【GUI-Agent】阿里通义MAI-UI 代码阅读(2)--- 实现
0x00 摘要
MAI-UI 是阿里通义实验室发布的一项重磅研究成果:是一个旨在 重塑人机交互方式 的"基础图形用户界面(GUI)智能体",和阶跃星辰的思路非常类似,因此我们可以互相印证。
MAI-UI的信息如下:
MAI-UI 的两类核心Agent如下,本篇会介绍这两类Agent:
| Agent | 文件 | 任务 | 输出协议 |
|---|---|---|---|
| MAIGroundingAgent | src/mai_grounding_agent.py | UI 元素定位(单步) | <grounding_think>.</grounding_think>{"coordinate":x,y},坐标基于 SCALE_FACT0R=999 归一化 |
| MAIUINavigationAgent | src/mai_navigation_agent.py | 多步移动端GUI导航,支持ask_user与mcp_call | .<tool_call>{json}</tool_call>,多轮带历史截图 |
0x01 工程实现特色
MAI-UI 工程实现的三个特色如下。
1.1 特色1
特色1:三套系统提示词对应三种Agent形态:grounding / 纯导航 / ask_user + MCP 增强导航
src/prompt.py同时维护:
-
MAI_MOBILE_SYS_PROMPT_GROUNDING 一 单步元素定位
-
MAI_MOBILE_SYS_PROMPT 一 标准多步导航
-
MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP 一 在导航动作集里叠加两个特殊工具:
- ask_user(question):模型主动反问用户、把任务"打回去"
- mcp_call(tool,args):调外部MCP工具(如高德导航)补全设备端做不到的能力

阿里5
意义:
- 这是"Agent-User Interaction +MCP Augmentation" 范式在代码层面的真实落点一不是新API、就是同一个模型在不同system prompt下解锁不同动作集。
- 新增交互类工具的正确姿势就是改prompt.py+parse_tagged_text的 schema,而不是另起一个Agent类。
1.2 特色2
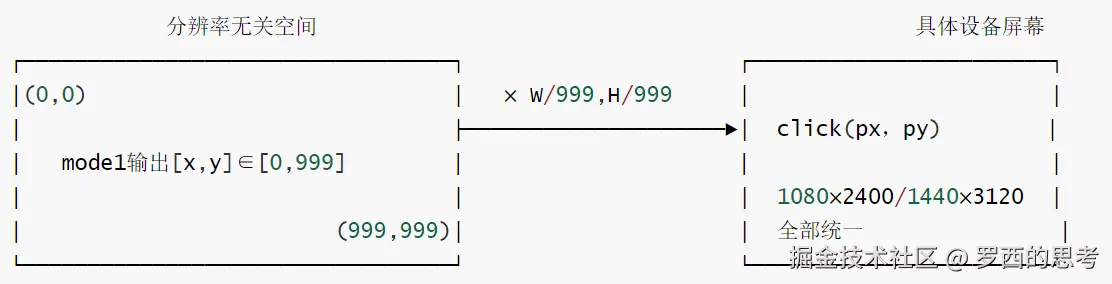
特色2是:归一化坐标空间SCALE_FACTOR = 999 + XML标签输出协议(而非function-calling)。
-
src/mai_grounding_agent.py 与 src/mai_naivigation_agent.py 都硬编码为 SCALE_FACTOR= 999;模型永远输出0,999区间整数,由客户端按当前截图(W,H)反归一化。
-
输出不是OpenAI function-calling,而是裸文本里的 XML 标签:
- Grounding:<grounding_think>...</grounding_think>{"coordinate":x,y}
- Navigation:.<tool_call>{json}</tool_call>(兼容 thinking 模型的)
- 解析器:parse_grounding_response、parse_tagged_text,错误统一抛 ValueError。
阿里6
意义:
- 跨分辨率泛化:同一个模型同一个权重无缝服务任意手机分辨率,不需要在 prompt里写屏幕尺寸;
- 协议无关于推理后端一VLLM0.11.0、HFtransformers 本地推理、DashScope都能用,因为只解析纯文本,不依赖任何后端的tool-call结构;
- 代价:解析鲁棒性必须由客户端自己保证(所以两个parser都做了容错+显式异常)
1.3 特色 3
特色 3:无状态服务端 +客户端自管TrajMemory,每步把历史截图重塞回 messages:
- BaseAgent 持有 traj_memory:TrajMemory,每个 TrajStep 同时存 screenshot: Image 和 screenshot_bytes:bytes(渲染vs序列化双用)
- MAIUINaivigationAgent._build_messages() 按 runtime_conf"history_n" 把最近 N 步的"截图+模型回复"重组成多轮user/assistant对话再发给vLLM一一一vLLM 端零会话状态。
- save_traj()/load_traj()走bytes,可被序列化/回放/做评测离线分析。
- stept的请求体(每步独立、无状态)如下:

阿里7
意义:
- 可回放、可评测、可断点续跑---save_traj出dict、load_traj直接灌回,离线replay,不需要真机/模拟器;
- 横向扩展友好一VLLM可以集群水平扩,因为没有会话粘性,这正契合 scaling parallel environments up to 512"的训l练形态在推理侧的对应做法;
- 代价:每步N张图都要重传,带宽与 prefill 成本随 history_n线性增长,调小 history_n是常见的省 token 技巧。
1.4 小结
MAI-UI的工程独到之处不是模型本身,而是这套客户端契约:分辨率无关的999坐标空间 + XML标签协议(与后端解耦)+ 无状态多轮重放(与历史长度解耦)+ 三档 prompt解锁的grounding/导航/ask_user+MCP 三种形态一一一后续任何二次开发都沿着这四条线走,而不是去改模型契约。
0x02 提示词
2.1 提示词代码
以下是提示词代码。
MAI_MOBILE_SYS_PROMPT
vbnet
MAI_MOBILE_SYS_PROMPT = """You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
For each function call, return the thinking process in <thinking> </thinking> tags, and a json object with function name and arguments within <tool_call></tool_call> XML tags:
```
<thinking>
...
</thinking>
<tool_call>
{"name": "mobile_use", "arguments": <args-json-object>}
</tool_call>
```
## Action Space
{"action": "click", "coordinate": [x, y]}
{"action": "long_press", "coordinate": [x, y]}
{"action": "type", "text": ""}
{"action": "swipe", "direction": "up or down or left or right", "coordinate": [x, y]} # "coordinate" is optional. Use the "coordinate" if you want to swipe a specific UI element.
{"action": "open", "text": "app_name"}
{"action": "drag", "start_coordinate": [x1, y1], "end_coordinate": [x2, y2]}
{"action": "system_button", "button": "button_name"} # Options: back, home, menu, enter
{"action": "wait"}
{"action": "terminate", "status": "success or fail"}
{"action": "answer", "text": "xxx"} # Use escape characters \', \", and \n in text part to ensure we can parse the text in normal python string format.
## Note
- Write a small plan and finally summarize your next action (with its target element) in one sentence in <thinking></thinking> part.
- Available Apps: `["Camera","Chrome","Clock","Contacts","Dialer","Files","Settings","Markor","Tasks","Simple Draw Pro","Simple Gallery Pro","Simple SMS Messenger","Audio Recorder","Pro Expense","Broccoli APP","OSMand","VLC","Joplin","Retro Music","OpenTracks","Simple Calendar Pro"]`.
You should use the `open` action to open the app as possible as you can, because it is the fast way to open the app.
- You must follow the Action Space strictly, and return the correct json object within <thinking> </thinking> and <tool_call></tool_call> XML tags.
""".strip()MAI_MOBILE_SYS_PROMPT_NO_THINKING
vbnet
MAI_MOBILE_SYS_PROMPT_NO_THINKING = """You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
```
<tool_call>
{"name": "mobile_use", "arguments": <args-json-object>}
</tool_call>
```
## Action Space
{"action": "click", "coordinate": [x, y]}
{"action": "long_press", "coordinate": [x, y]}
{"action": "type", "text": ""}
{"action": "swipe", "direction": "up or down or left or right", "coordinate": [x, y]} # "coordinate" is optional. Use the "coordinate" if you want to swipe a specific UI element.
{"action": "open", "text": "app_name"}
{"action": "drag", "start_coordinate": [x1, y1], "end_coordinate": [x2, y2]}
{"action": "system_button", "button": "button_name"} # Options: back, home, menu, enter
{"action": "wait"}
{"action": "terminate", "status": "success or fail"}
{"action": "answer", "text": "xxx"} # Use escape characters \', \", and \n in text part to ensure we can parse the text in normal python string format.
## Note
- Available Apps: `["Camera","Chrome","Clock","Contacts","Dialer","Files","Settings","Markor","Tasks","Simple Draw Pro","Simple Gallery Pro","Simple SMS Messenger","Audio Recorder","Pro Expense","Broccoli APP","OSMand","VLC","Joplin","Retro Music","OpenTracks","Simple Calendar Pro"]`.
You should use the `open` action to open the app as possible as you can, because it is the fast way to open the app.
- You must follow the Action Space strictly, and return the correct json object within <thinking> </thinking> and <tool_call></tool_call> XML tags.
""".strip()MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP
vbnet
# Placeholder prompts for future features
MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP = Template(
"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
For each function call, return the thinking process in <thinking> </thinking> tags, and a json object with function name and arguments within <tool_call></tool_call> XML tags:
```
<thinking>
...
</thinking>
<tool_call>
{"name": "mobile_use", "arguments": <args-json-object>}
</tool_call>
```
## Action Space
{"action": "click", "coordinate": [x, y]}
{"action": "long_press", "coordinate": [x, y]}
{"action": "type", "text": ""}
{"action": "swipe", "direction": "up or down or left or right", "coordinate": [x, y]} # "coordinate" is optional. Use the "coordinate" if you want to swipe a specific UI element.
{"action": "open", "text": "app_name"}
{"action": "drag", "start_coordinate": [x1, y1], "end_coordinate": [x2, y2]}
{"action": "system_button", "button": "button_name"} # Options: back, home, menu, enter
{"action": "wait"}
{"action": "terminate", "status": "success or fail"}
{"action": "answer", "text": "xxx"} # Use escape characters \', \", and \n in text part to ensure we can parse the text in normal python string format.
{"action": "ask_user", "text": "xxx"} # you can ask user for more information to complete the task.
{"action": "double_click", "coordinate": [x, y]}
{% if tools -%}
## MCP Tools
You are also provided with MCP tools, you can use them to complete the task.
{{ tools }}
If you want to use MCP tools, you must output as the following format:
```
<thinking>
...
</thinking>
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
```
{% endif -%}
## Note
- Available Apps: `["Contacts", "Settings", "Clock", "Maps", "Chrome", "Calendar", "files", "Gallery", "Taodian", "Mattermost", "Mastodon", "Mail", "SMS", "Camera"]`.
- Write a small plan and finally summarize your next action (with its target element) in one sentence in <thinking></thinking> part.
""".strip()
)MAI_MOBILE_SYS_PROMPT_GROUNDING
css
MAI_MOBILE_SYS_PROMPT_GROUNDING = """
You are a GUI grounding agent.
## Task
Given a screenshot and the user's grounding instruction. Your task is to accurately locate a UI element based on the user's instructions.
First, you should carefully examine the screenshot and analyze the user's instructions, translate the user's instruction into a effective reasoning process, and then provide the final coordinate.
## Output Format
Return a json object with a reasoning process in <grounding_think></grounding_think> tags, a [x,y] format coordinate within <answer></answer> XML tags:
<grounding_think>...</grounding_think>
<answer>
{"coordinate": [x,y]}
</answer>
""".strip()2.2 移动系统提示词差异一览
只有 MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP 模板支持 MCP 工具集成,且通过 Jinja2 条件语法实现动态插入;其余提示词版本均不包含 MCP 功能。
| 提示词 ID | 核心用途 | 思考标签 | 操作空间 | 特殊功能 |
|---|---|---|---|---|
| MAI_MOBILE_SYS_PROMPT | 标准 GUI 代理 | `` 必须 | 点击/长按/输入/滑动等全功能 | 无 |
| MAI_MOBILE_SYS_PROMPT_NO_THINKING | 快速响应 | 无思考标签 | 同上 | 省略思考,直接返回 JSON |
| MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP | 模板化+用户询问 | 可选 | 同上 | ask_user、double_click、Jinja2 模板、MCP 工具集成 |
| MAI_MOBILE_SYS_PROMPT_GROUNDING | 纯定位专用 | `` | 仅元素识别 | 输出 x,y 坐标,无操作命令 |
2.3 工具集成差异
MCP 功能只在 MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP 模板层集成,其余版本需外部桥接。
-
集成位置
- 仅 MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP 内置 MCP 工具调用入口(通过 Jinja2 模板动态注入)。
- 其余版本无 MCP 工具入口,需外部调用。
-
提示词层差异
- 标准版:无 MCP 占位符,纯 JSON 输出。
- MCP 版:模板内预留
{{mcp_tools}}变量,运行时注入具体工具描述。
-
运行时差异
- 标准版:LLM 输出传统动作 JSON,由外部框架手动转发至 MCP。
- MCP 版:渲染后提示词包含完整 MCP 工具 JSON,LLM 可直接调用。
-
条件性集成(仅 MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP)
- 使用 Jinja2 模板语法
{%if tools -%}...{%endif -%}实现动态集成 - 独立
## MCP Tools区域存放 MCP 工具描述 - 通过
{{tools}}变量动态插入可用工具信息 - 输出格式与标准移动操作不同:`` 内直接嵌入 MCP 函数调用
- 使用 Jinja2 模板语法
0x03 输出
3.1 输出格式区别
非 MCP 版本(MAI_MOBILE_SYS_PROMPT)
-
统一格式 :所有操作通过
mobile_use函数调用 -
固定结构 :GUI 操作封装在
arguments字段 -
示例:
bash<thinking>...</thinking> <tool_call> {"name":"mobile_use","arguments":<args-json-object>} </tool_call>
MCP 版本(MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP)
-
双重格式:支持标准 GUI 操作和 MCP 工具调用
-
工具特定格式 :MCP 工具调用使用实际函数名作为
name -
示例:
xml<thinking>...</thinking> <tool_call> {"name":<function-name>,"arguments":<args-json-object>} </tool_call>
下面代码把LLM的输出转换为结构化输出
python
def parse_action_to_structure_output(text: str) -> Dict[str, Any]:
"""
Parse model output text into structured action format.
Args:
text: Raw model output containing thinking and tool_call tags.
Returns:
Dictionary with keys:
- "thinking": The model's reasoning process
- "action_json": Parsed action with normalized coordinates
Note:
Coordinates are normalized to [0, 1] range by dividing by SCALE_FACTOR.
"""
text = text.strip()
results = parse_tagged_text(text)
thinking = results["thinking"]
tool_call = results["tool_call"]
action = tool_call["arguments"]
# Normalize coordinates from SCALE_FACTOR range to [0, 1]
if "coordinate" in action:
coordinates = action["coordinate"]
if len(coordinates) == 2:
point_x, point_y = coordinates
elif len(coordinates) == 4:
x1, y1, x2, y2 = coordinates
point_x = (x1 + x2) / 2
point_y = (y1 + y2) / 2
else:
raise ValueError(
f"Invalid coordinate format: expected 2 or 4 values, got {len(coordinates)}"
)
point_x = point_x / SCALE_FACTOR
point_y = point_y / SCALE_FACTOR
action["coordinate"] = [point_x, point_y]
return {
"thinking": thinking,
"action_json": action,
}3.2 功能范围区别
非 MCP 版本
- 有限操作集:仅预定义 GUI 操作(点击、滑动、输入等)
- 移动设备专属:专注触摸屏界面交互
- 固定动作空间:无法扩展新操作类型
MCP 版本
- 扩展操作集:除 GUI 操作外,支持 MCP 工具
- 系统级功能:可通过 MCP 工具执行复杂系统操作
- 动态功能:依据配置工具动态扩展功能范围
3.3 实际应用场景
标准 GUI 操作
- MCP 版本中标准 GUI 操作仍使用 mobile_use 函数
- 与非 MCP 版本行为基本相同
MCP 工具调用
- 需执行 MCP 工具时,使用工具名称作为函数名
- 可执行复杂任务(系统配置、数据处理等)
代码实现中的处理
在 MAIUIMobileAgent 类中:
- 若 self.tools 非空,使用 MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP 模板;
- 通过 render(tools=tools_str) 将工具列表注入提示词;
- 未配置工具时,回退到标准 MAI_MOBILE_SYS_PROMPT。
代码如下:
python
@property
def system_prompt(self) -> str:
"""
Generate the system prompt based on available MCP tools.
Returns:
System prompt string, with MCP tools section if tools are configured.
"""
if self.tools:
tools_str = "\n".join(
[json.dumps(tool, ensure_ascii=False) for tool in self.tools]
)
return MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP.render(tools=tools_str)
return MAI_MOBILE_SYS_PROMPTMCP 版本提供更灵活的操作能力,允许智能体在标准 GUI 操作与 MCP 工具间切换,从而执行更复杂任务;非 MCP 版本则专注纯粹移动界面操作。
0x04 MAIUINaivigationAgent
MAIUINaivigationAgent(移动端 GUI 导航智能体) 是整个 MAI-GUI 智能体的 "底座模块"------ 它封装了 LLM 初始化、历史界面上下文管理、多模态消息构建等核心能力,专门为移动端 GUI 自动化场景设计,能基于任务指令和多步历史界面截图,构建标准化的多模态消息发送给 LLM,为后续动作生成提供统一的输入基础。
4.1 核心特色
MAIUINaivigationAgent 的核心逻辑如下:初始化(配置 + LLM 客户端)→ 图片预处理(历史 + 当前截图统一格式)→ 消息构建(按固定结构拼接多模态内容),全流程为 LLM 提供标准化、结构化的输入。
| 特色维度 | 具体说明 |
|---|---|
| 历史上下文智能管理 | 支持配置history_n参数(默认 3),自动截取最近 N 步的界面截图作为历史上下文,既保留关键操作轨迹,又避免上下文过长导致 LLM 推理效率下降;仅加载history_n-1条历史截图 + 当前截图,精准控制上下文长度 |
| 多格式图片兼容处理 | _prepare_images方法支持字节流、PIL Image 等多种图片输入格式,自动转换为 RGB 格式的 PIL Image,解决不同来源截图的格式兼容问题,适配移动端截图的多样化场景 |
| MCP 工具集成能力 | 初始化时支持传入 MCP 工具列表,为后续 LLM 调用 MCP 工具(如执行设备操作)预留扩展接口,兼容 MCP 协议生态 |
| 标准化多模态消息构建 | _build_messages方法按 "系统提示词→用户指令→历史截图 + 历史响应→当前截图" 的固定逻辑构建消息,严格对齐 LLM 多模态输入格式,确保不同历史长度下消息结构统一 |
| 高度可配置化 | 支持自定义温度、top_k、top_p 等 LLM 推理参数,以及历史上下文长度(history_n),可根据不同移动端任务(如简单点击 / 复杂表单填写)调整配置 |
4.2 定义
MAIUINaivigationAgent 的定义如下。
python
class MAIUINaivigationAgent(BaseAgent):
"""
Mobile automation agent using vision-language models.
This agent processes screenshots and natural language instructions to
generate GUI actions for mobile device automation.
Attributes:
llm_base_url: Base URL for the LLM API endpoint.
model_name: Name of the model to use for predictions.
runtime_conf: Configuration dictionary for runtime parameters.
history_n: Number of history steps to include in context.
"""
def __init__(
self,
llm_base_url: str,
model_name: str,
runtime_conf: Optional[Dict[str, Any]] = None,
tools: Optional[List[Dict[str, Any]]] = None,
):
"""
Initialize the MAIMobileAgent.
Args:
llm_base_url: Base URL for the LLM API endpoint.
model_name: Name of the model to use.
runtime_conf: Optional configuration dictionary with keys:
- history_n: Number of history images to include (default: 3)
- max_pixels: Maximum pixels for image processing
- min_pixels: Minimum pixels for image processing
- temperature: Sampling temperature (default: 0.0)
- top_k: Top-k sampling parameter (default: -1)
- top_p: Top-p sampling parameter (default: 1.0)
- max_tokens: Maximum tokens in response (default: 2048)
tools: Optional list of MCP tool definitions. Each tool should be a dict
with 'name', 'description', and 'parameters' keys.
"""
super().__init__()
# Store MCP tools
self.tools = tools or []
# Set default configuration
default_conf = {
"history_n": 3,
"temperature": 0.0,
"top_k": -1,
"top_p": 1.0,
"max_tokens": 2048,
}
self.runtime_conf = {**default_conf, **(runtime_conf or {})}
self.llm_base_url = llm_base_url
self.model_name = model_name
self.llm = OpenAI(
base_url=self.llm_base_url,
api_key="empty",
)
# Extract frequently used config values
self.temperature = self.runtime_conf["temperature"]
self.top_k = self.runtime_conf["top_k"]
self.top_p = self.runtime_conf["top_p"]
self.max_tokens = self.runtime_conf["max_tokens"]
self.history_n = self.runtime_conf["history_n"]4.3 构建图像
_prepare_images 函数被用来构建图像。
python
def _prepare_images(self, screenshot_bytes: bytes) -> List[Image.Image]:
"""
Prepare image list including history and current screenshot.
Args:
screenshot_bytes: Current screenshot as bytes.
Returns:
List of PIL Images (history + current).
"""
# Calculate how many history images to include
if len(self.history_images) > 0:
max_history = min(len(self.history_images), self.history_n - 1)
recent_history = self.history_images[-max_history:] if max_history > 0 else []
else:
recent_history = []
# Add current image bytes
recent_history.append(screenshot_bytes)
# Normalize input type
if isinstance(recent_history, bytes):
recent_history = [recent_history]
elif isinstance(recent_history, np.ndarray):
recent_history = list(recent_history)
elif not isinstance(recent_history, list):
raise TypeError(f"Unidentified images type: {type(recent_history)}")
# Convert all images to PIL format
images = []
for image in recent_history:
if isinstance(image, bytes):
image = Image.open(BytesIO(image))
elif isinstance(image, Image.Image):
pass
else:
raise TypeError(f"Expected bytes or PIL Image, got {type(image)}")
if image.mode != "RGB":
image = image.convert("RGB")
images.append(image)
return images4.4 构建文字
python
def _build_messages(
self,
instruction: str,
images: List[Image.Image],
) -> List[Dict[str, Any]]:
"""
Build the message list for the LLM API call.
Args:
instruction: Task instruction from user.
images: List of prepared images.
Returns:
List of message dictionaries for the API.
"""
messages = [
{
"role": "system",
"content": [{"type": "text", "text": self.system_prompt}],
},
{
"role": "user",
"content": [{"type": "text", "text": instruction}],
},
]
image_num = 0
history_responses = self.history_responses
if len(history_responses) > 0:
for history_idx, history_response in enumerate(history_responses):
# Only include images for recent history (last history_n responses)
if history_idx + self.history_n >= len(history_responses):
# Add image before the assistant response
if image_num < len(images) - 1:
cur_image = images[image_num]
encoded_string = pil_to_base64(cur_image)
messages.append({
"role": "user",
"content": [{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{encoded_string}"},
}],
})
image_num += 1
messages.append({
"role": "assistant",
"content": [{"type": "text", "text": history_response}],
})
# Add current image (last one in images list)
if image_num < len(images):
cur_image = images[image_num]
encoded_string = pil_to_base64(cur_image)
messages.append({
"role": "user",
"content": [{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{encoded_string}"},
}],
})
else:
# No history, just add the current image
cur_image = images[0]
encoded_string = pil_to_base64(cur_image)
messages.append({
"role": "user",
"content": [{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{encoded_string}"},
}],
})
return messages4.5 流程
MAIUINaivigationAgent 多步循环流程图如下:

阿里8
特殊动作:
- ask_user(question) →暂停,把问题返还给用户(设备-云协同里的用户交互)
- mcp_call(tool,args) →调用外部MCP工具(如高德地图导航)
- finish() 任务结束
也参见如下: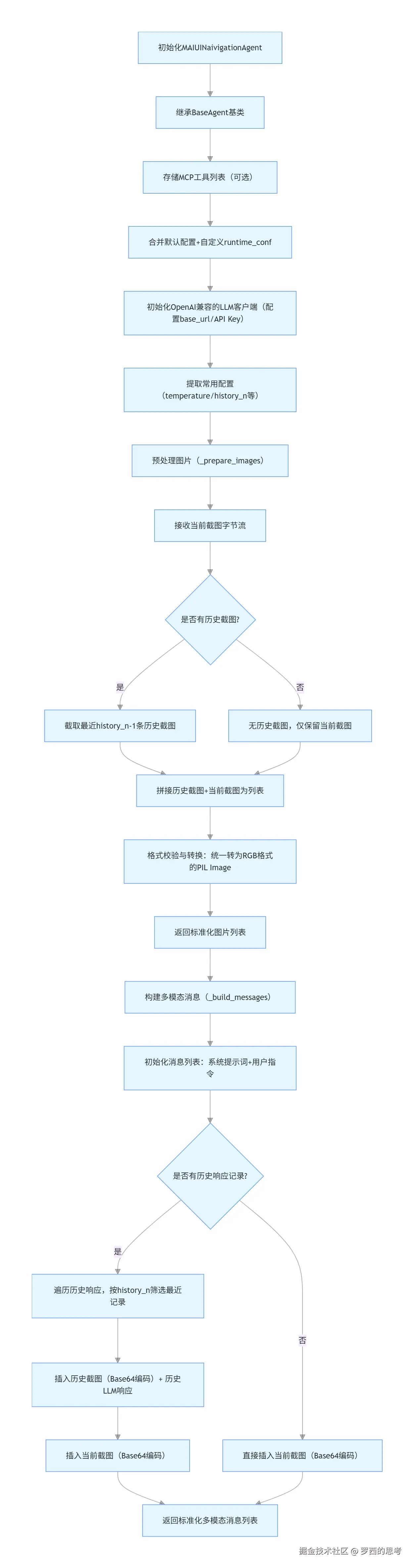
4.6 推理
核心作用
predict 是 MAI-GUI 智能体的核心决策与动作生成模块,是 GUI Agent 的 "决策大脑",核心解决 "根据任务指令和当前界面状态,生成下一步具体 GUI 动作" 的问题,区别于单纯的元素定位模块。
predict 的核心功能是接收任务指令(如 "完成 APP 登录")和当前界面观测信息(截图 + 可选的无障碍树),通过调用大语言模型生成并解析出下一步要执行的结构化 GUI 动作(如点击、滑动、输入等),同时记录完整的任务轨迹(Trajectory),是 GUI Agent 实现 "根据界面状态决策操作" 的核心环节。
predict 的流程闭环是:输入处理→消息构建→LLM 调用→响应解析→轨迹记录→结果输出,全流程覆盖异常处理,确保动作生成的稳定性。
核心特色
| 特色维度 | 具体说明 |
|---|---|
| 任务轨迹全链路记录 | 内置 traj_memory 轨迹记忆模块,每一步操作都会存储截图、模型响应、解析后的动作、推理过程等全量信息,支持任务溯源、调试和复盘 |
| 多维度界面观测输入 | 同时接收截图(视觉信息)和无障碍树(结构化 UI 信息),相比纯视觉输入更精准理解界面结构,适配复杂 GUI 场景 |
| 鲁棒的 LLM 调用与解析 | ① 内置 3 次 API 重试机制,捕获并打印异常栈信息,提升调用稳定性;② 标准化解析模型响应为 thinking(推理过程)+ action_json(结构化动作),确保输出格式统一 |
| 任务目标持久化 | 首次调用时将任务指令存入轨迹记忆作为持久化目标,避免后续步骤丢失核心任务方向 |
| 日志可视化友好 | 对包含图片的消息做脱敏打印(mask_image_urls_for_logging),既保留日志完整性又避免 Base64 编码刷屏,便于调试 |
流程
predict 的流程如下
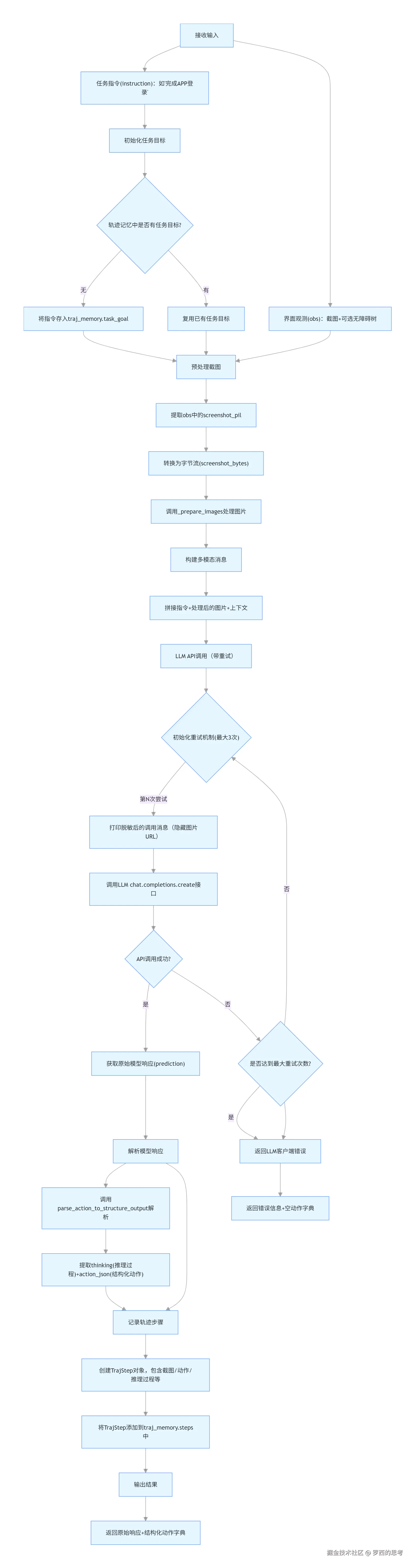
MAI-UI-2
时序图
时序图:用户 ⇔ Agent ⇔ vLLM (Navigation 场景)如下:
要点:
- 每步都把历史 history_n张截图重新塞进 messages(无服务端会话状态,vLLM是无状态的 chat completions);
- ask_user/mcp_call 是模型直接吐出的tool_call,调度由外层环境完成,agent 本身不做副作用;
- 日志路径上的 base64 图片一定经过 mask_image_urls_for_logging 替换为 IMAGE_DATA。

阿里9
代码
ini
def predict(
self,
instruction: str,
obs: Dict[str, Any],
**kwargs: Any,
) -> Tuple[str, Dict[str, Any]]:
"""
Predict the next action based on the current observation.
Args:
instruction: Task instruction/goal.
obs: Current observation containing:
- screenshot: PIL Image or bytes of current screen
- accessibility_tree: Optional accessibility tree data
**kwargs: Additional arguments including:
- extra_info: Optional extra context string
Returns:
Tuple of (prediction_text, action_dict) where:
- prediction_text: Raw model response or error message
- action_dict: Parsed action dictionary
"""
# Set task goal if not already set
if not self.traj_memory.task_goal:
self.traj_memory.task_goal = instruction
# Process screenshot
screenshot_pil = obs["screenshot"]
screenshot_bytes = safe_pil_to_bytes(screenshot_pil)
# Prepare images
images = self._prepare_images(screenshot_bytes)
# Build messages
messages = self._build_messages(instruction, images)
# Make API call with retry logic
max_retries = 3
prediction = None
action_json = None
for attempt in range(max_retries):
try:
messages_print = mask_image_urls_for_logging(messages)
print(f"Messages (attempt {attempt + 1}):\n{messages_print}")
response = self.llm.chat.completions.create(
model=self.model_name,
messages=messages,
max_tokens=self.max_tokens,
temperature=self.temperature,
top_p=self.top_p,
frequency_penalty=0.0,
presence_penalty=0.0,
extra_body={"repetition_penalty": 1.0, "top_k": self.top_k},
seed=42,
)
prediction = response.choices[0].message.content.strip()
print(f"Raw response:\n{prediction}")
# Parse response
parsed_response = parse_action_to_structure_output(prediction)
thinking = parsed_response["thinking"]
action_json = parsed_response["action_json"]
print(f"Parsed response:\n{parsed_response}")
break
except Exception as e:
print(f"Error on attempt {attempt + 1}: {e}")
traceback.print_exc()
prediction = None
action_json = None
# Return error if all retries failed
if prediction is None or action_json is None:
print("Max retry attempts reached, returning error flag.")
return "llm client error", {"action": None}
# Create and store trajectory step
traj_step = TrajStep(
screenshot=screenshot_pil,
accessibility_tree=obs.get("accessibility_tree"),
prediction=prediction,
action=action_json,
conclusion="",
thought=thinking,
step_index=len(self.traj_memory.steps),
agent_type="MAIMobileAgent",
model_name=self.model_name,
screenshot_bytes=screenshot_bytes,
structured_action={"action_json": action_json},
)
self.traj_memory.steps.append(traj_step)
return prediction, action_json4.7 轨迹
TrajMemory / TrajStep 数据结构图

阿里10
派生视图
派生视图(BaseAgent上的@property,避免外部直接遍历steps)如下:
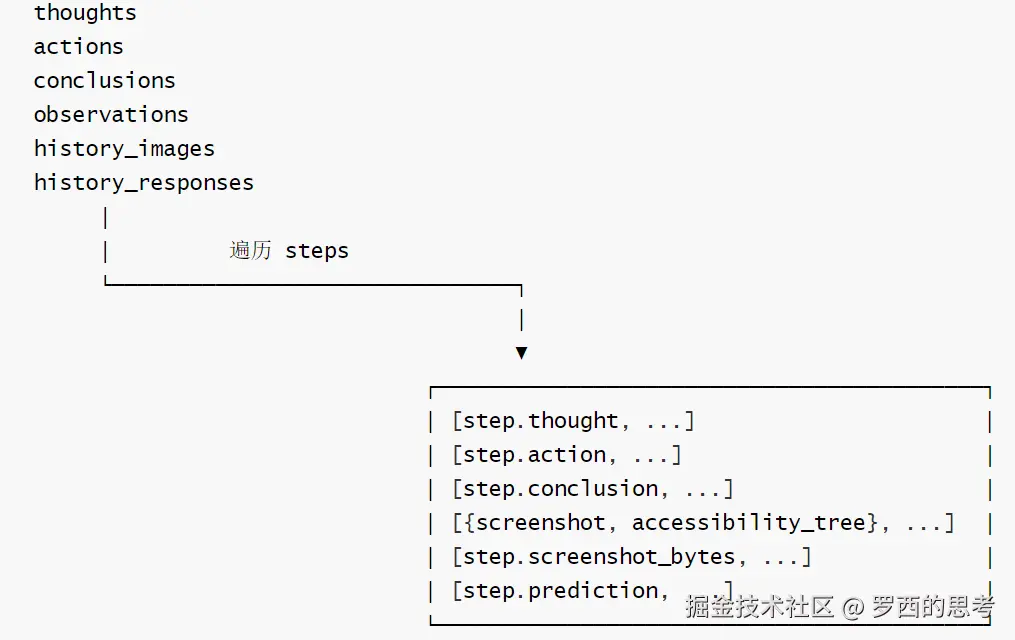
阿里11
序列化路径
python
BaseAgent.save_traj() → {
"task_goal", "task_id",
"steps": [
{ screenshot_bytes, accessibility_tree, prediction,
action, conclusion, thought,
step_index, agent_type, model_name }, ...
]
}
△ 注意:save 时只输出 screenshot_bytes,丢弃 PIL.Image 对象
△ structured_action 字段不在 save_traj 输出里(只在内存中使用)
BaseAgent.load_traj(traj_memory) →直接覆盖self.traj_memory
(需要外部自行从dict重建TrajMemory)要点:
- Screenshot(PIL)+screenshot_bytes(bytes)双份并存:渲染走PIL、序列化/网络走 bytes,不要只保留一个;
- thought、action <tool_call>,是解析器parse_tagged_text的两端落点; prediction存原始未解析的字符串,便于回放与debug,不要用解析后的结果覆盖它;
- save_traj与TrajStep 字段不完全同构(structured_action 不导出),新增字段时要同步两处,否则round-trip会丢失。
代码
less
@dataclass
class TrajStep:
"""
Represents a single step in an agent's trajectory.
Attributes:
screenshot: PIL Image of the screen at this step.
accessibility_tree: Accessibility tree data for the screen.
prediction: Raw model prediction/response.
action: Parsed action dictionary.
conclusion: Conclusion or summary of the step.
thought: Model's reasoning/thinking process.
step_index: Index of this step in the trajectory.
agent_type: Type of agent that produced this step.
model_name: Name of the model used.
screenshot_bytes: Original screenshot as bytes (for compatibility).
structured_action: Structured action with metadata.
"""
screenshot: Image.Image
accessibility_tree: Optional[Dict[str, Any]]
prediction: str
action: Dict[str, Any]
conclusion: str
thought: str
step_index: int
agent_type: str
model_name: str
screenshot_bytes: Optional[bytes] = None
structured_action: Optional[Dict[str, Any]] = None
@dataclass
class TrajMemory:
"""
Container for a complete trajectory of agent steps.
Attributes:
task_goal: The goal/instruction for this trajectory.
task_id: Unique identifier for the task.
steps: List of trajectory steps.
"""
task_goal: str
task_id: str
steps: List[TrajStep] = field(default_factory=list)0x05 MAIGroundingAgent
MAIGroundingAgent 是一款基于视觉 - 语言模型(VLM)的 GUI 定位智能体(Grounding Agent) ,该代码是 GUI Agent 的 "视觉定位模块",核心解决 "从自然语言 + 截图中精准找到 UI 元素坐标" 的问题,是 GUI Agent 实现界面理解的核心环节
MAIGroundingAgent 的核心功能是接收自然语言指令(如 "点击登录按钮")和 GUI 界面截图,通过调用大语言模型 API 解析指令意图、识别目标 UI 元素,并输出该元素的标准化坐标(归一化到 0,1 范围),为 GUI Agent 的后续操作(如点击、输入)提供精准的元素定位能力 ------ 这是 GUI Agent 实现 "看懂界面" 的核心模块。
MAIGroundingAgent 的流程闭环如下:输入预处理→消息构建→LLM 调用→响应解析→结果输出,全流程覆盖异常处理,确保可用性。
5.1 核心特色
| 特色维度 | 具体说明 |
|---|---|
| 多模态输入处理 | 同时接收自然语言指令(文本)和界面截图(图像),适配 GUI 交互的视觉 + 语言双输入场景 |
| 标准化解析逻辑 | 固定解析模型输出中的 (推理过程)和(坐标)标签,确保输出结构统一;坐标自动归一化(除以 SCALE_FACTOR),适配不同分辨率界面 |
| 鲁棒性设计 | ① 内置 3 次 API 重试机制,应对网络 / 模型临时异常;② 兼容图片格式(自动转换为 RGB)、输入类型(支持 PIL Image / 字节流);③ 完善的异常捕获,失败时返回明确错误标识 |
| 可配置化推理 | 支持自定义 LLM 推理参数(temperature/top_k/top_p/max_tokens 等),可根据场景调整模型生成策略(如 temperature=0 保证输出确定性) |
| 清晰的流程闭环 | 从 "输入处理→构建多模态消息→调用 LLM→解析响应→返回标准化结果" 形成完整闭环,输出同时包含模型推理过程和最终坐标,便于调试与溯源 |
5.2 定义
MAIGroundingAgent 如下。
python
class MAIGroundingAgent:
"""
GUI grounding agent using vision-language models.
This agent processes a screenshot and natural language instruction to
locate a specific UI element and return its coordinates.
Attributes:
llm_base_url: Base URL for the LLM API endpoint.
model_name: Name of the model to use for predictions.
runtime_conf: Configuration dictionary for runtime parameters.
"""
def __init__(
self,
llm_base_url: str,
model_name: str,
runtime_conf: Optional[Dict[str, Any]] = None,
):
"""
Initialize the MAIGroundingAgent.
Args:
llm_base_url: Base URL for the LLM API endpoint.
model_name: Name of the model to use.
runtime_conf: Optional configuration dictionary with keys:
- max_pixels: Maximum pixels for image processing
- min_pixels: Minimum pixels for image processing
- temperature: Sampling temperature (default: 0.0)
- top_k: Top-k sampling parameter (default: -1)
- top_p: Top-p sampling parameter (default: 1.0)
- max_tokens: Maximum tokens in response (default: 2048)
"""
# Set default configuration
default_conf = {
"temperature": 0.0,
"top_k": -1,
"top_p": 1.0,
"max_tokens": 2048,
}
self.runtime_conf = {**default_conf, **(runtime_conf or {})}
self.llm_base_url = llm_base_url
self.model_name = model_name
self.llm = OpenAI(
base_url=self.llm_base_url,
api_key="empty",
)
# Extract frequently used config values
self.temperature = self.runtime_conf["temperature"]
self.top_k = self.runtime_conf["top_k"]
self.top_p = self.runtime_conf["top_p"]
self.max_tokens = self.runtime_conf["max_tokens"]5.3 数据流
Grounding Agent单步流程图如下:

阿里12
也可以参见如下:
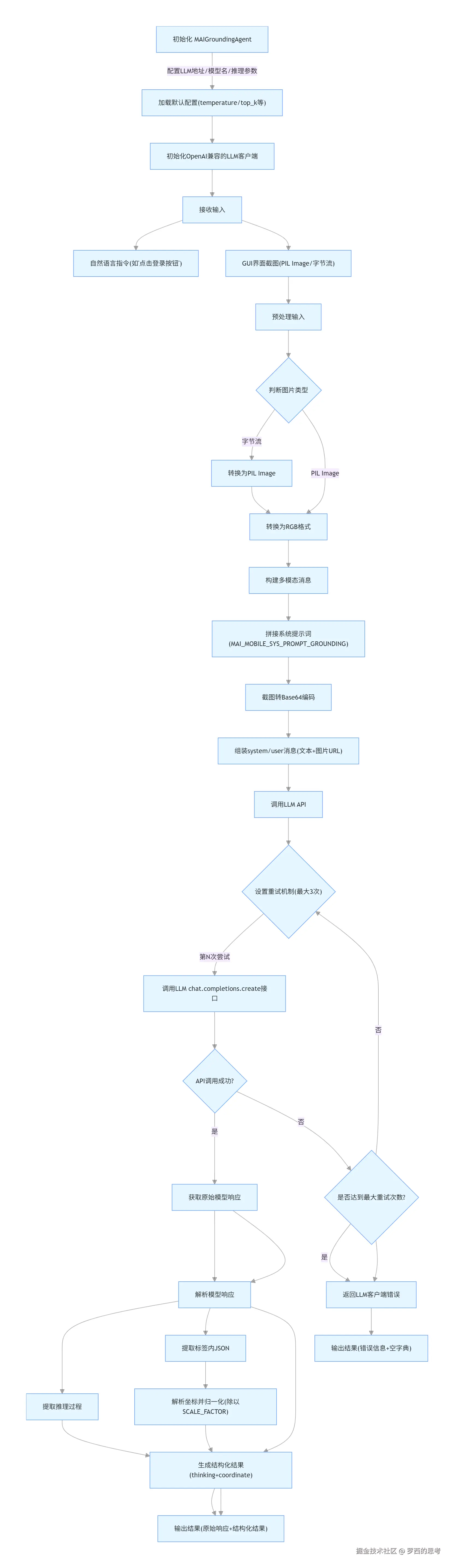
MAI-UI-3
5.4 推理
python
@property
def system_prompt(self) -> str:
"""Return the system prompt for grounding tasks."""
return MAI_MOBILE_SYS_PROMPT_GROUNDING
def _build_messages(
self,
instruction: str,
image: Image.Image,
) -> list:
"""
Build the message list for the LLM API call.
Args:
instruction: Grounding instruction from user.
image: PIL Image of the screenshot.
magic_prompt: Whether to use the magic prompt format.
Returns:
List of message dictionaries for the API.
"""
encoded_string = pil_to_base64(image)
messages = [
{
"role": "system",
"content": [
{
"type": "text",
"text": self.system_prompt,
}
],
}
]
messages.append(
{
"role": "user",
"content": [
{
"type": "text",
"text": instruction + "\n",
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{encoded_string}"
},
},
],
}
)
return messages
def predict(
self,
instruction: str,
image: Union[Image.Image, bytes],
**kwargs: Any,
) -> Tuple[str, Dict[str, Any]]:
"""
Predict the coordinate of the UI element based on the instruction.
Args:
instruction: Grounding instruction describing the UI element to locate.
image: PIL Image or bytes of the screenshot.
**kwargs: Additional arguments (unused).
Returns:
Tuple of (prediction_text, result_dict) where:
- prediction_text: Raw model response or error message
- result_dict: Dictionary containing:
- "thinking": Model's reasoning process
- "coordinate": Normalized [x, y] coordinate
"""
# Convert bytes to PIL Image if necessary
if isinstance(image, bytes):
image = Image.open(BytesIO(image))
if image.mode != "RGB":
image = image.convert("RGB")
# Build messages
messages = self._build_messages(instruction, image)
# Make API call with retry logic
max_retries = 3
prediction = None
result = None
for attempt in range(max_retries):
try:
response = self.llm.chat.completions.create(
model=self.model_name,
messages=messages,
max_tokens=self.max_tokens,
temperature=self.temperature,
top_p=self.top_p,
frequency_penalty=0.0,
presence_penalty=0.0,
extra_body={"repetition_penalty": 1.0, "top_k": self.top_k},
seed=42,
)
prediction = response.choices[0].message.content.strip()
print(f"Raw response:\n{prediction}")
# Parse response
result = parse_grounding_response(prediction)
print(f"Parsed result:\n{result}")
break
except Exception as e:
print(f"Error on attempt {attempt + 1}: {e}")
prediction = None
result = None
# Return error if all retries failed
if prediction is None or result is None:
print("Max retry attempts reached, returning error flag.")
return "llm client error", {"thinking": None, "coordinate": None}
return prediction, result5.5 解析
python
def parse_grounding_response(text: str) -> Dict[str, Any]:
"""
Parse model output text containing grounding_think and answer tags.
Args:
text: Raw model output containing <grounding_think> and <answer> tags.
Returns:
Dictionary with keys:
- "thinking": The model's reasoning process
- "coordinate": Normalized [x, y] coordinate
Raises:
ValueError: If parsing fails or JSON is invalid.
"""
text = text.strip()
result: Dict[str, Any] = {
"thinking": None,
"coordinate": None,
}
# Extract thinking content
think_pattern = r"<grounding_think>(.*?)</grounding_think>"
think_match = re.search(think_pattern, text, re.DOTALL)
if think_match:
result["thinking"] = think_match.group(1).strip()
# Extract answer content
answer_pattern = r"<answer>(.*?)</answer>"
answer_match = re.search(answer_pattern, text, re.DOTALL)
if answer_match:
answer_text = answer_match.group(1).strip()
try:
answer_json = json.loads(answer_text)
coordinates = answer_json.get("coordinate", [])
if len(coordinates) == 2:
# Normalize coordinates from SCALE_FACTOR range to [0, 1]
point_x = coordinates[0] / SCALE_FACTOR
point_y = coordinates[1] / SCALE_FACTOR
result["coordinate"] = [point_x, point_y]
else:
raise ValueError(
f"Invalid coordinate format: expected 2 values, got {len(coordinates)}"
)
except json.JSONDecodeError as e:
raise ValueError(f"Invalid JSON in answer: {e}")
return result0xFF 参考
阿里发布MAI-UI,一个"活"在屏幕里的全能AI助手!手机真能全自动了?
本文使用 markdown.com.cn 排版