还在为新接手的巨型仓库发愁? App、前端、后端揉在一起的祖传代码,看着就头大?
Zread 是你的代码导航员 ------ 一键生成项目文档,从全局架构到模块细节,清晰得像看地图。
bash
# 就是这么简单
cd 你的项目
zread generate -y && zread browse
# 浏览器自动打开,清晰的项目文档就在眼前
生成的文档效果还挺好:
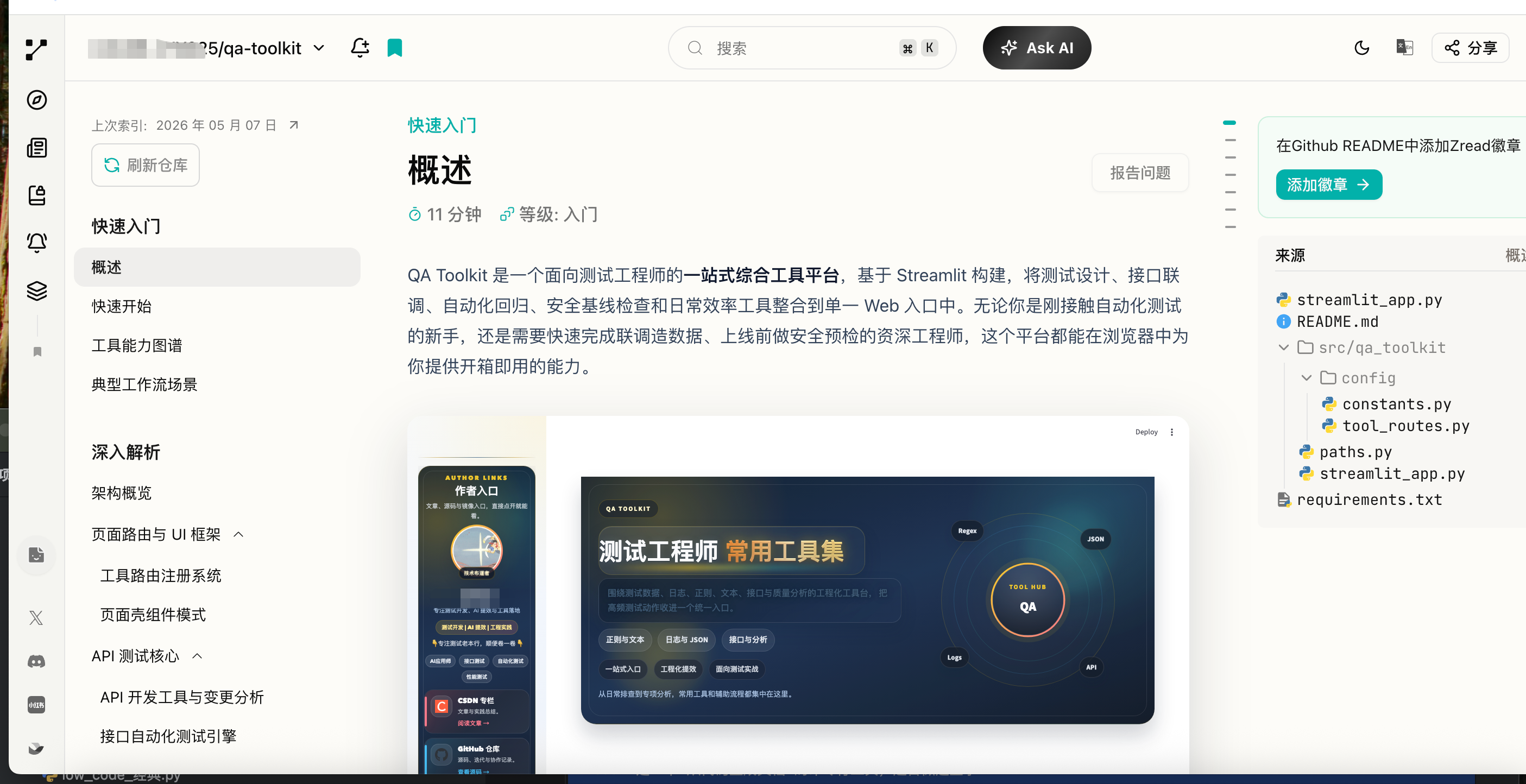
Zread 使用说明
本文面向本机已安装好的 zread 命令,适合日常给代码仓库生成可读文档,也适合结构较复杂的项目做代码理解和复盘。
说明:
- 文中命令参数以当前已安装版本
zread_cli@0.2.12为准。 zread的核心工作方式是"基于当前工作区生成文档",所以你通常需要先cd到目标项目根目录再执行。- 对"复杂项目、App + 前后端混合项目"的部分,属于结合工具能力给出的实战建议,不是额外隐藏参数。
1. 工具定位
zread 是一个"从代码生成文档"的命令行工具,适合做这些事:
- 快速理解一个新仓库
- 给已有项目生成 Wiki/文档视图
- 帮团队成员或自己做项目复盘
- 在大仓库里建立"先总览、再下钻"的阅读入口
2. 安装后如何使用
如果你已经按当前机器的方式安装过,只需要在新终端里执行:
bash
source ~/.zshrc确认命令可用:
bash
zread version
zread --help如果 zread 找不到,优先检查:
bash
echo $PATH当前机器已经把下面这条写进 ~/.zshrc:
bash
export PATH="$HOME/.npm-global/bin:$PATH"3. 基本命令
3.1 登录
首次使用建议先登录:
bash
zread login常见变体:
bash
zread login --custom
zread login --model <模型名>说明:
--custom:跳过模型服务菜单,直接手动配置 API Key--model:登录完成后自动选择某个模型
3.1.1 先明确一件事
zread 的登录和你终端里已有的 GitHub 登录状态不是一套。
也就是说:
- 你已经在终端里登录 GitHub,不代表
zread已登录 zread需要单独执行一次zread login或zread login --custom
3.1.2 最常见的两种登录方式
方式 1:走默认登录流程
bash
zread login适用场景:
- 你准备直接使用
zread内置支持的模型服务 - 你有 Z.AI / BigModel 等体系内的账号或订阅
方式 2:手动配置 API Key
bash
zread login --custom适用场景:
- 你已经有自己的 API Key
- 你使用的是 OpenAI 兼容接口
- 你使用的是中转 API / 代理 API
3.1.3 登录菜单该怎么选
如果出现类似这些选项:
BigModel.cn Coding Plan (CN)Z.AI Coding Plan (Non-CN)BigModel.cn (CN)Z.AI (Non-CN)OpenAIOpenRouterMoonshot(Kimi)MiniMax自定义
推荐选择原则:
- 用官方 Z.AI / BigModel 账号:选对应官方项
- 用官方 OpenAI API Key:优先选
OpenAI - 用 OpenAI 兼容中转 API Key:优先选
自定义 - 不确定 provider,但你知道
Base URL + API Key + Model:优先选自定义
3.1.4 OpenAI 和 自定义 的区别
如果你手里是官方 OpenAI API Key,并且接口地址就是官方地址:
text
https://api.openai.com/v1那么优先选:
text
OpenAI如果你手里是中转 Key、代理 Key、OpenAI 兼容网关 Key,例如常说的"codex 中转 key",优先选:
text
自定义原因:
- 中转服务通常需要手动填写
Base URL 自定义更适合自己指定API Key、Base URL、Model
3.1.5 codex 中转 API Key 能不能用
结论:
- 如果它是 OpenAI 兼容 API,大概率可以试
- 如果它只是网页登录态、GitHub 登录态、或不是标准 API Key,一般不行
能尝试的前提通常是:
- 你有实际可用的
API Key - 你知道对应的
Base URL - 你知道对应的
Model - 这个中转服务兼容 OpenAI 风格接口
建议直接走:
bash
zread login --custom3.1.6 --custom 怎么填
常见填写模板:
text
Provider: custom
API Key: 你的key
Base URL: 你的中转地址/v1
Model: 你的模型名例如:
text
Provider: custom
API Key: sk-xxxxx
Base URL: https://example.com/v1
Model: gpt-4.1填写时注意:
Base URL通常写到/v1- 不要写成具体接口地址
- 一般不要写成
/v1/chat/completions
正确示例:
text
https://example.com/v1错误示例:
text
https://example.com/v1/chat/completions3.1.7 模型名怎么填
模型名必须是你当前 provider 或中转真实支持的名字,例如可能是:
gpt-4.1gpt-4ogpt-4.1-minio4-mini- 或者你中转平台自己定义的模型别名
如果模型名写错,即使 API Key 正确,也可能登录后无法正常生成文档。
3.1.8 有没有免费的登录方式
目前更稳妥的理解是:
zread没有明确写出"永久免费登录方案"- 如果你用
--custom,是否免费取决于你接入的模型服务是否有免费额度
所以"免费"的关键不在 zread 本身,而在你使用的模型平台。
3.1.9 登录后怎么验证
登录或配置完成后,建议直接验证:
bash
cd /path/to/project
zread generate -y如果命令能正常开始生成,说明配置基本已经打通。
如果 zread 命令找不到,先执行:
bash
source ~/.zshrc3.2 生成文档
在项目根目录执行:
bash
cd /path/to/your/project
zread generate常用参数:
bash
zread generate -y
zread generate --skip-failed
zread generate --draft resume
zread generate --draft clear
zread generate --draft cancel参数说明:
-y, --yes:跳过确认,直接开始生成--skip-failed:某些页面失败时跳过失败页面,先提交剩余文档--draft resume:继续未完成的草稿/生成任务--draft clear:清空草稿,重新开始--draft cancel:取消本次草稿处理
3.3 浏览文档
文档生成后,在项目目录中执行:
bash
zread browse常用参数:
bash
zread browse --generate
zread browse --port 9681
zread browse --host 0.0.0.0
zread browse --version <version-id>参数说明:
--generate:如果当前还没有文档,直接触发生成流程--port:指定浏览端口--host:指定监听地址--version:打开指定版本,或显示版本选择
3.4 查看配置
bash
zread config3.5 更新工具
bash
zread update4. 常见报错排查
下面这些问题是实际使用 zread 时最常见的。
4.1 command not found: zread
现象:
bash
zsh: command not found: zread原因通常是:
- 当前终端还没加载
~/.zshrc PATH里没有~/.npm-global/bin
先执行:
bash
source ~/.zshrc
which zread如果还是不行,检查:
bash
echo $PATH确认是否包含:
bash
$HOME/.npm-global/bin4.2 登录后仍然不能用
现象:
zread login看起来完成了- 但
zread generate -y仍然失败
常见原因:
- 登录的是错误 provider
- 配置了错误模型
- API Key 虽然保存了,但没有实际权限
Base URL或模型名不匹配
建议优先检查:
- 你选的是不是正确 provider
- 如果是中转 key,是否应该走
自定义 - 模型名是不是这个 provider 真正支持的名字
4.3 401 Unauthorized / 403 Forbidden
常见含义:
401:API Key 错误、过期、未生效403:有 Key,但没有访问当前模型或当前接口的权限
优先排查:
- Key 是否输错
- Key 是否属于当前 provider
- 模型是否超出权限范围
- 账号是否真的开通了对应服务
如果你用的是中转 API:
- 检查中转服务是否还有效
- 检查中转是否限制来源、模型、并发或额度
4.4 model not found / 模型不可用
原因通常是:
- 模型名拼错
- 模型名不是 provider 支持的真实名字
- 你的账号没有该模型权限
例如,不同 provider 的模型名可能完全不同:
gpt-4.1gpt-4ogpt-4.1-minio4-mini- 或者 provider 自定义别名
处理方式:
- 回到你使用的 provider 或中转平台,确认模型真实名称
- 不要凭感觉填模型名
4.5 Base URL 填错
这是 --custom 最容易出错的地方。
正确写法通常是:
text
https://example.com/v1错误写法常见有:
text
https://example.com/v1/chat/completions
https://example.com/chat/completions
example.com/v1排查原则:
- 一般写到
/v1 - 不写具体接口路径
- 要带
https://
4.6 只有 GitHub / Codex 登录态,没有 API Key
这种情况通常不能直接让 zread 工作。
原因:
- GitHub 登录不是
zread的 API 授权 - Codex/ChatGPT 网页登录态也不是标准 API Key
结论:
- 只有网页登录态,一般不够
- 真正可用的是
API Key - 如果是中转方案,还需要
Base URL + Model
4.7 codex 中转 key 配好了还是不通
如果你已经选了 自定义,仍然失败,优先检查这几项:
- 这个中转是否真兼容 OpenAI 接口
Base URL是否写到了/v1- 模型名是否和中转支持的一致
- 这个 key 是否有额度
- 中转站是否对来源 IP、接口类型、模型做了限制
推荐的最小配置格式:
text
Provider: custom
API Key: 你的key
Base URL: 你的中转地址/v1
Model: 你的模型名4.8 生成过程中中断或失败
如果登录已经没问题,但生成过程失败,可以优先试:
bash
zread generate --draft resume
zread generate --skip-failed
zread generate --draft clear使用建议:
- 被中断后先试
--draft resume - 只想先拿到可用结果,试
--skip-failed - 草稿脏了或结构变动大,再试
--draft clear
4.9 复杂仓库根目录跑不动或结果太乱
现象:
- 生成太慢
- 文档信息量太大
- 看不出真正主业务
原因:
- 仓库太大
- 混合了 App、前端、后端、脚本、文档、构建产物
处理方式:
- 先根目录跑一次,只看全局拓扑
- 再进入关键子项目分别跑
例如:
bash
cd /path/to/repo
zread generate -y
cd /path/to/repo/app
zread generate -y
cd /path/to/repo/server
zread generate -y4.10 如何快速判断是登录问题还是项目问题
最简单的判断方法:
先在任意一个小一点的项目目录执行:
bash
cd /path/to/small-project
zread generate -y判断逻辑:
- 如果小项目都跑不通,优先怀疑登录或配置问题
- 如果小项目能跑,大项目不顺,优先怀疑项目体量或目录选择问题
5. 最常用的使用方式
5.1 给单个项目快速出文档
bash
cd /path/to/project
zread generate -y
zread browse适用场景:
- 一个前端仓库
- 一个后端服务仓库
- 一个独立 App 仓库
建议:
- 在仓库根目录执行,不要在
src/、app/、pages/这种子目录里直接跑第一遍 - 先生成全局视图,再决定要不要进入子模块单独生成
5.2 给陌生项目做"先看再问"
推荐顺序:
bash
cd /path/to/project
zread generate
zread browse先重点看:
- 项目首页/总览
- 模块结构
- 核心入口文件
- 主要调用链
- 配置文件和环境变量相关说明
这类场景下,zread 的价值不是替代你读代码,而是先帮你建立地图。
5.3 生成失败后继续
如果过程被中断,优先试:
bash
zread generate --draft resume如果你已经改了很多代码结构,或者怀疑旧草稿不干净,再试:
bash
zread generate --draft clear如果只是部分页面失败,但你更关心先拿到能看的版本:
bash
zread generate --skip-failed6. 复杂项目怎么用
复杂项目的关键不是"有没有更复杂的命令",而是"选对运行目录"和"拆对文档粒度"。
6.1 先判断你的项目属于哪一类
常见复杂结构:
- Monorepo:一个仓库里有多个应用/服务
- App + 后端 + 管理后台在同一个仓库
- App 单独一个目录,前端单独一个目录,服务端单独一个目录
- 微服务仓库,多个服务并列
- 代码很多、依赖很多、目录层级很深
6.2 总原则
建议按两层来使用:
- 在仓库根目录跑一遍,拿"全局架构视图"
- 再进入关键子项目分别跑,拿"子系统深度文档"
这样通常比只在根目录跑一次更实用。
7. App、前后端一起的项目怎么用
假设你的仓库大致像这样:
text
repo/
app/
web/
admin/
server/
docs/
package.json推荐做法不是只跑一次,而是分三步。
7.1 第一步:在仓库根目录生成总览
bash
cd /path/to/repo
zread generate -y
zread browse这一遍的目标:
- 看清整个仓库有哪些子系统
- 看清 App、Web、Admin、Server 之间的大致关系
- 找入口文件、共享模块、公共配置
适合回答的问题:
- 这个仓库整体是干什么的
- 哪些目录是主业务
- 哪些模块彼此依赖
- 哪一块值得继续深入
7.2 第二步:对关键子目录分别生成
如果你要看 App:
bash
cd /path/to/repo/app
zread generate -y
zread browse如果你要看前端:
bash
cd /path/to/repo/web
zread generate -y
zread browse如果你要看后端:
bash
cd /path/to/repo/server
zread generate -y
zread browse这样做的好处:
- 文档焦点更集中
- 单次生成的上下文更干净
- 更容易看清某一端内部模块划分
- 比在超级大仓根目录里硬看所有细节更高效
6.3 第三步:把"根目录总览"和"子项目细化"结合起来用
推荐阅读顺序:
- 先看根目录生成的文档,理解全局结构
- 再看
app/、web/、server/的独立文档 - 最后回到代码里验证关键调用链
这套方法特别适合这些问题:
- App 调的是哪个后端接口
- Web 和 Admin 是否共用组件或接口层
- Server 的哪一层在服务 App 和 Web
- 登录、支付、消息、上传这类跨端能力放在哪
7. 几类典型复杂场景建议
7.1 Monorepo 场景
例如:
text
repo/
apps/
mobile/
web/
packages/
ui/
utils/
services/
api/建议顺序:
bash
cd /path/to/repo
zread generate -y然后按关注点继续:
bash
cd /path/to/repo/apps/mobile
zread generate -y
cd /path/to/repo/apps/web
zread generate -y
cd /path/to/repo/services/api
zread generate -y推荐用途:
- 根目录:看工程组织方式
apps/mobile:看 App 业务结构apps/web:看前端页面与状态管理services/api:看接口、服务层、数据流
7.2 App 仓库里又内嵌前后端能力
例如一个移动端项目同时包含:
- 原生代码
- H5/Hybrid 页面
- 本地桥接层
- BFF 或 mock 服务脚本
建议:
- 先在 App 根目录生成一次
- 再针对
android/、ios/、hybrid/、mock/或server/子目录分别跑
原因:
- 原生层和前端层的关注点差别很大
- 分开跑更容易把桥接关系、资源依赖、页面容器职责看清楚
7.3 前后端都在一个仓库,但后端服务很多
如果 server/ 下还有多个微服务,不建议只在 server/ 跑一遍就结束。
更实用的方式是:
bash
cd /path/to/repo/server/service-a
zread generate -y
cd /path/to/repo/server/service-b
zread generate -y这样更适合做:
- 单服务职责理解
- 单服务接口排查
- 服务间依赖复盘
8. 如何提高生成质量
虽然 zread 能直接从代码生成文档,但项目本身越清晰,生成结果通常越好。
建议你在仓库里尽量具备这些内容:
- 根目录有
README - 子模块目录名清晰,不要全是缩写
- 关键配置文件保留在仓库中
- 接口定义、环境说明、启动方式尽量可见
- 不要把核心逻辑都藏在过度动态的脚本里
如果是复杂项目,尤其建议补这些信息:
- 根目录增加"仓库结构说明"
- 标清各子项目职责
- 标清哪些目录属于 App、前端、后端、共享层
- 标清核心链路,比如登录、订单、支付、消息
9. 实战工作流建议
如果你要做项目复盘,我建议按这个顺序使用。
9.1 理解项目
bash
cd /path/to/repo
zread generate -y
zread browse先记下:
- 项目分几层
- 入口在哪
- 共享模块在哪
- 关键业务在哪几个目录
9.2 深入某个子系统
bash
cd /path/to/repo/<sub-project>
zread generate -y
zread browse重点看:
- 页面入口
- 状态管理
- 接口层
- 服务层
- 数据模型
9.3 输出复盘结论
可以把 zread 生成出来的理解,转成你自己的复盘维度:
- 系统边界
- 模块职责
- 关键链路
- 技术债
- 耦合点
- 后续优化方向
10. 常见问题
10.1 应该在仓库根目录跑,还是子目录跑
结论:
- 第一次先在仓库根目录跑
- 复杂项目再进入关键子目录分别跑
10.2 项目很大,一次生成太重怎么办
建议:
- 先根目录生成总览
- 再对子系统单独生成
- 中断后优先尝试
--draft resume - 如果旧结果已经不可信,再用
--draft clear
10.3 只有 App、Web、Server 三块,怎么最稳
最稳的方式:
bash
cd /path/to/repo
zread generate -y
cd /path/to/repo/app
zread generate -y
cd /path/to/repo/web
zread generate -y
cd /path/to/repo/server
zread generate -y也就是:
- 根目录看整体
- 各端看细节
10.4 文档没生成完怎么办
按优先级试:
bash
zread generate --draft resume
zread generate --skip-failed
zread generate --draft clear11. 推荐命令清单
首次接触一个项目:
bash
cd /path/to/project
zread login
zread generate -y
zread browse复杂仓库总览:
bash
cd /path/to/repo
zread generate -y深入某个子系统:
bash
cd /path/to/repo/app
zread generate -y继续上次未完成任务:
bash
zread generate --draft resume跳过失败页面先出结果:
bash
zread generate --skip-failed没有文档时直接边生成边打开:
bash
zread browse --generate12. 一句话建议
对于简单项目,直接在根目录 zread generate 即可。
对于包含 App、前端、后端的复杂项目,不要只跑一次根目录。最实用的方式是:
- 根目录跑一次,拿全局结构
app/、web/、server/分别再跑一次,拿各自细节
这样生成出来的文档最容易真正服务于理解、复盘和交接。