前面学了 Function Calling(让 Agent 会动手)和 RAG(让 Agent 会翻书),但还有个尴尬的问题:
你刚跟 Agent 聊完天,转头再问它"我刚才说了啥?"------它不记得了。
就像你跟朋友说"我喜欢吃辣的",下次吃饭他给你点了盆清汤------你啥心情?
Agent 没有记忆,就像一个金鱼的脑子。
今天来解决这个问题。
一、为什么 Agent 需要记忆?
先想想人类是怎么聊天的:
| 人类聊天 | Agent 聊天 |
|---|---|
| "你好,我叫张三" | Agent 记住你叫张三 |
| "我喜欢打篮球" | Agent 记住你的爱好 |
| "你叫什么名字?" | "我叫张三啊,你刚告诉我的" |
| 聊完,第二天再见 | "早啊张三,今天还聊篮球吗?" |
没有记忆的 Agent 呢?
你:你好,我叫张三
AI:你好!
你:我叫什么名字?
AI:我不知道啊,你没告诉过我。气不气人?
记忆系统就是解决这个问题的。
二、两种记忆:短期 vs 长期
类比人类记忆:
| 短期记忆 | 长期记忆 | |
|---|---|---|
| 像什么 | 便利贴 | 笔记本 |
| 存什么 | 刚才聊的话题 | 用户的重要信息 |
| 存多久 | 聊完就忘(或覆盖) | 写到文件里,永久保存 |
| 怎么用 | 维持对话上下文 | 下次启动还能读 |
| 例子 | "刚才说到哪了?" | "我记得你叫张三" |
2.1 短期记忆(ShortTermMemory)
就是记录当前对话的上下文。我实现了一个简单的:
python
class ShortTermMemory:
def __init__(self, max_turns=10):
self.conversation = [] # 存对话记录
self.max_turns = 10 # 最多记 10 轮
def add(self, role, content):
"""记下一条对话"""
self.conversation.append({
"role": role, # "user" 或 "assistant"
"content": content, # 说了什么
"time": "14:30:25" # 什么时候说的
})
# 太长就忘掉最早的
if len(self.conversation) > self.max_turns:
self.conversation.pop(0)关键:短期记忆有容量上限,满了就扔掉最旧的。就像你记不住一周前中午吃了什么一样。
2.2 长期记忆(LongTermMemory)
把重要信息存到文件里,下次启动还能读:
python
class LongTermMemory:
def __init__(self, storage_path="memory/long_term.json"):
self.storage_path = storage_path
self.memories = self._load() # 启动时加载
def remember(self, key, value):
"""记下一件事"""
self.memories[key] = {"value": value, "time": "2026-04-19"}
self._save() # 立刻写到文件
def recall(self, key):
"""回想一件事"""
return self.memories.get(key, {}).get("value")
def forget(self, key):
"""忘记一件事"""
del self.memories[key]
self._save()存储的文件长这样:
json
{
"user_name": {
"value": "张三",
"time": "2026-04-19 14:30:25"
},
"preferences": {
"value": ["打篮球", "辣的食物"],
"time": "2026-04-19 14:31:10"
}
}三、MemoryAgent:有记性的 Agent
把短期和长期记忆组合起来,就是有记忆的 Agent:
python
class MemoryAgent:
def __init__(self):
self.short_term = ShortTermMemory() # 便利贴
self.long_term = LongTermMemory() # 笔记本
def reply(self, user_message):
# 1. 记到短期记忆
self.short_term.add("user", user_message)
# 2. 查长期记忆,看看有没有相关信息
user_info = self.long_term.recall_all()
# 3. 根据消息 + 记忆,决定怎么回复
reply = self._think_reply(user_message, user_info)
# 4. 把回复也记到短期记忆
self.short_term.add("assistant", reply)
return reply四、Token 优化------别让你的 prompt 变成"裹脚布"
上面说的短期记忆有个问题:对话越长,prompt 越长,花的 token 越多。
聊 10 轮,几百 token。聊 100 轮,几千 token。聊 1000 轮......钱包受得了吗?
4.1 记忆压缩(Memory Compression)
原理很简单:把旧对话"浓缩"成摘要,扔掉细节,只留关键信息。
就像你写日记不会写"8:00 起床,8:01 刷牙,8:03 洗脸......",而是写"今天去了医院"。
我实现了一个 CompressedShortTermMemory:
python
class CompressedShortTermMemory:
def __init__(self, keep_recent=4, compress_after=8):
self.summaries = [] # 历史摘要列表
self.recent = [] # 最近几轮原始对话
self.keep_recent = 4 # 保留最近 4 轮原文
self.compress_after = 8 # 超过 8 轮就压缩
def add(self, role, content):
# 添加对话
self.recent.append(f"{role}:{content}")
# 满了?触发压缩
if len(self.recent) >= self.compress_after:
self._compress()
def _compress(self):
# 把要压缩的对话提取关键信息
to_compress = self.recent[:-4] # 保留最近 4 轮
summary = self._summarize(to_compress)
self.summaries.append(summary)
self.recent = self.recent[-4:] # 只保留最近 4 轮
def build_context(self):
# 输出:历史摘要 + 最近对话
# 体积小多了!
return self.summaries + self.recent4.2 压缩效果对比
跑一下测试,看看省了多少:
| 指标 | 普通记忆 | 压缩记忆 | 效果 |
|---|---|---|---|
| 存储方式 | 全部原文 | 摘要 + 最近几轮 | --- |
| 20 轮对话 | ~340 tokens | ~280 tokens | 省 ~18% |
| 100 轮对话 | ~1700 tokens | ~400 tokens | 省 ~76% |
| 对话越长 | 线性增长 | 趋于稳定 | 省更多! |
| 关键信息 | 全保留 | 摘要提取 | 够用 |
对话越长,压缩效果越明显。如果你和 Agent 能聊几百轮,压缩能帮你省 70-80% 的 token 费用。
4.3 摘要怎么生成?
生产环境一般调 LLM 来总结:
erlang
原始对话:
用户:我叫张三
助手:你好张三!
用户:我喜欢打篮球
...
LLM 摘要 → "用户叫张三,喜欢打篮球"但我代码里用的是规则提取------找"我叫""喜欢""学了"等关键词来提取。好处是不用调 API 也能演示原理。
4.4 token 估算方法
代码里我写了个 estimate_tokens() 函数,不用 API 也能估算:
python
def estimate_tokens(text):
"""粗略估算 token 数"""
chinese = sum(1 for c in text if '一' <= c <= '鿿')
english = len(text) - chinese
return int(chinese * 1.5 + english * 0.3)规则:中文 1.5 个字 / token,英文 3 个字母 / token。不完全准确,但够用来对比效果。
4.5 更多省 token 技巧
| 技巧 | 做法 | 效果 |
|---|---|---|
| 滑动窗口 | 只保留最近 N 轮对话 | 最简单,但会丢掉旧信息 |
| 摘要压缩 | 把旧对话总结成几句话 | 省 token,保留关键信息 |
| 重要性打分 | 重要的永远保留,不重要的先丢 | 精准控制 |
| 去重 | 去掉重复的信息 | 特别是长期记忆里 |
| 结构化存储 | 用 JSON 而不是自然语言存 | 减少冗余描述 |
运行效果演示
代码写好了,跑起来看看:
测试 1:短期记忆------记得刚才聊了什么
css
[用户] 你好!
[AI] 我知道了,这个话题我记下了。
[用户] 我想学英语单词
[AI] 我知道了,这个话题我记下了。
[用户] 我叫小明
[AI] 你好,小明!已经记住你啦!
[用户] 我叫什么名字?
[AI] 你叫小明呀,我记性可好了!
→ 短期记忆已记录 10 条对话测试 2:长期记忆------跨会话还记得你
css
第一轮对话:
[用户] 你好,我叫小红
[AI] 你好,小红!已经记住你啦!
[用户] 我喜欢猫和音乐
[AI] 好嘞,我记住了!
[用户] 我学了 cat 和 dog 单词
[AI] 收到!
------ 模拟重新启动 ------
第二轮对话(Agent 加载了长期记忆文件):
[用户] 我叫什么名字?
[AI] 你叫小红呀,我记性可好了!
[用户] 我喜欢什么?
[AI] 我记得你喜欢:猫、音乐测试 3:记忆管理------回顾和遗忘
css
[用户] 查看我的记忆
[AI] 我的记忆状态:
[短期记忆] 1 条对话
[长期记忆] 3 条信息
执行:让 Agent 忘记偏好设置
→ 还剩 2 条记忆:user_name, learned_words
[用户] 清空所有记忆
→ 长期记忆剩余:0 条
→ 短期记忆剩余:0 条测试 4:记忆一致性------短期和长期配合
css
[用户] 我叫张三
[AI] 你好,张三!已经记住你啦!
[用户] 我喜欢打篮球
[AI] 好嘞,我记住了!
[用户] 我学了 rabbit 单词
[AI] 收到!
[用户] 我叫什么?
[AI] 你叫张三呀,我记性可好了!
[用户] 我有什么爱好?
[AI] 我记得你喜欢:打篮球
最终状态:
- 短期记忆:10 条对话记录
- 长期记忆:3 条持久化信息
- 两者协同工作,互不冲突测试 5:记忆压缩------省 token 还能记住关键信息
css
[对比] 普通记忆 vs 压缩记忆
对话总轮数:20 轮
普通记忆:~340 tokens
压缩记忆:~280 tokens
省了约 18% 的 token!
状态:轮次:40 | 摘要:9条 | 近期:4轮 | 预估:284 tokens | 节省:~449 tokens
关键信息还在:
- 记住了"我叫张三"
- 记住了"喜欢打篮球"
- 记住了"学了 cat 和 dog"五、什么时候用什么记忆
| 场景 | 用哪个 | 为什么 |
|---|---|---|
| 用户说"刚才我们聊到哪了?" | 短期记忆 | 找最近的对话上下文 |
| 用户说"你还记得我叫什么吗?" | 长期记忆 | 跨会话的信息 |
| 用户说"帮我总结今天的学习" | 短期 + 长期 | 短期看今天聊了啥,长期看用户信息 |
| 用户说"忘掉我的偏好设置" | 长期记忆.forget() | 精确删除指定内容 |
| 用户说"重置所有" | 两个都清空 | 彻底重新开始 |
六、短期记忆 vs 长期记忆 对比
加上压缩记忆,就是三种记忆了。可以理解成:
- 短期记忆:便利贴(方便,但贴满了就扔旧的)
- 压缩记忆:笔记本摘要(定期整理,把旧内容浓缩)
- 长期记忆:保险箱(重要信息永久保存)
| 维度 | 短期记忆 | 长期记忆 |
|---|---|---|
| 存哪 | 内存(列表) | 磁盘(JSON 文件) |
| 速度 | 极快 | 慢一点(要读写文件) |
| 容量 | 有限(默认 10 轮) | 几乎无限 |
| 持久性 | 程序退出就丢 | 下次启动还在 |
| 适合 | 对话上下文 | 用户画像、偏好、关键信息 |
七、生产环境的内存设计思路
真实项目里,记忆系统不能只是 demo 级别,要考虑这几个问题:
7.1 三层记忆架构
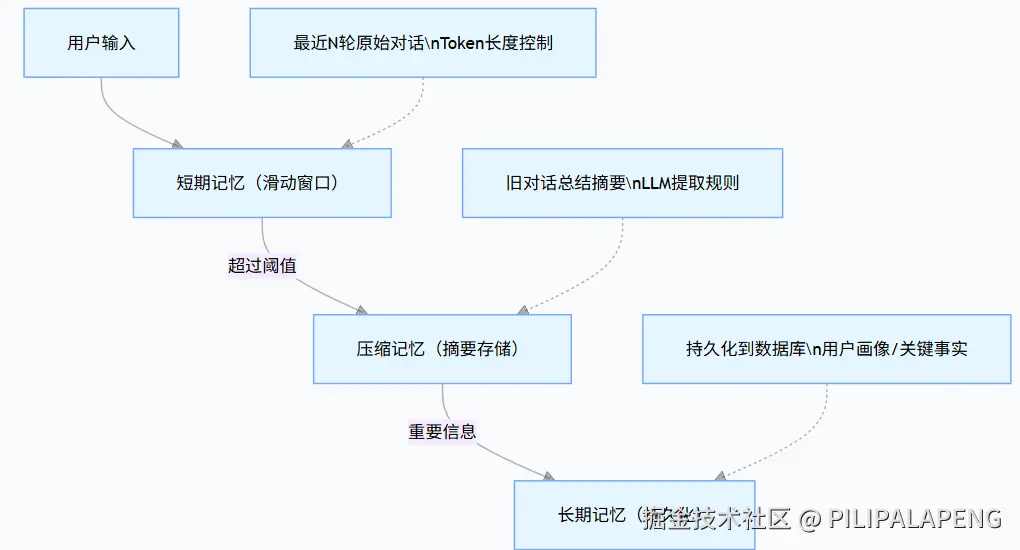
7.2 Token 预算管理
python
# 设定 token 预算,防止 prompt 无限膨胀
MAX_CONTEXT_TOKENS = 4000
def build_prompt(user_input, short_term, long_term):
"""动态构建 prompt,确保不超预算"""
prompt_parts = []
# 1. 系统指令(固定,最优先)
system = "你是一个有帮助的 AI 助手。"
prompt_parts.append(system)
budget = MAX_CONTEXT_TOKENS - estimate_tokens(system)
# 2. 长期记忆(重要信息,优先放)
user_info = long_term.recall_all()
if user_info:
info_text = f"用户信息:{json.dumps(user_info, ensure_ascii=False)}"
if estimate_tokens(info_text) < budget:
prompt_parts.append(info_text)
budget -= estimate_tokens(info_text)
# 3. 短期记忆(尽量放,但要控制)
context = short_term.build_context()
if estimate_tokens(context) > budget:
# 超预算了,只放最近几轮
context = short_term.build_context(max(3, budget // 50))
prompt_parts.append(context)
# 4. 当前问题
prompt_parts.append(f"用户问题:{user_input}")
return "\n\n".join(prompt_parts)7.3 重要信息优先级
不是所有记忆都同等重要。可以给信息打分,重要的优先保留:
| 优先级 | 信息类型 | 例子 | 处理方式 |
|---|---|---|---|
| 🔴 高 | 身份信息 | 名字、年龄、职业 | 永远保留,存长期记忆 |
| 🟡 中 | 偏好信息 | 喜欢什么、讨厌什么 | 尽量保留,可压缩 |
| 🟢 低 | 日常对话 | "今天天气不错" | 随意压缩或丢弃 |
7.4 实际项目中用什么存
| 存储方案 | 适合 | 不适合 |
|---|---|---|
| JSON 文件 | 个人项目、小规模 | 并发读写、大量数据 |
| SQLite | 单机应用、轻量级 | 高并发、分布式 |
| Redis | 高频读写、短期记忆 | 长期持久化(要配合其他方案) |
| PostgreSQL | 生产环境、结构化存储 | 简单项目太重了 |
八、记忆 + RAG + Function Calling 的完整拼图
现在你已经学了三个核心能力:
javascript
Function Calling → Agent 会"动手"(调用工具、发消息、查天气)
+
RAG → Agent 会"翻书"(检索文档、查知识库)
+
记忆系统 → Agent 有"记性"(记住你是谁、喜欢什么)
=
一个像样的智能体!举个综合例子:
markdown
用户:"帮我查一下昨天我学了哪些单词,然后发个总结到我邮箱"
Agent 的处理:
1. 记忆系统 → 查用户信息:叫小明,邮箱是 xxx@xx.com
2. RAG → 检索学习记录:找到昨天学的单词
3. Function Calling → 调用发邮件接口
最终:"小明,你昨天学了 cat、dog、bird 三个单词,
总结已发送到你的邮箱 xxx@xx.com"九、今日总结
今天干了啥:
- 理解了 Agent 为什么需要记忆(不然像个金鱼脑子)
- 学会了短期记忆(便利贴,记对话上下文)
- 学会了长期记忆(笔记本,跨会话持久化)
- 学会了记忆压缩(省 token 还能记住关键信息)
- 理解了生产环境的内存设计(三层架构 + token 预算)
- 实现了完整的记忆 Agent,跑了 5 个测试用例
三种记忆对比
| 短期记忆 | 压缩记忆 | 长期记忆 | |
|---|---|---|---|
| 存啥 | 最近几轮对话原文 | 旧对话的摘要 | 用户关键信息 |
| 存哪 | 内存 | 内存 | 磁盘文件 |
| 持久性 | 重启丢 | 重启丢 | 重启还在 |
| Token | 最费 | 省 | 极少 |
| 适合 | 上下文理解 | 长对话场景 | 跨会话信息 |
省 token 核心口诀
能扔的扔,能缩的缩,重要的存保险箱。
代码位置 :week4/01_agent_memory/app.py
可以运行的命令:
python app.py------ 跑 5 个测试用例python app.py --chat------ 交互模式,自己试试
试试说这些话:
- "我叫小明"
- "我喜欢看电影"
- "我学了 apple 单词"
- "我的记忆怎么样?"
- "清空记忆"
明天预告:多步推理 Agent------让 Agent 学会"拆解问题,一步步解决"。
写于 2026-05-08,智能体记忆系统------给 Agent 一个"大脑"
