大,且如果目标定义不当可能产生意想不到的副作用。当任务只需即时反应、不需要规划,或者目标本身难以精确定义时,使用基于目标的智能体是杀鸡用牛刀。
基于效用的智能体(Utility-Based Agent)
当存在多个需要权衡的目标时,效用函数为每个可能的状态赋予一个满意度评分,智能体的目标是最大化期望效用。它能在相互冲突的目标之间做出最优折中。适用于需要多目标优化的复杂决策场景,如投资组合管理、资源分配。它的代价是设计合理的效用函数极其困难------权重的微小变化可能导致截然不同的决策结果,且多目标优化可能导致计算复杂度过高。当只需要优化单一明确指标,或各目标之间不存在冲突时,不需要引入效用函数。
学习型智能体(Learning Agent)
不依赖预设规则,而是通过与环境的交互自主学习。强化学习是实现这一类型的典型方法。通过与大量自我对弈,学习型智能体能够发现超越人类既有知识的策略。适用于规则明确但策略空间巨大的博弈场景,以及需要持续优化的推荐系统。它的代价是需要大量交互数据和时间来学习,且在训练期间可能做出危险决策。安全关键场景(如医疗设备控制、航空管制)不该用它,因为训练过程中的试错行为可能造成不可挽回的后果。
这五类智能体体现了一条清晰的演进路径:从执行固定规则,到拥有记忆和规划能力,再到自主学习。核心问题始终是同一个------如何在复杂环境中做出更好的决策。
这五类的复杂度是递进的,但实际应用中并不存在"谁比谁好"------简单场景用简单反射智能体反而更高效,关键在于选对适合当前问题的类型。
在实际应用中,智能体还可以从另外两个维度分类:
从时间与反应性来看:反应式智能体追求低延迟即时响应(如安全气囊系统、高频交易),规划式智能体在行动前进行复杂思考和规划(如商业计划制定),混合式智能体结合两者优势,在需要即时反应的场景快速响应,在需要长远规划的场景深度思考。现代 LLM 智能体通常采用混合模式,在"思考-行动-观察"循环中将规划和反应融为一体。
从知识表示来看:符号主义 AI 使用人类可读的符号和逻辑规则,透明可解释但脆弱;亚符号主义 AI(如神经网络)从数据中隐式学习模式,识别能力强但内部运作像一个黑盒------你能看到输入和输出,却说不清中间发生了什么;神经符号主义 AI 融合两者,LLM 智能体正是这一路线的实践------内核是神经网络(亚符号),但工作时生成结构化的中间步骤(思想、计划、API 调用),相当于在黑盒外面装了一扇玻璃窗,让推理过程变得部分可见可追踪,实现感知与认知的初步融合。但神经符号主义也有代价:让黑盒产生结构化中间步骤会增加计算开销和系统设计复杂度,且"部分可见"仍不等于"完全可解释"。当追求极致推理速度,或当问题本身只需要纯感知能力时,引入符号推理层是多余的。
1.2 智能体发展史
现代 LLM 智能体不是凭空出现的,它是多种技术思想长期积累、竞争与融合的结果。理解这段历史,能帮助我们把握当前技术选型背后的深层原因。
1.2.1 从符号主义到 LLM 驱动的演进历程
符号主义:将知识编码为规则
早期 AI 研究者认为,智能的核心是对符号的逻辑操作。于是产生了专家系统------将领域专家的经验编写成"IF-THEN"规则,由推理机执行。这类系统在医疗诊断、设备故障排查等垂直领域取得了不错的效果。
符号主义要解决的根本问题是:如何让机器拥有知识? 它的回答是把人类头脑中的判断依据,用"如果...那么..."的规则一条条写下来。这相当于把专家的经验变成一本操作手册------遇到情况 A 翻到第几页,遇到情况 B 翻到第几页。旧方案的缺陷显而易见:专家的很多判断是内隐的、直觉性的,根本无法拆解成显式规则。医生看病时的"感觉不对劲"、老师批改作文时的"语感",这些东西很难写成"IF-THEN"。这就是知识获取瓶颈------我们能观察专家的行为,却无法完整提取他们头脑中的知识。
这个瓶颈带来两个后果:
- 规则永远写不完------真实世界的情况千变万化,为每一个可能的场景编写规则几乎不可能。
- 系统极度脆弱------严格依赖预设规则,遇到规则外的情况就直接失效。在封闭环境中表现良好,但能力无法迁移到真实世界。
联结主义:从数据中学习
既然知识难以手工编码,研究者转向让机器从数据中自动学习。联结主义要解决的根本问题是:知识能不能不靠人工编写,而是让机器自己获得? 它的回答是:把知识分散存储在神经网络的连接权重中,通过大量样本来自动调整这些权重。这就像教小孩认猫------不是列一条"有胡须、有四条腿、会喵喵叫"的规则清单,而是给他看足够多的猫的照片,他自己就能总结出猫的特征。旧方案(符号主义)的缺陷是知识获取瓶颈,联结主义绕过了这个问题:不再试图把知识翻译成人能写的规则,而是让机器直接从数据中"浸泡"出知识。深度学习是这一路径的成果,使机器获得了强大的感知和模式识别能力------图像识别、语音理解、文本生成。但感知能力解决的是"这是什么"的问题,智能体还需要解决"接下来该做什么"的决策问题。
强化学习:在交互中学习决策
联结主义让机器学会了"看"和"听",但还没学会"做决定"。强化学习要解决的根本问题是:在没有标准答案的情况下,机器怎么学会做出一系列正确的选择? 类比:教狗做动作------不是告诉它每一步该抬哪只脚,而是它做对了就给零食,做错了就没有。狗不知道哪一次动作会得到奖励,但它会逐渐发现某种行为模式能最大化零食的获得量。强化学习正是这个思路:智能体通过与环境交互试错来学习,做对了获得奖励,做错了没有奖励。关键点是智能体的目标是最大化累积奖励而非即时奖励,这要求它具备"远见"------有时需要牺牲眼前利益以换取更大的长期收益。
强化学习专注于序贯决策问题。智能体通过与环境的交互试错学习:
- 观察环境当前状态
- 根据策略选择一个行动
- 环境转移到新状态,并返回一个奖励信号
- 智能体利用反馈优化策略
但强化学习需要从零开始学习,效率受限,且缺乏对世界的先验知识。一个从零开始学下棋的强化学习智能体,需要数百万局对弈才能达到高水平------它没有人类几千年积累下来的棋谱知识。
预训练:先获取世界知识,再适应具体任务
预训练提供了一条更高效的路径:先在海量通用语料上训练,使模型获得对世界知识的广泛理解,再针对具体任务微调。
GPT 等大语言模型采用这一路径。在万亿级别的文本上预训练后,模型不仅学会了语言规律,还隐式地存储了大量世界知识,展现出上下文学习和思维链推理等涌现能力。它以一种全新的方式,解决了符号主义时代最棘手的知识获取瓶颈问题。
技术融合:LLM 智能体的诞生
所有关键要素到齐:
- 符号主义提供了逻辑推理框架
- 联结主义提供了感知和模式识别能力
- 强化学习提供了交互决策机制
- 预训练 LLM 提供了世界知识和通用推理能力
LLM 智能体是这些思想的融合体。它的内核是联结主义的神经网络,但工作时生成结构化的中间步骤(思想、计划、工具调用),这本质上是符号推理。它通过与环境的交互来推进任务,这是强化学习的思路。多种技术思想在这一架构中实现了统一。
到这里,我们已经理清了各条技术路径各自的贡献,下面用一张时间线把它们串起来,直观地看每一代技术是如何解决上一代的核心缺陷的。
1.2.2 智能体发展的关键里程碑
arduino
1950s-1970s 符号主义时代
├── 物理符号系统假说提出:智能的本质是符号的计算与处理
├── 专家系统诞生:知识库 + 推理机,在垂直领域展现"智能"
└── 自然语言理解尝试:在封闭环境中实现语言指令理解
1980s-1990s 联结主义复兴
├── 反向传播算法推动神经网络复苏
├── 分布式智能思想萌芽:复杂智能从简单单元的交互中涌现
└── 强化学习框架确立:智能体通过试错学习序贯决策
2000s-2010s 深度学习爆发
├── 卷积神经网络在图像识别上超越人类
├── 强化学习与深度学习结合,在博弈游戏中击败人类顶尖选手
└── 预训练-微调范式在NLP领域确立
2020s LLM 智能体时代
├── 大规模预训练模型涌现出上下文学习和思维链推理能力
├── LLM 开始与工具调用结合,形成自主行动能力
└── 多智能体协作框架百花齐放,智能体从概念走向大规模应用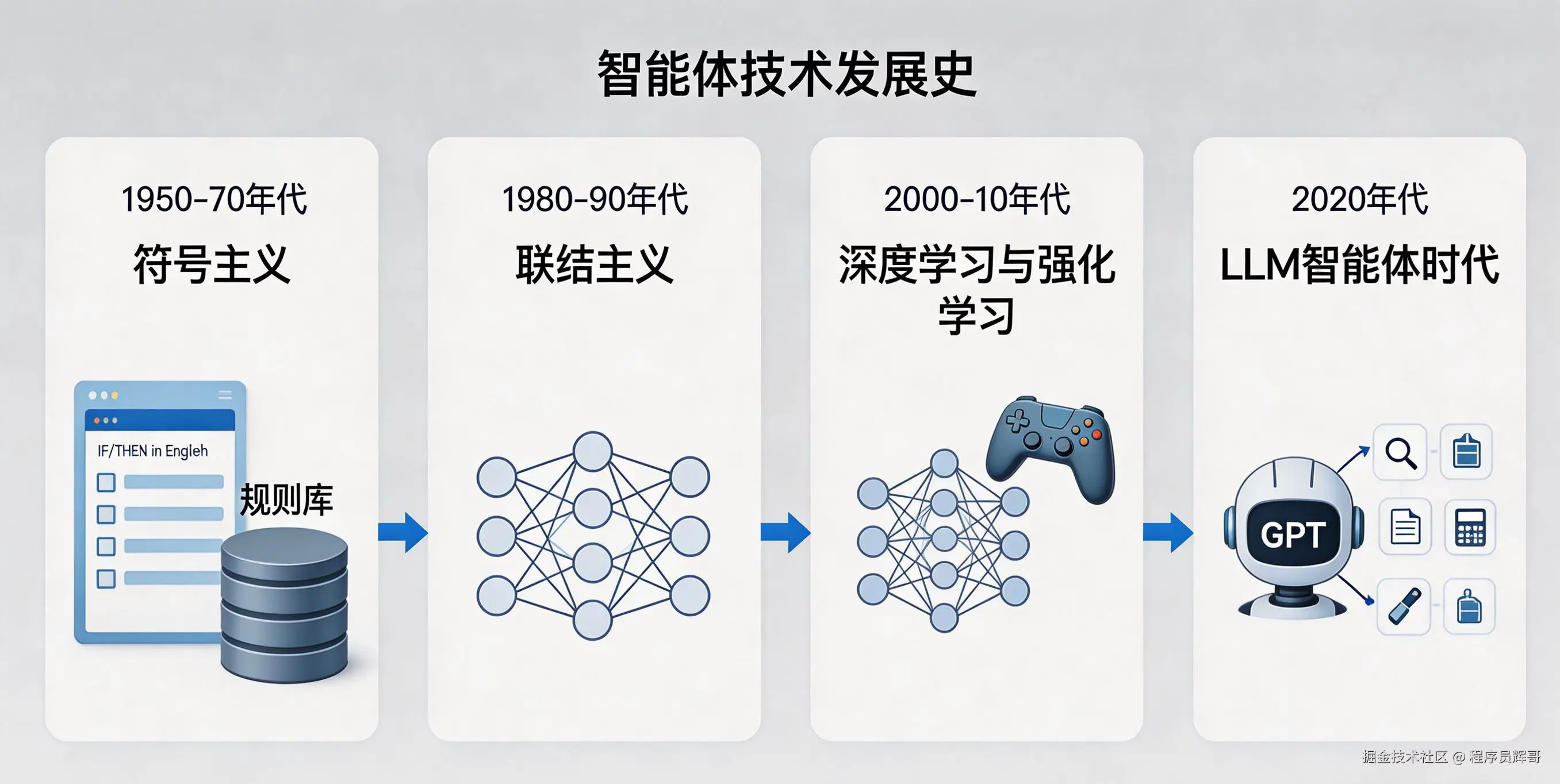
这条演进线的内在逻辑是一致的:每一代技术都在尝试解决上一代的核心缺陷。 符号主义无法获取足够的知识,联结主义让机器从数据中学习;联结主义只能感知不会决策,强化学习赋予决策能力;强化学习缺乏先验知识,预训练提供世界知识;单一模型无法完成复杂任务,智能体架构将模型与工具、记忆、规划结合起来。
1.3 智能体架构全景
了解了智能体的概念来源和演进逻辑,接下来我们看"怎么把它搭出来"。
1.3.1 核心组件:规划、记忆、工具、行动
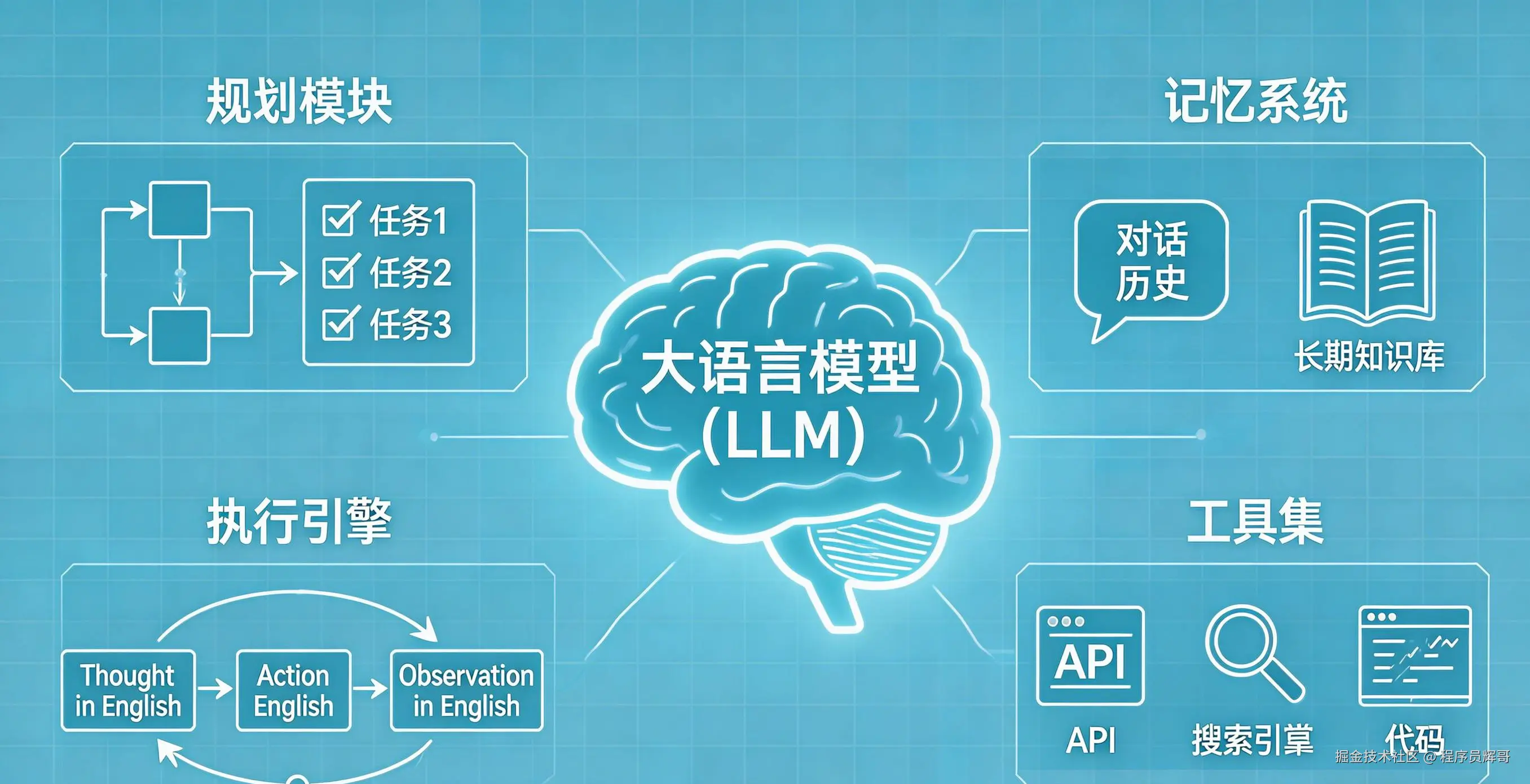
不管用什么框架,一个完整的 LLM 智能体都离不开以下核心组件:
大语言模型(LLM)------推理引擎
LLM 是智能体的"大脑",负责语言理解、逻辑推理和决策生成。它接收经过处理的上下文信息,输出结构化的思考与行动指令。
规划模块(Planning)------任务编排
规划模块负责将高层目标分解为可执行的子任务。它包含两个关键能力:
- 任务分解:将复杂目标拆解为有序的子步骤
- 反思修正:根据执行结果评估当前计划是否有效,必要时调整策略
规划的本质是在行动之前先想清楚"应该做什么"和"按什么顺序做"。
记忆系统(Memory)------状态保持
智能体需要记住关键信息才能有效工作。记忆分为两层:
- 短期记忆:当前任务的对话历史和执行记录,通常通过上下文窗口维护
- 长期记忆:跨任务持久化的知识,如用户偏好、历史经验、外部知识库
记忆系统解决的问题是:当上下文窗口有限、任务跨度很长时,如何让智能体"记住"重要的事情。
工具集(Tools)------能力扩展
LLM 本身只能生成文本,无法直接操作外部世界。工具是 LLM 感知和影响环境的接口:
- 搜索引擎、API 接口:获取外部信息
- 代码执行器:执行计算和操作
- 文件读写、数据库:持久化数据
工具的本质是将 LLM 的推理能力与外部世界的实际操作能力连接起来。
执行引擎(Execution)------运行循环
执行引擎将上述组件串联起来,驱动智能体持续运转。核心循环如下:
css
用户输入
│
▼
[感知] 接收并处理环境信息
│
▼
[思考] LLM 分析信息,规划下一步
│
▼
[行动] 执行工具调用或输出结果
│
▼
[观察] 获取行动结果,反馈给下一轮
│
▼
是否达成目标?──是──→ 输出最终结果
│
否
│
▼
回到 [思考],继续下一轮循环这个循环通常被称为 Thought-Action-Observation 循环,是所有主流智能体框架的底层逻辑。
以"规划厦门之旅"为例,完整的循环过程如下:
vbnet
用户: 帮我规划厦门之旅
Thought: 我需要先了解出行天数和预算
Action: ask_preference(days, budget)
Observation: 3天,预算2000元
Thought: 先查询厦门天气
Action: get_weather("厦门")
Observation: 厦门天气晴,气温28度
Thought: 晴天适合户外景点,查询推荐
Action: get_attraction("厦门", "晴")
Observation: 推荐鼓浪屿、环岛路、南普陀...
Thought: 信息充足,整合为完整行程
Action: Finish[3天厦门行程:Day1 鼓浪屿...Day2 环岛路...Day3 南普陀...]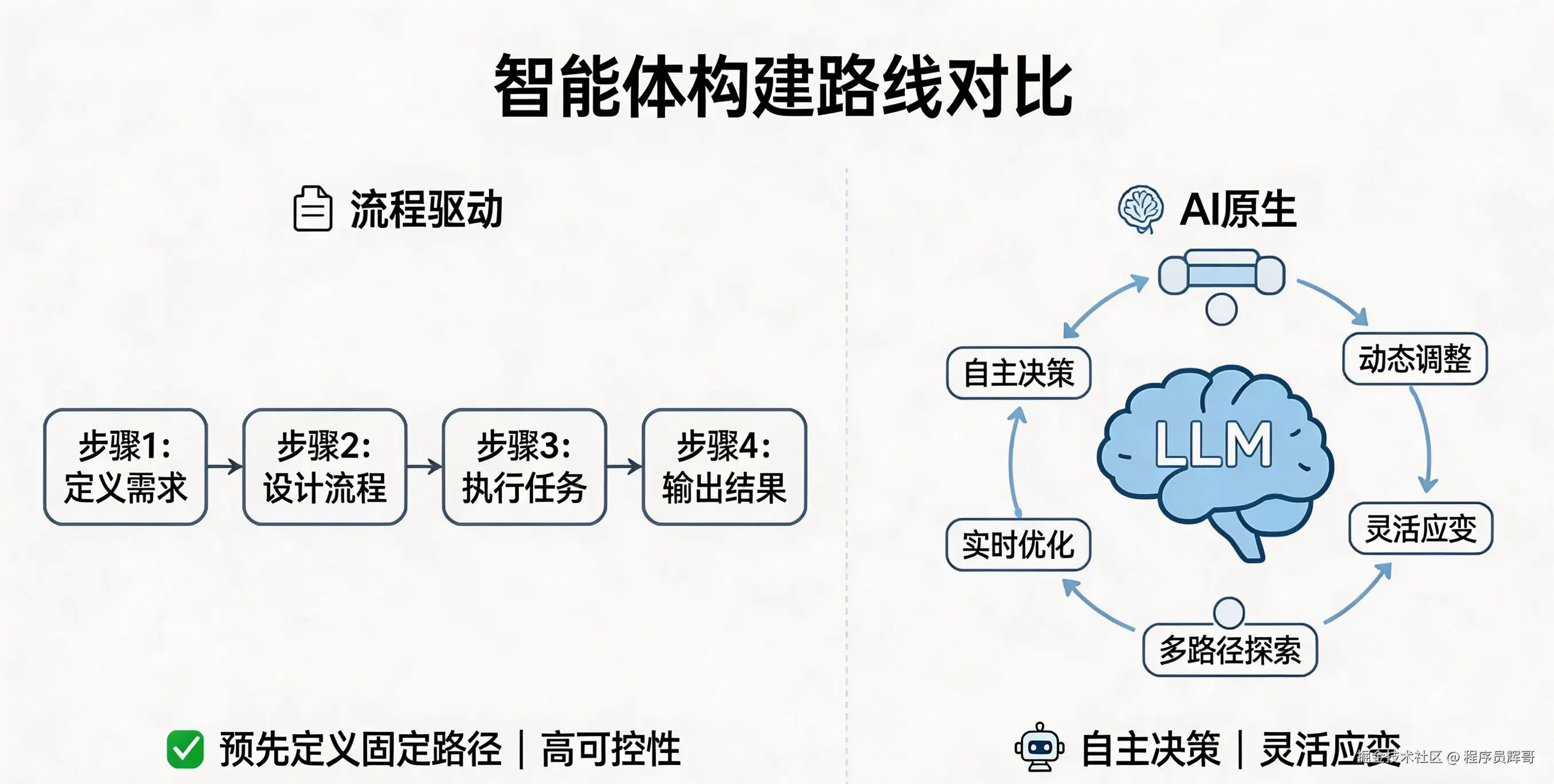
1.3.2 动手:实现一个最小智能体
光看组件可能还有些抽象,我们直接写代码,把一个最简智能体跑起来。这个示例能把上面讲到的规划、记忆、工具、执行引擎全部串通,完整走完 Thought-Action-Observation 循环。
首先定义两个工具函数。天气查询使用免费的 wttr.in 服务:
python
import requests
def get_weather(city: str) -> str:
"""查询城市当前天气"""
url = f"https://wttr.in/{city}?format=j1"
data = requests.get(url).json()
current = data['current_condition'][0]
desc = current['weatherDesc'][0]['value']
temp = current['temp_C']
return f"{city}当前天气: {desc},气温 {temp} 摄氏度"第二个工具根据天气推荐景点:
python
def get_attraction(city: str, weather: str) -> str:
"""根据城市和天气推荐景点"""
if "晴" in weather:
return f"天气晴好,推荐{city}户外景点:故宫、颐和园。"
elif "雨" in weather:
return f"雨天适合室内活动,推荐{city}博物馆、美术馆。"
else:
return f"建议在{city}选择半户外行程,如历史文化街区。"
tools = {
"get_weather": get_weather,
"get_attraction": get_attraction,
}接下来定义 Prompt,它规定了智能体的行为准则、可用工具和输出格式:
python
SYSTEM_PROMPT = """
你是一个旅行助手。你有两个可用工具:
- get_weather(city): 查询城市天气
- get_attraction(city, weather): 根据天气推荐景点
每次回复必须严格使用以下格式:
Thought: [你的思考]
Action: [调用工具或结束]
工具调用格式: tool_name(key="value")
结束格式: Finish[最终答案]
注意:每次只执行一个工具,收集到足够信息后用 Finish 结束。
"""接入 LLM(使用 Anthropic SDK):
python
import os
from anthropic import Anthropic
api_key = os.environ.get("ANTHROPIC_API_KEY") or os.environ.get("ANTHROPIC_AUTH_TOKEN")
if not api_key:
raise ValueError("未设置 ANTHROPIC_API_KEY 环境变量。")
base_url = os.environ.get("ANTHROPIC_BASE_URL")
client_kwargs = {"api_key": api_key}
if base_url:
client_kwargs["base_url"] = base_url
client = Anthropic(**client_kwargs)
model_name = os.environ.get("ANTHROPIC_MODEL") or "claude-sonnet-4-20250514"
def ask_llm(prompt: str) -> str:
response = client.messages.create(
model=model_name,
system=SYSTEM_PROMPT,
messages=[
{"role": "user", "content": prompt},
],
)
# 提取文本内容(处理 ThinkingBlock)
text_parts = [b.text for b in response.content if hasattr(b, "text")]
return "\n".join(text_parts)最后将各组件串联成主循环:
python
import re
def run_agent(user_input: str):
history = [f"用户请求: {user_input}"]
for _ in range(5): # 最多循环 5 轮,防止无限循环
reply = ask_llm("\n".join(history))
print(reply)
action = re.search(r"Action:\s*(.*)", reply, re.DOTALL)
if not action:
history.append("Observation: 请按照格式输出 Thought 和 Action")
continue
action_text = action.group(1).strip()
if action_text.startswith("Finish"):
answer = re.match(r"Finish\[(.*)\]", action_text)
if answer:
print(f"\n最终结果: {answer.group(1)}")
break
tool_match = re.search(r"(\w+)\((.*)\)", action_text)
if tool_match:
tool_name = tool_match.group(1)
args_str = tool_match.group(2)
kwargs = dict(re.findall(r'(\w+)="([^"]*)"', args_str))
result = tools.get(tool_name, lambda **_: f"未知工具: {tool_name}")(**kwargs)
history.append(reply)
history.append(f"Observation: {result}")
else:
history.append(reply)
history.append("Observation: 工具调用格式不正确")
run_agent("查询北京天气并推荐景点")典型运行结果:
makefile
第1章 智能体基础 - 最小智能体演示
模型: aliyun/qwen3.6-plus
==================================================
用户请求: 查询北京天气并推荐景点
--------------------------------------------------
--- 第 1 轮回复 ---
Thought: 用户需要查询北京的天气,并据此推荐景点。首先需要查询北京的天气情况。
Action: get_weather(city="北京")
Observation: 北京当前天气: Sunny,气温 24 摄氏度
--- 第 2 轮回复 ---
Thought: 已获取北京的天气信息(Sunny,24摄氏度),接下来需要根据此天气为用户推荐景点。
Action: get_attraction(city="北京", weather="Sunny")
Observation: 建议在北京选择半户外行程,如历史文化街区。
--- 第 3 轮回复 ---
Thought: 已经获取了北京的天气状况(晴天,24度)以及根据天气推荐的景点(历史文化街区)。信息已足够,可以直接回答用户。
Action: Finish[北京目前天气晴好,气温为24摄氏度。基于这样的天气条件,推荐前往历史文化街区游览,体验半户外的文化之旅。]
==================================================
最终结果: 北京目前天气晴好,气温为24摄氏度。基于这样的天气条件,推荐前往历史文化街区游览,体验半户外的文化之旅。
==================================================智能体在三轮循环中自主完成了"查天气 -> 查景点 -> 整合输出"的完整流程。核心只有两样东西:工具让 LLM 能操作外部世界,Prompt 规定了 LLM 的思考和行动规则。后续所有的框架和范式,都是在这个最小循环上做增强。
1.3.3 两种构建路线对比:流程驱动 vs AI 原生
看到这里可能会有疑问:既然 LLM 智能体这么强大,为什么还有很多企业选择用流程驱动的方式?答案没有绝对的优劣,关键在于不同场景对可控性和灵活性的要求不同。先搞清楚两种路线的差异,后面做技术选型时才能少走弯路。
当前智能体构建主要分为两种路线:
流程驱动(Workflow):以 Dify、Coze、n8n 等平台为代表。本质是将 LLM 嵌入预先定义的流程中,LLM 作为流程节点中的数据处理单元。
AI 原生(AI Native Agent):真正以 LLM 为核心驱动力的智能体。LLM 负责理解、规划、决策,工具和外部系统作为 LLM 的能力延伸。
两者的核心差异如下:
| 维度 | 流程驱动(Workflow) | AI 原生(Agent) |
|---|---|---|
| 控制权 | 流程引擎控制执行顺序 | LLM 自主决定下一步行动 |
| 路径确定 | 预先定义的固定路径 | 根据上下文动态规划路径 |
| 适用场景 | 规则明确、流程标准化的任务 | 需求模糊、需要灵活应变的任务 |
| 可预测性 | 高,行为完全可控 | 中等,LLM 输出带有概率性 |
| 开发方式 | 可视化编排,低代码 | 代码为主,需要设计架构 |
| LLM 角色 | 流程中的一个处理节点 | 整个系统的决策核心 |
| 缺点/代价 | 灵活性差,无法处理流程外的异常情况 | 不可完全预测,调试困难,成本较高 |
流程驱动的典型场景是费用报销审批:金额小于 500 元直接由部门经理审批,大于 500 元需财务总监复审。每一步的判断条件和流转规则都预先设定好了。这类场景不需要智能体做自主判断,只需要可靠地执行既定规则。
AI 原生的典型场景是智能旅行助手:用户说"帮我规划厦门之旅",智能体需要自主理解意图、规划步骤、查询信息、调整方案。每一步的行动取决于上一步的结果,无法预先写死流程。
两种路线并非互斥。在实际工程中,常常将两者结合:在确定性的子任务上使用流程驱动保证可靠性,在需要灵活判断的环节交给 AI 原生智能体做自主决策。这种混合架构兼顾了可控性和灵活性。

本章小结
这一章涉及的概念比较多,但核心主线很清晰:从什么是智能体,到它是怎么演进的,再到我们亲手搭了一个最小可用的智能体。一起回顾下今天都掌握了哪些能力:
- 智能体的定义与特征:能感知环境、自主决策、达成目标的实体,核心特征是自主性、反应性、主动性和社交性
- 五类智能体:从简单反射到自主学习,复杂度递增,每一类解决上一类无法处理的场景
- 技术演进因果链:符号主义(知识编码困难)→ 联结主义(只能感知不会决策)→ 强化学习(缺乏先验知识)→ 预训练 LLM(无法直接操作外部世界)→ 智能体架构
- LLM 带来的范式转变:从人工编码规则转向利用通用推理能力,同时也引入了幻觉和不确定性等新挑战
- 核心组件:LLM 提供推理能力,规划负责任务分解,记忆保持状态,工具扩展能力,执行引擎驱动 Thought-Action-Observation 循环
- 两种构建路线:流程驱动可控但僵化,AI 原生灵活但不可完全预测,工程中常采用混合架构
下一章将学习智能体的三种经典工作范式:ReAct、Plan-and-Solve 和 Reflection。它们对应三种不同的"思考方式":边想边做、先想清楚再做、做完再反思改进。