这篇主要是博主想了解一下Spring AI的advisor底层机制,所记下的一篇笔记,博主扒源码扒了一整天,算是从大体上梳理了整个advisor的机制,具体细节问题可能会有错误和疏忽。同时附上了一些项目中advisor的涉及遇见的一些问题和解决方法,以及项目中advisor的一些比较好的设计思路和方案,觉的有帮助或者喜欢的还请点个赞⦁⩊⦁ ੭
一:解释一下advisor机制
一句话解释:Spring AI 的 Advisor 机制,本质上就是一个专门针对"AI对话(请求与响应)"的拦截器。 它可以在你把问题发给大模型之前 ,或者大模型把答案返回给你之后,对数据进行拦截、修改、增强或记录。
1. 核心概念:洋葱模型
Advisor 的执行过程就像一个洋葱。请求从外向内层层穿透,直到核心(调用大模型),然后响应从内向外层层返回。
- 请求阶段 (Request) :按顺序执行(A -> B -> C -> 模型)。
- 响应阶段 (Response) :按相反顺序执行(模型 -> C -> B -> A)。
这意味着,你可以在请求发给 AI 之前 修改提示词(比如注入历史记录),也可以在 AI 返回结果 之后 处理数据(比如格式化输出或检查敏感词)。这里可以看见advisor机制就类似于
拦截器,在我们发送LLM请求之前做一些自定义的处理(比如做RAG检索,记录观测日志),并在LLM返回响应后,通过他的回调方法来进行一些AI响应结果的自定义处理,然后返回给用户
二:具体深入了解一下advisor内部
1.介绍一下继承体系
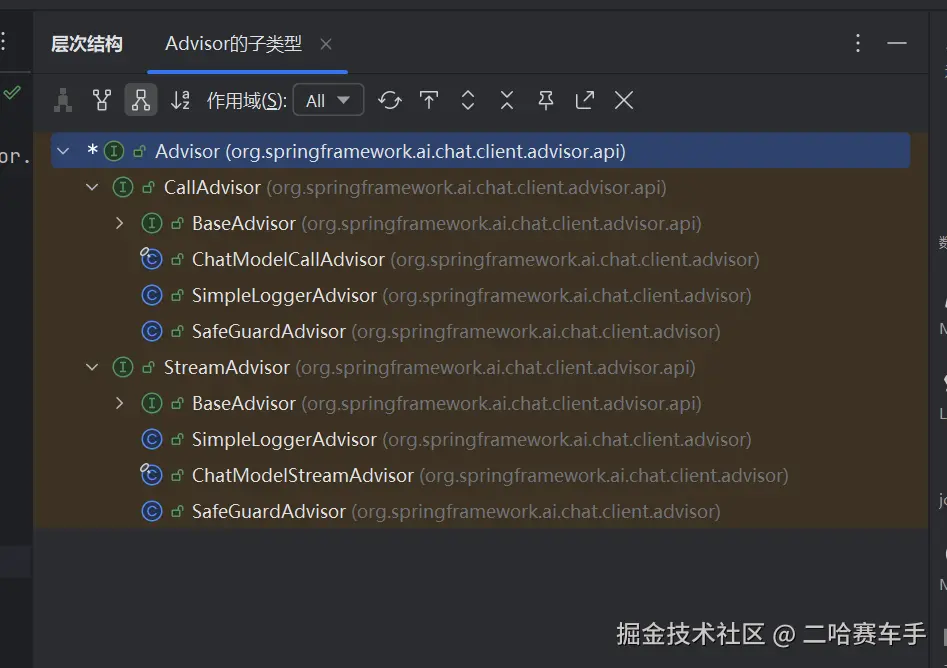
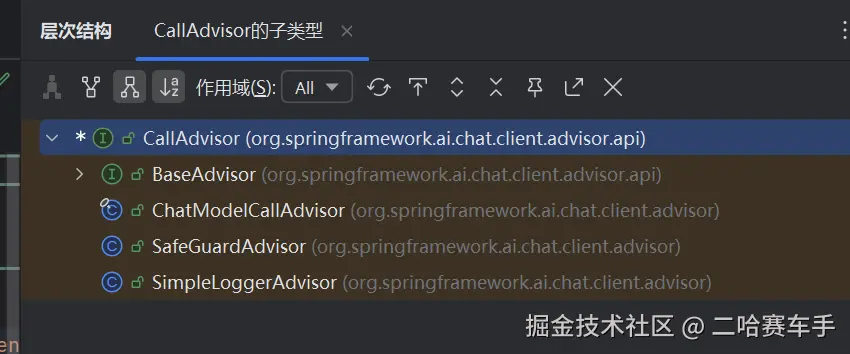
这是advisor的继承体系,可以看见我们的
advisor接口是整个体系的核心,有两个子接口:CallAdvisor和StreamAdvisor,他们的实现类都差不多
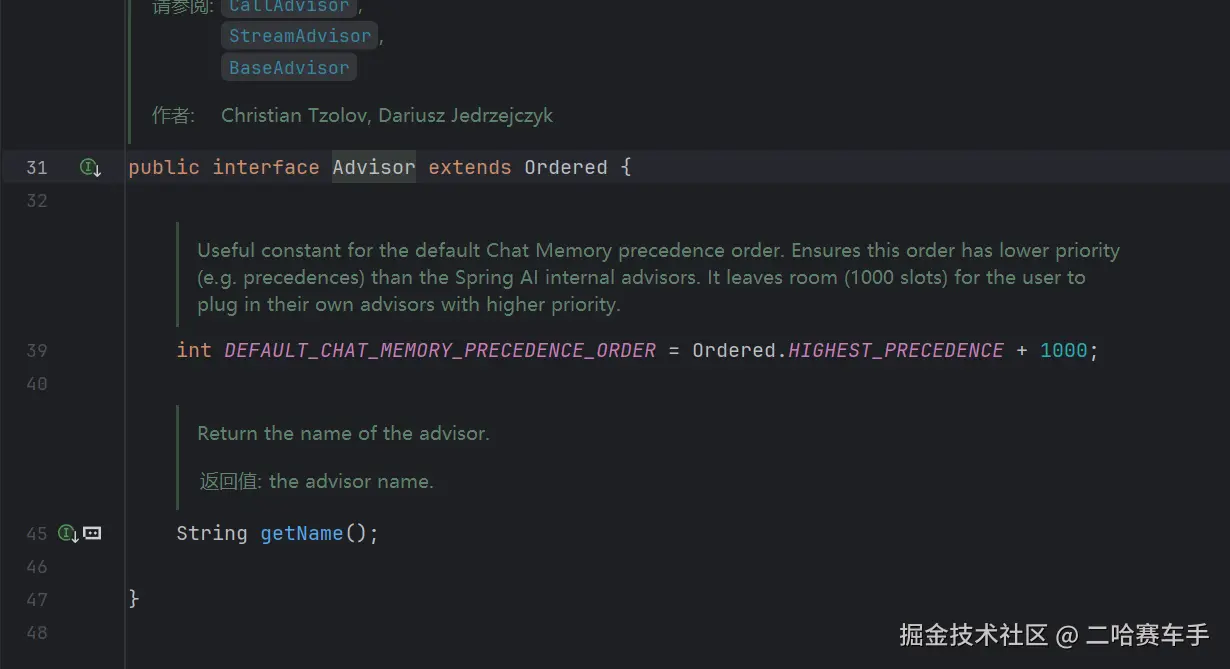
我们查看
advisor接口的内部,发现他继承自order接口,并且内部提供了一个变量DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER,这个博主也不太理解,下面引入一下AI的解释
一、DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER
java
int DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER = Ordered.HIGHEST_PRECEDENCE + 1000;这是定义 Chat Memory Advisor 的默认执行优先级顺序。
| 部分 | 含义 |
|---|---|
Ordered.HIGHEST_PRECEDENCE |
Spring 框架中定义的最高优先级值(通常是 Integer.MIN_VALUE,即 -2147483648) |
+ 1000 |
在最高优先级基础上往后挪1000位,也就是**优先级降低1000档 |
为什么要这样设计?
java
优先级数值越小,执行越靠前(越先执行)
Ordered.HIGHEST_PRECEDENCE (-2147483648)
↓
Spring AI 内部 Advisors(框架自己的拦截器)
↓
DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER (-2147482648) ← 这里
↓
用户自定义 Advisors(你写的拦截器,可以插在这里)
↓
...
Ordered.LOWEST_PRECEDENCE (2147483647)设计意图
"It leaves room (1000 slots) for the user to plug in their own advisors with higher priority"
翻译:留出1000个空位,让用户可以插入优先级更高的自定义 Advisor
也就是说:
- Spring AI 自己的内部 Advisor 优先级最高(最先执行)
- Chat Memory Advisor 次之
- 用户自定义的 Advisor 可以插在 Chat Memory 之前(数值更小,优先级更高),处理更紧急的逻辑
使用方法
方式1:你不干预(默认情况)
Spring AI 自动把
ChatMemoryAdvisor放在+1000的位置,你什么都不用做。
java
// 默认配置,ChatMemoryAdvisor 自动生效
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder
.defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory))
.build();
}方式2:你想让自定义 Advisor 在 ChatMemory 之前执行
场景:你想在加载历史记忆之前,先做一些预处理(比如敏感词过滤、请求改写)。
java
@Component
public class MyPreProcessAdvisor implements Advisor {
// 优先级比 ChatMemory 高(数值更小,先执行)
@Override
public int getOrder() {
// 比 ChatMemory 的 +1000 更小,所以先执行
return Ordered.HIGHEST_PRECEDENCE + 500; // 插在前500的位置
}
@Override
public String getName() {
return "MyPreProcessAdvisor";
}
@Override
public AdvisedRequest advise(AdvisedRequest request, Map<String, Object> context) {
// 在 ChatMemory 加载历史之前,先处理请求
System.out.println("我先执行!在记忆加载之前");
return request; // 继续传给下一个 Advisor
}
}执行顺序:
java
1. MyPreProcessAdvisor (+500) ← 你先执行
2. ChatMemoryAdvisor (+1000) ← 然后加载记忆
3. 其他默认 Advisors
4. 最终调用 LLM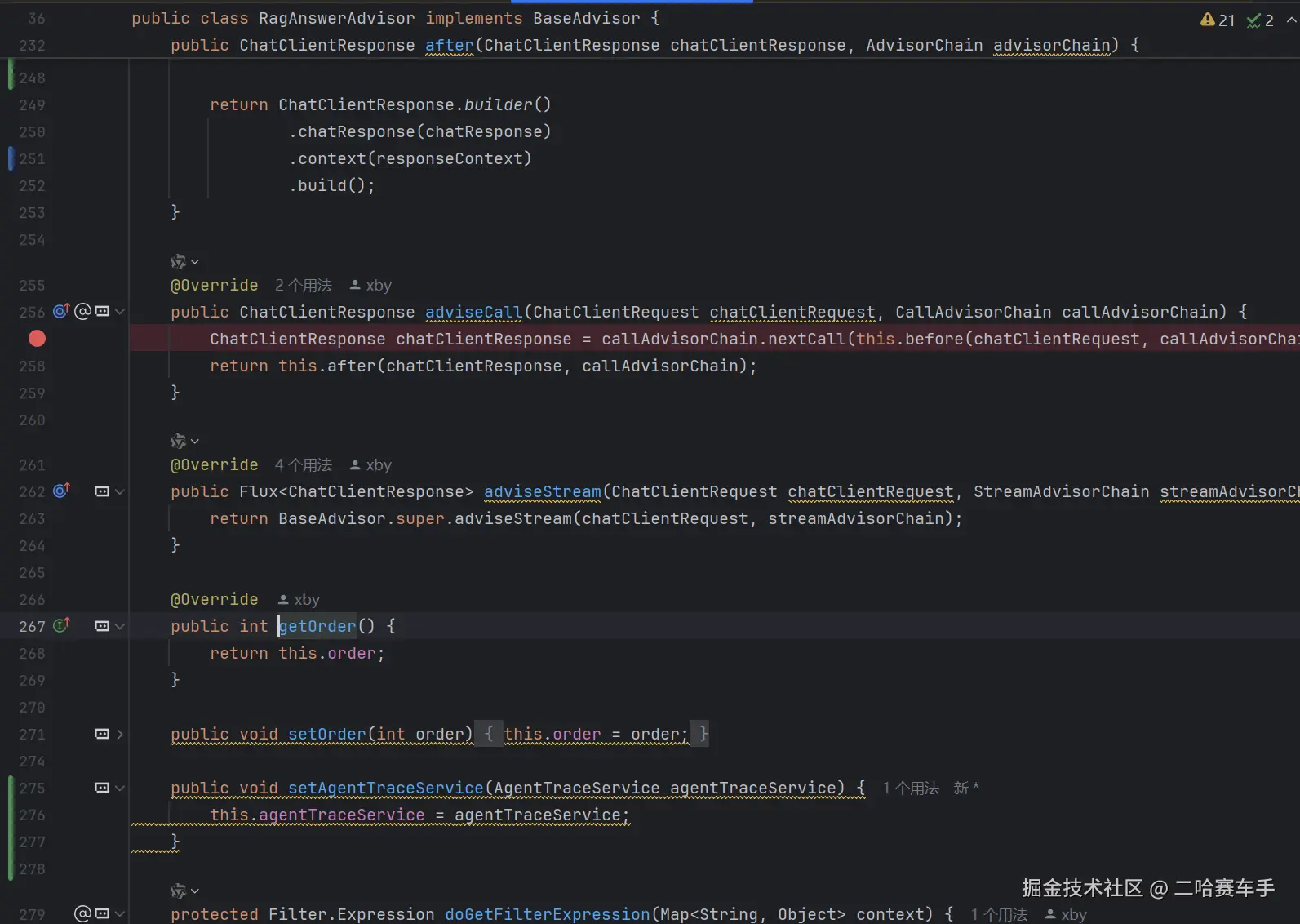
可以看见我们实现的自定义的顾问,它内部都会提供
getOrder(),setOrder()发给方法,我们可以手动通过控制返回值大小,来控制advisor的执行顺序(数值小的先执行)
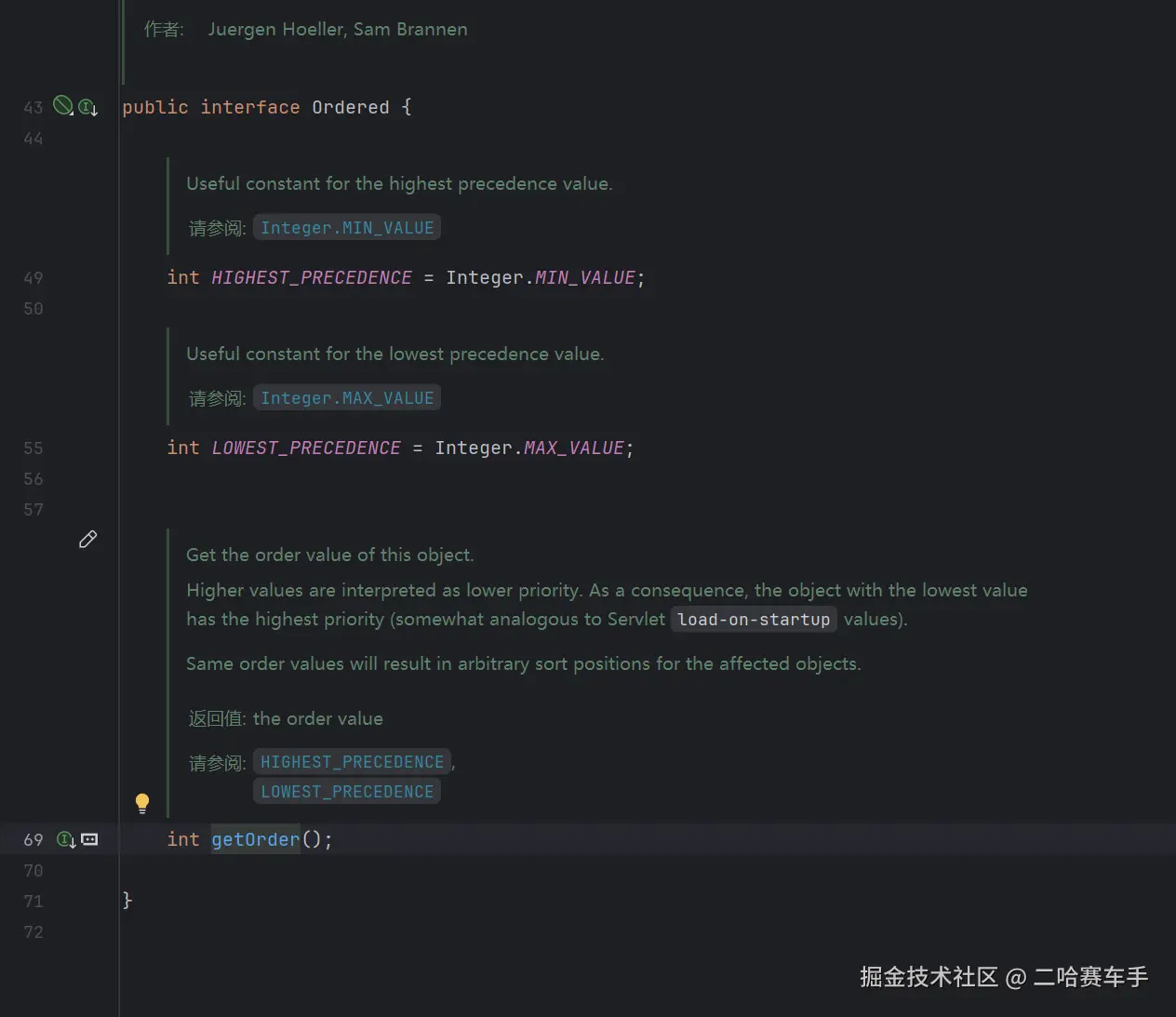
可以看见
order接口内部提供了两个不同的precedence阈值与一个getOrder方法,getOrder()方法核心作用只有一个:为对象定义一个 "优先级 / 顺序值",让 Spring 能自动按这个值排序,决定它们的执行顺序。
2.介绍一下CallAdvisor与StreamAdvisor
(1)介绍一下CallAdvisor与StreamAdvisor
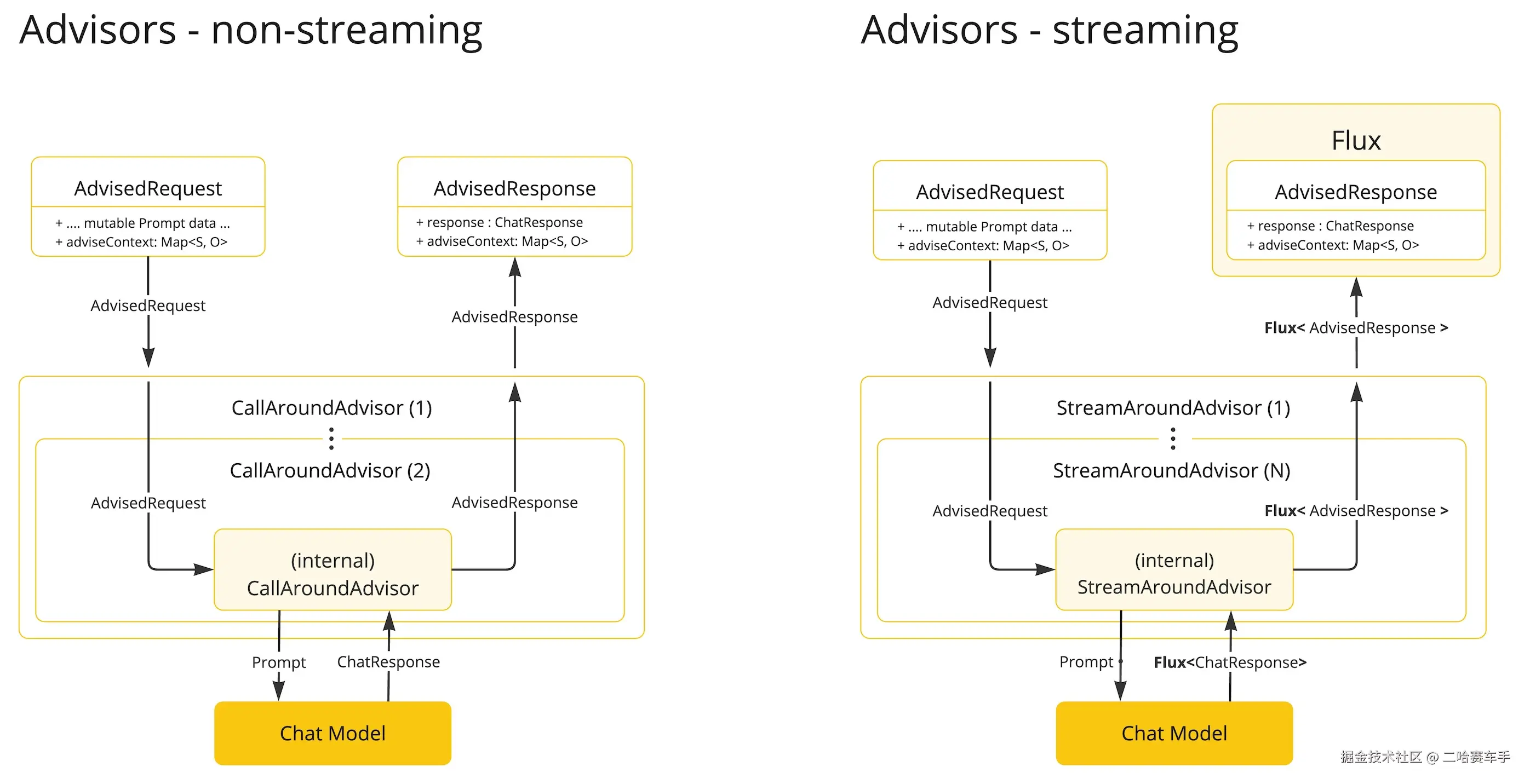
1. CallAdvisor(同步拦截器)
它是处理"一次性买卖"的。
-
核心方法 :
adviseCall(ChatClientRequest request, CallAdvisorChain chain) -
工作流程:
- 接收请求。
- 调用
chain.nextCall(request)(这一步会阻塞,直到 AI 返回完整结果)。 - 拿到完整的
ChatClientResponse。 - 你可以修改这个完整的响应,或者直接返回。
-
适用场景:
- 普通的问答接口。
- 需要获取完整 Token 消耗统计。
- 需要将 AI 的回复转换为 Java 对象(JSON 转 Object)。
2. StreamAdvisor(流式拦截器)
它是处理"涓涓细流"的。
-
核心方法 :
adviseStream(ChatClientRequest request, StreamAdvisorChain chain) -
工作流程:
- 接收请求。
- 调用
chain.nextStream(request)。 - 注意 :这里拿到的不是一个结果,而是一个
Flux<ChatClientResponse>(这是一个数据流管道,里面源源不断地流出文字片段)。 - 你需要对这个
Flux进行操作(比如使用 Reactor 操作符:map,filter,doOnNext)。 - 最后返回修改后的
Flux。
-
适用场景:
- 聊天窗口,需要用户看到实时的生成过程。
- 需要实时过滤敏感词(一旦检测到敏感词,立马切断流)。
java
┌─────────────────────────────────────────────────────────┐
│ 用户发送消息 │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 判断调用方式:call() 还是 stream()? │
│ • chatClient.prompt().call() → 走 callAdvisor │
│ • chatClient.prompt().stream() → 走 streamAdvisor │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────┴─────────────────┐
↓ ↓
┌───────────────┐ ┌───────────────┐
│ callAdvisor │ │ streamAdvisor │
│ (同步路径) │ │ (流式路径) │
├───────────────┤ ├───────────────┤
│ 1. 前处理 │ │ 1. 前处理 │
│ 加载记忆 │ │ 加载记忆 │
│ 2. 调用下一个 │ │ 2. 调用下一个 │
│ Advisor │ │ Advisor │
│ 3. 调用 LLM │ │ 3. 调用 LLM │
│ 4. 后处理 │ │ 4. 流式返回 │
│ 保存记忆 │ │ 逐字显示 │
│ 5. 返回完整响应│ │ 5. 流结束后 │
│ │ │ 保存记忆 │
└───────────────┘ └───────────────┘下面重点解释一下
stream流式响应
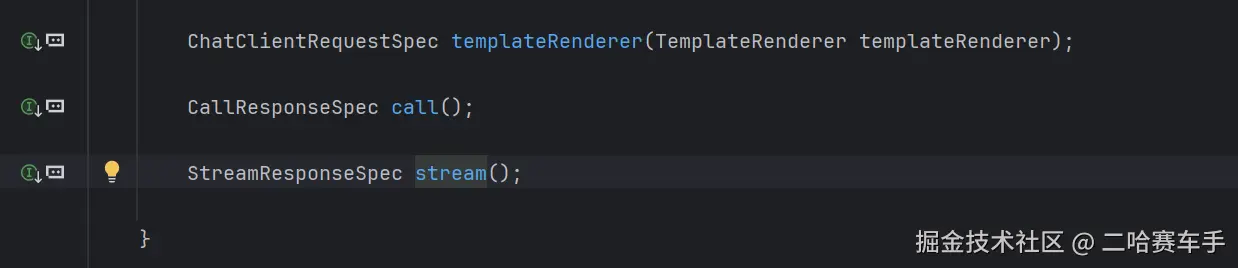
具体可以看
chatClient内部构造,调用stream()方法会返回一个StreamResponseSpec接口类型的对象

这里看stream()的重写方法,本质是返回一个
DefaultStreamResponSpec对象,并将设置好的请求参数,包括顾问连都传递进去
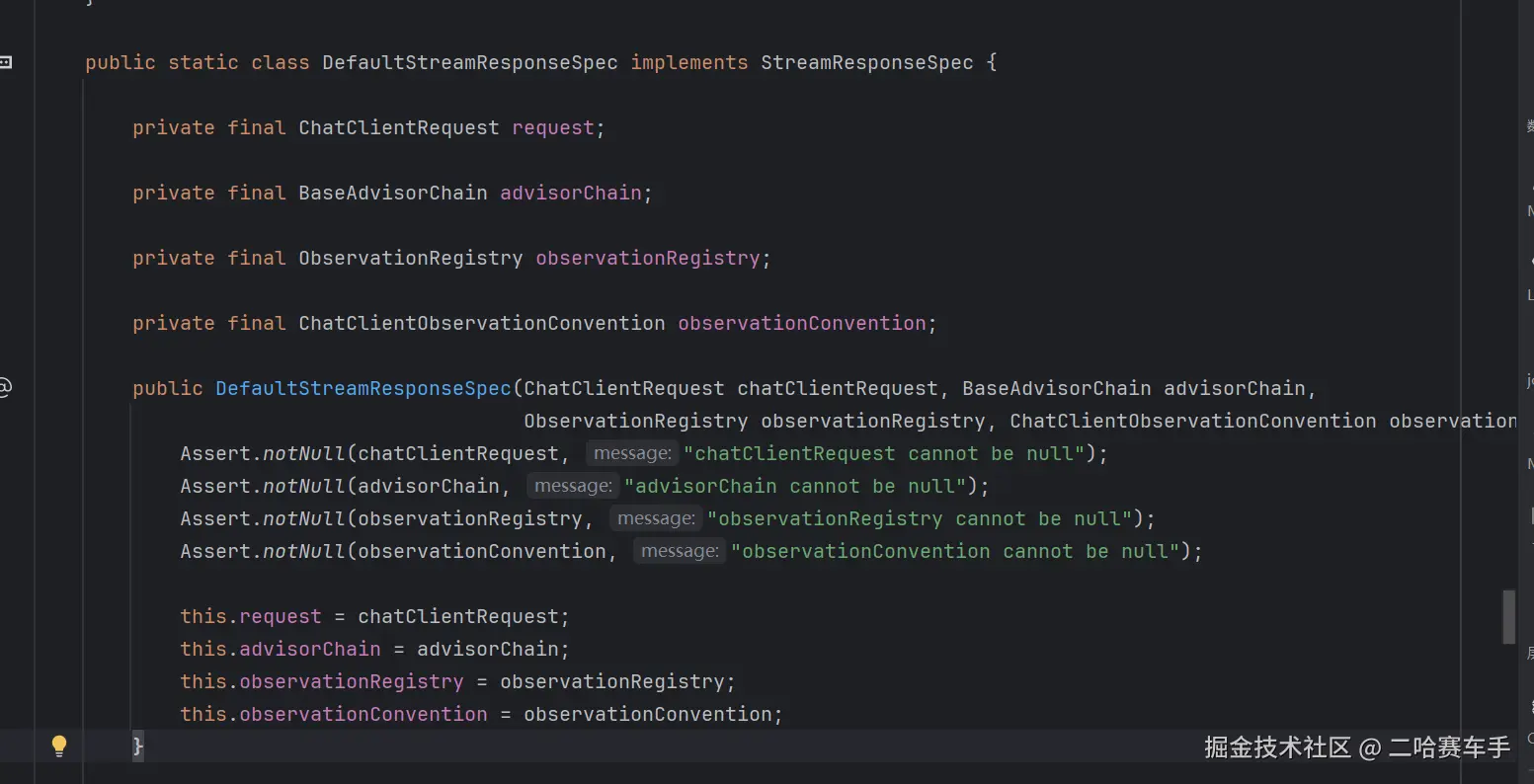
该类是
StreamResponseSpec的实现类,接受stream()的方法并且封装在内部变量中
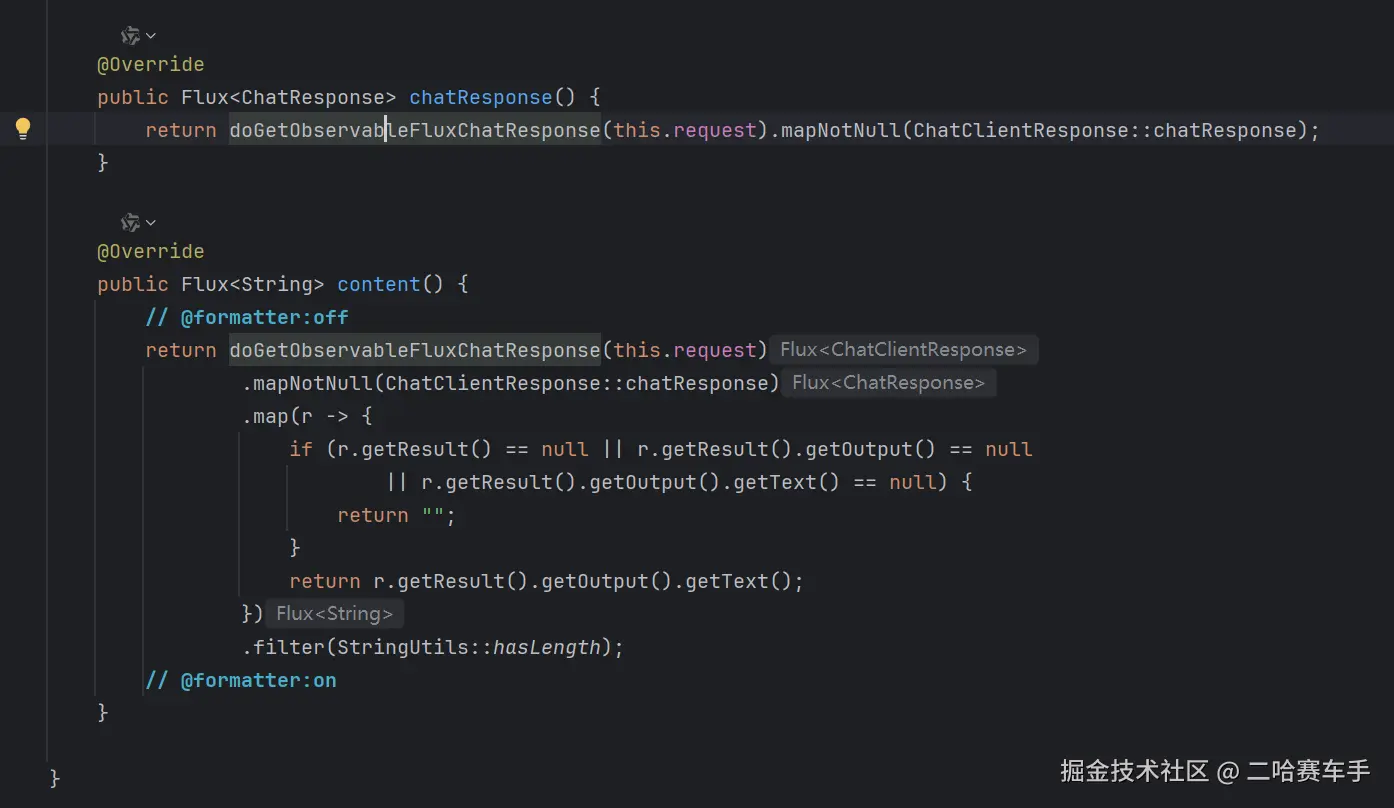
最终我们调用的
chatReponse方法本质还是调用该类的重写后的chatResponse方法,底层还是doGetObservableFluxChatResponse方法,和之前的chatClient源码篇都差不多,最后返回一个流式对象Flux<ChatResponse>
具体的调用图片
(2)CallAdvisor的方法
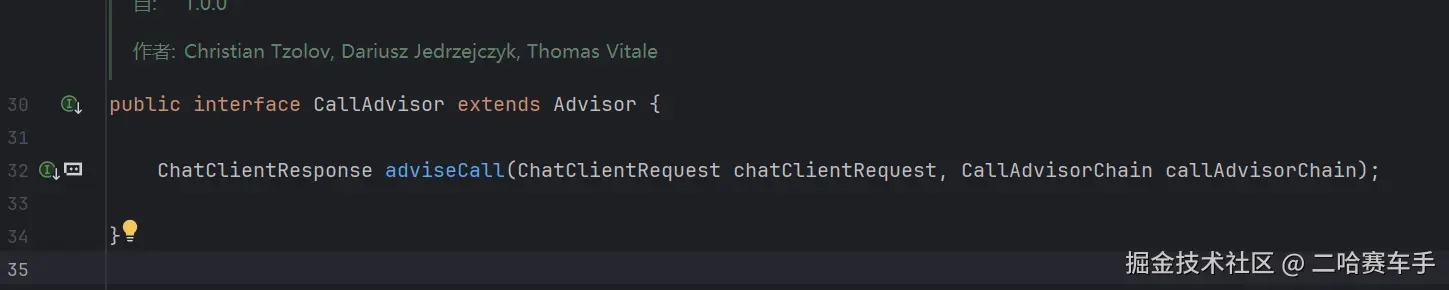
他提供了一个接口方法
adviseCall
| 参数 | 类型 | 含义 |
|---|---|---|
chatClientRequest |
ChatClientRequest |
用户的请求对象(包含 Prompt、配置等) |
callAdvisorChain |
CallAdvisorChain |
Advisor 调用链,用于传给下一个 Advisor |
| 返回值 | ChatClientResponse |
AI 的完整响应对象 |
adviseCall = 对「同步阻塞式」AI 调用进行拦截处理的方法
adviseCall |
streamAdvisor |
|
|---|---|---|
| 调用方式 | 同步(阻塞等待完整响应) | 异步流式(实时接收片段) |
| 返回值 | ChatClientResponse(单个完整对象) |
Flux<ChatClientResponse>(数据流) |
| 适用场景 | 短回复、不需要实时显示 | 长回复、需要打字机效果 |
| 用户感知 | 等全部生成完才显示 | 逐字实时显示 |
adviseCall(总指挥)
- 定义:这是 CallAdvisor 接口中定义的唯一必须实现的方法。
- 职责:它负责完全控制请求的处理流程。它决定了什么时候修改请求、什么时候调用下一个节点(最终调用 AI)、什么时候修改响应。
- 底层逻辑:如果你直接实现 CallAdvisor 接口,你必须手写 adviseCall,并在里面手动调用 chain.nextCall(request)。
它定义了我们内部的顾问核心逻辑的处理,顾问链中节点的传递等等,Spring AI 提供了一个名为
BaseAdvisor的接口,它实现了 CallAdvisor,并帮你写好了 adviseCall 的默认逻辑。
StreamAdvisor也是同理,这里就不再解释了
3.介绍一下BaseAdvisor,以及具体的顾问链的底层,如何调用等等
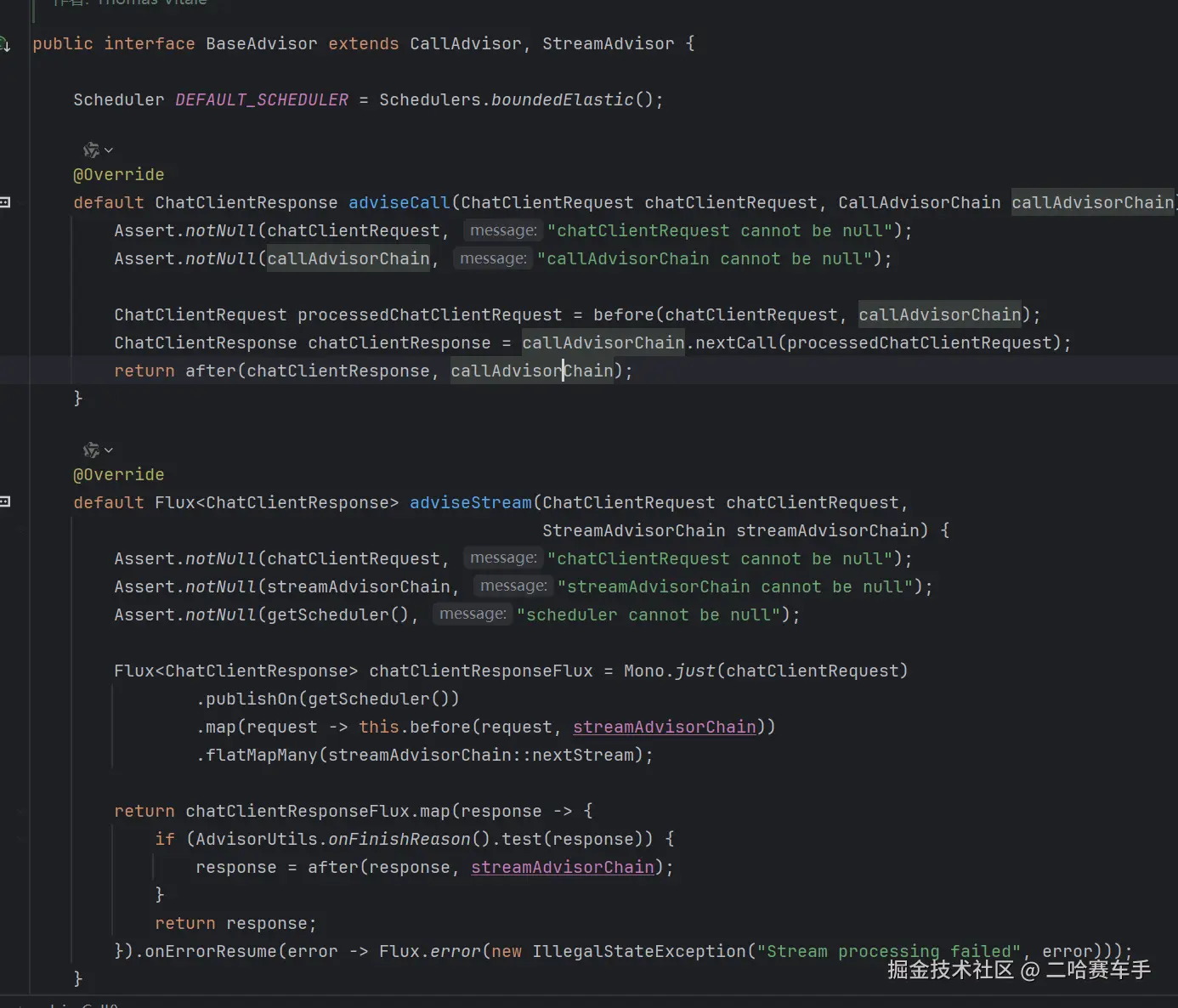
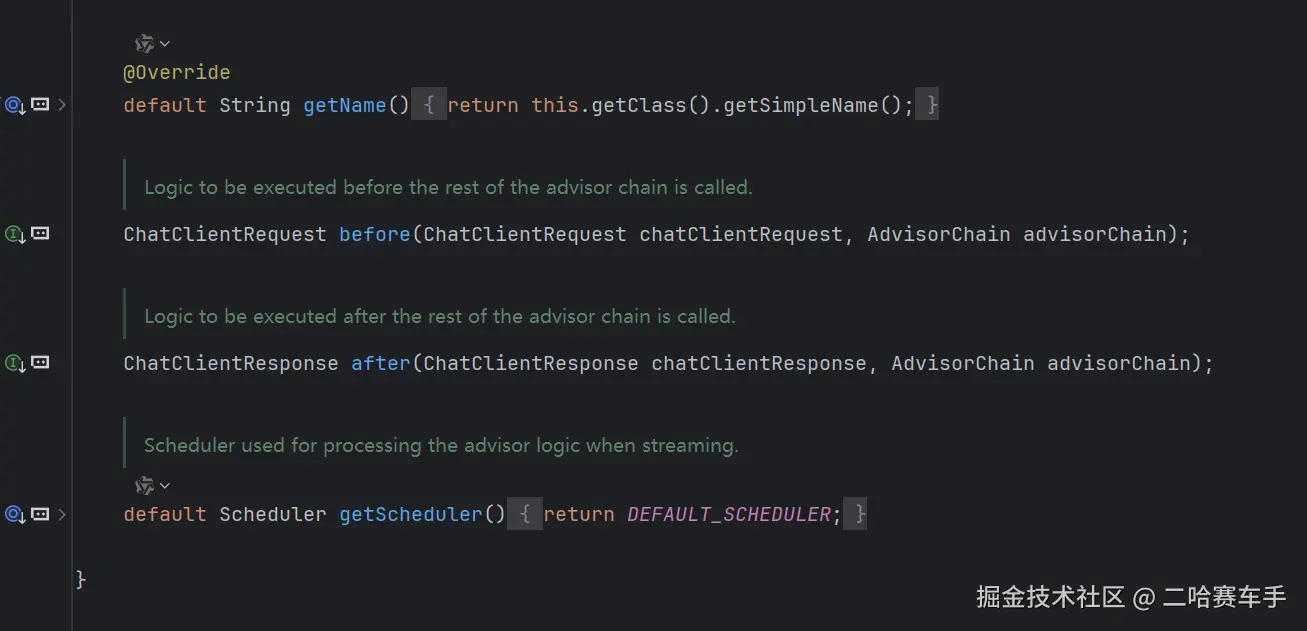
该类具体的结构图
java
// BaseAdvisor 的默认实现
public interface BaseAdvisor extends CallAdvisor {
// 这是核心方法(总指挥)
@Override
default ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// 1. 调用 before 方法(前置处理)
// 你可以在这里修改 request
ChatClientRequest processedRequest = this.before(request, chain);
// 2. 调用链中的下一个 Advisor 或 AI 模型
// 这一步才是真正的"调用 AI"
ChatClientResponse response = chain.nextCall(processedRequest);
// 3. 调用 after 方法(后置处理)
// 你可以在这里修改 response
return this.after(response, chain);
}
// 这是留给你的扩展点(具体工人)
default ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
return request; // 默认什么都不做
}
default ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
return response; // 默认什么都不做
}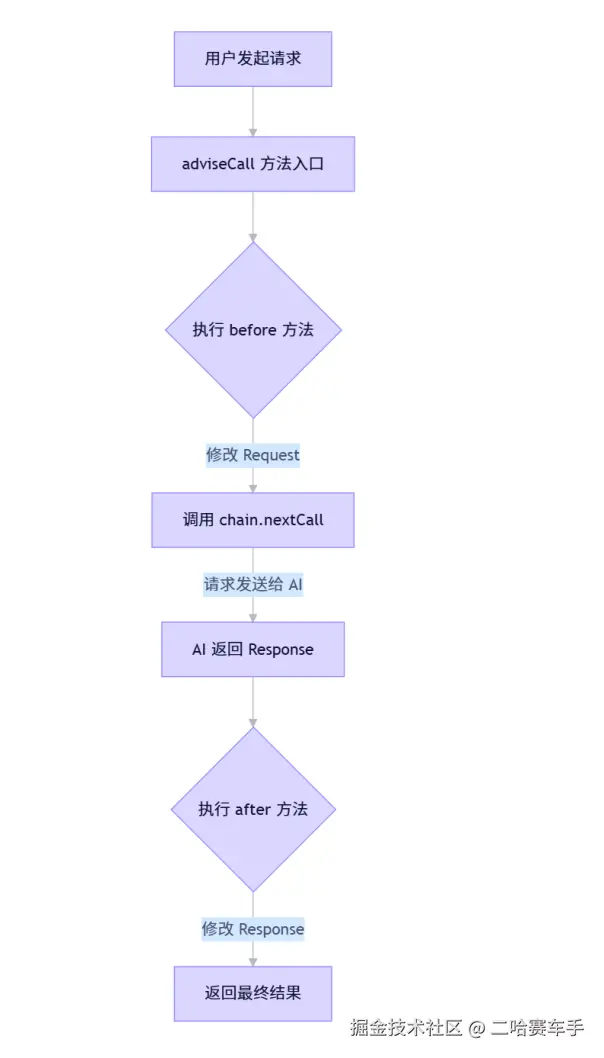
baseAdvisor就像是一个半成品的advisor,他是一个接口,继承自callAdvisor/streamAdvisor,提供了before/after方法,让我们自己实现顾问增强逻辑,同时重写了advisorCall发方法,封装好了顾问跳转方法,不需要我们手动实现,以及顾问调用before/after的触发时机等等,我们后续的自定义顾问就用到了他,基本我们需要实现自己的顾问,就要实现该接口
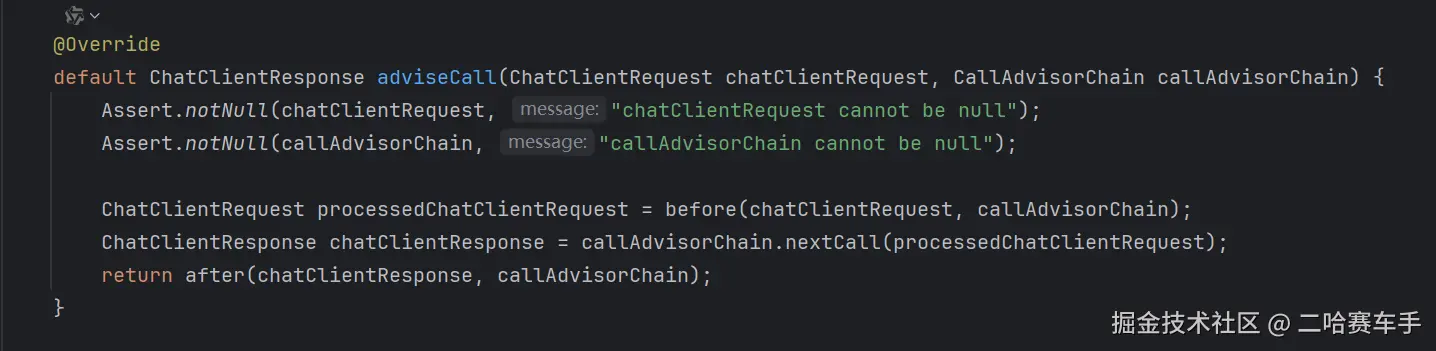
他这里的输入参数有
ChatRequest与顾问链CallAdvisorChain,看到这一点,博主突然想到了,他这与chatClient内部的call方法有关系啊

我们的
call内部就是构建了一个advisor顾问链BaseAdvisorChain,并且传递了参数chatRequest和顾问链条等全部所需参数
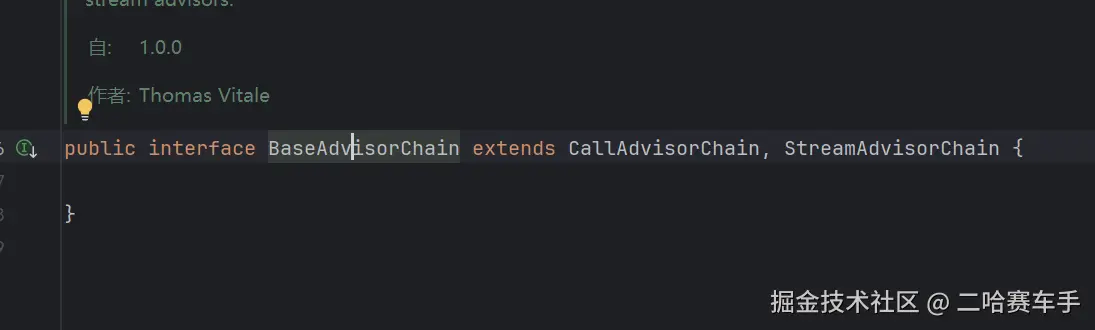
同时该
BaseAdvisorChain本身就继承了CallAdvisorChain和StreamAdvisorChain,正好符合我们顾问的两种形式,是不是猛然间都联系起来了,后续他就会去调用doGetObservableChatClientResponse,我们之前笔记有讲过
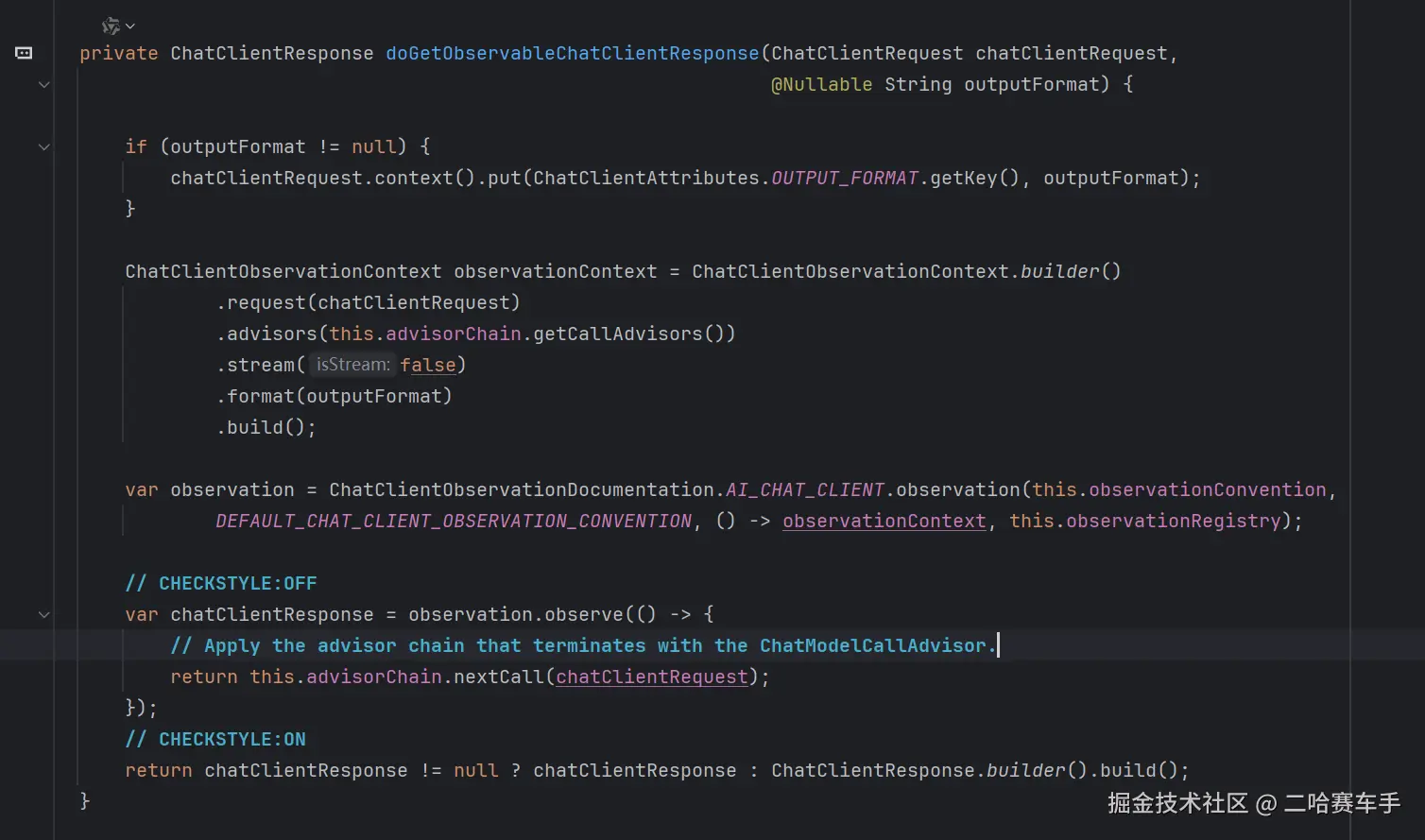
简单来说:
doGetObservableChatClientResponse是启动流水线的"总开关",而adviseCall是流水线上具体的"加工工位"。
以下是详细的代码级关系解析:
核心连接点:nextCall
这两段代码通过 CallAdvisorChain.nextCall() 方法紧密连接在一起。
-
第一段代码 (
doGet...) :- 它是整个流程的入口。
- 它负责设置监控环境(Observation)。
- 关键动作:它调用了
this.advisorChain.nextCall(chatClientRequest)。 - 含义:"准备好环境,然后启动第一个 Advisor。"
-
第二段代码 (
adviseCall) :- 它是
BaseAdvisor的默认实现,代表任意一个中间 Advisor 的行为。 - 关键动作:它内部也调用了
callAdvisorChain.nextCall(processedChatClientRequest)。 - 含义:"我处理完我的逻辑(before),然后交给下一个 Advisor,处理完后我再收尾(after)。"
- 它是
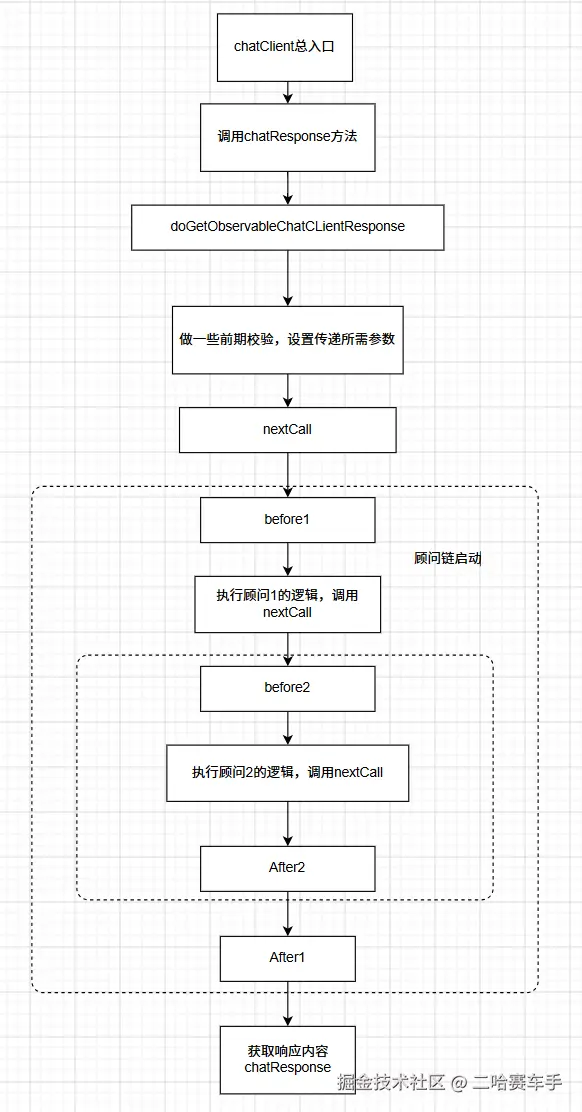
我们顺着这个思路再继续狠狠扒,看看底层到底发生了什么
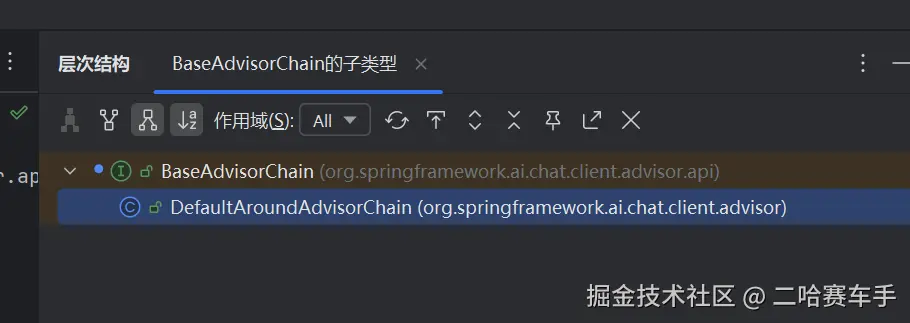
BaseAdvisorChain底有唯一一个实现类DefaultAroundAdvisorChain,所以我们传递的顾问链本质就是传的这个实现类
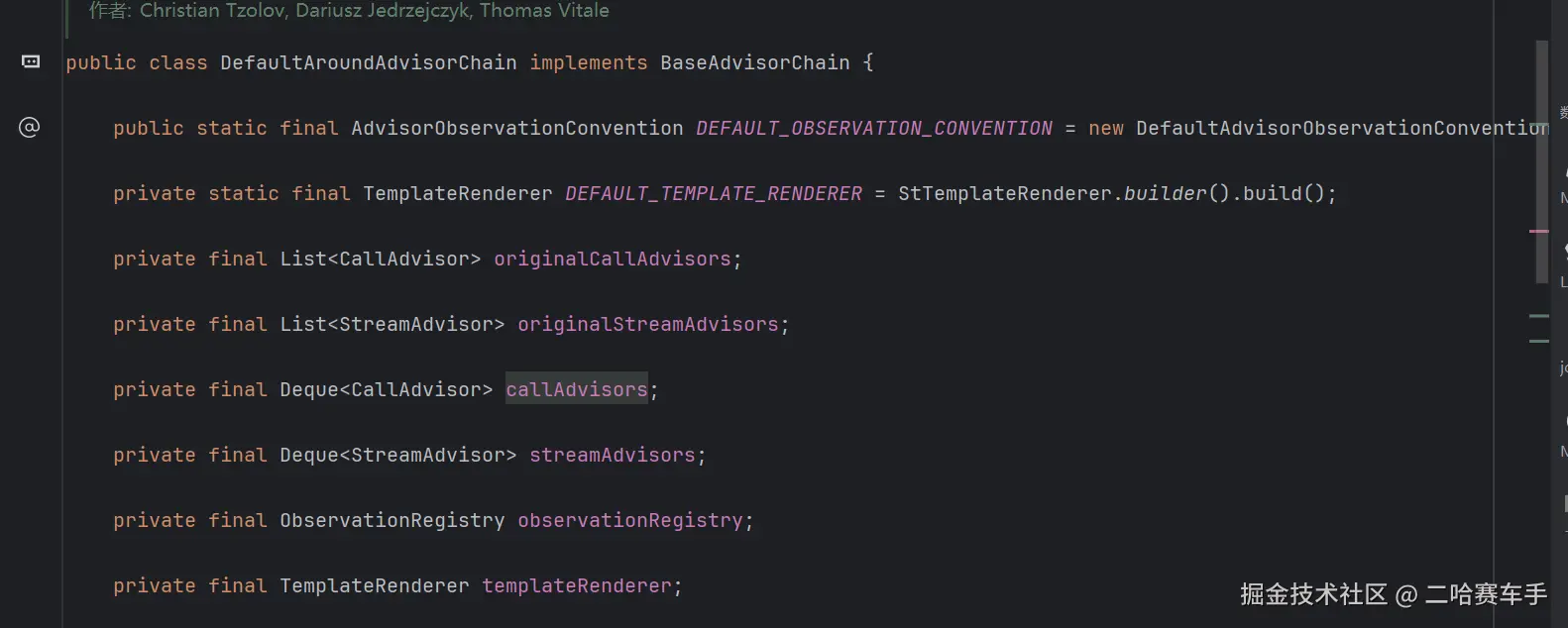
他这里内部的顾问链本质就是一个栈
Deque
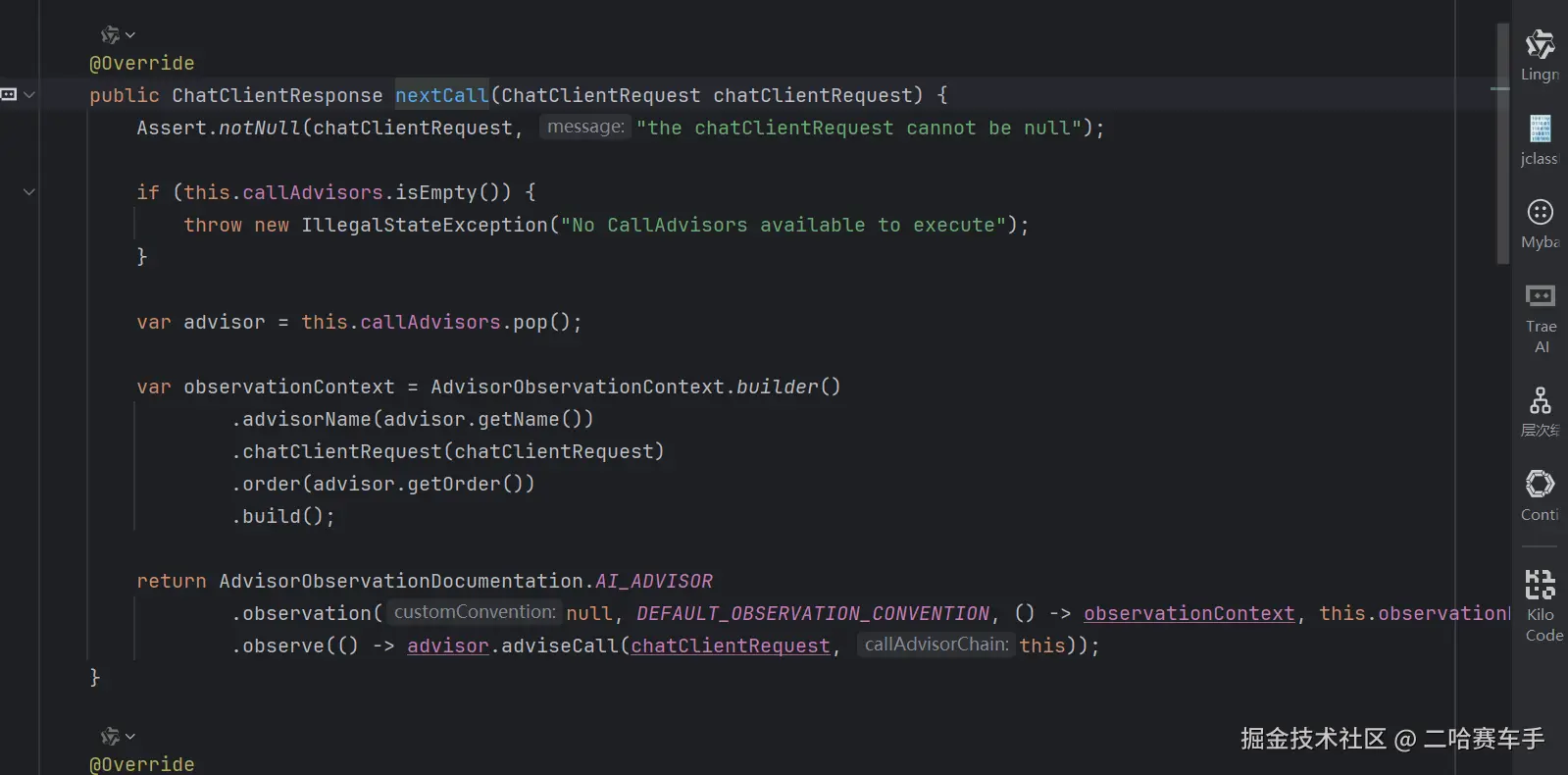
这是他核心的方法
nextCall,也是我们之前一直说的中重要的方法,他就是控制顾问节点到底怎么传递的 它的作用是取出下一个顾问(Advisor)并执行它 。nextCall= 从链中"弹出"下一个 Advisor,并执行它的adviseCall方法
核心点来了
第8行:弹出下一个 Advisor
java
var advisor = this.callAdvisors.pop();| 操作 | 含义 |
|---|---|
.pop() |
从栈顶弹出一个 Advisor(移除并返回) |
关键理解:
- Advisors 是按
getOrder()排序后压入栈的 pop()取出当前应该执行的那个- 取出后链中就少了一个,下次
nextCall会取下一个
java
初始栈(按 order 从小到大排序):
[Logging(100), Memory(200), Safety(300)]
第1次 pop() → Logging(100) 栈变成 [Memory(200), Safety(300)]
第2次 pop() → Memory(200) 栈变成 [Safety(300)]
第3次 pop() → Safety(300) 栈变成 []第10-14行:构建可观测性上下文
java
var observationContext = AdvisorObservationContext.builder()
.advisorName(advisor.getName()) // Advisor 名称
.chatClientRequest(chatClientRequest) // 当前请求
.order(advisor.getOrder()) // 优先级顺序
.build();作用 :为 Micrometer Observation(监控/追踪)准备数据。
| 字段 | 用途 |
|---|---|
advisorName |
日志/监控中显示 "正在执行 MemoryAdvisor" |
chatClientRequest |
记录这个 Advisor 处理时的请求状态 |
order |
记录执行顺序,方便排查问题 |
他底层就是通过将顾问执行链以栈形式构建,启动执行链从栈顶pop()顾问,执行,不断
pop弹出顾问,然后执行该顾问的增强逻辑,再弹出,再执行,直到栈为空,此时顾问链执行完成
4.介绍一下其他的顾问实现类
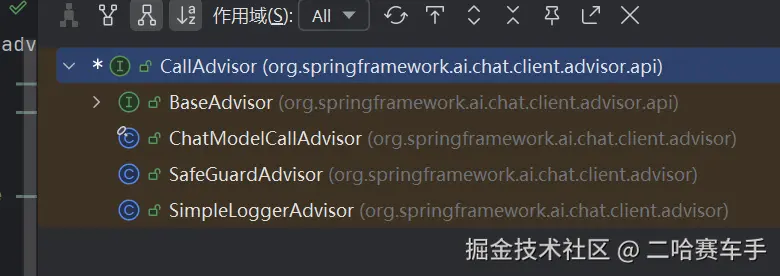
这几个顾问实现类就简单讲解一下,不需要过多关注
1. ChatModelCallAdvisor ------ LLM 调用代理
作用 :链的终点,真正调用大模型生成响应。
java
public class ChatModelCallAdvisor extends BaseAdvisor {
private final ChatModel chatModel;
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// 不调用 chain.next()!直接调 LLM
return this.chatModel.generate(request.getPrompt());
}
}特点:
- 它是 最后一个执行的 Advisor
- 内部不调用
chain.next() - 它的
getOrder()应该是LOWEST_PRECEDENCE(最后执行)
执行位置:
java
LoggingAdvisor (100) → MemoryAdvisor (200) → SafetyAdvisor (300) → ChatModelCallAdvisor (MAX)
↓
调用 LLM.generate()这就解释了之前
nextCall中空栈的问题------不是空栈调 LLM,而是 ChatModelCallAdvisor 作为最后一个节点直接调 LLM!
2. SafeGuardAdvisor ------ 安全防护顾问
作用:过滤敏感内容,防止 AI 生成有害信息。
java
public class SafeGuardAdvisor extends BaseAdvisor {
@Override
protected ChatClientRequest before(ChatClientRequest request) {
// BEFORE: 检查用户输入是否含敏感词
String content = request.getPrompt().getContents();
if (containsSensitiveWords(content)) {
throw new IllegalArgumentException("输入包含敏感内容");
}
return request;
}
@Override
protected ChatClientResponse after(ChatClientResponse response) {
// AFTER: 检查 AI 输出是否含敏感内容
String output = response.getResult().getOutput().getContent();
if (containsSensitiveWords(output)) {
// 替换或拦截
return replaceSensitiveContent(response);
}
return response;
}
}使用场景:
- 内容审核
- 敏感词过滤
- 合规检查
3. SimpleLoggerAdvisor ------ 简单日志记录
作用:记录请求和响应,方便调试和监控。
java
public class SimpleLoggerAdvisor extends BaseAdvisor {
private static final Logger logger = LoggerFactory.getLogger(SimpleLoggerAdvisor.class);
@Override
protected ChatClientRequest before(ChatClientRequest request) {
logger.info("【Request】Prompt: {}", request.getPrompt().getContents());
logger.info("【Request】Model: {}", request.getModel());
logger.info("【Request】Temperature: {}", request.getTemperature());
return request;
}
@Override
protected ChatClientResponse after(ChatClientResponse response) {
logger.info("【Response】Content: {}", response.getResult().getOutput().getContent());
logger.info("【Response】Tokens: {}", response.getResult().getMetadata().getUsage());
return response;
}
}输出示例:
java
[SimpleLoggerAdvisor] 【Request】Prompt: 你好,请介绍一下Spring AI
[SimpleLoggerAdvisor] 【Request】Model: gpt-4
[SimpleLoggerAdvisor] 【Request】Temperature: 0.7
...
[SimpleLoggerAdvisor] 【Response】Content: Spring AI 是一个用于简化...
[SimpleLoggerAdvisor] 【Response】Tokens: prompt=15, completion=128, total=143怎么添加
方式1:全局默认(推荐)
java
@Bean
public ChatClient chatClient(ChatClient.Builder builder, ChatModel chatModel) {
return builder
.defaultAdvisors(
new SimpleLoggerAdvisor(100), // 手动加日志
new SafeGuardAdvisor(200), // 手动加安全
new MessageChatMemoryAdvisor(chatMemory) // 手动加记忆
)
.build();
}方式2:单次调用添加
java
chatClient.prompt("你好")
.advisors(
new SimpleLoggerAdvisor(100), // 这次调用才加
new SafeGuardAdvisor(200)
)
.call();5.怎么手动实现自定义顾问
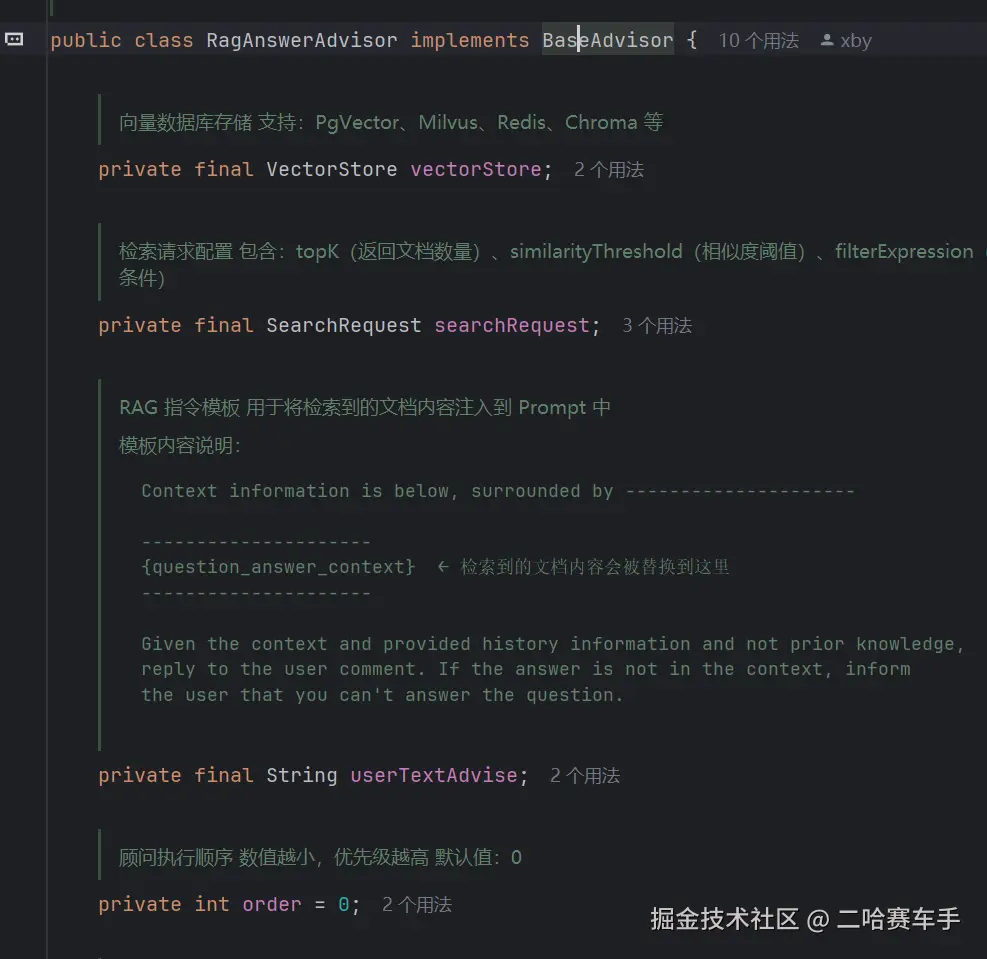
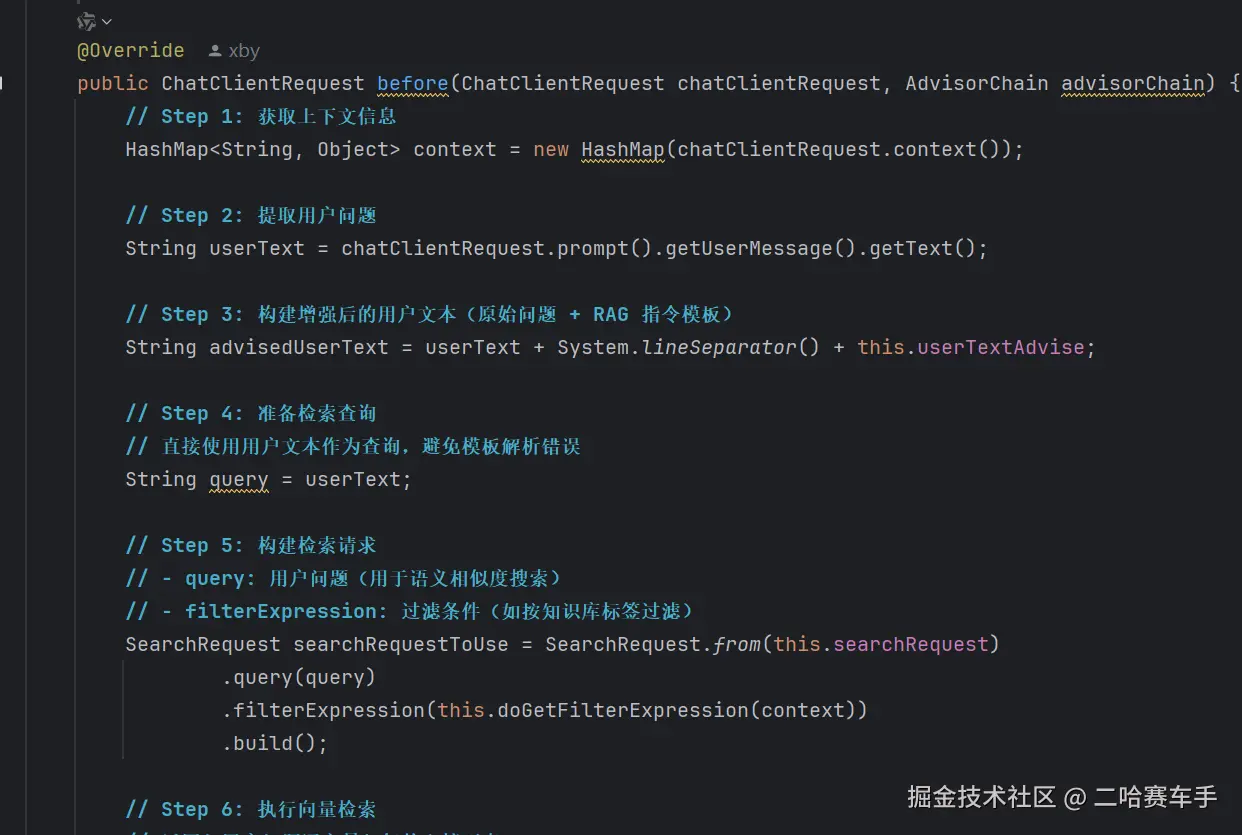
我们继承
BaseAdvisor接口即可,然后重写他内部的方法
三:博主自己的疑问点
(1)
这里博主有个问题是:我们chatClient说到底就是通过执行顾问链的方式,来层层传递数据,执行增强后的逻辑,最后返回AI的响应结果ChatResponse,但是博主当前项目只是搭建了一个顾问,顾问里也没涉及AI调用内容,那么我们为什么执行完顾问链就获取到了AI执行结果了,哪一步触发了AI调用
这里就引入了另一个顾问ChatModelAdvisor
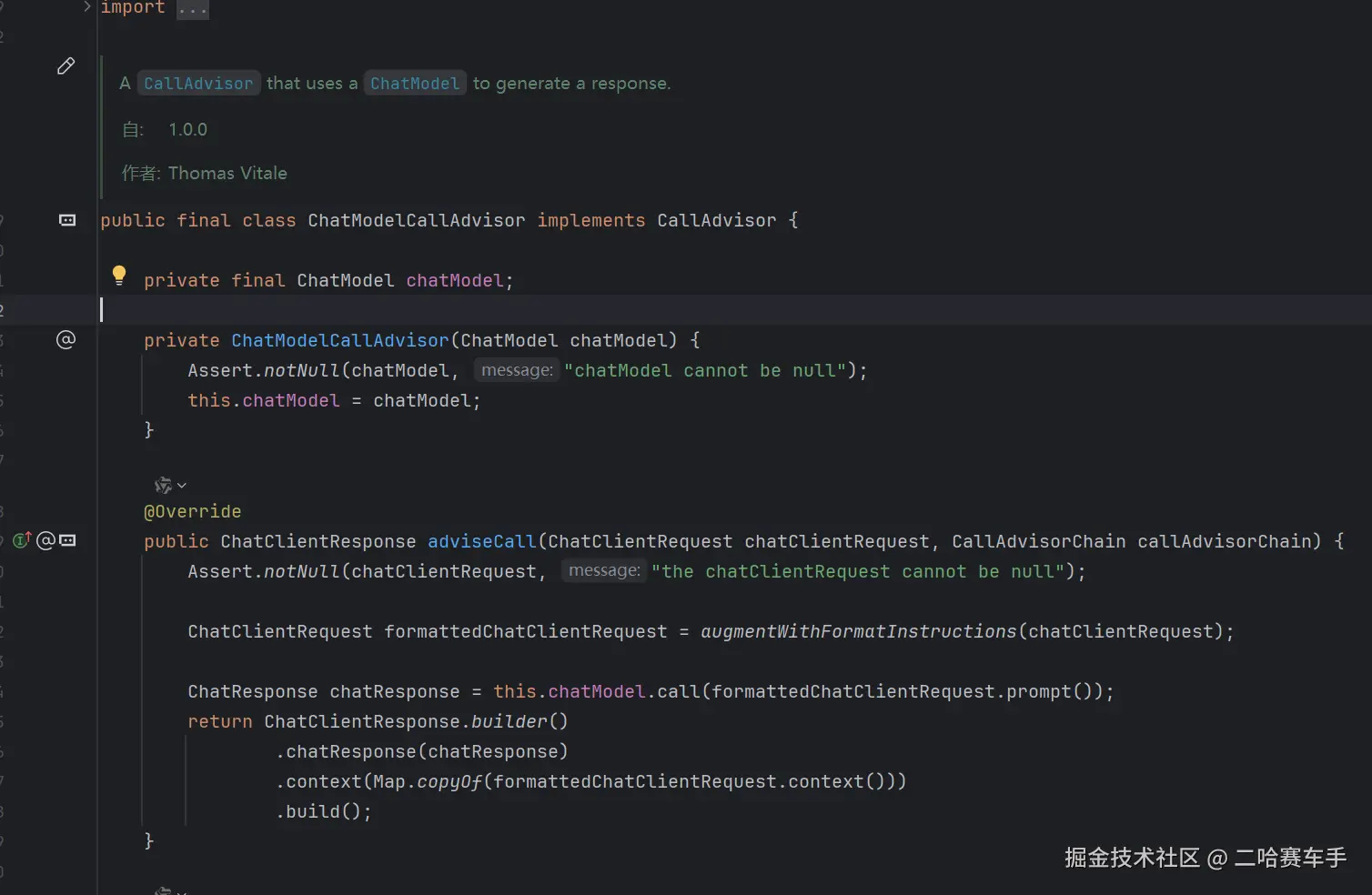
他也是
callAdvisor/StreamAdvisor接口的实现类,有没有发现他已经重写好了adviseCall方法,内部你可以看见他就是自动获取到我们的参数信息,然后底层调用chatModel.call()方法,去实际调用AI的执行,并获取到响应结果chatClientResponse
- 你负责:配置"花里胡哨"的顾问功能(记忆、RAG、日志、鉴权)。
- 框架负责 :自动在顾问链条的最后一位 安插
ChatModelCallAdvisor,确保请求最终能发出去,并且能拿到 AI 的回复。
这一切都是SPring AI框架给你做好的了,这也太贴心了
(2)
我们的顾问链本质就是栈,那么我们设置的顾问的order属性哪里用到了
核心关系
java
getOrder() 返回值 → 排序 → 压入栈 → pop() 弹出顺序 → 实际执行顺序表格
getOrder() |
数值特点 | 在栈中的位置 | 执行时机 |
|---|---|---|---|
| 越小(如 100) | 优先级高 | 栈底(后压入) | 先执行(先 pop) |
| 越大(如 300) | 优先级低 | 栈顶(先压入) | 后执行(后 pop) |
这一点博主没有继续扒源码,扒不动了,但是博主推测,Spring AI应该是通过我们的order值,去手动控制我们栈的顺序,让他符合
数值越小越先执行的规律
四:ChatMemoryAdvisor
一、ChatMemoryAdvisor 是什么
官方内置 Advisor ,专门处理对话历史记忆。
核心功能
| 功能 | 说明 |
|---|---|
| 加载历史 | 从 ChatMemory 中读取之前的对话 |
| 拼接 Prompt | 把历史消息 + 当前消息合并成完整 Prompt |
| 保存对话 | 把本轮对话(用户输入 + AI 回复)存回 ChatMemory |
代码示意
java
public class MessageChatMemoryAdvisor extends BaseAdvisor {
private final ChatMemory chatMemory;
private final String conversationId; // 区分不同用户的对话
@Override
protected ChatClientRequest before(ChatClientRequest request) {
// 1. 加载历史(Before)
List<Message> history = chatMemory.get(conversationId, 10); // 最近10条
// 2. 拼接到当前请求
List<Message> messages = new ArrayList<>();
messages.addAll(history); // 历史
messages.add(request.getUserMessage()); // 当前
return request.withPrompt(new Prompt(messages));
}
@Override
protected ChatClientResponse after(ChatClientResponse response) {
// 3. 保存本轮对话(After)
chatMemory.add(conversationId, request.getUserMessage());
chatMemory.add(conversationId, response.getAssistantMessage());
return response;
}
}二、与自定义 Advisor 的对比
| 维度 | ChatMemoryAdvisor(内置) |
自定义 Advisor |
|---|---|---|
| 来源 | Spring AI 官方提供 | 你自己写 |
| 功能 | 专门处理对话记忆 | 任意功能(日志、安全、限流...) |
| 实现方式 | 继承 BaseAdvisor,重写 before/after |
同样继承 BaseAdvisor,重写 before/after |
是否需要 ChatMemory Bean |
✅ 需要 | 看需求,不需要 |
| 复杂度 | 中等(要管理历史消息) | 简单到复杂都可以 |
三、和自定义顾问的本质区别:没有本质区别!
ChatMemoryAdvisor 就是一个"官方写的自定义 Advisor"
它的结构和你的自定义 Advisor 完全一样:
java
// 官方写的
public class MessageChatMemoryAdvisor extends BaseAdvisor {
@Override
protected ChatClientRequest before(ChatClientRequest request) { ... }
@Override
protected ChatClientResponse after(ChatClientResponse response) { ... }
}
// 你写的
public class MyLoggerAdvisor extends BaseAdvisor {
@Override
protected ChatClientRequest before(ChatClientRequest request) { ... }
@Override
protected ChatClientResponse after(ChatClientResponse response) { ... }
}唯一区别:官方已经帮你写好了,你不用重复造轮子。
四、ChatMemoryAdvisor 的特殊之处
1. 它依赖 ChatMemory 接口
java
public interface ChatMemory {
void add(String conversationId, Message message);
List<Message> get(String conversationId, int lastN);
void clear(String conversationId);
}| 实现类 | 存储位置 | 特点 |
|---|---|---|
InMemoryChatMemory |
JVM 内存 | 简单、重启丢失 |
CassandraChatMemory |
Cassandra | 分布式持久化 |
JdbcChatMemory |
关系型数据库 | 已有数据库基础设施 |
Neo4jChatMemory |
Neo4j 图数据库 | 图结构分析 |
2. 它需要 conversationId 区分不同对话
java
// 每次调用要指定对话ID
chatClient.prompt()
.advisors(a -> a.param("conversation_id", "user_123")) // 区分用户
.call();五:具体内部构造
先看一下构造
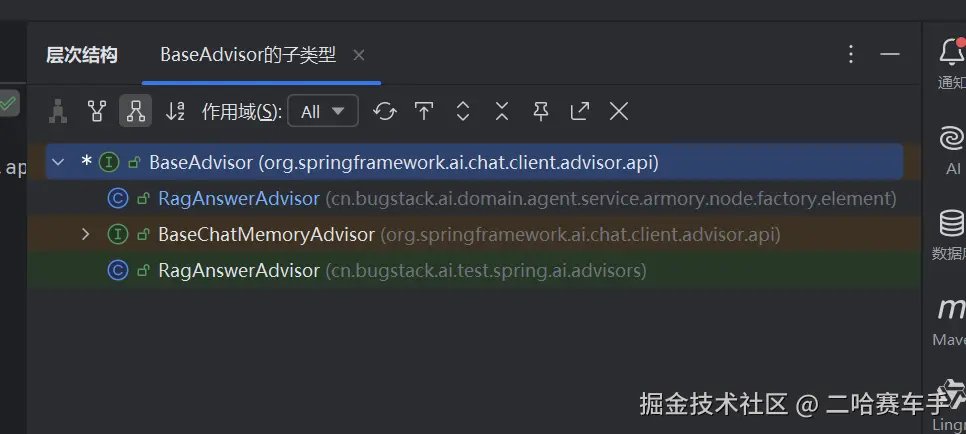
这里可以看见我们上面介绍的
BaseAdvisor内部还有一个接口,即BaseChatMemoryAdvisor,
java
default String getConversationId(Map<String, Object> context, String defaultConversationId)| 参数 | 类型 | 含义 |
|---|---|---|
context |
Map<String, Object> |
上下文数据,可能包含 conversation_id |
defaultConversationId |
String |
默认对话ID,当 context 中没有时用这个 |
返回值 :最终使用的 conversationId(String)
逐行拆解
java
Assert.notNull(context, "context cannot be null");作用 :如果 context 是 null,抛 IllegalArgumentException
java
Assert.noNullElements(context.keySet().toArray(), "context cannot contain null keys");作用 :遍历 context 的所有 key,如果有 null key,抛异常
防御性编程,防止
Map中有null作为 key(虽然HashMap允许 null key,但这里不允许)
java
Assert.hasText(defaultConversationId, "defaultConversationId cannot be null or empty");作用 :defaultConversationId 必须有实际内容(不能是 null、""、" ")
java
return context.containsKey(ChatMemory.CONVERSATION_ID)
? context.get(ChatMemory.CONVERSATION_ID).toString() // 有就用 context 里的
: defaultConversationId; // 没有就用默认值整体逻辑流程图
java
传入参数:
context = {"conversation_id": "user_123", ...}
defaultConversationId = "default_session"
检查:
context.containsKey("conversation_id") ?
├── true → 返回 "user_123"(context里的)
└── false → 返回 "default_session"(默认值)使用场景:多用户对话(需要区分用户)
java
// 用户A的请求
Map<String, Object> context = new HashMap<>();
context.put(ChatMemory.CONVERSATION_ID, "user_A_001");
String convId = advisor.getConversationId(context, "default");
// 结果: "user_A_001" ← 用 context 里的,A和B的记忆隔离
// 用户B的请求
context.put(ChatMemory.CONVERSATION_ID, "user_B_002");
String convId2 = advisor.getConversationId(context, "default");
// 结果: "user_B_002"作用:不同用户的对话历史互不干扰
这里总结一下,这个
Map集合很重要,我们不同的顾问都可以享有这个共享的MAP,每个顾问可以从MAP集合中获取到自己当前所需要的数据,比如我们上面的例子,他就是通过在Map中存放当前记忆顾问所需要的conversation_id,原因是不同用户的记忆是必须要隔离开的,通过将这个标识存入共享Map中,传递给顾问链,记忆顾问就能自动检索当前Map中是否有conversation_id,取出该值,从而找出该表示下用户的记忆。关于这个Map后面会讲解
下面我们简单讲解一下BaseChatMemoryAdvisor的实现类
这一块博主扒不动了,太累了,直接展示AI解释吧,各位大佬有兴趣可以自己去手动翻阅一下源码
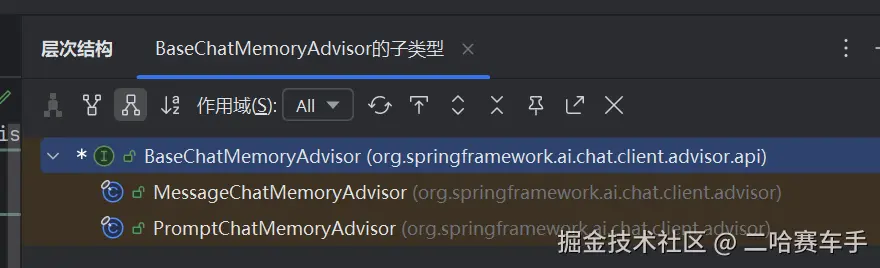
一、核心区别:存储和拼接的粒度不同
表格
| 维度 | MessageChatMemoryAdvisor |
PromptChatMemoryAdvisor |
|---|---|---|
| 存储单位 | Message 对象(结构化) |
Prompt 对象(整体模板) |
| 记忆内容 | 单条消息(用户/AI各一条) | 整个 Prompt(包含系统提示+历史+当前) |
| 灵活性 | 高(可精确控制每条消息) | 低(整体替换) |
| 适用场景 | 通用对话、多轮聊天 | 复杂模板、固定格式的 Prompt |
二、MessageChatMemoryAdvisor ------ 基于消息的记忆
工作原理
java
public class MessageChatMemoryAdvisor extends BaseChatMemoryAdvisor {
@Override
protected ChatClientRequest before(ChatClientRequest request) {
// 1. 从内存读取历史消息(List<Message>)
List<Message> history = chatMemory.get(conversationId, lastN);
// 2. 构建新消息列表:系统提示 + 历史 + 当前消息
List<Message> messages = new ArrayList<>();
messages.add(new SystemMessage("你是一个助手")); // 系统提示
messages.addAll(history); // 历史对话
messages.add(request.getUserMessage()); // 当前用户消息
// 3. 用消息列表创建 Prompt
return request.withPrompt(new Prompt(messages));
}
@Override
protected ChatClientResponse after(ChatClientResponse response) {
// 保存本轮对话(两条消息)
chatMemory.add(conversationId, response.getUserMessage()); // 用户消息
chatMemory.add(conversationId, response.getAssistantMessage()); // AI回复
return response;
}
}存储结构
java
ChatMemory 中存储:
├── [0] UserMessage: "你好"
├── [1] AssistantMessage: "你好!有什么可以帮你的?"
├── [2] UserMessage: "我叫张三"
├── [3] AssistantMessage: "你好张三!"
└── ...特点
- 结构化:每条消息有明确角色(User/Assistant/System)
- 可精确控制:可以只取最近 N 条,或过滤特定类型
- 通用性强:适用于大多数对话场景
三、PromptChatMemoryAdvisor ------ 基于 Prompt 的记忆
工作原理
java
public class PromptChatMemoryAdvisor extends BaseChatMemoryAdvisor {
@Override
protected ChatClientRequest before(ChatClientRequest request) {
// 1. 从内存读取历史 Prompt(整个 Prompt 对象)
List<Prompt> historyPrompts = chatMemory.get(conversationId, lastN);
// 2. 构建新 Prompt:历史 Prompt + 当前 Prompt
// 或者直接把历史 Prompt 的 messages 提取出来拼接
Prompt currentPrompt = request.getPrompt();
// 合并所有 messages
List<Message> allMessages = new ArrayList<>();
for (Prompt histPrompt : historyPrompts) {
allMessages.addAll(histPrompt.getInstructions()); // 提取历史消息
}
allMessages.addAll(currentPrompt.getInstructions()); // 当前消息
return request.withPrompt(new Prompt(allMessages));
}
@Override
protected ChatClientResponse after(ChatClientResponse response) {
// 保存整个 Prompt(包含系统提示+历史+当前)
Prompt fullPrompt = buildFullPrompt(response);
chatMemory.add(conversationId, fullPrompt); // 存的是 Prompt 对象!
return response;
}
}存储结构
java
ChatMemory 中存储:
├── [0] Prompt: {system="你是助手", messages=[User:"你好", Assistant:"你好!"]}
├── [1] Prompt: {system="你是助手", messages=[User:"我叫张三", Assistant:"你好张三!"]}
└── ...特点
- 整体存储:保留完整的 Prompt 模板(含系统提示、参数等)
- 适合复杂场景:如需要保留每次调用的完整上下文(包括温度、模型参数等)
- 占用空间大:存储的是整个 Prompt 对象,不是单条消息
四、对比总结
| 场景 | 推荐选择 |
|---|---|
| 普通多轮对话 | MessageChatMemoryAdvisor |
| 需要精确控制单条消息 | MessageChatMemoryAdvisor |
| 复杂 Prompt 模板(含系统提示、变量) | PromptChatMemoryAdvisor |
| 需要保留每次调用的完整参数 | PromptChatMemoryAdvisor |
| 内存敏感(存储空间小) | MessageChatMemoryAdvisor |
五、使用方式
java
@Bean
public ChatClient chatClient(ChatClient.Builder builder, ChatMemory chatMemory) {
return builder
.defaultAdvisors(
// 方式1:基于消息(常用)
new MessageChatMemoryAdvisor(chatMemory),
// 方式2:基于 Prompt(特殊场景)
// new PromptChatMemoryAdvisor(chatMemory)
)
.build();
}六、快速记忆
java
MessageChatMemoryAdvisor = "记聊天记录"(一条一条记)
PromptChatMemoryAdvisor = "记整篇作文"(一整篇一整篇记)
大多数情况用 MessageChatMemoryAdvisor 就够了,
只有需要保留完整 Prompt 模板时才用 PromptChatMemoryAdvisor。我们的这些顾问都是已经被Spring AI封装好了,可以直接使用,下面博主展示一下我们项目里怎么用
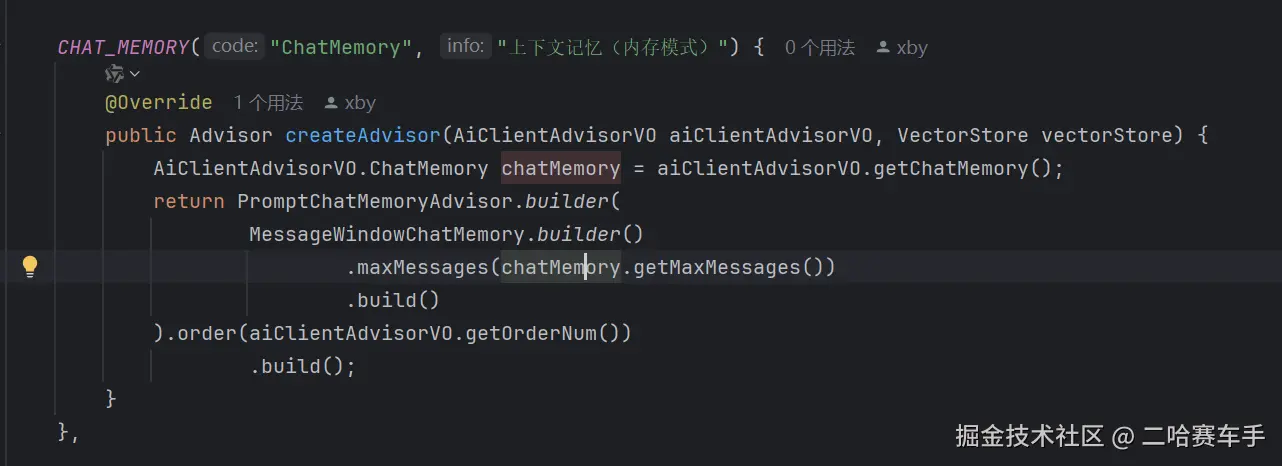
五:顾问的Map容器
(1)顾问容器讲解
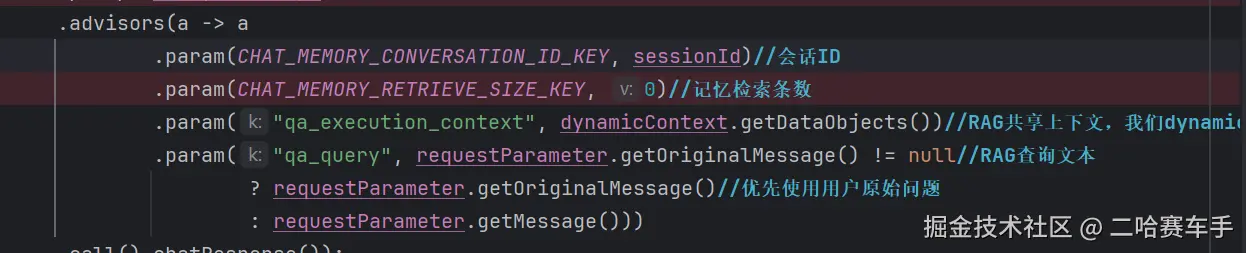
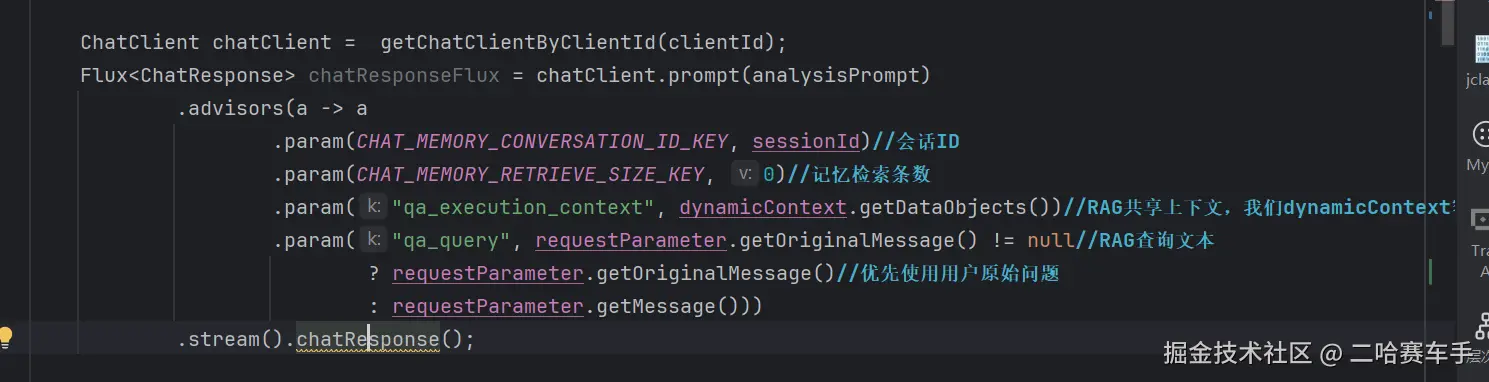
还是举我们项目中的例子,我们为顾问设置了多个param值
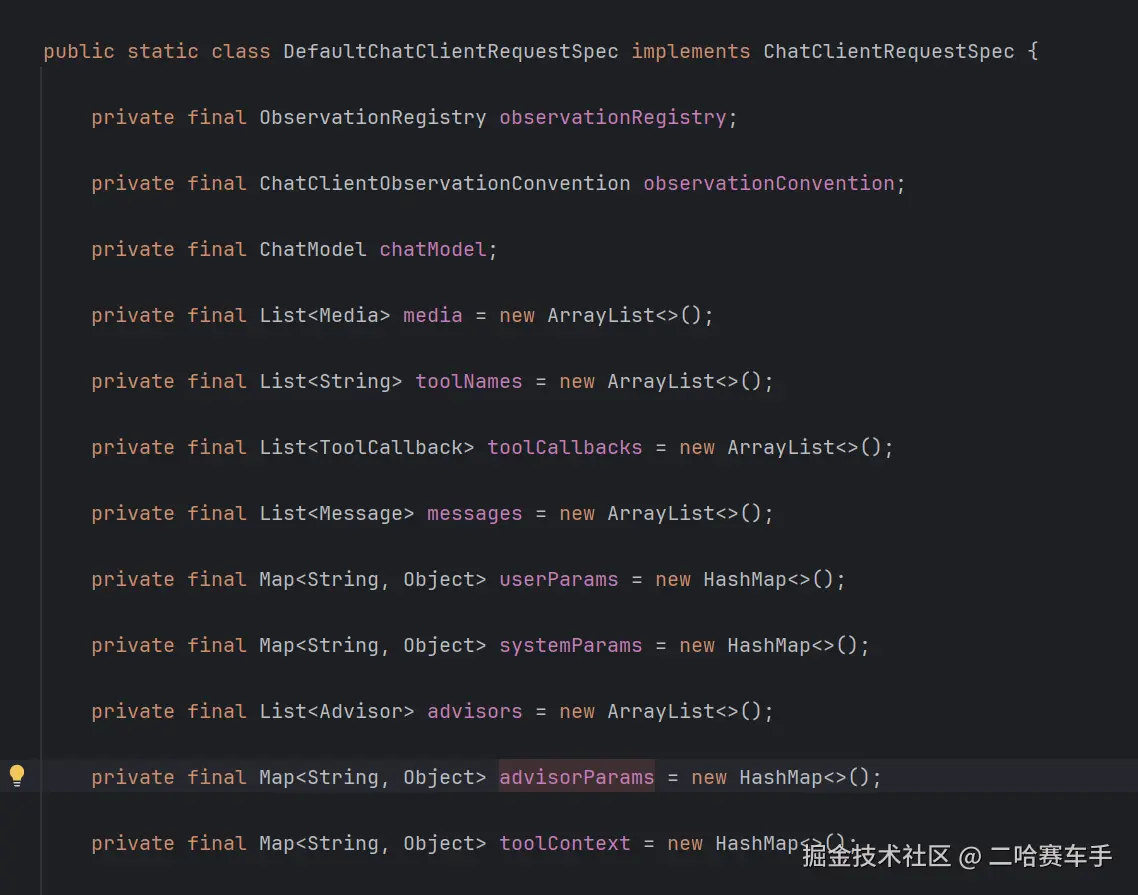
最终advisor的param存入当前图片该类的advisorParams参数中(不再赘述存如过程,前面有笔记)

这里的核心是
toChatCLientRequest方法,他就是将我们的DefaultChatClientRequestSpec中的所有参数封装成ChatClientRequest对象,下面来看一下具体内部是啥样的
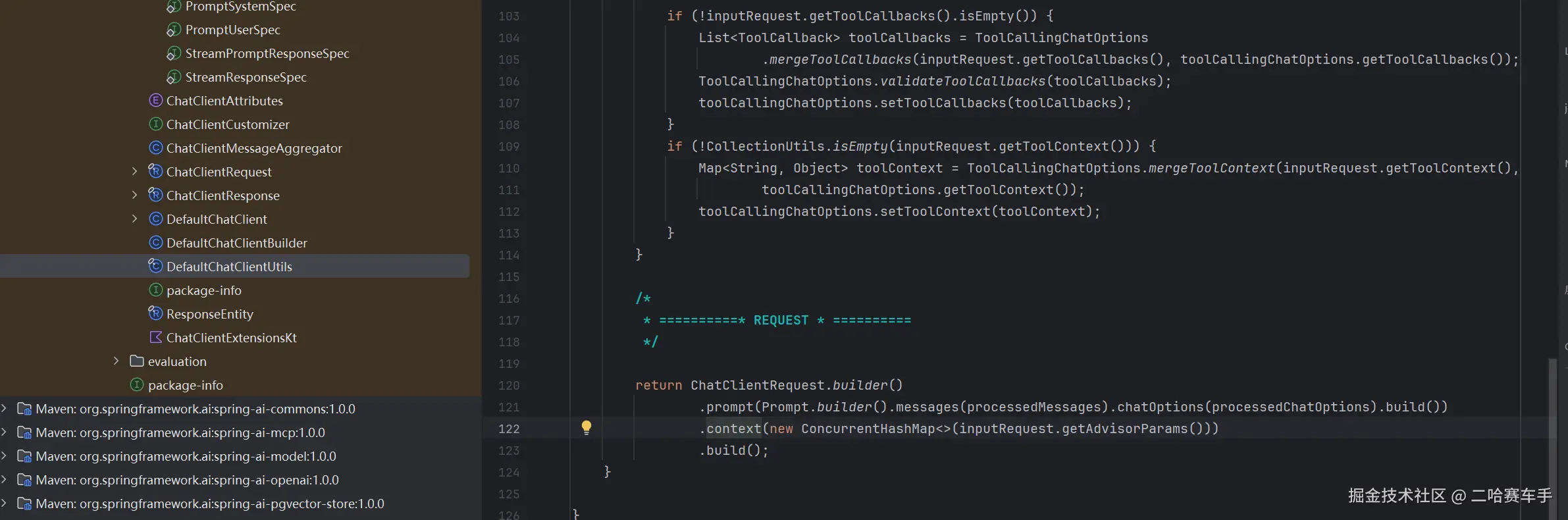
看代码最后面,
DefaultChatClientUtils将变量advisorParams封装为一个context变量中,并返回一个chatClient
java
/**
* Represents a request processed by a {@link ChatClient} that ultimately is used to build
* a {@link Prompt} to be sent to an AI model.
*
* @param prompt The prompt to be sent to the AI model
* @param context The contextual data through the execution chain
* @author Thomas Vitale
* @since 1.0.0
*/
public record ChatClientRequest(Prompt prompt, Map<String, Object> context) {
public ChatClientRequest {
Assert.notNull(prompt, "prompt cannot be null");
Assert.notNull(context, "context cannot be null");
Assert.noNullElements(context.keySet(), "context keys cannot be null");
}
public ChatClientRequest copy() {
return new ChatClientRequest(this.prompt.copy(), new HashMap<>(this.context));
}
public Builder mutate() {
return new Builder().prompt(this.prompt.copy()).context(new HashMap<>(this.context));
}
public static Builder builder() {
return new Builder();
}
public static final class Builder {
private Prompt prompt;
private Map<String, Object> context = new HashMap<>();
private Builder() {
}这段是chatCLient的部分源码,可知它内部有变量Prompt和context(Map类型),通过看开发师的注释,可知prompt = 最终发给 AI 的内容 ,context = 执行过程中内部用的临时数据(不发给 AI) ,
可以确定我们给AI设置的advisor的param参数全部被放进这个context中了,传递给整个顾问链使用
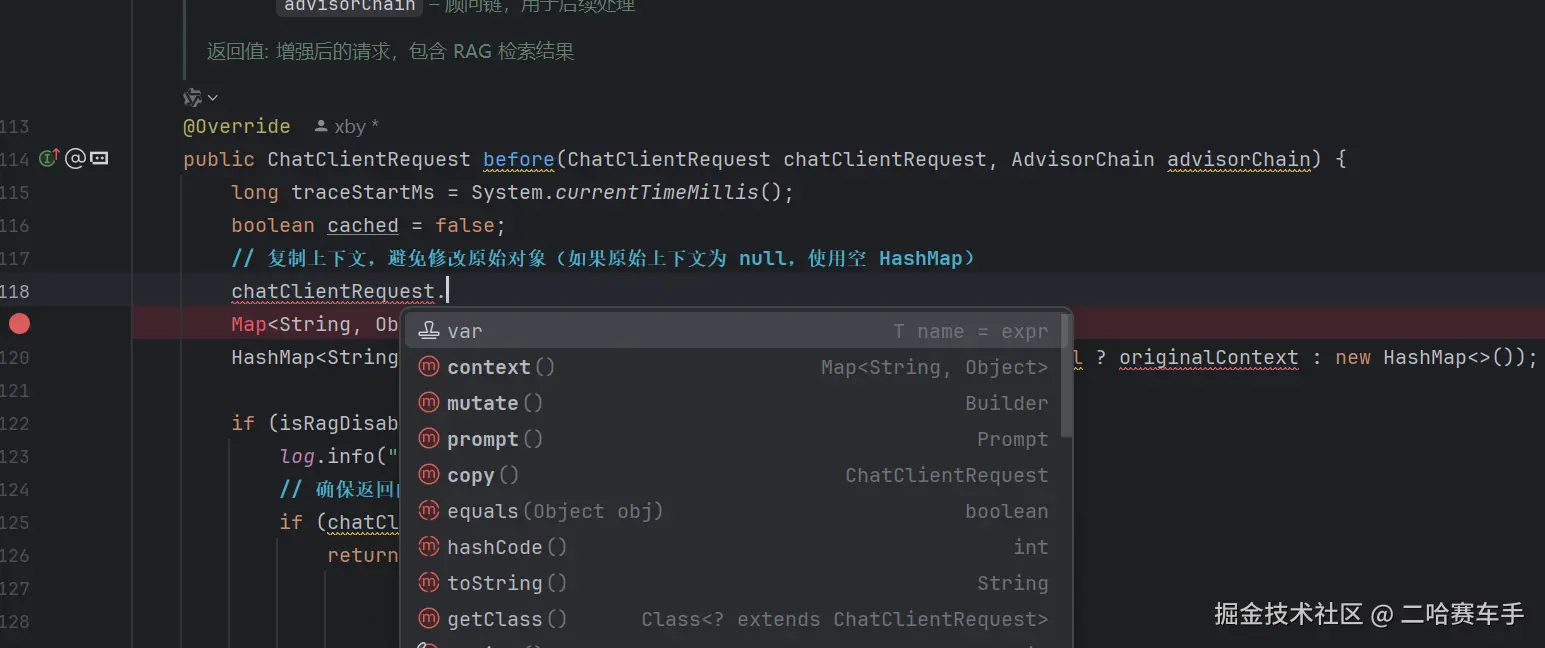
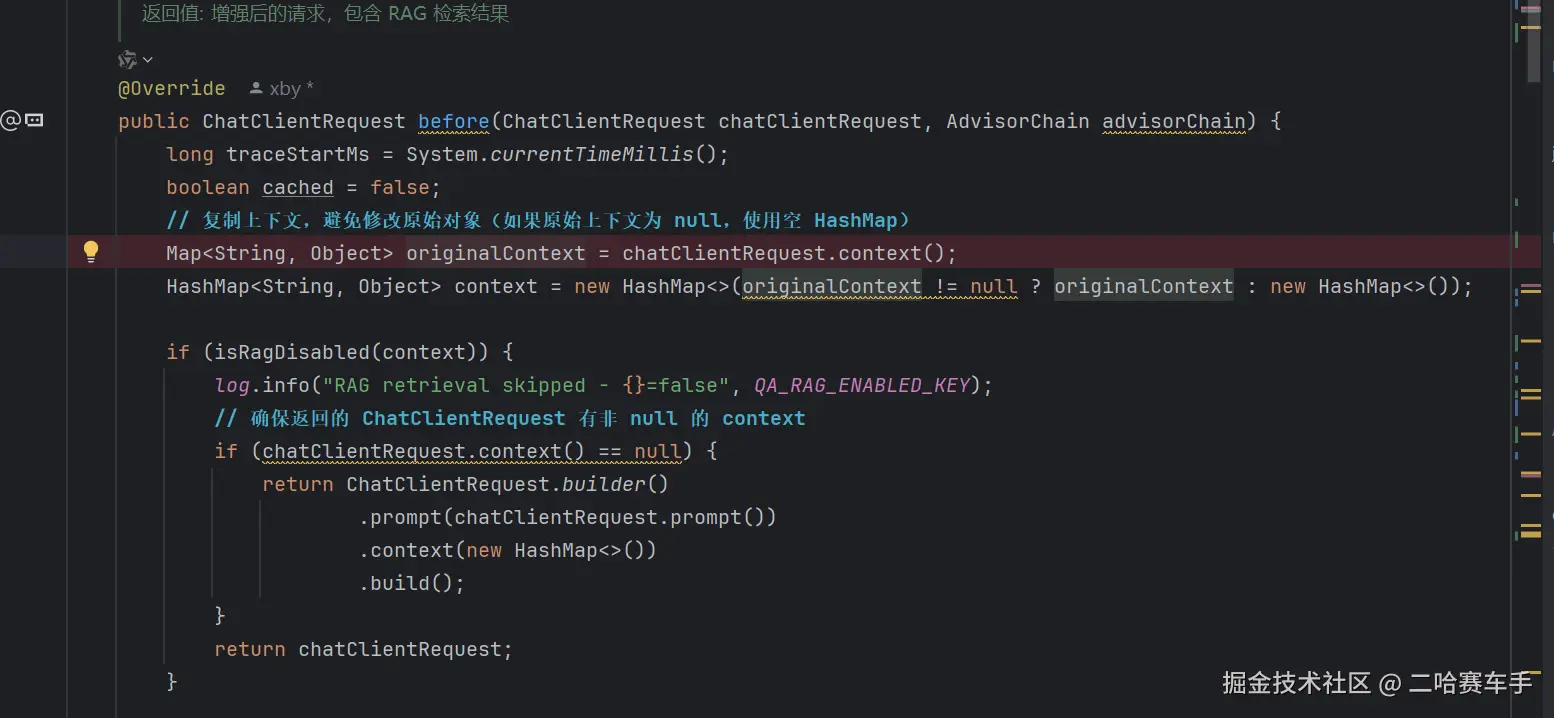
后续我们在使用自定义顾问时,只需要通过获取到chatClientRequest对象,通过
context()方法就可以获取到共享容器Map了,可以获取到内部的数据
(2)项目中的使用技巧
项目背景:我们是一个多智能体项目,具体其中一个架构是client1->client2->client3,client1负责分析,client2负责根据分析结果执行,client3负责监督执行情况,我们是都给他们配备了顾问,同时自定义了一个
RAGAnswerAdvisor顾问,该顾问会在调用AI前执行我们的顾问,会进行RAG检索,bm25评分等等一堆逻辑
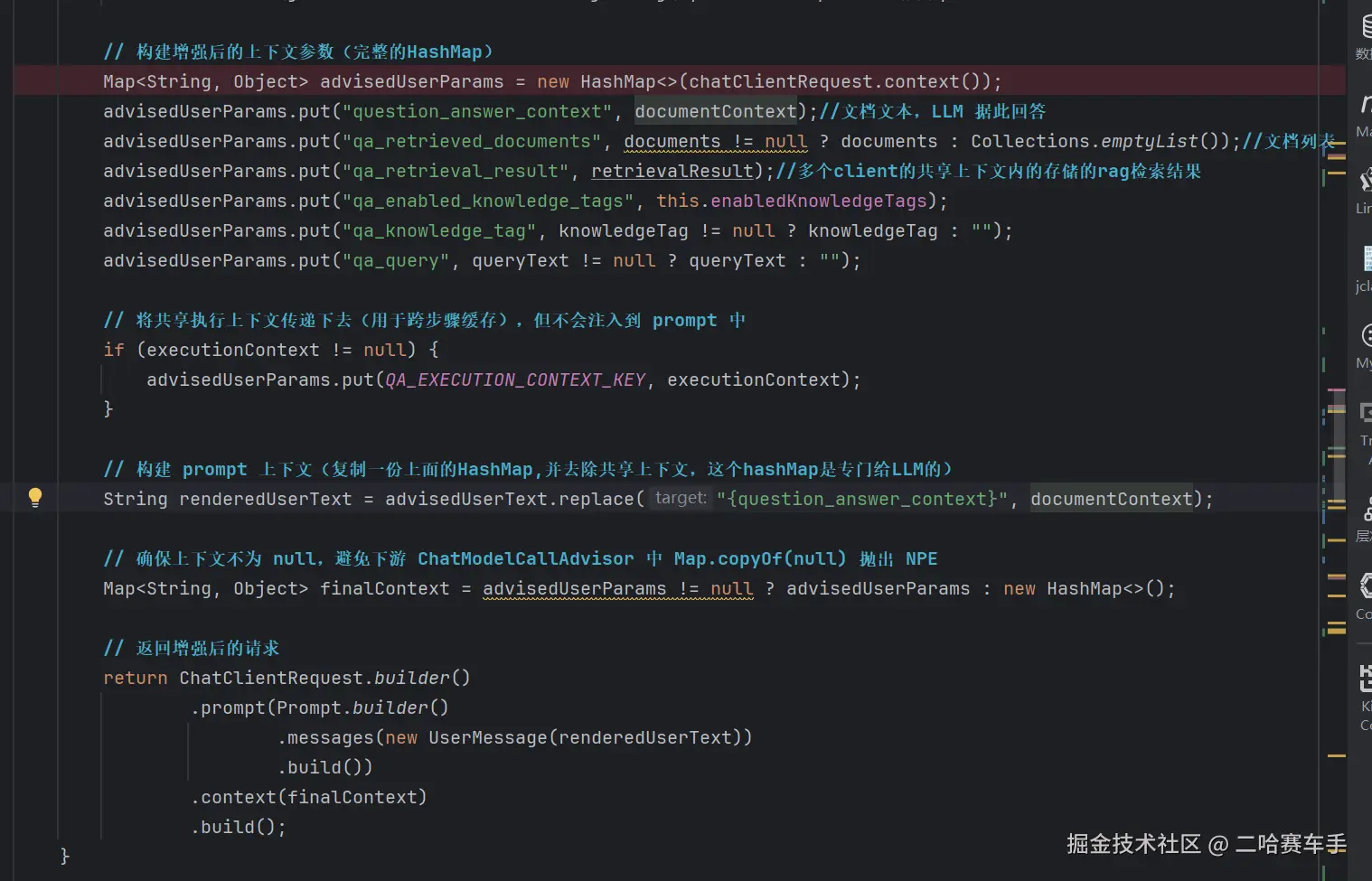
可以看见我们是将RAG检索结果
documentContext,拼装到chatReuest的prompt变量中,当作提示词返回给AI
问题1
我们每个client的顾问都是单独设置的,走的都是
RAGAnwserAdvisor自定义顾问,这就会引发一个问题,就是MAP容器不互通,client1执行完后,client的顾问就结束了,Map容器不会再传到client2.这就会引发一个问题,我们client2的顾问调用时还会触发顾问的完整的RAG检索流程(因为走到都是同一个顾问),过于影响性能,因为用户问题是一样的,检索结果不会有太大区别,反而每次触发检索很影响性能
解决办法:
在第一次进行RAG检索时,外界传入一个共享容器的引用
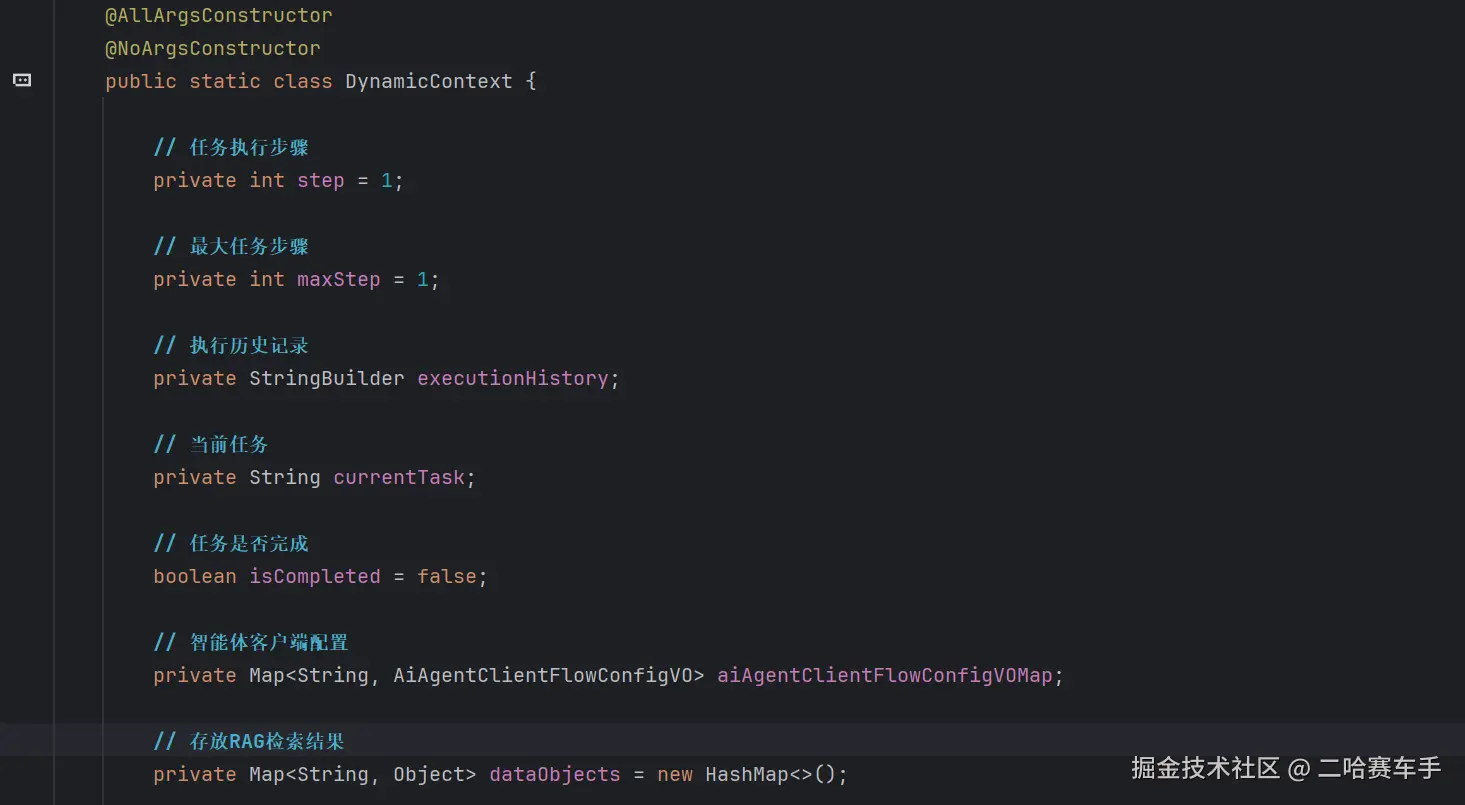
我们设置了一个对象,专门用来管理多个client间的共享数据,这里注意我们设定了一个MAP集合,用于存放我们的RAG检索结果
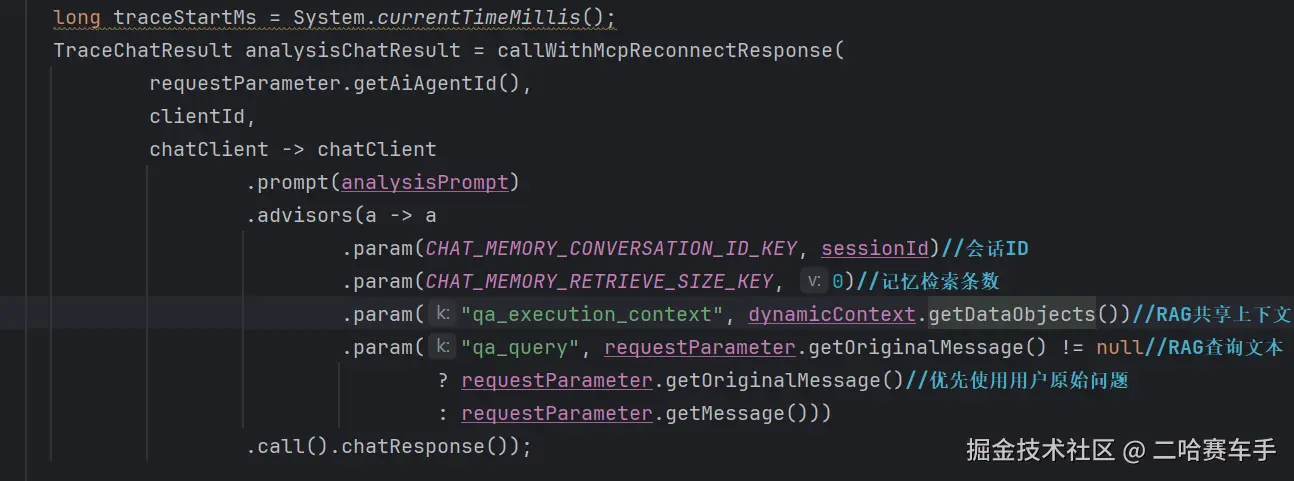
我们client1调用advisor时,调用
getDataObjects方法,获取到一个空的hashMap,传递给client1的顾问的共享容器,并设置键qa_execution_context
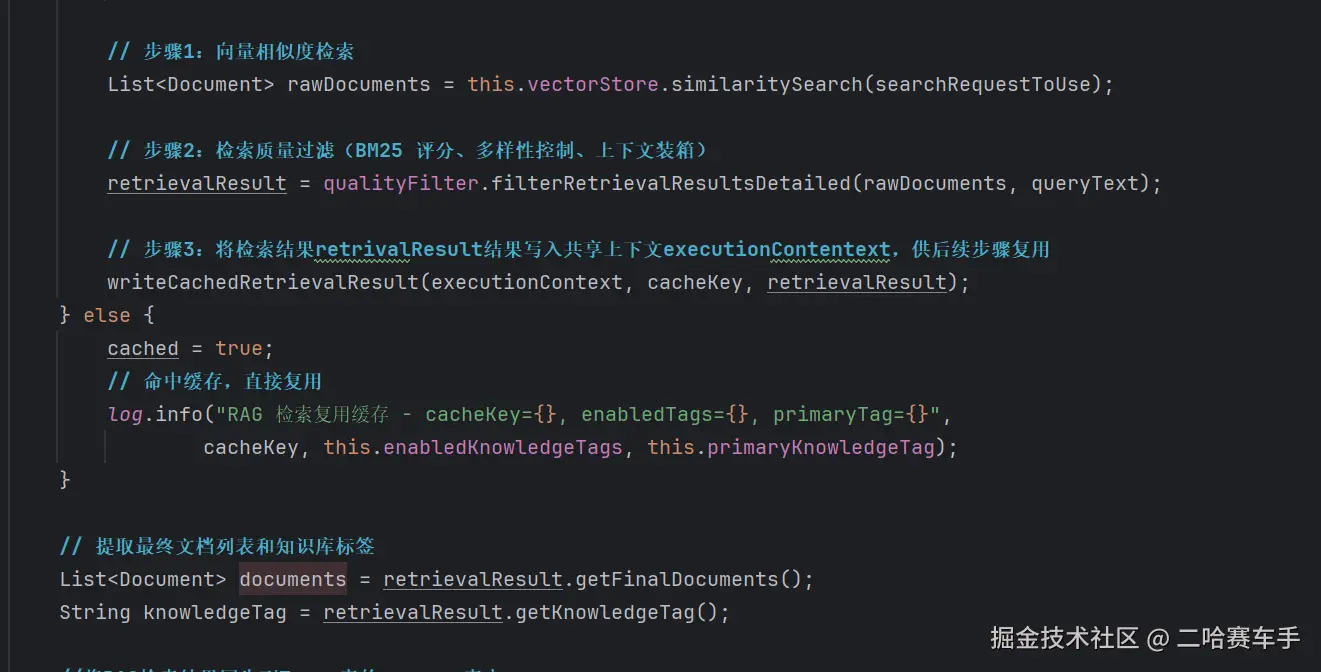
client1执行顾问,先获取到我们的RAG检索结果并规范化操作,注意我们这里调用了一个
writeCacheRetriecalResult方法
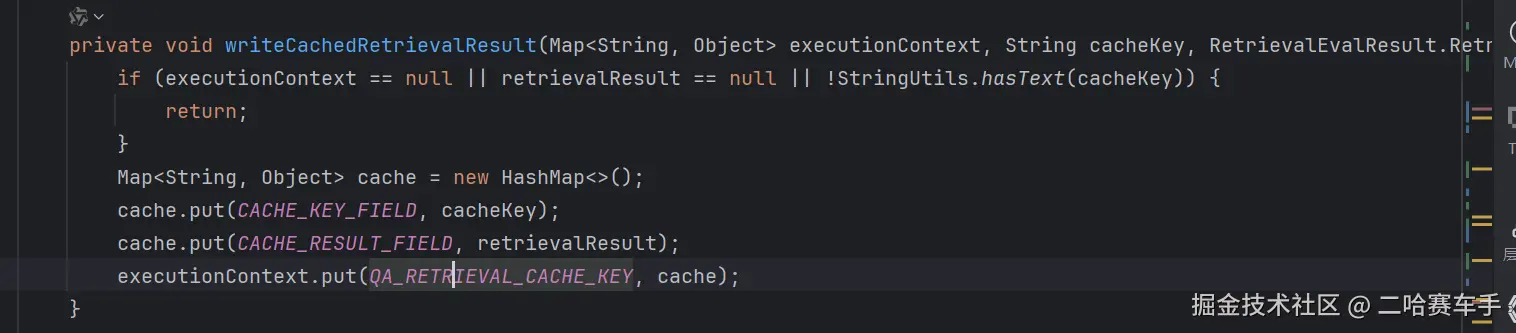
我们将RAG检索结果保存在这个我们传递的HashMap中,而不再存入顾问的共享容器中(因为client1执行完后,client1的顾问链就会结束,共享容器也就不存在了)
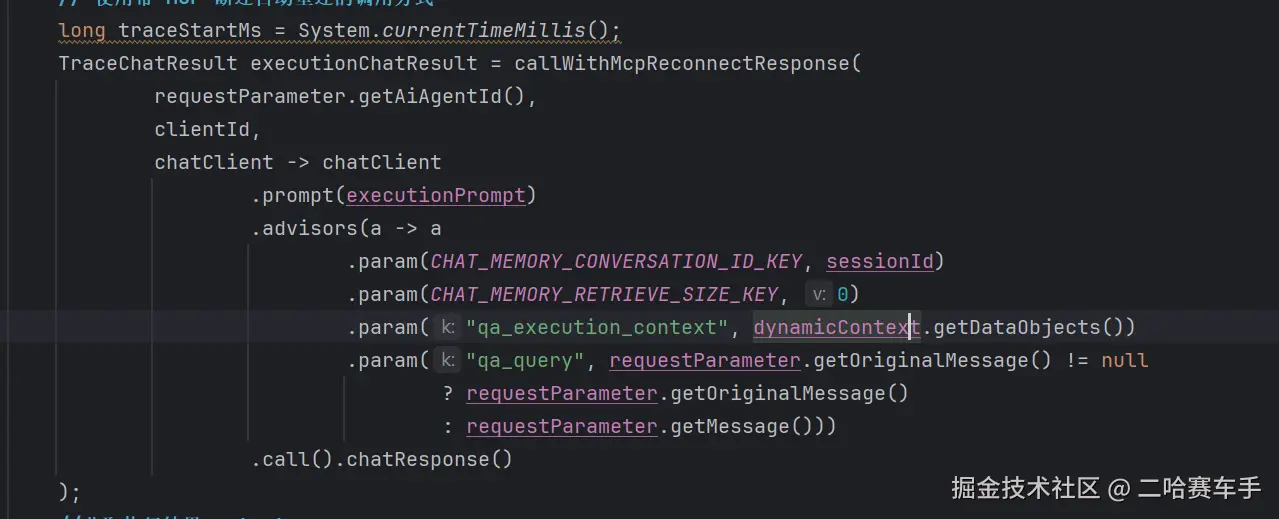
因为外界的
dynamicContext变量持有我们上面的hashMap的引用,上一步client1存入RAG检索结果,我们可以通过这个引用获取到具体的值。我们在设置client2的顾问时,通过调用dynamicContext.getDataObjects传递这个引用给client2的顾问,这样client2的顾问在执行的before方法时,通过取出client2的共享容器context,在通过qa_execution_context取出具体的结果。如果有值,则直接复用该RAG检索结果,如果没有值,再重新进行RAG检索,并将结果再次存入这个hashMap中
java
┌─────────────────────────────────────────────────────────────┐
│ Step1AnalyzerNode 执行 │
│ │
│ dynamicContext.getDataObjects() │
│ ├─ 返回 HashMap 实例(容器 A) │
│ └─ 传递给 advisor: .param("qa_execution_context", 容器 A) │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ RagAnswerAdvisor.before() │
│ │
│ executionContext = context.get("qa_execution_context") │
│ ├─ executionContext 引用 容器 A │
│ └─ writeCachedRetrievalResult(executionContext, ...) │
│ └─ executionContext.put("qa_retrieval_cache", ...) │
│ 👆 直接修改容器 A │
└─────────────────────┬───────────────────────────────────────┘
│
│ 容器 A 现在包含 RAG 检索结果
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Step2PrecisionExecutorNode 执行 │
│ │
│ dynamicContext.getDataObjects() │
│ ├─ 返回同一个 HashMap 实例(容器 A) │
│ └─ 容器 A 中已经包含 Step1 写入的数据 │
│ └─ .param("qa_execution_context", 容器 A) │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ RagAnswerAdvisor.before() (Step2) │
│ │
│ readCachedRetrievalResult(executionContext, cacheKey) │
│ ├─ executionContext 引用 容器 A │
│ └─ 从容器 A 中读取 "qa_retrieval_cache" │
│ └─ 命中缓存!跳过 RAG 检索 │
└─────────────────────────────────────────────────────────────┘- 通过 Java 的 引用传递 机制
- Step1 调用时: dynamicContext.getDataObjects() → HashMap 实例 A → 传给 advisor → advisor 修改实例 A
- Step2 调用时: dynamicContext.getDataObjects() → 同一个 HashMap 实例 A → 读取已修改的数据
- 为什么能共享?
- 因为 dynamicContext.getDataObjects() 始终返回 同一个 HashMap 实例
- Java 中对象是引用传递,advisor 内部的修改会直接反映到原始对象中
问题2
如果我们有的client本身需要跳过顾问的一些方法,比如client1需要RAG检索,client3不需要,怎么控制实现这种差异化的顾问,虽然用的是同一个顾问,但是执行的内容不同
解决
博主举个例子就明白了
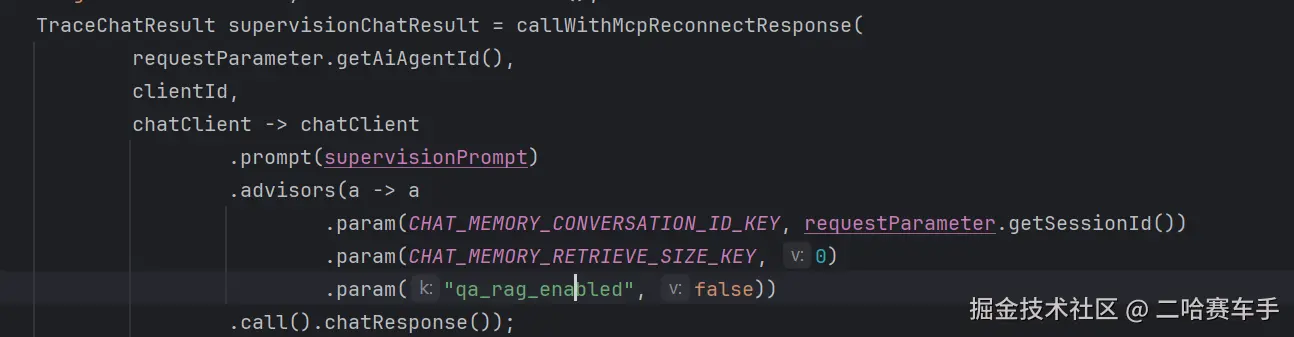
我们在执行顾问时传递一个标识,比如我们图上的
"qa_rag_enabled":false,那么我们在顾问执行RAG检索逻辑时,先从共享容器context中读取"qa_rag_enabled"这个键,如果值为fakse,那么就说明我们需要跳过RAG检索,直接进行下一步逻辑
六·:Spring AI的Advisor的一些缺陷
这是博主偶然之间发现的,也是那种本来程序好好的,突然改动了一点,程序突然就运行不了了,但是通过不断debug调试+问AI,终于解决了
我们是自定义的顾问出问题了,抛出空指针异常,这里博主就不迈关子了,直接解释哪里有问题

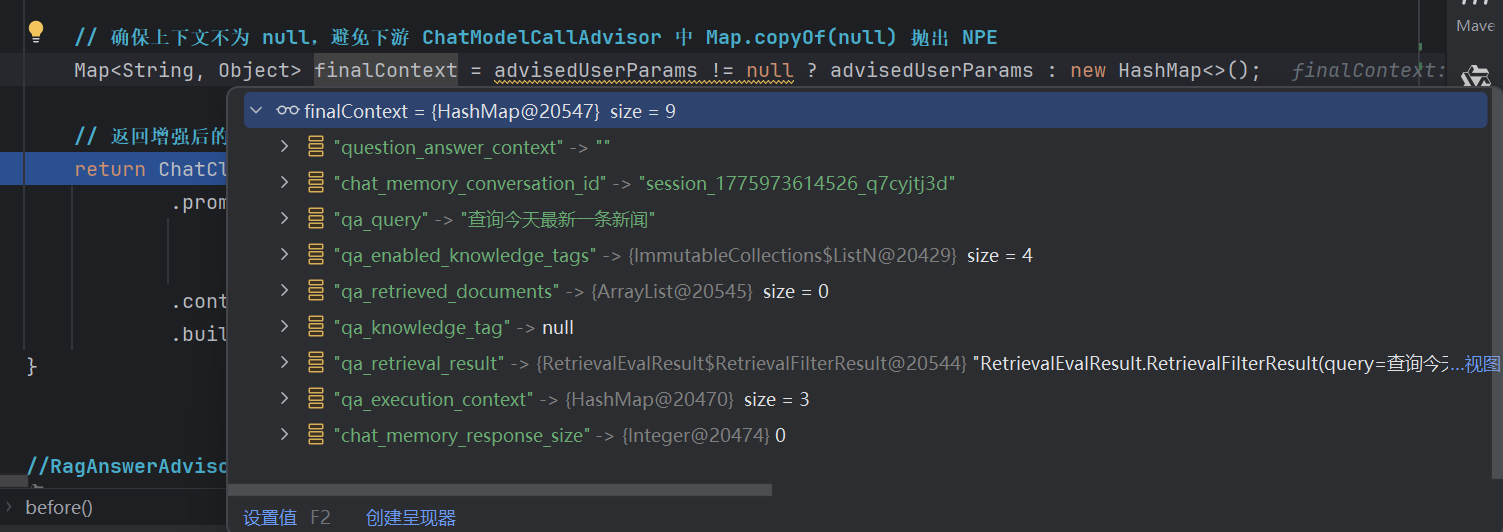
博主在操作顾问的共享容器
context时,设置了一个keyqa_knowledge_tag,但是值为NULL,这一点就出问题了
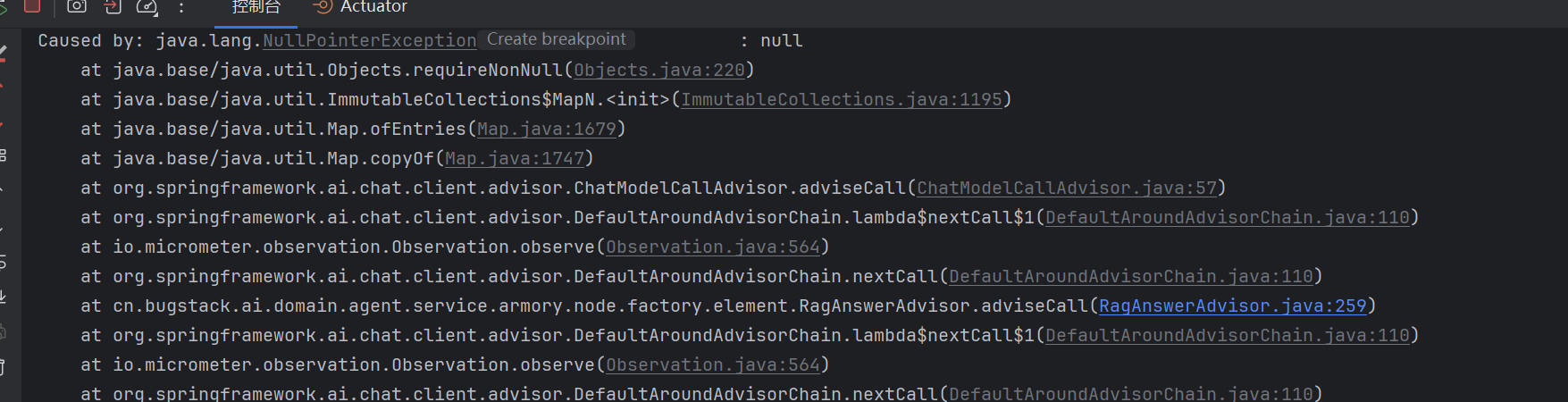
我们顾问的before(...) 执行成功了,返回了一个 ChatClientRequest 。然后 callAdvisorChain.nextCall() 把这个请求传给下一个 Advisor( ChatModelCallAdvisor ),而 ChatModelCallAdvisor 在处理时,其内部调用了 Map.copyOf(context) ,这里的 context 为 null。为NULL的原因就是因为我们的那个key的值为NULL
这就涉及到了Spring AI的一个涉及缺陷,这里附上github的具体问题链接
https://github.com/spring-projects/spring-ai/issues/4952问题的根因是: ChatClientRequest 的 context Map 中如果 某个 value 为 null ,那么在 ChatModelCallAdvisor 中调用 Map.copyOf() 时会抛出 NullPointerException 。因为
Map.copyOf() 不允许 null 值。ChatModelCallAdvisor.adviseCall() 内部会调用 Map.copyOf(context) ,而 Java 的 Map.copyOf() 方法 不允许 Map 中存在 null 值 ,否则会抛出NullPointerException。
从堆栈可以看到(博主出现的错误):
java
at java.base/java.util.Map.copyOf(Map.java:1747)
at org.springframework.ai.chat.client.advisor.ChatModelCallAdvisor.
adviseCall(ChatModelCallAdvisor.java:57)解决方案
做防御性编程,如果设置给context容器的字符串为NULL,那么就替换为空字符串``
java
// 修复前
advisedUserParams.put("qa_retrieved_documents", documents);
advisedUserParams.put("qa_knowledge_tag", knowledgeTag);
advisedUserParams.put("qa_query", queryText);
// 修复后
advisedUserParams.put("qa_retrieved_documents", documents != null ? documents : Collections.emptyList());
advisedUserParams.put("qa_knowledge_tag", knowledgeTag != null ? knowledgeTag : "");
advisedUserParams.put("qa_query", queryText != null ? queryText : "");